Java֪ʶ��ϰ��
��ص���
Java��������(һ)
Java��������(��)
Java��������(��)
Java��������(��)
Java��������(��)
Java����
ǰ��
���������ں�ʵJava������֪ʶ��,�ع��鱾,��ʵ����,ѧ��ѧ��
������Ҫ������Ŀ����ʵϰ,�ƻ����㽫Java������ͷ��ϰһ��,��ʵ����,���ܶ�Java��һЩ���Ʋ��˽����һ֪���,���ý�˻�������ѧϰ,Ҳ���¼�Լ���һ��ѧϰ�ܽᡣ
Java�����ο��鼮:��Java ����ʵս���� ��ʦ��̳ ��2�桷�롶Java���ļ��� ��I��
?��������Ҫ��������JavaӦ�ó�����Ʒ�������֪ʶ,���༯�������� IO��GUI���֪ʶ�㡣
?
һ��Java�༯���
1��ֱ�ۿ��
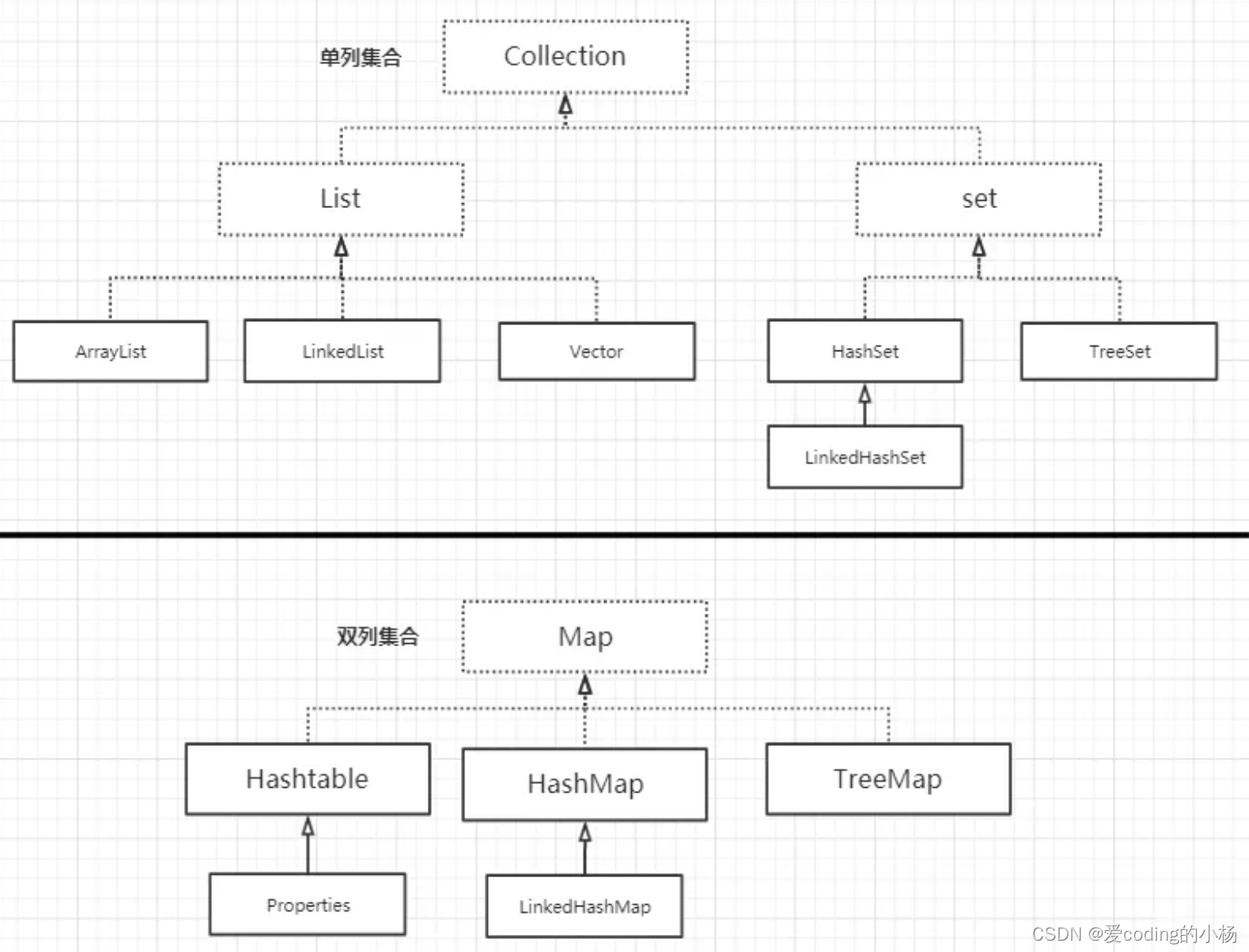
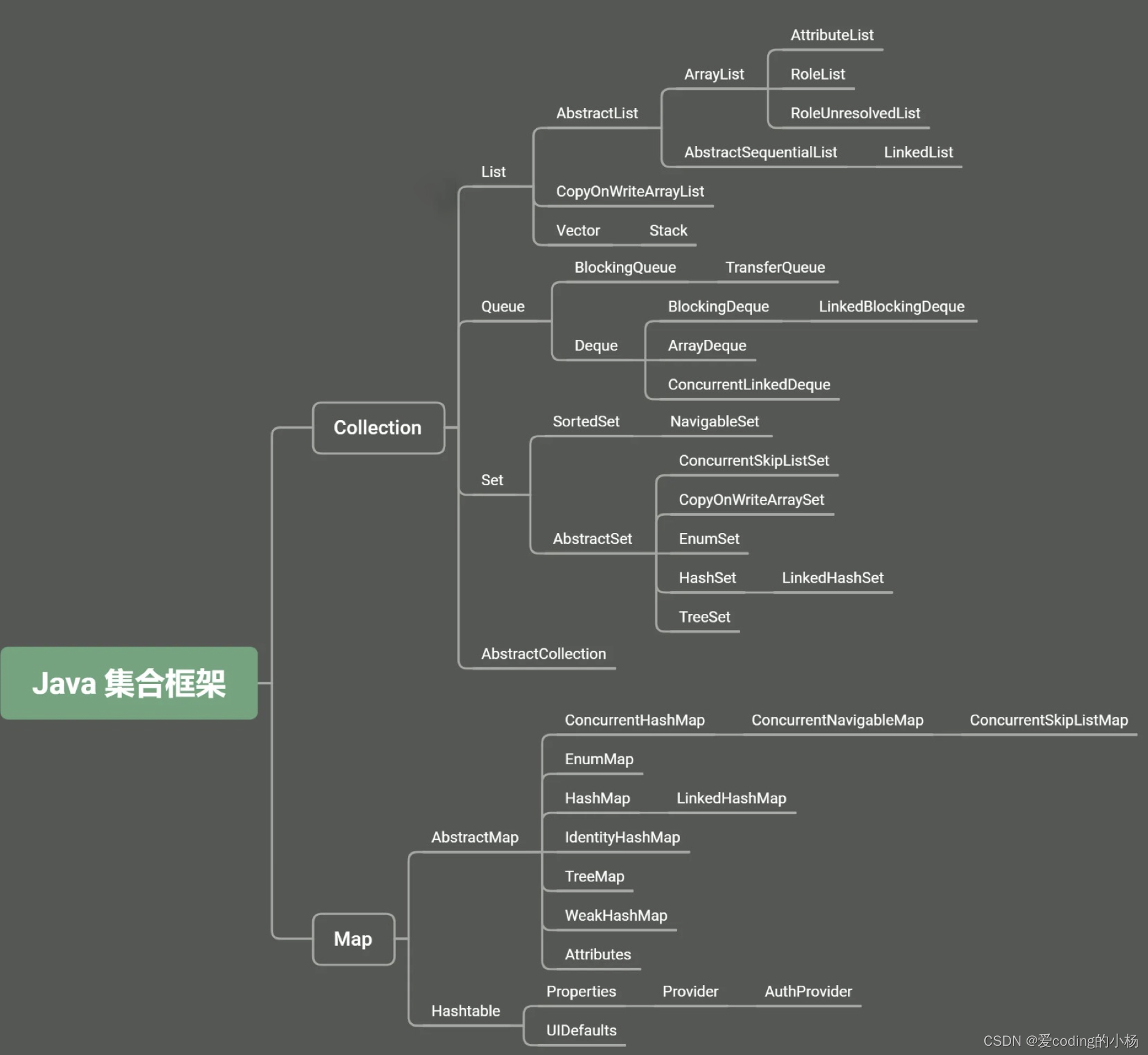
Java���Ͽ����Ҫ�����������͵�����,һ��������(Collection),��һ����ͼ(Map)��Collection�ӿ�����3��������,List��Set��Queue,��������һЩ������,���������ʵ����,���õ���ArrayList��LinkedList��HashSet��LinkedHashSet�ȵȡ�Map���õ���HashMap,LinkedHashMap�ȡ�
ע��
�ӿ� ��������=new ����ʵ����();//ʵ����һ��ʵ�������
����ȷ��,����������������̳�����̬˼�롣
2��Collection�ӿ�
2.1 List�ӿ�
List�ӿ���չ��Collection,�����Զ���һ�������ظ�������,��List�ӿ��еķ�������,List�ӿ���Ҫ������������λ�õ�����,������ָ��λ���ϲ���Ԫ��,ͬʱ������һ���ܹ�˫��������Ա������б�������ListIterator��AbstractList���ṩ��List�ӿڵIJ���ʵ��,AbstractSequentialList��չ��AbstractList,��Ҫ���ṩ��������֧�֡�
- ���÷���
-
add(Object element): ���б���β������ָ����Ԫ�ء�
-
size(): �����б��е�Ԫ�ظ�����
-
get(int index): �����б���ָ��λ�õ�Ԫ��,index��0��ʼ��
-
add(int index, Object element): ���б���ָ��λ�ò���ָ��Ԫ�ء�
-
set(int i, Object element): ������iλ��Ԫ���滻ΪԪ��element�����ر��滻��Ԫ�ء�
-
clear(): ���б����Ƴ�����Ԫ�ء�
-
isEmpty(): �ж��б��Ƿ����Ԫ��,������Ԫ���� true,����false��
-
contains(Object o): ����б�����ָ����Ԫ��,�� true��
-
remove(int index): �Ƴ��б���ָ��λ�õ�Ԫ��,�����ر�ɾԪ�ء�
-
remove(Object o): �Ƴ������е�һ�γ��ֵ�ָ��Ԫ��,�Ƴ��ɹ�����true,����false��
-
11��iterator(): ���ذ��ʵ�˳�����б���Ԫ���Ͻ��е����ĵ�������
�������List�ӿڵ�������Ҫ�ľ���ʵ����,Ҳ�����ǿ�����õ���,ArrayList��LinkedList��
- ���
������ĩβ�ⲻ��������λ�ò������ɾ��Ԫ��,��ôArrayListЧ�ʸ���,�����Ҫ�����������ɾ��Ԫ��,��ѡ��LinkedList��
2.1.1 ArrayList
����������洢Ԫ����,������������̬����,���Ԫ�ظ������������������,��ô�ʹ���һ�������������,������ǰ�����е�����Ԫ�ض����Ƶ��������С�
1���ҵ�add()ʵ�ַ�����
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
2���˷�����Ҫ��ȷ����Ҫ�����������С��
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
3������Ǵ�������,�������ԵĿ�������ȷ��������Ԫ�غ�Ĵ�С֮��Ԫ�ظ��Ƶ��������С�
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
- ʵ����
ArrayList<String> list = new ArrayList<String>(); //<String>���ͱ�ʾ�����д�����ַ�����ʽ��Ԫ�ء�
list.add("���"); //add()������List��������������Ԫ�ء�
list.add("ө��");
--------------------
List<String> list = new ArrayList<String>(){{
add("string1");
add("string2");
}};
- ���ֱ�����ʽ
import java.util.*;
public class Test{
public static void main(String[] args){
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("World");
list.add("Hello");
//��һ��:withOutSize-for����������ʱ,�ڲ�������, **Ч��**���,
//���ǵ�д���߳�ʱҪ���Dz������������⡣
int size=list.size();
for(int i = 0;i < size; i ++){
System.out.println(list.get(i));
}
//�ڶ���:withSize-for����������ʱ,�ڲ�������,���ϳ�����ѭ���ڲ�,
// **Ч��**����withOutSize-for�ķ�����
for(int i = 0;i < list.size(); i ++){
System.out.println(list.get(i));
}
//�����ַ���: ʹ�õ�����
//�����ַ������õ����ڱ��������г������ϵij���
//Ч�ʴ���withSize-for����
Iterator<String> ite = list.iterator();
while(ite.hasNext()){
System.out.println(ite.next());
}
//�����ַ���: for-each���� list
// �ڲ����õ�����, ��������ҩ,
// ��˱�Iterator ��,����ѭ����ʽ������������, ������ʹ������
//������
for(String str : list){
System.out.println(str);
}
}
}
For each��ʵҲ�����˵�������ʵ��,��˵����������ʱ,���ߵ�Ч�ʻ���һ�¡�Ҳ��Ϊ���˵�����,�����ٶ�������Ӱ�졣����ֱ��get(index)����
-
��Ϊ��get(index)��ȽϿ���?
-
��ΪArrayList��ͨ����̬������ʵ�ֵ�,֧���������,����get(index)�Ǻܿ�ġ�������,��ʵҲ��ͨ��������+�±�����ȡ,������������,��Ȼ���get(index)����
2.1.2 LinkedList
LinkedList����һ�������д洢Ԫ�ء�
��������������������������Ƕ�Ԫ�ص��洢��ʽ�IJ�ͬ���������������ݽ��в�ͬ����ʱ��Ч�ʲ�ͬ��
ʵ��������ͬAraayList��
- LinkedList�����ֱ�����ʽ
LinkedList��ͨ��˫������ʵ�ֵ�,��֧��������ʡ�����Ҫ��һ������ȡ��index��Ԫ��ʱ,����Ҫ���ֺ��ijһ�˿�ʼ��,һ��һ�����������ҵ���Ԫ�ء�����һ��,��������Ϊ��get(index)��˷�ʱ�ˡ�
import java.util.*;
public class Test{
public static void main(String[] args){
List<String> list = new LinkedList<String>();
list.add("Hello");
list.add("World");
list.add("Hello");
//��һ��:withOutSize-for����������ʱ,�ڲ�������, **Ч��**���,
int size=list.size();
for(int i = 0;i < size; i ++){
System.out.println(list.get(i));
}
//�ڶ���:withSize-for����������ʱ,�ڲ�������,���ϳ�����ѭ���ڲ�,
// **Ч��**����withOutSize-for�ķ�����
for(int i = 0;i < list.size(); i ++){
System.out.println(list.get(i));
}
//�����ַ���: ʹ�õ�����
//�����ַ������õ����ڱ��������г������ϵij���
//�����
Iterator<String> ite = list.iterator();
while(ite.hasNext()){
System.out.println(ite.next());
}
//�����ַ���: for-each���� list
// �ڲ����õ�����, ��������ҩ,
// ��˱�Iterator ��,����ѭ����ʽ������������, ������ʹ������
//Ч�ʴ��ڵ������ķ���
for(String str : list){
System.out.println(str);
}
}
}
2.1.3 CopyOnWriteArrayList
CopyOnWriteArrayList,��һ���̰߳�ȫ��List�ӿڵ�ʵ��,��ʹ����ReentrantLock������֤������������ṩ�����ܵIJ�����ȡ��
2.1.4 ArrayList��LinkedList���ֱ�����ʽ���ܽ�
-
����ArrayList��LinkedList,��
sizeС��1000ʱ,ÿ�ַ�ʽ�IJ��ڼ�ms֮��,���,ѡ���ĸ���ʽ�����ԡ� -
����ArrayList,����size�Ƕ��,
������,ѡ���ĸ���ʽ�������� -
����LinkedList,
��size�ϴ�ʱ,����ʹ����������for-each�ķ�ʽ���б���,����Ч�ʻ��н����ԵIJ�ࡣ
����,�ۺ�����,����ʹ��for-each,������,����Ҳ���
2.2 Set�ӿ�
Set�ӿ���չ��Collection,����List�IJ�֮ͬ������,�涨Set��ʵ���������ظ���Ԫ�ء�
��һ��������,һ��������������ȵ�Ԫ����AbstractSet��һ��ʵ��Set�ӿڵij�����,Set�ӿ�����������ʵ����,�ֱ���ɢ�м�HashSet����ʽɢ�м�LinkedHashSet�����μ�TreeSet��
2.2.1 HashSet
ɢ�м�HashSet��һ������ʵ��Set�ӿڵľ�����,����ʹ�������ι��������������յ�ɢ�м�,Ҳ������һ�����еļ�������ɢ�м���- ��ɢ�м���,������������Ҫ��ע,
��ʼ��������������
��������ȷ������������֮ǰ,�ù��ı����̶�,��Ԫ�ظ���������������������ij˻�ʱ,�����ͻ��Զ������� - ����Ԫ��ֵ����Ϊ
null; ����֤Ԫ�ص�����˳��,�п�������˳��������˳��ͬ;- ��ͬ������,
���̷߳���HashSetʱ,�Dz���ȫ��,��Ҫͨ��ͬ�����뱣֤ͬ���� - Ԫ��
�����ظ���ͬ,ͨ��equals()��hashCode()����һ���ж��Ƿ���ͬ�� - �����Dz�ѯԪ��ʱ,Ҳ��ͨ����Ԫ�ص�hashCodeֵ���ٶ�λ����Ԫ���ڼ����е�λ��,��ʵHashSet�ײ���ͨ��HashMapʵ�ֵġ�
ʵ������List��ͬ - ���ֱ�����ʽ
��HashSet��ͬ������ʹ��for, ������ͬ,for each(���õ�����)�ϲ��ȶ�
import java.util.*;
public class Test{
public static void main(String[] args){
HashSet<String> set = new HashSet<String>();
set.add("Hello");
set.add("World");
set.add("Hello");
//��һ�ַ���: ʹ�õ�����
//��һ�ַ������õ����ڱ��������г������ϵij���
//Ч���൱,���ȶ�
Iterator<String> ite = set.iterator();
while(ite.hasNext()){
System.out.println(ite.next());
}
//�ڶ��ַ���: for-each���� list
//Ч���൱,�����ȶ�
for(String str : set){
System.out.println(str);
}
}
}
2.2.2 LinkedHashSet
LinkedHashSet����һ������ʵ������չHashSet��,��֧�ֶԹ����ڵ�Ԫ�����������������ظ�����HashSet�е�Ԫ����û�б������,��LinkedHashSet�е�Ԫ�ؿ����������������˳����ȡ��
ʵ������List��ͬ
LinkedHashSet<String> linkedHashSet =new LinkedHashSet<String>();
linkedHashSet.add("a");
linkedHashSet.add("a");
linkedHashSet.add("a");
linkedHashSet.add("b");
linkedHashSet.add("b");
linkedHashSet.add("c");
linkedHashSet.add("d");
System.out.println(linkedHashSet);
----------------------------------------
���
[a,b,c,d]
������ʽ��Ч����HashSet��ͬ
2.2.3 TreeSet
TreeSet��չ��AbstractSet,��ʵ����NavigableSet,AbstractSet��չ��AbstractCollection,���μ���һ��������Set,��ײ���һ����,�������ܴ�Set������ȡһ��������������
�������֮,TresSet�����ǿ����Զ�����ġ�
��ʵ����TreeSetʱ,���ǿ��Ը�TreeSetָ��һ���Ƚ���Comparator��ָ�����μ��е�Ԫ��˳�������μ����ṩ�˺ܶ��ݵķ�����
ʹ��Comparator�����ַ���
//��һ�ַ���
//��ʵ��Comparable�ӿ�,����дcompareTo����
public class Person implements Comparable{
private int age;
private String name;
public Person(){}
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
public void setAge(int age) {
this.age = age;
}
public void setName(String name) {
this.name = name;
}
@Override
public int compareTo(Object o) {
if (!(o instanceof Person))
throw new RuntimeException("�����˶���");
Person p = (Person) o;
if (this.age > p.age)
return 1;
if (this.age == p.age){
return this.name.compareTo(p.name);
}
return -1;
}
}
----------------------------------------
//�ڶ��ַ���
//д����ʵ��Comparartor�ӿ�,��дcompare����
class myComparator implements Comparator{
@Override
public int compare(Object o1, Object o2) {
Person p1 = (Person) o1;
Person p2 = (Person) o2;
int num = p1.getName().compareTo(p2.getName());
// 0�Ļ���������ͬ,������һ�����ԱȽ�
if (num == 0){
return new Integer(p1.getAge()).compareTo(new Integer(p2.getAge()));
}
return num;
}
}
//��new Set��ʱ��Ž�ȥ
TreeSet ts = new TreeSet(new myComparator());
----------------------------------------
//�����ַ���
//д�����ڲ���,��дcompare����
TreeSet ts = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
Person p1 = (Person) o1;
Person p2 = (Person) o2;
int num = p1.getName().compareTo(p2.getName());
if (num == 0){
return new Integer(p1.getAge()).compareTo(new Integer(p2.getAge()));
}
return num;
}
});
ʵ�����ͱ�����ʽͬHashSet
2.2.4 Queue
������һ���Ƚ��ȳ������ݽṹ,Ԫ��������ĩβ����,������ͷ��ɾ����Queue�ӿ���չ��Collection,���ṩ���롢��ȡ������Ȳ�����
��Ҫ����
//����������
add(E e) : ��Ԫ��e���뵽����ĩβ,�������ɹ�,��true;�������ʧ��(����������),����׳��쳣;
remove() :�Ƴ�����Ԫ��,���Ƴ��ɹ�,��true;����Ƴ�ʧ��(����Ϊ��),����׳��쳣;
offer(E e) :��Ԫ��e���뵽����ĩβ,�������ɹ�,��true;�������ʧ��(����������),��false;
poll() :�Ƴ�����ȡ����Ԫ��,���ɹ�,�ض���Ԫ��;����null;
peek() :��ȡ����Ԫ��,���ɹ�,�ض���Ԫ��;����null
���ڷ���������,һ������½���ʹ��**offer��poll��peek**��������,
������ʹ��add��remove������
��Ϊʹ��offer��poll��peek������������ͨ������ֵ�жϲ����ɹ����,
��ʹ��add��remove����ȴ���ܴﵽ������Ч����
ע��,�����������еķ�����û�н���ͬ����ʩ��
//��������(ArrayBlockingQueue��LinkedBlockingQueue��
//PriorityBlockingQueue��DelayQueue)
�������а����˷����������еĴַ���,
�����оٵ�5�����������������ж�����,
����Ҫע����5�����������������ж�������ͬ����ʩ��
���еķ���
put(E e) : �������β����Ԫ��,���������,��ȴ�;
take() : �����Ӷ���ȡԪ��,�������Ϊ��,��ȴ�;
offer(E e,long timeout, TimeUnit unit) : �������β����Ԫ��,���������,��ȴ�һ����ʱ��,��ʱ�����ﵽʱ,�����û�в���ɹ�,��false;����true;
poll(long timeout, TimeUnit unit) : �����Ӷ���ȡԪ��,������п�,��ȴ�һ����ʱ��,��ʱ�����ﵽʱ,���ȡ��,��null;����ȡ�õ�Ԫ��;
����Ԫ�غ���������Set��ͬ
Queue<Integer> q = new LinkedBlockingQueue<Integer>();
//��ʼ������
for (int i = 0; i < 5; i++) {
q.offer(i);
}
//ʹ��offer()����ʵ����������
ʵ�����ͱ���
import java.util.Queue;
import java.util.concurrent.LinkedBlockingQueue;
/**
* ���еı���
*
* @author leizhimin 2009-7-22 15:05:14
*/
public class TestQueue {
public static void main(String[] args) {
Queue<Integer> q = new LinkedBlockingQueue<Integer>();
//��ʼ������
for ( int i = 0; i < 5; i++) {
q.offer(i);
}
System.out.println( "-------1-----");
//���Ϸ�ʽ����,Ԫ�ز��ᱻ�Ƴ�
for (Integer x : q) {
System.out.println(x);
}
System.out.println( "-------2-----");
//����������
Iterator it = queue.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
System.out.println( "-------3-----");
//���з�ʽ����,Ԫ��������Ƴ�
while (q.peek() != null) {
System.out.println(q.poll());
}
System.out.println( "-------4-----");
while (!queue.isEmpty()) {
System.out.println(queue.poll());
}
}
}
�ܽ�,���������ֵı�����ʽ������ͬ,���������������еı�����ʽ
2.2.5 ������ʽ�ܽ�
����ʹ��for each����,Ч�ʺ���ʽ�������������,���ǿ��Ժ�List��Ӧ����,���ڼ��䡣
2.3 Map�ӿ�
Map��������һ������,�������dz�˵��"��ֵ��",Map��ÿ��Ԫ�ض���key-value����ʽ�洢��
���÷���
���ӡ�ɾ�����IJ���:
Object put(Object key,Object value):��ָ��key-value���ӵ�(����)��ǰmap������
void putAll(Map m):��m�е�����key-value�Դ�ŵ���ǰmap��
Object remove(Object key):�Ƴ�ָ��key��key-value��,������value
void clear():��յ�ǰmap�е���������
Ԫ�ز�ѯ�IJ���:
Object get(Object key):��ȡָ��key��Ӧ��value
boolean containsKey(Object key):�Ƿ����ָ����key
boolean containsValue(Object value):�Ƿ����ָ����value
int size():����map��key-value�Եĸ���
boolean isEmpty():�жϵ�ǰmap�Ƿ�Ϊ��
boolean equals(Object obj):�жϵ�ǰmap�Ͳ�������obj�Ƿ����
Ԫ����ͼ�����ķ���:
Set keySet():��������key���ɵ�Set����
Collection values():��������value���ɵ�Collection����
Set entrySet():��������key-value�Թ��ɵ�Set����
�ܽ�
����:put(Object key,Object value)
ɾ��:remove(Object key)
��:put(Object key,Object value)
��ѯ:get(Object key)
����:size()
����:keySet() / values() / entrySet()
2.3.1 HashMap
HashMap�ǻ�����ϣ����Map�ӿڵ���ͬ��ʵ��,�̳���AbstractMap,AbstractMap�Dz���ʵ��Map�ӿڵij����ࡣԪ���������ġ�
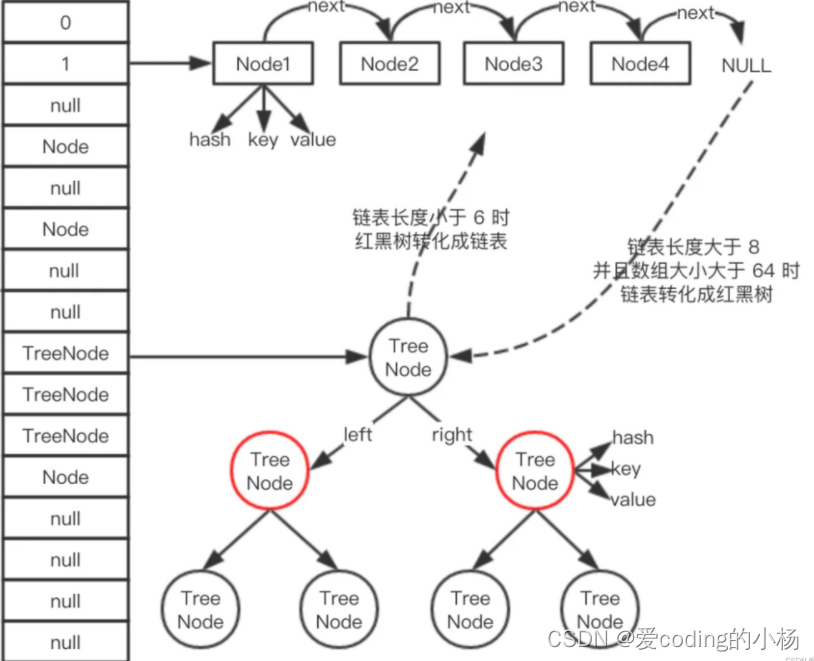
JDK1.8֮��,(֮ǰ������+����)HashMap��������+����+�����ʵ��,���������ȳ�����ֵ(8)ʱ,������ת��Ϊ�����,�����������˲���ʱ�䡣
- ���ֱ�������
1.ʹ�� Iterator ���� HashMap EntrySet
2.ʹ�� Iterator ���� HashMap KeySet
3.ʹ�� For-each ѭ������ HashMap
4.ʹ�� Lambda ����ʽ���� HashMap
5.ʹ�� Stream API ���� HashMap
----------------------------------------
1. ʹ�� Iterator ���� HashMap EntrySet
package com.java.tutorials.iterations;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
/**
* �� Java �б��� HashMap ��5����ѷ���
*
*/
public class IterateHashMapExample {
public static void main(String[] args) {
// 1. ʹ�� Iterator ���� HashMap EntrySet
Map < Integer, String > coursesMap = new HashMap < Integer, String > ();
coursesMap.put(1, "C");
coursesMap.put(2, "C++");
coursesMap.put(3, "Java");
coursesMap.put(4, "Spring Framework");
coursesMap.put(5, "Hibernate ORM framework");
Iterator < Entry < Integer, String >> iterator = coursesMap.entrySet().iterator();
while (iterator.hasNext()) {
Entry < Integer, String > entry = iterator.next();
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
}
2. ʹ�� Iterator ���� HashMap KeySet
package com.java.tutorials.iterations;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
/**
* �� Java �б��� HashMap ��5����ѷ���
*
*/
public class IterateHashMapExample {
public static void main(String[] args) {
Map < Integer, String > coursesMap = new HashMap < Integer, String > ();
coursesMap.put(1, "C");
coursesMap.put(2, "C++");
coursesMap.put(3, "Java");
coursesMap.put(4, "Spring Framework");
coursesMap.put(5, "Hibernate ORM framework");
// 2. ʹ�� Iterator ���� HashMap KeySet
Iterator < Integer > iterator = coursesMap.keySet().iterator();
while (iterator.hasNext()) {
Integer key = iterator.next();
System.out.println(key);
System.out.println(coursesMap.get(key));
}
}
}
3. ʹ�� For-each ѭ������ HashMap
package com.java.tutorials.iterations;
import java.util.HashMap;
import java.util.Map;
/**
* �� Java �б��� HashMap ��5����ѷ���
*
*/
public class IterateHashMapExample {
public static void main(String[] args) {
Map < Integer, String > coursesMap = new HashMap < Integer, String > ();
coursesMap.put(1, "C");
coursesMap.put(2, "C++");
coursesMap.put(3, "Java");
coursesMap.put(4, "Spring Framework");
coursesMap.put(5, "Hibernate ORM framework");
// 3. ʹ�� For-each ѭ������ HashMap
for (Map.Entry < Integer, String > entry: coursesMap.entrySet()) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
}
4. ʹ�� Lambda ����ʽ���� HashMap
package com.java.tutorials.iterations;
import java.util.HashMap;
import java.util.Map;
/**
* �� Java �б��� HashMap ��5����ѷ���
*
*/
public class IterateHashMapExample {
public static void main(String[] args) {
Map < Integer, String > coursesMap = new HashMap < Integer, String > ();
coursesMap.put(1, "C");
coursesMap.put(2, "C++");
coursesMap.put(3, "Java");
coursesMap.put(4, "Spring Framework");
coursesMap.put(5, "Hibernate ORM framework");
// 4. ʹ�� Lambda ����ʽ���� HashMap
coursesMap.forEach((key, value) -> {
System.out.println(key);
System.out.println(value);
});
}
}
5. ʹ�� Stream API ���� HashMap
package com.java.tutorials.iterations;
import java.util.HashMap;
import java.util.Map;
/**
* �� Java �б��� HashMap ��5����ѷ���
*
*/
public class IterateHashMapExample {
public static void main(String[] args) {
Map < Integer, String > coursesMap = new HashMap < Integer, String > ();
coursesMap.put(1, "C");
coursesMap.put(2, "C++");
coursesMap.put(3, "Java");
coursesMap.put(4, "Spring Framework");
coursesMap.put(5, "Hibernate ORM framework");
// 5. ʹ�� Stream API ���� HashMap
coursesMap.entrySet().stream().forEach((entry) - > {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
}
}
//���� entrySet ���������,����ִ���ٶ����,
//�������� stream ,Ȼ�������� keySet,���������� KeySet
// entrySet �����ܱ� keySet �����ܸ߳���һ��֮��,
//�������Ӧ�þ���ʹ�� entrySet ��ʵ�� Map ���ϵı�����
2.3.2 LinkedHashMap
LinkedHashMap�̳���HashMap,����Ҫ��������ʵ������չHashMap��,HashMap����Ŀ��û��˳���,������LinkedHashMap��Ԫ�ؼȿ�������������ͼ��˳������,Ҳ�����������һ�α����ʵ�˳��������
LinkedHashMap��ͨ����HashMap����һ��˫������ʵ�ֵ�������
������ʽ��������HashMap��ͬ�������а��պ���˳������ķ��ࡣ
- ����
����˳������ - ����
����˳������
�Ƿ�ʹ�÷���˳�����,��ͨ��LinkedHashMap ��accessOrder�������Ƶ�,trueΪ����˳������,falseΪ����˳��������
���ø�ֵֻ���ڴ���LinkedHashMap ʱͨ�����췽�����õġ�
/**
* ʵ����һ��LinkedHashMap;
*
* LinkedHashMap�IJ���˳��ͷ���˳��;
* LinkedHashMap(int initialCapacity,
* float loadFactor, boolean accessOrder);
* ˵��:
* ��accessOrderΪtrueʱ��ʾ��ǰ���ݵIJ����ȡ˳��Ϊ����˳��;
* ��accessOrderΪfalseʱ��ʾ��ǰ���ݵIJ����ȡ˳��Ϊ����˳��;
*/
Map<String,String> linkedHashMap = new
LinkedHashMap<String,String>(0,1.6f,true); // ����˳��;
// Map<String,String> linkedHashMap = new
//LinkedHashMap<String,String>(0,1.6f,false); // ����˳��;
2.3.3 TreeMap
TreeMap������������ݽṹ��ʵ��,��ֵ����ʹ��Comparable��Comparator�ӿ���������TreeMap�̳���AbstractMap,ͬʱʵ���˽ӿ�NavigableMap,���ӿ�NavigableMap��̳���SortedMap��
SortedMap��Map���ӽӿ�,ʹ��������ȷ��ͼ�е���Ŀ���ź����ġ�
TreeMap Ĭ���������:����key���ֵ�˳��������(����)
��Ȼ,Ҳ�����Զ����������:Ҫʵ��Comparator�ӿ���
��ʵ��ʹ����,�������ͼʱ����Ҫ����ͼ��Ԫ�ص�˳��,��ʹ��HashMap,�����Ҫ����ͼ��Ԫ�ص�����˳����߷���˳��,��ʹ��LinkedHashMap,�����Ҫʹͼ������ֵ����,��ʹ��TreeMap��
2.3.4 ConcurrentHashMap
Concurrent,����,�����־Ϳ��Կ�����ConcurrentHashMap��HashMap���̰߳�ȫ����ͬHashMap���,ConcurrentHashMap������֤�˷��ʵ��̰߳�ȫ��,������Ч������HashTable���,Ҳ�нϴ�������
2.3.5 ������ʽ�ܽ�
������������,����ʹ�� for each ѭ������ HashMap��entrySet����Map�ı�����
for (Map.Entry < Integer, String > entry: coursesMap.entrySet()) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
2.4 ���ϱ�����ʽ�ܽ�
��������Ч�ʿ���,Collection��Map���϶���������for each���õ��������м�������,����,Mapϵ������for each����entrySet��
��������
���͵ı���������������,Ҳ����˵���������������ͱ�ָ��Ϊһ�����������������������������ࡢ�ӿںͷ����Ĵ�����,�ֱ��Ϊ�����ࡢ���ͽӿڡ����ͷ�����
Java�������뷺�͵ĺô�����ȫ������Ҫ�������ת����
���ڳ����ķ���ģʽ,�Ƽ���������:
K ������,����ӳ��ļ���
V ����ֵ,���� List �� Set ������,���� Map �е�ֵ��
E �����쳣�ࡣ
T �������͡�
1��������
�������е����Ͳ����������������κο���ʹ�ýӿ����������ĵط���
public interface Map<K, V> {
public void put(K key, V value);
public V get(K key);
}
2�����ͷ���
���ͷ���ʹ�ø÷��������������������仯��
������һ��������ָ��ԭ��:���ۺ�ʱ,ֻҪ��������,���Ӧ�þ���ʹ�÷��ͷ�����Ҳ����˵,���ʹ�÷��ͷ�������ȡ����������ͻ�,��ô��Ӧ��ֻʹ�÷��ͷ���,
��Ϊ������ʹ������������������,����һ��static�ķ�������,�����ʷ���������Ͳ���������,���static������Ҫʹ�÷�������,�ͱ���ʹ���Ϊ���ͷ�����
Ҫ�������ͷ���,ֻ�轫���Ͳ����б���������ֵ֮ǰ��
ʾ��
package Generics;
public class GenericMethods {
//�����������������������Ͳ�ȷ����ʱ��,���Խ����Ͷ����ڷ�����
public <T> void f(T x){
System.out.println(x.getClass().getName());
}
public static void main(String[] args) {
GenericMethods gm = new GenericMethods();
gm.f(99);
gm.f("���Ϻ��");
gm.f(new Integer(99));
gm.f(18.88);
gm.f('a');
gm.f(gm);
}
}
/* ������:
java.lang.Integer
java.lang.String
java.lang.Integer
java.lang.Double
java.lang.Character
Generics.GenericMethods
*/
���ͷ�����ɱ�����б��ܺܺõع���
package Generics;
import java.util.ArrayList;
import java.util.List;
public class GenericVarargs {
public static <T> List<T> makeList(T... args){
List<T> result = new ArrayList<T>();
for(T item:args)
result.add(item);
return result;
}
public static void main(String[] args) {
List ls = makeList("A");
System.out.println(ls);
ls = makeList("A","B","C");
System.out.println(ls);
ls = makeList("ABCDEFGHIJKLMNOPQRSTUVWXYZ".split(""));
System.out.println(ls);
}
}
/*
[A]
[A, B, C]
[A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z]
*/
��̬�����ϵķ���
��̬�������������϶���ķ��͡������̬���������������������Ͳ�ȷ����ʱ��,����Ҫ�����Ͷ����ڷ����ϡ�
public static <Q> void function(Q t) {
System.out.println("function:"+t);
}
3������ͨ��� ?
���Խ�����������Ͳ�ȷ����ʱ��,���ͨ�������? ;
����������ʱ,����Ҫʹ�����͵ľ��幦��ʱ,ֻʹ��Object���еĹ��ܡ���ô������ ? ͨ�������δ֪������
Class<?>classType = Class.forName("java.lang.String");
4������������ʽ
- ����:?extends E:���Խ���E���ͻ���E�������Ͷ���
- ?super E:���Խ���E���ͻ���E�ĸ����Ͷ���
����ʲôʱ����:������������Ԫ��ʱ,�ȿ�������E���Ͷ���,�ֿ�������E������������Ϊʲô?��Ϊȡ��ʱ��,E���ͼȿ�������E�����,�ֿ�������E�������Ͷ�����
����ʲôʱ����:���Ӽ����л�ȡԪ�ؽ��в�����ʱ��,�����õ�ǰԪ�ص����ͽ���,Ҳ��������ǰԪ�صĸ����ͽ�����
5��Ӧ�ó���
���ӿڡ��༰�����еIJ����������������Ͳ�ȷ����ʱ��,��ǰ�õ�Object��������չ��,���ڿ�������������ʾ��������������ǿת���鷳��
���͵�ϸ��
-
���͵���
����ʲô����ȡ���������ߴ��������,���û��,Ĭ����Object����; -
ʹ��
�����͵�����������ʱ,��ʽ����ָ������������һ��;ԭ��:��������������÷���ʱֻ������,Ȼ�����������ڼ���÷���ʱ��Ҫ���Ƕ������������;
-
��ʽ���߿���������һ��ʹ������,����һ����ʹ��(�����������)��
����IO����
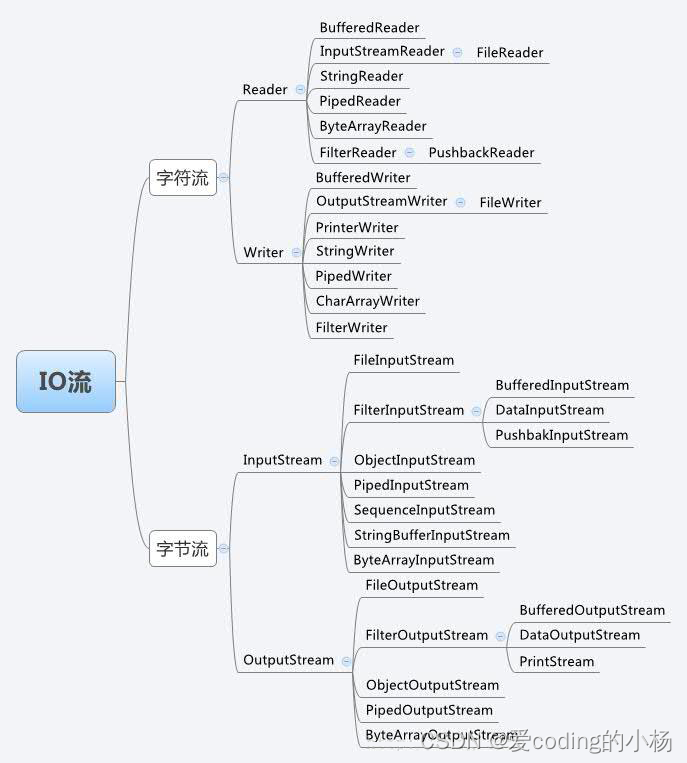
1��ֱ��ͼ
2���ֽ������ַ���
- �ֽ������Դ���
�������͵�����,��MP3��ͼƬ�����֡���Ƶ�ȡ��ڶ�ȡʱ,����һ���ֽھͷ���һ���ֽڡ�
��Java�ж�Ӧ����ԡ�Stream����β�� - �ַ������ܹ�����
���ı�����,��txt�ı������ڶ�ȡʱ,����һ�������ֽ�,�Ȳ���ָ���ı����,Ȼ�鵽���ַ����ء�
��Java�ж�Ӧ����ԡ�Reader����Writer����β��
3����ȡ�ļ�ʾ��
public class ReadFromFile {
/**
* ���ֽ�Ϊ��λ��ȡ�ļ�,�����ڶ�**�������ļ�**,��ͼƬ��������Ӱ����ļ���
*/
public static void readFileByBytes(String fileName) {
File file = new File(fileName);
InputStream in = null;
try {
System.out.println("���ֽ�Ϊ��λ��ȡ�ļ�����,һ�ζ�һ���ֽ�:");
// һ�ζ�һ���ֽ�
in = new FileInputStream(file);
int tempbyte;
while ((tempbyte = in.read()) != -1) {
System.out.write(tempbyte);
}
in.close();
} catch (IOException e) {
e.printStackTrace();
return;
}
try {
System.out.println("���ֽ�Ϊ��λ��ȡ�ļ�����,һ�ζ�����ֽ�:");
// һ�ζ�����ֽ�
byte[] tempbytes = new byte[100];
int byteread = 0;
in = new FileInputStream(fileName);
ReadFromFile.showAvailableBytes(in);
// �������ֽڵ��ֽ�������,bytereadΪһ�ζ�����ֽ���
while ((byteread = in.read(tempbytes)) != -1) {
System.out.write(tempbytes, 0, byteread);
}
} catch (Exception e1) {
e1.printStackTrace();
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e1) {
}
}
}
}
/**
* ���ַ�Ϊ��λ��ȡ�ļ�,�����ڶ��ı�,���ֵ����͵��ļ�
*/
public static void readFileByChars(String fileName) {
File file = new File(fileName);
Reader reader = null;
try {
System.out.println("���ַ�Ϊ��λ��ȡ�ļ�����,һ�ζ�һ���ֽ�:");
// һ�ζ�һ���ַ�
reader = new InputStreamReader(new FileInputStream(file));
int tempchar;
while ((tempchar = reader.read()) != -1) {
// ����windows��,\r\n�������ַ���һ��ʱ,��ʾһ�����С�
// ������������ַ��ֿ���ʾʱ,�ỻ�����С�
// ���,���ε�\r,��������\n������,�������ܶ���С�
if (((char) tempchar) != '\r') {
System.out.print((char) tempchar);
}
}
reader.close();
} catch (Exception e) {
e.printStackTrace();
}
try {
System.out.println("���ַ�Ϊ��λ��ȡ�ļ�����,һ�ζ�����ֽ�:");
// һ�ζ�����ַ�
char[] tempchars = new char[30];
int charread = 0;
reader = new InputStreamReader(new FileInputStream(fileName));
// �������ַ����ַ�������,charreadΪһ�ζ�ȡ�ַ���
while ((charread = reader.read(tempchars)) != -1) {
// ͬ�����ε�\r����ʾ
if ((charread == tempchars.length)
&& (tempchars[tempchars.length - 1] != '\r')) {
System.out.print(tempchars);
} else {
for (int i = 0; i < charread; i++) {
if (tempchars[i] == '\r') {
continue;
} else {
System.out.print(tempchars[i]);
}
}
}
}
} catch (Exception e1) {
e1.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
}
/**
* ����Ϊ��λ��ȡ�ļ�,�����ڶ������еĸ�ʽ���ļ�
*/
public static void readFileByLines(String fileName) {
File file = new File(fileName);
BufferedReader reader = null;
try {
System.out.println("����Ϊ��λ��ȡ�ļ�����,һ�ζ�һ����:");
reader = new BufferedReader(new FileReader(file));
String tempString = null;
int line = 1;
// һ�ζ���һ��,ֱ������nullΪ�ļ�����
while ((tempString = reader.readLine()) != null) {
// ��ʾ�к�
System.out.println("line " + line + ": " + tempString);
line++;
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
}
/**
* �����ȡ�ļ�����
*/
public static void readFileByRandomAccess(String fileName) {
RandomAccessFile randomFile = null;
try {
System.out.println("�����ȡһ���ļ�����:");
// ��һ����������ļ���,��ֻ����ʽ
randomFile = new RandomAccessFile(fileName, "r");
// �ļ�����,�ֽ���
long fileLength = randomFile.length();
// ���ļ�����ʼλ��
int beginIndex = (fileLength > 4) ? 4 : 0;
// �����ļ��Ŀ�ʼλ���Ƶ�beginIndexλ�á�
randomFile.seek(beginIndex);
byte[] bytes = new byte[10];
int byteread = 0;
// һ�ζ�10���ֽ�,����ļ����ݲ���10���ֽ�,���ʣ�µ��ֽڡ�
// ��һ�ζ�ȡ���ֽ�������byteread
while ((byteread = randomFile.read(bytes)) != -1) {
System.out.write(bytes, 0, byteread);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (randomFile != null) {
try {
randomFile.close();
} catch (IOException e1) {
}
}
}
}
/**
* ��ʾ�������л�ʣ���ֽ���
*/
private static void showAvailableBytes(InputStream in) {
try {
System.out.println("��ǰ�ֽ��������е��ֽ���Ϊ:" + in.available());
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String fileName = "C:/temp/newTemp.txt";
ReadFromFile.readFileByBytes(fileName);
ReadFromFile.readFileByChars(fileName);
ReadFromFile.readFileByLines(fileName);
ReadFromFile.readFileByRandomAccess(fileName);
}
}
�塢GUI
ͼ�λ����û�����(Graphical User Interface,���GUI),Java�ṩ��Swing�����JavaFx����GUI������
ǰ����ͨ���������GUI�������¼�ע��;
������ͨ����ק���в��֡�
�ص����JavaFx��һ�����
5.1 Swing���
-
java.awt �� �C ��Ҫ�ṩ����/���ֹ�����
-
javax.swing ��[��ҵ��������] �C ��Ҫ�ṩ�������(����/��ť/�ı���)
-
java.awt.event �� �C �¼�����,��̨���ܵ�ʵ�֡�
5.2JavaFx����
����˵,������Ҫ��Ϊ���¼���
- ��JDK(7����)
- װJavaFx Scence Builder ��������
- IDEAװJavaFx���
- IDEAָ��JavaFx Scence Builder�Ŀ�ִ���ļ���·��
- ʹ��MVCģʽ���п���
5.3 JavaFx��Ŀ����
- Main.java
����һ��start()������main()����,start()����������JavaFXӦ�ó�������,�DZ����;
����JavaFXӦ�ó�����ͨ��JavaFX Packager���ߴ��ʱ,main()�����Ͳ��DZ���ĵ���,��ΪJavaFX Package���ὫJavaFX LauncherǶ�뵽JAR�ļ��С����ļ�ʹ��FXMLLoader��,���ฺ�����FXMLԴ�ļ�sample.fxml�����ؽ������ͼ�� - sample.fxml
fxmlԴ�ļ�,������ʽ����Controller������JavaFX������,�����û�������صĶ����������� - Controller.java
����sample.fxml�е����id��ʵ��sample.fxml���¼������ķ���,��Ҫ��������������¼��������� - �����������Ļ�,���Զ���һ��
Model�ļ���,���ҵ���������ݶ�ȡ������
�����ܽ�
����JDBC��һЩ���ݻ��ں�����Springϵ�н��Mybatis-plus���й���,�����ڴ���

