��һ�� ����Ľ���
1.1ϵͳ�ܹ��ݱ�
���Ż������ķ�չ,��վӦ�õĹ�ģҲ�ڲ��ϵ�����,��������ϵͳ�ܹ�Ҳ�ڲ��ϵĽ��б仯�� �ӻ�������������,ϵͳ�ܹ����徭�������漸������: ����Ӧ�üܹ���>��ֱӦ�üܹ���>�ֲ�ʽ�ܹ���>SOA�ܹ���>����ܹ�,��Ȼ������Ȼ�����Service Mesh(��������)��
���������Ǿ����˽�һ��ÿ��ϵͳ�ܹ���ʲô���ӵ�, �Լ�����ʲô��ȱ�㡣
1.1.1����Ӧ�üܹ�
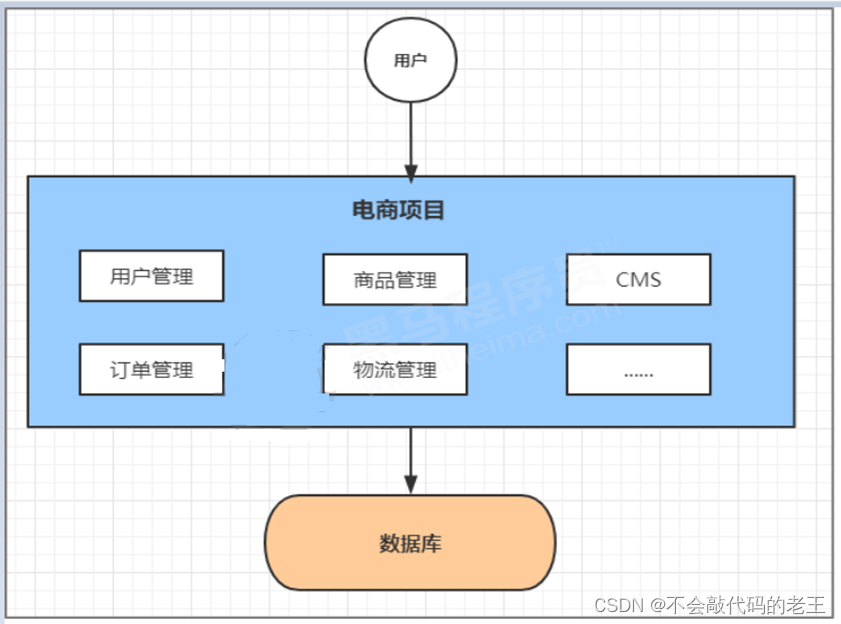
����������,һ�����վӦ��������С,ֻ��һ��Ӧ��,�����й��ܴ��붼������һ��Ϳ���,�������Լ��ٿ����������ά���ijɱ���
����˵һ������ϵͳ,���������ܶ��û�����,��Ʒ����,��������,���������ȵȺܶ�ģ��, ���ǻ����������һ��web��Ŀ,Ȼ����һ̨tomcat�������ϡ�
�ŵ�:
-
��Ŀ�ܹ���,С����Ŀ�Ļ�,�����ɱ��͡�
-
��Ŀ������һ���ڵ���,ά������
ȱ��:
-
ȫ�����ܼ�����һ��������,���ڴ�����Ŀ������������ά��[�Ĵ���]��
-
��Ŀģ��֮��������,�����ݴ��ʵ͡�
-
����Բ�ͬģ�����������Ż���ˮƽ��չ
1.1.2��ֱӦ�üܹ�
���ŷ�������������,��һӦ��ֻ���������ӽڵ���Ӧ��,������ʱ��ᷢ�ֲ��������е�ģ�� �����бȽϴ�ķ�����.
����������ĵ���Ϊ����, �û������������ӿ���Ӱ���ֻ���û��Ͷ���ģ��, ���Ƕ���Ϣģ���Ӱ��ͱȽ�С. ��ô��ʱ����ϣ��ֻ�����Ӽ�������ģ��, ����������Ϣģ��. ��ʱ����Ӧ�þ���������, ��ֱӦ�þ�Ӧ�˶�����.
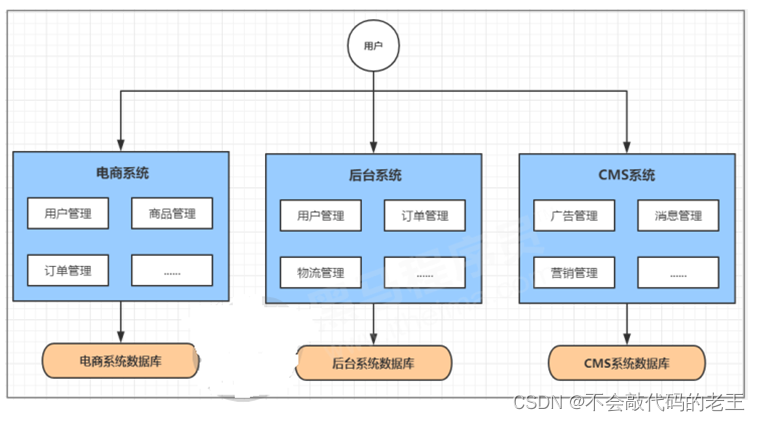
��ν�Ĵ�ֱӦ�üܹ�,���ǽ�ԭ����һ��Ӧ�ò�ɻ�����ɵļ���Ӧ��,������Ч�ʡ��������ǿ� �Խ�������̵ĵ���Ӧ�ò�ֳ�:
����ϵͳ(�û����� ��Ʒ���� ��������)
��̨ϵͳ(�û����� �������� �ͻ�����)
CMSϵͳ(������ Ӫ������)
����������֮��,һ���û����������,ֻ��Ҫ���ӵ���ϵͳ�Ľڵ�Ϳ�����,���������Ӻ�̨ ��CMS�Ľڵ㡣�����������̡�
�ŵ�:
-
ϵͳ���ʵ���������ֵ�,����˲�������,������Բ�ͬģ������Ż���ˮƽ��չ
-
һ��ϵͳ�����ⲻ��Ӱ�쵽����ϵͳ,����ݴ���
ȱ��:
-
ϵͳ֮�������, �����������
-
ϵͳ֮�������, �����ظ��Ŀ�������
1.1.3�ֲ�ʽ�ܹ�
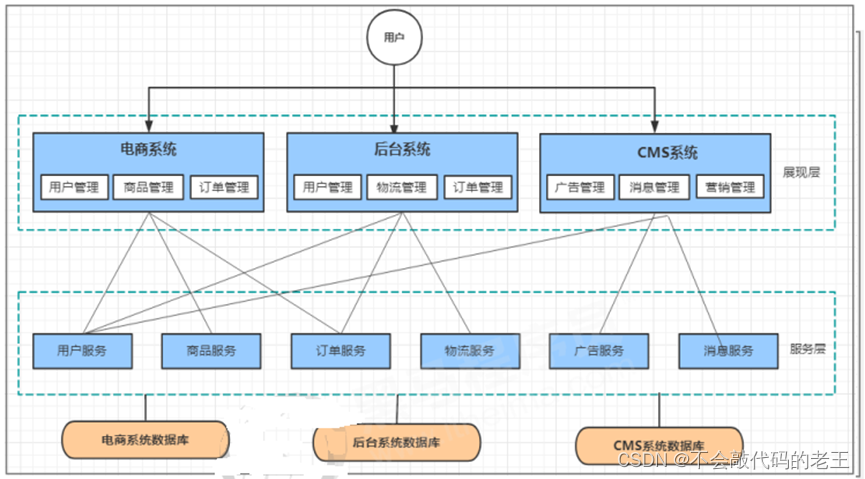
����ֱӦ��Խ��Խ��,�ظ���ҵ�����ͻ�Խ��Խ�ࡣ��ʱ��,���Ǿ�˼���ɲ����Խ��ظ��Ĵ��� ��ȡ����,����ͳһ��ҵ�����Ϊ�����ķ���(service),Ȼ����ǰ�˿��Ʋ�(controller)���ò�ͬ��ҵ��������?
��Ͳ������µķֲ�ʽϵͳ�ܹ��������ѹ��̲�ֳɱ��ֲ�ͷ������������,������а���ҵ�� �������ֲ�ֻ��Ҫ������ҳ��Ľ���,ҵ�������ǵ��÷����ķ�����ʵ�֡�
�ŵ�:
- ��ȡ�����Ĺ���Ϊ�����,��ߴ��븴����
ȱ��:
- ϵͳ����϶ȱ��,���ù�ϵ���۸���,����ά��
1.1.4 SOA�ܹ�----����dubbo
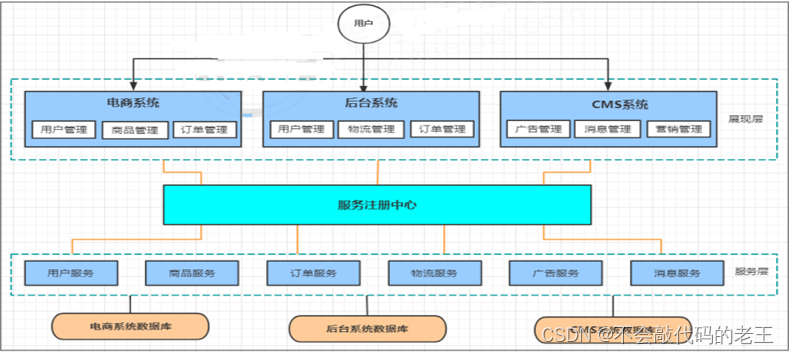
�ڷֲ�ʽ�ܹ���,������Խ��Խ��,����������,С������Դ���˷ѵ�����������,��ʱ������һ���������ĶԼ�Ⱥ����ʵʱ��������ʱ,������Դ���Ⱥ���������(SOA Service Oriented Architecture,�������ļܹ�)�ǹؼ���
�ŵ�:
- ʹ��ע�����Ľ���˷������ù�ϵ���Զ�����
ȱ��:
-
��������������ϵ,һ��ij�����ڳ�����Ӱ��ϴ�( ����ѩ�� )
-
������ĸ���,��ά�����Բ�������
1.1.5����ܹ�
����ܹ���ij�̶ֳ������������ļܹ�SOA������չ����һ��,������ǿ�������"���ײ��"---->����Ҫspringboot(������ϵͳ)
![[]{width="5.766666666666667in" height="3.091666666666667in"}](https://img-blog.csdnimg.cn/524e86a1659e4ad3be322701a8ef3705.png)
�ŵ�:
-
����ԭ�ӻ����,������������������,��֤ÿ����������������,������չ
-
����֮�����Restful��������httpЭ�������
ȱ��: С����Ŀ----����ܹ������ʡ��ֿ�ϵͳ������
- ����ϵͳ�����ļ����ɱ��ߡ��ߡ�(�ݴ����ֲ�ʽ�����)
1.2 ����ܹ�����
����ܹ�, ��˵���ǽ�����Ӧ�ý�һ�����,��ֳɸ�С�ķ���,ÿ��������һ�����Զ������е���Ŀ��
1.2.1 ����ܹ��ij�������
һ����������ϵͳ�ܹ�,���Ʊػ�����������������:
-
��ô��С����,��ι�������? ----����������Щ����
-
��ô��С����,����֮�����ͨѶ?
-
��ô��С����,�ͻ�����ô��������?
-
��ô��С����,һ������������,Ӧ������Դ���?
-
��ô��С����,һ������������,Ӧ������Ŵ�?
�������������,���κ�һ����������߶������ƹ�ȥ��,��˴ֵ������Ʒ�����ÿһ�������ṩ����Ӧ�������������ǡ�ϰ�߸��硪>���塪>����������ջ����>springcloud -------->
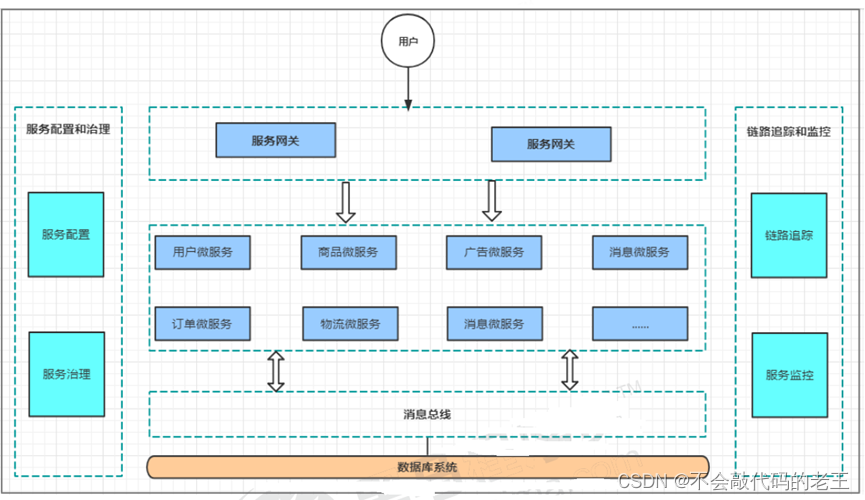
1.2.2����ܹ��ij�������
1.2.2.1 ��������
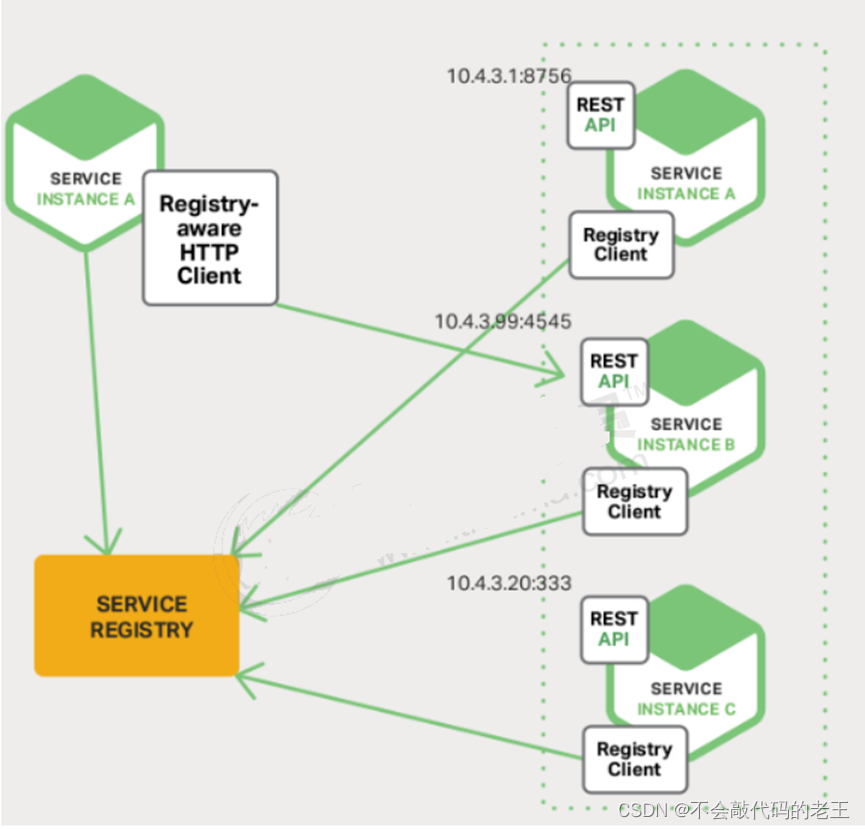
�����������ǽ��з�����Զ�������,������Ƿ�����Զ�ע���뷢�֡�
����ע��:����ʵ��������������Ϣע�ᵽע�����ġ�
������:����ʵ��ͨ��ע������,��ȡ��ע�ᵽ���еķ���ʵ������Ϣ,ͨ����Щ��Ϣȥ���������ṩ�ķ���
������:����ע�����Ľ�������ķ����Զ����������б�֮��,ʹ�䲻�ᱻ���õ���
1.2.2.2 �������
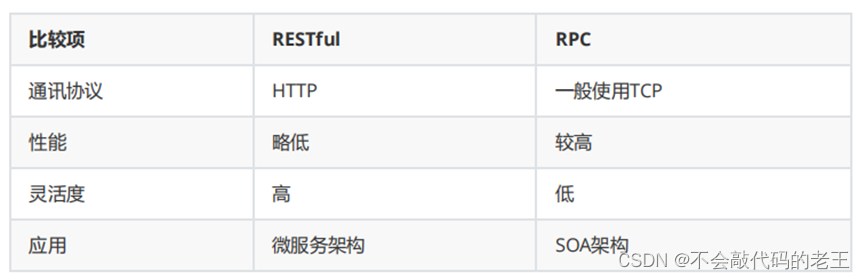
������ܹ���,ͨ�����ڶ������֮���Զ�̵��õ�����Ŀǰ������Զ�̵��ü����л���HTTP��RESTful�ӿ��Լ�����TCP��RPCЭ�顣
REST(Representational State Transfer)
����һ��HTTP���õĸ�ʽ,����,��ͨ��,�����������Զ�֧��httpЭ�顣
RPC(Remote Promote Call)
Rpc @Autowire Bservice bservice.����()
һ�ֽ��̼�ͨ�ŷ�ʽ����������ñ��ط���һ������Զ�̷���RPC��ܵ���ҪĿ�������Զ�̷�����ø�������RPC��ܸ������εײ�Ĵ��䷽ʽ�����л���ʽ��ͨ��ϸ�ڡ�������Ա��ʹ�õ�ʱ��ֻ��Ҫ�˽�˭��ʲôλ���ṩ��ʲô����Զ�̷���ӿڼ���,������Ҫ���ĵײ�ͨ��ϸ�ں͵��ù��̡�
��������ϵ
1.2.2.3 ��������
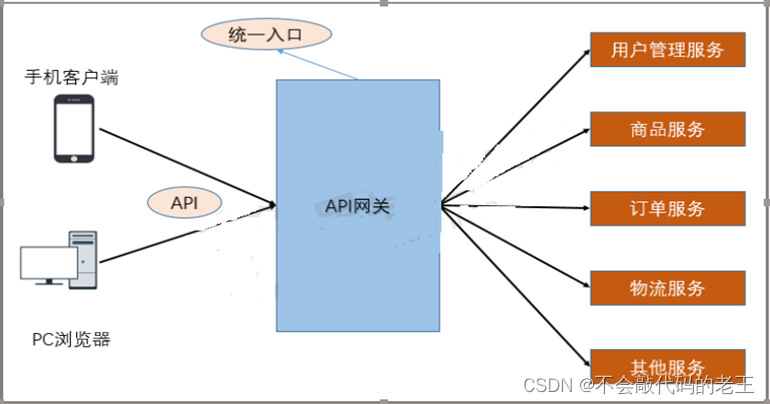
��������IJ�������,��ͬ������һ����в�ͬ�������ַ,���ⲿ�ͻ��˿�����Ҫ���ö������Ľӿڲ������һ��ҵ������,����ÿͻ���ֱ�����������ͨ�ſ��ܳ���:
-
�ͻ�����Ҫ���ò�ͬ��url��ַ,�����Ѷ�
-
��һ���ij�����,���ڿ������������
-
ÿ��������Ҫ���е�����������֤
�����Щ����,API����˳�ƶ�����
API����ֱ����˼�ǽ�����API����ͳһ���뵽API���ز�,�����ز�ͳһ����������һ�����صĻ���������:ͳһ���롢��ȫ������Э�����䡢�����ܿء���������֧�֡��ݴ���������������֮��,����API�����ṩ�Ŷӿ���רע���Լ��ĵ�ҵ��������,��API���ظ�רע�ڰ�ȫ��������·�ɵ����⡣
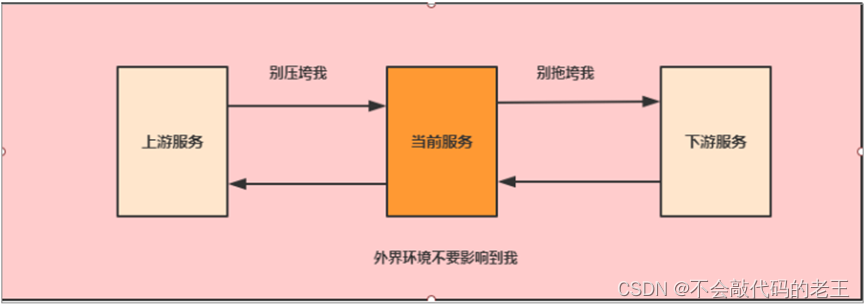
1.2.2.4 �����ݴ�
��������,һ���������漰�����ü�������,�������ij��������,û���������ݴ��Ļ�,���п��ܻ����һ�����ķ�����,�����ѩ��ЧӦ��
����û��Ԥ��ѩ��ЧӦ�ķ���,ֻ�ܾ�����ȥ�����ݴ��������ݴ�����������˼����:
-
������绷��Ӱ��
-
������������ѹ��
-
����������Ӧ�Ͽ�
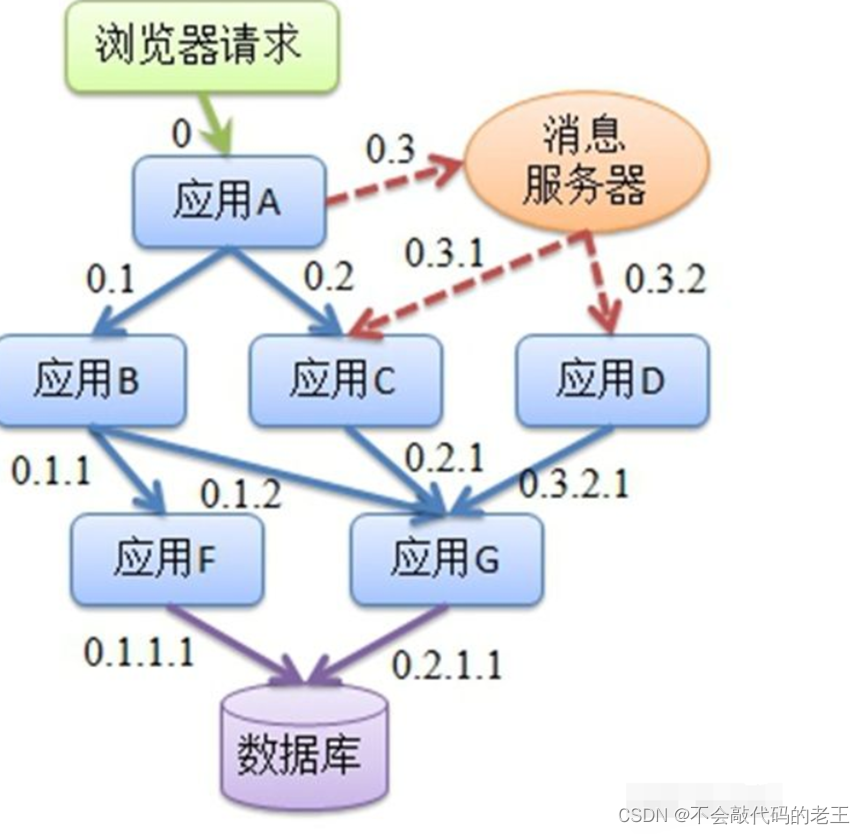
1.2.2.5 ��·��
��������ܹ�������,�����ղ�ͬ��ά�Ƚ��в��,һ������������Ҫ�漰�������������Ӧ�ù����ڲ�ͬ������ģ�鼯��,��Щ����ģ��,�п������ɲ�ͬ���Ŷӿ���������ʹ�ò�ͬ�ı��������ʵ�֡��п��ܲ����˼�ǧ̨������,�������ͬ���������ġ����,����Ҫ��һ�������漰�Ķ��������·������־��¼,���ܼ�ؼ���·��
1.2.3 ����ܹ��ij����������
1.2.3.1 ServiceComb

Apache ServiceComb,ǰ���ǻ�Ϊ�Ƶ��������� CSE (Cloud Service Engine) �Ʒ���,��ȫ����Apache������Ŀ�����ṩ��һվʽ������Դ�������,�����ڰ�����ҵ���û��Ϳ����߽���ҵӦ��������������,��ʵ�ֶ�����Ӧ�õĸ�Ч��ά����.
SpringCloud (springcloud �ܶ���������õ���Netflix��˾,��ҹ�˾��Щ���ֹͣά�����¡�)
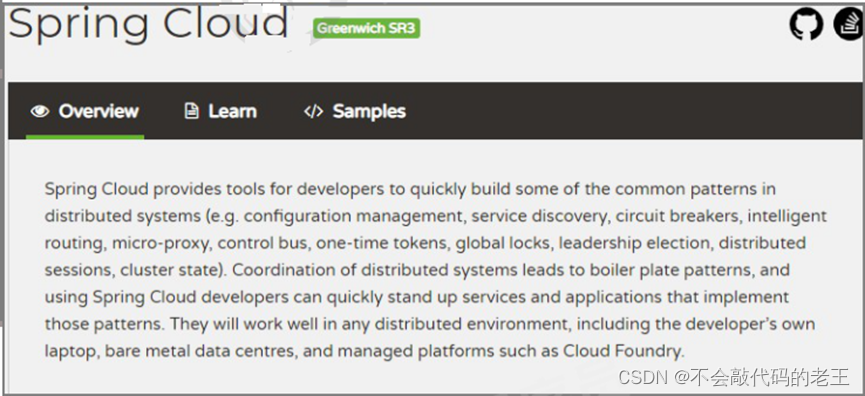
Spring Cloud��һϵ�п�ܵļ��ϡ�������Spring Boot�Ŀ�������������ؼ��˷ֲ�ʽϵͳ������ʩ�Ŀ���,�������ע�ᡢ�������ġ���Ϣ���ߡ����ؾ��⡢��·�������ݼ�ص�,��������Spring Boot�Ŀ����������һ�������Ͳ���
Spring Cloud��û���ظ���������,��ֻ�ǽ�Ŀǰ���ҹ�˾�����ıȽϳ��졢������ʵ�ʿ���ķ������������,ͨ��Spring Boot�������ٷ�װ���ε��˸��ӵ����ú�ʵ��ԭ��,���ո�������������һ�������ײ������ά���ķֲ�ʽϵͳ�������߰���
�Ѿ�ͣ���ˡ�Euruka(ע����),feignԶ�̵���,hystrix �ݴ�,zuul����
SpringCloud Alibaba(����springcloud�ܶ�����������ˡ�) springcloud alibaba

Spring Cloud Alibaba �������ṩ������һվʽ�������������Ŀ���������ֲ�ʽӦ������ı������,���㿪����ͨ�� Spring Cloud ���ģ������ʹ����Щ����������ֲ�ʽӦ�÷���
1.3 SpringCloud Alibaba����
Spring Cloud Alibaba �������ṩ������һվʽ�������������Ŀ���������ֲ�ʽӦ������ı������,���㿪����ͨ�� Spring Cloud ���ģ������ʹ����Щ����������ֲ�ʽӦ�÷���
���� Spring Cloud Alibaba,��ֻ��Ҫ����һЩע�����������,�Ϳ��Խ� Spring Cloud Ӧ�ý��밢������������,ͨ�������м����Ѹ�ٴ�ֲ�ʽӦ��ϵͳ��
1.3.1 ��Ҫ����
������������:Ĭ��֧�� WebServlet��WebFlux, OpenFeign��RestTemplate��Spring Cloud
Gateway, Zuul, Dubbo �� RocketMQ �����������ܵĽ���,����������ʱͨ������̨ʵʱ��
��������������,��֧�ֲ鿴�������� Metrics ��ء�
����ע���뷢��:���� Spring Cloud ����ע���뷢�ֱ�nacos,Ĭ�ϼ����� Ribbon ��֧�֡�
�ֲ�ʽ���ù���:֧�ֲַ�ʽϵͳ�е��ⲿ������,���ø���ʱ�Զ�ˢ�¡�
��Ϣ��������:���� Spring Cloud Stream Ϊ����Ӧ�ù�����Ϣ����������
�ֲ�ʽ����:ʹ�� @GlobalTransactional ע��, ��Ч���Ҷ�ҵ��������ؽ���ֲ�ʽ�������⡣
�����ƶ���洢:�������ṩ�ĺ�������ȫ���ͳɱ����߿ɿ����ƴ洢����֧�����κ�Ӧ�á���
��ʱ�䡢�κεص�洢�ͷ����������͵����ݡ�
�ֲ�ʽ�������:�ṩ�뼶�������߿ɿ����߿��õĶ�ʱ(���� Cron ����ʽ)������ȷ���
ͬʱ�ṩ�ֲ�ʽ������ִ��ģ��,������������������֧�ֺ�����������ȷ��䵽����
Worker(schedulerx-client)��ִ�С�
�����ƶ��ŷ���:����ȫ��Ķ��ŷ���,�Ѻá���Ч�����ܵĻ�����ͨѶ����,������ҵѸ�ٴ
�ͻ�����ͨ����
1.3.2 ���
Sentinel:��������Ϊ�����,���������ơ��۶Ͻ�����ϵͳ���ر����ȶ��ά�ȱ����������
���ԡ�
Nacos:һ�������ڹ�����ԭ��Ӧ�õĶ�̬�����֡����ù����ͷ������ƽ̨��
RocketMQ:һ�Դ�ķֲ�ʽ��Ϣϵͳ,���ڸ߿��÷ֲ�ʽ��Ⱥ����,�ṩ����ʱ�ġ��߿ɿ�
����Ϣ�����붩�ķ���
Dubbo:Apache Dubbo? ��һ������� Java RPC ��ܡ�
Seata:����ͰͿ�Դ��Ʒ,һ������ʹ�õĸ���������ֲ�ʽ������������
Alibaba Cloud ACM:һ���ڷֲ�ʽ�ܹ������ж�Ӧ�����ý��м��й��������͵�Ӧ����������
��Ʒ��
Alibaba Cloud OSS: �����ƶ���洢����(Object Storage Service,��� OSS),�ǰ�������
���ĺ�������ȫ���ͳɱ����߿ɿ����ƴ洢�������������κ�Ӧ�á��κ�ʱ�䡢�κεص�洢��
�����������͵����ݡ�
Alibaba Cloud SchedulerX: �����м���Ŷӿ�����һ��ֲ�ʽ������Ȳ�Ʒ,�ṩ�뼶����
���߿ɿ����߿��õĶ�ʱ(���� Cron ����ʽ)������ȷ���
Alibaba Cloud SMS: ����ȫ��Ķ��ŷ���,�Ѻá���Ч�����ܵĻ�����ͨѶ����,������ҵѸ��
��ͻ�����ͨ����
�ڶ��� �����
���DZ�����ʹ�õĵ�����Ŀ�е���Ʒ����������Ϊ�������н��⡣
2.1 ������
2.1.1 ����ѡ��
maven:3.5.0+
���ݿ�:MySQL 5.7 ����
�־ò�: Mybatis-plus ��Mybatis Mapper Mybatis-plus��
����: SpringCloud Alibaba ����ջ druid
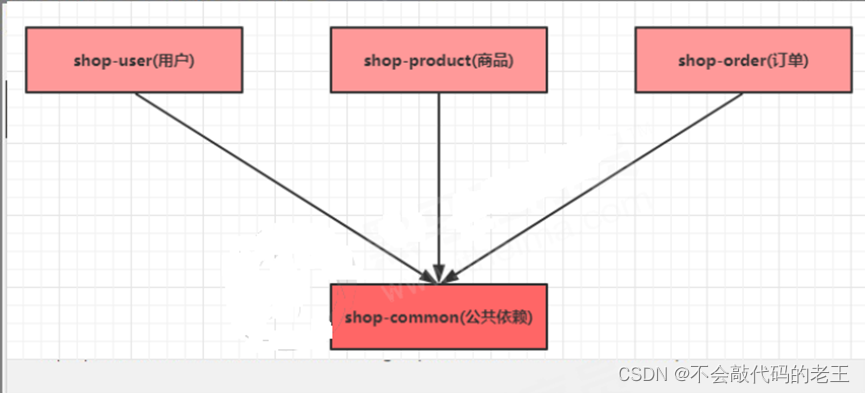
2.1.2 ģ�����
springcloud-alibaba ������ ��jar�汾�Ĺ�����
shop-common ����ģ�顾ʵ���ࡿ ��ʵ����,��������,�����ࡣ��
shop-product ��Ʒ���� ���˿�: 8080~8089 ���Ⱥ��
shop-order �������� ���˿�: 8090~8099 ���Ⱥ��
2.1.3 �������
������ܹ���,����ij�����������֮�������á������Ե���ϵͳ�г������û��µ�Ϊ������ʾ����ĵ���:�ͻ���������һ���µ�������,�ڽ��б��涩��֮ǰ��Ҫ������Ʒ�����ѯ��Ʒ����Ϣ��
����һ��ѷ�����������÷���Ϊ����������,�ѷ���ı����÷���Ϊ�����ṩ����

�����ֳ�����,�����������һ������������, ��Ʒ�������һ�������ṩ�ߡ�
2.2 ����������
����һ��maven����,Ȼ����pom.xml�ļ���������������
ע��:��ʱ��˳���� Spring Cloud Alibaba �Լ���Ӧ������ Spring Cloud �� Spring Boot �汾��ϵ(���� Spring Cloud �汾�����е���,���Զ�Ӧ�� Spring Cloud Alibaba �汾��Ҳ���˶�Ӧ�仯),��Ϣ���¾�����Կ��·���ַ:
https://github.com/alibaba/spring-cloud-alibaba/wiki/�汾˵��
��ͼ������2022.05.21���¶��ձ�,֮��ʱ�佨��ο��Ϸ���ַ

<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.ykq</groupId>
<artifactId>springcloud-alibaba</artifactId>
<version>1.0-SNAPSHOT</version>
<!--���븸����-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.2.RELEASE</version>
</parent>
<!--����汾��-->
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF- 8</project.reporting.outputEncoding>
<spring-cloud.version>Hoxton.SR8</spring-cloud.version>
<spring-cloud-alibaba.version>2.2.3.RELEASE</spring-cloud-alibaba.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring-cloud-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>
2.3 ��������ģ��
1 ���� shop-common ģ��,��pom.xml����������
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>springcloud-alibaba</artifactId>
<groupId>com.ykq</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>shop-common</artifactId>
<!--��������-->
<dependencies>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.56</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
</project>
2 ����ʵ����
package com.ykq.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName("shop_order")
public class Order {
@TableId(type = IdType.AUTO)
private Long oid; //����id
private Integer uid;//�û�id
private String username;//�û���
private Integer pid;//��Ʒid
private String pname;//��Ʒ����
private Double pprice;//��Ʒ�۸�
private Integer number;//��������
}
package com.ykq.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
//��Ʒ
@Data
@TableName(value="shop_product")
public class Product {
@TableId(type= IdType.AUTO)
private Integer pid;
private String pname;//��Ʒ����
private Double pprice;//��Ʒ�۸�
private Integer stock;//���
}
2.4 �����û�����
����:
1 ����ģ�� ��������
2 ����SpringBoot����
3 ���������ļ�
4 ������Ҫ�Ľӿں�ʵ����(controller service dao)
�½�һ�� shop-user ģ��,Ȼ������������
1 ����pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>springcloud-alibaba</artifactId>
<groupId>com.ykq</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>shop-user</artifactId>
<!--����shop-commonģ�������-->
<dependencies>
<dependency>
<groupId>com.ykq</groupId>
<artifactId>shop-common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
</project>
2 �����
package com.ykq;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class UserApplication {
public static void main(String[] args) {
SpringApplication.run(UserApplication.class,args);
}
}
3 ���������ļ�
server:
port: 8071
spring:
application:
name: shop-user
# ��������Դ
datasource:
url: jdbc:mysql://localhost:3306/shop?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
jpa:
properties:
hibernate:
hbm2ddl:
auto: update
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
2.5 ������Ʒ����
1 ����һ����Ϊ shop_product ��ģ��,������springboot����
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>springcloud-alibaba</artifactId>
<groupId>com.ykq</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>shop-product</artifactId>
<dependencies>
<dependency>
<groupId>com.ykq</groupId>
<artifactId>shop-common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
</project>
2 �������̵�����
package com.ykq;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ProductApplication {
public static void main(String[] args) {
SpringApplication.run(ProductApplication.class,args);
}
}
3 ���������ļ�application.yml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/springcloud?serverTimezone=Asia/Shanghai
username: root
password: root
server:
port: 8080
4 ����ProductDao�ӿ�
package com.ykq.dao;
import com.ykq.domain.Product;
public interface ProductDao extends BaseMap<Product> {
}
5 ����ProductService�ӿ�
package com.ykq.service;
import com.ykq.domain.Product;
public interface ProductService {
public Product findById(Integer pid);
}
6 ����ProductServiceImplʵ����
package com.ykq.service.impl;
import com.ykq.dao.ProductDao;
import com.ykq.domain.Product;
import com.ykq.service.ProductService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private ProductDao productDao;
@Override
public Product findById(Integer pid) {
return productDao.findById(pid).get();
}
}
7 ����ProductController��
package com.ykq.controller;
import com.alibaba.fastjson.JSON;
import com.ykq.domain.Product;
import com.ykq.service.ProductService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@Slf4j
public class ProductController {
@Autowired
private ProductService productService;
@RequestMapping("/product/{pid}")
public Product product(@PathVariable(value = "pid")Integer pid){
Product product = productService.findById(pid);
log.info("��ѯ����Ʒ:" + JSON.toJSONString(product));
return product;
}
}
8 ��������,�ȵ����ݿ���������֮��,�����������
INSERT INTO shop_product VALUE(NULL,'��','1000','5000');
INSERT INTO shop_product VALUE(NULL,'��Ϊ','2000','5000');
INSERT INTO shop_product VALUE(NULL,'ƻ��','3000','5000');
INSERT INTO shop_product VALUE(NULL,'OPPO','4000','5000');
9.ͨ����������ʷ���
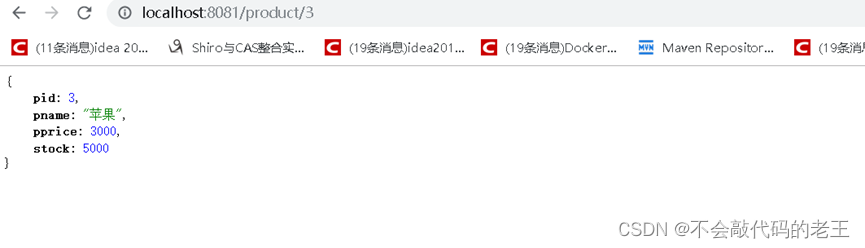
2.6 ������������
1 ����һ����Ϊ shop-order ��ģ��,������springboot����
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>springcloud-alibaba</artifactId>
<groupId>com.ykq</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>shop-order</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.ykq</groupId>
<artifactId>shop-common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
</project>
2 ����������
package com.ykq;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class,args);
}
}
3 ���������ļ�application.yml
server:
port: 8091
spring:
application:
name: shop-order
# ��������Դ
datasource:
url: jdbc:mysql://localhost:3306/shop?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
4 ����OrderDao�ӿ�
package com.ykq.dao;
import com.ykq.domain.Order;
import org.springframework.data.jpa.repository.JpaRepository;
public interface OrderDao extends BaseMapper<Order> {
}
5 ����OrderService�ӿ�
package com.ykq.service;
import com.ykq.domain.Order;
public interface OrderService {
public void save(Order order);
}
6 ����OrderServiceImplʵ����
package com.ykq.service.impl;
import com.ykq.dao.OrderDao;
import com.ykq.domain.Order;
import com.ykq.service.OrderService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderDao orderDao;
@Override
public void save(Order order) {
orderDao.save(order);
}
}
7 ����OrderController��
package com.ykq.controller;
import com.alibaba.fastjson.JSON;
import com.ykq.domain.Order;
import com.ykq.domain.Product;
import com.ykq.service.OrderService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
@Slf4j
public class OrderController {
@Autowired
private OrderService orderService;
@Autowired
private RestTemplate restTemplate;
@GetMapping("/order/prod/{pid}")
public Order order(@PathVariable("pid")Integer pid){
log.info(">>�ͻ��µ�,��ʱ��Ҫ������Ʒ�����ѯ��Ʒ��Ϣ");
Product product = restTemplate.getForObject("http://localhost:8081/product/" + pid, Product.class);
log.info(">>��Ʒ��Ϣ,��ѯ���:" + JSON.toJSONString(product));
Order order = new Order();
order.setPid(product.getPid());
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
order.setUid(1);
order.setUsername("asd");
orderService.save(order);
return order;
}
}
8 �������̲���������ϲ���
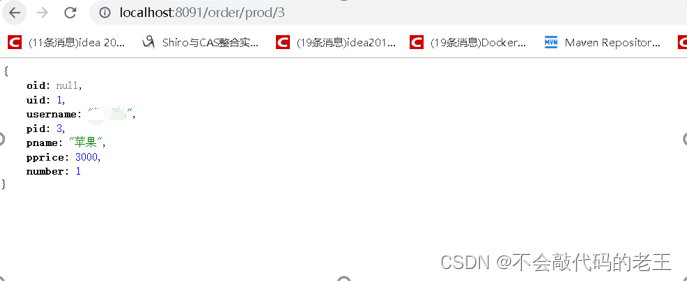
������ Nacos Discovery�C��������
3.1 ������������
����˼��һ������
ͨ����һ�µIJ���,�����Ѿ�����ʵ������֮��ĵ��á��������ǰѷ����ṩ�ߵ������ַ
(ip,�˿�)��Ӳ���뵽�˴�����,��������������������:
-
һ�������ṩ�ߵ�ַ�仯,����Ҫ�ֹ��Ĵ���
-
һ���Ƕ�������ṩ��,��ʵ�ָ��ؾ����
-
һ��������Խ��Խ��,�˹�ά�����ù�ϵ����
��ôӦ����ô�����, ��ʱ�����Ҫͨ��ע�����Ķ�̬��ʵ������������
ʲô�Ƿ�������
��������������ܹ���������������ģ�顣����ʵ�ָ���������Զ���ע���뷢����
**����ע��:**�ڷ������������,���ṹ��һ��ע������,ÿ������Ԫ��ע�����ĵǼ��Լ��ṩ��
�����ϸ��Ϣ������ע�������γ�һ�ŷ�����嵥,����ע��������Ҫ�������ķ�ʽȥ����嵥��
�ķ����Ƿ����,���������,��Ҫ�ڷ����嵥���������õķ���
**������:**������÷������ע��������ѯ����,����ȡ���з����ʵ���嵥,ʵ�ֶԾ������ʵ
���ķ��ʡ�
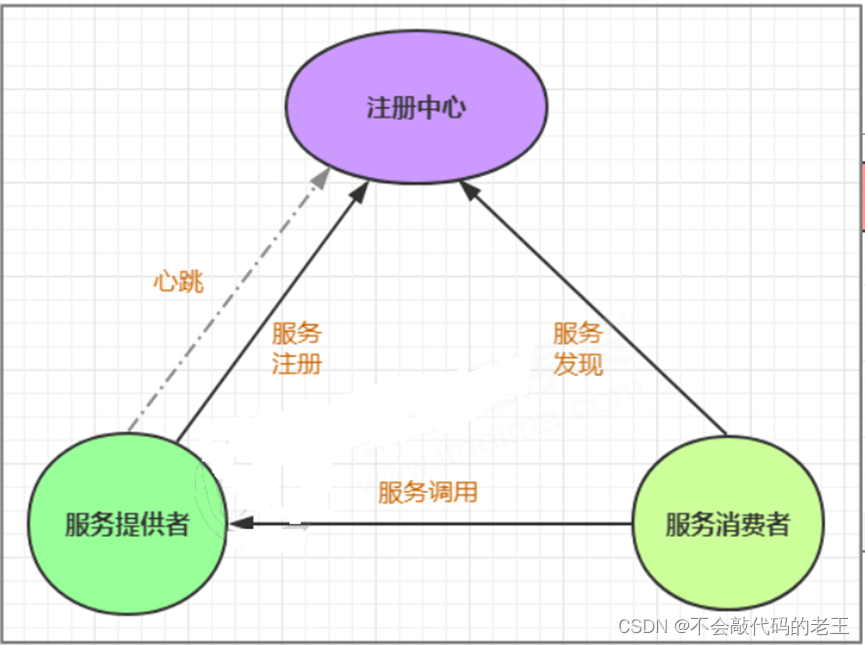
ͨ������ĵ���ͼ�ᷢ��,��������,����һ�����������ע������,��������ܹ��dz���Ҫ
��һ�����,������ܹ�����Ҫ����Э���ߵ�һ�����á�ע������һ��������¼�������:
1. ������:
����ע��:��������ṩ�ߺͷ�������ߵ���Ϣ
������:��������߶��ķ����ṩ�ߵ���Ϣ,ע�����������������ṩ�ߵ���Ϣ
2. ��������:
���ö���:�����ṩ�ߺͷ�������߶���������ص�����
�����·�:�������������������ṩ�ߺͷ��������
3. �������
�������ṩ�ߵĽ������,��������쳣,ִ�з�����
������ע������
Zookeeper
zookeeper��һ���ֲ�ʽ������,��Apache Hadoop ��һ������Ŀ,����Ҫ����������ֲ�ʽ
Ӧ���о���������һЩ���ݹ�������,��:ͳһ��������״̬ͬ������Ⱥ�������ֲ�ʽӦ��
������Ĺ����ȡ�
Eureka
Eureka��Springcloud Netflix�е���Ҫ���,��Ҫ���þ���������ע��ͷ��֡����������Ѿ���
Դ
Consul
Consul�ǻ���GO���Կ����Ŀ�Դ����,��Ҫ����ֲ�ʽ,����ϵͳ�ṩ����ע�ᡢ������
�����ù����Ĺ��ܡ�Consul�Ĺ��ܶ���ʵ��,���а���:����ע��/���֡�������顢Key/Value
�洢�����������ĺͷֲ�ʽһ���Ա�֤�����ԡ�Consul����ֻ��һ�������ƵĿ�ִ���ļ�,����
��װ�Ͳ��dz���,ֻ��Ҫ�ӹ������غ�,��ִ�ж�Ӧ�������ű����ɡ�
Nacos (�������� ��������)
Nacos��һ�������ڹ�����ԭ��Ӧ�õĶ�̬�����֡����ù����ͷ������ƽ̨������ Spring
Cloud Alibaba ���֮һ,�������ע�ᷢ�ֺͷ�������,����������Ϊnacos=eureka+config��
3.2 nacos���
Nacos �����ڰ��������֡����ú�������Nacos �ṩ��һ������õ����Լ�,����������
ʵ�ֶ�̬�����֡��������á�����Ԫ���ݼ�����������
������Ľ��ܾͿ��Կ���,nacos�����þ���һ��ע������,��������ע�������ĸ�������
3.3 nacosʵս����
������,���Ǿ������еĻ����м���nacos,�������ǵ���������ע����ȥ��
3.3.1 �nacos����
��1��: ��װnacos
���ص�ַ: https://github.com/alibaba/nacos/releases
����zip��ʽ�İ�װ��,Ȼ����н�ѹ������
��2��: ����nacos
#�л�Ŀ¼
cd nacos/bin
#��������
startup.cmd -m standalone
��3��: ����nacos
�����������http://localhost:8848/nacos,���ɷ��ʷ���, Ĭ��������nacos/nacos
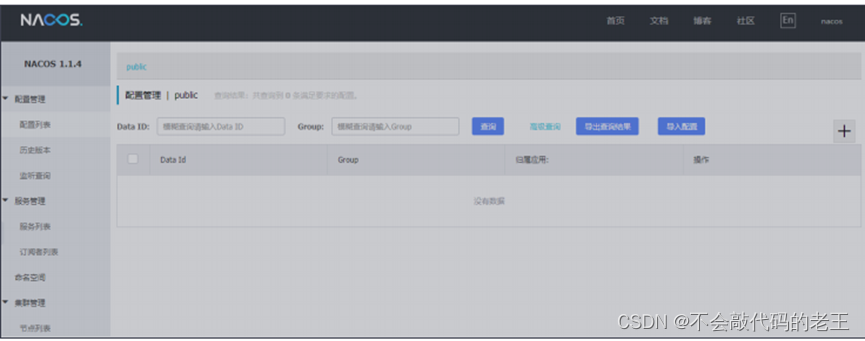
3.3.2 ����Ʒ����ע�ᵽnacos
��������ʼ�� shop-product ģ��Ĵ���, ����ע�ᵽnacos������
- ��pom.xml������nacos������
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
- ����������������nacos�Ŀ���ע��
package com.ykq;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
public class ProductApplication {
public static void main(String[] args) {
SpringApplication.run(ProductApplication.class,args);
}
}
- ��application.yml����nacos������
# ����nacosע�����ĵĵ�ַ
spring:
cloud:
nacos:
discovery:
server-addr: localhost:8848
- ��������, �۲�nacos�Ŀ���������Ƿ���ע����������Ʒ����

3.3.3 ����������ע�ᵽnacos
��������ʼ�� shop_order ģ��Ĵ���, ����ע�ᵽnacos������
- ��pom.xml������nacos������
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-nacos-discovery</artifactId>
</dependency>
- ����������������nacos�Ŀ���ע��
package com.ykq;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
@EnableDiscoveryClient //����nacos��ע��
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class,args);
}
}
- ��application.yml������nacos����ĵ�ַ
# ����nacosע�����ĵĵ�ַ
spring:
cloud:
nacos:
discovery:
server-addr: localhost:8848
-
��������, �۲�nacos�Ŀ���������Ƿ���ע����������Ʒ����

-
��OrderController�еĴ���
@GetMapping("/order/prod/{pid}")
public Order order(@PathVariable("pid")Integer pid){
log.info(">>�ͻ��µ�,��ʱ��Ҫ������Ʒ�����ѯ��Ʒ��Ϣ");
List<ServiceInstance> instances = discoveryClient.getInstances("shop-product");
ServiceInstance instance = instances.get(0);
//instance.getHost():��ȡ��һ��������Ϊshop-product��������ַ
//instance.getPort():��ȡ��һ��������Ϊshop-product�Ķ˿ں�
Product product = restTemplate.getForObject("http://"+instance.getHost()+":"+instance.getPort()+"/product/" + pid, Product.class);
log.info(">>��Ʒ��Ϣ,��ѯ���:" + JSON.toJSONString(product));
Order order = new Order();
order.setPid(product.getPid());
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
order.setUid(1);
order.setUsername("asd");
// orderService.save(order);
return order;
}
DiscoveryClient��ר�Ÿ������ע��ͷ��ֵ�,���ǿ���ͨ������ȡ��ע�ᵽע�����ĵ����з���
- ��������, �۲�nacos�Ŀ���������Ƿ���ע�������Ķ�������,Ȼ��ͨ�����������߷�����֤�����Ƿ�ɹ�
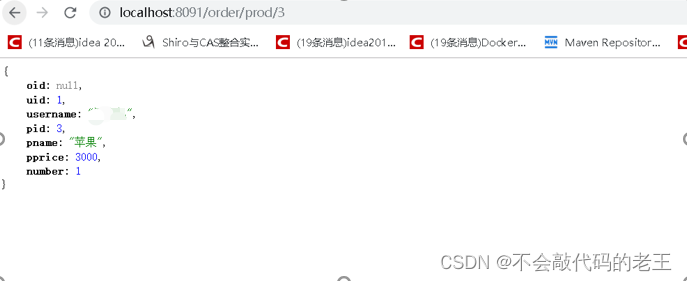
3.4 ʵ�ַ�����õĸ��ؾ���
3.4.1 ʲô�Ǹ��ؾ��� nginx
ͨ�Ľ�, ���ؾ�����ǽ�����(��������,��������)���з�̯�����������Ԫ(������,���)�Ͻ���ִ�С�
���ݸ��ؾ��ⷢ��λ�õIJ�ͬ,һ���Ϊ����˸��ؾ������ͻ��˸��ؾ�����
����˸��ؾ���ָ���Ƿ����ڷ����ṩ��һ��,���糣����nginx���ؾ���
���ͻ��˸��ؾ���ָ���Ƿ����ڷ��������һ��,Ҳ�����ڷ�������֮ǰ�Ѿ�ѡ�������ĸ�ʵ����������
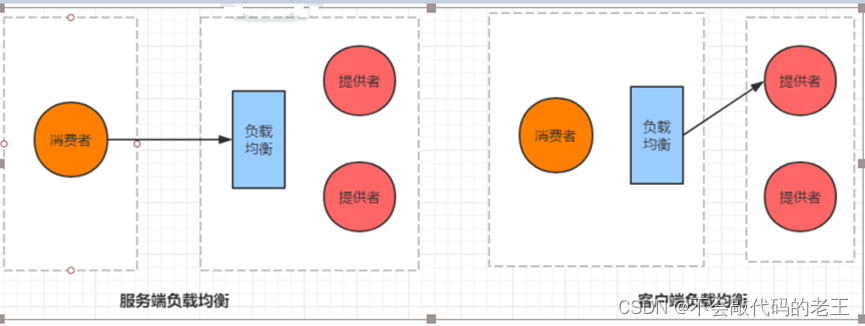
������������ù�ϵ��һ���ѡ��ͻ��˸��ؾ���,Ҳ�����ڷ�����õ�һ���������������ĸ��ṩ��ִ��.
3.4.2 �Զ���ʵ�ָ��ؾ���
1 ͨ��idea������һ�� shop-product ����,������˿�Ϊ8082
2 ͨ��nacos�鿴������������
3 �� shop-order �Ĵ���,ʵ�ָ��ؾ���
@GetMapping("/order/prod/{pid}")
public Order order(@PathVariable("pid")Integer pid){
log.info(">>�ͻ��µ�,��ʱ��Ҫ������Ʒ�����ѯ��Ʒ��Ϣ");
List<ServiceInstance> instances = discoveryClient.getInstances("shop-product");
int index = new Random().nextInt(instances.size());
ServiceInstance instance = instances.get(index);
log.info("��nacos��ȡshop-product�����ip��ַ{},�Լ��˿ں�{}",instance.getHost(),instance.getPort());
Product product = restTemplate.getForObject("http://"+instance.getHost()+":"+instance.getPort()+"/product/" + pid, Product.class);
log.info(">>��Ʒ��Ϣ,��ѯ���:" + JSON.toJSONString(product));
Order order = new Order();
order.setPid(product.getPid());
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
order.setUid(1);
order.setUsername("asd");
orderService.save(order);
return order;
}
��3��:�������������ṩ�ߺ�һ������������,����ʼ��������߲���Ч��

3.4.3 ����Ribbonʵ�ָ��ؾ��� �����
1.ʲô��Ribbon
�� Netflix ������һ�����ؾ�����,�����ڿ��� HTTP �� TCP�ͻ�����Ϊ���� SpringCloud ��, nacosһ�����Ribbon����ʹ��,Ribbon�ṩ�˿ͻ��˸��ؾ���Ĺ���,Ribbon���ô�nacos�ж� ȡ���ķ�����Ϣ,�ڵ��÷���ڵ��ṩ�ķ���ʱ,�����(����)�Ľ��и��ء� ��SpringCloud�п��Խ�ע�����ĺ�Ribbon���ʹ��,Ribbon�Զ��Ĵ�ע�������л�ȡ�����ṩ�ߵ� �б���Ϣ,���������õĸ��ؾ����㷨,�������
�� Netflix ������һ�����ؾ�����,Ribbon�Զ��Ĵ�ע�������л�ȡ�����ṩ�ߵ� �б���Ϣ,���������õĸ��ؾ����㷨,�������
2.Ribbon����Ҫ����
(1)�������
����Ribbonʵ�ַ������, ��ͨ����ȡ�������з����б����(������-����·����)ӳ���ϵ������ RestTemplate ���ս��е���
(2)���ؾ���
���ж�������ṩ��ʱ,Ribbon���Ը��ݸ��ؾ�����㷨�Զ���ѡ����Ҫ���õķ����ַ
Ribbon��Spring Cloud��һ�����, ������������ʹ��һ��ע��������ɵĸ㶨���ؾ���
��1��:��RestTemplate �����ɷ���������@LoadBalancedע��
@Bean
@LoadBalanced //������ѯ
public RestTemplate getRestTemplate() { return new RestTemplate(); }
��2��:�ķ�����õķ���
@GetMapping("/order/prod/{pid}")
public Order order(@PathVariable("pid")Integer pid){
log.info(">>�ͻ��µ�,��ʱ��Ҫ������Ʒ�����ѯ��Ʒ��Ϣ");
Product product = restTemplate.getForObject("http://shop-product/product/" + pid, Product.class);
log.info(">>��Ʒ��Ϣ,��ѯ���:" + JSON.toJSONString(product));
Order order = new Order();
order.setPid(product.getPid());
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
order.setUid(1);
order.setUsername("asd");
orderService.save(order);
return order;
}
Ribbon֧�ֵĸ��ؾ������
Ribbon�����˶��ָ��ؾ������,�ڲ����ؾ���Ķ����ӿ�Ϊ
com.netflix.loadbalancer.IRule , ����ĸ��ز�������ͼ��ʾ:
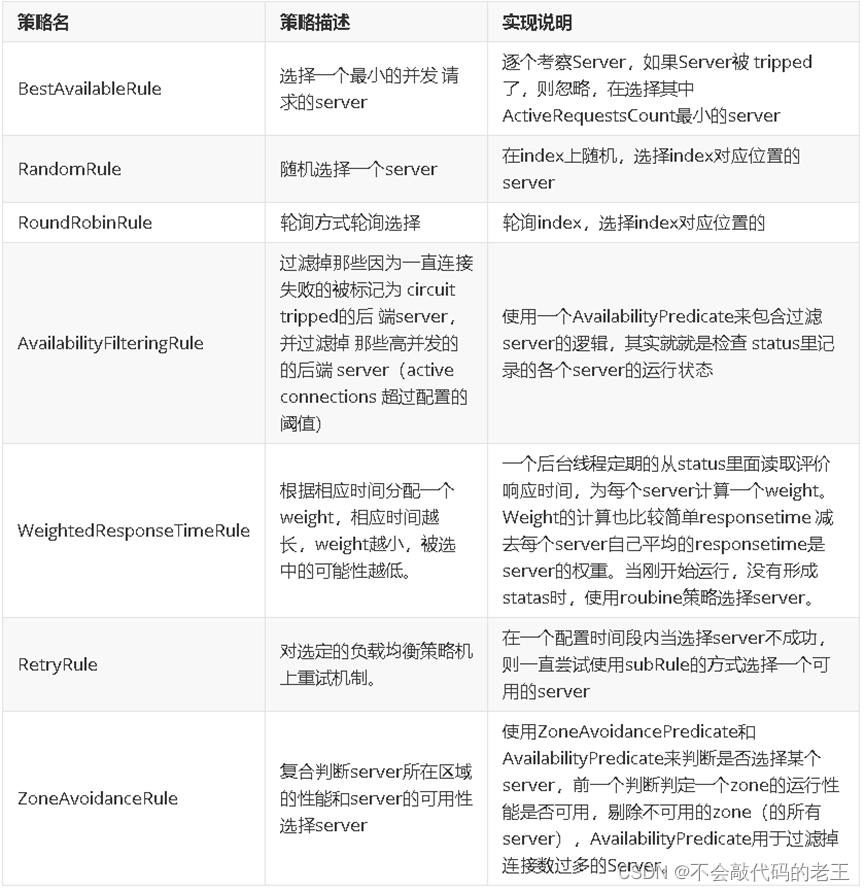
���ǿ���ͨ��������������Ribbon�ĸ��ؾ������,�����������
shop-product: # ����ʹ�÷��������
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #ʹ�õĵĸ��ؾ������
˼��:����ʹ��ribbon��ɸ��ؾ�����ʲôȱ��: restTemplate��url��ַ��
//1.����ɶ��Խϲ�.
//2.������һ��.
ϰ�ߵı�����service ����dao service��ע��dao,dao���������Ӧ�ķ���
3.5 ����OpenFeignʵ�ַ������
3.5.1 ʲô��OpenFeign
Feign��Spring Cloud�ṩ��һ������ʽ��αHttp�ͻ���, ��ʹ�õ���Զ�̷��������ñ��ط���һ����, ֻ��Ҫ����һ���ӿڲ�����һ��ע�⼴�ɡ�
Nacos�ܺõļ�����Feign, Feign���ؾ���Ĭ�ϼ����� Ribbon, ������Nacos��ʹ��FeginĬ�Ͼ�ʵ���˸��ؾ����Ч����
3.5.2 Feign��ʹ��
- ����Fegin������
<!--feign��jar�ļ�-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
- �����������ϼ��뿪��feign��ע��
@SpringBootApplication
@EnableDiscoveryClient //����nacos��ע��
@EnableFeignClients //����feign��ע��
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class,args);
}
@Bean
@LoadBalanced
public RestTemplate getRestTemplate() { return new RestTemplate(); }
}
- ����feign�Ľӿ�
@FeignClient(value = "shop-product")
public interface ProductFeign {
@RequestMapping("/product/{pid}")
public Product findById(@PathVariable("pid") Integer pid);
}
- ��OrderController�Ĵ���
@Autowired
private ProductFeign productFeign;
@GetMapping("/order/prod/{pid}")
public Order order(@PathVariable("pid")Integer pid){
log.info(">>�ͻ��µ�,��ʱ��Ҫ������Ʒ�����ѯ��Ʒ��Ϣ");
//����ֱ��ʹ��productFeign���ýӿ��еķ���,������ԭ��controller����serviceһ����
Product product = productFeign.findById(pid);
log.info(">>��Ʒ��Ϣ,��ѯ���:" + JSON.toJSONString(product));
Order order = new Order();
order.setPid(product.getPid());
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
order.setUid(1);
order.setUsername("asd");
orderService.save(order);
return order;
}
- ����order����,�鿴Ч��
������ʹ��eureka��Ϊע������
3.1 ʲô��eureka?
Eureka��Netflix�����ķ����ֿ��,SpringCloud�����������Լ�������Ŀspring-cloud-netflix��,ʵ��SpringCloud�ķ����ֹ��ܡ�
-
����һ��eureka�����

-
��eureka�����������ص�����
<dependencies>
<!--eureka-server-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
</dependencies>
- ��yml�ļ�
server:
port: 7001
eureka:
instance:
hostname: localhost
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://localhost:7001/eureka/
# ��ȫ����
security:
basic:
enabled: false
- ��������
package com.ykq;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaApp {
public static void main(String[] args) {
SpringApplication.run(EurekaApp.class,args);
}
}
�ͻ���
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
�����ļ�
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka/
������ Sentinel�C�����ݴ�
4.1 �߲�������������
������ܹ���,���ǽ�ҵ���ֳ�һ�����ķ���,���������֮����������,������������ԭ�����������ԭ��,�����ܱ�֤�����100%����,������������������,�����������ͻ���������ӳ�,��ʱ���д���������ӿ��,���γ�����ѻ�,���յ��·���̱����
����: ����һ��������30�������Ӧ�ó���,ÿ��������99.99%����������ʱ��,�������������:
99.99^30 = 99.7% ����
Ҳ����˵һ�ڸ������0.3% = 3000000 ��ʧ��
������,������ģ��һ���߲����ij���
1 ��дjava����
@GetMapping("/order/prod/{pid}")
public Order order(@PathVariable("pid")Integer pid){
log.info(">>�ͻ��µ�,��ʱ��Ҫ������Ʒ�����ѯ��Ʒ��Ϣ");
//����ֱ��ʹ��productFeign���ýӿ��еķ���,������ԭ��controller����serviceһ����
Product product = productFeign.findById(pid);
//����ģ��shop-product ��Ӧʱ��Ϊ2��
try {
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info(">>��Ʒ��Ϣ,��ѯ���:" + JSON.toJSONString(product));
Order order = new Order();
order.setPid(product.getPid());
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
order.setUid(1);
order.setUsername("asd");
//Ϊ�˲����������������� ���ǰ����Ӷ����ĵ���ע��
//orderService.save(order);
return order;
}
@RequestMapping("order/ceshi")
public String ceshi(){
return "���Dz�������";
}
2 ��application.yml
server:
port: 8091
tomcat: # Ϊ�˲��Է��� ���ǰ�Tomcat�������߳�����Ϊ10��
max-threads: 10
3 ������ʹ��ѹ���,���������ѹ������
���ص�ַhttps://jmeter.apache.org/
��һ��:������,����������
����binĿ¼,��jmeter.properties�ļ��е�����֧��Ϊlanguage=zh_CN,Ȼ����jmeter.bat
����������
�ڶ���:�����߳���
������:�����̲߳�����
���IJ�:����Httpȡ��
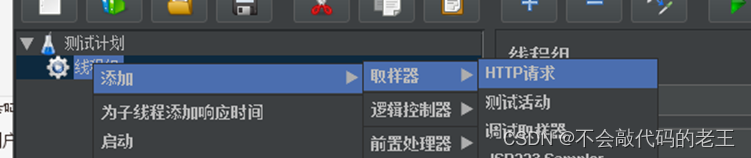
���岽:����ȡ��,����������
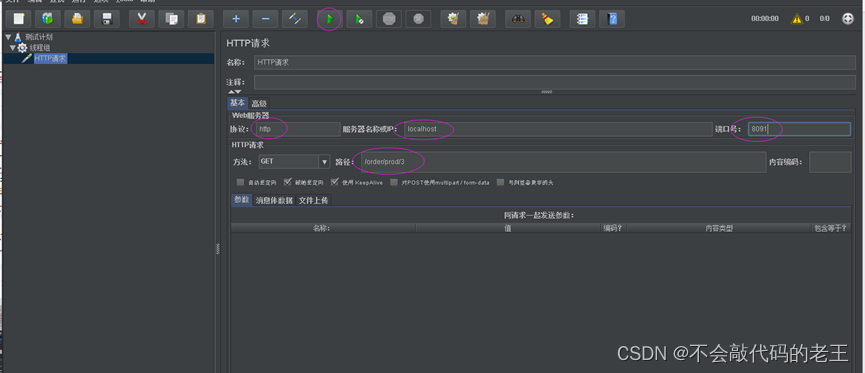
4 ����ceshi�����۲�Ч��
����:
��ʱ�ᷢ��, ����a�����ڻ��˴�������, ����b�����ķ��ʳ���������,���������ѩ���ij��Ρ�
4.2 ����ѩ��ЧӦ
�ڷֲ�ʽϵͳ��,��������ԭ���������ԭ��,����һ������֤ 100% ���á����һ���������������,�����������ͻ�����߳����������,��ʱ���д���������ӿ��,�ͻ���ֶ����߳������ȴ�,�������·���̱����
���ڷ��������֮���������,���ϻᴫ��,�����������ϵͳ��������Ե����غ��,����Ƿ�����ϵ� ��ѩ��ЧӦ�� ��
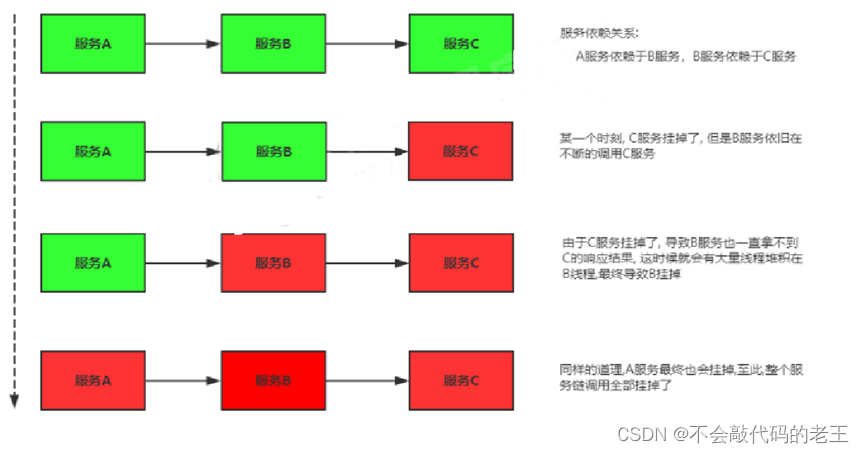
ѩ��������ԭ����ֶ���,�в��������������,�����Ǹ߲�����ijһ��������Ӧ����,�����ij̨��������Դ�ľ�����������ȫ�ž�ѩ��Դͷ�ķ���,ֻ�������㹻���ݴ�,��֤��һ������������,����Ӱ�쵽����������������С�Ҳ����"ѩ�����ѩ��"��
4.3 �����ݴ�����
Ҫ��ֹѩ������ɢ,���Ǿ�Ҫ���÷�����ݴ�,�ݴ�˵���˾��DZ����Լ������������Ͽ��һЩ��ʩ, ������ܳ����ķ����ݴ�˼·�������
�������ݴ�˼· ----> �����Ӧ�ò�Ʒ
�������ݴ�˼·�и��롢��ʱ���������۶ϡ������⼸��,����ֱ����һ�¡�
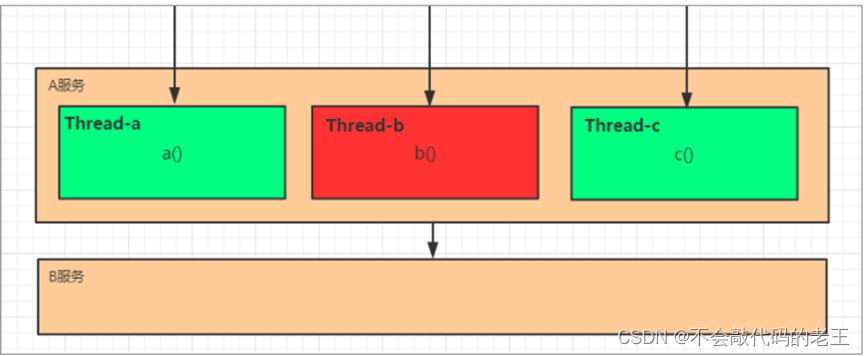
����
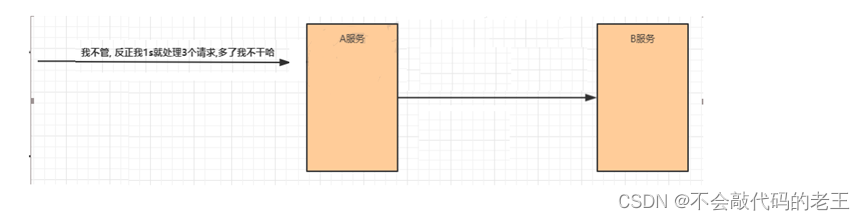
����ָ��ϵͳ����һ����ԭ��Ϊ���ɸ�����ģ��,����ģ��֮����Զ���,��ǿ���������й��Ϸ���ʱ,�ܽ������Ӱ�������ij��ģ���ڲ�,������ɢ����,����������ģ��,��Ӱ������� ϵͳ����
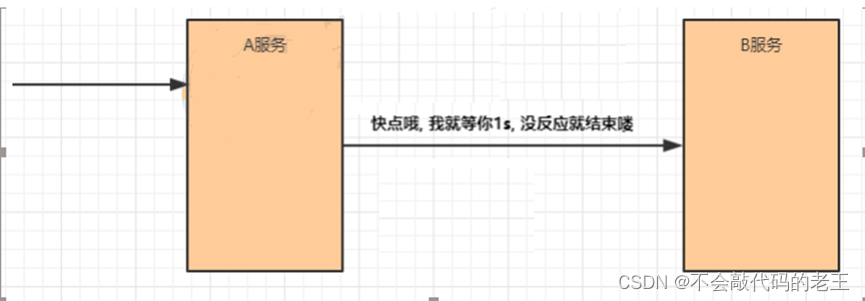
��ʱ
�����η���������η����ʱ��,����һ�������Ӧʱ��,����������ʱ��,����δ������Ӧ,
�ͶϿ�����,�ͷŵ��̡߳�
����
������������ϵͳ���������������Ѵﵽ����ϵͳ��Ŀ�ġ�һ����˵ϵͳ���������ǿ��Ա������,Ϊ�˱�֤ϵͳ���ȹ�����,һ���ﵽ����Ҫ���Ƶ���ֵ,����Ҫ������������ȡ������ʩ���������������Ŀ�ġ��ȷ�:�Ƴٽ��,�ܾ����,�����߲��־ܾ�����ȵȡ�
�۶� �ڻ�����ϵͳ��,�����η��������ѹ���������Ӧ������ʧ��,���η���Ϊ�˱���ϵͳ����Ŀ�����,������ʱ�ж϶����η���ĵ��á����������ֲ�,��ȫ����Ĵ�ʩ�ͽ����۶ϡ�
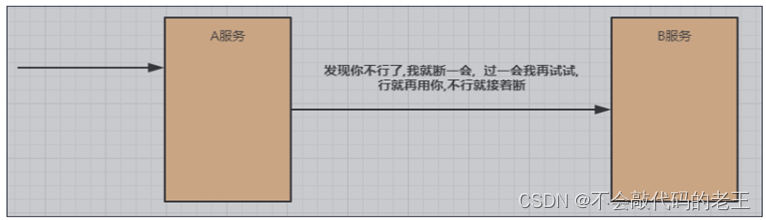
�����۶�һ��������״̬:
- �۶Ϲر�״̬(Closed)
����û�й���ʱ,�۶���������״̬,�Ե��÷��ĵ��ò����κ�����
- �۶Ͽ���״̬(Open)
�����Ը÷���ӿڵĵ��ò��پ�������,ֱ��ִ�б��ص�fallback����
- ���۶�״̬(Half-Open)
���Իָ��������,���������������ø÷���,����ص��óɹ��ʡ�����ɹ��ʴﵽԤ��,��˵�������ѻָ�,�����۶Ϲر�״̬;����ɹ����Ծɺܵ�,�����½����۶Ϲر�״̬��
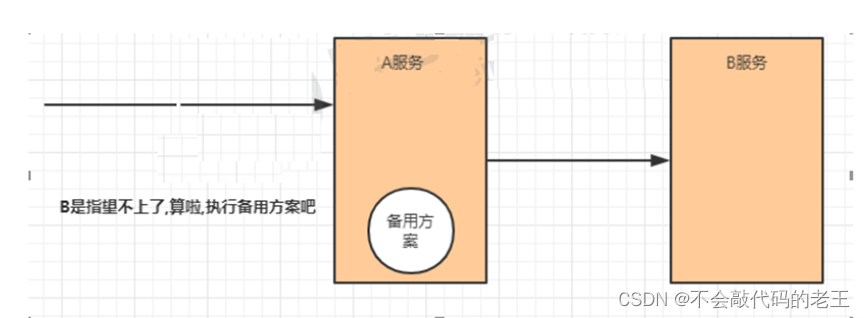
����
������ʵ����Ϊ�����ṩһ���е���,һ����������������,��ʹ���е�����
�������ݴ���� hystrix sentinel
Hystrix
Hystrix����Netflix��Դ��һ���ӳٺ��ݴ���,���ڸ������Զ��ϵͳ��������ߵ�������,��ֹ����ʧ��,�Ӷ�����ϵͳ�Ŀ��������ݴ��ԡ�
Resilience4J
Resilicence4Jһ��dz���������,�����ĵ��dz��������ḻ���۶Ϲ���,��Ҳ��Hystrix�ٷ��Ƽ��������Ʒ���������,Resilicence4j��ԭ��֧��Spring Boot 1.x/2.x,���Ҽ��Ҳ֧�ֺ� prometheus�ȶ��������Ʒ�������ϡ�
Sentinel
Sentinel �ǰ���ͰͿ�Դ��һ���·��ʵ��,�����ڰ����ڲ��Ѿ������ģ����,�dz��ȶ���
��������������ڸ�����ĶԱ�:
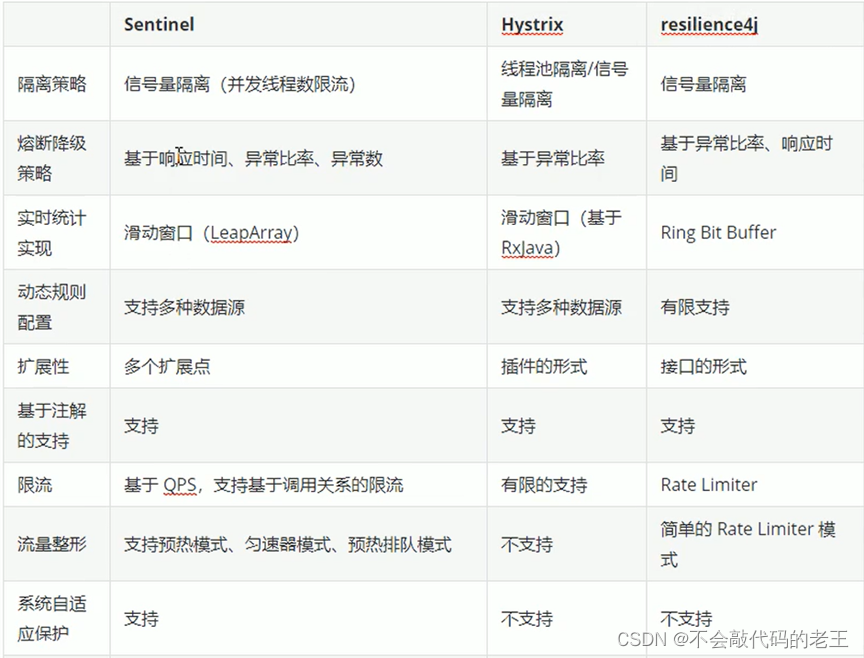
Ϊʲô��Ҫʹ�÷����ݴ�������
��α��������ݴ�? (1.���� 2. ���� 3.��ʱ 4.�۶Ͻ���)
�ݴ����������Щ? (hystrix, sentinel) ����ڶ���
4.4 Sentinel����
4.4.1 ʲô��Sentinel
Sentinel (�ֲ�ʽϵͳ������������) �ǰ��↑Դ��һ�����������ݴ����ۺ��Խ����������������Ϊ�����, ���������ơ��۶Ͻ�����ϵͳ���ر����ȶ��ά��������������ȶ��ԡ�
Sentinel ����������:
���Ŀ�(Java �ͻ���) �������κο��/��,�ܹ����������� Java ����ʱ����,ͬʱ�� Dubbo /Spring Cloud �ȿ��Ҳ�нϺõ�֧�֡�
����̨(Dashboard)���� Spring Boot ����,��������ֱ������,����Ҫ����� Tomcat ��Ӧ��������
4.4.2 ����Sentinel
Ϊ����Sentinel�dz���, ֻ��Ҫ����Sentinel����������
1 ��pom.xml�����������
<!--����sentinal������jar�ļ�-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
2 ��дһ��Controller����ʹ��
@RestController
@Slf4j
public class OrderController2 {
@RequestMapping("order/message1")
public String message1(){
return "message1";
}
@RequestMapping("order/message2")
public String message2(){
return "message2";
}
}
4.4.3 ��װSentinel����̨
Sentinel �ṩһ���������Ŀ���̨, ���ṩ�������֡�������Դʵʱ����Լ���������ȹ��ܡ�
1 ����jar��,��ѹ���ļ���
https://github.com/alibaba/Sentinel/releases
2 ��������̨
java -jar sentinel-dashboard-1.7.0.jar
3 �� shop-order ,����������йؿ���̨������
spring:
cloud:
sentinel:
transport:
port: 9999 # �ö˿ں�Ϊsentinal�ڷ���֮��Ľ��� ���дֻҪ����ռ��
dashboard: localhost:8888 #sentinal�������ڵĵ�ַ�Ͷ˿ں�
��4��: ͨ�����������localhost:8080 �������̨ ( Ĭ���û��������� sentinel/sentinel )

����:�˽����̨��ʹ��ԭ��
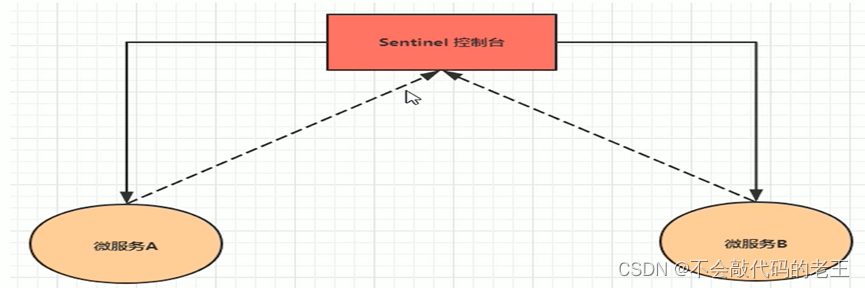
Sentinel�Ŀ���̨��ʵ����һ��SpringBoot��д�ij���������Ҫ�����ǵ��������ע�ᵽ����̨��, ����������ָ������̨�ĵ�ַ, ���һ�Ҫ����һ��������̨�������ݵĶ˿�, ����̨Ҳ����ͨ���˶˿ڵ��������еļ�س����ȡ����ĸ�����Ϣ��
4.4.4 ʵ��һ���ӿڵ�����
1 ͨ������̨Ϊmessage1����һ�����ع���
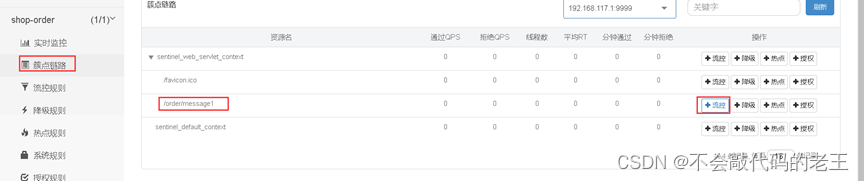
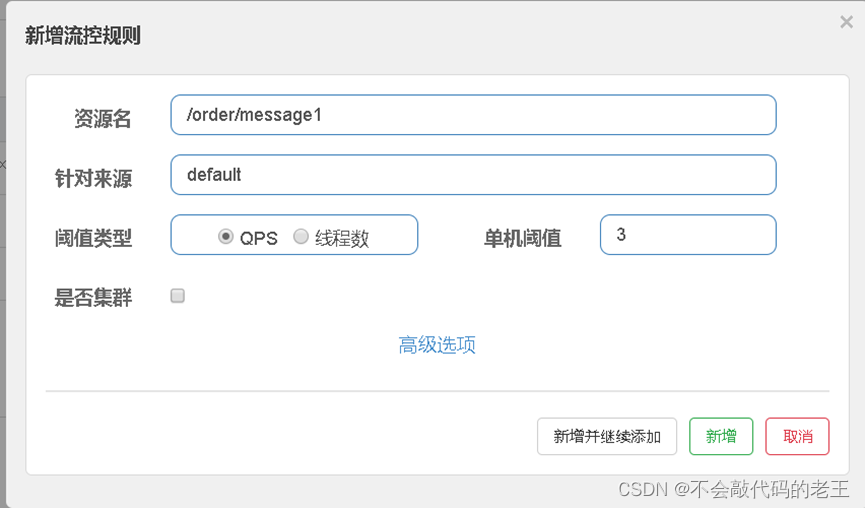
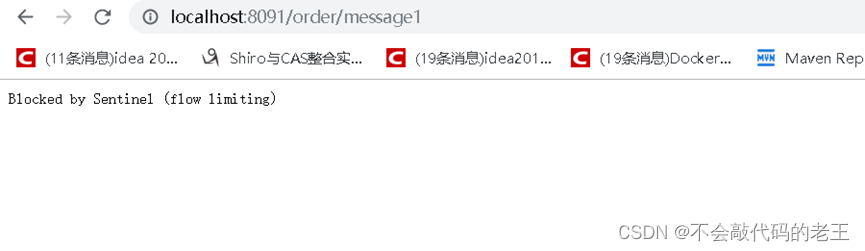
2 ͨ������̨����Ƶ������, �۲�Ч��
4.5 Sentinel�ĸ������
4.5.1 ��������
��Դ
��Դ: ����sentinelҪ���������ݡ�
��Դ�� Sentinel �Ĺؼ������������ Java Ӧ�ó����е��κ�����,������һ������,Ҳ������
һ������,����������һ�δ��롣
| �������Ű����е�message1�����Ϳ�����Ϊ��һ����Դ
����
����: ��ʲô�ķ�ʽ�����������Դ��
��������Դ֮��, ������ʲô���ķ�ʽ������Դ,��Ҫ�����������ƹ����۶Ͻ��������Լ�ϵͳ
��������
| �������Ű����о���Ϊmessage1��Դ������һ�����ع���, �����˽���message1������
4.5.2 ��Ҫ����
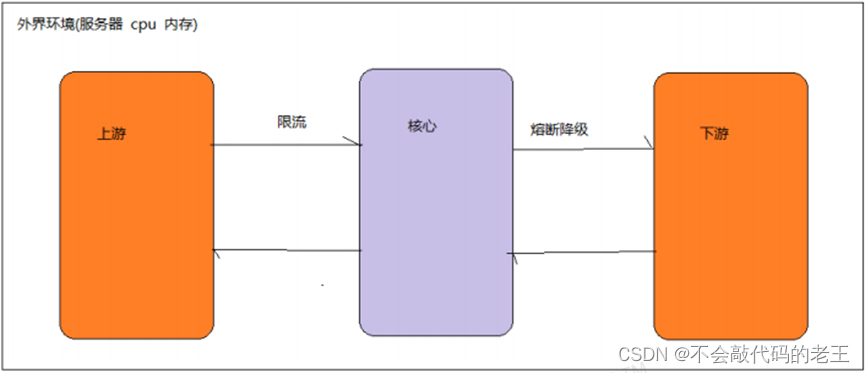
Sentinel����Ҫ���ܾ����ݴ�,��Ҫ����Ϊ����������:
��������
�������������紫������һ�����õĸ���,�����ڵ�������������ݡ�����ʱ�䵽��������������������ɿص�,��ϵͳ�Ĵ������������ġ�������Ҫ����ϵͳ�Ĵ����������������п��ơ�Sentinel ��Ϊһ��������,���Ը�����Ҫ���������������ɺ��ʵ���״��
�۶Ͻ���
����������·��ij����Դ���ֲ��ȶ��ı���,����������Ӧʱ�䳤���쳣�������ߵ�ʱ��,��������Դ�ĵ��ý�������,���������ʧ��,����Ӱ�쵽��������Դ�����¼������ϡ�Sentinel ����������ȡ�������ֶ�:
- ͨ�������߳�����������
Sentinel ͨ��������Դ�����̵߳�����,�����ٲ��ȶ���Դ��������Դ��Ӱ�졣��ij����Դ���ֲ��ȶ��������,������Ӧʱ��䳤,����Դ��ֱ��Ӱ����ǻ�����߳������ѻ������߳������ض���Դ�϶ѻ���һ��������֮��,�Ը���Դ��������ͻᱻ�ܾ����ѻ����߳���������ſ�ʼ������������
- ͨ����Ӧʱ�����Դ���н���
���˶Բ����߳������п�������,Sentinel ������ͨ����Ӧʱ�������ٽ������ȶ�����Դ������������Դ������Ӧʱ�������,���жԸ���Դ�ķ��ʶ��ᱻֱ�Ӿܾ�,ֱ������ָ����ʱ�䴰��֮������»ָ���
��֮һ�仰: ������Ҫ��������,������Sentinel����Դ�����ø��ָ����Ĺ���,��ʵ�ָ����ݴ��Ĺ��ܡ�
4.6 Sentinel����
4.6.1 ���ع���
��������,��ԭ���Ǽ��Ӧ��������QPS(ÿ���ѯ��) ���߳�����ָ��,���ﵽָ������ֵʱ���������п���,�Ա��ⱻ˲ʱ�������߷���,�Ӷ�����Ӧ�õĸ߿����ԡ�
��1��: ����ص���·,���ǾͿ��Կ������ʹ��Ľӿڵ�ַ,Ȼ������Ӧ�����ذ�ť,�������ع�������ҳ�档�������ع����������:
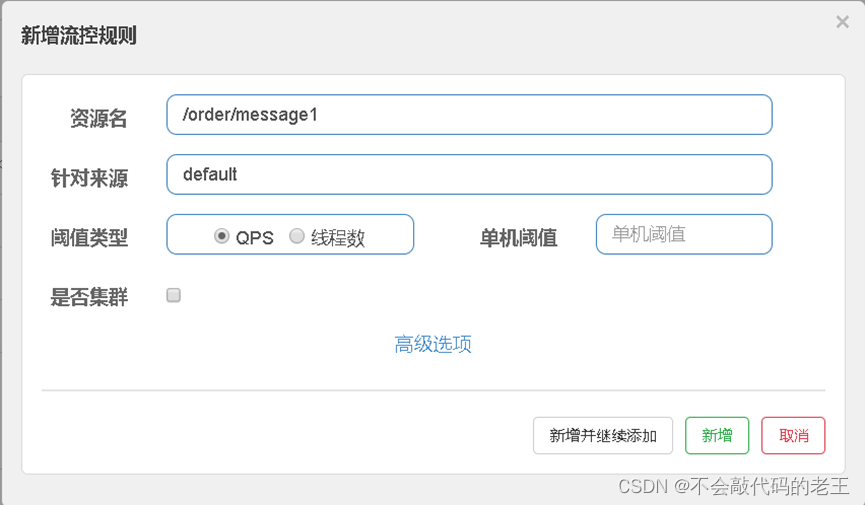
��Դ��:Ψһ����,Ĭ��������·��,���Զ���
�����Դ:ָ�����ĸ������������,Ĭ��ָdefault,��˼�Dz�������Դ,ȫ������
��ֵ����/������ֵ:
-
QPS(ÿ����������): �����øýӿڵ�QPS�ﵽ��ֵ��ʱ��,��������
-
�߳���:�����øýӿڵ��߳����ﵽ��ֵ��ʱ��,��������
�Ƿ�Ⱥ:�ݲ���Ҫ��Ⱥ
������������QPSΪ�����о��������������
4.6.1.1 ������
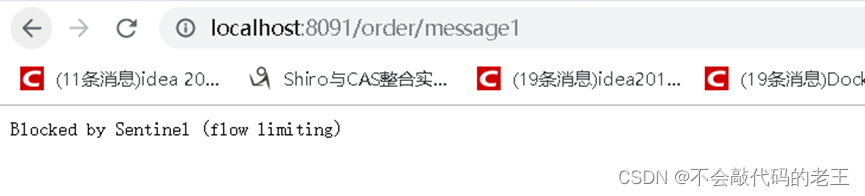
��������һ��������,������ֵ����ΪQPS,������ֵΪ3����ÿ������������3��ʱ��ʼ����
������,�����ع���ҳ��Ϳ��Կ����������

Ȼ����ٷ��� /order/message1 �ӿ�,�۲�Ч������ʱ����,��QPS > 3��ʱ��,����Ͳ���������Ӧ,���Ƿ���Blocked by Sentinel (flflow limiting)�����
4.6.1.2 ��������ģʽ
��������������ع�����༭��ť,Ȼ���ڱ༭ҳ������ѡ��,�ῴ��������ģʽһ����
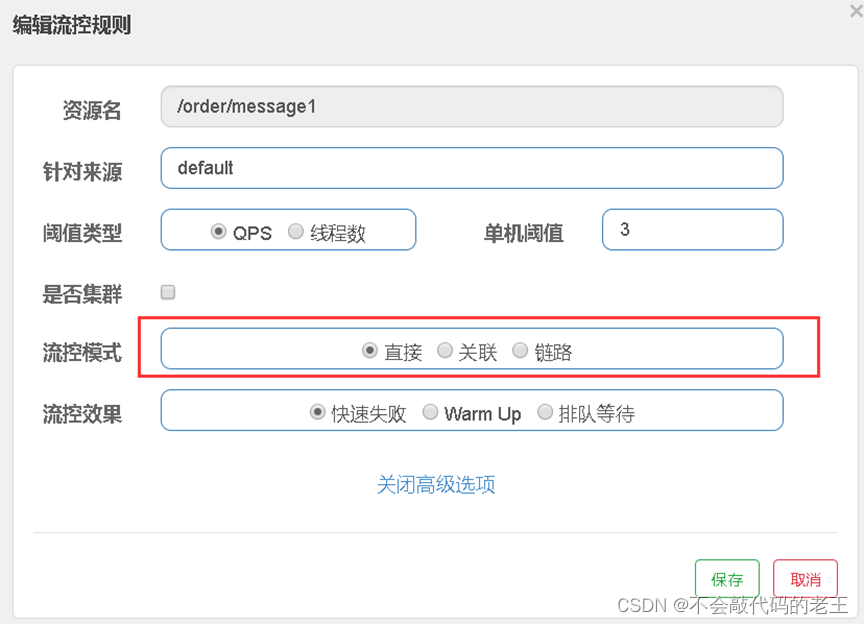
sentinel������������ģʽ,�ֱ���:
-
ֱ��(Ĭ��):�ӿڴﵽ��������ʱ,��������
-
����:����������Դ�ﵽ��������ʱ,�������� [�ʺ���Ӧ���ò�]
-
��·:����ij���ӿڹ�������Դ�ﵽ��������ʱ,��������
�����طֱ���ʾ����ģʽ:
ֱ������ģʽ
ֱ������ģʽ�����ģʽ,��ָ���Ľӿڴﵽ��������ʱ�������������永��ʹ�õľ���ֱ������ģʽ��
��������ģʽ
��������ģʽָ����,��ָ���ӿڹ����Ľӿڴﵽ��������ʱ,������ָ���ӿڿ���������
��1��:������������, ������ģʽ����Ϊ����,������Դ����Ϊ�� /order/message2��
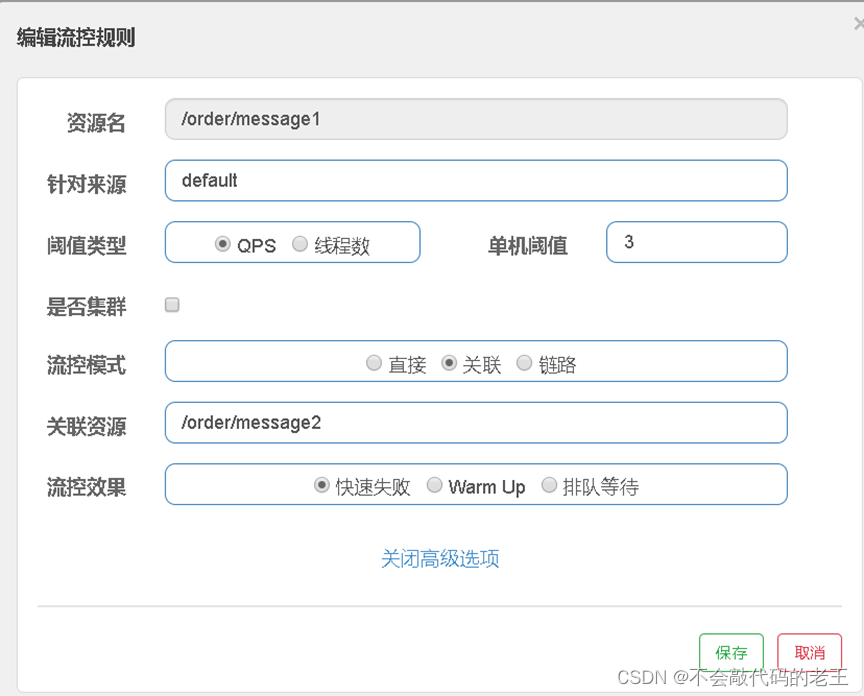
��4��:����/order/message1,�ᷢ���Ѿ�������

��·����ģʽ(�˽�)
��·����ģʽָ����,����ij���ӿڹ�������Դ�ﵽ��������ʱ,�������������Ĺ����е������������Դ������,��������:�����Դ������ϼ�����,����·����������ϼ��ӿ�,Ҳ����˵�������ȸ�ϸ��
��1��: ��дһ��service,����������һ������message
@Service
public class OrderServiceImpl3 {
@SentinelResource("message")
public void message() {
System.out.println("message");
}
}
��2��: ��Controller��������������,�ֱ����service�еķ���m
@RestController
@Slf4j
public class OrderController3 {
@Autowired
private OrderServiceImpl3 orderServiceImpl3;
@RequestMapping("/order/message1")
public String message1() {
orderServiceImpl3.message();
return "message1";
}
@RequestMapping("/order/message2")
public String message2() {
orderServiceImpl3.message();
return "message2";
}
}
��3��: ��ֹ����URL����� context
��1.6.3 �汾��ʼ,Sentinel Web fifilterĬ����������URL�����context,�����·��������Ч��
1.7.0 �汾��ʼ(��ӦSCA��2.1.1.RELEASE),�ٷ���CommonFilter ������
WEB_CONTEXT_UNIFY ����,���ڿ����Ƿ�����context����������Ϊ false ���ɸ��ݲ�ͬ��
URL ������·������
SCA 2.1.1.RELEASE֮��İ汾,����ͨ������spring.cloud.sentinel.web-context-unify=false��
�ɹر�����
���ǵ�ǰʹ�õİ汾��SpringCloud Alibaba 2.1.0.RELEASE,��ʵ����·������
Ŀǰ�ٷ���δ����SCA 2.1.2.RELEASE,��������ֻ��ʹ��2.1.1.RELEASE,��Ҫд�������ʽʵ��
(1) ��ʱ��SpringCloud Alibaba�İ汾����Ϊ2.1.1.RELEASE
<spring-cloud-alibaba.version>2.1.1.RELEASE</spring-cloud-alibaba.version>
(2) �����ļ��йر�sentinel��CommonFilterʵ����
spring:
cloud:
sentinel:
filter:
enabled: false
(3) ����һ��������,�Լ�����CommonFilterʵ��
package com.ykq.config;
import com.alibaba.csp.sentinel.adapter.servlet.CommonFilter;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class FilterContextConfig {
@Bean
public FilterRegistrationBean sentinelFilterRegistration() {
FilterRegistrationBean registration = new FilterRegistrationBean();
registration.setFilter(new CommonFilter());
registration.addUrlPatterns("/*");
// �����Դ�رվۺ�
registration.addInitParameter(CommonFilter.WEB_CONTEXT_UNIFY, "false");
registration.setName("sentinelFilter");
registration.setOrder(1);
return registration;
}
}
**(4)**����̨������������
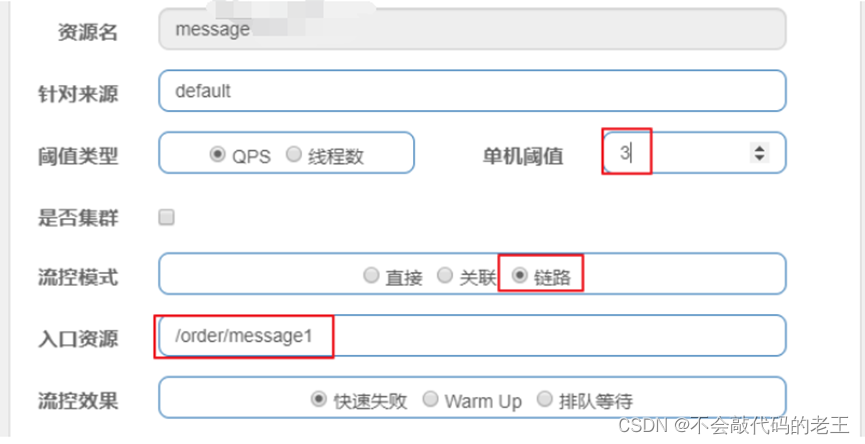
**(5)**�ֱ�ͨ�� /order/message1 �� /order/message2 ����, ����2û����, 1�ı�������
4.6.1.3 ����������
-
����ʧ��(Ĭ��): ֱ��ʧ��,�׳��쳣,�����κζ���Ĵ���,�����Ч��
-
Warm Up:���ӿ�ʼ��ֵ�����QPS��ֵ����һ�������,һ��ʼ����ֵ�����QPS��ֵ��1/3,Ȼ����������,ֱ�������ֵ,�����ڽ�ͻȻ���������ת��Ϊ���������ij�����
-
�Ŷӵȴ�:�������Ծ��ȵ��ٶ�ͨ��,������ֵΪÿ��ͨ������,������Ŷӵȴ�; ������������һ����ʱʱ��,��������ʱ��ʱ�仹δ����,��ᱻ������
4.6.2 ��������
��������������õ�����ʲô������ʱ��,�Է�����н�����Sentinel�ṩ��������������:
- ƽ����Ӧʱ�� :����Դ��ƽ����Ӧʱ�䳬����ֵ(�� ms Ϊ��λ)֮��,��Դ��������״̬����������� 1s �ڳ������� 5 ������,���ǵ� RT���������������ֵ,��ô�ڽ��µ�ʱ�䴰��(�� s Ϊ��λ)֮��,�ͻ������������з�����
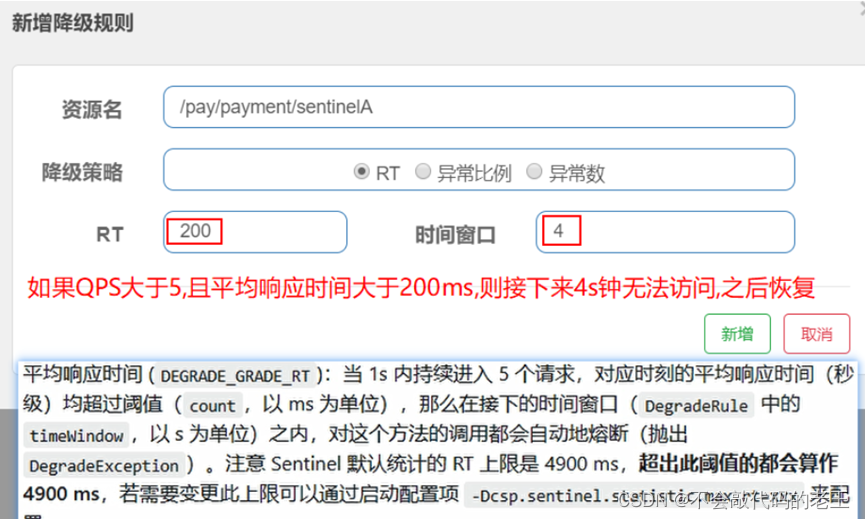
- �쳣����:����Դ��ÿ��������>=5,����ÿ���쳣����ռͨ�����ı�ֵ������ֵ֮��,��Դ���뽵��״̬,���ڽ��µ�ʱ�䴰������,����������ĵ��ö����Զ��ط��ء��쳣���ʵ���ֵ��Χ��[0.0,1.0],����0%~100%
��1��: ����ģ��һ���쳣
private int i=0;
@RequestMapping("order/message2")
public String message2(){
i++;
if(i%3==0){
throw new RuntimeException("�쳣");
}
return "message2";
}
��2��: �����쳣����Ϊ0.25
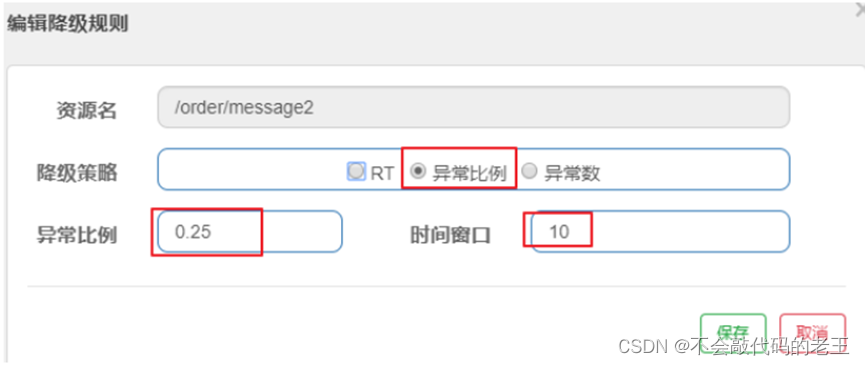
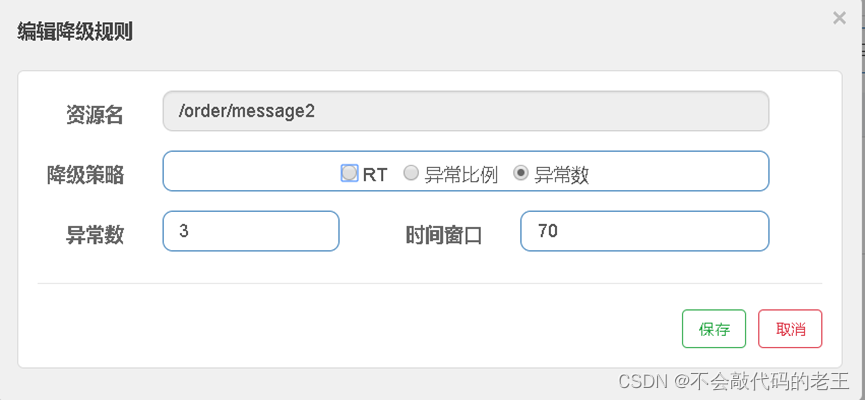
�쳣�� :����Դ�� 1 ���ӵ��쳣��Ŀ������ֵ֮�����з�����ע������ͳ��ʱ�䴰���Ƿ��Ӽ����,��ʱ�䴰��С�� 60s,������۶�״̬���Կ����ٽ����۶�״̬��
4.6.3 �ȵ����
�ȵ�������ع�����һ�ָ�ϸ���ȵ����ع���, ��������������嵽�����ϡ�
�ȵ�����ʹ��
��1��: �����
@RequestMapping("/order/message3")
@SentinelResource(value = "message3")
//ע���������ʹ�����ע���ʶ,�ȵ������Ч
public String message3(String name, Integer age) { return name + age; }
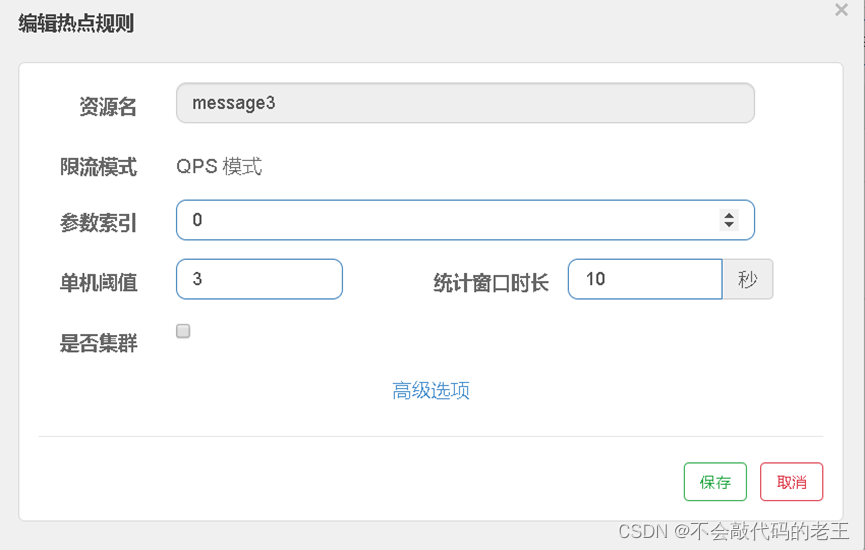
��3��: �ֱ���������������,�ᷢ��ֻ�Ե�һ������������
�ȵ������ǿʹ��
����������������һ�������ľ���ֵ�������ر༭�ղŶ���Ĺ���,���Ӳ���������
��չ: �Զ����쳣����
package com.ykq.handler;
import com.alibaba.csp.sentinel.adapter.servlet.callback.UrlBlockHandler;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeException;
import com.alibaba.csp.sentinel.slots.block.flow.FlowException;
import com.alibaba.fastjson.JSON;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.bouncycastle.asn1.ocsp.ResponseData;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
//�쳣����ҳ��
@Component
public class ExceptionHandlePage implements UrlBlockHandler {
//BlockException �쳣�ӿ�,����Sentinel������쳣
// FlowException �����쳣
// DegradeException �����쳣
// ParamFlowException ���������쳣
// AuthorityException ��Ȩ�쳣
// SystemBlockException ϵͳ�����쳣
@Override
public void blocked(HttpServletRequest request, HttpServletResponse response, BlockException e) throws IOException {
response.setContentType("application/json;charset=utf-8");
ResponseData data = null;
if (e instanceof FlowException) {
data = new ResponseData(-1, "�ӿڱ�������...");
}
else if (e instanceof DegradeException) {
data = new ResponseData(-2, "�ӿڱ�������...");
}
response.getWriter().write(JSON.toJSONString(data));
}
@Data
@AllArgsConstructor
@NoArgsConstructor
class ResponseData{
private Integer id;
private String msg;
}
}
˼��:����������������Ʒ����ʱ,��Ʒ�������,��ô�ͻᵼ�¶�������Ҳ���ͻ���ʾ����,����Ӧ������һ�����ķ���������ʹ��sentinelSource�е�fallback����
4.7 Feign����sentinel
��1��: ����sentinel������
<!--����sentinal������jar�ļ�-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
��2��: �������ļ��п���Feign��Sentinel��֧��
feign:
sentinel:
enabled: true
��3��: �����ݴ���
package com.ykq.handler;
import com.ykq.domain.Product;
import com.ykq.feign.ProductFeign;
import org.springframework.stereotype.Component;
import org.springframework.web.bind.annotation.PathVariable;
@Component
public class ProductFeignHandler implements ProductFeign {
@Override
public Product findById(Integer pid) {
return null;
}
public Product find2(@PathVariable("pid") Integer pid){
Product product = new Product();
product.setPid(-1);
product.setPname("�������");
return product;
}
}
��4��: Ϊ�������Ľӿ�ָ���ݴ���
@FeignClient(value = "shop-product",fallback = ProductFeignHandler.class)
public interface ProductFeign {
@RequestMapping("/product/{pid}")
public Product findById(@PathVariable("pid") Integer pid);
@RequestMapping("/find2/{pid}")
public Product find2(@PathVariable("pid") Integer pid);
}
��5��: ��controller
@GetMapping("/order/prod/{pid}")
public Order order(@PathVariable("pid")Integer pid){
log.info(">>�ͻ��µ�,��ʱ��Ҫ������Ʒ�����ѯ��Ʒ��Ϣ");
//����ֱ��ʹ��productFeign���ýӿ��еķ���,������ԭ��controller����serviceһ����
Product product = productFeign.find2(pid);
if(product.getPid()==-1){
Order order = new Order();
order.setPname("�µ�ʧ��");
return order;
}
log.info(">>��Ʒ��Ϣ,��ѯ���:" + JSON.toJSONString(product));
Order order = new Order();
order.setPid(product.getPid());
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
order.setUid(1);
order.setUsername("asd");
//Ϊ�˲����������������� ���ǰ����Ӷ����ĵ���ע��
//orderService.save(order);
return order;
}
��6��: ֹͣ���� shop-product ����,���� shop-order ����,��������,�۲��ݴ�Ч��
��չ: ��������ݴ������õ�����Ĵ���,����ʹ������ķ�ʽ
@FeignClient(
value = "service-product",
//fallback = ProductServiceFallBack.class,
fallbackFactory = ProductServiceFallBackFactory.class)
public interface ProductService {
//@FeignClient��value + @RequestMapping��valueֵ ��ʵ������ɵ������ַ
"http://service-product/product/" + pid
@RequestMapping("/product/{pid}")//ָ�������URI����
Product findByPid(@PathVariable Integer pid);
}
@Component
public class ProductServiceFallBackFactory implements
FallbackFactory<ProductService> {
@Override
public ProductService create(Throwable throwable) {
return new ProductService() {
@Override
public Product findByPid(Integer pid) {
throwable.printStackTrace();
Product product = new Product();
product.setPid(-1);
return product;
}
};
}
}
ע��: fallback��fallbackFactoryֻ��ʹ������һ�ַ�ʽ
4.8 Sentinel����־û�
ͨ��ǰ��Ľ���,�����Ѿ�֪��,����ͨ��Dashboard��Ϊÿ��Sentinel�ͻ������ø��ָ����Ĺ���,����������һ������,������Щ����Ĭ���Ǵ�����ڴ���,�����ȶ�,������Ҫ����־û���
�����ļ�����Դ�ᶨʱ��ѯ�ļ��ı��,��ȡ�����������Ǽȿ�����Ӧ�ñ���ֱ�����ļ������¹���,Ҳ����ͨ�� Sentinel ����̨�������Ա����ļ�����ԴΪ��,����������ͼ��ʾ:
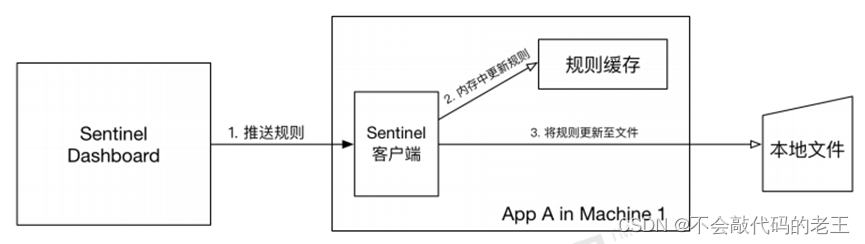
���� Sentinel ����̨ͨ�� API �������������ͻ��˲����µ��ڴ���,����ע���д����Դ�Ὣ�µĹ��浽���ص��ļ��С�
1 �������
package com.ykq.config;
import com.alibaba.csp.sentinel.command.handler.ModifyParamFlowRulesCommandHandler;
import com.alibaba.csp.sentinel.datasource.*;
import com.alibaba.csp.sentinel.init.InitFunc;
import com.alibaba.csp.sentinel.slots.block.authority.AuthorityRule;
import com.alibaba.csp.sentinel.slots.block.authority.AuthorityRuleManager;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeRule;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeRuleManager;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import com.alibaba.csp.sentinel.slots.block.flow.param.ParamFlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.param.ParamFlowRuleManager;
import com.alibaba.csp.sentinel.slots.system.SystemRule;
import com.alibaba.csp.sentinel.slots.system.SystemRuleManager;
import com.alibaba.csp.sentinel.transport.util.WritableDataSourceRegistry;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import org.springframework.beans.factory.annotation.Value;
import java.io.File;
import java.io.IOException;
import java.util.List
public class FilePersistence implements InitFunc {
@Value("${spring.application.name}")
private String appcationName;
@Override
public void init() throws Exception {
String ruleDir = System.getProperty("user.home") + "/sentinel-rules/" + appcationName;
String flowRulePath = ruleDir + "/flow-rule.json";
String degradeRulePath = ruleDir + "/degrade-rule.json";
String systemRulePath = ruleDir + "/system-rule.json";
String authorityRulePath = ruleDir + "/authority-rule.json";
String paramFlowRulePath = ruleDir + "/param-flow-rule.json";
this.mkdirIfNotExits(ruleDir);
this.createFileIfNotExits(flowRulePath);
this.createFileIfNotExits(degradeRulePath);
this.createFileIfNotExits(systemRulePath);
this.createFileIfNotExits(authorityRulePath);
this.createFileIfNotExits(paramFlowRulePath);
// ���ع���
ReadableDataSource<String, List<FlowRule>> flowRuleRDS = new FileRefreshableDataSource<>(
flowRulePath,
flowRuleListParser
);
FlowRuleManager.register2Property(flowRuleRDS.getProperty());
WritableDataSource<List<FlowRule>> flowRuleWDS = new FileWritableDataSource<>(
flowRulePath,
this::encodeJson
);
WritableDataSourceRegistry.registerFlowDataSource(flowRuleWDS);
// ��������
ReadableDataSource<String, List<DegradeRule>> degradeRuleRDS = new FileRefreshableDataSource<>(
degradeRulePath,
degradeRuleListParser
);
DegradeRuleManager.register2Property(degradeRuleRDS.getProperty());
WritableDataSource<List<DegradeRule>> degradeRuleWDS = new FileWritableDataSource<>(
degradeRulePath,
this::encodeJson
);
WritableDataSourceRegistry.registerDegradeDataSource(degradeRuleWDS);
// ϵͳ����
ReadableDataSource<String, List<SystemRule>> systemRuleRDS = new FileRefreshableDataSource<>(
systemRulePath,
systemRuleListParser
);
SystemRuleManager.register2Property(systemRuleRDS.getProperty());
WritableDataSource<List<SystemRule>> systemRuleWDS = new FileWritableDataSource<>(
systemRulePath,
this::encodeJson
);
WritableDataSourceRegistry.registerSystemDataSource(systemRuleWDS);
// ��Ȩ����
ReadableDataSource<String, List<AuthorityRule>> authorityRuleRDS = new FileRefreshableDataSource<>(
authorityRulePath,
authorityRuleListParser
);
AuthorityRuleManager.register2Property(authorityRuleRDS.getProperty());
WritableDataSource<List<AuthorityRule>> authorityRuleWDS = new FileWritableDataSource<>(
authorityRulePath,
this::encodeJson
);
WritableDataSourceRegistry.registerAuthorityDataSource(authorityRuleWDS);
// �ȵ��������
ReadableDataSource<String, List<ParamFlowRule>> paramFlowRuleRDS = new FileRefreshableDataSource<>(
paramFlowRulePath,
paramFlowRuleListParser
);
ParamFlowRuleManager.register2Property(paramFlowRuleRDS.getProperty());
WritableDataSource<List<ParamFlowRule>> paramFlowRuleWDS = new FileWritableDataSource<>(
paramFlowRulePath,
this::encodeJson
);
ModifyParamFlowRulesCommandHandler.setWritableDataSource(paramFlowRuleWDS);
}
private Converter<String, List<FlowRule>> flowRuleListParser = source -> JSON.parseObject(
source,
new TypeReference<List<FlowRule>>() {
}
);
private Converter<String, List<DegradeRule>> degradeRuleListParser = source -> JSON.parseObject(
source,
new TypeReference<List<DegradeRule>>() {
}
);
private Converter<String, List<SystemRule>> systemRuleListParser = source -> JSON.parseObject(
source,
new TypeReference<List<SystemRule>>() {
}
);
private Converter<String, List<AuthorityRule>> authorityRuleListParser = source -> JSON.parseObject(
source,
new TypeReference<List<AuthorityRule>>() {
}
);
private Converter<String, List<ParamFlowRule>> paramFlowRuleListParser = source -> JSON.parseObject(
source,
new TypeReference<List<ParamFlowRule>>() {
}
);
private void mkdirIfNotExits(String filePath) throws IOException {
File file = new File(filePath);
if (!file.exists()) {
file.mkdirs();
}
}
private void createFileIfNotExits(String filePath) throws IOException {
File file = new File(filePath);
if (!file.exists()) {
file.createNewFile();
}
}
private <T> String encodeJson(T t) {
return JSON.toJSONString(t);
}
}
2 ��������
��resources�´�������Ŀ¼ META-INF/services ,Ȼ�������ļ�
com.alibaba.csp.sentinel.init.InitFunc
���ļ��������������ȫ·��
com.ykq.config.FilePersistence
������Hystrix����
Hystrix����Netflix��Դ��һ���ӳٺ��ݴ���,���ڸ������Զ��ϵͳ��������ߵ�������,��ֹ����ʧ ��,�Ӷ�����ϵͳ�Ŀ��������ݴ��ԡ�Hystrix��Ҫͨ�����¼���ʵ���ӳٺ��ݴ���
- ��բ����:��ij����Ĵ����ʳ���һ������ֵʱ,Hystrix�����Զ����ֶ���բ,ֹͣ����÷���һ��ʱ�䡣
- ��Դ����:HystrixΪÿ��������ά����һ��С�͵��̳߳�(�����ź���)��������̳߳�����, ����������������ͱ������ܾ�,�������Ŷӵȴ�,�Ӷ�����ʧ���ж���
- ���:Hystrix���Խ���ʵʱ�ؼ������ָ������õı仯,����ɹ���ʧ�ܡ���ʱ���Լ����ܾ�������ȡ�
- ���˻���:������ʧ�ܡ���ʱ�����ܾ�,��·����ʱ,ִ�л��������������ɿ�����Ա�����ṩ,���緵��һ��ȱʡֵ��
- ������:��·����һ��ʱ���,���Զ�����"�뿪"״̬��
������ Gateway�C��������
5.1 ���ؼ��
��Ҷ���֪��������ܹ���,һ��ϵͳ�ᱻ���Ϊ�ܶ��������ô��Ϊ�ͻ���(pc androud ios ƽ��)Ҫ���ȥ������ô���������?���û�����صĴ���,����ֻ���ڿͻ��˼�¼ÿ������ĵ�ַ,Ȼ��ֱ�ȥ���á� axios.get(ip:port/url) axios.get(ip:port/url)
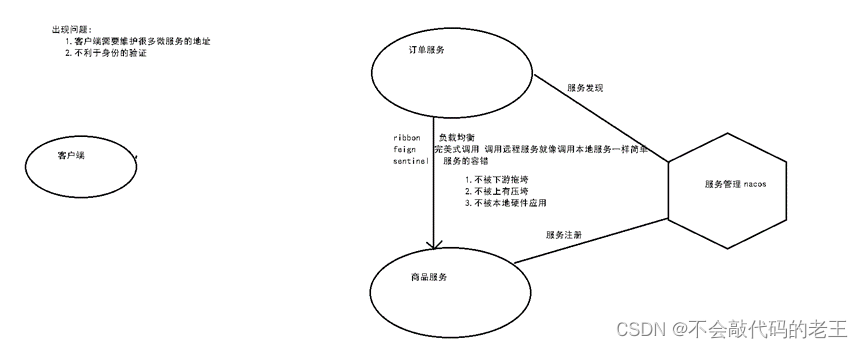
�����ļܹ�,���������������:
-
�ͻ��˶������ͬ������,���ӿͻ��˴�������ñ�д�ĸ�����
-
��֤����,ÿ��������Ҫ������֤��
-
���ڿ�������,��һ�������´�����Ը��ӡ�
(����: �������ajax��һ����ַ������һ����ַ:
Э��://ip:port ���������һ����ͬ,�����ֿ������⡣
http://192.168.10.11:8080 ----->https://192.168.10.11:8080
http://127.0.0.1:8080��>http://localhost:8080 ����
)
�������Щ������Խ���API�����������
��ν��API����,����ָϵͳ��ͳһ���,����װ��Ӧ�ó�����ڲ��ṹ,Ϊ�ͻ����ṩͳһ�� ��,һЩ��ҵ���������صĹ���������������ʵ��,������֤����Ȩ�����(�ڰ�����)��·��ת���ȵȡ� ������API����֮��,ϵͳ�ļܹ�ͼ�����������ʾ:
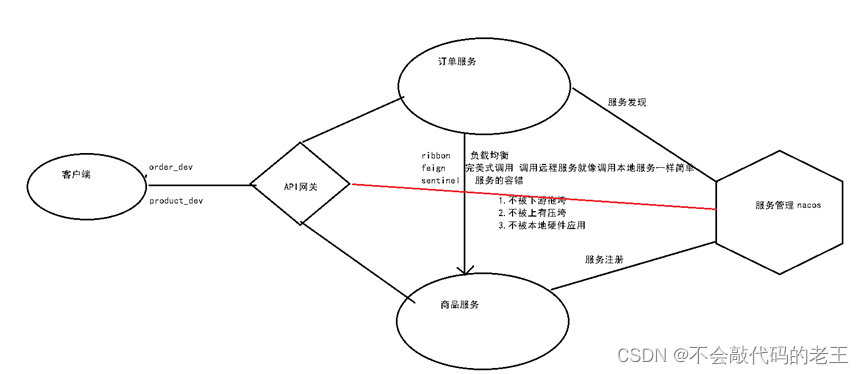
��ҵ��Ƚ����е�����,��������Щ:
- Ngnix+lua
ʹ��nginx�ķ���������ؾ����ʵ�ֶ�api�������ĸ��ؾ��⼰�߿���
lua��һ�ֽű�����,��������дһЩ����, nginx֧��lua�ű�
- Kong
����Nginx+Lua����,���ܸ�,�ȶ�,�ж�����õIJ��(��������Ȩ�ȵ�)���Կ��伴�á� ����:
ֻ֧��HttpЭ��;���ο���,������չ����;�ṩ����API,ȱ�������õĹܿء����÷�ʽ��
- Zuul 1.0(�� servlet 2.0 ) zuul2.0 û������
Netflix��Դ������,���ܷḻ,ʹ��JAVA����,���ڶ��ο��� ����:ȱ���ܿ�,����̬��
��;��������϶�;����Http������������Web����,���ܲ���Nginx
- Spring Cloud Gateway
Spring��˾Ϊ���滻Zuul�����������ط���,�������������ܡ�
ע��:SpringCloud alibaba����ջ�в�û���ṩ�Լ�������,���ǿ��Բ���Spring Cloud Gateway��������
5.2 Gateway���
Spring Cloud Gateway��Spring��˾����Spring 5.0,Spring Boot 2.0 �� Project Reactor ��������������,��ּ��Ϊ����ܹ��ṩһ�ּ���Ч��ͳһ�� API ·�ɹ�����ʽ������Ŀ������� Netflix Zuul,�䲻���ṩͳһ��·�ɷ�ʽ,���һ��� Filter ���ķ�ʽ�ṩ�����ػ����Ĺ���,����:��ȫ,��غ�������
�ŵ�:
-
����ǿ��:�ǵ�һ������Zuul��1.6��
-
����ǿ��:�����˺ܶ�ʵ�õĹ���,����ת������ء�������
-
�������,������չ.
ȱ��:
-
��ʵ������Netty��WebFlux,���Ǵ�ͳ��Servlet���ģ��,ѧϰ�ɱ���
-
���ܽ��䲿����Tomcat��Jetty��Servlet������,ֻ�ܴ��jar��ִ�� web.Jar
-
��ҪSpring Boot 2.0�����ϵİ汾,��֧��
5.3 Gateway��������
Ҫ��: ͨ�����������api����,Ȼ��ͨ�����ؽ�����ת������Ʒ����
5.3.1 ����һ��api-gateway�Ĺ��̲���������
<!--����gateway������-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
5.3.2 ����������
@SpringBootApplication
public class ApiGatewayApplication {
public static void main(String[] args) {
SpringApplication.run(ApiGatewayApplication.class,args);
}
}
5.3.3 �������ļ�

server:
port: 7000
spring:
application:
name: api-gateway
# ����api
cloud:
gateway:
routes:
- id: product_route # ·�ɵ�Ψһ��ʶ,ֻҪ���ظ�������,�����дĬ�ϻ�ͨ��UUID����,һ��д�ɱ�·�ɵķ�������
uri: http://localhost:8081/ # ��·�ɵĵ�ַ
order: 1 #��ʾ���ȼ� ����ԽС���ȼ�Խ��
predicates: #����: ִ��·�ɵ��ж�����
- Path= /product_serv/**
filters: # ������: ����������ǰ���������һЩ�ֽ�
- StripPrefix=1
��4��: ������Ŀ, ��ͨ������ȥ��������
5.3.2 ��ǿ��
�����������ļ���д����ת��·���ĵ�ַ, ǰ�������Ѿ���������ַд������������, ���������Ǵ�ע�����Ļ�ȡ�˵�ַ��
��1��:����nacos����
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-nacos-discovery</artifactId>
</dependency>
��2��:�����������ϼ�������ֵ�ע��
@SpringBootApplication
@EnableDiscoveryClient
public class ApiGatewayApplication {
public static void main(String[] args) {
SpringApplication.run(ApiGatewayApplication.class,args);
}
}
��3��:��application.yml�������ļ�
server:
port: 7000
spring:
application:
name: api-gateway
# ����api
cloud:
gateway:
routes:
- id: product_route # ·�ɵ�Ψһ��ʶ,ֻҪ���ظ�������,�����дĬ�ϻ�ͨ��UUID����,һ��д�ɱ�·�ɵķ�������
uri: lb://shop-product # ��·�ɵĵ�ַ
order: 1 #��ʾ���ȼ� ����ԽС���ȼ�Խ��
predicates: #����: ִ��·�ɵ��ж�����
- Path=/product_serv/**
filters: # ������: ����������ǰ���������һЩ�ֽ�
- StripPrefix=1
nacos:
discovery:
server-addr: localhost:8848
5.3.3 ���
��1��: ȥ������·�ɵ�����
server:
port: 7000
spring:
application:
name: api-gateway
# ����api
cloud:
nacos:
discovery:
server-addr: localhost:8848
gateway:
discovery:
locator:
enabled: true
��2��: ������Ŀ,��ͨ������ȥ��������
��ʱ��,�ͷ���ֻҪ�������ص�ַ/����/�ӿ��ĸ�ʽȥ����,�Ϳ��Եõ��ɹ���Ӧ
5.4 Gateway���ļܹ�
5.4.1 ��������
·��(Route) �� gateway ������������֮һ,��ʾһ�������·����Ϣ���塣��Ҫ����������ļ�����Ϣ:
-
id,·�ɱ�ʶ��,���������� Route��
-
uri,·��ָ���Ŀ�ĵ� uri,���ͻ����������ձ�ת����������
-
order,���ڶ�� Route ֮�������,��ֵԽС����Խ��ǰ,ƥ�����ȼ�Խ�ߡ�
-
predicate,���Ե������ǽ��������ж�,ֻ�ж��Զ�������,�Ż�������ִ��·�ɡ�
-
filter,�������������������Ӧ��Ϣ��
5.4.2 ִ������
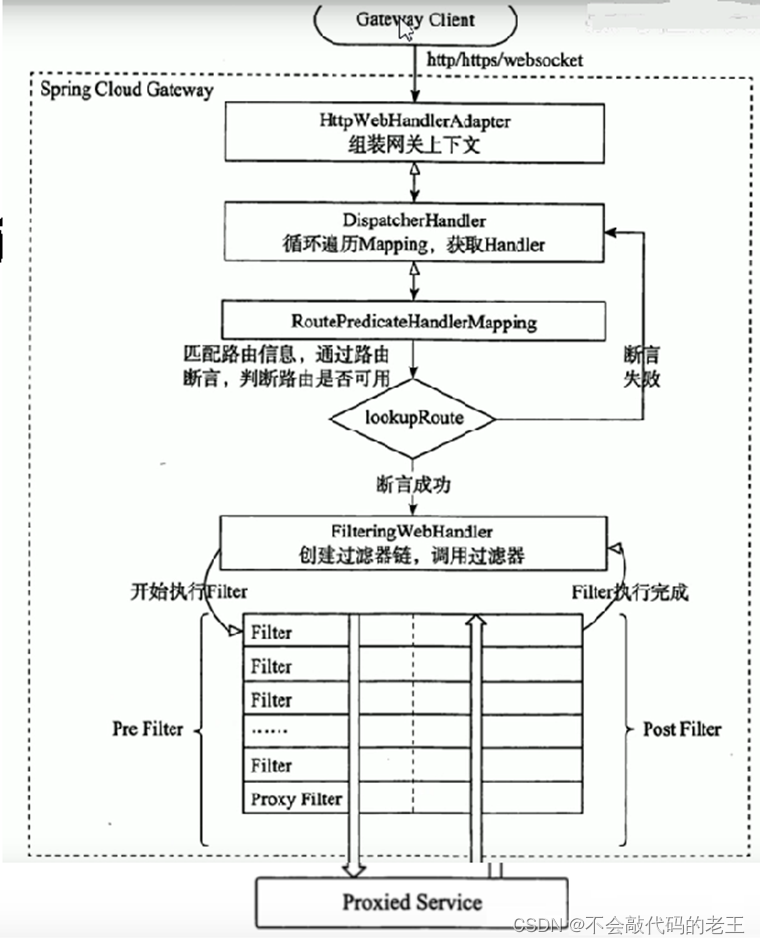
ִ�����̴�������:
1. Gateway Client��Gateway Server��������
2. �������ȻᱻHttpWebHandlerAdapter������ȡ��װ������������
3. Ȼ�����ص������Ļᴫ�ݵ�DispatcherHandler,����������ַ��� RoutePredicateHandlerMapping
4. RoutePredicateHandlerMapping����·�ɲ���,������·�ɶ����ж�·���Ƿ����
5. ��������Գɹ�,��FilteringWebHandler������������������
6. �����һ�ξ���PreFilter�C����CPostFilter�ķ���,���շ�����Ӧ
5.5 ����
Predicate(����, ν��) ���ڽ��������ж�,ֻ�ж��Զ�������,�Ż�������ִ��·�ɡ�
���Ծ���˵: �� ʲô������ ���ܽ���·��ת��
5.5.1 ����·�ɶ��Թ���
SpringCloud Gateway�����������õĶ��Թ���,������Щ���Զ���HTTP����IJ�ͬ����ƥ��������:
- ����Datetime���͵Ķ��Թ���
�����͵Ķ��Ը���ʱ�����ж�,��Ҫ������:
AfterRoutePredicateFactory: ����һ�����ڲ���,�ж����������Ƿ�����ָ������
BeforeRoutePredicateFactory: ����һ�����ڲ���,�ж����������Ƿ�����ָ������
BetweenRoutePredicateFactory: �����������ڲ���,�ж����������Ƿ���ָ��ʱ�����
-After=2019-12-31T23:59:59.789+08:00[Asia/Shanghai]
- ����Զ�̵�ַ�Ķ��Թ��� RemoteAddrRoutePredicateFactory:
����һ��IP��ַ��,�ж�����������ַ�Ƿ��ڵ�ַ����
-RemoteAddr=192.168.1.1/24
- ����Cookie�Ķ��Թ���
CookieRoutePredicateFactory:������������,cookie ���ֺ�һ���������ʽ�� �ж�����
cookie�Ƿ���и���������ֵ���������ʽƥ�䡣
-Cookie=chocolate, ch.
- ����Header�Ķ��Թ���
HeaderRoutePredicateFactory:������������,�������ƺ��������ʽ�� �ж�����Header�Ƿ�
���и���������ֵ���������ʽƥ�䡣 key value
-Header=X-Request-Id, \d+
- ����Host�Ķ��Թ���
HostRoutePredicateFactory:����һ������,������ģʽ���ж������Host�Ƿ�����ƥ�����
-Host=**.testhost.org
- ����Method�����Ķ��Թ���
MethodRoutePredicateFactory:����һ������,�ж����������Ƿ��ָ��������ƥ�䡣
-Method=GET
- ����Path����·���Ķ��Թ���
PathRoutePredicateFactory:����һ������,�ж������URI�����Ƿ�����·������
-Path=/foo/{segment}����Query��������Ķ��Թ���
QueryRoutePredicateFactory :������������,����param���������ʽ, �ж���������Ƿ��
�и���������ֵ���������ʽƥ�䡣
-Query=baz, ba.
- ����·��Ȩ�صĶ��Թ���
WeightRoutePredicateFactory:����һ��[����,Ȩ��], Ȼ�����ͬһ�����ڵ�·�ɰ���Ȩ��ת��
routes:
-id: weight_route1 uri: host1 predicates:
-Path=/product/**
-Weight=group3, 1
-id: weight_route2 uri: host2 predicates:
-Path=/product/**
-Weight= group3, 9
- ����·�ɶ��Թ�����ʹ��
������������֤�������ö��Ե�ʹ��:
server:
port: 7000
spring:
application:
name: api-gateway
# ����api
cloud:
nacos:
discovery:
server-addr: localhost:8848
gateway:
# discovery:
# locator:
# enabled: true
routes:
- id: product_route # ·�ɵ�Ψһ��ʶ,ֻҪ���ظ�������,�����дĬ�ϻ�ͨ��UUID����,һ��д�ɱ�·�ɵķ�������
uri: lb://shop-product # ��·�ɵĵ�ַ
order: 1 #��ʾ���ȼ� ����ԽС���ȼ�Խ��
predicates: #����: ִ��·�ɵ��ж�����
- Path=/product_serv/**
- Before=2020-11-28T00:00:00.000+08:00 # ��ʾ��2020ǰ����
- Method=POST # ����ʽ����ΪPOST
filters: # ������: ����������ǰ���������һЩ�ֽ�
- StripPrefix=1
5.5.2 �Զ���·�ɶ��Թ���
�������趨һ������: �������ǵ�Ӧ�ý�����age��(min,max)֮����������ʡ�
��1��:�������ļ���,����һ��Age�Ķ�������
routes:
- id: product_route # ·�ɵ�Ψһ��ʶ,ֻҪ���ظ�������,�����дĬ�ϻ�ͨ��UUID����,һ��д�ɱ�·�ɵķ�������
uri: lb://shop-product # ��·�ɵĵ�ַ
order: 1 #��ʾ���ȼ� ����ԽС���ȼ�Խ��
predicates: #����: ִ��·�ɵ��ж�����
- Path=/product_serv/**
- Age=18,60
��2��:�Զ���һ�����Թ���, ʵ�ֶ��Է���
package com.ykq.config;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.lang.StringUtils;
import org.springframework.cloud.gateway.handler.predicate.AbstractRoutePredicateFactory;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import java.util.Arrays;
import java.util.List;
import java.util.function.Predicate;
//����Ϊ�Զ����һ��������,��������������������ļ��е�ֵ
@Component
public class AgeRoutePredicateFactory extends AbstractRoutePredicateFactory<AgeRoutePredicateFactory.Config> {
public AgeRoutePredicateFactory() {
super(AgeRoutePredicateFactory.Config.class);
}
//��ȡ�����ļ��е����ݲ����ø��������е�����
public List<String> shortcutFieldOrder() {
return Arrays.asList("minAge","maxAge");
}
public Predicate<ServerWebExchange> apply(AgeRoutePredicateFactory.Config config) {
return (exchange) -> {
String age = exchange.getRequest().getQueryParams().getFirst("age");
if(StringUtils.isNotEmpty(age)){
int a = Integer.parseInt(age);
return a>=config.minAge && a<=config.maxAge;
}
return true;
};
}
@Data
@NoArgsConstructor
public static class Config{
private Integer minAge;
private Integer maxAge;
}
}
��3��:��������
#���Է��ֵ�age��(18,60)���Է���,������Χ���ܷ���
http://localhost:7000/product-serv/product/1?age=30
http://localhost:7000/product-serv/product/1?age=10
5.6 ������
����֪ʶ��:
1 ����: ����������������Ĵ��ݹ�����,���������Ӧ��һЩ�ֽ�
2 ��������: Pre Post
3 ����: �ֲ�������(������ijһ��·����) ȫ�ֹ�����(����ȫ��·����)
��Gateway��, Filter����������ֻ������:��pre�� �� ��post����
-
PRE: ���ֹ�����������·��֮ǰ���á����ǿ��������ֹ�����ʵ��������֤���ڼ�Ⱥ��ѡ�����������¼������Ϣ�ȡ�
-
POST:���ֹ�������·�ɵ������Ժ�ִ�С����ֹ�����������Ϊ��Ӧ���ӱ���HTTP Header���ռ�ͳ����Ϣ��ָ�ꡢ����Ӧ���������ͻ��˵ȡ�

Gateway ��Filter�����÷�Χ�ɷ�Ϊ����: GatewayFilter��GlobalFilter��
-
GatewayFilter:Ӧ�õ�����·�ɻ���һ�������·���ϡ�
-
GlobalFilter:Ӧ�õ����е�·���ϡ�
5.6.1 �ֲ�������
�ֲ�����������Ե���·�ɵĹ�������
5.6.1.1 ���þֲ�������
��SpringCloud Gateway�������˺ܶͬ���͵�����·�ɹ�������
https://www.cnblogs.com/zhaoxiangjun/p/13042189.html


���þֲ���������ʹ��
server:
port: 7000
spring:
application:
name: api-gateway
# ����api
cloud:
nacos:
discovery:
server-addr: localhost:8848
gateway:
# discovery:
# locator:
# enabled: true
routes:
- id: product_route # ·�ɵ�Ψһ��ʶ,ֻҪ���ظ�������,�����дĬ�ϻ�ͨ��UUID����,һ��д�ɱ�·�ɵķ�������
uri: lb://shop-product # ��·�ɵĵ�ַ
order: 1 #��ʾ���ȼ� ����ԽС���ȼ�Խ��
predicates: #����: ִ��·�ɵ��ж�����
- Path=/product_serv/**
- Age=18,60
# - Before=2020-11-28T00:00:00.000+08:00 # ��ʾ��2020ǰ����
# - Method=POST # ����ʽ����ΪPOST
filters: # ������: ����������ǰ���������һЩ�ֽ�
- StripPrefix=1
- SetStatus=2000
5.6.1.2 �Զ���ֲ������� (ʡ��)
��1��:�������ļ���,����һ��Log�Ĺ���������
filters: # ������: ����������ǰ���������һЩ�ֽ�
- StripPrefix=1
- SetStatus=2000
- Log=true,false
��2��:�Զ���һ������������,ʵ�ַ���
package com.ykq.config;
import lombok.Data;
import org.springframework.cloud.gateway.filter.GatewayFilter;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.factory.AbstractGatewayFilterFactory;
import org.springframework.cloud.gateway.filter.factory.SetStatusGatewayFilterFactory;
import org.springframework.cloud.gateway.support.HttpStatusHolder;
import org.springframework.cloud.gateway.support.ServerWebExchangeUtils;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import java.util.Arrays;
import java.util.List;
@Component
public class LogGatewayFilterFactory extends AbstractGatewayFilterFactory<LogGatewayFilterFactory.Config> {
public LogGatewayFilterFactory() {
super(LogGatewayFilterFactory.Config.class);
}
public List<String> shortcutFieldOrder() {
return Arrays.asList("consoleLog","cacheLog");
}
@Override
public GatewayFilter apply(Config config) {
return new GatewayFilter() {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
if(config.cacheLog){
System.out.println("����������־");
}
if(config.consoleLog){
System.out.println("��������̨��־");
}
return chain.filter(exchange);
}
};
}
@Data
public static class Config {
private Boolean consoleLog;
private Boolean cacheLog;
public Config() {
}
}
}
��3��:��������
5.6.2 ȫ�ֹ�����
ȫ�ֹ���������������·��, �������á�ͨ��ȫ�ֹ���������ʵ�ֶ�Ȩ��ͳһУ��,��ȫ����֤�ȹ��ܡ�
5.6.2.1 ����ȫ�ֹ�����
SpringCloud Gateway�ڲ�Ҳ��ͨ��һϵ�е�����ȫ�ֹ�����������·��ת�����д�������:
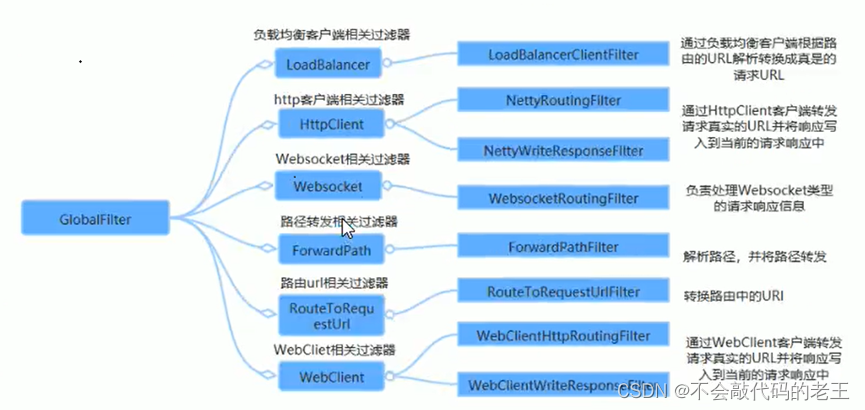
5.6.2.2 �Զ���ȫ�ֹ�����
���õĹ������Ѿ�������ɴֵĹ���,���Ƕ�����ҵ������һЩҵ���ܴ���,������Ҫ�����Լ���д��������ʵ�ֵ�,��ô����һ��ͨ���������ʽ�Զ���һ��������,ȥ���ͳһ��Ȩ��У�顣
�����еļ�Ȩ��:
-
���ͻ��˵�һ���������ʱ,����˶��û�������Ϣ��֤(��¼)
-
��֤ͨ��,���û���Ϣ���м����γ�token,���ظ��ͻ���aaaa,��Ϊ��¼ƾ֤
-
�Ժ�ÿ������,�ͻ��˶�Я����֤��token
-
����˶�token���н���,�ж��Ƿ���Ч��
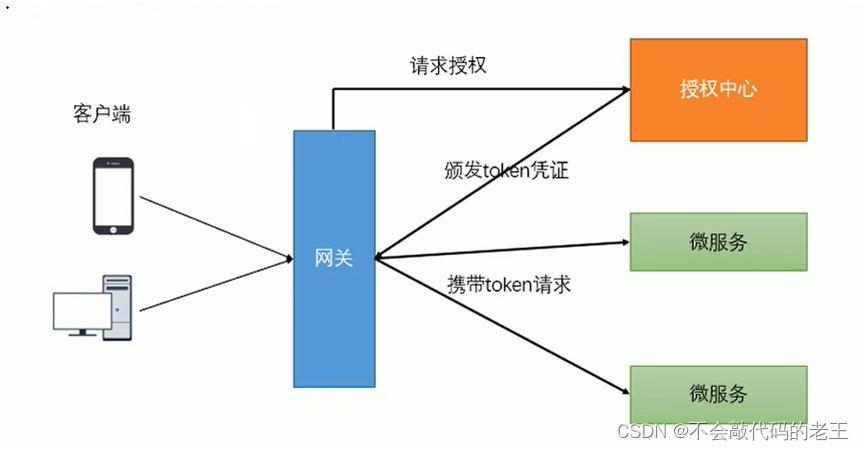
����ͼ,������֤�û��Ƿ��Ѿ���¼��Ȩ�Ĺ��̿���������ͳһ���顣
����ı������������Ƿ�Я��tokenƾ֤�Լ�token����ȷ�ԡ�
����������Զ���һ��GlobalFilter,ȥУ���������������������Ƿ����"token",��β������������"token"��ת��·��,����ִ����������
�Զ���ȫ�ֹ����� Ҫ��:����ʵ��GlobalFilter,Order�ӿ�
package com.ykq.config;
import org.apache.commons.lang.StringUtils;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Component
public class AuthGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String token = exchange.getRequest().getQueryParams().getFirst("token");
if(StringUtils.isNotEmpty(token) && StringUtils.equals(token,"admin")){
return chain.filter(exchange);
}
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}
//���ȼ� ֵԽС���ȼ�Խ��
@Override
public int getOrder() {
return 1;
}
}
5.7 ��������
5.7.1 �����������㷨
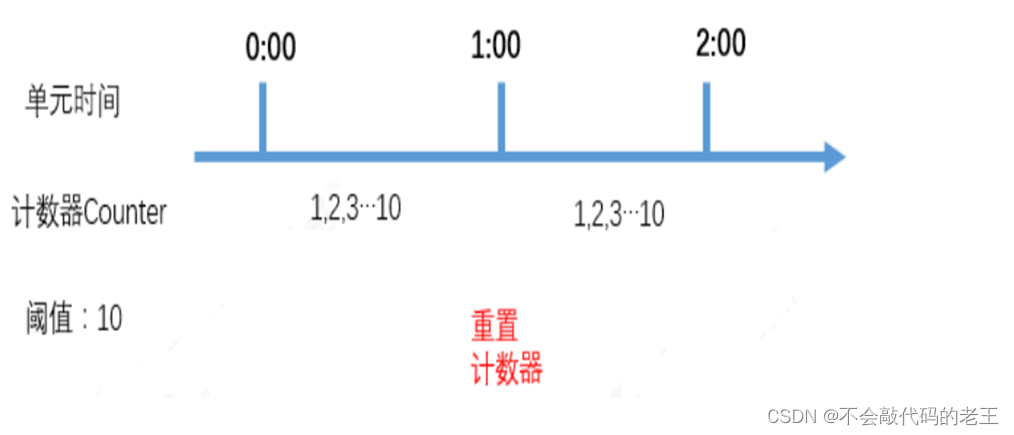
(1) ������
�����������㷨�����һ������ʵ�ַ�ʽ���䱾����ͨ��ά��һ����λʱ���ڵļ�����,ÿ�������������1,����λʱ���ڼ������ۼӵ������趨����ֵ,��֮��������ܾ�,ֱ����λʱ���Ѿ���ȥ,�ٽ�����������Ϊ��
(2) ©Ͱ�㷨
©Ͱ�㷨���Ժܺõ����������صĴ�С,�Ӷ���ֹ����������©Ͱ���Կ�����һ�����г�������ʱ��ĵ�����������,���©Ͱ(������)���,��ô���ݰ��ᱻ������ ��������,©Ͱ�㷨���Կ��ƶ˿ڵ������������,ƽ�������ϵ�ͻ������,ʵ����������,�Ӷ�Ϊ�����ṩһ���ȶ���������
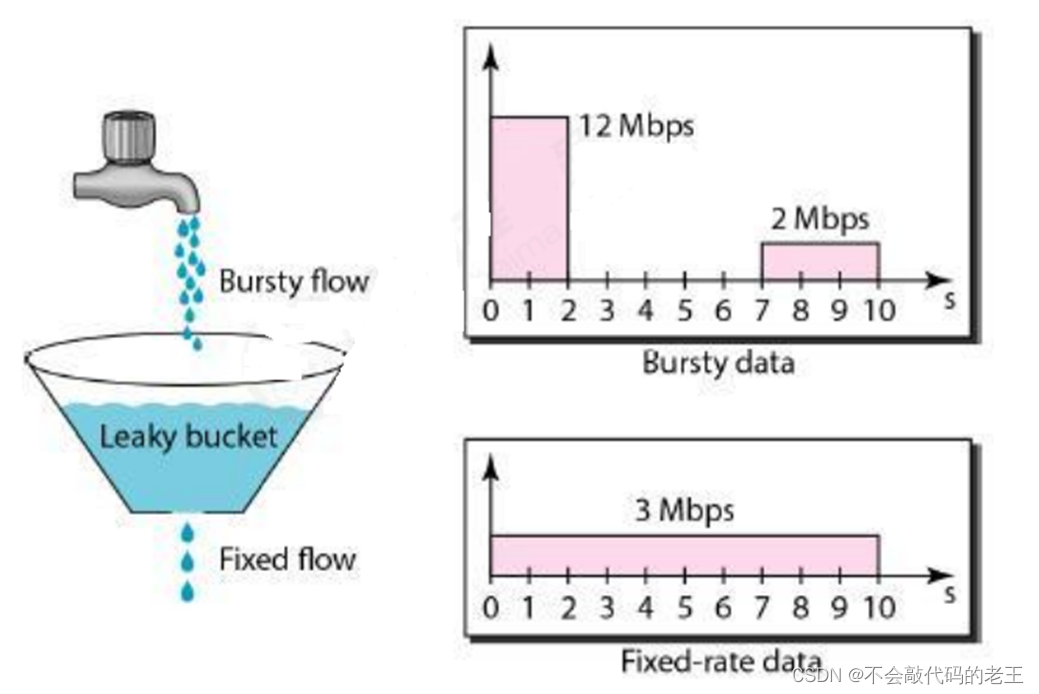
Ϊ�˸��õĿ�������,©Ͱ�㷨��Ҫͨ�������������п���:һ����Ͱ�Ĵ�С,֧������ͻ������ʱ���Դ���ٵ�ˮ(burst),��һ����ˮͰ©���Ĵ�С(rate)��
(3) ����Ͱ�㷨
����Ͱ�㷨�Ƕ�©Ͱ�㷨��һ�ָĽ�,Ͱ�㷨�ܹ�����������õ�����,������Ͱ�㷨�ܹ������Ƶ��õ�ƽ�����ʵ�ͬʱ������һ���̶ȵ�ͻ�����á�������Ͱ�㷨��,����һ��Ͱ,������Ź̶����������ơ��㷨�д���һ�ֻ���,��һ����������Ͱ�з����ơ�ÿ�����������Ҫ�Ȼ�ȡ����,ֻ���õ�����,���л������ִ��,����ѡ��ѡ��ȴ����õ����ơ�����ֱ�Ӿܾ�����������������dz������ϵĽ���,���Ͱ���������ﵽ����,�Ͷ�������,���Ծʹ����������,Ͱ��һֱ�д����Ŀ�������,��ʱ����������Ϳ���ֱ���õ�����ִ��,��������qpsΪ100,��ô��������ʼ�����һ���,Ͱ�о��Ѿ���100��������,��ʱ����û��ȫ������,��������ɶ����ṩ����ʱ,�����������Եֵ�˲ʱ��100����������,ֻ��Ͱ��û������ʱ,����Ż���еȴ�,����൱����һ��������ִ�С�
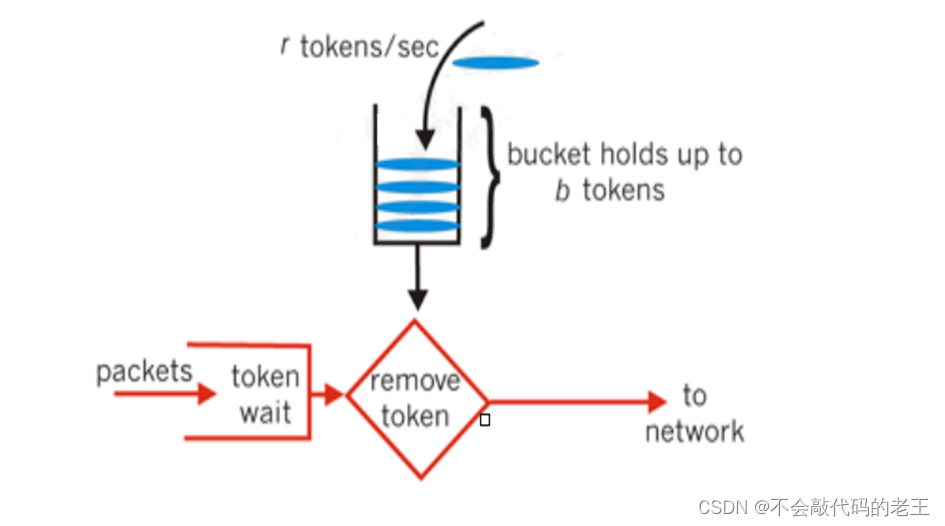
5.7.2����Sentinel������
�� 1.6.0 �汾��ʼ,Sentinel �ṩ�� Spring Cloud Gateway ������ģ��,�����ṩ������Դά�ȵ�����:
-
route ά��:���� Spring �����ļ������õ�·����Ŀ,��Դ��Ϊ��Ӧ�� routeId
-
�Զ��� API ά��:�û��������� Sentinel �ṩ�� API ���Զ���һЩ API ����
Sentinel 1.6.0 ������ Sentinel API Gateway Adapter Common ģ��,��ģ���а������������Ĺ�����Զ��� API ��ʵ�������:
-
GatewayFlowRule :������������,��� API Gateway �ij������Ƶ���������,������Բ�ͬroute ���Զ���� API �����������,֧����������еIJ�����Header����Դ IP �Ƚ��ж��ƻ���������
-
ApiDefinition :�û��Զ���� API �������,���Կ�����һЩ URL ƥ�����ϡ��������ǿ��Զ���һ�� API �� my_api ,���� path ģʽΪ /foo/** �� /baz/** �Ķ��鵽 my_api ��� API�������档������ʱ������������Զ���� API ����ά�Ƚ���������
(1)�����
����Sentinel ����Ӧ����
<!--����spring-cloud-gateway��sentinel���ϵ�jar-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-spring-cloud-gateway-adapter</artifactId>
</dependency>
(2) �������
@Configuration
public class GatewayConfiguration {
private final List<ViewResolver> viewResolvers;
private final ServerCodecConfigurer serverCodecConfigurer;
public GatewayConfiguration(ObjectProvider<List<ViewResolver>> viewResolversProvider,
ServerCodecConfigurer serverCodecConfigurer) {
this.viewResolvers = viewResolversProvider.getIfAvailable(Collections::emptyList);
this.serverCodecConfigurer = serverCodecConfigurer;
}
/**
* �����������쳣������:SentinelGatewayBlockExceptionHandler
*/
@Bean
@Order(Ordered.HIGHEST_PRECEDENCE)
public SentinelGatewayBlockExceptionHandler sentinelGatewayBlockExceptionHandler() {
return new SentinelGatewayBlockExceptionHandler(viewResolvers, serverCodecConfigurer);
}
/**
* ��������������
*/
@Bean
@Order(Ordered.HIGHEST_PRECEDENCE)
public GlobalFilter sentinelGatewayFilter() {
return new SentinelGatewayFilter();
}
/**
* ���ó�ʼ������������
*/
@PostConstruct
public void initGatewayRules() {
Set<GatewayFlowRule> rules = new HashSet<>();
rules.add(new GatewayFlowRule("product_service") //��Դ����
.setCount(1) // ������ֵ
.setIntervalSec(1) // ͳ��ʱ�䴰��,��λ����,Ĭ���� 1 ��
);
GatewayRuleManager.loadRules(rules);
}
}
-
����Sentinel ��Gateway������ͨ�����ṩ��Filter����ɵ�,ʹ��ʱֻ��ע���Ӧ��SentinelGatewayFilter ʵ���Լ� SentinelGatewayBlockExceptionHandler ʵ�����ɡ�
-
@PostConstruct�����ʼ���ļ��ط���,����ָ����Դ����������������Դ������Ϊ order-service ,ͳ��ʱ����1����,������ֵ��1����ʾÿ��ֻ�ܷ���һ������
(3)��������
spring:
application:
name: shop-gateway-server
cloud:
gateway:
routes:
- id: product_service #·�ɵ�ID,û�й̶�����Ҫ��Ψһ,������Ϸ�����
uri: lb://shop-product-service #ƥ����ṩ�����·�ɵ�ַ
predicates:
#- Path=/product/** #����,·����ƥ��Ľ���·��
- Path=/product-service/**
filters:
- StripPrefix=1
��һ�����ڶ�η��� http://localhost/product-service/product/2 �Ϳ��Կ��������������ˡ�

(4)�Զ����쳣��ʾ
������������ҳ����ʾ����Blocked by Sentinel: FlowException��Ϊ��չʾ�����Ѻõ�������ʾ,Sentinel֧���Զ����쳣������
�������� GatewayCallbackManager ע��ص����ж���:
setBlockHandler :ע�ắ������ʵ���Զ����������������������,��Ӧ�ӿ�Ϊ BlockRequestHandler ��Ĭ��ʵ��Ϊ DefaultBlockRequestHandler ,��������ʱ�᷵������ ������Ĵ�����Ϣ: Blocked by Sentinel: FlowException ��
@PostConstruct
public void initBlockHandlers() {
BlockRequestHandler blockRequestHandler = new BlockRequestHandler() {
public Mono<ServerResponse> handleRequest(ServerWebExchange serverWebExchange, Throwable throwable) {
Map map = new HashMap<>();
map.put("code", 001);
map.put("message", "�Բ���,�ӿ�������");
return ServerResponse.status(HttpStatus.OK).
contentType(MediaType.APPLICATION_JSON_UTF8).
body(BodyInserters.fromObject(map));
}
};
GatewayCallbackManager.setBlockHandler(blockRequestHandler);
}
(5)�Զ���API����
/**
* ���ó�ʼ������������
*/
@PostConstruct
public void initGatewayRules() {
Set<GatewayFlowRule> rules = new HashSet<>();
rules.add(new
GatewayFlowRule("product_api1").setCount(1).setIntervalSec(1));
rules.add(new
GatewayFlowRule("product_api2").setCount(1).setIntervalSec(1));
GatewayRuleManager.loadRules(rules);
}
//�Զ���API����
@PostConstruct
private void initCustomizedApis() {
Set<ApiDefinition> definitions = new HashSet<>();
ApiDefinition api1 = new ApiDefinition("product_api1")
.setPredicateItems(new HashSet<ApiPredicateItem>() {{
// ��/product-serv/product/api1 ��ͷ������
add(new ApiPathPredicateItem().setPattern("/product-
serv/product/api1/**").
setMatchStrategy(SentinelGatewayConstants.URL_MATCH_STRATEGY_PREFIX));
}});
ApiDefinition api2 = new ApiDefinition("product_api2")
.setPredicateItems(new HashSet<ApiPredicateItem>() {{
// ��/product-serv/product/api2/demo1 ��ɵ�url·��ƥ��
add(new ApiPathPredicateItem().setPattern("/product-
serv/product/api2/demo1"));
}});
definitions.add(api1);
definitions.add(api2);
GatewayApiDefinitionManager.loadApiDefinitions(definitions);
}
5.8 ���ظ߿���
�߿���HA(High Availability)�Ƿֲ�ʽϵͳ�ܹ�����б��뿼�ǵ�����֮һ,��ͨ����ָ,ͨ����Ƽ���ϵͳ�����ṩ�����ʱ�䡣���Ƕ�֪��,������ϵͳ�߿��õĴ��,����������ϵͳ�߿������� ���պ͵���,Ӧ�þ�����ϵͳ��ƵĹ����б��ⵥ�㡣��������,�߿��ñ�֤��ԭ����"��Ⱥ��",���߽�"����":ֻ��һ������,���˷������Ӱ��;��������౸��,���˻�������backup�ܹ����ϡ� ngnix linux
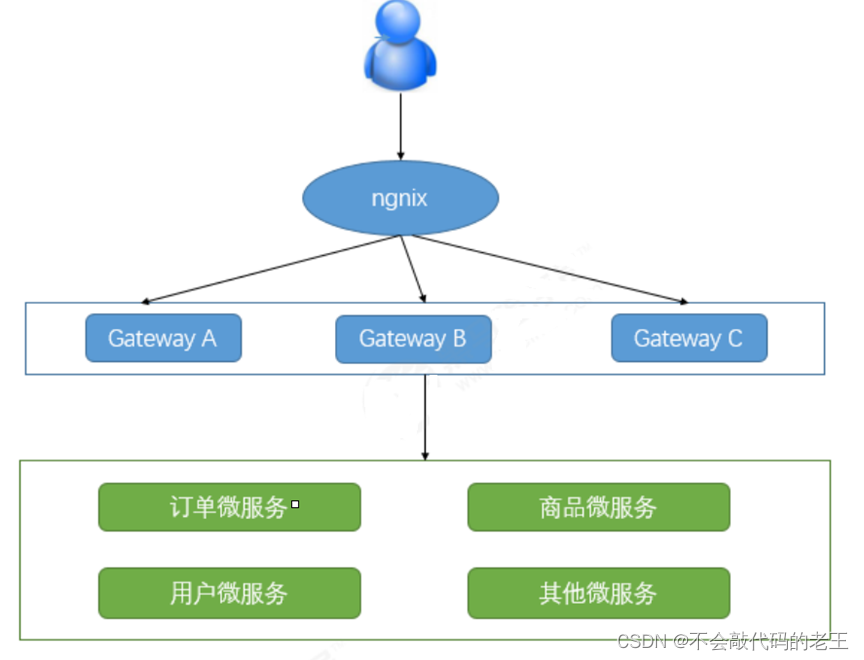
����ʵ��ʹ�� Spring Cloud Gateway �ķ�ʽ����ͼ,��ͬ�Ŀͻ���ʹ�ò�ͬ�ĸ��ؽ�����ַ�����˵� Gateway,Gateway ��ͨ��HTTP���ú�˷���,��������������Ϊ�˱�֤ Gateway �ĸ߿�����,ǰ�˿���ͬʱ������� Gateway ʵ�����и���,�� Gateway ��ǰ��ʹ�� Nginx ���� F5 ���и���ת���Դﵽ�߿����ԡ�
(1) �����GateWay����
�� shop_gateway_server8080 ��application.yml��������������
server:
port: 80
spring:
application:
name: shop-gateway-server
cloud:
gateway:
routes:
- id: product_service #·�ɵ�ID,û�й̶�����Ҫ��Ψһ,������Ϸ�����
uri: lb://shop-product-service #ƥ����ṩ�����·�ɵ�ַ
predicates:
#- Path=/product/** #����,·����ƥ��Ľ���·��
- Path=/product-service/**
filters:
- RewritePath=/product-service/(?<segment>.*), /$\{segment}
discovery:
locator:
enabled: true # ������������ת��
lower-case-service-id: true #������Сд
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka/
registry-fetch-interval-seconds: 5 # ��ȡ�����б�������:5s
instance:
preferIpAddress: true
ip-address: 127.0.0.1
ͨ����ͬ��profifiles���������������ط���,����˿ڷֱ�Ϊ8080��8081���������֤����Ч����һ�µ�.
(2) ����ngnix
#���ö�̨������(����ֻ��һ̨�������ϵIJ�ͬ�˿�)
upstream gateway {
server 127.0.0.1:8081;
server 127.0.0.1:8080;
}
#����ת��mysvr ����ķ������б�
location / {
proxy_pass http://gateway;
}
���������ͨ������http://localhost/product-service/product/2�����Ч����֮ǰ��һ���ġ���ιر�һ̨���ط�����,���ǿ���֧�ֲ�������ķ��ʡ�
������ Sleuth�C��·��
6.1 ��·�ٽ���
�ڴ���ϵͳ����������,һ��ϵͳ����ֳ�������ģ�顣��Щģ�鸺��ͬ�Ĺ���,��ϳ�ϵͳ,���տ����ṩ�ḻ�Ĺ��ܡ������ּܹ���,һ������������Ҫ�漰�������������Ӧ�ù����ڲ�ͬ������ģ�鼯��,��Щ����ģ��,�п������ɲ�ͬ���Ŷӿ���������ʹ�ò�ͬ�ı��������ʵ�֡��п��ܲ����˼�ǧ̨������,�������ͬ����������,Ҳ����ζ�����ּܹ���ʽҲ�����һЩ����:
-
��ο��ٷ�������?
-
����жϹ���Ӱ�췶Χ?
-
����������������Լ������ĺ�����?
-
��η�����·���������Լ�ʵʱ�����滮?
�ֲ�ʽ��·��(Distributed Tracing),���ǽ�һ�ηֲ�ʽ����ԭ�ɵ�����·,������־��¼,���ܼ�ز���һ�ηֲ�ʽ����ĵ����������չʾ�������������ڵ��ϵĺ�ʱ��������嵽����̨������IP��ÿ������ڵ������״̬200 500�ȵȡ�
��������·�ټ�����������Щ:
cat �ɴ��ڵ�����Դ,����Java������ʵʱӦ�ü��ƽ̨,����ʵʱӦ�ü��,ҵ���� �� ����
������ͨ���������ķ�ʽ��ʵ�ּ��,����: ������,�������ȡ� �Դ���������Ժܴ�,���ɳɱ��ϸߡ����սϴ�
zipkin ��Twitter��˾��Դ,����Դ����ֲ�ʽ�ĸ���ϵͳ,�����ռ�����Ķ�ʱ����,�Խ��
����ܹ��е��ӳ�����,����:���ݵ��ռ����洢�����Һ�չ�֡�ͼ�λ������ò�Ʒ���spring-cloud-sleuth ʹ�ý�Ϊ��, ���ɺܷ���, ���ǹ��ܽϼ�
pinpoint Pinpoint�Ǻ����˿�Դ�Ļ����ֽ���ע��ĵ���������,�Լ�Ӧ�ü�ط������ߡ��ص�
��֧�ֶ��ֲ��,UI����ǿ��,������������롣
skywalking
SkyWalking�DZ�����Դ�Ļ����ֽ���ע��ĵ���������,�Լ�Ӧ�ü�ط������ߡ��ص���֧�ֶ�
�ֲ��,UI���ܽ�ǿ,������������롣Ŀǰ�Ѽ���Apache��������
Sleuth (��־��¼ÿһ����·�ϵ����нڵ�,�Լ���Щ�ڵ����ڵĻ���,�ͺ�ʱ��)log4j
SpringCloud �ṩ�ķֲ�ʽϵͳ����·�ٽ��������
ע��:SpringCloud alibaba����ջ�в�û���ṩ�Լ�����·�ټ�����,���ǿ��Բ���Sleuth +
Zipkin������·�ٽ������
Springcloud �������Լ����������ǰ����п��������һ�� ����������ϵ����⡣
6.2 Sleuth����
6.2.1 Sleuth����
SpringCloud Sleuth��Ҫ���ܾ����ڷֲ�ʽϵͳ���ṩ�ٽ��������������������Google Dapper�����, �����˽�һ��Sleuth�е��������ظ��
Trace (һ��������·�C�����ܶ�span(����ӿ�))
��һ��Trace Id(�ᴩ������·)��ͬ��Span�����γ�һ����״�ṹ��Ϊ��ʵ���������,������ֲ�ʽϵͳ����ڶ˵�ʱ,ֻ��Ҫ������ٿ��Ϊ������һ��Ψһ�ı�ʶ(��TraceId),ͬʱ�ڷֲ�ʽϵͳ�ڲ���ת��ʱ��,���ʼ�ձ��ִ��ݸ�Ψһֵ,ֱ����������ķ��ء���ô���ǾͿ���ʹ�ø�Ψһ��ʶ�����е�����������,�γ�һ��������������·��
Span
������һ������Ĺ�����Ԫ��Ϊ��ͳ�Ƹ�������Ԫ���ӳ�,������������������ʱ��,Ҳͨ��һ��Ψһ��ʶ(SpanId)��������Ŀ�ʼ��������̺ͽ�����ͨ��SpanId�Ŀ�ʼ�ͽ���ʱ���,����ͳ�Ƹ�span�ĵ���ʱ��,����֮��,���ǻ����Ի�ȡ���¼������ơ�������Ϣ��Ԫ���ݡ�
Annotation
������¼һ��ʱ���ڵ��¼�,�ڲ�ʹ�õ���Ҫע��:
-
cs(Client Send)�ͻ��˷�������,��ʼһ�����������
-
sr(Server Received)����˽��ܵ�����ʼ���д���, sr-cs = �����ӳ�(������õ�ʱ��)
-
ss(Server Send)����˴�����������͵��ͻ���,ss - sr = �������ϵ�������ʱ��
-
cr(Client Reveived)�ͻ��˽��ܵ�����˵���Ӧ,��������� cr - sr = �������ʱ��
6.2.2 Sleuth����
������ͨ��֮ǰ����Ŀ��������Sleuth,������Ű����ı�д��
�ĸ���������Sleuth����
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
��������,����֮��,���ǿ����ڿ���̨�۲쵽sleuth����־���

���� 5399d5cb061971bd ��TraceId, 5399d5cb061971bd ��SpanId,���ε�����һ��ȫ�ֵ�TraceId,��������·����������ϸ����ÿ���������־,���ѿ�������ľ�����̡�
�鿴��־�ļ�������һ���ܺõķ���,������Խ��Խ����־�ļ�Ҳ��Խ��Խ��,ͨ��Zipkin���Խ���־�ۺ�,�����п��ӻ�չʾ��ȫ�ļ�����
6.3 Zipkin�ļ���
6.3.1 ZipKin����
Zipkin �� Twitter ��һ����Դ��Ŀ,������Google Dapperʵ��,���������ռ�����Ķ�ʱ����,�Խ������ܹ��е��ӳ�����,�������ݵ��ռ����洢չ�֡����Һ����ǿ���ʹ�������ռ�������������������·�ĸ�������,��ͨ�����ṩ��REST API�ӿ����������Dz�ѯ����������ʵ�ֶԷֲ�ʽϵͳ�ļ�س���,�Ӷ���ʱ�ط���ϵͳ�г��ֵ��ӳ��������Ⲣ�ҳ�ϵͳ����ƿ���ĸ�Դ
���������� API �ӿ�֮��,��Ҳ�ṩ�˷����UI�������������ֱ�۵�����������Ϣ�ͷ���������·��ϸ,����:���Բ�ѯij��ʱ���ڸ��û�����Ĵ���ʱ��ȡ�
Zipkin �ṩ�˿ɲ�����ݴ洢��ʽ:In-Memory��MySql��Cassandra �Լ� Elasticsearch��
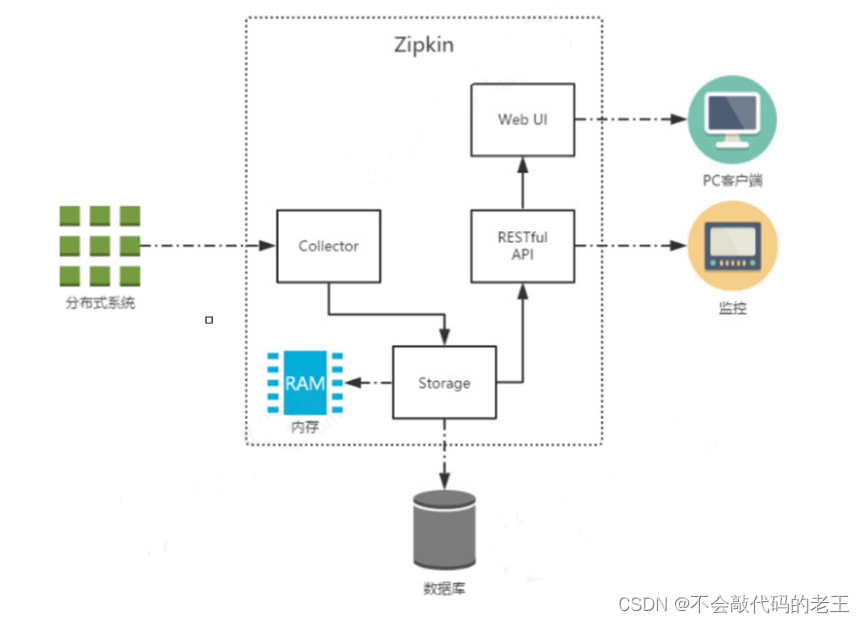
��ͼչʾ�� Zipkin �Ļ����ܹ�,����Ҫ�� 4 �������������:
-
Collector:�ռ������,����Ҫ���ڴ������ⲿϵͳ�������ĸ�����Ϣ,����Щ��Ϣת��ΪZipkin �ڲ������� Span ��ʽ,��֧�ֺ����Ĵ洢��������չʾ�ȹ��ܡ�
-
Storage:�洢���,����Ҫ�Դ����ռ������յ��ĸ�����Ϣ,Ĭ�ϻὫ��Щ��Ϣ�洢���ڴ���,����Ҳ�����Ĵ˴洢����,ͨ��ʹ�������洢�����������Ϣ�洢�����ݿ��С�
-
RESTful API:API ���,����Ҫ�����ṩ�ⲿ���ʽӿڡ�������ͻ���չʾ������Ϣ,�������ϵͳ������ʵ�ּ�صȡ�
-
Web UI:UI ���,���� API ���ʵ�ֵ��ϲ�Ӧ�á�ͨ�� UI ����û����Է������ֱ�۵ز�ѯ�ͷ���������Ϣ��
Zipkin ��Ϊ����,һ���� Zipkin �����,һ���� Zipkin �ͻ���,�ͻ���Ҳ���������Ӧ�á��ͻ��˻����÷���˵� URL ��ַ,һ�����������ĵ��õ�ʱ��,�ᱻ��������������� Sleuth �ļ���������,��������Ӧ�� Trace �� Span ��Ϣ��������ˡ�
6.3.2 ZipKin����˰�װ
��1��: ����ZipKin��jar��
https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
�����������ַ,���ɵõ�һ��jar��,�����ZipKin����˵�jar��
��2��: ͨ��������,�����������������ZipKin Server
java -jar zipkin-server-2.12.9-exec.jar
��3��:ͨ����������� http://localhost:9411����
6.3.3 Zipkin�ͻ��˼���
ZipKin�ͻ��˺�Sleuth�ļ��ɷdz���,ֻ��Ҫ�����������������������ü��ɡ�
��1��:��ÿ����������������
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
��2��:��������
spring:
zipkin:
base-url: http://127.0.0.1:9411
discovery-client-enabled: false # ��Ҫ��nacos��zipkinע���ȥ
sleuth:
sampler:
probability: 1.0
��3��: ��������
http://localhost:7000/order-serv/order/prod/1
��4��: ����zipkin��UI����,�۲�Ч��
��5��:�������һ����¼,�ɹ۲�һ�η��ʵ���ϸ��·
6.4 ZipKin���ݳ־û�
Zipkin ServerĬ�ϻὫ��������Ϣ���浽�ڴ�,�����ַ�ʽ���ʺ�����������Zipkin֧�ֽ������ݳ־û���mysql���ݿ��elasticsearch�С�
6.4.1 ʹ��mysqlʵ�����ݳ־û�
��1��: ����mysql���ݻ���
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query' )
ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null' )
ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT )
ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
��2��: ������ZipKin Server��ʱ��,ָ�����ݱ����mysql����Ϣ
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --
MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root -
-MYSQL_PASS=root
������Nacos Config�C��������
7.1 �����������Ľ���
������������һ��,����ܹ��¹��������ļ���һЩ����:
1. �����ļ���Է�ɢ����һ������ܹ���,�����ļ������������������Խ��Խ��,���ҷ�ɢ�ڸ���������,����ͳһ���ú�����
2. �����ļ������ֻ����C�������� ���Ի��� ���ϻ�����������Ŀ���ܻ��ж������,����:���Ի�����Ԥ����������������
����ÿһ��������ʹ�õ����������϶��Dz�ͬ��,һ����Ҫ��,����Ҫ����ȥ�����������ֶ�
ά��,��Ƚ����ѡ�
3. �����ļ���ʵʱ���¡��������������ļ�֮��,�������������������ʹ������Ч,���һ���������е���Ŀ��˵�Ƿdz����Ѻõġ�
����������Щ����,���Ǿ���Ҫ���������ļ����������Щ���⡣
�������ĵ�˼·��:
-
���Ȱ���Ŀ�и�������ȫ�����ŵ�һ�����еĵط�����ͳһ����,���ṩһ�ױ��Ľӿڡ�
-
������������Ҫ��ȡ���õ�ʱ��,�����������ĵĽӿ���ȡ�Լ������á�
-
�����������еĸ��ֲ����и��µ�ʱ��,Ҳ��֪ͨ����������ʵʱ�Ĺ���ͬ�����µ���Ϣ,ʹ֮��̬���¡�
�������˷�����������֮��,���ǵ�ϵͳ�ܹ�ͼ������������:
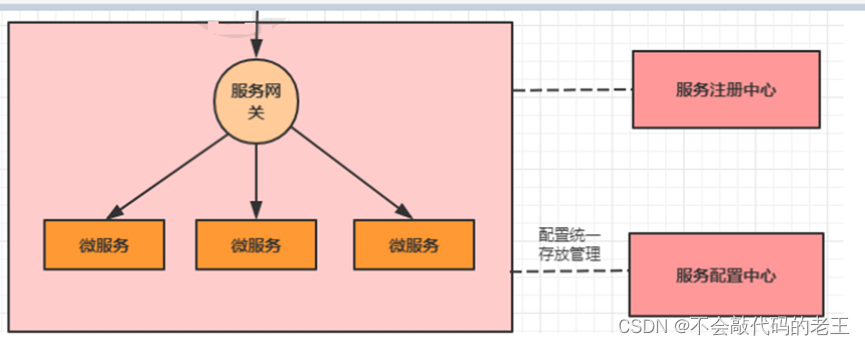
��ҵ�糣���ķ�����������,��������Щ:
- Apollo------>�ܶ�ʹ��apollo
Apollo����Я�̿�Դ�ķֲ�ʽ�������ġ��ص��кܶ�,����:���ø���֮�����ʵʱ��Ч,֧�ֻҶȷ�������,�����ܶ����е����ý��а汾������������Ƶȹ���,�ṩ����ƽ̨API���������� Ҳд�ĺ���ϸ��
- Disconf
Disconf���ɰٶȿ�Դ�ķֲ�ʽ�������ġ����ǻ���Zookeeper��ʵ�����ñ����ʵʱ֪ͨ����Ч�ġ�
- SpringCloud Config
����Spring Cloud�д��������������������Spring���켯��,ʹ�������dz�����,�����������ô洢֧��Git<gitûѧ>��������û�п��ӻ��IJ�������,���õ���ЧҲ����ʵʱ��,��Ҫ������ȥˢ�¡�
- Nacos
����SpingCloud alibaba����ջ�е�һ�����,ǰ�������Ѿ�ʹ������������ע�����ġ���ʵ��Ҳ�����˷������õĹ���,���ǿ���ֱ��ʹ������Ϊ�����������ġ�
7.2 Nacos Config����
ʹ��nacos��Ϊ��������,��ʵ���ǽ�nacos����һ�������,�����������ǿͻ���,���ǽ���������������ļ�ͳһ�����nacos��,Ȼ����������nacos����ȡ���ü��ɡ�
��������������Ʒ����Ϊ��,ѧϰnacos config��ʹ�á�
1 �nacos������ʹ�����е�nacos�������ɡ�
2 ������������nacos������
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
3 ������������nacos confifig������
ע��:����ʹ��ԭ����application.yml��Ϊ�����ļ�,�����½�һ��bootstrap.yml��Ϊ�����ļ�
�����ļ����ȼ�(�ɸߵ���):
bootstrap.properties -> bootstrap.yml -> application.properties -> application.yml
spring:
application:
name: service-product
cloud:
nacos:
config:
server-addr: 127.0.0.1:8848 #nacos���ĵ�ַ
file-extension: yaml # �����ļ���ʽ
profiles:
active: dev # ������ʶ
4 ��nacos����������
��������б�,����ұ�+��,�½����á����½����ù�����,Ҫע�������ϸ��:
1)Data ID�������д,Ҫ�������ļ��еĶ�Ӧ,��Ӧ��ϵ��ͼ��ʾ
2)�����ļ���ʽҪ�������ļ��ĸ�ʽ��Ӧ,��Ŀǰ����֧��YAML��Properties
3)�������ݰ�������ѡ���ĸ�ʽ��д
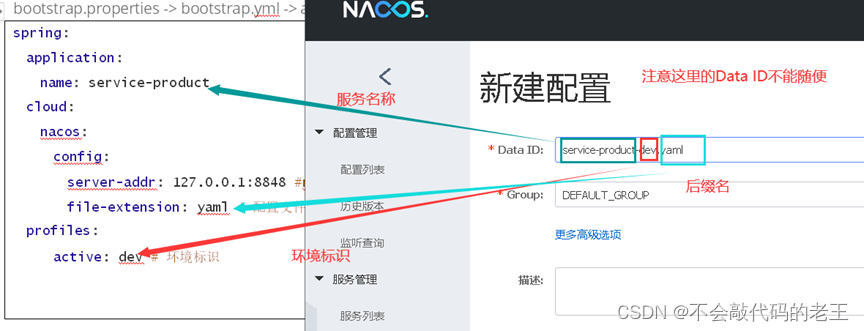
5 ע�ͱ��ص�application.yam�е�����, ����������в���
������ɿ��Գɹ����ʳ���,˵������nacos���������Ĺ����Ѿ�ʵ��
7.3 Nacos Confifig����
7.3.1 ���ö�̬ˢ��
�����Ű�����,����ʵ�������õ�Զ�̴��,���Ǵ�ʱ�����������,���ǵij���������ȡ����,���,������Ҫ�������õĶ�̬ˢ�¹��ܡ�
��nacos�е�service-product-dev.yaml��������������������:
config:
appName: product222
��ʽһ: Ӳ���뷽ʽ
@RestController
public class NacosConfigController {
@Autowired
private ConfigurableApplicationContext applicationContext;
@GetMapping("/nacos-config-test1")
public String nacosConfingTest1() {
return
applicationContext.getEnvironment().getProperty("config.appName");
}
}
��ʽ��: ע�ⷽʽ(�Ƽ�)
@RestController
@RefreshScope//ֻ��Ҫ����Ҫ��̬��ȡ���õ��������Ӵ�ע��Ϳ���
public class NacosConfigController {
@Value("${config.appName}")
private String appName;
//2 ע�ⷽʽ
@GetMapping("/nacos-config-test2")
public String nacosConfingTest2() {
return appName;
}
}
7.3.2���ù���
������Խ��Խ���ʱ��,���Ǿͷ����кܶ��������ظ���,��ʱ��Ϳ��ǿɲ����Խ����������ļ���ȡ����,Ȼ��ʵ�ֹ�����?��Ȼ�ǿ��Եġ����������Ǿ���̽�����ʵ����һ���ܡ�
ͬһ������IJ�ͬ����֮�乲������
�������ͬһ������IJ�ͬ����֮��ʵ�����ù���,��ʵ�ܼ�
ֻ��Ҫ��ȡһ���� spring.application.name �����������ļ�,Ȼ�������л����Ĺ������÷������漴�ɡ�
1 �½�һ����Ϊservice-product.yaml���ô����Ʒ����Ĺ�������
2 �½�һ����Ϊservice-product-dev.yaml���ô�Ų��Ի���������
3.�½�һ����Ϊservice-product-test.yaml���ô�Ų��Ի���������
4 ���Ӳ��Է���
@RestController
@RefreshScope
public class NacosConfigController {
@Value("${config.env}")
private String env;
//3 ͬһ����IJ�ͬ�����¹�������
@GetMapping("/nacos-config-test3")
public String nacosConfingTest3() {
return env;
}
}
5 ���ʲ���
6 ������,��bootstrap.yml�е�����,��active���ó�test,�ٴη���,�۲���
spring:
profiles:
active: test # ������ʶ
��ͬ�����м乲������
��ͬΪ����֮��ʵ�����ù�����ԭ���������ļ�����,���Ƕ���һ����������,Ȼ���ڵ�ǰ��������
�롣
1 ��nacos�ж���һ��DataIDΪall-service.yaml������,��������������
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql:///shop?
serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
username: root
password: root
jpa:
properties:
hibernate:
hbm2ddl:
auto: update
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
2 ��nacos������service-product.yaml����������
server:
port: 8081
config:
appName: product
3 ��bootstrap.yaml
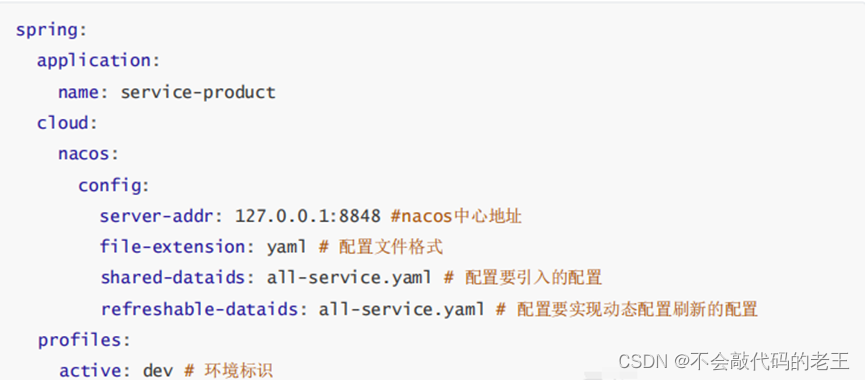
4 ������Ʒ������в���
7.4 nacos�ļ�������
�����ռ�(Namespace) (dev�������� test���Ի��� online���ϻ���)
�����ռ�����ڽ��в�ͬ���������ø��롣һ��һ���������ֵ�һ�������ռ�
���÷���(Group) (���ֵ���Ŀ)
���÷������ڽ���ͬ�ķ�����Թ��ൽͬһ���顣һ�㽫һ����Ŀ�����÷ֵ�һ��
���ü�(Data ID)
��ϵͳ��,һ�������ļ�ͨ������һ�����ü���һ����������þ���һ�����ü�
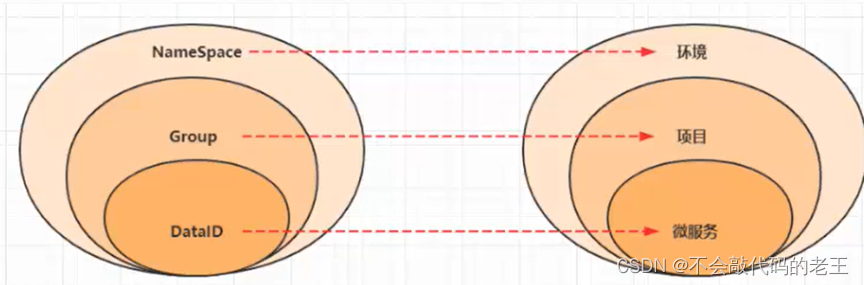
�ڰ��·ֲ�ʽ�������alibaba��� seata
��������: ��һЩ�ж������,��Щ����Ҫô�ɹ� Ҫôʧ�ܡ�
1.�ֲ�ʽ���������

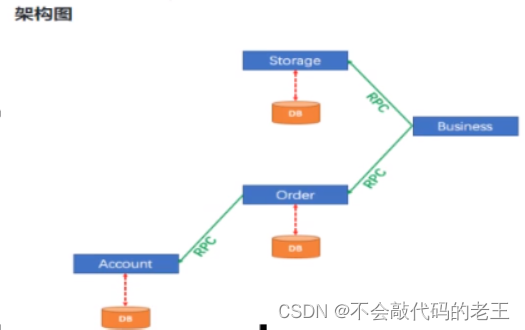
2.Seata�ֲ�ʽ����ļ��
2.1 ��ʲô?
Seata��һ�Դ�ķֲ�ʽ����������,������������ܹ����ṩ�����ܺͼ����õķֲ�ʽ�������
������ַ: http://seata.io/zh-cn/
2.2 �ܸ�ʲô?
1. һ�����͵ķֲ�ʽ�������
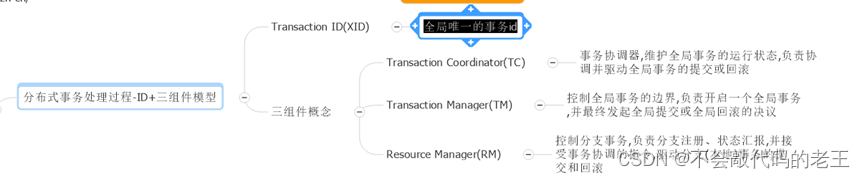
2.��������!
Seata��ִ����������:
1. A�����TM[�ӳ�:]��TC[seata]���뿪��һ��ȫ������,TC�ͻᴴ��һ��ȫ��������һ��Ψһ��XID
2. A�����RM[�������ݿ�]��TCע���֧����,����������XID��Ӧȫ������Ĺ�Ͻ
3. A��������ִ�з�֧,�����ݿ�������
4. A����ʼԶ�̵���B����,��ʱXID��������ĵ������ϴ���
5. B�����RM��TCע���֧����,����������XID��Ӧ��ȫ������Ĺ�Ͻ
6. B����ִ�з�֧����,�����ݿ�������
7. ȫ������������������,TM���������쳣��TC����ȫ��������ύ���ع�
8. TCЭ�����Ͻ֮�µ����з�֧����, �����Ƿ�ع�
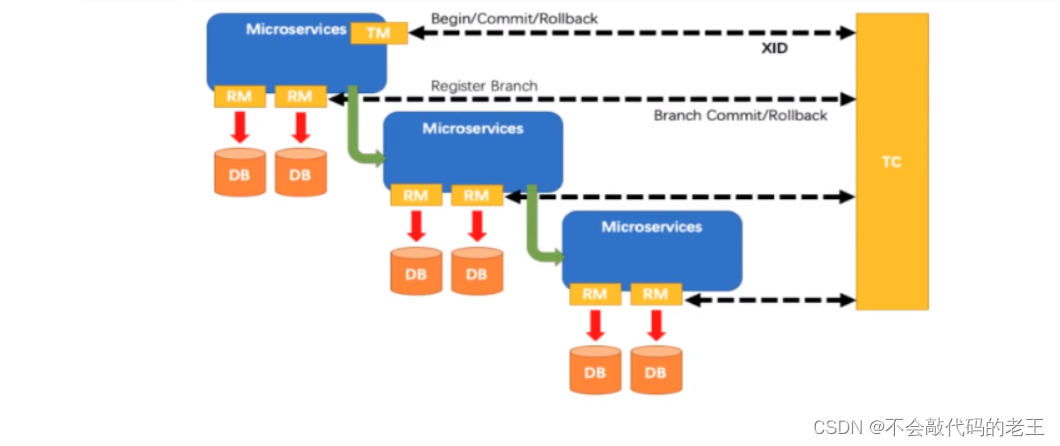
2.3 ȥ������
https://github.com/seata/seata/releases
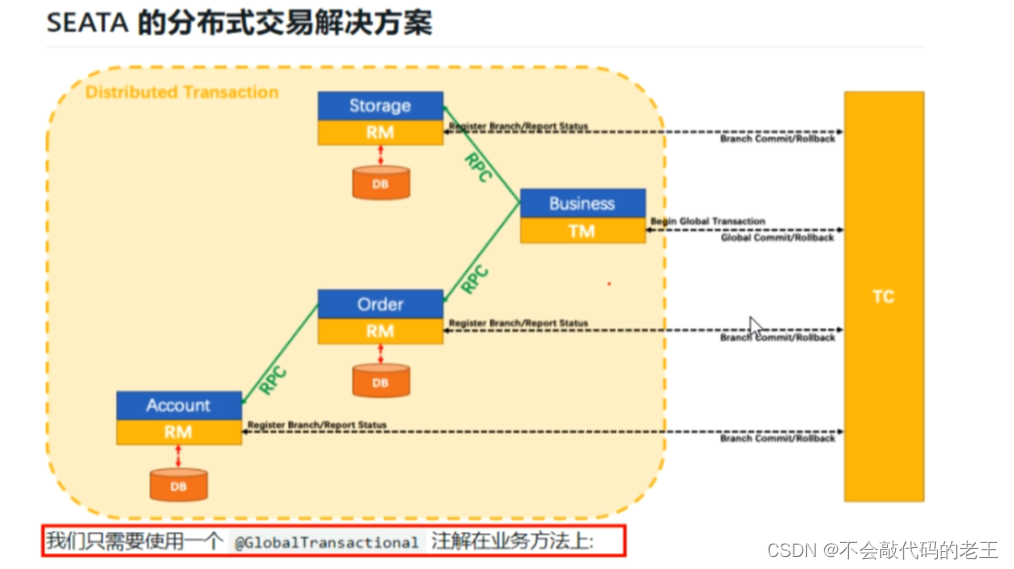
3.Seata-Server��װ
1��seata-server-0.9.0.zip��ѹ��ָ��Ŀ¼����confĿ¼�µ�file.conf�����ļ�
(1)�ȱ���ԭʼfile.conf�ļ�
(2)��Ҫ��:�Զ�������������+������־�洢ģʽΪdb+���ݿ�����
(3)

(4) mysql5.7���ݿ��½���seata,����db_store.sql��seata-server-0.9.0\seata\confĿ¼���档
�C the table to store GlobalSession data
drop table if existsglobal_table;
create tableglobal_table(
xidvarchar(128) not null,
transaction_idbigint,
statustinyint not null,
application_idvarchar(32),
transaction_service_groupvarchar(32),
transaction_namevarchar(128),
timeoutint,
begin_timebigint,
application_datavarchar(2000),
gmt_createdatetime,
gmt_modifieddatetime,
primary key (xid),
keyidx_gmt_modified_status(gmt_modified,status),
keyidx_transaction_id(transaction_id)
);
�C the table to store BranchSession data
drop table if exists branch_table;
create table branch_table (
branch_id bigint not null,
xid varchar(128) not null,
transaction_id bigint ,
resource_group_id varchar(32),
resource_id varchar(256) ,
lock_key varchar(128) ,
branch_type varchar(8) ,
status tinyint,
client_id varchar(64),
application_data varchar(2000),
gmt_create datetime,
gmt_modified datetime,
primary key (branch_id),
key idx_xid (xid)
);
�C the table to store lock data
drop table if exists lock_table;
create table lock_table (
row_key varchar(128) not null,
xid varchar(96),
transaction_id long ,
branch_id long,
resource_id varchar(256) ,
table_name varchar(32) ,
pk varchar(36) ,
gmt_create datetime ,
gmt_modified datetime,
primary key(row_key)
);
- ��seata-server-0.9.0\seata\confĿ¼�µ�registry.confĿ¼�µ�registry.conf�����ļ�

7.������Nacos�˿ں�8848
8.������seata-server
4.����/���/�˻�ҵ�����ݿ���
1. �ֲ�ʽ����ҵ��˵��

2.�������ݿ�
3.��������3��ֱ�����Ӧҵ���

4.��������3��ֱ�����Ӧ�Ļع���־��(ǰ�ÿ��պͺ��ÿ���)

CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
4.������
����/���/�˻�ҵ��������
1.ҵ������

- �½�����Order-Module,Account-Module,Storage_Module.

Pom:
<dependencies>
<!-- nacos -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- nacos -->
<!-- seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
<version>0.9.0</version>
</dependency>
<!-- seata-->
<!--feign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--jdbc-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>
����
- �¶���->�����->�����->��(����)״̬
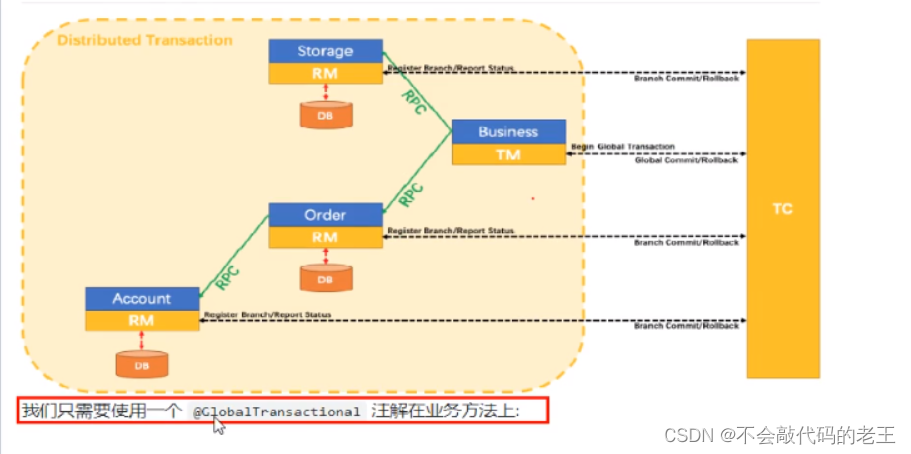
2.���ݿ��ʼ���
1.�����µ�
2.��ʱ�쳣,û��@GlobalTransactional

- ��ʱ�쳣,����@GlobalTransactional


