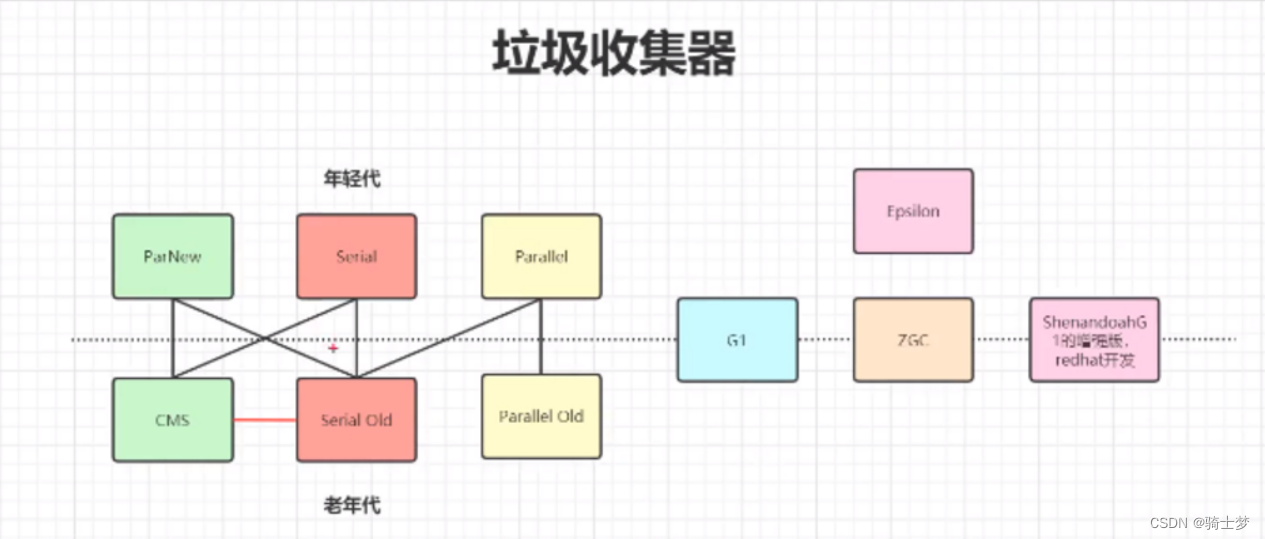
һ�������ռ��㷨
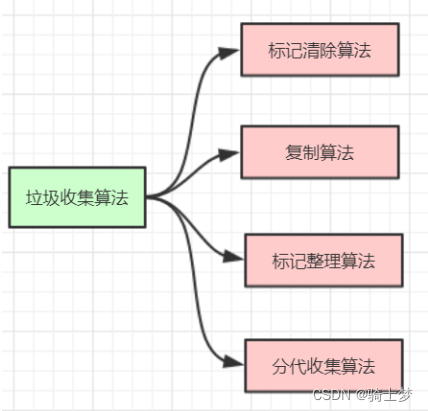
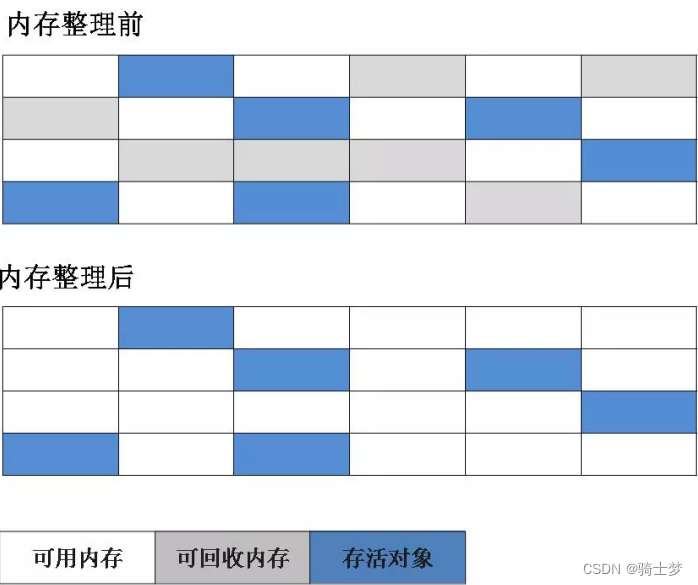
1. ���-����㷨
- �㷨��Ϊ ����ǡ� �� "����� �Ρ�
- ���ȱ�dz�������Ҫ���յĶ���
- �ڱ����ɺ�,ͳһ�������б���ǵĶ���
- ������������ռ��㷨,Ч��Ҳ�ܸ���
- ���ǻ�����������Ե�����:Ч�����⡢�ռ�����(��������������������������Ƭ)��
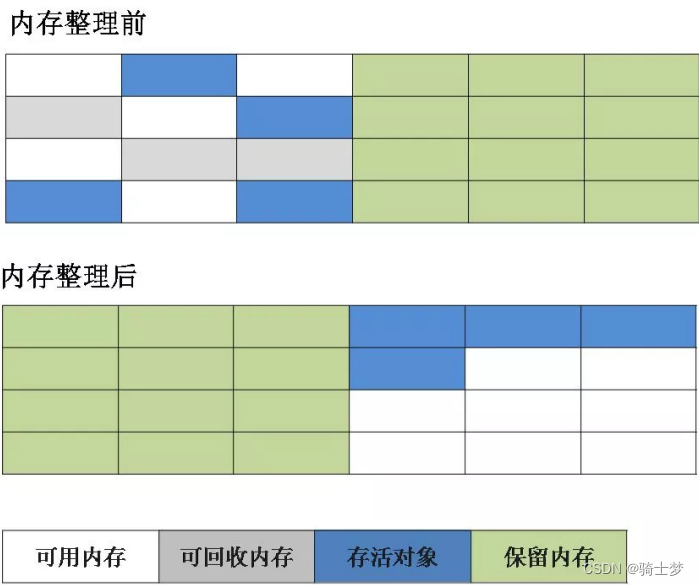
2. �����㷨
- Ϊ�˽��Ч������,�����ơ� �ռ��㷨�����ˡ�
- �����Խ��ڴ��Ϊ��С��ͬ������,ÿ��ʹ�����е�һ�顣
- ����һ����ڴ�ʹ�����,�ͽ������Ķ����Ƶ���һ��ȥ��
- Ȼ���ٰ�ʹ�õĿռ�һ����������
- ������ʹÿ�ε��ڴ����,���Ƕ��ڴ������һ����л�����
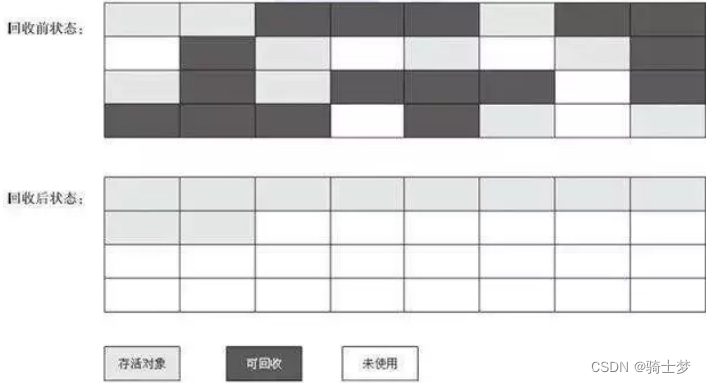
3. ���-�����㷨
- ������������ص��س���һ�ֱ���㷨,��ǹ�����Ȼ�� �����-����� �㷨һ����
- ����������,����ֱ�ӶԿɻ��ն�����ա�
- ���������д��Ķ�����һ���ƶ�,Ȼ��ֱ���������˱߽�������ڴ档
4. �ִ��ռ��㷨
- ��ǰ����� �� �����ռ� ������ �ִ��ռ��㷨��
- �����㷨û��ʲô�µ�˼��,ֻ�Ǹ��� ���������� �IJ�ͬ���ڴ��Ϊ���顣
- һ�㽫 Java �ѷ�Ϊ ������ �� �������
- �������ǾͿ��Ը��ݸ���������ص�,ѡ����ʵ������ռ��㷨��
- ����:����������,ÿ���ռ������д�������(�� 99%)��ȥ��
���Կ���ѡ�� �����㷨,ֻ��Ҫ������������ĸ��Ƴɱ��Ϳ������ÿ�������ռ��� - ��������Ķ�������DZȽϸߵ�,����û�ж���Ŀռ�������з��䵣����
�������DZ���ѡ�� �����-����� �� �����-������ �㷨���������ռ��� - ע��,�����-����� �� �����-������ �㷨��� �����㷨 ��
10 ��������
���������ռ���
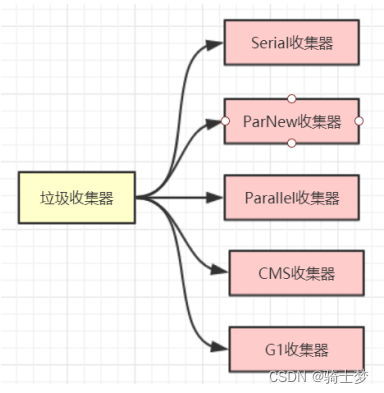
- ���˵�ռ��㷨���ڴ���յķ�����,��ô�����ռ��������ڴ���յľ���ʵ����
- ��Ȼ���ǶԸ����ռ������бȽ�,������Ϊ����ѡ��һ����õ��ռ�����
- ��Ϊֱ������Ϊֹ��û����õ������ռ�������,����û�����ܵ������ռ�����
- ���������ľ��Ǹ��ݾ���Ӧ�ó���,ѡ���ʺ��Լ��������ռ�����
- �����һ���ĺ�֮�ڡ��κγ����¶����õ������ռ������ڡ�
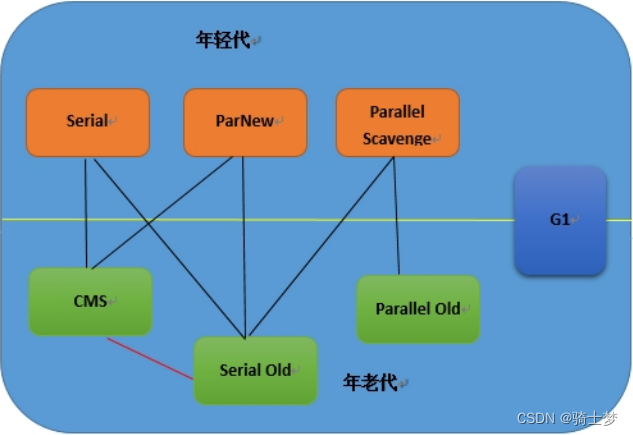
��ô���ǵ� Java �����,�Ͳ���ʵ����ô�ͬ�������ռ����ˡ�
1. Serial �ռ���
Serial(����)�ռ��������������ʷ���ƾõ������ռ����ˡ�- ����ռ�����һ�����߳��ռ����ˡ�
- ���� �����̡߳� ������,��������ζ����ֻ��ʹ��һ�������ռ��߳�ȥ��������ռ�������
- ����Ҫ�������ڽ��������ռ�������ʱ��,������ͣ�������еĹ����߳�(
Stop The World),ֱ�����ռ�������
- �������������ǵ�Ȼ֪��(
Stop The World)�����IJ����û����顣
�����ں����������ռ��������,ͣ��ʱ���ڲ�������(��Ȼ����ͣ��,Ѱ��������������ռ����Ĺ�����Ȼ�ڼ���)��
-XX:+UseSerialGC
-XX:+UseSerialOldGC
- ���������� �����㷨,��������� ���-�����㷨��
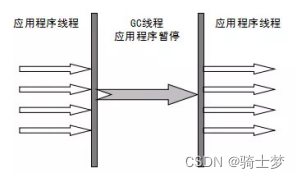 Serial �ռ����������������ռ����ĵط�:����Ч(�������ռ����ĵ��߳����)��
Serial �ռ�������û���߳̽����Ŀ���,��Ȼ���Ի�úܸߵĵ��߳��ռ�Ч�ʡ�Serial Old �ռ����� Serial �ռ�����������汾,��ͬ����һ�����߳��ռ�����
Serial �ռ���,��Ҫ��������;:
- һ����;���� JDK-1.5 �Լ���ǰ�İ汾��,��
Parallel Scavenge �ռ�������ʹ�á� - ��һ����;����Ϊ
CMS �ռ����ĺ�����
2. ParNew �ռ���
ParNew �ռ�����ʵ���� Serial �ռ����� ���߳� �汾��
- ����ʹ�ö��߳̽��������ռ���,������Ϊ(���Ʋ������ռ��㷨�����ղ��Եȵ�)��
Serial �ռ�����ȫһ���� - Ĭ�ϵ��ռ� �߳��� �� CPU ������ͬ,��ȻҲ�����ò���(
-XX:ParallelGCThreads)ָ���ռ��߳���,����һ�㲻�Ƽ��ġ�
-XX:+UseParNewGC
- ���������� �����㷨,��������� ���-�����㷨��
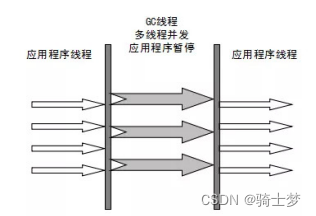 - ��������������
Server ģʽ�µ����������Ҫѡ�� - ����
Serial �ռ�����,ֻ�������� CMS �ռ���(���������ϵIJ����ռ���)��Ϲ�����
3. Parallel Scavenge �ռ���
Parallel Scavenge �ռ��������� ParNew �ռ�����Parallel Scavenge �� Server ģʽ(�ڴ���� 2G,2��CPU)�µ�Ĭ���ռ�����
Parallel Scavenge �ռ�����ע����������(��Ч�ʵ����� CPU)��
��ν���������� CPU �����������û������ʱ�� �� CPU ������ʱ��ı�ֵ��CMS �������ռ����Ĺ�ע��,��������û��̵߳�ͣ��ʱ��(����û�����)��
Parallel Scavenge �ռ����ṩ�˺ܶ����,���û��ҵ�����ʵ�ͣ��ʱ��������������
��������ռ���������̫�˽�Ļ�,����ѡ����ڴ�����Ż�,���������ȥ���Ҳ��һ��������ѡ��
-XX:+UseParallelGC
-XX:+UseParallelOldGC
- ���������� �����㷨,��������� ���-�����㷨��
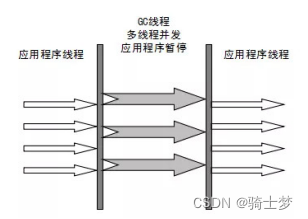 Parallel Old �ռ����� Parallel Scavenge �ռ�����������汾,ʹ�ö��̺߳� �����-������ �㷨��- ��ע���������Լ� CPU ��Դ�ij���,���������ȿ���
Parallel Scavenge �ռ����� Parallel Old �ռ�����
4. CMS �ռ���
CMS(Concurrent Mark Sweep)�ռ���,��һ���Ի�ȡ��̻���ͣ��ʱ��ΪĿ����ռ�����
- ���dz�������ע���û������Ӧ����ʹ�á�
- ����
HotSpot �������һ�����������ϵ� �����ռ����� - ����һ��ʵ�����������ռ��߳� �� �û��߳�(������)ͬʱ������
-XX:+UseConcMarkSweepGC
- �������е�
Mark Sweep �������ʿ��Կ���,CMS �ռ�����һ�� �����-����� �㷨ʵ�ֵġ�
�����������������ǰ�漸�������ռ�����˵���Ӹ���һЩ��
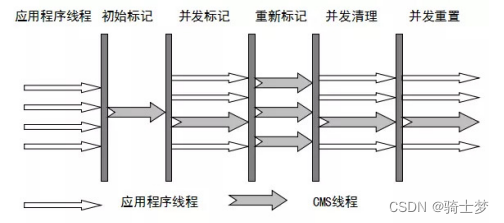 - �������̷�Ϊ�ĸ����衣
- ��ʼ���: ��ͣ���е������߳�,����¼��
GCRoots ֱ�������õĶ���,�ٶȺܿ졣 - �������: ͬʱ����
GC �� �û��߳�,��һ���հ��ṹȥ��¼�ɴ����
- ��������ν���,����հ��ṹ�����ܱ�֤������ǰ���еĿɴ����
- ��Ϊ�û��߳̿��ܻ�ϵĸ���������,����
GC �߳�����֤�ɴ��Է�����ʵʱ�ԡ� - ��������㷨�����ټ�¼��Щ�������ø��µĵط���
- ���±��: ���±�ǽξ���Ϊ��������������ڼ�,��Ϊ�û������������,�����±�Dz����䶯����һ���ֶ���ı�Ǽ�¼��
����ε�ͣ��ʱ��,һ���� ��ʼ��� �ε�ʱ���Գ�,ԶԶ�� ������� ��ʱ��̡� - ��������: ���� �û��߳�,ͬʱ
GC �߳� ��ʼ��δ��ǵ���������ɨ��
4.1 CMS ��ȱ��
- �����ռ���
- ��ͣ����
- �� CPU ��Դ����(��ͷ�������Դ)��
- ������ ��������(�ڲ����������ֲ�������,���ָ�������ֻ�ܵȵ���һ��
GC ��������)�� - ��ʹ�õĻ����㷨 �����-����� �㷨,�ᵼ���ռ�����ʱ���д����ռ���Ƭ������
��Ȼͨ������(-XX:+UseCMSCompactAtFullCollection)������ JVM ��ִ��������������������� - ִ�й����еIJ�ȷ����,�������һ���������ջ�ûִ����,Ȼ�����������ֱ������������
- �ر����� ������� �� �������� �λ����,һ����,ϵͳһ�����С�
- Ҳ��û��������ٴδ���
FullGC,Ҳ����(��Concurrent Mode Failure��)�� - ��ʱ�����(Stop The World),��
Serial old �����ռ�����������
4.2 CMS ��ز���
-XX:+UseConcMarkSweepGC
-XX:ConcGCThreads
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction
-XX:CMSInitiatingOccupancyFraction
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+CMSScavengeBeforeRemark
5. G1 �ռ���
G1(Garbage-First)��һ������������������ռ�����
- ��Ҫ����䱸 ��Ŵ����� �� �������ڴ� �Ļ�����
- �Լ��߸�������
GC ͣ��ʱ�� Ҫ���ͬʱ,���߱� �������� ����������
-XX:+UseG1GC
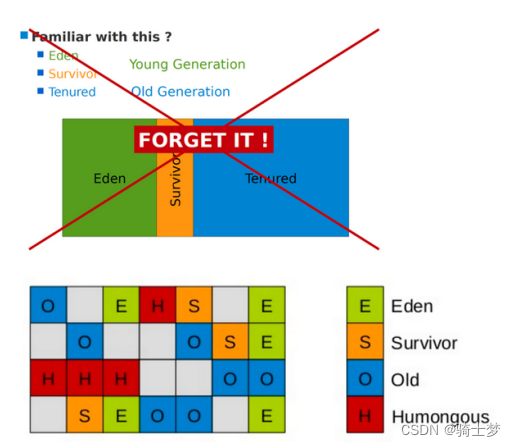
G1 �� Java �ѻ���Ϊ�����С��ȵĶ�������(Region,JVM �������� 2048 �� Region)��- һ�� Region ��С ���� �Ѵ�С ���� 2048(����:�Ѵ�СΪ 4096M,�� Region ��СΪ 2M)��
��ȻҲ�����ò���(-XX:G1HeapRegionSize)�ֶ�ָ�� Region ��С,�����Ƽ�Ĭ�ϵļ��㷽ʽ�� G1 ������ ����� �� ����� �ĸ���,������������������,���Ƕ���(���Բ�����)Region �ļ��ϡ�
5.1 G1 �����������
- Ĭ�� ����� �� ���ڴ� ��ռ����
5%(����Ѵ�СΪ 4096M,��ô ����� ռ�� 200MB ���ҵ��ڴ�)��
- ��Ӧ����� 100 �� Region,����ͨ��(
-XX:G1NewSizePercent)���� ������ ��ʼռ�ȡ� - ��ϵͳ������,JVM �ͣ�ĸ� ����� ���Ӹ���� Region��
- ������� ������ ��ռ�Ȳ��ᳬ��
60%,����ͨ��(-XX:G1MaxNewSizePercent)������
- ����� �е�
Eden �� Survivor ��Ӧ�� Region Ҳ��֮ǰһ��(Ĭ��:8:1:1)��
- ���� ����� ������ 1000 �� Region,Eden ����Ӧ 800 ��,S0 ��Ӧ 100��,S1 ��Ӧ 100 ����
- һ�� Region ����֮ǰ�� �����,��� Region ��������������,֮������ֻ��� �������
Ҳ����˵ Region �������ܿ��ܻᶯ̬�仯��
5.2 G1 ��������� Humongous ��
G1 �����ռ���,���ڶ���ʲôʱ���ת�Ƶ� ����� ��֮ǰ��ԭ��һ����
- Ψһ��ͬ���Ƕ� ����� �Ĵ���,
G1 ��ר�ŷ�������� Region �� Humongous ���� - �������ô����ֱ�ӽ��� ����� �� Region �С�
- ��
G1 �д������ж�����,����һ�� ����� ������һ�� Region ��С�� 50%��
- ����:�����������,ÿ�� Region �� 2M,ֻҪһ��������� 1M,�ͻᱻ���� Humongous �С�
- ����һ����������̫��,���ܻ����� Region ����š�
Humongous ��ר�Ŵ�Ŷ��ھ��Ͷ���,����ֱ�ӽ��������
���Խ�Լ������Ŀռ�,������Ϊ������ռ䲻���� GC ������
FullGC ��ʱ��,�����ռ� ����� �� ����� ֮��,Ҳ�Ὣ Humongous ��һ�����ա�
5.3 G1 �ռ�����
G1 �ռ���һ��,GC ���������̴��·�Ϊ���¼������衣
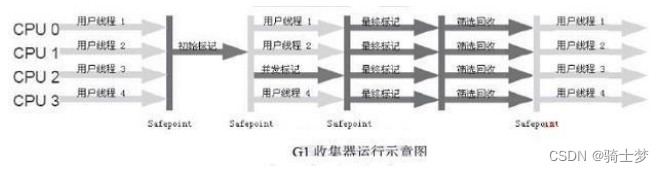
- ��ʼ���(Initial mark,STW):��ͣ���е������߳�,����¼��
GCRoots ֱ�������õĶ���,�ٶȺܿ졣 - �������(Concurrent Marking):ͬ
CMS �IJ�����ǡ� - ���ձ��(Remark,STW):ͬ
CMS �����±�ǡ� - ɸѡ����(Cleanup,STW):
- ɸѡ���ս�,���ȶԸ��� Region �� ���ռ�ֵ �� �ɱ� ����������
���� �û� �������� GC ͣ��ʱ��(������ JVM ���� -XX:MaxGCPauseMillis ����)���ƶ����ռƻ��� - ����˵ ����� ��ʱ�� 1000 �� Region �����ˡ�
������Ϊ���� Ԥ��ͣ��ʱ��,������������ֻ��ͣ�� 200 ���롣 - ��ôͨ��֮ǰ ���ճɱ� �����֪,���ܻ������� 800 �� Region �պ���Ҫ 200ms��
��ô��ֻ����� 800 �� Region,������ GC ���µ� ͣ��ʱ�� ����������ָ���ķ�Χ�ڡ� - �����,��ʵҲ���������� �û����� һ��ִ�С�
������Ϊֻ����һ���� Region,ʱ�����û��ɿ��Ƶ�,���� ͣ���û��߳� ���������ռ�Ч���� - ������ ����� ���� �����,�����㷨��Ҫ�õ��� �����㷨��
��һ�� Region �еĴ�����,���Ƶ���һ�� Region �С� - ���ֲ�����
CMS ����������,��Ϊ�кܶ� �ڴ���Ƭ ����Ҫ����һ�Ρ�
G1 ���� �����㷨 ����,����������̫���ڴ���Ƭ��
G1 �ռ����ں�̨ά����һ�������б���
- ÿ�θ����������ռ�ʱ��,����ѡ����ռ�ֵ���� Region(��Ҳ������������
Garbage-First ������)�� - ����һ�� Region �� 200ms �ܻ��� 10M ����,����һ�� Region �� 50ms �ܻ��� 20M ����,�ڻ���ʱ�����������,
G1 ��Ȼ������ѡ�������� Region ���ա� - ����ʹ�� Region �����ڴ�ռ�,�Լ������ȼ���������շ�ʽ,��֤��
G1 �ռ���������ʱ���ڿ��Ծ����ܸߵ��ռ�Ч�ʡ�
5.4 G1 �ص�
G1 ����Ϊ JDK-1.7 ���ϰ汾,Java �������һ����Ҫ����������G1 �߱������ص�:
- �����벢��:
G1 �ܳ������ CPU����˻����µ�Ӳ�����ơ�
- ʹ�ö�� CPU(CPU ���� CPU����)������(Stop-The-World)ͣ��ʱ�䡣
- ���������ռ���,ԭ����Ҫͣ�� Java �߳� ��ִ�� GC ������
- G1 �ռ���,��Ȼ����ͨ�� �����ķ�ʽ �� Java �������ִ�С�
- �ִ��ռ�:��Ȼ
G1 ���Բ���Ҫ�����ռ������,���ܶ����������� GC ��,���ǻ��DZ����˷ִ��ĸ�� - �ռ�����:��
CMS �� ����ǨC������ �㷨��ͬ��
G1 �����������ǻ��� �����-������ �㷨ʵ�ֵ��ռ�����- �Ӿֲ��������ǻ��� �����ơ�* �㷨ʵ�ֵġ�
- ��Ԥ���ͣ��:����
G1 ����� CMS ����һ�������ơ�
- ����ͣ��ʱ����
G1 �� CMS ��ͬ�Ĺ�ע�㡣 - ��
G1 �������ͣ����,���ܽ�����Ԥ���ͣ��ʱ��ģ�͡� - ����ʹ������ȷָ����һ������Ϊ M ���� ��ʱ��Ƭ��(ͨ������
-XX:MaxGCPauseMillis ָ��)����������ռ���
5.5 G1 ��ز���
-XX:+UseG1GC
-XX:ParallelGCThreads
-XX:G1HeapRegionSize
-XX:MaxGCPauseMillis
-XX:G1NewSizePercent
-XX:G1MaxNewSizePercent
-XX:TargetSurvivorRatio
-XX:MaxTenuringThreshold
-XX:InitiatingHeapOccupancyPercent
-XX:G1HeapWastePercent
-XX:G1MixedGCLiveThresholdPercent
-XX:G1MixedGCCountTarget
5.6 G1 �����ռ�����
- YoungGC ������˵���е� Eden �������˾ͻ����ϴ���,����
G1 ����������� Eden �����մ��Ҫ���ʱ�䡣 - �������ʱ��ԶԶС�ڲ���(
-XX:MaxGCPauseMills)�趨��ֵ��
��ô����������� Region,�������¶�����,���������� YoungGC�� - ֱ����һ�� Eden ������,
G1 �������ʱ��ӽ�����(-XX:MaxGCPauseMills)�趨��ֵ,��ô�ͻᴥ�� YoungGC��
MixedGC:���� FullGC,������Ķ�ռ���ʴﵽ����(-XX:InitiatingHeapOccupancyPercen)�趨��ֵ����
- �������е� Young �Ͳ��� Old(���������� GC ͣ��ʱ��,ȷ�� Old �������ռ�������˳��)�Լ����������
- �������
G1 �������ռ������� MixedGC,��Ҫʹ�� �����㷨�� - ��Ҫ�Ѹ��� Region �д��Ķ�������� Region ��ȥ��
����������,�������û���㹻�Ŀ� Region �ܹ����ؿ�������,�ͻᴥ��һ�� FullGC��
FullGC:ֹͣϵͳ����,Ȼ����õ��߳̽��� ��ǡ�������ѹ��������
�ÿ��г���һ�� Region ������һ�� MixedGC ʹ��,��������Ƿdz���ʱ�ġ�
5.7 G1 �����ռ����Ż�����
- �������(
-XX:MaxGCPauseMills)���õ�ֵ�ܴ�,����ϵͳ���кܾá�
��������ܶ�ռ���˶��ڴ�� 60% ��,��ʱ�Ŵ�������� GC�� - ��ô��������Ķ�����ܾͻ�ܶ�,��ʱ�ͻᵼ��
Survivor ����Ų�����ô��Ķ���,�ͻ����������С� - ����������� GC ����,��������Ķ������,���½���
Survivor ������˶�̬�����ж�����
�ﵽ�� Survivor ����� 50%,Ҳ����ٵ���һЩ�������������С� - ����������Ļ������ڵ���(
-XX:MaxGCPauseMills)���������ֵ��
- �ڱ�֤����� GC ��̫Ƶ����ͬʱ,���ÿ���ÿ�� GC ����Ĵ������ж��١�
- ���������̫����ٽ��������,Ƶ������
MixedGC��
5.8 ÿ�뼸ʮ��,�Ż� JVM
Kafka ���Ƶ�֧�Ÿ߲�����Ϣϵͳ��
- ���� Kafka ��˵,ÿ�봦�� ���� ���� ��ʮ�� ��Ϣʱ��������,һ����˵���� Kafka ��Ҫ�ô��ڴ������
- ����:64G,Ҳ����˵���Ը� ����� �����
30-40G ���ڴ�,����֧�Ÿ߲���������
- ������漰��һ��������,��ǰ��˵�Ķ��� Eden ���� YoungGC �Ǻܿ��,�������������ִ�л���ܿ���?
- ����Ȼ,������,��Ϊ�ڴ�̫��,��������Ҫ������ʱ���,����
30-40G �ڴ���տ������ҲҪ�����ӡ� - �� Kafka ���������,����
30-40G �� Eden ������Ҳ��һ�����Ӱɡ� - ��ô��ζ������ϵͳÿ����һ������,�ͻ���Ϊ YoungGC ���ټ�����û����������Ϣ,��Ȼ�Dz��еġ�
- ���ǿ���ʹ��
G1 �ռ���,����(-XX:MaxGCPauseMills Ϊ 50ms)�� - ���� 50ms �ܹ�����
30-40G �ڴ�,Ȼ�� 50ms �Ŀ�����ʵ��ȫ�ܹ����ܡ�
�û�������֪,��ô����ϵͳ�Ϳ����ڿ��ټ�����֪�������,һ�ߴ���ҵ��һ���ռ�������
G1 �������ʺ����� ���ڴ� ������ JVM ����,���ԱȽ������Ľ�� ���ڴ� ��������ʱ����������⡣
�������ѡ�������ռ���
- ���ȵ����ѵĴ�С,�÷������Լ���ѡ��
- ����ڴ�С�� 100 M,ʹ�� �����ռ�����
- ����ǵ���,����û�� ͣ��ʱ�� ��Ҫ��,���� �� JVM �Լ�ѡ����
- ������� ͣ��ʱ�� ���� 1 ��,ѡ�� ���� �� JVM �Լ�ѡ��
- ��� ��Ӧʱ�� ����Ҫ,���Ҳ��ܳ��� 1 ��,ʹ�� �����ռ�����
- ��ͼ�����ߵĿ��Դ���ʹ��,�ٷ��Ƽ�ʹ��
G1,��Ϊ���ܸߡ�
| 
