ЩњВњЪТЙЪМЧТМ
БГОА
гЩгкЯюФПвЊЧѓ99.9%ПЩгУад,ЖјДЫДЮЪТЙЪЕМжТхДЛњСЫЮхИіаЁЪБ,вдКѓУПИіМОЖШжЛФмгавЛИіаЁЪБЕФВЛПЩгУЪБМфЁЃе§КУЮЪЬтЕФХХВщвЛжБЖМЪєгкГЬађдБЕФБІЙѓОбщ,вђДЫОЭдкетМЧТМЯТРДЁЃ
ЗЂЩњЕФЯжЯѓ:
ЩЯЮч10Еужгзѓгв,ПЊЪМГіЯжвГУцЗУЮЪвьГЃЧщПі,МьВщЗЂЯжФГИіЗўЮёУПМфИєвЛЖЮЪБМфОЭЛсжиЦєвЛЛсЁЃКѓајЙлВьЪЧУПЙЬЖЈ20ЗжжгОЭЛсБЛk8sжиЦєвЛДЮЁЃ
ГіЯжСЫвьГЃжиЦєЕФЧщПі,ЪзЯШОЭвЊВщУївьГЃЕФдвђ,жБНгдвђБШШчCPUЁЂФкДцЕШдвђ,МфНгдвђОЭЪЧПДЪЧФФРяв§Ц№ЕФУП20ЗжжгжиЦєЁЃ
ХХВщЙ§ГЬ
1ЁЂGrafanaМрПиБЈБэ
дкGrafanaЩЯПДЕН,ЛљБОдкжиЦєЧАЕФБпдЕЩЯЕФЧщПі:
- CPUБШНЯе§ГЃ,вЛжБЖМЪЧДІгкНЯЕЭЕФЪЙгУТЪЫЎЦНЁЃ
- JVMФкДцдкгаМИДЮжиЦєЧАЖМНгНќТњСЫ,ПЩФмФмЙЛБЛЛиЪе,ЕЋЛЙУЛгаДЅЗЂMajor GC,ЪЧИіжЕЕУХХВщЕФЕиЗН,ЭЌЪБЕУШЅПДПДШежОжагаУЛгаout of memoryЕФБЈДэШежОЁЃ
- TomcatСЌНгГиЕФЯпГЬЪ§ЖМТњСЫ,ДяЕНзюДѓЕФЪЙгУЪ§СПСЫ,вђЮЊЮвУЧетРяЪЙгУЕФФЌШЯЕФХфжУ,200ИіОЭвбОТњСЫЁЃетЪЧзюДѓЕФЯгвЩЁЃ
дкЩЯУцШ§ЕуЛљБОПДРДзюгІИУХХВщЕФОЭЪЧTomcatСЌНгГиЁЃ
2ЁЂДцЛюЬНеыЯрЙиYaml
ПЩФмгаШЫЛсОѕЕУ,ОЭЫуСЌНгГиТњСЫ,ЛђепJVMЗЂЩњout of memoryСЫ,ЖМВЛгІИУЛсжБНгЕМжТЗўЮёЕФжиЦє,етРявђЮЊЮвУЧгУЕФЪЧk8s,ХфжУСЫЗўЮёЕФОЭаїЬНеыКЭДцЛюЬНеы,УПИє10УыжгЕїгУвЛДЮЗўЮёЕФНгПкРДШЗБЃЗўЮёДцЛюЁЃЕБЪЇАмГЌЙ§3ДЮвдКѓОЭЛсШЯЮЊетИіЗўЮёвбОЫРЭі,ОЭЛсПЊЪМжиаТЦєЖЏвЛИіPod,ВЂremoveЕєдРДЕФPodЁЃЫљвдВХГіЯжСЫетбљЕФЧщПіЁЃ
livenessProbe:
failureThreshold: 3
httpGet:
path: /actuator/health
port: 9902
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
ЪзЯШЮвУЧЪЧЯШЕїДѓСЫжиЦєЕФЗўЮёЕФTomcatВЂЗЂСЌНгЪ§ЕН500,ЕЋЪЧЗЂЯжСЫвЛЕу,МДЪЙСЌНгЪ§Дг200ЩЯЩ§ЕНСЫ500,ЗўЮёвРОЩдкВЛЖЯжиЦєЕБжаЁЃ
ФЧУДОЭдйРДХХВщЪЧЪВУДеМгУСЫШчДЫЖрЕФСЌНгЪ§,УПМфИє20ЗжжгГіЯжвЛДЮ,ЛљБОЩЯФмЙЛШЗЖЈЪЧФГИіЖЈЪБШЮЮёв§Ц№ЕФ,дйВщПДGrafanaЩЯЯрЙиhttpЧыЧѓЕїЖШЦЕТЪ,зюжеЖЈЮЛЕНСЫЮЪЬт,ЭЌЪБПДЕНФЧБпЕФДњТыаДЗЈвВЪЧгаЮЪЬтЕФЁЃ
3ЁЂtomcatЯпГЬГигыЪ§ОнПтСЌНгГи
БОРДЪЧвЛИівЊХњСПЛёШЁЪ§ОнЕФЙІФм,гЩгкжЎЧАОЭДцдкСЫfeignClientЕФВщбЏЕЅИіЪ§ОнЕФНгПк,гкЪЧетРяЮЊСЫЭМЗНБу,БужБНгЪЙгУСЫетИіНгПк,ЖјВЛЪЧаТдівЛИіХњСПВщбЏЪ§ОнЕФНгПкЁЃе§КУгжЪЧвђЮЊЖрДЮЕФВщбЏБШНЯТ§,ЫљвдИУЭЌЪТЪЙгУСЫЖрЯпГЬвьВНЕФЗНЪНШЅЛёШЁЪ§Он,УПгавЛИіid,ЖМЛсПЊЦєвЛИіЯпГЬШЅВщбЏ,ЕБгаМИАйЩЯЧЇЬѕЪ§ОнЕФЪБКђ,ОЭЛсгаДѓСПЕФЯпГЬЭЌЪБЧыЧѓЙ§ШЅ,ДгЖјдьГЩСЫФПБъЗўЮёЕФTomcatСЌНгЪ§ВЛзуЕФЮЪЬтЁЃ
вЕЮёДњТыРрЫЦЯТУцЪОР§:
for (int i = 0; i < list.size(); i++) {
CompletableFuture<String> future=CompletableFuture.runAsync(()->
//ЕїгУжиЦєЗўЮёЕФНгПк
);
}
ЕЋЪЧгавЛИіЮЪЬтОЭЪЧ,TomcatВЂЗЂСЌНгЪ§ЬсИпЕНСЫ500СЫ,вЛИіНгПкЗУЮЪВЛЕН1УыжгЕФЪБМф,зюЖрвВВЛЙ§МИАйЩЯЧЇЕФЧыЧѓДЮЪ§,АДРэРДЫЕдкМИУыжЎФкДІРэЭъетаЉЧыЧѓ,ВЛгІИУЛсдйГіЯжетбљЕФЧщПіВХЖд,ШЛЖјk8sдкСЌајЕФШ§ДЮДцЛюЬНВтжавРШЛЖМжБНгГЌЪБСЫЁЃФЧУДГ§СЫTomcatВЂЗЂСЌНгЪ§,ЛЙгаЪВУДЛсЭЯТ§ЧыЧѓФи?
ЫљвдОЭХХВщЕНСЫЪ§ОнПтзюДѓСЌНгЪ§,ФПЧАЪ§ОнПтЕФзюДѓСЌНгЪ§БЛЩшжУГЩСЫ20,ВЛТлФуTomcatСЌНгЪ§ЩшжУЕФЖрДѓ,ЯЕЭГЕФадФмжЕШЁОігкзюЖЬАхЕФЕиЗН,ЖјетИіОЭЪЧЪ§ОнПтзюДѓСЌНгЪ§,гЩгкЮвУЧЕФЯЕЭГЪЧTOBЗўЮё,етИіЗўЮёЪЧВщбЏКЭвЕЮёЖдНгЕФ,вГУцЖдНгЕФаХЯЂ,ВЂВЛЪЧДІРэЪ§ОнЕФЗўЮё,вђДЫДѓМвжЎЧАвВУЛгаЖдетИіЗўЮёЕФХфжУгаЙ§ЬЋЖрЙизЂ,ВХЕМжТСЫетжжЧщПіЁЃФЧУДЪзЯШвЊзіЕФОЭЪЧЬсИпЪ§ОнПтСЌНгГизюДѓСЌНгЪ§ЕН100,ЭЌЪБНЋФЧИівьВНЖрДЮЕїгУНгПкЕФЖЈЪБШЮЮёНјаагХЛЏ,ОЭНтОіетИіЮЪЬтСЫЁЃ
4ЁЂЖбеЛаХЯЂгыJprofileЕФЪЙгУ
Г§СЫЖдСЌНгГиЕШзіСЫвЛаЉХХВщжЎЭт,ЭЌЪБЮвУЧЛЙЖдJVMЖбФкДцНјааСЫЗжЮі,ХХГ§JVMЕФЮЪЬтЁЃ
ЦфЪЕвЛАуЧщПіЯТЕБЗЂЩњФкДцЮоЗЈе§ГЃЛиЪеЕФЧщПі,ЪЧФмЙЛжБНгдкЗўЮёШежОжаПДЕН java.lang.OutOfMemoryError: Java heap spaceЕФЖдФкДцвчГіЕФШежОЕФ,вђДЫжЛашвЊДђПЊJVM heap dump on out of memoryЕФВЮЪ§МДПЩ,ФЧУДдкЗЂЩњЖбФкДцвчГіЪБ,ОЭЛсНЋЕБЪБЕФПьееБЃДцЯТРДЁЃ
ВЛЙ§ЮвУЧФЧднЪБУЛгаГіЯжФкДцвчГіЕФДэЮѓШежОЁЃвЛИіОЭЪЧПМТЧЕНЗЂЩњФкДцвчГі,ЮвМЧЕУЪЧдкЖрЩйДЮGCжЎФкЛиЪеТЪаЁгкФГИіЙЬЖЈуажЕжЎКѓВХЛсХзГівьГЃ,ЫќВЂВЛЪЧвЛЫВМфОЭЛсЗЂЩњЕФ,ЫљвдФЧУДЛсВЛЛсдкетжЎЧАk8sОЭНЋPodжиЦєСЫФивВЫЕВЛзМЁЃ
ЮвУЧбЁШЁСЫPODжиЦєЧАЯІЕФЧщПізїЮЊПьееЪжЖЏЕМСЫГіРДНјааЗжЮіЁЃЪЙгУJProfilerЙЄОпНјааЗжЮіЁЃ
ЛљБОЩЯжЛашвЊПДСНИіЖЋЮїОЭааСЫЁЃ
вЛИіЪЧеМгУФкДцКЭЪ§СПзюЖрЕФЪЧФФаЉРр,гШЦфЪЧЙизЂЦфжаКЭЮвУЧвЕЮёЯрЙиЕФРр:
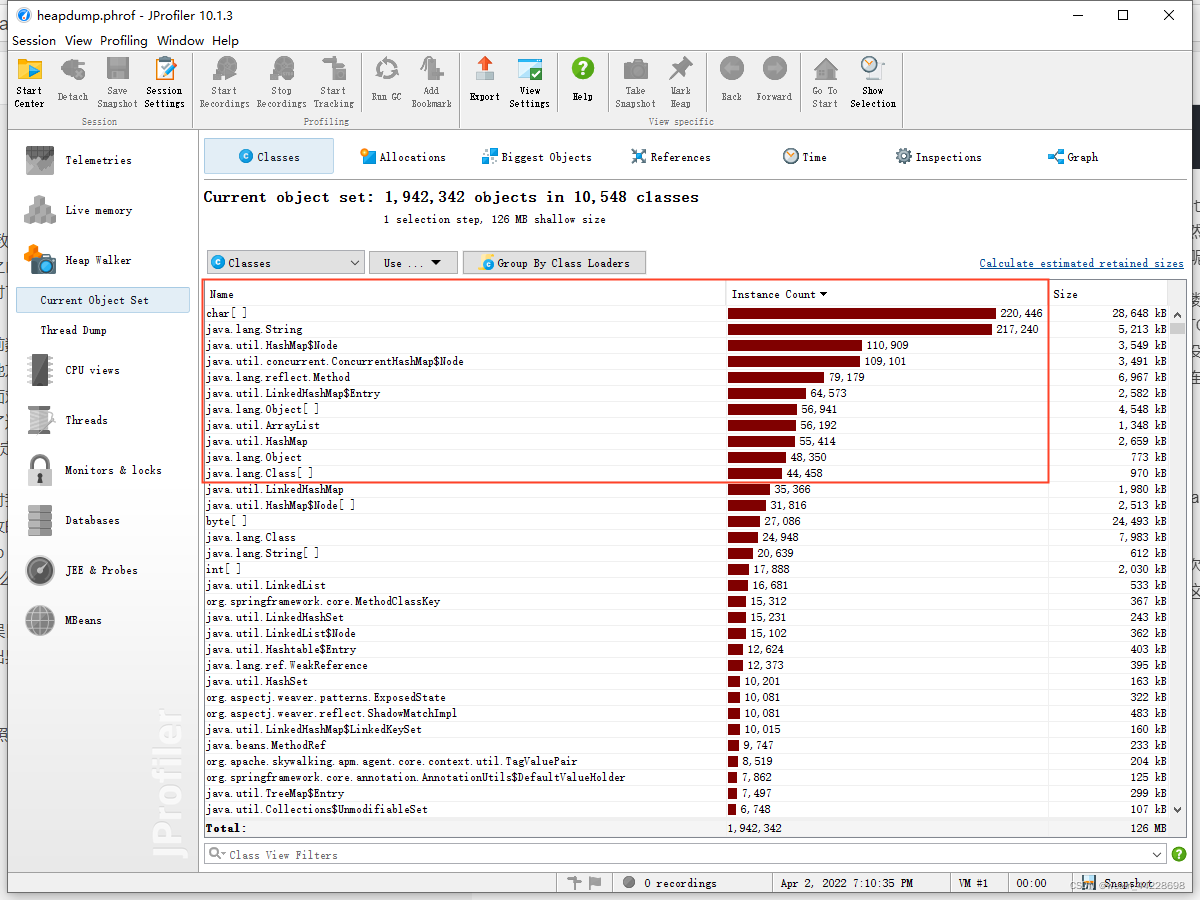
ЛЙгавЛИіОЭЪЧЙизЂДѓЖдЯѓ,етвВЪЧзюжЕЕУЙизЂЕФ:
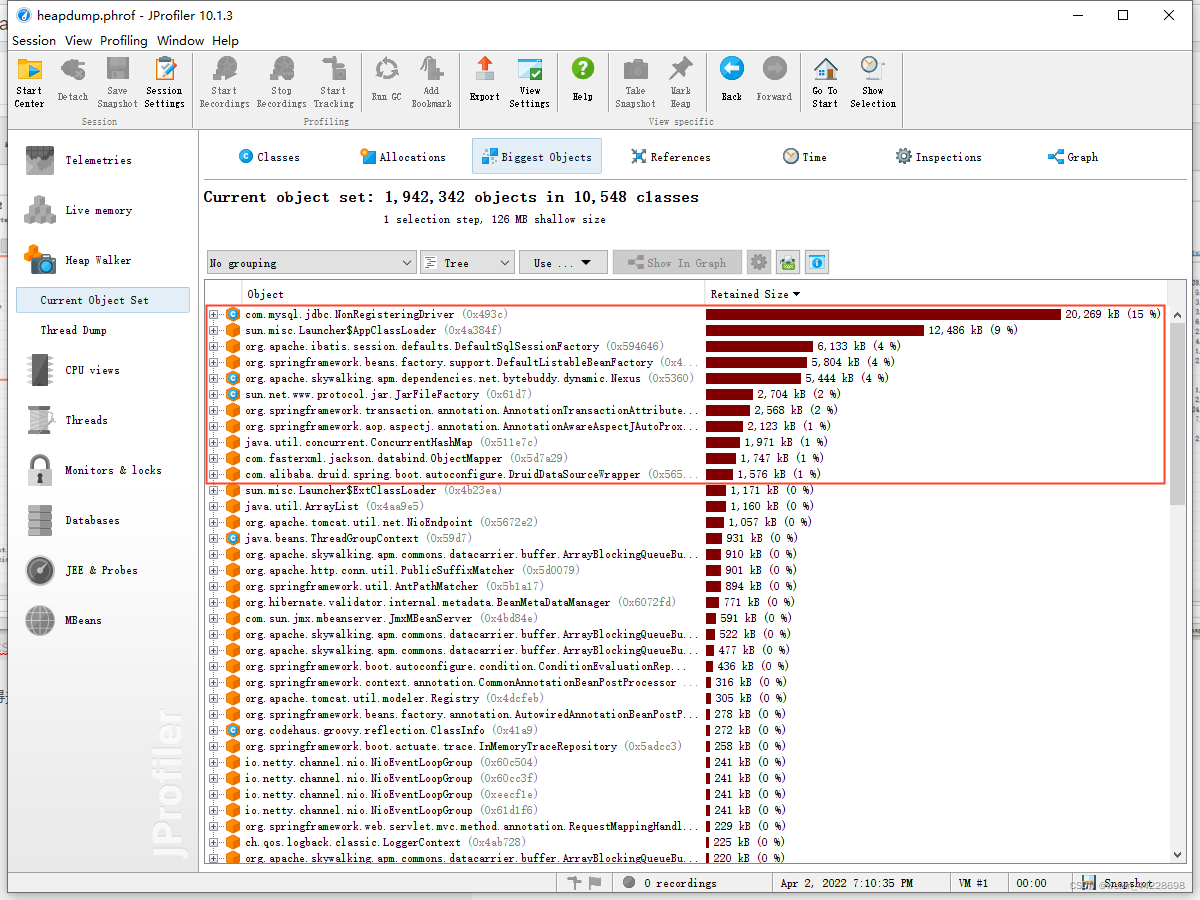
ПЩвдПДЕН,ЩЯЪіЭМЦЌЛљБОЯдЪОСЫетаЉЖдЯѓЛљБОУЛгаКЭЮвУЧвЕЮёЯрЙиЕФРр,ШчЙћетЪЧheap dump on out of memoryФУГіРДЕФПьее,ЖјФГаЉвЕЮёЯрЙиРреМСЫКмДѓФкДцКЭЪ§СП,ФЧетОЭЪЧЮвУЧМЋЮЊашвЊЙизЂЕФЁЃ
дйОЭЪЧBiggest ObjectsетеХЭМ,ВњЩњФкДцвчГіЕФдвђ,ЛљБООЭжБНгдкетРяУцСЫ,вђЮЊЕМжТФкДцвчГіЕФжБНгдвђОЭЪЧвђЮЊгаДѓЕФЖдЯѓВЛФмЙЛМДЪЙЛиЪе,ЯждкЛљБОЖдЯѓЛиЪеЖМЪЧПЩДяадЗжЮіЗЈ,ЩЯУцЕФзюДѓРрЛљБОвВОЭЪЧДѓСПЖдЯѓЕФИљв§гУЫљдк,ЯТУцЙвСЫвЛДѓШКвђДЫЖјВЛФмЛиЪеЕФЖдЯѓ,ЮвУЧПЩвджБНгЕуЛївЛжБЭљЯТ,ХХВщЕНгывЕЮёДњТыжаЯрЙиЕФдвђЁЃ
вђЮЊЮветРяВЂУЛгаЗЂЩњФкДцвчГі,ОЭФУspringЯТЕФDefaultListableBeanFactoryМђЕЅОйИіР§зг
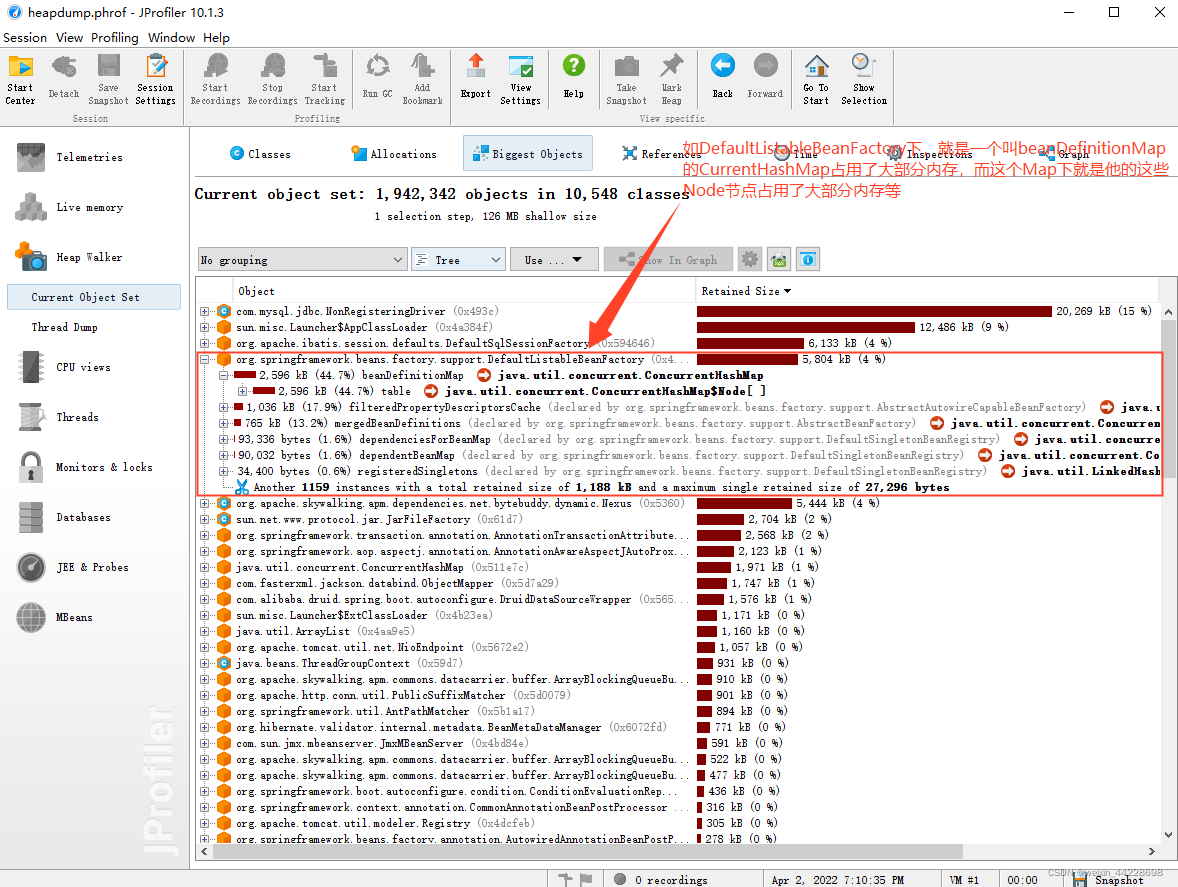
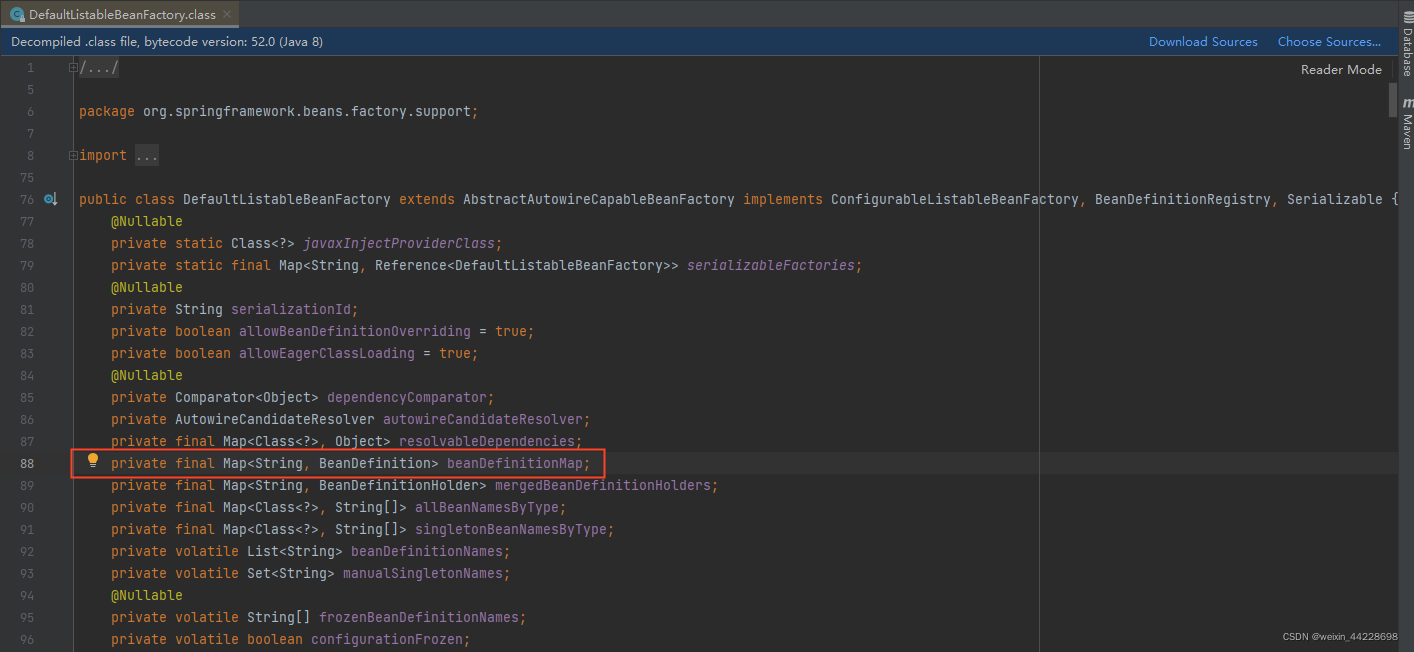
ШчDefaultListableBeanFactoryЯТДѓВПЗжЕФФкДцеМгУОЭЪЧетИіbeanDefinitionMapЕФHashMapЫљеМгУЕФФкДц,етИіMapЯТгжЪЧгЩЫћЕФNodeНкЕуеМгУСЫДѓВПЗжФкДцЁЃ
ЮвУЧПЩвджБНгдкJprofilerжаЕуЛї+КХвЛжБЭљЯТев,ОЭКмШнвзДгИљНкЕувЛжБбзХв§гУСДевЕНгыЮвУЧвЕЮёДњТыЯрЙиЕФЮЪЬтЕудкФФСЫЁЃ

