一、为什么要学习集合?
1、数组的缺陷:
(1)数组中只能存储相同类型的数据。(2)数组的长度固定不变,不能很好的解决元素数量动态变化的问题。(3)虽然可以通过数组名.length获取数组的长度,但却无法直接获取其中真正存储的元素的个数;(4)数组采取的是在内存中分配连续空间的方式来存储数据,虽然可以通过下标快速获取元素,但是反过来,要想通过某个元素的信息来查找这个元素时却比较麻烦,需要逐个遍历,效率低下。(5)无法通过更复杂、方便的方式来存储数据....2、针对数组的这些缺陷,Java 提供了比数组更灵活、更实用的“集合框架”,可大大提高软件的开发效率,并且不同的集合可适用于不同的场合。
?二、什么是集合?
1、与变量、数组一样,集合也是存储数据的一种容器。2、它由一组接口和类组成,位于java.util包中。3、它的关系结构如下: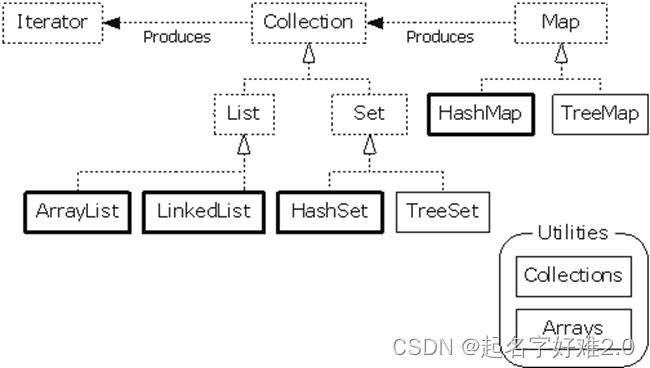 虚线框表示接口或抽象类,实线框表示实现类,粗实线框表示常用的实现类。虚线和空心箭头表示实现关系,虚线和实心箭头表示依赖关系(即线连接的类中使用了箭头所指向的类)JavaUML图解:https://www.cnblogs.com/shamao/p/10875550.html
虚线框表示接口或抽象类,实线框表示实现类,粗实线框表示常用的实现类。虚线和空心箭头表示实现关系,虚线和实心箭头表示依赖关系(即线连接的类中使用了箭头所指向的类)JavaUML图解:https://www.cnblogs.com/shamao/p/10875550.html
?三、list接口:有序?&?不唯一?
(1)ArraysList:?
????????①和数组采用相同的存储方式,在内存中开辟连续的空间,并且实现了长度可变的数组,也称为动态数组。????????②与数组的不同的是:数组只能存储相同类型的元素,但ArraysList可以存储任何类型的元素,并且会把所有元素都转换成Object类型(本质上仍是相同数据类型)。????????③因其内存空间连续,在增加和删除非尾部元素时会造成其它元素的移动,因此(“增删改”)效率较低。但 适用于遍历和随机访问元素?(即“查”)。
?(2)LinkedList:
????????①采用链表式的存储方式,适用于插入和删除元素,不适用于查找元素。与ArraysList互补。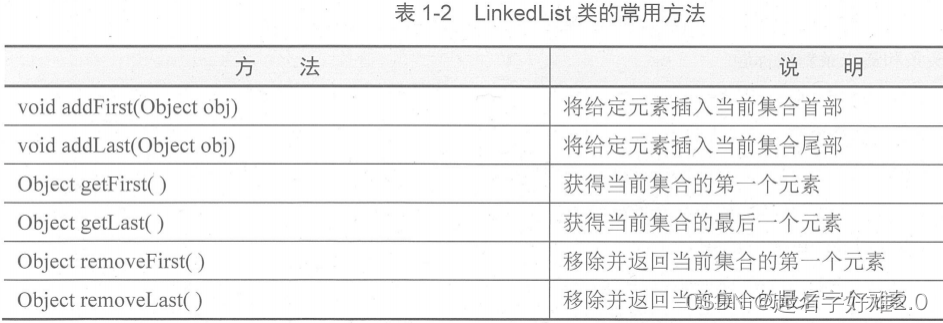

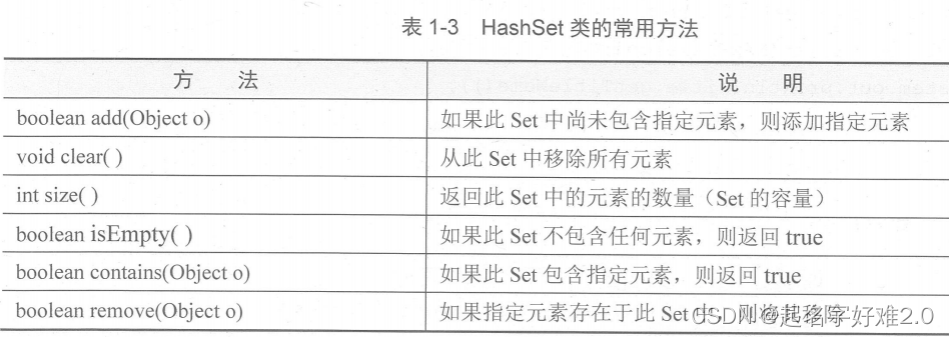
?四、set:无序&唯一?
①它的查找效率更高
?注:set没有get方法
?五、Iterator:对集合进行迭代遍历
(1)使用iterator()方法获取Iterator对象:Iteratoriterator=****.iterator();(2)hasNext():判断是否存在下一个可迭代的元素,有则返回true;(3)next():获取要访问的下一个元素;
六、Map:
①存储K键-V值组合;②K键是一个set集合,不要求有序,不可重复;③value不要求序但可重复;Map<String,List<String>>map=newHashMap<>();//复合结构,可存放如某人的通话记录类的数据。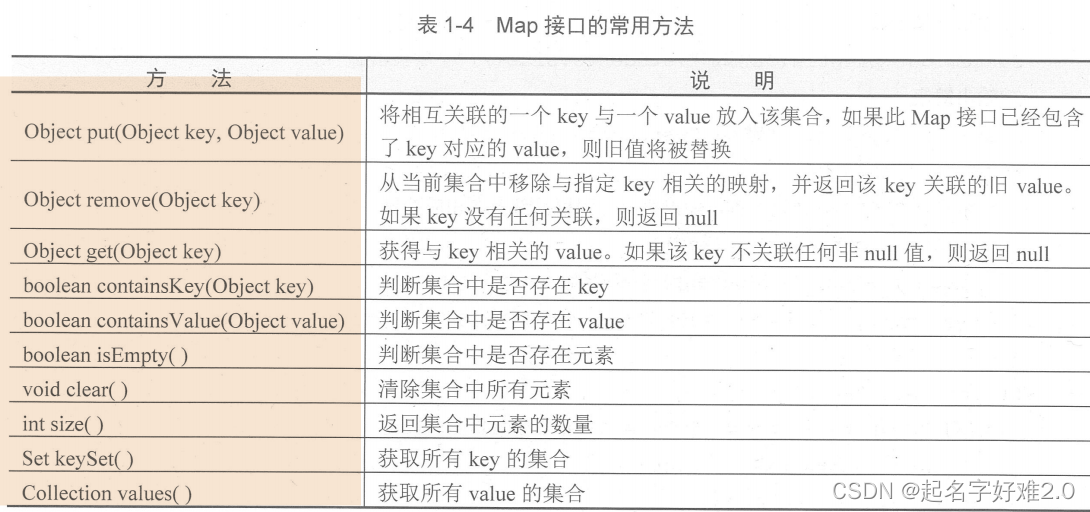
七.Collections?类
(1)排序: //comparable:可比较的若要对一个类的对象进行排序,要先让这个类实现comparable接口,再调用方法:intcomparaTo(Objecto):this>o?返回1;this<o返回-1;this==o返回0;然后通过collections.sort()方法进行排序。(2)替换:全部替换成同一元素?collections.fill(); // fill:装满,填充;(3)最大最小值:max();min()(4)查找:binarySearch();
Collections类:?
一、Collections类,类似于Arrays类,其中提供了很多用于操作集合的、静态的方法。 二、如果要实现一个类的对象之间比较大小,则该类必须要实现Comparable接口,并根据需要重写其中的compareTo()方法。用来比较两个对象,如果o1小于o2,返回负数;等于o2,返回0;大于o2返回正数? ? ? ? ? ? ? ?intcompare(To1,To2);
二、如果要实现一个类的对象之间比较大小,则该类必须要实现Comparable接口,并根据需要重写其中的compareTo()方法。用来比较两个对象,如果o1小于o2,返回负数;等于o2,返回0;大于o2返回正数? ? ? ? ? ? ? ?intcompare(To1,To2);
泛型:
泛型:所谓“泛型”,就是“宽泛的数据类型”,任意的数据类型。它的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数,使代码可以应用于多种类型。即:将对象的类型作为参数,指定到其他类或者方法上,从而保证类型转换的安全性和稳定性,这就是泛型。类型参数必须是一个合法的标识符,习惯上使用单个大写字母,通常情况下,K 表示键,V 表示值,E 表示异常或错误,T 表示一般意义上的数据类型。注意:1.泛型参数只能使用引用类型变量来充当,不能使用基本数据类型2.集合中,如果没使用泛型,则默认为Object类型3.如果集合中使用泛型,则集合的相关属性、方法中,凡是使用到类或接口泛型参数的地方,都调整为具体的泛型类型。
数组与集合的异同
数组和集合的主要区别包括以下几个方面:1. 数组可以存储基本数据类型和对象,集合只能存储对象(可以以包装类的形式存储基本数据类型);2. 数组的长度固定,而集合的长度是可变的;3. 定义数组时必须指定数组元素类型,集合则是默认其中的所有元素类型都是Object;4. 无法直接获取数组中实际存储的元素个数,但集合可以通过size()方法直接获取集合中实际存储的元素个数;5. 数组只采用分配连续空间的方式存储数据,而集合有多种实现方式和不同的适用场合;6. 集合以接口和类的形式存在,具有封闭、继承、多态等类的特性,通过简单的方法和属性调用即可实现各种复杂操作,大大提高了开发效率;7. JDK中有一个Arrays类,专门用来操作数组,它提供一系列静态方法实现以数组的搜索、排序、比较、填充等操作;8. JDK中也有一个Collection类,专门用来操作集合,它也提供了一系列的静态方法实现对集合的搜索、复制、排序、线程安全化等操作。
ArrayList其它方法
?
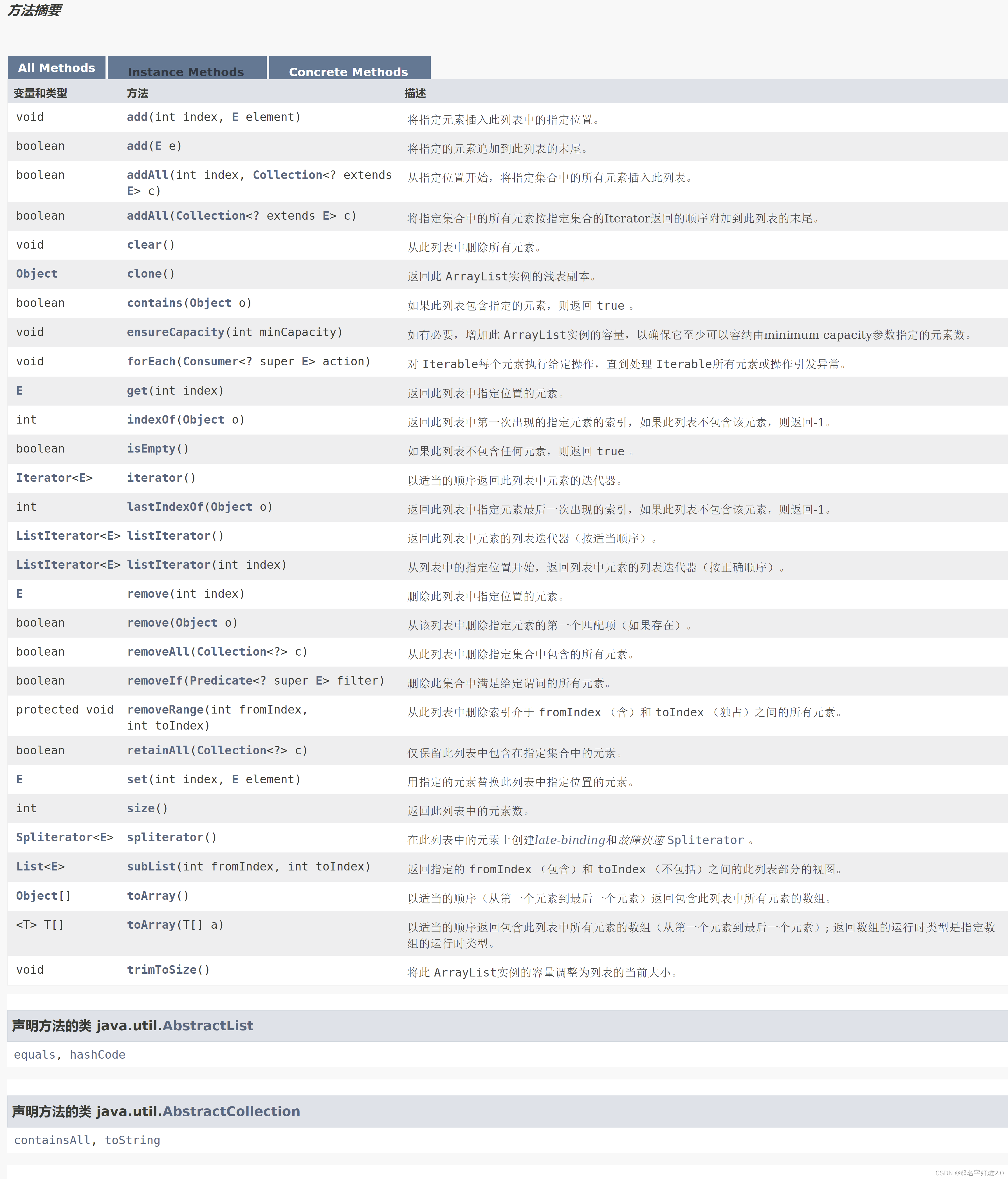
ArrayList和LinkedList有什么区别??
ArrayList和LinkedList有什么区别?相同点:都实现了List接口非线程安全的集合中的元素都是有序的不同点:1. 底层数据结构ArrayList 底层采用数组来存储元素的。LinkedList 底层采用双向链表来存储元素的。2. add(E e):尾部添加元素ArrayList 内部是采用数组结构,若数组的容量足够大的时候,向尾部追加元素是相当快的,只需数组[size+1] = e;即可,但是当数组满的时候,需要对数组进行扩容,会生成一个新的数组,新的数组大小为原数组大小的1.5倍,然后将老的数据复制到新的数组中,这个需要一定的时间,如果扩容之后只新增了一个元素,此时可能会造成一些空间的浪费。而LinkedList内部采用双向链表的结构存放数据,所以追加元素的时候,只需要将最后一个元素next指针指向新的元素就可以了,非常的快。结论:add(E e)向尾部追加元素LinkedList更快一些。3. add(int index, E element):指定的位置插入元素ArrayList:index位置插入元素的时候,需要将index位置后面的元素后移,若数组已满,涉及到数组的扩容和复制,相对来说效率不是特别的高。LinkedList:需沿着链表找到index位置的元素,然后改变一下指针的指向就可以了,主要耗时在index位置的查找上。结论:add(int index, E element)他们的效率差不多。4. get(int index):获取指定位置的元素ArrayList内部通过数组定义,非常快。而LinkedList内部需要沿着链表查找,会慢一些,看一下LinkedList 的get(index)源码public E get(int index) { return node(index).item; }Node<E> node(int index) { //判断index是否位于集合的前半部分,如果在前半部分,从头向后找,如果在后半部分, 从最后向前找 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }结论:get(index)随机访问ArrayList更快。5. remove(int index):随机删除指定位置元素ArrayList:涉及到数组内元素的移动,将index位置后面的元素向前移动。LinkedList:先找到指定位置的元素,然后调整一下指针的指向就可以了。结论:remove(index)随机删除指定位置元素LinkedList更快。6. remove(Object o):删除指定的元素ArrayList:先按顺序找到这个元素的位置,然后将位置后面的所有元素前移,内部涉及到数组元素的移动。LinkedList:先按顺序找到这个元素的位置,然后调整一下指针的指向就可以了,更快一些。结论:remove(o) LinkedList更快。7. int indexOf(Object o):获取元素的位置ArrayList:按序遍历查找。LinkedList:按序遍历查找。结论:2则都需要遍历,效率差不多。8. set(int index, E element):替换指定位置的元素ArrayList:数组[index] = elelement 就可以了,非常的快。LinkedList:需要先找到inde位置的元素,然后调整一下指针的指向。结论:替换元素ArrayList更快。 使用场景根据它们的优缺点,可以知道,ArrayList适用于频繁查询和获取数据;而LinkedList适合频繁地增加或删除数据的场景。总结大家已经注意到了,这道题目主要考察的是2个集合内部的数据结构,一个是数组,一个是双向链表,2种数据结构的特点搞清楚了,那么问题就很容易了。数组通过下标访问元素是非常快的,但是插入或者删除元素会涉及到后面元素的移动,所以效率会慢一些。而链表中插入和删除只需要调整一下指针的指向就行了,所以非常快
?集合的容量
1、List 元素是有序的、可重复ArrayList、Vector默认初始容量为10ArrayList :线程不安全,查询速度快底层数据结构是数组结构扩容增量:原容量的 0.5倍+1个如 ArrayList的容量为10,一次扩容后是容量为15+1=16LlinkedList:是一个双向链表,没有初始化大小,也没有扩容的机制,就是一直在前面或者后面新增就好。Vector :线程安全,但速度慢底层数据结构是数组结构加载因子为1:即当元素个数超过容量长度时,进行扩容扩容增量:原容量的 1倍如 Vector的容量为10,一次扩容后是容量为202、Set(集) 元素无序的、不可重复HashSet :线程不安全,存取速度快底层实现是一个HashMap(保存数据),实现Set接口默认初始容量为16(为何是16,见下方对HashMap的描述)加载因子为0.75:即当元素个数超过容量长度的0.75倍时,进行扩容扩容增量:原容量的 1 倍如 HashSet的容量为16,一次扩容后是容量为323、Map是一个双列集合HashMap:默认初始容量为16 (为何是16:16==2^4,可以提高查询效率)加载因子为0.75:即当元素个数超过容量长度的0.75倍时,进行扩容扩容增量:原容量的 1 倍如 HashSet的容量为16,一次扩容后是容量为324、一个问题:ArrayList list = new ArrayList(20);中的list扩充几次?答:0次。解析: ArrayList list=new ArrayList(); 这种是默认创建大小为10的数组,每次扩容大小为1.5倍。ArrayList list=new ArrayList(20); 这种是指定数组大小的创建,没有扩充。

