背景
今天在进行模拟服务联调测试时发现一个中间件的消费服务的延迟有不断增加的迹象,这个可不是好现象,由于这个中间件本身就是一个性能敏感的服务,延迟增加带来很大的问题。于是不得不放下手中的联调测试工作,优先解决这个问题。
打开中间件的源码,看到原来直接同步处理过程,额,这当然会造成延迟了,于是简单的啊加上了@Async异步化处理,然后消费者直接返回ack。但发现就算是这么改了这个延迟还是再累加,方法1失败。
于是怀疑是不是@Async默认的线程池参数不合理呢,于是自定义了线程池@Bean,然后再@Async(线程池的beanName),给到了32个线程也是一样的延迟累积,方法2失败。
难道是消费者的配置不合理于是增加消费者的并发参数,但是发现效果提升还是不合理。
现在可以肯定这个肯定是消费者本身太慢了造成的,于是回滚其他修改从消费者服务本身找原因。我简单翻了翻消费者代码,没有发现什么特殊的,就是一堆数据计算,当然循环是多了一点,但那也没办法。感觉不应该有太慢的地方。加了一下计时,好家伙短的几十ms,长的要200ms。
这肯定是不对劲,于是接下来的主要任务就是定位消费者服务中异常耗时的地方。
定位过程
说起来惭愧,一直没找到好的性能测试工具或是方法,这次基本是依靠手工计时定位的,但手工计时也是有不同方式。
当然大部分人可能还是用 long now = System.currentTimeMillis(); long cost = System.currentTimeMillis()-now的方式。但这种每次换个地方就要重新编译好麻烦,而且会添加很多没用的代码。
这次用的方法是在可以的 方法中第一行添加 long now = System.currentTimeMillis();,然后通过条件断点来打印耗时,总算是比上面那种方法有所进步。不用一个一个地方改了。
条件断点的添加方法就是,先添加一个正常的断点,如下图所示:
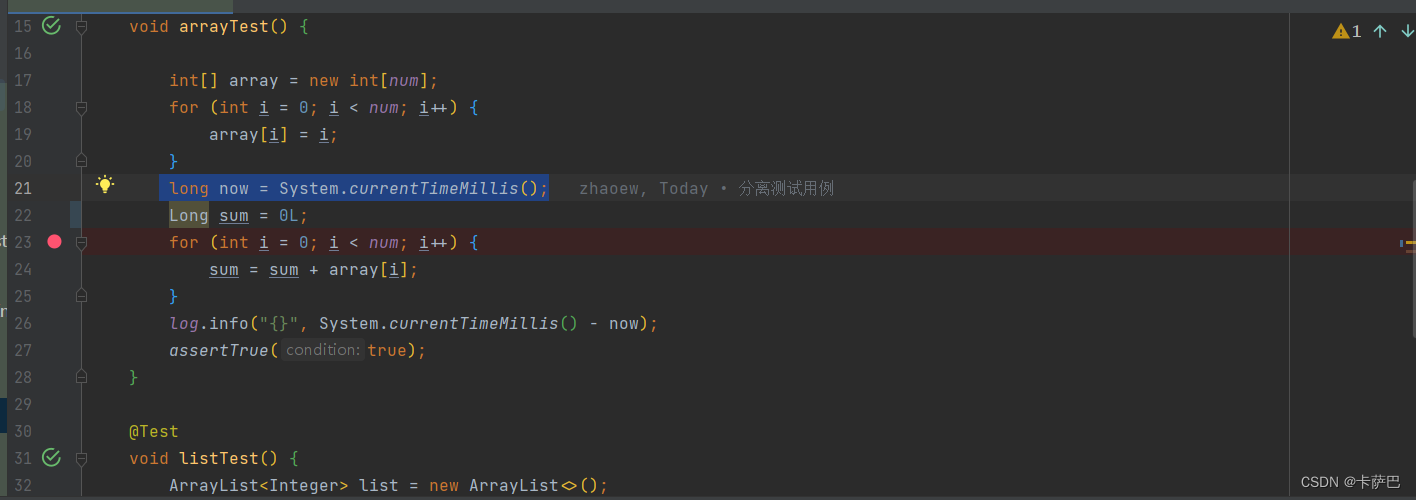
然后端点上右键,取消暂停(suspend),在Evalutea and log中添加log.info("cost {}",System.currentTimeMillis()-now)
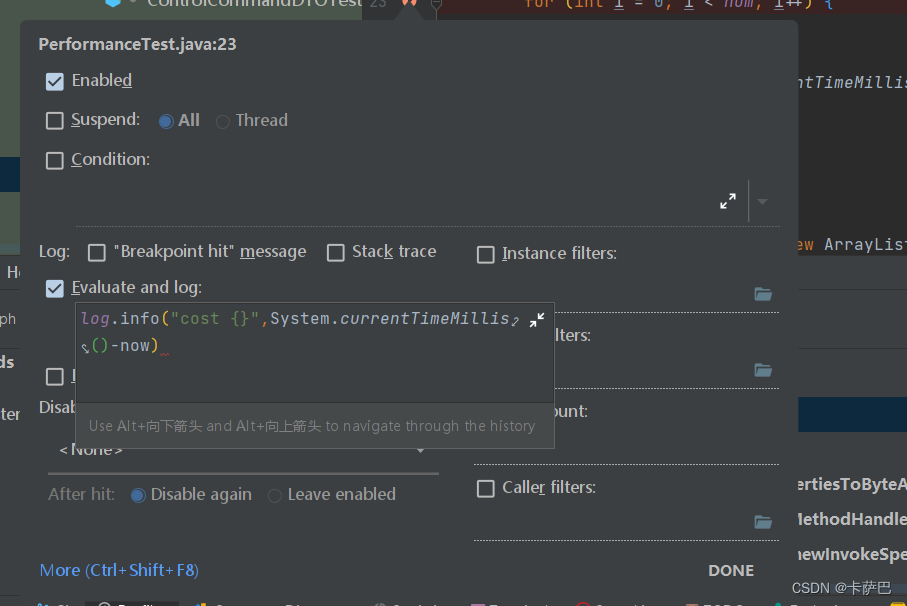
当然入口函数还是需要添加计时基准点的。
最后附录给大家介绍一个更好的IDEA下性能统计方式。
示意代码
这次就不把源码贴上来,而是换成示意代码,基本能反映问题。
@Slf4j
class PerformanceTest {
private static final int num = 1000;
@Test
void arrayTest() {
int[] array = new int[num];
for (int i = 0; i < num; i++) {
array[i] = i;
}
long now = System.currentTimeMillis();
long sum = 0;
for (int i = 0; i < num; i++) {
sum = sum + array[i];
}
log.info("{}", System.currentTimeMillis() - now);
assertTrue(true);
}
@Test
void listTest() {
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < num; i++) {
list.add(i);
}
long now = System.currentTimeMillis();
long sum = 0;
for (int i = 0; i < num; i++) {
sum = sum + list.get(i);
}
log.info("{}", System.currentTimeMillis() - now);
assertTrue(true);
}
}
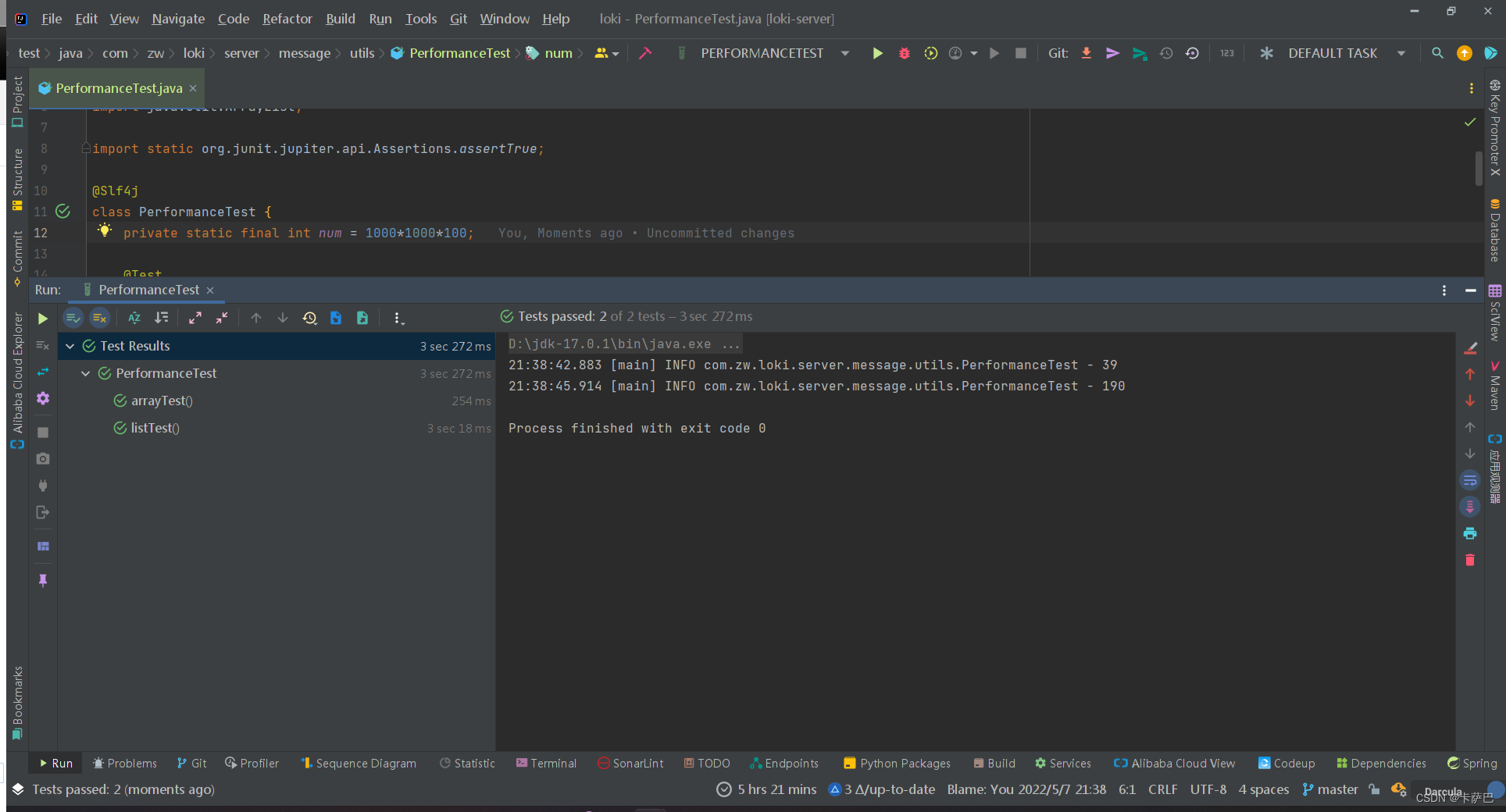
num=1000,没有区别
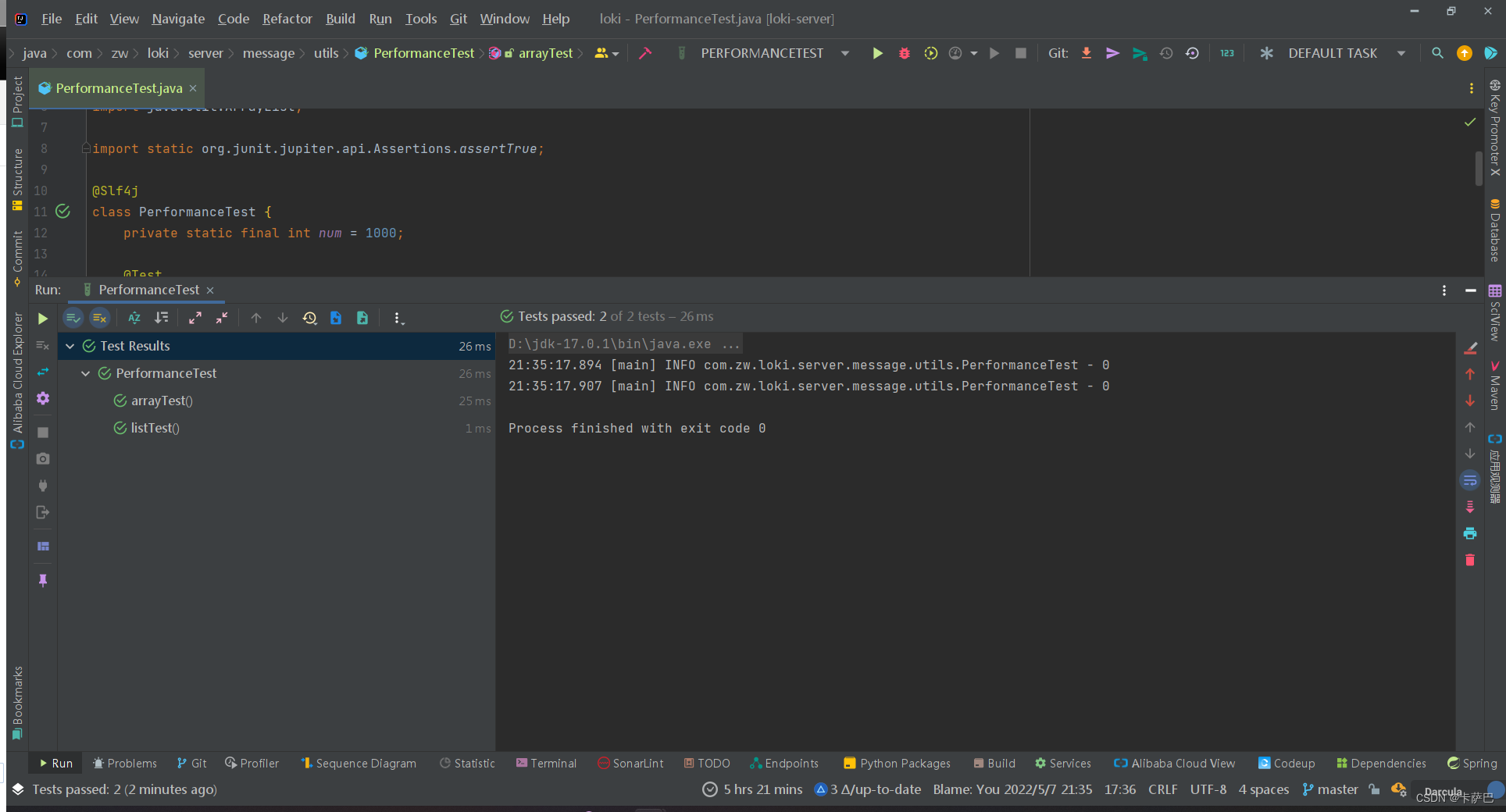
n=10001000,开始出现区别了
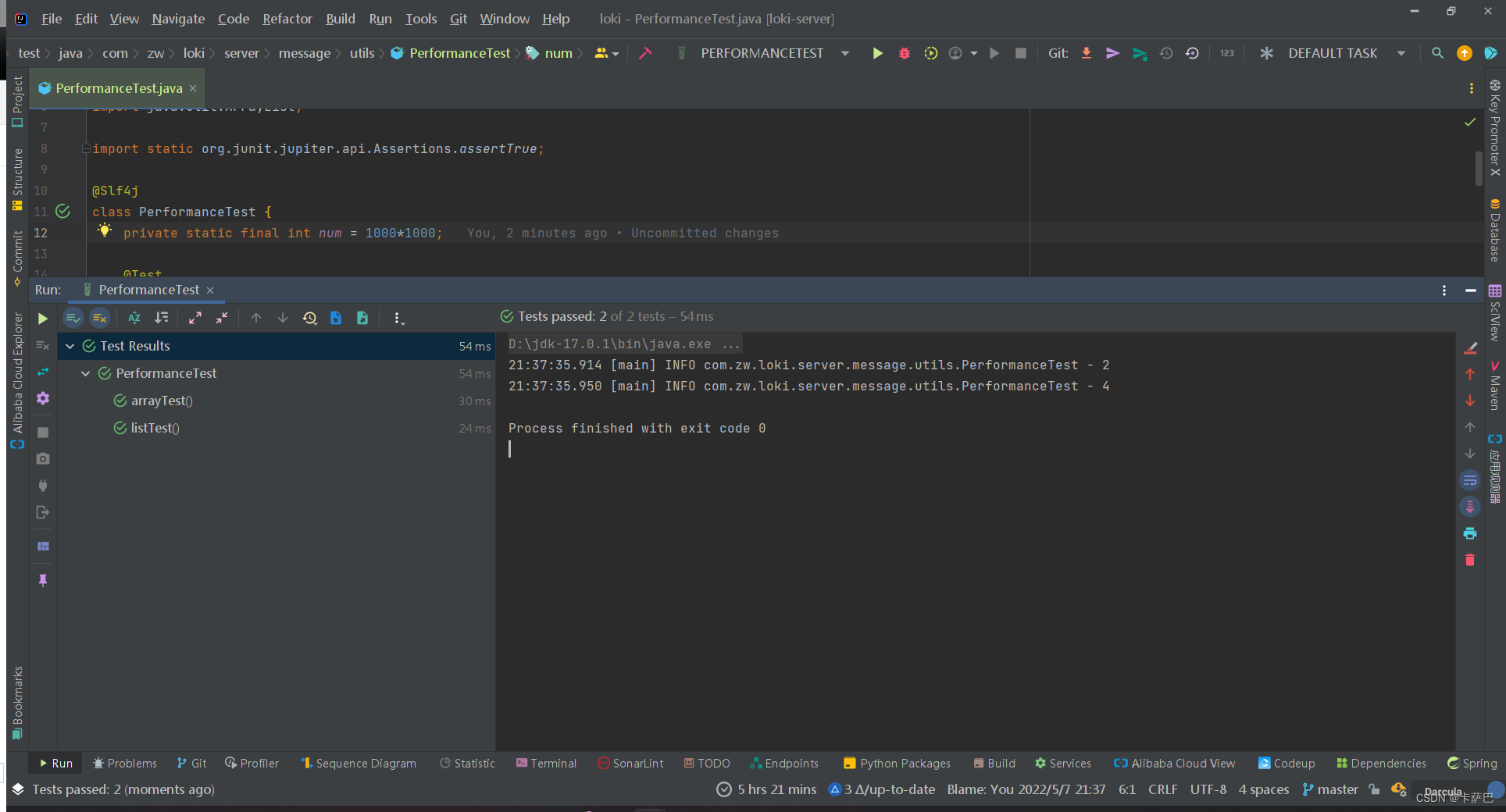
n=10001000*100,开始出现区别了,近4倍的差距
原因分析
推测1-数据结构
以为是ArrayList的数据结果在执行get时候跟原生数组取数据有差距,但查找源码后否定了这个想法,arrayList底层数据结构就是数组,如下图所示。
推测2-包装类到原始类型的转换
估计已经有眼见的同学看出来了,第一个方法中数组的数据类型为原生的int,而第二个的数据类型为包装类,于是在第二个方法中每次累加的时候都要将包装类转变为原生数据类型,再进行计算。于是计算量就比第一个方法高出不少。
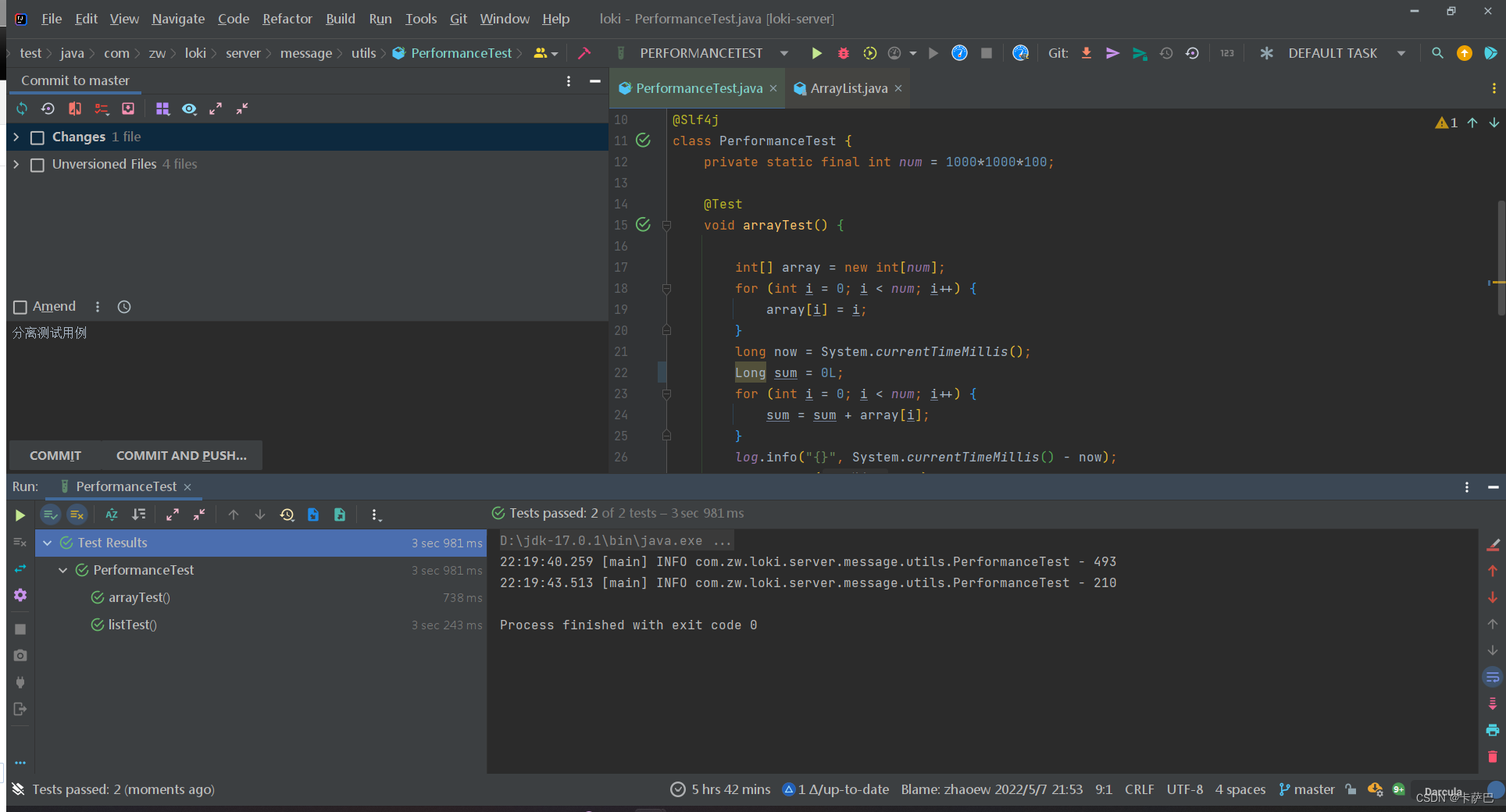
怎么验证我们的推测呢,我们就把第一个方法中的long sum=0;改为 Long sum =0L这样,结果如下:
果然第一个方法的耗时也变为几百毫秒了,直接高了一个数量级。
注意点
- 优化是一个枯燥的过程,尤其是定位,需要持之以恒不断探究真相
- 基线思维,比如一段普通的纯内存代码执行不太可能消耗毫秒级的时间
- 通过源码来寻找证据,通过实验来验证结论,实现【逻辑闭环】
- 不能止步于解决眼前问题,弄懂为什么更重要
附录
IDEA中性能测试的工具
Profile是IDEA自带的性能优化工具
启动方式很简单,就是测试或运行方式选择Profile方式,如下图
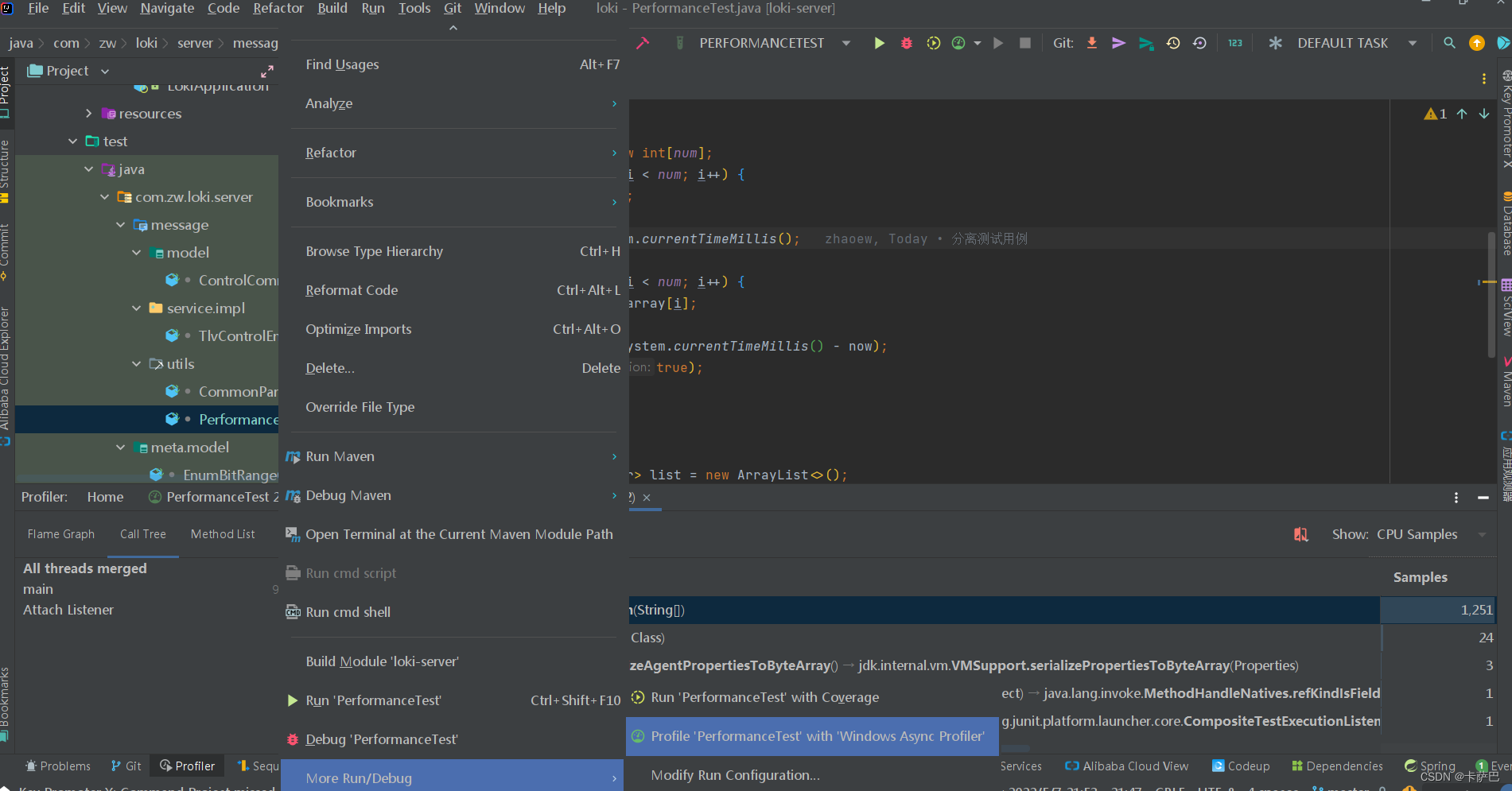
结束后查看报告就可以了,结果如下所示:
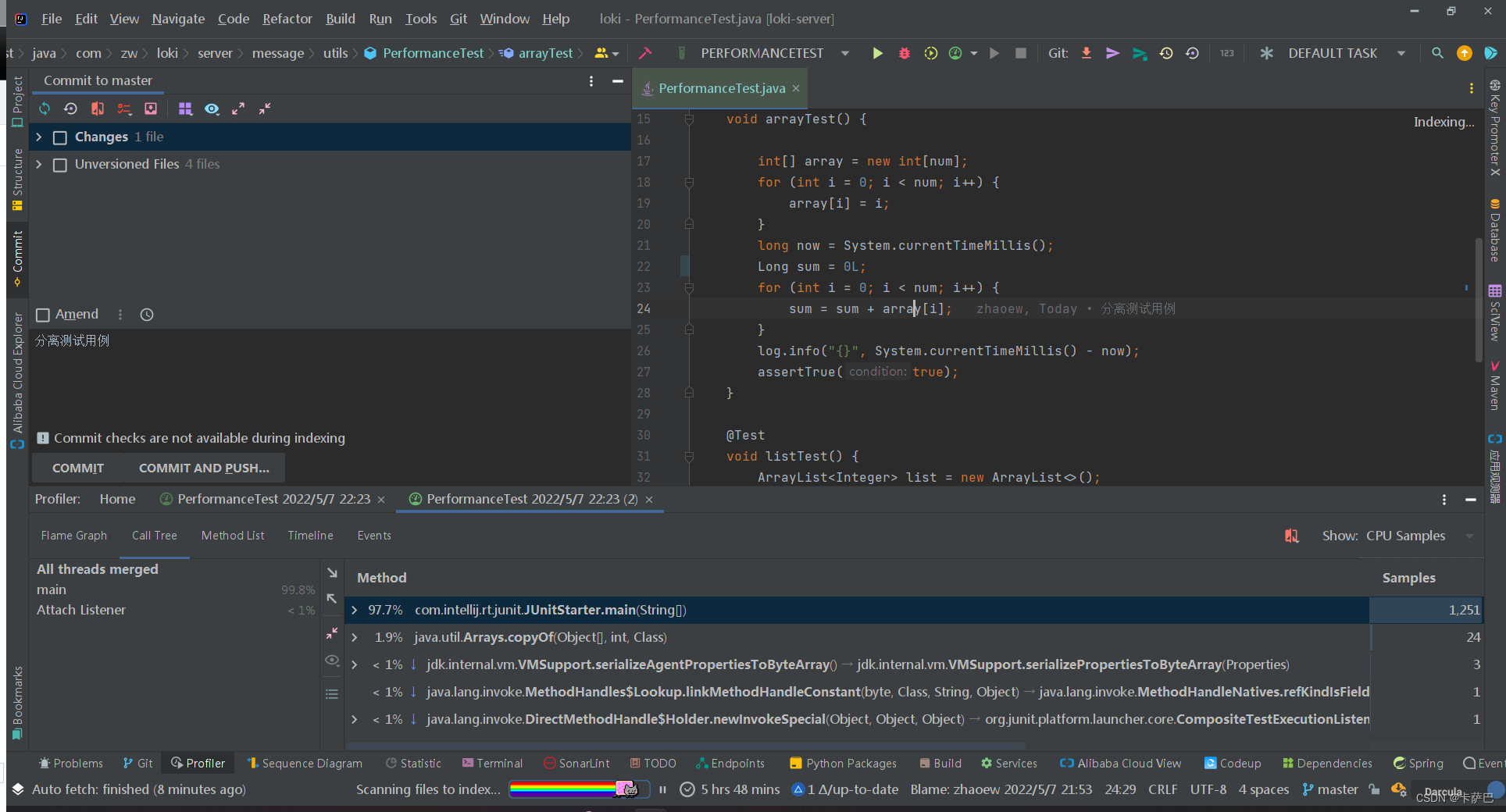
一般通过Call Tree就可以看出那个地方耗时最长了。
线上性能测试工具
- Alibaba Cloud View,通过ssh连接到目标主机上,在通过agent就可以实现监测了,https://help.aliyun.com/document_detail/147728.html
- Arthas,又是阿里系的神器,一个jar包就可以解决问题,值得你尝试https://arthas.aliyun.com/zh-cn/

