���ݹ�˾ҵ������,��Ŀ��Ҫ��д����,���Լ�¼�¶�д����Ĺ��̡�
����������:
1.��Ŀ�Ķ�д���롣
2.mysql���ݿ�����Ӹ��ơ�
��ƪʹ�õ�������Ϊsharding-jdbc-spring-boot-starter,Ҳ�п���ֱ����dynamic-datasource-spring-boot-starter,������Ҫ�ڳ�������ʽ��������ָ��������Դ,�����ڴӿ�>=2 ��ʱ����Ҫ�Լ�д�㷨���ж����ѡ��sharding-jdbc֧�ֶ���ĸ��ؾ������,sharding��������Ĺؼ������Q���Ƕ���������д����
Insertѡ������
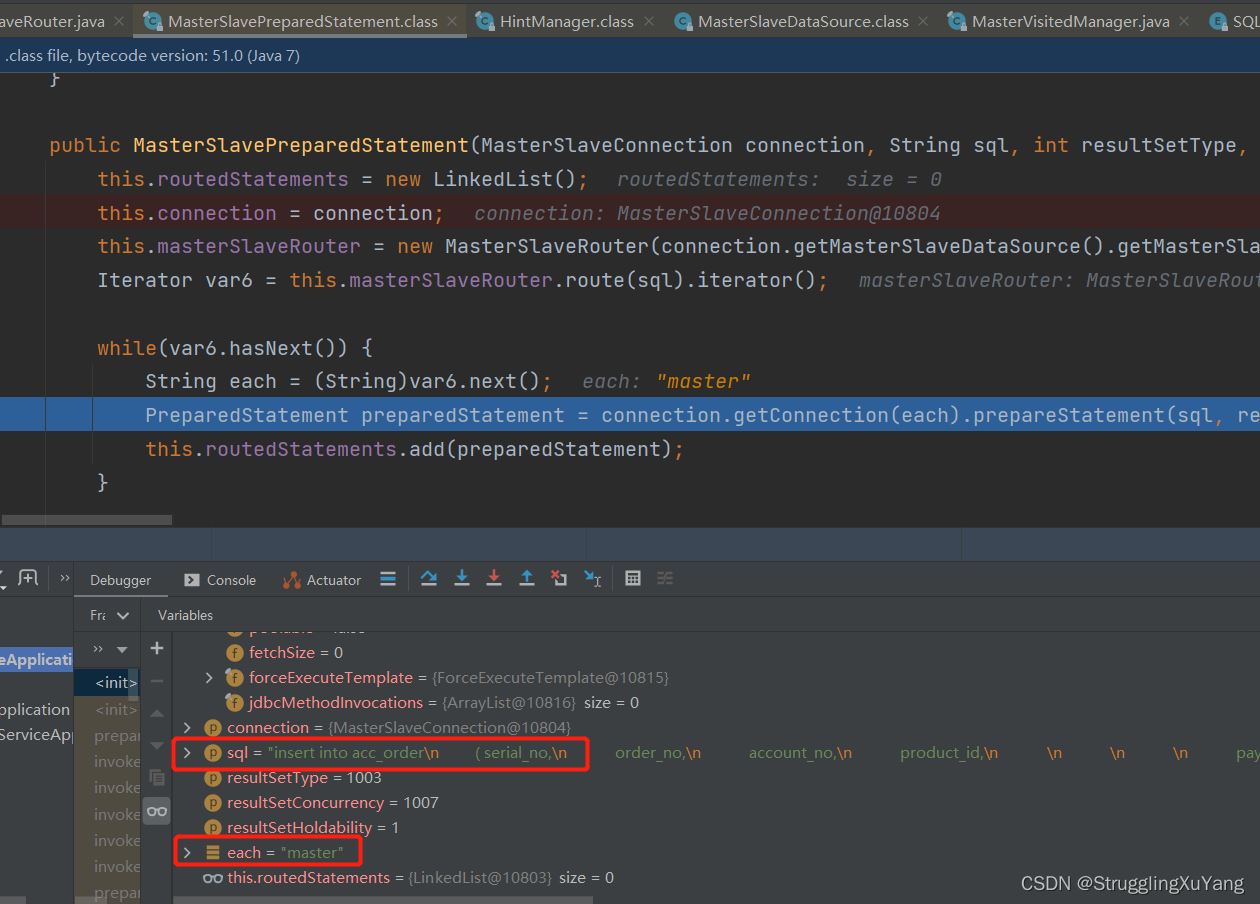
Selectѡ��ӿ�2(�������õ�����ѯ,������һ�ξ��Ǵӿ�1)
1.��Ŀ��������
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2.yml����
������̨����,
����һ̨(127.0.0.1)
�ӿ���̨(192.168.1.5 192.168.1.6)
spring:
shardingsphere:
props:
sql:
show: false
sharding:
default-data-source-name: master
masterslave:
name: ms
master-data-source-name: master
slave-data-source-names: slave1,slave2
#����slave�ڵ�ĸ��ؾ���������,������ѯ����
load-balance-algorithm-type: round_robin
datasource:
names: master,slave1,slave2
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/life_account_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
maxPoolSize: 100
minPoolSize: 5
slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.1.5:3306/life_account_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: test
password: Houxuyang123!@#
maxPoolSize: 100
minPoolSize: 5
slave2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.1.6:3306/life_account_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: test
password: Houxuyang123!@#
maxPoolSize: 100
minPoolSize: 5
3.����

4.����
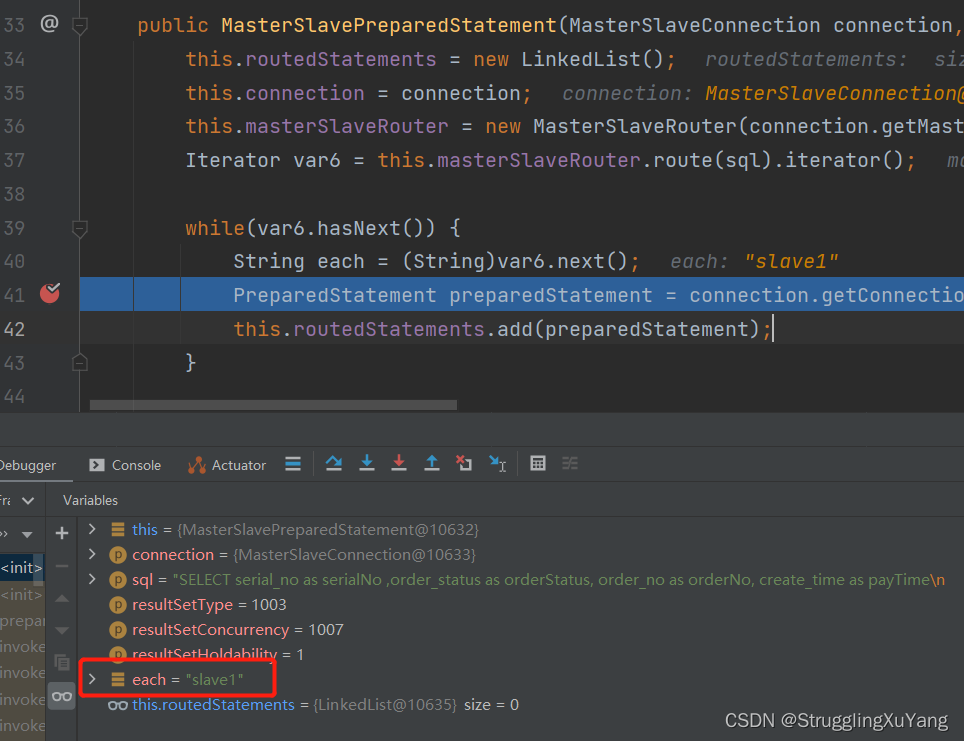
��һ�ζ�����(�ӿ�1)
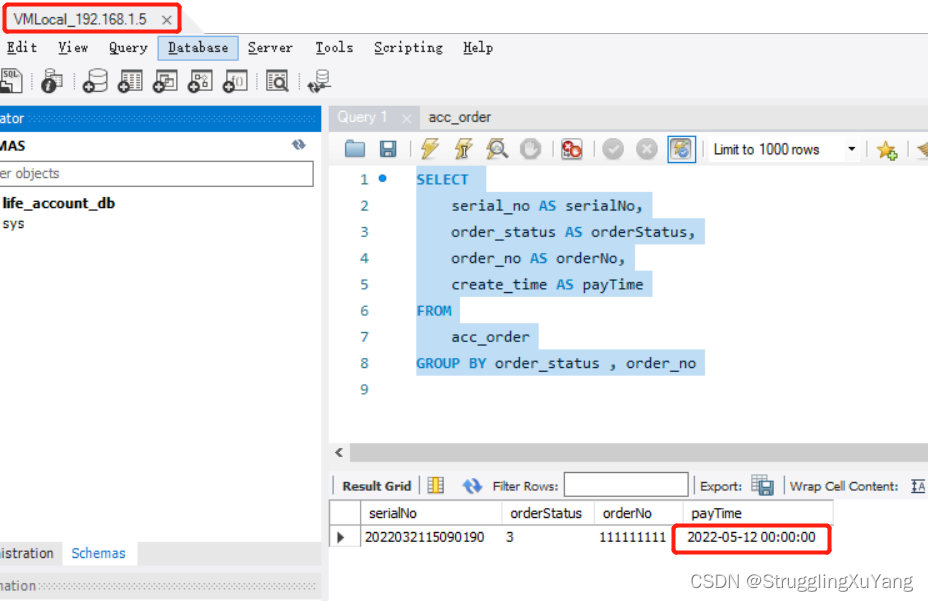
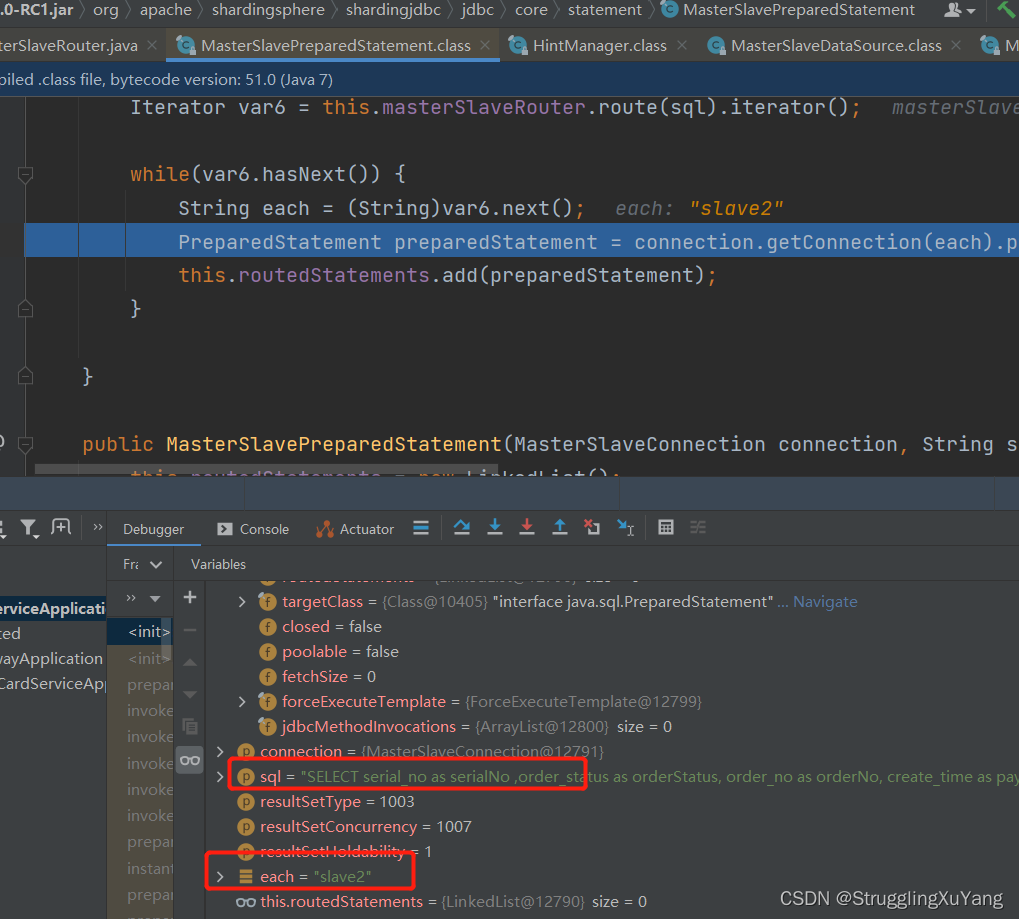
�ڶ��ζ�����(�ӿ�2)
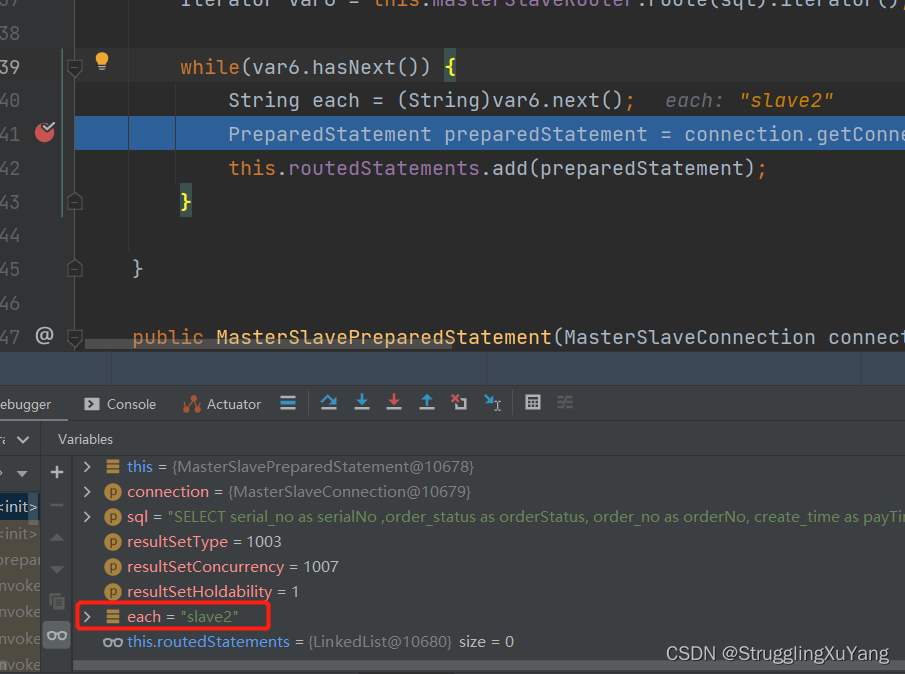
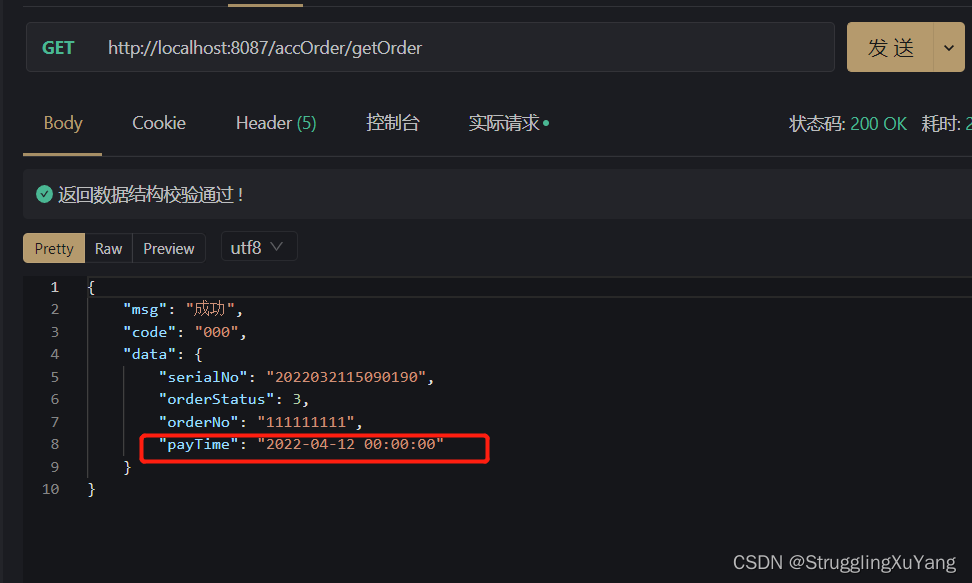
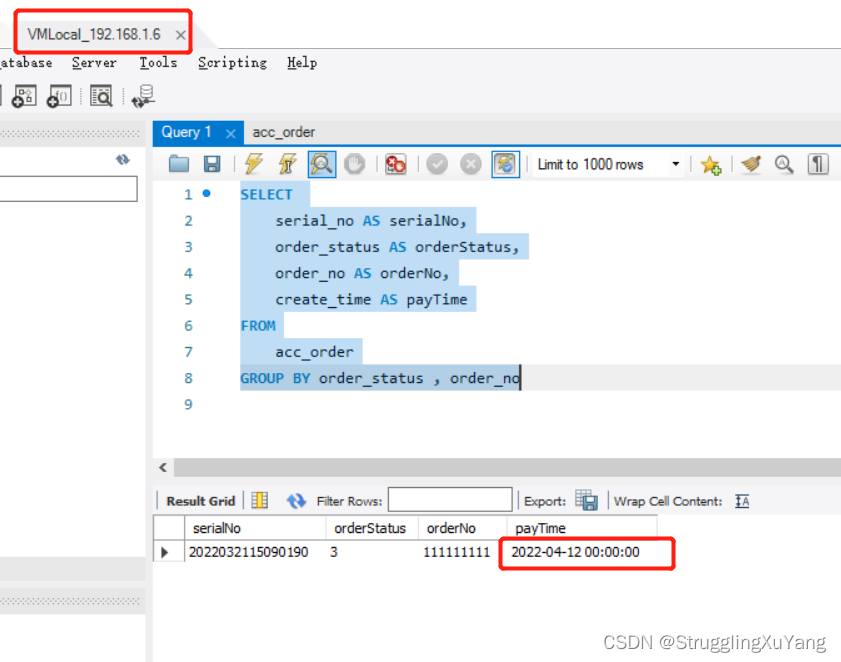
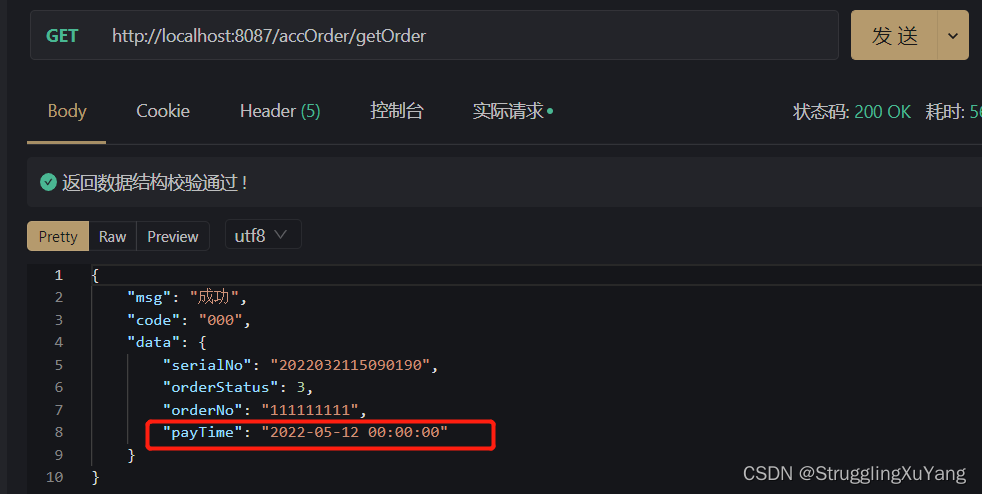
����д
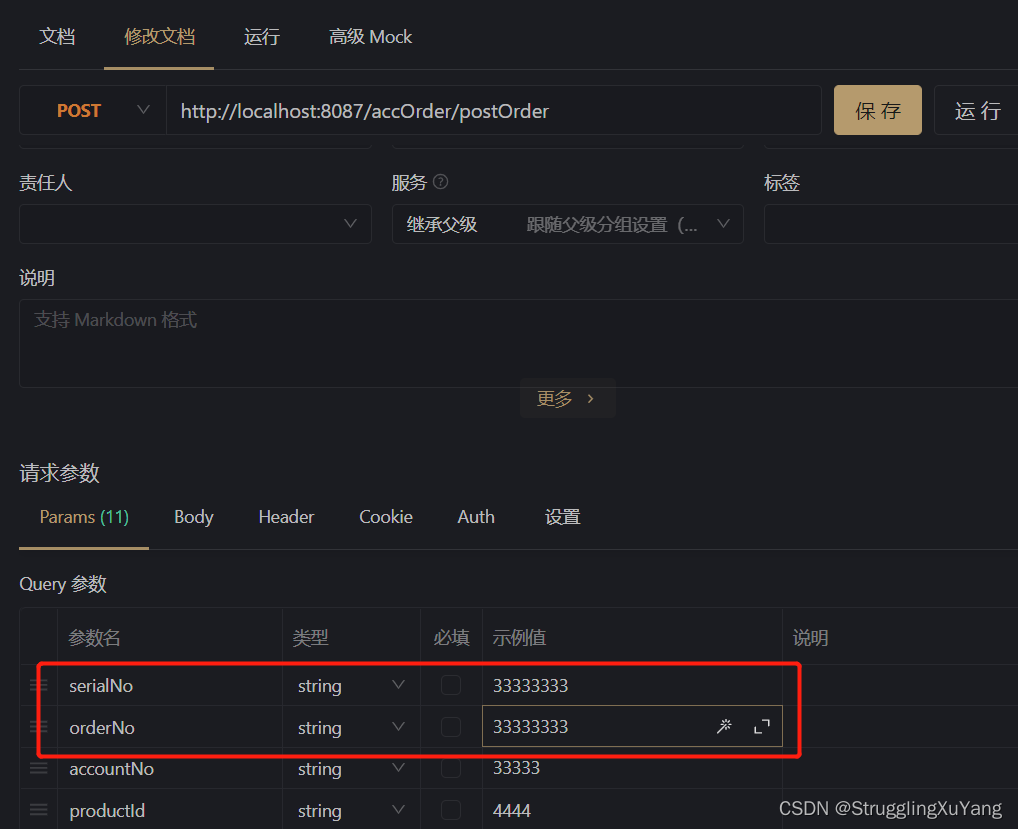

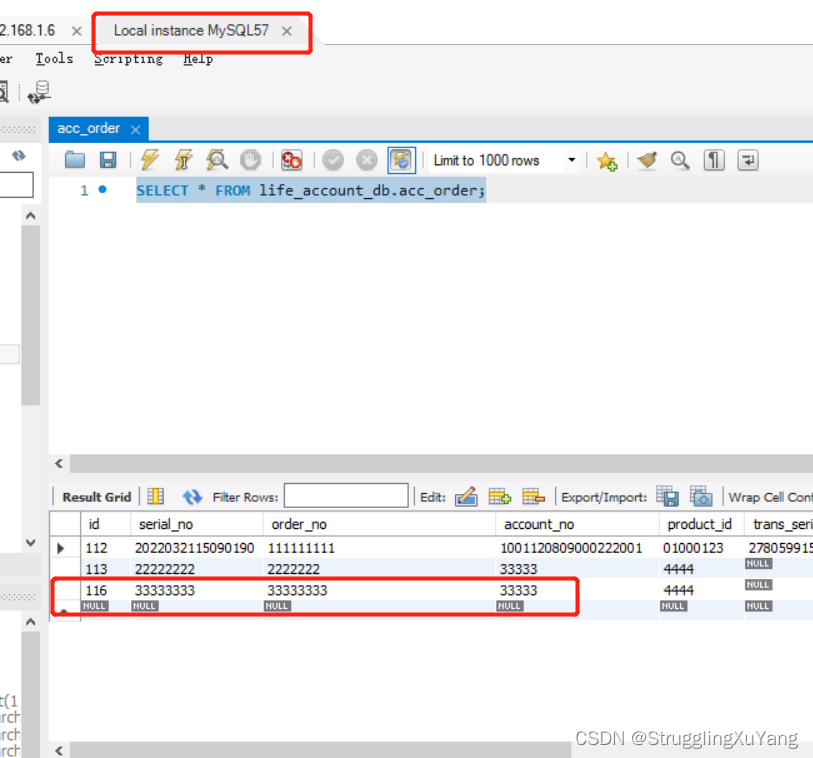
��Ŀ��д�������ʵ�֡�
5.�������������
mysql��ѯ����
Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'life_account_db.acc_order.serial_no' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
ԭ��:
û����ѭԭ���sql�ᱻ��Ϊ�Dz��Ϸ���sql
1.order by������б�������select������ڵ�
2.select��having��order by������ڵķǾۺ��б���ȫ����group by�д���
�������:
�������ļ�:vim /etc/my.cnf
����:sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
����mysql:systemctl restart mysqld
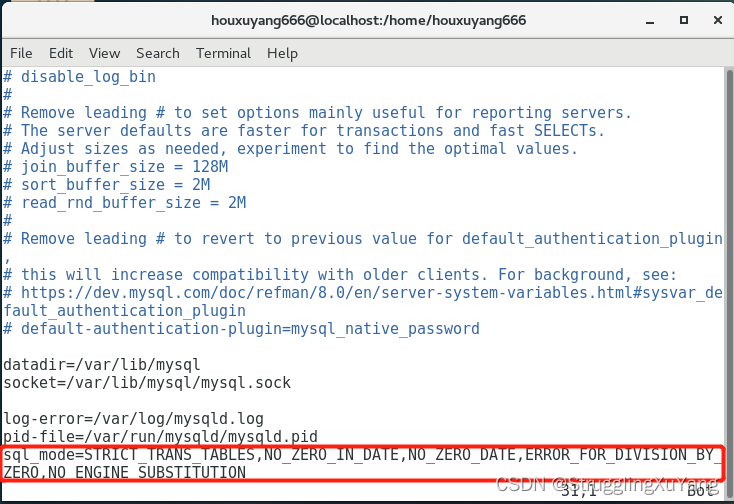
:wq

