һ.Java����
1.java������ʲô�ص�
-
�������(��װ,�̳�,��̬);
-
ƽ̨����,ƽ̨���Եľ����������,Java �ǡ�һ�α�д,��������(Write Once,Run any Where)��������,��˲��� Java ���Ա�д�ij�����кܺõĿ���ֲ��,����֤��һ������� Java ������������������������֮��,Java �����ڲ�ͬ��ƽ̨�����в���Ҫ���±��롣
-
�ɿ��ԡ���ȫ��;
-
֧�ֶ��̡߳�C++ ����û�����õĶ��̻߳���,��˱�����ò���ϵͳ�Ķ��̹߳��������ж��̳߳������,�� Java ����ȴ�ṩ�˶��߳�֧��;
-
֧�������̲��Һܷ��㡣Java ���Ե�����������Ϊ����������Ƶ�,��� Java ���Բ���֧�������̶��Һܷ���;
-
��������Ͳ���;
2.Java��C++��ʲô��ϵ,������ʲô����?
-
����������������,��֧�ַ�װ���̳кͶ�̬;
-
֧��ָ��,�� Java û��ָ��ĸ���;
-
C++ ֧�ֶ�̳�,�� Java ��֧�ֶ��ؼ̳�,������һ����ʵ�ֶ���ӿ�;
-
Java �Զ����������ڴ���ղ���,������Ҫ����Ա�����ֶ�ɾ��,�� C++ �б����ɳ����ͷ��ڴ���Դ,��������˳���Ա�ĸ�����
-
Java ��֧�ֲ���������,��������������Ϊ�� C++ ��ͻ������;
-
Java ����ȫ������������,���һ�ȡ���� C/C++ �еĽṹ������,ʹ���������Ӽ��;
-
C �� C++ ��֧���ַ�������,�� C �� C++ ������ʹ�á�Null����ֹ�������ַ����Ľ������� Java ���ַ������������(String �� StringBuffer)��ʵ�ֵ�;
-
goto ����� C �� C++ �ġ����,Java ���ṩ goto ���,��Ȼ Java ָ�� goto ��Ϊ�ؼ���,����֧
������ʹ��,��ʹ����������;
3. JVM��JRE��JDK�Ĺ�ϵ��ʲô?
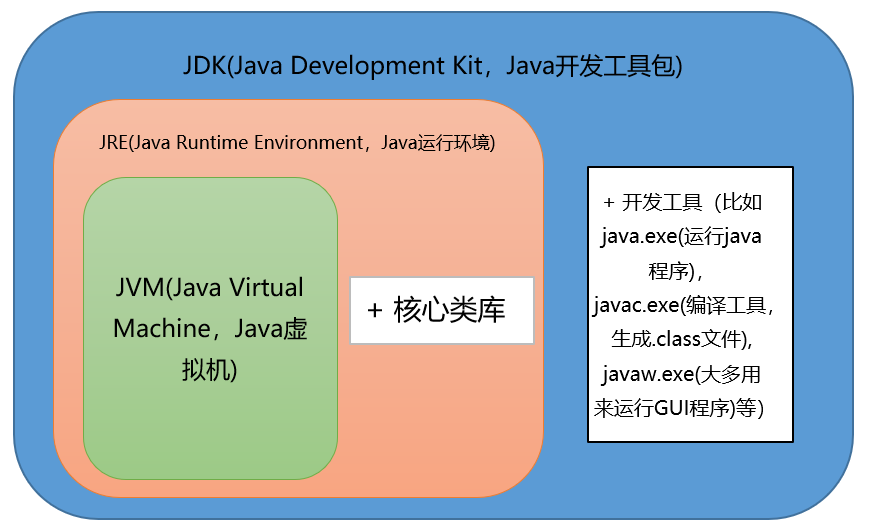
4. ʲô���ֽ���?�����ֽ���ĺô���ʲô?
-
Java֮���Կ��ԡ�һ�α���,����������,һ����ΪJVM��Ը��ֲ���ϵͳ��ƽ̨�������˶���,������Ϊ������ʲôƽ̨,�����Ա������ɹ̶���ʽ���ֽ���(.class�ļ�)��JVMʹ�������,Ҳ���Կ����ֽ������Java��̬����Ҫ�ԡ�
֮���Ա���֮Ϊ�ֽ���,����Ϊ�ֽ����ļ���ʮ������ֵ���,��JVM������ʮ������ֵΪһ��,�����ֽ�Ϊ��λ���ж�ȡ����Java��һ������javac�������Դ����Ϊ�ֽ����ļ���
-
Java����ͨ���ֽ���ķ�ʽ,��һ���̶�������˴�ͳ����������ִ��Ч�ʵ͵�����,ͬʱ�ֱ����˽��������Կ���ֲ���ص㡣����Java��������ʱ�Ƚϸ�Ч,����,�����ֽ��벢��ר��һ���ض��Ļ���,���,Java�����������±������ڶ��ֲ�ͬ�ļ���������С�
5.Oracle JDK �� OpenJDK ��������ʲô?
-
Oracle JDK �汾��ÿ���귢��һ��,�� OpenJDK �汾ÿ�����·���һ��;
-
OpenJDK ��һ���ο�ģ�Ͳ�������ȫ��Դ��,�� Oracle JDK ��OpenJDK ��һ��ʵ��,��������ȫ��Դ��;
-
Oracle JDK �� OpenJDK ���ȶ���OpenJDK �� Oracle JDK �Ĵ��뼸����ͬ,�� Oracle JDK �и�������һЩ�����������,������뿪����ҵ/��ҵ����,����ѡ�� Oracle JDK,��Ϊ�������˳��IJ��Ժ��ȶ���ijЩ�����,��Щ���ᵽ��ʹ�� OpenJDK ���ܻ�����������Ӧ�ó������������,����,ֻ���л��� Oracle JDK �Ϳ��Խ������;
-
����Ӧ�Ժ� JVM ���ܷ���,Oracle JDK �� OpenJDK ����ṩ�˸��õ�����;
-
Oracle JDK ����Ϊ���������İ汾�ṩ����֧��,�û�ÿ�ζ�����ͨ�����µ����°汾���֧������ȡ���°汾;
-
Oracle JDK ���ݶ����ƴ�������Э��������,�� OpenJDK ���� GPLv2 ���ɻ������
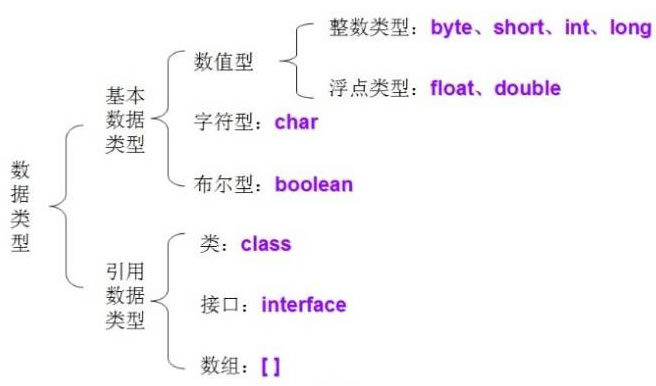
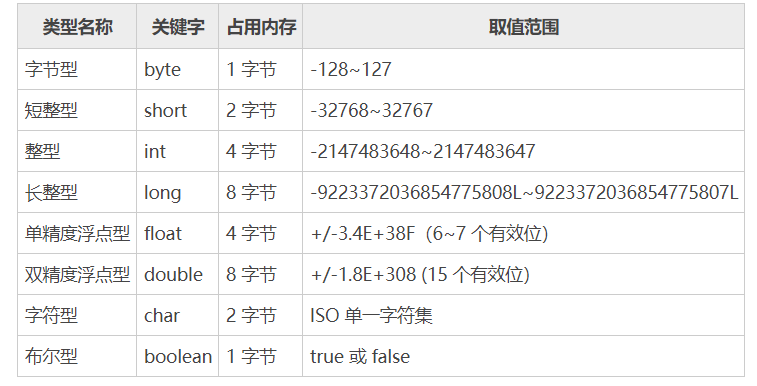
6. Java������������?
- Java ���Ե��������ͷ�Ϊ����:�����������ͺ������������͡�
7. switch �Ƿ��������� byte ��,�Ƿ��������� long��,�Ƿ��������� String ��?
-
Java5 ��ǰ switch(expr)��,expr ֻ���� byte��short��char��int��
�� Java 5 ��ʼ,Java ��������ö������, expr Ҳ������ enum ���͡�
�� Java 7 ��ʼ,expr���������ַ���(String),���dz�����(long)��Ŀǰ���еİ汾�ж��Dz����Եġ�
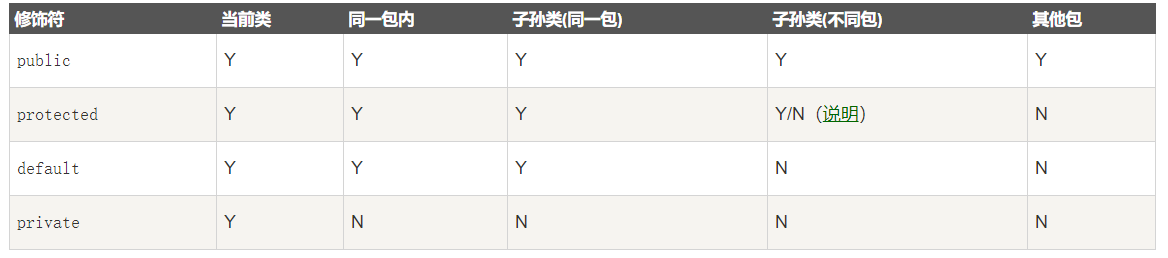
8. �������η�public��private��protected���Լ���д(Ĭ��)ʱ������?
-
default (��Ĭ��,ʲôҲ��д): ��ͬһ���ڿɼ�,��ʹ���κ����η���ʹ�ö���:�ࡢ�ӿڡ�������������
-
private : ��ͬһ���ڿɼ���ʹ�ö���:������������ע��:����������(�ⲿ��)
-
public : ��������ɼ���ʹ�ö���:�ࡢ�ӿڡ�����������
-
protected : ��ͬһ���ڵ������������ɼ���ʹ�ö���:������������ע��:����������(��
����)��
9. break ,continue ,return ����������?
-
break ��������һ��ѭ��,����ִ��ѭ��(������ǰ��ѭ����)
-
continue ��������ѭ��,����ִ���´�ѭ��(��������ִ�е�ѭ�� ������һ��ѭ������)
-
return ����,����ִ������Ĵ���(������ǰ�ķ��� ֱ�ӷ���)
10. final��finally��finalize������?
-
final �������α������������ࡣ
- final ����:�����εı������ɱ�,���ɱ��Ϊ ���ò��ɱ� �� ���ɱ� ,final ָ�������ò��ɱ� ,final ���εı��������ʼ��,ͨ���Ʊ����εı���Ϊ ���� ��
- final ����:�����εķ����������κ�������д,�������ʹ�ø÷�����
- final ��:�����ε���ܱ��̳�,���з������ܱ���д��
-
finally ��Ϊ�쳣������һ����,��ֻ���� try/catch �����,���Ҹ���һ�������ʾ����������һ����ִ��(�����Ƿ��׳��쳣),������������Ҫ�ͷ���Դ�������, System.exit (0) �������finally ִ�С�
-
finalize ���� java.lang.Object �ﶨ��ķ���,Ҳ����˵ÿһ����������ô������,���������gc ����,�������յ�ʱ���á�
һ������� finalize ����ֻ�ᱻ����һ��,finalize �����ò�һ�����������ոö���,�����п��ܵ���finalize ��,�ö����ֲ���Ҫ��������,Ȼ��������Ҫ�����յ�ʱ��,��Ϊǰ����ù�һ��,���Բ����ٴε��� finalize ��,������������,��˲��Ƽ�ʹ�� finalize ������
11. ΪʲôҪ��static�ؼ���?
- ͨ����˵,��new������Ķ���ʱ,���ݴ洢�ռ�ű�����,�����Ź�������������ʱ����ֻ��Ϊ�ض�����䵥һ�洢�ռ�,������Ҫ�������ٶ������˵�����Ͳ������κζ���,�پ�����������û�д�������������Ҳ����÷������������������,static�ؼ���,���������ǵ�����
12. ��static���ؼ�����ʲô��˼?Java���Ƿ���Ը���(override)һ��private������static�ķ���?
- ��static���ؼ��ֱ���һ����Ա���������dz�Ա����������û�����������ʵ������������±����ʡ�Java��static�������ܱ�����,��Ϊ���������ǻ�������ʱ��̬��,��static�����DZ���ʱ��̬����static����������κ�ʵ���������,���Ը����ϲ����á�
13. �Ƿ������static�����з��ʷ�static����?
- static������Java�����������,�������е�ʵ���е�ֵ��һ���ġ����౻Java����������ʱ��,���static�������г�ʼ���������Ĵ��볢�Բ���ʵ�������ʷ�static�ı���,�������ᱨ��,��Ϊ��Щ������û�б���������,��û�и��κ�ʵ����������
14. static��̬�����ܲ������÷Ǿ�̬��Դ?
- ����,new��ʱ��Ż�����Ķ���,������ʼ����ʹ��ڵľ�̬��Դ��˵,��������ʶ����
15. static��̬���������ܲ������þ�̬��Դ?
- ����,��Ϊ�������ʼ����ʱ����ص�,��������ʶ
16. �Ǿ�̬���������ܲ������þ�̬��Դ?
- ����,�Ǿ�̬��������ʵ������,����new֮��Ų�����,��ô�����������������ʶ��
17. java��̬����������顢�;�̬������ִ��˳����ʲô?
-
�����ϴ�����Ϊ����:Static��̬����顢�������顢��ͨ�����
-
�����ִ��˳��̬����顪��> �������� ����>���캯������> ��ͨ�����
-
�̳��д����ִ��˳��:���ྲ̬�顪��>���ྲ̬�顪��>�������顪��>�����������>�������顪��>�������
��������ڹ�����,������������
18. ��������������̵�����?
-
�������:
�ŵ�:���ܱ���������,��Ϊ�����ʱ��Ҫʵ����,�����Ƚϴ�,�Ƚ�������Դ;���絥Ƭ����Ƕ��ʽ������Linux/Unix��һ�����������̿���,����������Ҫ�����ء�
ȱ��:û�����������ά�������á�����չ�� -
�������:
�ŵ�:��ά�������á�����չ,���������������װ���̳С���̬�Ե�����,������Ƴ��������ϵͳ,ʹϵͳ��������������ά����
ȱ��:���ܱ�������̵�
19. �������������������
-
��װ����װ��������ˡ���װ��������������֮һ,�Ƕ������������Ҫ���ԡ���װ,Ҳ���ǰѿ������װ�ɳ������,������������Լ������ݺͷ���ֻ�ÿ��ŵ�����߶������,�Բ����ŵĽ�����Ϣ���ء�
-
�̳С��̳���ָ����һ������:������ʹ������������й���,�����������±�дԭ�����������¶���Щ���ܽ�����չ��ͨ���̳д����������Ϊ�����ࡱ�������ࡱ,���̳е����Ϊ�����ࡱ�������ࡱ���ࡱ��
-
��̬�ԡ�����ָ�ڸ����ж�������Ժͷ���������̳�֮��,���Ծ��в�ͬ���������ͻ���ֳ���ͬ����Ϊ,��ʹ��ͬһ�����Ի��ڸ��༰����������о��в�ͬ�ĺ�����
20. Java���������ʵ�ֶ�̬��?
-
�����϶�̬������:
1������ʱ��̬(�ֳƾ�̬��̬)
2������ʱ��̬(�ֳƶ�̬��̬)
-
����(overload)��������ʱ��̬��һ������,����ʱ��̬�ڱ���ʱ���Ѿ�ȷ��,���е�ʱ����õ���ȷ���ķ�����
-
����ͨ����˵�Ķ�ָ̬�Ķ�������ʱ��̬,Ҳ���DZ���ʱ��ȷ�����������ĸ����巽��,һֱ�ӳٵ�����ʱ����ȷ������Ҳ��Ϊʲô��ʱ���̬�����ֱ���Ϊ�ӳٷ�����ԭ��
-
Javaʵ�ֶ�̬�� 3 ����Ҫ����:�̳С���д������ת����ֻ�������� 3 ������,������Ա���ܹ���ͬһ���̳нṹ��ʹ��ͳһ����ʵ�ִ��봦����ͬ�Ķ���,�Ӷ�ִ�в�ͬ����Ϊ��
-
�̳�:�ڶ�̬�б�������м̳й�ϵ��������ࡣ
-
��д:����Ը�����ijЩ�����������¶���,�ڵ�����Щ����ʱ�ͻ��������ķ�����
-
����ת��:�ڶ�̬����Ҫ����������ø����������,ֻ�����������òż��ܿ��Ե��ø���ķ���,���ܵ�������ķ�����
21. ����(Overload)����д(Override)��������ʲô?
- ���������غ���д����ʵ�ֶ�̬�ķ�ʽ,��������ǰ��ʵ�ֵ��DZ���ʱ�Ķ�̬��,������ʵ�ֵ�������
ʱ�Ķ�̬�ԡ�
- ��д�����������븸��֮��, ��д��������ֵ���βζ����ܸı�,�뷽������ֵ�ͷ������η���
��,�����صķ������ܸ��ݷ������ͽ������֡�����Dz���,������д!
- ����(overloading) ����һ��������,����������ͬ,��������ͬ���������Ϳ�����ͬҲ���Բ�
ͬ��ÿ�����صķ���(���߹��캯��)��������һ����һ���IJ��������б���õĵط�����
�����������ء�

22. ���صķ����ܷ���ݷ���ֵ���ͽ�������?
- ���ܸ��ݷ���ֵ�������������صķ�������Ϊ����ʱ��ָ��������Ϣ,��������֪����Ҫ�����ĸ�������
23. ������(constructor)�Ƿ�ɱ���д(override)?
- ���������ܱ��̳�,��˲��ܱ���д,�����Ա�������ÿһ����������Լ��Ĺ��캯��,�������Լ��ⲿ�ֵĹ��졣����Ḳ�Ǹ���Ĺ��캯��,�෴����һ��ʼ���ø���Ĺ��캯����
24. ������ͽӿڵ�������ʲô?
- ������ϵ�����:
����������ṩ��Ա������ʵ��ϸ��,���ӿ���ֻ�ܴ���public abstract ����;
�������еij�Ա���������Ǹ������͵�,���ӿ��еij�Ա����ֻ����public static final���͵Ľӿ��в��ܺ��о�̬������Լ���̬����������������о�̬�����;�̬����;
һ����ֻ�ܼ̳�һ��������,��һ����ȴ����ʵ�ֶ���ӿڡ�
- ��Ʋ����ϵ�����:
�������Ƕ�һ������ij���,���������,���ӿ��Ƕ���Ϊ�ij��������Ƕ�������������г�
��,�������ԡ���Ϊ,���ǽӿ�ȴ�Ƕ���ֲ�(��Ϊ)���г���
��Ʋ��治ͬ,��������Ϊ�ܶ�����ĸ���,����һ��ģ��ʽ��ơ����ӿ���һ����Ϊ�淶,����
һ�ַ���ʽ��ơ�
25. ��������ʹ�� final ������?
- ����,��������������������̳е�,�������Ϊ final ����Ͳ��ܱ��̳�,�����˴˾ͻ����ì��,
���� final �����������
26. java �����������ļ��ַ�ʽ?
-
java���ṩ���������ִ�������ķ�ʽ:
? new�����¶���
? ͨ���������
? ����clone����
? ͨ�����л�����
ǰ���߶���Ҫ��ʽ�ص��ù��췽��������clone����,��Ҫע��dz���������������,�������л�����
��Ҫ��ȷ��ʵ��ԭ��,��java�����л�����ͨ��ʵ��Externalizable����Serializable��ʵ�֡�
27.ʲô�Dz��ɱ����?�ô���ʲô?
- ���ɱ����ָ����һ��������,״̬�Ͳ����ٸı�,�κ��Ķ��ᴴ��һ���µĶ���,�� String��Integer��������װ��.���ɱ�������ĺô����̰߳�ȫ
28. �ܷ�һ�������ɱ����IJ��ɱ����?
- ��Ȼ����,���� final Person[] persons = new Persion[]{} . persons �Dz��ɱ���������,������
���е�Personʵ��ȴ�ǿɱ��.�����������Ҫ�ر����,��Ҫ�����ɱ���������.���������,���������Ҫ�仯ʱ,�ͷ���ԭ�����һ������.
29. ֵ���ݺ����ô��ݵ������ʲô?Ϊʲô˵Java��ֻ��ֵ����?
-
ֵ����:ָ�����ڷ�������ʱ,���ݵIJ����ǰ�ֵ�Ŀ�������,���ݵ���ֵ�Ŀ���,Ҳ����˵���ݺ�ͻ�������ˡ�
-
���ô���:ָ�����ڷ�������ʱ,���ݵIJ����ǰ����ý��д���,��ʵ���ݵ������õĵ�ַ,Ҳ���DZ�������Ӧ���ڴ�ռ�ĵ�ַ�����ݵ���ֵ������,Ҳ����˵����ǰ�ʹ��ݺ�ָ��ͬһ������(Ҳ����ͬһ���ڴ�ռ�)��
-
����������Ϊ����������ʱ�϶���ֵ����;����������Ϊ����������ʱҲ��ֵ����,ֻ������ֵ��Ϊ��Ӧ�����á�
30. == �� equals ������ʲô?
-
== ��������ͬ�Ļ�����������֮��ıȽ�,Ҳ��������ͬ���͵Ķ���֮��ıȽ�;
? ��� == �Ƚϵ��ǻ�����������,��ô�Ƚϵ������������������͵�ֵ�Ƿ����;
? ��� == �DZȽϵ���������,��ô�Ƚϵ����������������,Ҳ�����������������Ƿ�ָ����ͬһ���ڴ�����;
equals������Ҫ������������֮��,���һ�������Ƿ������һ������
- ��������Ҳ���ж����������Ƿ����,��������ʹ�����:
? ���1,��û�и���equals()��������ͨ��equals()�Ƚϸ������������ʱ,�ȼ���ͨ����==���Ƚ���
��������
? ���2,�า����equals()������һ��,���Ƕ�����equals()����������������������;�����ǵ�
�������,��true(��,���������������)��
- java���Թ淶Ҫ��equals����������������:
�Է����������ⲻΪnull������ֵx,x.equals(x)һ����true��
�Գ����������ⲻΪnull������ֵx��y,���ҽ���x.equals(y)��trueʱ,y.equals(x)Ҳ��true��
�������������ⲻΪnull������ֵx��y��z,���x.equals(y)��true,ͬʱy.equals(z)��true,��
ôx.equals(z)һ����true��
һ�����������ⲻΪnull������ֵx��y,�������equals�ȽϵĶ�����Ϣû�б��ĵĻ�,���
����ʱx.equals(y)Ҫôһ�µط���trueҪôһ�µط���false���������ⲻΪnull������ֵx,x.equals(null)����false��
31. ������hashCode()?
-
hashCode() �������ǻ�ȡ��ϣ��,Ҳ��Ϊɢ����;��ʵ�����Ƿ���һ��int�����������ϣ���������
ȷ���ö����ڹ�ϣ���е�����λ����hashCode() ������JDK��Object.java��,�����ζ��Java�е��κ��������hashCode()������
ɢ�б��洢���Ǽ�ֵ��(key-value),�����ص���:�ܸ��ݡ��������ٵļ�������Ӧ�ġ�ֵ���������о����õ���ɢ����!(���Կ����ҵ�����Ҫ�Ķ���)
32. ΪʲôҪ�� hashCode?
-
�ԡ�HashSet��μ���ظ���Ϊ������˵��ΪʲôҪ�� hashCode:
����Ѷ������ HashSet ʱ,HashSet ���ȼ������� hashcode ֵ���ж϶�������λ��,ͬʱҲ���������Ѿ�����Ķ���� hashcode ֵ���Ƚ�,���û�������hashcode,HashSet��������û���ظ����֡����������������ͬ hashcode ֵ�Ķ���,��ʱ����� equals()��������� hashcode ��ȵĶ����Ƿ������ͬ�����������ͬ,HashSet �Ͳ��������������ɹ��������ͬ�Ļ�,�ͻ�����ɢ�е�����λ�á��������Ǿ��������� equals �Ĵ���,��Ӧ�ʹ�������ִ���ٶȡ�
33. hashCode(),equals()���ַ�����ʲô��ϵ?
-
Java ���� eqauls() ������ hashCode() �����������涨��:
? ͬһ�����϶�ε��� hashCode() ����,���Ƿ�����ͬ������ֵ��
? ��� a.equals(b),��һ���� a.hashCode() һ������ b.hashCode()��
? ��� !a.equals(b),�� a.hashCode() ��һ������ b.hashCode()����ʱ��� a.hashCode() ���Dz���
? �� b.hashCode(),����� hashtables �����ܡ�
? a.hashCode()==b.hashCode() �� a.equals(b) ����ɼ�
? a.hashCode()!= b.hashCode() �� a.equals(b) Ϊ�١�
������ۼ��:
? ����������� equals,Java ����ʱ��������Ϊ���ǵ� hashCode һ����ȡ�
? ����������� equals,���ǵ� hashCode �п�����ȡ�
? ����������� hashCode ���,���Dz�һ�� equals��
? ����������� hashCode �����,����һ���� equals
����:���� equals() �� hashCode() ����Ҫ�淶
? �淶1:����д equals() ����,�б�Ҫ��д hashcode()����,ȷ��ͨ�� equals()�����жϽ��Ϊ
? true ����������߱���ȵ� hashcode() ��������ֵ��˵�ü����:���������������ͬ,��ô
? ���ǵ� hashCode Ӧ����ȡ���������ע��:���ֻ�ǹ淶,�����Ҫдһ������ equals() ������
? �� true �� hashCode() ����������������ȵ�ֵ,��������ж��Dz��ᱨ���ġ���������Υ����
? Java �淶,����Ҳ�������� BUG��
? �淶2:��� equals() �������� false,������������ͬ��,����Ҫ����������������
? hashCode() �����õ���������ͬ������˵�ļ����:���������������ͬ,���ǵ�
? hashCode ������ͬ����
34. Ϊʲô��д equals ����������д hashcode ���� ?
�жϵ�ʱ��**�ȸ���hashcode���е��ж�,��ͬ��������ٸ���equals()���������жϡ�**���ֻ��д��
equals����,������дhashcode�ķ���,�����hashcode��ֵ��ͬ,��equals()�����жϳ����Ľ��
Ϊtrue��
��Java�е�һЩ������,��������������ȫ��ͬ�Ķ���,�����ʱ��,����ж���ͬ�����и��ǡ���
ʱ�����ֻ��д��equals()�ķ���,������дhashcode�ķ���,Object��hashcode�Ǹ��ݶ���Ĵ�
����ַת�����γɵ�һ����ϣֵ����ʱ����п�����Ϊû����дhashcode����,�����ͬ�Ķ���ɢ�е�
��ͬ��λ�ö���ɶ���IJ��ܸ��ǵ����⡣
35. String,StringBuffer, StringBuilder ��������ʲô?
1.�ɱ��벻�ɱ䡣String����ʹ���ַ����鱣���ַ���,��Ϊ�С�final�����η�,����string�����Dz��ɱ�
�ġ������Ѿ����ڵ�String������Ķ������´���һ���µĶ���,Ȼ����µ�ֵ�����ȥ
- StringBuilder��StringBuffer���̳���AbstractStringBuilder��,��AbstractStringBuilder��Ҳ��ʹ����
�����鱣���ַ���,�����ֶ����ǿɱ�ġ�
2.�Ƿ��̰߳�ȫ��
? String�еĶ����Dz��ɱ��,Ҳ�Ϳ�������Ϊ����,��Ȼ�̰߳�ȫ��
? StringBuilder�Ƿ��̰߳�ȫ�ġ�
? StringBuffer�Է�������ͬ�������߶Ե��õķ�������ͬ����,�������̰߳�ȫ�ġ�
3.�����ֻ���ڵ��߳���ʹ���ַ���������,��ôStringBuilder��Ч�ʻ����Щ��ֵ��ע�����StringBuilder����JDK1.5�汾�����ӵġ���ǰ�汾��JDK����ʹ�ø��ࡣ
36. StringΪʲôҪ��Ƴɲ��ɱ��?
1.����ʵ���ַ�����(String pool)
��Java��,���ڻ������ʹ��String����,���ÿһ������һ��String������һ��String����,��������
�ɼ���Ŀռ���Դ���˷���Java�����String pool�ĸ���,�ڶ��п���һ��洢�ռ�String pool,����
ʼ��һ��String����ʱ,������ַ����Ѿ�������,�Ͳ���ȥ����һ���µ��ַ�������,���ǻ᷵����
�������˵��ַ��������á�
2.ʹ���̰߳�ȫ
�ڲ���������,����߳�ͬʱ��һ����Դ,�ǰ�ȫ��,������������,������Դ����д����ʱ�Dz���ȫ
��,���ɱ�����ܱ�д,���Ա�֤�˶��̵߳İ�ȫ��
3.���ⰲȫ����
���������Ӻ����ݿ��������ַ���������Ϊ����,����,�������ӵ�ַURL,�ļ�·��path,�������
����Ҫ��String�����������ɱ��Կ��Ա�֤���ӵİ�ȫ�ԡ�����ַ����ǿɱ��,�ڿ;��п��ܸı���
����ָ������ֵ,��ô����������صİ�ȫ���⡣
4.�ӿ��ַ��������ٶ�
����String�Dz��ɱ��,��֤��hashcode��Ψһ��,�����ڴ�������ʱ��hashcode�Ϳ��Է��ĵĻ���
��,����Ҫ���¼��㡣��Ҳ����Mapϲ����String��ΪKey��ԭ��,�����ٶ�Ҫ��������ļ���������
HashMap�еļ�������ʹ��String��
37. �ַ��ͳ������ַ�������������?
-
��ʽ��: �ַ������ǵ����������һ���ַ�,�ַ���������˫������������ɸ��ַ�;
-
������: �ַ������൱��һ������ֵ( ASCII ֵ),���Բμӱ���ʽ����;�ַ�����������һ����ֵַ
(���ַ������ڴ��д��λ��,�൱�ڶ���;
- ռ�ڴ��С:�ַ�����ֻռ2���ֽ�;�ַ�������ռ���ɸ��ֽ�(����һ���ַ�������־) (ע��: char
��Java��ռ�����ֽ�)
38. ʲô���ַ���������?
- jvmΪ���������ܺͼ����ڴ濪��,�����ַ����ظ�����,��ά����һ��������ڴ�ռ�,���ַ���
��,����Ҫʹ���ַ���ʱ,��ȥ�ַ������в鿴���ַ����Ƿ��Ѿ�����,�������,�����ֱ��ʹ��,
���������,��ʼ��,�������ַ��������ַ����������С�
**39. String str=��aaa��**�� String str=new String(��aaa��)һ����?new String(��aaa��);�����˼����ַ�������?
- ʹ�� String a = ��aaa�� ; ,��������ʱ���ڳ������в��ҡ�aaa���ַ���,��û��,�Ὣ��aaa���ַ�
���Ž�������,�ٽ����ַ����a;����,���ҵ��ġ�aaa���ַ����ĵ�ַ����a��
- ʹ��String b = new String(��aaa��);`,����������ڴ��п���һƬ�¿ռ����¶���,ͬʱ��
����aaa���ַ������볣����,�൱�ڴ�������������,���۳���������û�С�aaa���ַ���,����
�ڶ��ڴ��п���һƬ�¿ռ����¶���
40. String �������������������**?**
���ǡ�Java �еĻ�����������ֻ�� 8 �� :byte��short��int��long��float��double��char��boolean;
���˻�������(primitive type),ʣ�µĶ�����������(referencetype),Java 5 �Ժ������ö����
��Ҳ����һ�ֱȽ�������������͡�
41. String��������**?**
- ������:String ��ֻ���ַ���,��һ�����͵� immutable ����,���������κβ���,��ʵ���Ǵ�
��һ���µĶ���,�ٰ�����ָ��ö�����ģʽ����Ҫ�������ڵ�һ��������Ҫ�����̹߳�����
Ƶ������ʱ,���Ա�֤���ݵ�һ����;
- �������Ż�:String ����֮��,�����ַ����������н��л���,����´δ���ͬ���Ķ���ʱ,
��ֱ�ӷ��ػ��������;
- final:ʹ�� final ������ String ��,��ʾ String ��ܱ��̳�,�����ϵͳ�İ�ȫ�ԡ�
42. ��ʹ�� HashMap ��ʱ��,�� String �� key ��ʲô�ô�?
- HashMap �ڲ�ʵ����ͨ�� key �� hashcode ��ȷ�� value �Ĵ洢λ��,��Ϊ�ַ����Dz��ɱ��,����
�������ַ���ʱ,���� hashcode ����������,����Ҫ�ٴμ���,�������������������졣
43. ��װ������ʲô?�������ͺͰ�װ������ʲô����?
- Java Ϊÿһ�������������Ͷ������˶�Ӧ�İ�װ����(wrapper class),int �İ�װ����� Integer,
�� Java 5 ��ʼ�������Զ�װ��/�������,�ѻ�������ת���ɰ�װ���͵Ĺ��̽���װ��(boxing);��
֮,�Ѱ�װ����ת���ɻ������͵Ĺ��̽�������(unboxing),ʹ�ö��߿����ת����
-
Java Ϊÿ��ԭʼ�����ṩ�˰�װ����:
ԭʼ����: boolean,char,byte,short,int,long,float,double
��װ����:Boolean,Character,Byte,Short,Integer,Long,Float,Double
-
��װ���Ϳ���Ϊ null,���������Ͳ����ԡ�
-
��װ���Ϳ����ڷ���,���������Ͳ����������Ͳ���ʹ�û�������,��Ϊʹ�û�������ʱ���
�������
��Ϊ�����ڱ���ʱ��������Ͳ���,���ֻ����ԭʼ����,��ԭʼ����ֻ���� Object �༰������
�������������Ǹ�������
-
�������ͱȰ�װ������Ч������������ջ��ֱ�Ӵ洢�ľ�����ֵ,����װ������洢���Ƕ���
�����á� ����Ȼ,��Ƚ��ڻ������Ͷ���,��װ������Ҫռ�ø�����ڴ�ռ䡣
44. ����һ���Զ�װ����Զ�����?
- �Զ�װ��:������������������ת��Ϊ����
public class Test {
public static void main(String[] args) {
// ����һ��Integer����,�õ����Զ���װ��:����Ϊ:
Integer num = Integer.valueOf(9);
Integer num = 9; } }
9�����ڻ����������͵�,ԭ�������Dz���ֱ�Ӹ�ֵ��һ������Integer�ġ���jdk1.5 ��ʼ�������Զ�װ
��/�������,�Ϳ��Խ�������������,�Զ���������������ת��Ϊ��Ӧ�ķ�װ����,��Ϊһ�������Ժ�
�Ϳ��Ե��ö��������������еķ�����
- �Զ�����:����������ת��Ϊ������������
public class Test {
public static void main(String[] args) {
/ /����һ��Integer����
Integer num = 9;
// ���м���ʱ���������Զ�����
System.out.print(num--);
} }
��Ϊ����ʱ����ֱ�ӽ��������,����Ҫת��Ϊ�����������ͺ���ܽ��мӼ��˳���
45. int �� Integer ��ʲô����**?**
Integer��int�İ�װ��;int�ǻ�����������;
Integer��������ʵ���������ʹ��;int��������Ҫ;
Integerʵ���Ƕ��������,ָ���new��Integer����;int��ֱ�Ӵ洢����ֵ ;
Integer��Ĭ��ֵ��null;int��Ĭ��ֵ��0��
46. ����new���ɵ�Integer�����ĶԱ�
����Integer����ʵ�����Ƕ�һ��Integer���������,��������ͨ��new���ɵ�Integer������Զ�Dz���
�ȵ�(��Ϊnew���ɵ�����������,���ڴ��ַ��ͬ)��
47. Integer������int�����ĶԱ�
Integer������int�����Ƚ�ʱ,ֻҪ����������ֵ����ȵ�,����Ϊtrue
48. ��new���ɵ�Integer������**new Integer()**���ɱ��� �ĶԱ�
��new���ɵ�Integer������new Integer()���ɵı����Ƚ�ʱ,���Ϊfalse��(��Ϊ��new���ɵ�
Integer����ָ�����java�������еĶ���,��new Integer()���ɵı���ָ������½��Ķ���,��������
���еĵ�ַ��ͬ)
Integer b = new Integer(10000);
Integer c=10000;
System.out.println(b == c); // false
49. ������new���ɵ�Integer����ĶԱ�
����������new���ɵ�Integer����,���бȽ�ʱ,�������������ֵ������-128��127֮��,��ȽϽ�
��Ϊtrue,�������������ֵ���ڴ�����,��ȽϽ��Ϊfalse
��ֵ�� -128 ~ 127֮��ʱ,java������Զ�װ��Ȼ����ֵ���л���,����´�������ͬ��ֵ,��ֱ
���ڻ�����ȡ��ʹ�á�������ͨ��Integer���ڲ���IntegerCache����ɵġ���ֵ�����˷�Χ,���ڶ���
new��һ���������洢��
50. ʲô�Ƿ���?
������������״̬��,��������һ����,���ܹ�֪���������������Ժͷ���;��������һ������,��
�ܹ�������������һ������������;���ֶ�̬��ȡ����Ϣ�Լ���̬���ö���ķ����Ĺ��ܳ�Ϊ Java ����
�ķ�����ơ�
51. ������Ƶ���ȱ������Щ?
�ŵ�:�ܹ�����ʱ��̬��ȡ���ʵ��,��������;���붯̬������
Class.forName(��com.mysql.jdbc.Driver.class��); ,����MySQL�������ࡣ
ȱ��:ʹ�÷������ܽϵ�,��Ҫ�����ֽ���,���ڴ��еĶ�����н�����
52. ��λ�ȡ�����е�Class����?
-
Class.forName(�����·����);����֪�������ȫ·����ʱ,�����ʹ�ø÷�����ȡ Class �����
-
����.class���ַ���ֻ�ʺ��ڱ���ǰ��֪�������� Class��
-
������.getClass()��
53. Java����API���?
���� API �������� JVM �е��ࡢ�ӿڻ���������Ϣ��
? Class ��:����ĺ�����,���Ի�ȡ�������,��������Ϣ��
? Field ��:Java.lang.reflec ���е���,��ʾ��ij�Ա����,����������ȡ��������֮�е�����ֵ��
? Method ��:Java.lang.reflec ���е���,��ʾ��ķ���,������������ȡ���еķ�����Ϣ����ִ��
������
? Constructor ��:Java.lang.reflec ���е���,��ʾ��Ĺ��췽����
54. ����ʹ�õIJ���?
-
��ȡ��Ҫ���������Class�������Ƿ���ĺ���,ͨ��Class�������ǿ������������ķ�����
-
���� Class ���еķ����Ⱦ��Ƿ����ʹ�ýΡ�
-
ʹ�÷��� API ��������Щ��Ϣ��
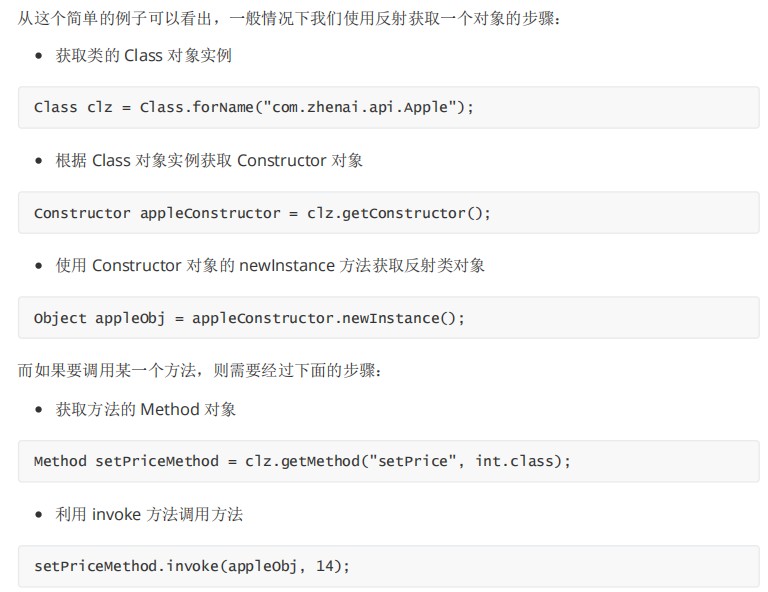
55. Ϊʲô���뷴�����?������Ƶ�Ӧ������Щ?
�����ÿ�����Ա����ͨ���ⲿ���ȫ·������������,��ʹ����Щ��,ʵ��һЩ��չ�Ĺ��ܡ�
�����ÿ�����Ա����ö�ٳ����ȫ����Ա,�������캯�������ԡ���������������д����ȷ�Ĵ��롣
����ʱ�������÷��� API �������˽�г�Ա,�Ա�֤���Դ��븲������
Ҳ����˵,Oracle ϣ�������߽�������Ϊһ������,������������Աʵ�ֱ�������ʵ�ֵĹ��ܡ�
- JDBC �����ݿ������
��JDBC �IJ�����,���Ҫ��������ݿ������,����밴�����ϵļ������
? ͨ��Class.forName()�������ݿ���������� (ͨ���������,ǰ�������������Jar��);
? ͨ�� DriverManager ��������ݿ������,���ӵ�ʱ��Ҫ�������ݿ�����ӵ�ַ���û���������;
? ͨ��Connection �ӿڽ������ӡ�
- Spring ��ܵ�ʹ��,���ľ���xml������ģʽ��
Spring �е� IOC �ĵײ�ʵ��ԭ�����Ƿ������,Spring ������������Ǵ���ʵ��,��������ʹ�õķ������Ƿ���,ͨ������xml�ļ�,��ȡ��id���Ժ�class�������������,���÷���ԭ�����������ļ������ʵ������,���뵽Spring��bean�����С�
? Spring�������ĺô���:
? ����ÿһ�ζ�Ҫ�ڴ�������ȥnew����������������;
? �Ժ�Ҫ�ĵĻ�ֱ�Ӹ������ļ�,����ά�������ͺܷ�����;
? ��ʱΪ����ӦijЩ����,Java�����治һ����ֱ�ӵ�������ķ���,����ͨ�����������ʵ�֡�
56. ������Ƶ�ԭ����ʲô?
57. Java�еķ�����ʲô ?
������ JDK1.5 ��һ��������,���;��ǽ����Ͳ�����,���ڱ���ʱ��ȷ������IJ�����
���ǽ�ԭ���ľ�������Ͳ�����,Ȼ����ʹ�� /����ʱ������������
- ���͵Ķ����ʽ:

58. ʹ�÷��͵ĺô���ʲô?
ʹ�÷��͵ĺô������¼���:
-
���Ͱ�ȫ
���͵���ҪĿ������� Java ��������Ͱ�ȫ
����ʱ�ھͿ��Լ����� Java ���Ͳ���ȷ���µ� ClassCastException �쳣
����Խ���������ԽСԭ��
-
����ǿ������ת��
���͵�һ�������ô���,ʹ��ʱֱ�ӵõ�Ŀ������,��������ǿ������ת��
���ü�����,��ʹ�ô�����ӿɶ�,���Ҽ����˳�������
-
DZ�ڵ���������
���ڷ��͵�ʵ�ַ�ʽ,֧�ַ���(����)����Ҫ JVM �����ļ�����
���й������ڱ����������
���������ɵĴ������ʹ�÷���(��ǿ������ת��)ʱ��д�Ĵ��뼸��һ��,ֻ�Ǹ���ȷ�����Ͱ�ȫ����
60. ʲô�Ƿ����е���ͨ����ͷ���ͨ��� ?
- ��ͨ��������ͽ��������ơ���������ͨ���,һ����<? extends T>��ͨ��ȷ�����ͱ�����T����
�����趨���͵��Ͻ�,��һ����<? super T>��ͨ��ȷ�����ͱ�����T�ĸ������趨���͵��½硣������
�ͱ��������ڵ����������г�ʼ��,����ᵼ�±������
- ����ͨ��� ?,����������������������� List<?> ����˼�����������һ�����Գ����������͵ļ�
��,�������� List ,Ҳ������ List ,���� List �ȵ�
**61. List<? extends T>��List <? super T>**֮����ʲô���� ?
- ������List������������ͨ���������,List<? extends T>���Խ����κμ̳���T�����͵�List,��
List<? super T>���Խ����κ�T�ĸ���ɵ�List������List<? extends Number>���Խ���List��List��
64. Java���л��뷴���л���ʲô?
- Java���л���ָ��Java����ת��Ϊ�ֽ����еĹ���,��Java�����л���ָ���ֽ����лָ�ΪJava����Ĺ���
- ���л�:���л��ǰѶ���ת���������ֽ���,�Ա��������ϴ�����߱����ڱ����ļ��С����������Ƕ���״̬�ı������ؽ������Ƕ�֪��,Java�����DZ�����JVM�Ķ��ڴ��е�,Ҳ����˵,���JVM�Ѳ�������,��ô����Ҳ������ʧ�ˡ������л��ṩ��һ�ַ���,���������ڼ�ʹJVMͣ���������Ҳ�ܰѶ��������ķ�������������ƽʱ�õ�U��һ������Java�������л��ɿɴ洢�������ʽ(���������),���籣�����ļ��С�����,���ٴ���Ҫ��������ʱ��,���ļ��ж�ȡ����������,�ٴӶ��������з����л�������
- �����л�:�ͻ��˴��ļ��л������ϻ�����л���Ķ����ֽ���,�����ֽ�����������Ķ���״̬��������Ϣ,ͨ�������л��ؽ�����
65. Ϊʲô��Ҫ���л��뷴���л�?
��Ҫ����:���ڴ��еĶ�����г־û������紫��**,** ���ʱ����Ҫ���л��ͷ����л�
-
���л����Խ��ڴ��е���д���ļ������ݿ��С�
-
�����ļ�������,�����ͬ�ĸ�ʽ,����ͳһ����ͱ��档
���л��Ժ�Ͷ����ֽ�����,����ԭ����ʲô����,���ܱ��һ���Ķ���,�Ϳ��Խ���ͨ�õĸ�ʽ�����,��������Ժ�,Ҫ�ٴ�ʹ��,�ͽ��з����л���ԭ,���������Ƕ���,�ļ������ļ���
-
�������л�����ʵ�ֲַ�ʽ����
-
java�������л���������һ�����������,���ҵݹ鱣��������õ�ÿ����������ݡ�
66. ���л�ʵ�ֵķ�ʽ����Щ?
ʵ��Serializable�ӿڻ���Externalizable�ӿ�
��ͨ��ʵ�� java.io.Serializable �ӿ������������л����ܡ������л�������������ͱ������ǿ����л��ġ����л��ӿ�û�з������ֶ�,�����ڱ�ʶ�����л������塣
70. Java ���л��������Щ�ֶβ���������л�,��ô ��?
���ڲ���������л��ı���,ʹ�� transient �ؼ������Ρ�
transient �ؼ��ֵ������ǿ��Ʊ��������л�,�ڱ�������ǰ���ϸùؼ���,������ֹ�ñ��������л����ļ���,�ڱ������л���, transient ������ֵ����Ϊ��ʼֵ,�� int �͵��� 0,�����͵��� null��transient ֻ�����α���,����������ͷ�����
71. ��̬�����ᱻ���л���?
���ᡣ��Ϊ���л�����Զ��������, ����̬���������ڶ������, ������ļ��ض�����, ���Բ��ᱻ���л�
72. Error �� Exception ������ʲô?
Java ��,���е��쳣����һ����ͬ������ java.lang ���е� Throwable �ࡣ Throwable ����������Ҫ������ Exception (�쳣)�� Error (����)
-
Exception :���������Դ������쳣,����ͨ�� catch �����в���,ͨ���������ִ���,Ӧ������д���,ʹӦ�ó�����Լ����������С� Exception �ֿ��Է�Ϊ����ʱ�쳣(RuntimeException, �ֽз��ܼ���쳣)�ͷ�����ʱ�쳣(�ֽ��ܼ���쳣) ��
-
Error : Error ���ڳ����������Ĵ��� ,����û�취ͨ�� catch �����в��� ������,ϵͳ����,�ڴ治��,��ջ�����,��������������������м��,һ�����������,ͨ��Ӧ�ó���ᱻ��ֹ,����Ӧ�ó��������ָ���
73.���ܼ���쳣(����ʱ�쳣)���ܼ���쳣(һ���쳣)������ʲô?
���ܼ���쳣���ܼ���쳣֮�������:�Ƿ�ǿ��Ҫ������߱��봦�����쳣,���ǿ��Ҫ������߱�����д���,��ô��ʹ���ܼ���쳣�����ѡ����ܼ���쳣
- ���ܼ���쳣:���� RuntimeException �༰������,��ʾ JVM �������ڼ���ܳ��ֵ��쳣�� Java ��
��������������ʱ�쳣������: NullPointException(��ָ��) �� NumberFormatException(�ַ���
ת��Ϊ����) �� IndexOutOfBoundsException(����Խ��) �� ClassCastException(��ת���쳣) ��
ArrayStoreException(���ݴ洢�쳣,��������ʱ���Ͳ�һ��) �ȡ�
- �ܼ���쳣:��Exception �г� RuntimeException ��������֮����쳣�� Java �����������ܼ��
�쳣���������ܼ���쳣��**: IO ��ص��쳣�� ClassNotFoundException �� SQLException �ȡ�**
74. throw �� throws ��������ʲô?
throw �ؼ������ڷ����ڲ�ֻ�������׳�һ���쳣,�����׳������������е��쳣,�ܲ��쳣
�ͷ��ܲ��쳣�����Ա��׳���
throws �ؼ������ڷ���������,�����׳�����쳣,������ʶ�÷��������׳����쳣�б���һ��
������ throws ��ʶ�˿����׳����쳣�б�,���ø÷����ķ����б�������ɴ����쳣�Ĵ���,��
��ҲҪ�ڷ���ǩ������ throws �ؼ���������Ӧ���쳣��
76. Java�����쳣����Щ?
java.lang.InstantiationError:ʵ��������һ��Ӧ����ͼͨ��Java��new����������һ������
����߽ӿ�ʱ�׳����쳣.
java.lang.OutOfMemoryError:�ڴ治����������ڴ治������Java����������һ������
ʱ�׳��ô���
java.lang.NullPointerException:��ָ���쳣
77. try-catch-finally ���ĸ����ֿ���ʡ��?
catch ����ʡ�ԡ���Ϊ�ϸ��˵����ʵ��:tryֻ�ʺϴ�������ʱ�쳣,try+catch�ʺϴ�������ʱ�쳣
+��ͨ�쳣��Ҳ����˵,�����ֻ��tryȥ������ͨ�쳣ȴ������catch����,������ͨ������,��Ϊ����
��Ӳ�Թ涨,��ͨ�쳣���ѡ��,�������catch��ʾ�����Ա��һ��������������ʱ�쳣�ڱ���ʱ
û����˹涨,����catch����ʡ��,�����catch������Ҳ�����ɺ�ǡ�
78. try-catch-finally ��,��� catch �� return ��,finally ����ִ����?
��ִ��,�� return ǰִ��
��.java����
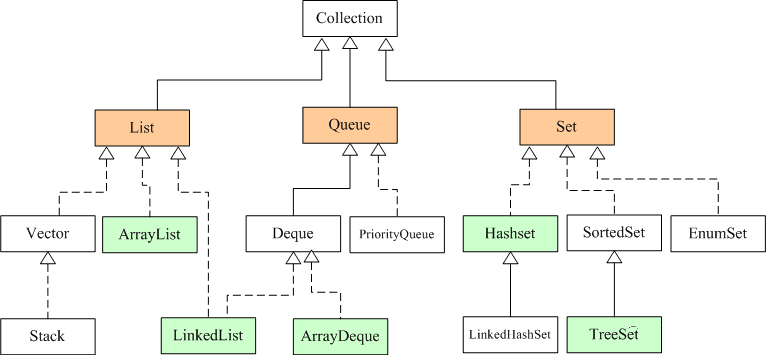
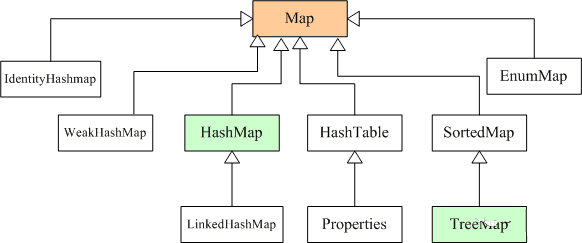
1. �����ļ�������Щ?
2. �̰߳�ȫ�ļ�������Щ?�̲߳���ȫ����?
-
�̰߳�ȫ��:
? Hashtable:��HashMap���˸��̰߳�ȫ��
? ConcurrentHashMap:��һ�ָ�Ч�����̰߳�ȫ�ļ��ϡ�
? Vector:��Arraylist���˸�ͬ�������ơ�
? Stack:ջ,Ҳ���̰߳�ȫ��,�̳���Vector��
-
���Բ���ȫ��:
HashMap
Arraylist
LinkedList
HashSet
TreeSet
TreeMap
3. Arraylist�� LinkedList ��ͬ��?
-
�Ƿ�֤�̰߳�ȫ: ArrayList �� LinkedList ���Dz�ͬ����,Ҳ���Dz���֤�̰߳�ȫ;
-
�ײ����ݽṹ: Arraylist �ײ�ʹ�õ���Object����;LinkedList �ײ�ʹ�õ���˫��ѭ���������ݽṹ;
-
�����ɾ���Ƿ���Ԫ��λ�õ�Ӱ��: ArrayList ��������洢,���Բ����ɾ��Ԫ�ص�ʱ�� ���Ӷ���Ԫ��λ�õ�Ӱ�졣 ����:ִ�� add(E e) ������ʱ��, ArrayList ��Ĭ���ڽ�ָ����Ԫ���ӵ����б���ĩβ,�������ʱ�临�ӶȾ���O(1)���������Ҫ��ָ��λ�� i �����ɾ��Ԫ�صĻ�( add(int index, E element) )ʱ�临�ӶȾ�Ϊ O(n-i)����Ϊ�ڽ�������������ʱ���е� i �͵� i ��Ԫ��֮���(n-i)��Ԫ�ض�Ҫִ�����λ/��ǰ��һλ�IJ����� **LinkedList �������� �洢,���Բ���,ɾ��Ԫ��ʱ�临�ӶȲ���Ԫ��λ�õ�Ӱ��,**���ǽ��� O(1)������Ϊ���� O(n)��
-
�Ƿ�֧�ֿ����������: LinkedList ��֧�ָ�Ч�����Ԫ�ط���,��ArrayList ʵ����RandmoAccess �ӿ�,������������ʹ��ܡ�����������ʾ���ͨ��Ԫ�ص���ſ��ٻ�ȡԪ�ض���(��Ӧ�� get(int index) ����)��
-
�ڴ�ռ�ռ��: ArrayList�Ŀ� ���˷���Ҫ��������list�б��Ľ�β��Ԥ��һ���������ռ�,��LinkedList�Ŀռ仨��������������ÿһ��Ԫ�ض���Ҫ���ı�ArrayList����Ŀռ�(��ΪҪ���ֱ�Ӻ�̺�ֱ��ǰ���Լ�����)��
4. ArrayList �� Vector ����?
-
Vector���̰߳�ȫ��,ArrayList�����̰߳�ȫ��������,Vector�ڹؼ��Եķ���ǰ�涼����synchronized�ؼ���,����֤�̵߳İ�ȫ�ԡ�����ж���̻߳���ʵ�����,�������ʹ��Vector,��Ϊ����Ҫ�����Լ���ȥ���Ǻͱ�д�̰߳�ȫ�Ĵ��롣
-
ArrayList�ڵײ����鲻����ʱ��ԭ���Ļ�������չ0.5��,Vector����չ1��,����ArrayList�������ڽ�Լ�ڴ�ռ䡣
5.˵һ˵ArrayList �����ݻ���?
ArrayList���ݵı��ʾ��Ǽ�����µ����������size��ʵ����,����ԭ���������ݸ��Ƶ���������ȥ��
Ĭ�������,�µ���������ԭ������1.5����
6. Array �� ArrayList ��ʲô����?ʲôʱ���Ӧ Array������ ArrayList ��?
-
Array �������������ͺͶ�������,ArrayList ֻ�ܰ����������͡�
-
Array ��С�ǹ̶���,ArrayList �Ĵ�С�Ƕ�̬�仯�ġ�
-
ArrayList �ṩ�˸���ķ���������,����:addAll(),removeAll(),iterator() �ȵȡ�
7. HashMap�ĵײ����ݽṹ��ʲô?
��JDK1.7 ��JDK1.8 ���������:
? ��JDK1.7 ��,�ɡ�����+���������,������ HashMap ������,����������ҪΪ�˽����ϣ��ͻ�����ڵġ�
? ��JDK1.8 ��,�ɡ�����+����+���������ɡ�����������,�������Ӱ�� HashMap ������,���������ʱ�临�Ӷ��� O(logn),������������ O(n)�����,JDK1.8 �����ݽṹ���˽�һ�����Ż�,�����˺����,�����ͺ�����ڴﵽһ�����������ת��:
-
���������� 8 �������������� 64 �Ż�ת�������
-
������ת���ɺ����ǰ���ж�,�����ǰ����ij���С�� 64,��ô��ѡ���Ƚ�����������,������ת��Ϊ�����,�Լ�������ʱ��
8. ���hash��ͻ�İ취����Щ?HashMap�õ�����?
���Hash��ͻ������:���Ŷ�ַ�����ٹ�ϣ��������ַ��(������)�����������������HashMap�в��õ��� ����ַ�� ��
? ���Ŷ�ַ��Ҳ��Ϊ ��ɢ�з� ,����˼�����,��� p=H(key) ���ֳ�ͻʱ,���� p Ϊ����,�ٴ�
hash, p1=H�� ,���p1�ٴγ��ֳ�ͻ,����p1Ϊ����,�Դ�����,ֱ���ҵ�һ������ͻ�Ĺ�ϣ��
ַ pi �� ��˿��Ŷ�ַ������Ҫ��hash���ij���Ҫ���ڵ�������Ҫ��ŵ�Ԫ��,������Ϊ�����ٴ�
hash,���� ֻ����ɾ���Ľڵ��������,����������ɾ���ڵ㡣
? **�ٹ�ϣ��(**˫��ɢ��,����ɢ��),�ṩ�����ͬ��hash����,�� R1=H1(key1) ������ͻʱ,�ټ�
�� R2=H2(key1) ,ֱ��û�г�ͻΪֹ�� ��������Ȼ���ײ����Ѽ�,�������˼����ʱ�䡣
? ����ַ��(������),����ϣֵ��ͬ��Ԫ�ع���һ��ͬ��ʵĵ�����,������������ͷָ�����ڹ�ϣ
���ĵ�i����Ԫ��,���ҡ������ɾ����Ҫ��ͬ��������н��С������������ھ������в����ɾ��
�������
? �������������,����ϣ����Ϊ�������������,���������ʱ,�������������ͳһ�ŵ��������
9. Ϊʲô�ڽ�� hash ��ͻ��ʱ��,��ֱ���ú����?�� ѡ����������,��ת�����?
��Ϊ�������Ҫ��������,����,��ɫ��Щ����������ƽ��,������������Ҫ����Ԫ��С�� 8 ����ʱ
��,��ʱ����ѯ����,�����ṹ�Ѿ��ܱ�֤��ѯ���ܡ���Ԫ�ش��� 8 ����ʱ��, ���������ʱ�临�Ӷ�
�� O(logn),�������� O(n),��ʱ��Ҫ��������ӿ��ѯ�ٶ�,���������ڵ��Ч�ʱ����ˡ�
���,���һ��ʼ���ú�����ṹ,Ԫ��̫��,����Ч���ֱȽ���,���������˷����ܵġ�
10. HashMapĬ�ϼ��������Ƕ���?Ϊʲô�� 0.75,����0.6 ���� 0.8 ?
Node[] table�ij�ʼ������length(Ĭ��ֵ��16),Load factorΪ��������(Ĭ��ֵ��0.75),threshold��HashMap�������ɼ�ֵ�Ե����ֵ��threshold = length * Load factor��Ҳ����˵,�����鶨��ó���֮��,��������Խ��,�������ɵļ�ֵ�Ը���Խ����
Ĭ�ϵ�loadFactor��0.75,0.75�ǶԿռ��ʱ��Ч�ʵ�һ��ƽ��ѡ��
11. HashMap �� key �Ĵ洢��������ô�����?
���ȸ���key��ֵ�����hashcode��ֵ,Ȼ�����hashcode�����hashֵ,���ͨ��hash&(length-1)
�������hashcode�ĸ�16λ���16λ�������,Ȼ�����(length-1)���������㡣
12. HashMap ��put��������?
��JDK1.8Ϊ��,��Ҫ��������:
-
���ȸ��� key ��ֵ���� hash ֵ,�ҵ���Ԫ���������д洢���±�;
-
��������ǿյ�,����� resize ���г�ʼ��;
-
���û�й�ϣ��ͻֱ�ӷ��ڶ�Ӧ�������±���;
-
�����ͻ��,�� key �Ѿ�����,���ǵ� value;
-
�����ͻ��,���ָýڵ��Ǻ����,�ͽ�����ڵ��������;
-
�����ͻ��������,�жϸ������Ƿ���� 8 ,������� 8 ������������С�� 64,�ͽ�������;��
�������ڵ���� 8 ����������������� 64,������ṹת��Ϊ�����;����,���������ֵ
��,�� key ����,���ǵ� value��
13. HashMap �����ݷ�ʽ?
? HashMap �����������������������������֮��,�ͻ����ݡ�Java ������������Զ����ݵ�,����
�ǽ� HashMap �Ĵ�С����Ϊԭ�����������,����ԭ���Ķ�������µ������С�
jdk1.7����ʱ�����¼���hashֵ,jdk1.8����Ҫ
jdk1.7������Ǩ�Ƶ�������Ԫ�ػᵹ��,��β�巨��jdk1.8���ᵹ��,ʹ��β�巨��
14. һ����ʲô��ΪHashMap��key?
һ����Integer��String ���ֲ��ɱ��൱ HashMap �� key,���� String ��Ϊ���á�
��Ϊ�ַ����Dz��ɱ��,��������������ʱ�� hashcode �ͱ�������,����Ҫ���¼����������
HashMap �еļ�������ʹ���ַ�����ԭ��
��Ϊ��ȡ�����ʱ��Ҫ�õ� equals() �� hashCode() ����,��ô��������ȷ����д�����������Ƿ�
����Ҫ��,��Щ���Ѿ��ܹ淶����д�� hashCode() �Լ� equals() ������
15. HashMapΪʲô�̲߳���ȫ?
- ���߳���������ѭ����JDK1.7�е� HashMap ʹ��ͷ�巨����Ԫ��,�ڶ��̵߳Ļ�����,���ݵ�ʱ
���п��ܵ��»��������ij���,�γ���ѭ�������,JDK1.8ʹ��β�巨����Ԫ��,������ʱ�ᱣ��
����Ԫ��ԭ����˳��,������ֻ������������⡣
-
���̵߳�put���ܵ���Ԫ�صĶ�ʧ�����߳�ͬʱִ�� put ����,����������������λ������ͬ
��,�ǻ����ǰһ�� key ����һ�� key ����,�Ӷ�����Ԫ�صĶ�ʧ����������JDK 1.7�� JDK 1.8 ��
������
-
put��get����ʱ,���ܵ���getΪnull���߳�1ִ��putʱ,��ΪԪ�ظ�������threshold������
rehash,�߳�2��ʱִ��get,�п��ܵ���������⡣��������JDK 1.7�� JDK 1.8 �ж����ڡ�
��: hashmap��hashtable������
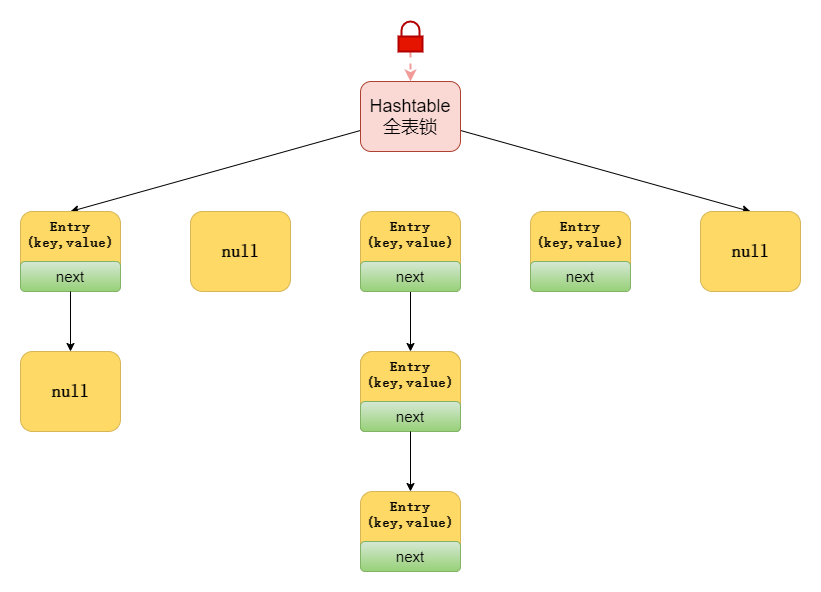
����,hashmap���̲߳���ȫ��,hashtable���̰߳�ȫ�ġ�Hashtable���̰߳�ȫ��,����ÿ�������ж�������Synchronize����HashMap�Ǽ̳���AbstractMap��,��HashTable�Ǽ̳���Dictionary�ࡣhashtable���ڻ��������á�Hashtable�Ȳ�֧��Null keyҲ��֧��Null value��HashMap��,null������Ϊ��,�����ļ�ֻ��һ��;������һ������������Ӧ��ֵΪnull��
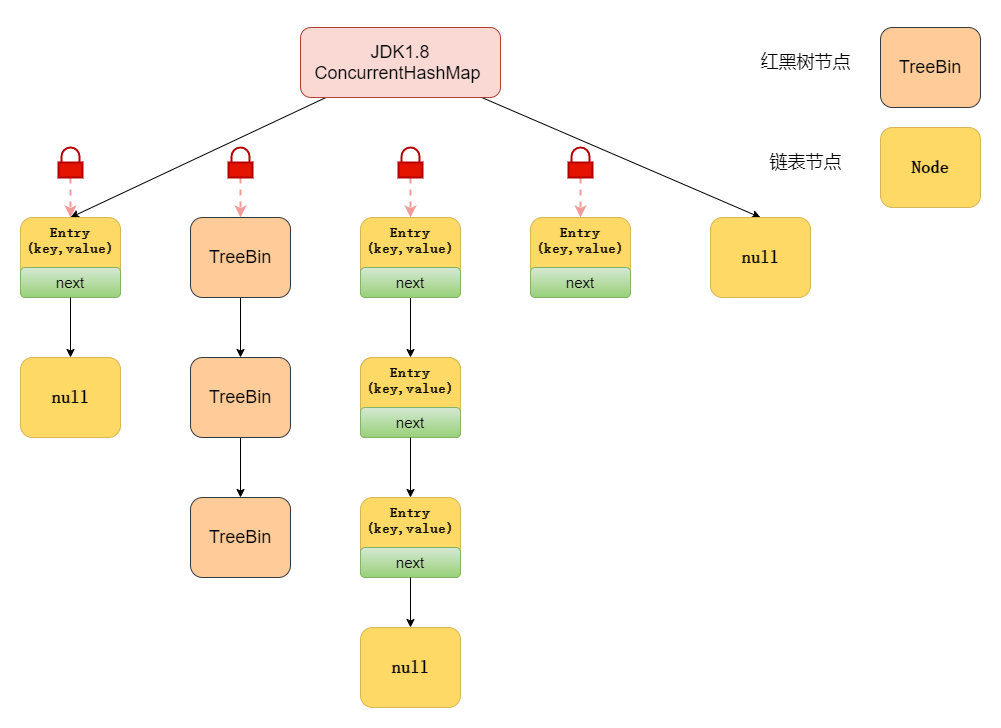
16. ConcurrentHashMap ��ʵ��ԭ����ʲô?
ConcurrentHashMap �� JDK1.7 �� JDK1.8 ��ʵ�ַ�ʽ�Dz�ͬ�ġ�
��������JDK1.7
JDK1.7�е�ConcurrentHashMap ���� Segment ����ṹ�� HashEntry ����ṹ���,��
ConcurrentHashMap �ѹ�ϣͰ�зֳ�С����(Segment ),ÿ��С������ n �� HashEntry �����
����,Segment �̳��� ReentrantLock,���� Segment ��һ�ֿ�������,�������Ľ�ɫ;HashEntry
���ڴ洢��ֵ�����ݡ�
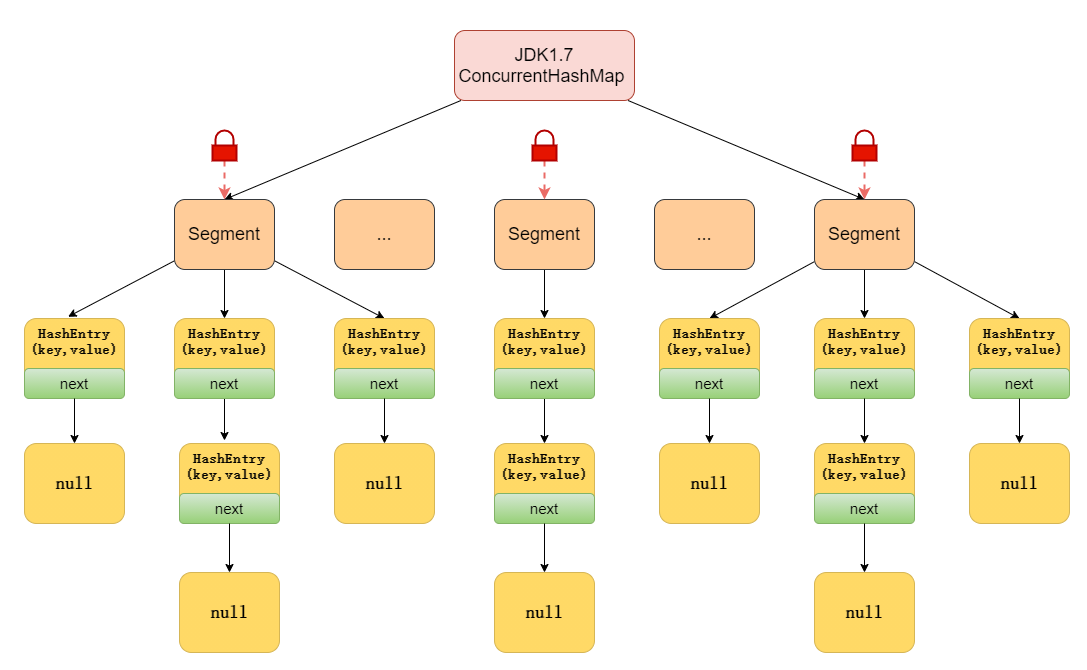
���Ƚ����ݷ�Ϊһ��һ�εĴ洢,Ȼ���ÿһ��������һ����,��һ���߳�ռ������������һ��������
ʱ,�����ε�����Ҳ�ܱ������̷߳���,�ܹ�ʵ�������IJ������ʡ�
��������JDK1.8
�����ݽṹ��, JDK1.8 �е�ConcurrentHashMap ѡ������ HashMap ��ͬ������**+����+**�������
��;**������ʵ����,������ԭ�е� Segment �ֶ���,���� CAS + synchronized ʵ�ָ��ӵ����ȵ����������ļ���������˸�ϸ���ȵĹ�ϣͰԪ�ؼ���,Ҳ����˵ֻ��Ҫ��ס�������ͷ���(������ĸ��ڵ��Ͳ���Ӱ�������Ĺ�ϣͰԪ�صĶ�д,�������˲����ȡ�
CAS����:��Ӣ�ĵ���Compare and Swap����д,����������DZȽϲ��滻��
CAS������ʹ����3������������:�ڴ��ַV,�ɵ�Ԥ��ֵA,Ҫ�ĵ���ֵB��
����һ��������ʱ��,ֻ�е�������Ԥ��ֵA���ڴ��ַV���е�ʵ��ֵ��ͬʱ,�ŻὫ�ڴ��ַV��Ӧ��ֵ��ΪB��
��˼������˵,synchronized���ڱ�����,���۵���Ϊ�����еIJ����������,�����Ϸ�����,CAS�����ֹ���,�ֹ۵���Ϊ�����еIJ����������ô����,�������̲߳���ȥ���Ը��¡�
17. ConcurrentHashMap �� put ����ִ������ʲô?
������JDK1.7
����,�᳢�Ի�ȡ��,�����ȡʧ��,����������ȡ��;����������ԵĴ������� 64 ��,���Ϊ����
��ȡ����
��ȡ������:
-
����ǰ Segment �е� table ͨ�� key �� hashcode ��λ�� HashEntry��
-
������ HashEntry,�����Ϊ�����жϴ���� key �͵�ǰ������ key �Ƿ����,����Ǿɵ�
value�� -
Ϊ������Ҫ�½�һ�� HashEntry �����뵽 Segment ��,ͬʱ�����ж��Ƿ���Ҫ���ݡ�
-
�ͷ� Segment ������
������JDK1.8
���¿��Է�Ϊ���²���:
-
���� key ����� hashֵ��
-
�ж��Ƿ���Ҫ���г�ʼ����
-
��λ�� Node,�õ��ڵ� f,�ж��ڵ� f:
-
���Ϊ null ,��ͨ��cas�ķ�ʽ�������ӡ�
-
���Ϊ f.hash = MOVED = -1 ,˵�������߳�������,����һ�����ݡ�
-
����������� ,synchronized ��ס f �ڵ�,�ж����������Ǻ����,�������롣
- �����������ȴﵽ8��ʱ��,�������ݻ��߽�����ת��Ϊ�������
18. ConcurrentHashMap �� get �����Ƿ�Ҫ����,Ϊʲô?
get ��������Ҫ����**����Ϊ Node ��Ԫ�� val ��ָ�� next ���� volatile ���ε�**,�ڶ��̻߳������߳�A
�Ľ���val���������ڵ��ʱ���Ƕ��߳�B�ɼ��ġ�
19. get��������Ҫ������volatile���εĹ�ϣͰ�й���?
û�й�ϵ����ϣͰ table ��volatile������Ҫ�DZ�֤���������ݵ�ʱ��֤�ɼ���
20. ConcurrentHashMap ��֧�� key ���� value Ϊnull ��ԭ��?
��������˵value Ϊʲô����Ϊ null ,��Ϊ ConcurrentHashMap �����ڶ��̵߳� ,���
map.get(key) �õ��� null ,���ж�,��ӳ���value�� null ,����û���ҵ���Ӧ��key��Ϊ null ,
������˶����ԡ�
�����ڵ��߳�״̬�� HashMap ȴ������ containsKey(key) ȥ�жϵ����Ƿ��������� null ��
ConcurrentHashMap �е�keyΪʲôҲ����Ϊ null ������,Դ���������д�ġ�
21. ConcurrentHashMap �IJ������Ƕ���?
��JDK1.7��,������Ĭ����16,���ֵ�����ڹ��캯�������á�����Լ������˲�����,
ConcurrentHashMap ��ʹ�ô��ڵ��ڸ�ֵ����С��2����ָ����Ϊʵ�ʲ�����,Ҳ���DZ��������õ�ֵ
��17,��ôʵ�ʲ�������32��
22. ConcurrentHashMap ��������ǿһ���Ի�����һ����?
HashMap��������ǿһ���Բ�ͬ,ConcurrentHashMap ����������һ���ԡ�
ConcurrentHashMap �ĵ�����������,�ͻᰴ�չ�ϣ���ṹ����ÿ��Ԫ��,���ڱ���������,�ڲ�Ԫ
�ؿ��ܻᷢ���仯,����仯�������ѱ������IJ���,�������Ͳ��ᷴӳ����,������仯������δ��
�����IJ���,�������ͻᷢ�ֲ���ӳ����,�������һ���ԡ�
�����������߳̿���ʹ��ԭ���ϵ�����,��д�߳�Ҳ���Բ�������ɸı�,����Ҫ��,�Ᵽ֤�˶����
�̲���ִ�е������Ժ���չ��,�����������Ĺؼ���
23. JDK1.7��JDK1.8 ��ConcurrentHashMap ������?
-
���ݽṹ:ȡ����Segment�ֶ��������ݽṹ,ȡ����֮��������+����+������Ľṹ��
-
��֤�̰߳�ȫ����:JDK1.7����Segment�ķֶ�������ʵ���̰߳�ȫ,����segment�̳���
ReentrantLock��JDK1.8 ����CAS+Synchronized��֤�̰߳�ȫ��
- ��������:ԭ���Ƕ���Ҫ�������ݲ�����Segment����,�ֵ���Ϊ��ÿ������Ԫ�ؼ���
(Node)��
- ����ת��Ϊ�����:��λ����hash�㷨�������,Hash��ͻ�Ӿ�,����������ڵ���������8
ʱ,�Ὣ����ת��Ϊ��������д洢��
- ��ѯʱ�临�Ӷ�:��ԭ���ı�������O(n),��ɱ��������O(logN)
24. ConcurrentHashMap ��Hashtable��Ч���ĸ�����?Ϊʲô?
ConcurrentHashMap ��Ч��Ҫ����Hashtable,��ΪHashtable��������ϣ������һ�Ѵ����Ӷ�ʵ����
�̰�ȫ����ConcurrentHashMap �������ȸ���,��JDK1.7�в��÷ֶ���ʵ���̰߳�ȫ,��JDK1.8 �в�
�� CAS+Synchronized ʵ���̰߳�ȫ��
25. ˵һ��Hashtable�������� ?
Hashtable��ʹ��Synchronized��ʵ���̰߳�ȫ��,��������ϣ������һ�Ѵ���,���̷߳���ʱ��,ֻ
Ҫ��һ���̷߳��ʻ�����ö���,�������߳�ֻ�������ȴ���Ҫ�������ͷ�,�ھ������ҵĶ��̳߳���
�����ܾͻ�dz���!
27. HashSet �� HashMap ����?

��.jvm
1. ʲô��JVM�ڴ�ṹ?
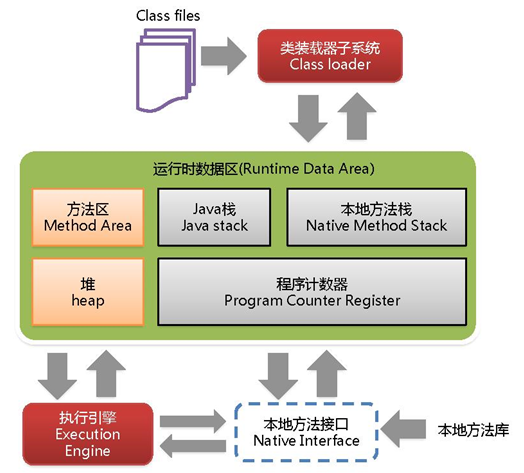
jvm���������Ϊ5������,����������������ջ�����ط���ջ��java�ѡ�������;
-
���������:�߳�˽�е�,��һ���С���ڴ�ռ�,��Ϊ��ǰ�̵߳��к�ָʾ��,���ڼ�¼��ǰ���������ִ�е��߳�ָ���ַ;
-
�����ջ:�߳�˽�е�,ÿ������ִ�е�ʱ�ᴴ��һ��ջ֡,���ڴ洢�ֲ�������������������̬���Ӻͷ������ص���Ϣ,���߳������ջ��ȳ����������������������ʱ,�ͻ��׳�StackOverFlowError;
-
**���ط���ջ:**�߳�˽�е�,�������native��������Ϣ,��һ��jvm�������̵߳���native������,jvm�����������ջ��Ϊ���̴߳���ջ֡,���ǼĶ�̬���Ӳ�ֱ�ӵ��ø÷���;
-
��:java���������̹߳�����һ���ڴ�,�������ж����ʵ�������鶼Ҫ�ڶ��Ϸ����ڴ�,��˸� ���������������յIJ���;
-
������:����ѱ����ص�����Ϣ����������̬��������ʱ�����������Ĵ������ݡ������ô�,��jdk1.8�в����ڷ�������,��Ԫ�����������,ԭ���������ֳ�������;1:���ص�����Ϣ,2:����ʱ������;���ص�����Ϣ��������Ԫ��������,����ʱ�����ر����ڶ���;
2. ʲô��JVM�ڴ�ģ��?
Java �ڴ�ģ��(���ļ�� JMM)�������ײ㴦�����ڴ�ģ�͵Ļ�����,�����Լ��Ķ��߳�����������ȷָ����һ���������,����֤�̼߳�Ŀɼ��ԡ�
��һ�����Ϊ Happens-Before, JMM �涨,Ҫ�뱣֤ B �����ܹ����� A �����Ľ��(����������
����ͬһ���߳�),��ô A �� B ֮��������� Happens-Before ��ϵ:
-
���̹߳���:һ���߳��е�ÿ�������� happens-before ���߳��к�����ÿ������
-
��������������:���������������� happens-before �������������������������
-
volatile ��������:�� volatile �ֶε�д�붯�� happens-before ����������ֶε�ÿ����ȡ����
-
�߳� start ����:�߳� start() ������ִ�� happens-before һ�������߳��ڵ������
-
�߳� join ����:һ���߳��ڵ����ж��� happens-before ���������߳��ڸ��߳� join() �ɹ�����֮ǰ
-
������:��� A happens-before B, �� B happens-before C, ��ô A happens-before C
��ô���� happens-before ��?�����������˼,����ڶ�������,�߳�(�����Dz���ͬһ��)�Ľ���
��������������֮ǰ?�����Բ��ԡ�happens-before Ҳ��Ϊ�˱�֤�ɼ���,�����Ǹ������ͼ����Ķ�
��,������������,�߳�1�ͷ����˳�ͬ����,�߳�2��������ͬ����,��ô�߳�2���ܿ����߳�1�Թ���
�����ĵĽ����
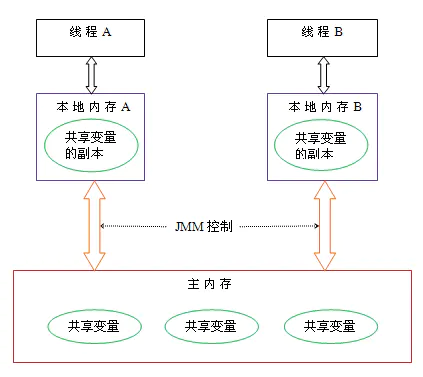
Java �ṩ�˼������Խṹ,���� volatile, final �� synchronized, ����ּ�ڰ�������Ա���������������
�IJ���Ҫ��,����:
-
volatile - ��֤�ɼ��Ժ�������
-
synchronized - ��֤�ɼ��Ժ�������; ͨ���ܳ�(Monitor)��֤һ�鶯����ԭ����
-
final - ͨ����ֹ�ڹ��캯����ʼ���� final �ֶθ�ֵ������������������,��֤�ɼ���(���
-
this �������ݾͲ���˵�ɼ�����)
��������������Щ�ؼ���ʱ,�������Ӧ���ڴ�����,��֤�������ȷ��
��һ����Ҫע�����,synchronized ����֤ͬ�����ڵĴ����ֹ������,��Ϊ��ͨ������֤ͬһʱ��
ֻ��һ���̷߳���ͬ����(���ٽ���),Ҳ����˵ͬ����Ĵ���ֻ������ as-if-serial ���� - ֻҪ����
�̵�ִ�н�����ı�,���Խ���������
����˵,Java �ڴ�ģ���������Ƕ��̶߳Թ����ڴ��ĺ�˴�֮��Ŀɼ���,����,��ȷ����ȷͬ����
Java ��������ڲ�ͬ��ϵ�ṹ�Ĵ���������ȷ���С�
3. heap ��stack ��ʲô����?
(1)���뷽ʽ
stack:��ϵͳ�Զ�����������,�����ں�����һ���ֲ����� int b; ϵͳ�Զ���ջ��Ϊ b ���ٿռ�
heap:��Ҫ����Ա�Լ�����,��ָ����С,�� c �� malloc ����,����Java ��Ҫ�ֶ� new Object()����ʽ����
(2)�����ϵͳ����Ӧ
stack:ֻҪջ��ʣ��ռ����������ռ�,ϵͳ��Ϊ�����ṩ�ڴ�,�����쳣��ʾջ�����
heap:����Ӧ��֪������ϵͳ��һ����¼�����ڴ��ַ������,��ϵͳ�յ����������ʱ,���������
��,Ѱ�ҵ�һ���ռ����������ռ�Ķѽ��,Ȼ�ý��ӿ��н��������ɾ��,�����ý��Ŀ�
��������������,�����ҵ��Ķѽ��Ĵ�С��һ�����õ�������Ĵ�С,ϵͳ���Զ��Ľ��������
�������·�����������С�
(3)�����������
stack:ջ����͵�ַ��չ�����ݽṹ,��һ���������ڴ����������仰����˼��ջ���ĵ�ַ��ջ����
��������ϵͳԤ�ȹ涨�õ�,�� WINDOWS ��,ջ�Ĵ�С�� 2M(Ĭ��ֵҲȡ���������ڴ�Ĵ�С),
�������Ŀռ䳬��ջ��ʣ��ռ�ʱ,����ʾ overflow�����,�ܴ�ջ��õĿռ��С��
heap:������ߵ�ַ��չ�����ݽṹ,�Dz��������ڴ���������������ϵͳ�����������洢�Ŀ����ڴ�
��ַ��, ��Ȼ�Dz�������,�������ı����������ɵ͵�ַ��ߵ�ַ���ѵĴ�С�����ڼ����ϵͳ����Ч
�������ڴ档�ɴ˿ɼ�, �ѻ�õĿռ�Ƚ����,Ҳ�Ƚϴ�
(4)����Ч�ʵıȽ�
stack:��ϵͳ�Զ�����,�ٶȽϿ���������Ա�������Ƶġ�
heap:�� new ������ڴ�,һ���ٶȱȽ���,�������ײ����ڴ���Ƭ,������������㡣
(5)heap��stack�еĴ洢����
stack:�ں�������ʱ,��һ����ջ�����������к����һ��ָ��(��������������һ����ִ�����)
�ĵ�ַ, Ȼ���Ǻ����ĸ�������,�ڴ������ C ��������,����������������ջ��,Ȼ���Ǻ����еľ�
��������ע�⾲̬�����Dz���ջ�ġ�
�����κ������ý�����,�ֲ������ȳ�ջ,Ȼ���Dz���,���ջ��ָ��ָ���ʼ��ĵ�ַҲ������
�����е���һ��ָ��,�����ɸõ�������С�
heap:һ�����ڶѵ�ͷ����һ���ֽڴ�ŶѵĴ�С�����еľ��������г���Ա���š�
4. ʲô����»ᷢ��ջ�ڴ����?
1��ջ���߳�˽�е�,ջ���������ں��߳�һ��,ÿ��������ִ�е�ʱ��ͻᴴ��һ��ջ֡,�������ֲ�
��������������ջ����̬���ӡ��������ڵ���Ϣ,�ֲ��������ְ��������������ͺͶ��������;
2�����߳������ջ��ȳ����������������������ʱ,���׳�StackOverFlowError�쳣,�����ݹ�
���ÿϿ��ܻ���ָ�����;
3����������-xssȥ����jvmջ�Ĵ�С
5. ̸̸�� OOM ����ʶ?����Ų� OOM ������?
���˳��������,�����ڴ������� OOM �ķ��ա�
-
ջһ�㾭���ᷢ�� StackOverflowError,���� 32 λ�� windows ϵͳ���������� 2G �ڴ�,�������߳̾ͻᷢ��ջ�� OOM
-
Java 8 �������Ƶ�����,������ java.lang.OutOfMemoryError: Java heap space,�������Ԫ �ռ��С������Ч;
-
���ڴ����,����ͬ��,���ֱȽϺ�����,GC ֮�����ڶ��������ڴ洴������ͻᱨ��;
-
������ OOM,�������������Ƕ�̬���ɴ������ࡢjsp ��;
-
ֱ���ڴ� OOM,�漰�� -XX:MaxDirectMemorySize ������ Unsafe ������ڴ�����롣
�Ų� OOM �ķ���:
-
������������ -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof,�� OOM ����ʱ�Զ� dump ���ڴ���Ϣ��ָ��Ŀ¼;
-
ͬʱ jstat �鿴��� JVM ���ڴ�� GC ���,�ȹ۲������ų���ʲô����;
-
ʹ�� MAT �������뵽 dump �ļ�(�ǽ��̵��ڴ澵��),����������ռ�����,���� HashMap ������δ����,ʱ�䳤�˾ͻ��ڴ����,���Ѹ�Ϊ������ ��
6. ̸̸ JVM �еij�����?
JVM��������Ҫ��ΪClass�ļ������ء�����ʱ������,ȫ���ַ���������,�Լ��������Ͱ�װ�� �������ء�
- Class�ļ������ء�class�ļ���һ�����ֽ�Ϊ��λ�Ķ�����������,��java����ı����ڼ�,����
��д��java�ļ��ͱ�����Ϊ.class�ļ���ʽ�Ķ��������ݴ���ڴ�����,���оͰ���class�ļ�����
�ء�
- ����ʱ������:����ʱ�����������class������һ���������Ǿ��ж�̬��,java�淶����Ҫ��
��ֻ��������ʱ�Ų���,Ҳ����˵����ʱ�����ص����ݲ���ȫ������class������,������ʱ����ͨ
���������ɳ����������������ʱ��������,�������Ա��õ����ľ���String.intern()��
- ȫ���ַ���������:�ַ�����������JVM��ά����һ���ַ���ʵ�������ñ�,��HotSpot VM��,
����һ������StringTable��ȫ�ֱ������ַ�����������ά�������ַ���ʵ��������,�ײ�C++ʵ��
����һ��Hashtable����Щ��ά����������ָ���ַ���ʵ��,����������פ�����ַ�������interned
string����ͨ����˵�ġ��������ַ��������ص��ַ�������
- �������Ͱ�װ���������:java�л������͵İ�װ��Ĵֶ�ʵ���˳����ؼ���,��Щ����
Byte,Short,Integer,Long,Character,Boolean,�������ָ��������͵İ�װ����û��ʵ�֡���������
��5�����͵İ�װ��Ҳֻ���ڶ�ӦֵС�ڵ���127ʱ�ſ�ʹ�ö����,Ҳ��������������
��127����Щ��Ķ���
7. ����ж�һ�������Ƿ���?
�ж�һ�������Ƿ���,��Ϊ�����㷨1:���ü�����;2:�ɴ��Է����㷨;
���ü�����:
��ÿһ����������һ�����ü�����,����һ���ط����øö����ʱ��,���ü�������+1,����ʧЧʱ,
���ü�������-1;�����ü�����Ϊ0��ʱ��,��˵���������û�б�����,Ҳ������������,�ȴ�����;
ȱ��:�����ѭ�����õ�����,��A����B,BҲ����A��ʱ��,��ʱAB��������ö���Ϊ0,��ʱҲ��
����������,����һ��������������������������;
�ɴ��Է�����
��һ������ΪGC Roots�Ķ�����������,���һ������GC Rootsû���κ�������������ʱ,˵���˶�
����,��java�п�����ΪGC Roots�Ķ��������¼���:
-
�����ջ�����õĶ���
-
�������ྲ̬�������õı���
-
���������������õĶ���
-
���ط���ջJNI���õĶ���
��һ��������������������ʱ��,�������ϱ�����,����Ҫ�������α��;��һ�α��:�жϵ�ǰ����
�Ƿ���finalize()�������Ҹ÷���û�б�ִ�й�,������������Ϊ��������,�ȴ�����;���еĻ�,��
���еڶ��α��;�ڶ��α�ǽ���ǰ�������F-Queue����,������һ��finalize�߳�ȥִ�и÷���,��
�������֤�÷���һ���ᱻִ��,������Ϊ����߳�ִ�л��������������,�ᵼ�»���ϵͳ�ı���;
���ִ����finalize����֮����Ȼû����GC Roots��ֱ�ӻ���ӵ�����,��ö���ᱻ����;
8. ǿ���á������á������á���������ʲô,��ʲô����?
-
ǿ����,������ͨ�Ķ������ù�ϵ,�� String s = new String(��ConstXiong��)
-
������,����ά��һЩ���п��Ķ���ֻ�����ڴ治��ʱ,ϵͳ�����������ö���,�������
�������ö���֮����Ȼû���㹻���ڴ�,�Ż��׳��ڴ�����쳣��SoftReference ʵ��
- ������,�����������˵,Ҫ��������һЩ,��ӵ�и��̵���������,�� JVM ������������ʱ,��
���ڴ��Ƿ����,������ձ������ù����Ķ���WeakReference ʵ��
- ��������һ����ͬ���������,����ʵ�������õIJ��Ǻܶ�,����Ҫ�������ٶ����������յĻ�
����PhantomReference ʵ��
9. �����õĶ����һ���ܴ����?
��һ��,�� Reference ����,�������� GC ʱ�ᱻ����,���������ڴ治���ʱ��,�� OOM ǰ
�ᱻ����,�����û���� Reference Chain �еĶ����һ���ᱻ���ա�
10. Java�е����������㷨����Щ?
java�����������������㷨,�ֱ��DZ�������������������������㷨���ִ��ռ��㷨;
��������:
��һ��:���ÿɴ���ȥ�����ڴ�,�Ѵ����������������б��;
�ڶ���:�ڱ���һ��,�����б�ǵĶ�����յ�;
�ص�:Ч�ʲ���,��Ǻ������Ч�ʶ�����;��Ǻ���������������IJ������Ŀռ��Ƭ,���ܻᵼ
��֮��������е�ʱ�������������Ҳ���������Ƭ�����ò�����һ��GC;
���������:
��һ��:���ÿɴ���ȥ�����ڴ�,�Ѵ����������������б��;
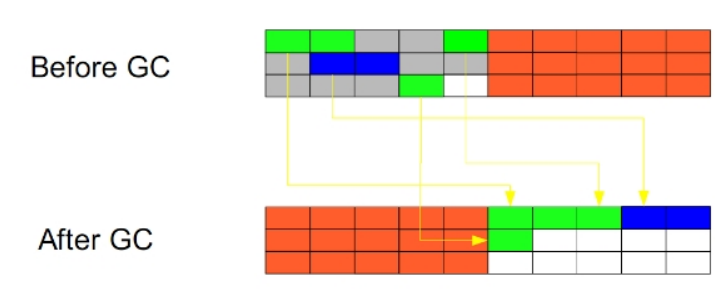
�ڶ���:�����еĴ��Ķ�����һ���ƶ�,���˱߽�����Ķ����յ�;
�ص�:�����ڴ������,�����ٵ����;��Ҫ�����Ĺ���,�ռ���Ƭ����;
�����㷨:
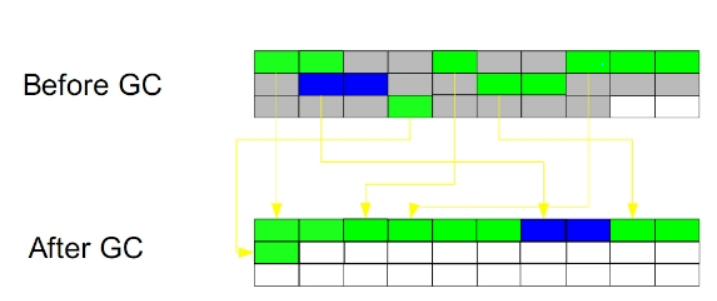
���ڴ水��������С��Ϊ��С��ȵ�����,ÿ��ֻʹ��һ��,��һ��ʹ������,�ͽ������Ķ����Ƶ�
��һ����,Ȼ���ڰ�ʹ�ù����ڴ�ռ��Ƴ�;(����from����to��Ȼ����ǿ�һ������ʹ��)
�ص�:��������ռ���Ƭ;�ڴ�ʹ���ʼ���;
�ִ��ռ��㷨:(��ʵ����е��������εĶ���)
�����ڴ����Ĵ�����ڲ�ͬ,���ڴ滮�ֳɼ���,java�����һ�㽫�ڴ�ֳ���������������,����
������,�д���������ȥ������������,���Բ��ø����㷨,ֻ��Ҫ��������������ĸ��Ƴɱ���
��������ռ�;���������Ϊ����Ĵ���ʼ���,û�ж���Ŀռ�������з��䵣��,���Բ��ñ����
�����߱�������㷨���л���;
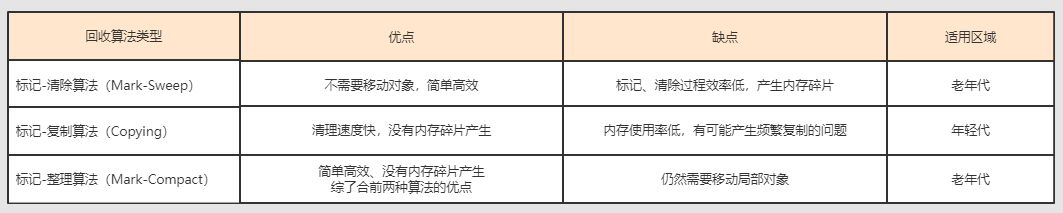
11. ���ļ�������������,���Ե���ȱ����ʲô?
-
Serial(����GC)-����
��������ص����ڽ�����������ʱ,��Ҫ����������ִ�е��߳���ͣ(stop the world),������ЩӦ�������Խ��ܵ�,�������Ӧ�õ�ʵʱ��Ҫ������ô��,ֻҪͣ�ٵ�ʱ�������N����֮��,�����Ӧ�û��ǿ��Խ��ܵ�,
-
ParNew(����GC)-����
Serial�ռ����Ķ��̰߳汾,Ҳ��Ҫstop the world
-
Parallel Scavenge(�����GC)-����
��ParNew�����������GC�Զ����ڲ���;����������ϵͳ������״̬�ռ����ܼ����Ϣ,��̬������Щ����,���ṩ����ͣ��ʱ�����ߵ�������
-
Serial Old(MSC)(����GC)-���-����
Serial�ռ�����������汾,���߳��ռ���,ʹ�ñ�������㷨��
-
Parallel Old(����GC)�C���-����
��Parallel Scavenge�ռ�����������汾,ʹ�ö��߳�,���-�����㷨��
-
CMS(����GC)-���-���
��һ���Ի����̻���ͣ��ʱ��ΪĿ����ռ���,�������㷨,��������:��ʼ���,�������,���±��,�������,�ռ���������������ռ���Ƭ;
-
G1(JDK1.7update14�ſ�����ʽ����)-���-����
����������Ҫ��������:��ʼ���,�������,���ձ��,ɸѡ��������������ռ���Ƭ,���Ծ�ȷ�ؿ���ͣ��;G1�������ѷ�Ϊ��С��ȵĶ��Region(����),G1����ÿ�������������С,�ں�̨ά��һ�����ȼ��б�,ÿ�θ����������ռ�ʱ��,���Ȼ��ռ�ֵ��������,�Ѵﵽ������ʱ���ڻ�ȡ�����ܸߵĻ���Ч��;
˵��:
- 1~3�����������������:��������������ճ�Ϊminor GC
- 4~6�������ϴ���������(��ȻҲ�������ڷ������Ļ���):���ϴ����������ճ�Ϊfull GC
- G1�������"�ִ���������"
ע��:�����벢��
- ����:�������������߳�ͬʱ����
- ����:���������߳����û��߳�һ�����
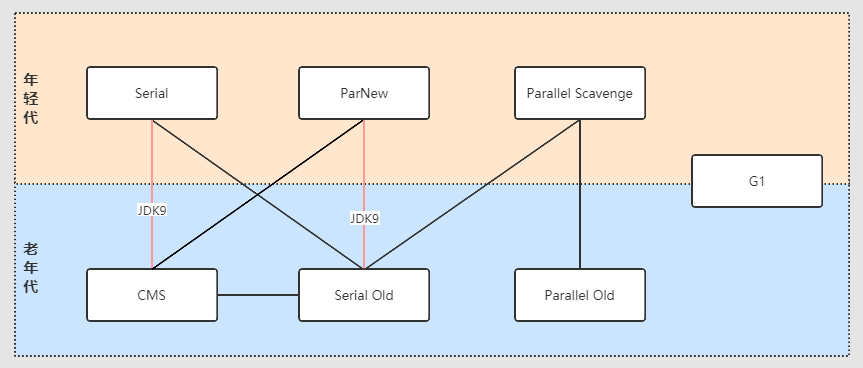
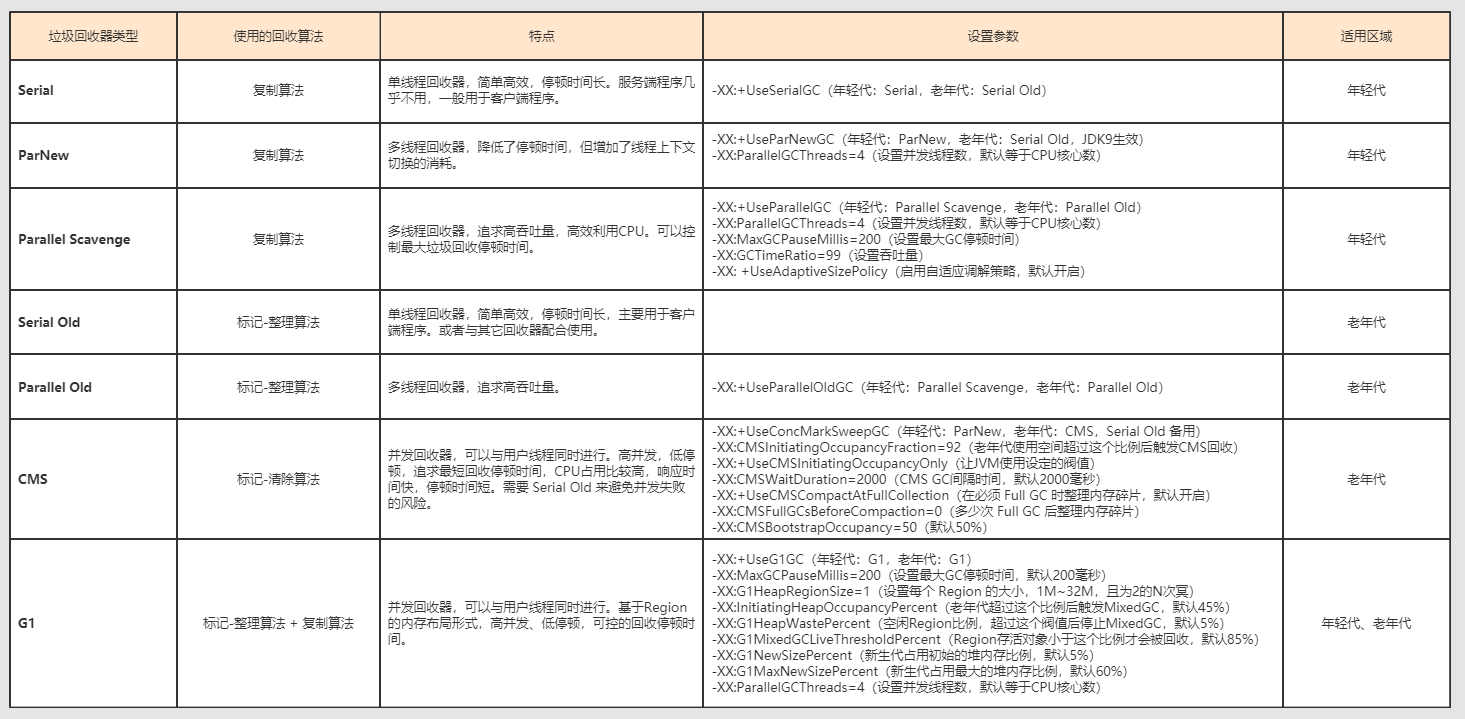
���������������Ա�:
12. ��ϸ˵һ��CMS�Ļ��չ���?CMS��������ʲô?
CMS(Concurrent Mark Sweep,����������) �ռ������Ի�ȡ��̻���ͣ��ʱ��ΪĿ����ռ���(
���ͣ��),���������ռ�ʱʹ���û��̺߳� GC �̲߳���ִ��,����������ռ��������û�Ҳ�����
�����ԵĿ��١�
�����־Ϳ���֪��,CMS�ǻ��ڡ����-������㷨ʵ�ֵġ�CMS ���չ��̷�Ϊ�����IJ�:
- ��ʼ��� (CMS initial mark):��Ҫ�DZ�� GC Root ��ʼ���¼�(ע:����һ��)����,�����
�̻� STW,���Ǹ� GC Root ֱ�ӹ������¼�����ܶ�,������������ʵ�ܿ졣
- ������� (CMS concurrent mark):������һ���Ľ��,�������±�ʶ���й����Ķ���,ֱ������
**���ϵ��ͷ����������Ƕ��̵߳�,**��Ȼ��ʱ�����ϻ�Ƚϳ�,�������������̲߳���������,
û�� STW��
- ���±��(CMS remark):����˼��,����Ҫ�ٱ��һ�Ρ�Ϊɶ��Ҫ�ٱ��һ��?��Ϊ�� 2 ����
û���������������߳�,�����߳��ڱ�ʶ������,���п��ܻ�����µ�������
- �������(CMS concurrent sweep):�����������ɾ������ǽ��жϵ��Ѿ������Ķ���,
���ڲ���Ҫ�ƶ�������,���������Ҳ�ǿ������û��߳�ͬʱ�������еġ�
CMS ������:
1. �������յ���CPU��Դ����:
�ڲ�����,����Ȼ���ᵼ���û��߳�ͣ��,��ȴ����Ϊռ����һ�����̶߳�����Ӧ�ó������,����
��������������CMSĬ�������Ļ����߳�����:(CPU���� + 3)/ 4,��CPU���������ĸ�ʱ,CMS��
�û������Ӱ��Ϳ��ܱ�úܴ�
2. ��������������:
��CMS�IJ�����ǺͲ���������,�û��̻߳��ڼ�������,�ͻ���������µ��������ϲ���,��
��һ�������������dz����ڱ�ǹ��̽����Ժ�,CMS���ڵ����ռ��д���������,ֻ��������һ����
���ռ�ʱ������������һ����������Ϊ��������������
3. ����ʧ��(Concurrent Mode Failure):
�������������ս��û��̻߳��ڲ�������,�Ǿͻ���ҪԤ���㹻���ڴ�ռ��ṩ���û��߳�ʹ��,��
��CMS���������������������ȵ������������ȫ���������ٽ��л���,����Ԥ��һ���ֿռ乩������
��ʱ�ij�������ʹ�á�Ĭ�������,�������ʹ���� 92% �Ŀռ��ͻᴥ�� CMS ��������,���ֵ��
��ͨ�� -XX: CMSInitiatingOccupancyFraction ���������á�
�������һ������:Ҫ��CMS�����ڼ�Ԥ�����ڴ��������������¶������Ҫ,�ͻ����һ�Ρ�����
ʧ�ܡ�(Concurrent Mode Failure),��ʱ������������ò�������Ԥ��:Stop The World,��ʱ��
�� Serial Old �����½������������������,����һ��ͣ��ʱ��ͺܳ��ˡ�
**4.**�ڴ���Ƭ����:
**CMS��һ����ڡ����-������㷨ʵ�ֵĻ�����,����ζ�Ż��ս���ʱ�����ڴ���Ƭ������**�ڴ���Ƭ����
ʱ,�����������������鷳,�����������������кܶ�ʣ��ռ�,���������ҵ��㹻�������
�ռ������䵱ǰ����,�����ò���ǰ����һ�� Full GC �������
Ϊ�˽���������,CMS�ռ����ṩ��һ�� -XX:+UseCMSCompactAtFullCollection ���ز���(Ĭ�Ͽ�
��),������ Full GC ʱ�����ڴ���Ƭ�ĺϲ���������,��������ڴ����������ƶ�������,����
������,����ͣ��ʱ��ͻ�䳤����������һ������ -XX:CMSFullGCsBeforeCompaction,���������
������Ҫ��CMS��ִ�й����ɴβ������ռ�� Full GC ֮��,��һ�ν��� Full GC ǰ���Ƚ�����Ƭ����
(Ĭ��ֵΪ0,��ʾÿ�ν��� Full GC ʱ��������Ƭ����)��
13. ��ϸ˵һ��G1�Ļ��չ���?
G1(Garbage First)��������������ֲ��ռ������˼·������Region���ڴ沼����ʽ,��һ����Ҫ
��������Ӧ�õ�������������G1��Ƴ��Ծ����滻 CMS,��Ϊһ��ȫ�����ռ�����G1 ��JDK9 ֮��
��Ϊ�����ģʽ�µ�Ĭ������������,ȡ���� Parallel Scavenge �� Parallel Old ��Ĭ�����,�� CMS
������Ϊ���Ƽ�ʹ�õ�������������G1�����������ǻ��� ���-���� �㷨ʵ�ֵĻ�����,���Ӿֲ�(��
��Region֮��)�Ͽ����ǻ��� ���-���� �㷨ʵ�ֵġ�
G1 ���չ���,G1 ���������������̴��¿ɷ�Ϊ�ĸ�����:
-
��ʼ���(��STW(������ִ�е��߳���ͣ)):����ֻ�DZ��һ�� GC Roots ��ֱ�ӹ������Ķ���,������TAMSָ���ֵ,����һ���û��̲߳�������ʱ,����ȷ���ڿ��õ�Region�з����¶����������Ҫͣ���߳�,����ʱ�ܶ�,�����ǽ��ý���Minor GC��ʱ��ͬ����ɵ�,����G1�ռ����������ʵ�ʲ�û�ж����ͣ�١�
-
�������:�� GC Roots ��ʼ�Զ��ж�����пɴ��Է���,�ݹ�ɨ����������Ķ���ͼ,�ҳ�Ҫ���յĶ���,��κ�ʱ�ϳ�,�������û�����ִ�С�������ͼɨ������Ժ�,��Ҫ���´����ڲ���ʱ�����ñ䶯�Ķ���
-
���ձ��(��STW):���û��߳������ݵ���ͣ,���������ν������������ñ䶯�Ķ���
-
������(��STW):����Region��ͳ������,�Ը���Region�Ļ��ռ�ֵ�ͳɱ���������,�����û���������ͣ��ʱ�����ƶ����ռƻ���������ѡ��������Region���ɻ��ռ�,Ȼ��Ѿ������յ���һ����Region�Ĵ������Ƶ��յ�Region��,��������������Region��ȫ���ռ䡣����IJ����漰��������ƶ�,������ͣ�û��߳�,�ɶ����������̲߳�����ɵ�
14.JVM��һ��������GC��ʲô���ӵ�?
������һ��Java���ڴ滮�֡�
�� Java ��,�ѱ����ֳ�������ͬ������:������ ( Young )������� ( Old ),������Ĭ��ռ�ܿռ��
1/3,�����Ĭ��ռ 2/3��
�������� 3 ������:Eden��To Survivor��From Survivor,���ǵ�Ĭ��ռ���� 8:1:1��
����������������(�ֳ�Minor GC)��ֻ������������,����ѡ�ø����㷨,ֻ��Ҫ�����ĸ��Ƴɱ�
�Ϳ�����ɻ��ա�
���������������(�ֳ�Major GC)ͨ��ʹ�á����-���������-�������㷨��
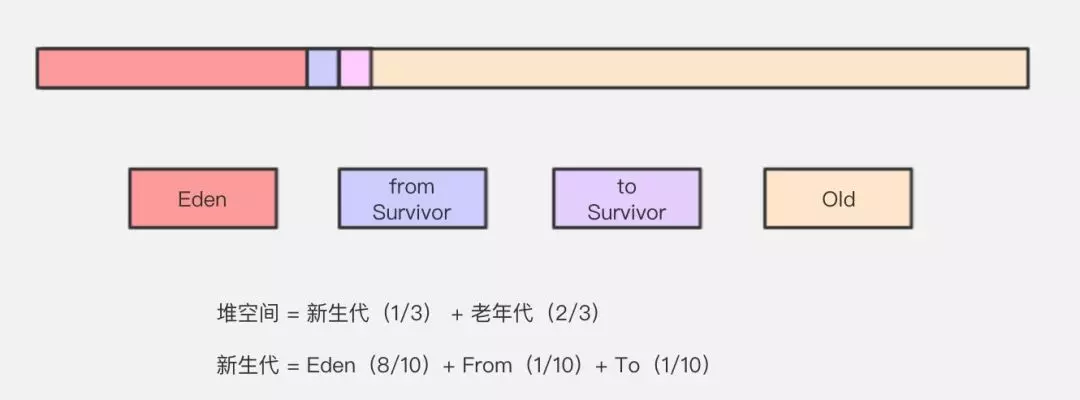
����������֮��ת������:
- ����������Eden���䡣�� eden ��û���㹻�ռ���з���ʱ,�����������һ�� Minor GC��
- �� Eden ��ִ���˵�һ�� GC ֮��,���Ķ���ᱻ�ƶ�������һ�� Survivor ����;
- Eden ���ٴ� GC,��ʱ����ø����㷨,�� Eden �� from ��һ������,���Ķ���ᱻ���Ƶ� to ��;
- �ƶ�һ��,��������� 1,�����������һ����ֵ��ֱ���ƶ����������GC����ķ�ֵ����ͨ������ -XX:MaxTenuringThreshold ����,Ĭ��Ϊ 15;
- ��̬���������ж�:Survivor ����ͬ�������ж����С���ܺ� > (Survivor ���ڴ��С * ���Ŀ��ʹ����)ʱ,���ڻ���ڸ�����Ķ���ֱ�ӽ�����������������ʹ����ͨ�� -XX:TargetSurvivorRatio ָ��,Ĭ��Ϊ 50%;
- Survivor ���ڴ治��ᷢ����������,����ָ����С�Ķ������ֱ�ӽ����������
- �����ֱ�ӽ��������,����������Ҫ���������ڴ�ռ�Ķ���(����:�ַ���������),Ϊ�˱���Ϊ���������ڴ�ʱ���ڷ��䵣�����ƴ����ĸ��ƶ�����Ч�ʡ�
- ��������˶������ɸ���Ķ���,Minor GC ֮��ͨ���ͻ����Full GC,Full GC ���������ڴ�� �C ����������������
15. Minor GC �� Full GC ��ʲô��ͬ��?
Minor GC:ֻ�ռ���������GC��
Full GC: �ռ�������,���� ������,�����,���ô��� JDK 1.8���Ժ�,���ô����Ƴ�,��Ϊmetaspace Ԫ�ռ�)�����в��ֵ�ģʽ��
Minor GC��������:��Eden����ʱ,����Minor GC��
Full GC��������:
- ͨ��Minor GC������������ƽ����С����������Ŀ����ڴ����������ͳ������˵֮ǰMinor
GC��ƽ��������С��Ŀǰold genʣ��Ŀռ��,�ᴥ��Minor GC����תΪ����full GC��
- ������ռ䲻�������µ��ڴ�(�����ô��ռ䲻��,��ֻ��JDK1.7�е�,��Ҳ����Ԫ�ռ���ȡ����
�ô���ԭ��,���Լ���Full GC��Ƶ��,����GC����,������Ч��)
- ��Eden����From Space����To Space������ʱ,�����С����To Space�����ڴ�,��Ѹö���ת
�浽�����,��������Ŀ����ڴ�С�ڸö����С��
- ����System.gcʱ,ϵͳ����ִ��Full GC,���Dz���Ȼִ��
16. �����¿ռ���䵣��ԭ��?
���YougGCʱ�������д�������������,�� survivor ���Ų�����,��ʱ����ת�Ƶ��������,����
ʱ���������Ҳ�Ų�����Щ������,����ô������?��ʵJVM��һ��������ռ���䵣����������֤��
���ܹ������������
��ִ��ÿ�� YoungGC ֮ǰ,JVM���ȼ������������������ռ��Ƿ�������������ж�����ܴ�С��
��Ϊ�ڼ��������,���������� YoungGC ��,���ж����������,�� survivor ���ַŲ���,�ǿ�
�����ж���Ҫ����������ˡ����ʱ�����������Ŀ��������ռ��Ǵ������������ж�����ܴ�С
��,�ǾͿ��Է��Ľ��� YoungGC���������������ڴ��С��С�������������ܴ�С��,�Ǿ��п�����
����ռ䲻���������������д�����,���ʱ��JVM�ͻ��ȼ�� -XX:HandlePromotionFailure ������
����������ʧ��,�������,�ͻ��ж�����������������ռ��Ƿ�������ν���������������ƽ��
��С,�������,�����Խ���һ��YoungGC,�������YoungGC���з��յ����С��,���� -
XX:HandlePromotionFailure ��������������ʧ��,��ʱ�ͻ����һ�� Full GC��
����������ʧ�ܲ����Խ���YoungGC��,���ܻ�����������:
-
�� YoungGC��,������С��survivor��С,��ʱ���������survivor����
-
�� YoungGC��,���������survivor��С,����С���������ÿռ��С,��ʱֱ�ӽ�������
����
- �� YoungGC��,���������survivor��С,Ҳ�����������ÿռ��С,�����Ҳ�Ų�����Щ
������,��ʱ�ͻᷢ����Handle Promotion Failure��,�ʹ����� Full GC����� Full GC��,�����
����û���㹻�Ŀռ�,��ʱ�ͻᷢ��OOM�ڴ�����ˡ�
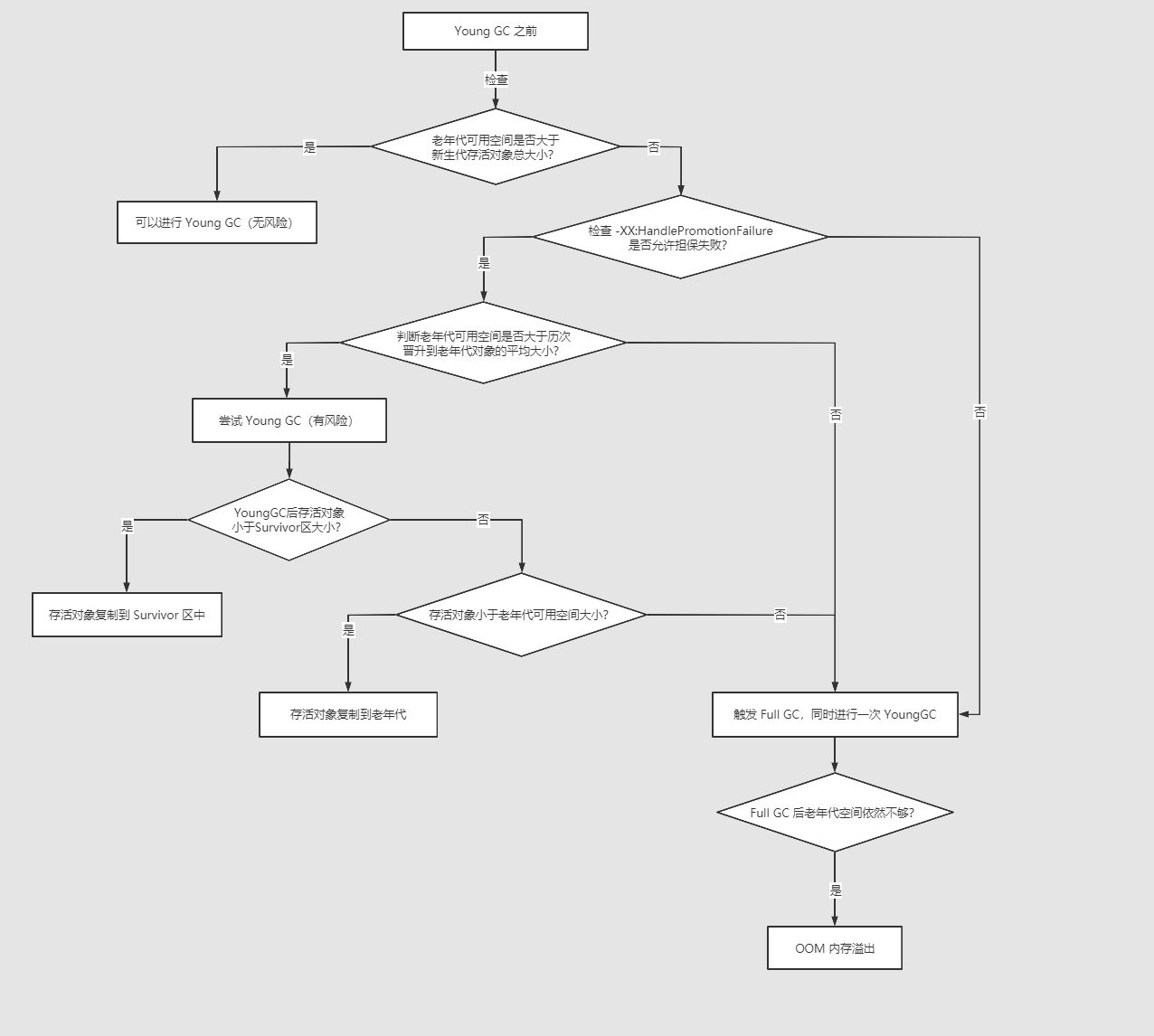
17. ʲô�������?����صĹ���?
�����������������ݼ��ص��ڴ�����,�������ݽ���У�顢�����ͳ�ʼ��,���ձ�ɿ��Ա������ֱ��ʹ�õ�class����;
��������������ڰ���:����(Loading)����֤(Verification)����(Preparation)������(Resolution)����ʼ��(Initialization)��ʹ��(Using)��ж��(Unloading)7���Ρ�����������֤������3������ͳ��Ϊ����(Linking)����ͼ��ʾ:
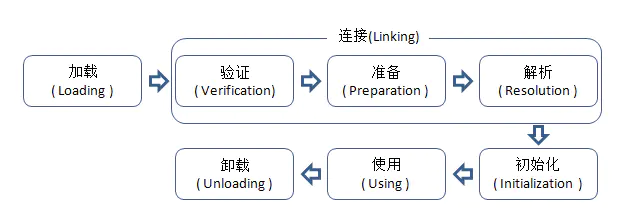
���ء���֤��������ʼ����ж����5���ε�˳����ȷ����,��ļ��ع��̱��밴������˳���Ͱ�ؿ�ʼ,����������һ��:����ijЩ����¿����ڳ�ʼ����֮���ٿ�ʼ,����Ϊ��֧��Java���Ե�����ʱ��(Ҳ��Ϊ��̬�����ڰ�)
����ع�������:
-
����,���ط�Ϊ����:
1��ͨ�����ȫ����������ȡ����Ķ�������;
2�����ö��������ľ�̬�洢�ṹתΪ������������ʱ���ݽṹ;
3���ڶ���Ϊ��������һ��class����;
-
��֤:��֤��class�ļ��е��ֽ�����Ϣ�����������Ҫ��,������в��jvm�İ�ȫ;
-
��:Ϊclass����ľ�̬���������ڴ�,��ʼ�����ʼֵ;
-
����:�ý���Ҫ��ɷ�������ת����ֱ������;
-
��ʼ��:���˳�ʼ����,�ſ�ʼִ�����ж����java����;��ʼ�����ǵ���������Ĺ���;
18. ʲô���������,�����������������Щ?
���������ָ:ͨ��һ�����ȫ����������ȡ����Ķ������ֽ��������������;���������Ϊ����
����:
-
�����������(BootStrapClassLoader):��������java�������,����java����ֱ������;
-
��չ�������(Extension ClassLoader):��������java����չ��,java�������ʵ�ֻ��ṩһ��
��չ��Ŀ¼,�������������չ��Ŀ¼������Ҳ�����java��;
-
ϵͳ�������(AppClassLoader):������java����·����������,һ����˵,javaӦ�õ����ͨ���������ص�;
-
�Զ����������:��java����ʵ��,�̳���ClassLoader;
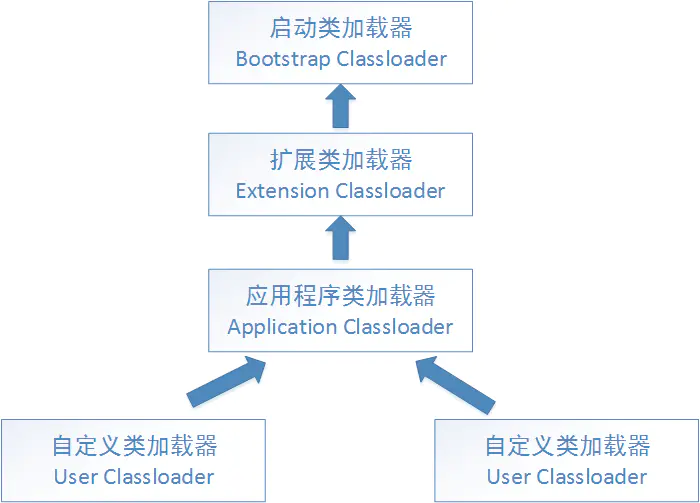
19. ʲô��˫��ί��ģ��?Ϊʲô��Ҫ˫��ί��ģ��?
��һ����������յ�һ������ص�����,�����Ȳ��᳢���Լ�ȥ����,���ǽ��������ί�ɸ��������
��ȥ����,ֻ�и�����������Լ���������Χ����Ҳ�������ʱ,�Ӽ������Ż᳢���Լ�ȥ���ظ���;
Ϊ�˷�ֹ�ڴ��г��ֶ����ͬ���ֽ���;��Ϊ���û��˫��ί�ɵĻ�,�û��Ϳ����Լ�����һ��
java.lang.String��,��ô������֤���Ψһ��
����:����ô����˫��ί��ģ��?
�Զ����������,�̳�ClassLoader��,��дloadClass������findClass����
20. �о�һЩ��֪���Ĵ���˫��ί�ɻ��Ƶ�����,ΪʲôҪ����?
-
JNDI ͨ�������߳��������������,������ Thread.setContextClassLoader ��������,Ĭ����Ӧ
�ó����������,������ SPI �Ĵ��롣�����߳��������������,�Ϳ�����ɸ����������������
�������������ص���Ϊ�����Ƶ�ԭ��,��Ϊ�� JNDI �������������������������,Ϊ�����
����������������������(�������е��߳������ļ�����)�����ࡣ
-
Tomcat,Ӧ�õ���������������м���Ӧ��Ŀ¼�µ� class,��������ί�ɸ���������,���ز���
��ί�ɸ�����������
tomcat֮��������һ���Լ���classloader,�����dz�����������Ŀ��:
-
���ڸ��� webapp �е� class �� lib ,��Ҫ�����,���ܳ���һ��Ӧ���м��ص�����Ӱ����һ��Ӧ�õ����,����������Ӧ��,��Ҫ�й�����lib�Ա㲻�˷���Դ��
-
�� jvm һ���İ�ȫ�����⡣ʹ�õ����� classloader ȥװ�� tomcat ���������,�������������������ƻ�;
-
�Ȳ���
tomcat�����������ͼ:
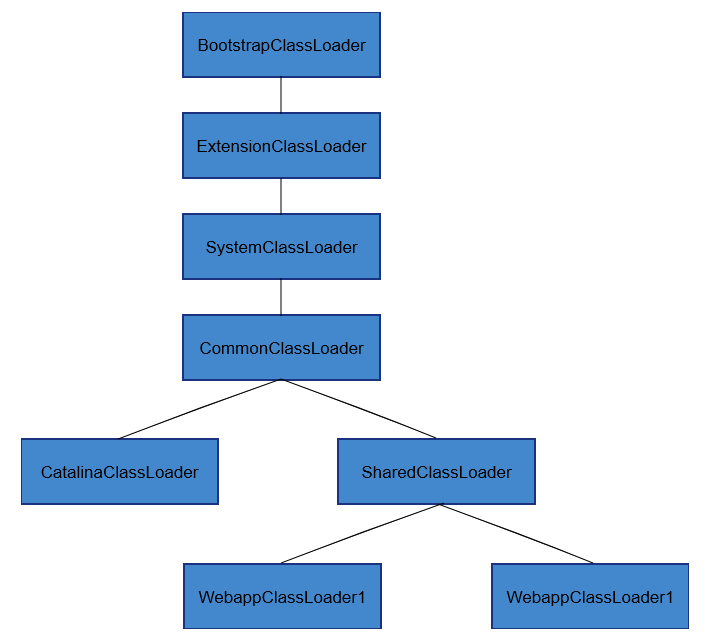
-
-
OSGi,ʵ��ģ�黯�Ȳ���,Ϊÿ��ģ�鶼�Զ������������,��Ҫ����ģ��ʱ,ģ�����������һ
�������������صĹ�����,��ƽ�����������������Ϊ�����Ƶ�ԭ����Ϊ��ʵ��ģ�����滻��
- JDK 9,Extension ClassLoader �� Platform ClassLoader ȡ��,��ƽ̨��Ӧ�ó�����������յ�
���������,��ί�ɸ�������������ǰ,Ҫ���жϸ����Ƿ��ܹ�������ijһ��ϵͳģ����,�����
���ҵ������Ĺ�����ϵ,��Ҫ����ί�ɸ������Ǹ�ģ��ļ�������ɼ��ء����Ƶ�ԭ��,��Ϊ����
��ģ�黯�����ԡ�
21.˵һ�� JVM ���ŵ�����?
-
jps:JVM Process Status Tool,��ʾָ��ϵͳ�����е�HotSpot��������̡�
-
jstat:jstat(JVM statistics Monitoring)�����ڼ������������ʱ״̬��Ϣ������,��������ʾ����
��������е���װ�ء��ڴ桢�����ռ���JIT������������ݡ�
jmap:jmap(JVM Memory Map)������������heap dump�ļ�,�����ʹ���������,������ʹ
��-XX:+HeapDumpOnOutOfMemoryError�����������������OOM��ʱ���Զ�����dump��
����
- jmap����������dump�ļ�,�����Բ�ѯfinalizeִ�ж��С�Java�Ѻ����ô�����ϸ��Ϣ,�統ǰʹ
���ʡ���ǰʹ�õ��������ռ����ȡ�
- jhat:jhat(JVM Heap Analysis Tool)��������jmap����ʹ��,��������jmap���ɵ�dump,jhat��
����һ���͵�HTTP/HTML������,����dump�ķ��������,������������в鿴���ڴ�Ҫע
��,һ�㲻��ֱ���ڷ������Ͻ��з���,��Ϊjhat��һ����ʱ���Һķ�Ӳ����Դ�Ĺ���,һ��ѷ�
�������ɵ�dump�ļ����Ƶ����ػ����������Ͻ��з�����
- jstack:jstack��������java�������ǰʱ�̵��߳̿��ա�jstack���鿴�����̵߳ĵ��ö�ջ,�Ϳ�
��֪��û����Ӧ���̵߳����ں�̨��ʲô����,���ߵȴ�ʲô��Դ�� ���java�����������core��
��,jstack���߿����������core�ļ���java stack��native stack����Ϣ,�Ӷ��������ɵ�֪��
java��������α������ڳ���δ��������⡣
�ġ�Java����
���̻߳���
1. �̺߳ͽ�����ʲô����?
�߳̾������ഫͳ���������е�����,���ֳ�Ϊ���ͽ���(Light��Weight Process)�����Ԫ;���Ѵ�ͳ�Ľ��̳�Ϊ���ͽ���(Heavy��Weight Process),���൱��ֻ��һ���̵߳��������������̵߳IJ���ϵͳ��,ͨ��һ�����̶������ɸ��߳�,���ٰ���һ���̡߳�
-
��������:�����Dz���ϵͳ��Դ����Ļ�����λ,���߳��Ǵ�����������Ⱥ�ִ�еĻ�����λ
-
��Դ����:ÿ�����̶��ж����Ĵ�������ݿռ�(����������),����֮����л����нϴ�Ŀ���;�߳̿��Կ����������Ľ���,ͬһ���̹߳�����������ݿռ�,ÿ���̶߳����Լ�����������ջ�ͳ��������(PC),�߳�֮���л��Ŀ���С��
-
������ϵ:���һ���������ж���߳�,��ִ�й��̲���һ���ߵ�,���Ƕ�����(�߳�)��ͬ��ɵ�;�߳��ǽ��̵�һ����,�����߳�Ҳ����Ϊ��Ȩ���̻������������̡�
-
�ڴ����:ͬһ���̵��̹߳��������̵ĵ�ַ�ռ����Դ,������֮��ĵ�ַ�ռ����Դ���������
-
Ӱ���ϵ:һ�����̱�����,�ڱ���ģʽ�²�����������̲���Ӱ��,����һ���̱߳����������̶����������Զ����Ҫ�ȶ��߳̽�׳��
-
ִ�й���:ÿ�������Ľ����г������е����. ˳��ִ�����кͳ�����ڡ������̲߳��ܶ���ִ��,����������Ӧ�ó�����,��Ӧ�ó����ṩ����߳�ִ�п���,���߾��ɲ���ִ��
2. �����̵߳����ַ�ʽ�ĶԱ�?
1)����ʵ��Runnable. Callable�ӿڵķ�ʽ�������̡߳�
������:
�߳���ֻ��ʵ����Runnable�ӿڻ�Callable�ӿ�,�����Լ̳���������
�����ַ�ʽ��,����߳̿��Թ���ͬһ��target����,���Էdz��ʺ϶����ͬ�߳�������ͬһ����Դ�����,�Ӷ����Խ�CPU. ��������ݷֿ�,�γ�������ģ��,�Ϻõ���������������˼�롣
������:
���������,���Ҫ���ʵ�ǰ�߳�,�����ʹ��Thread.currentThread()������
package com.itheima.d1_create;
/**
Ŀ��:ѧ���̵߳Ĵ�����ʽ��,����������ȱ�㡣
*/
public class ThreadDemo2 {
public static void main(String[] args) {
// 3������һ���������
Runnable target = new MyRunnable();
// 4�����������Thread����
Thread t = new Thread(target);
// Thread t = new Thread(target, "1��");
// 5�������߳�
t.start();
for (int i = 0; i < 10; i++) {
System.out.println("���߳�ִ�����:" + i);
}
}
}
/**
1������һ���߳������� ʵ��Runnable�ӿ�
*/
class MyRunnable implements Runnable {
/**
2����дrun����,�����̵߳�ִ�������
*/
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("���߳�ִ�����:" + i);
}
}
}
2)ʹ�ü̳�Thread��ķ�ʽ�������߳�
������:
��д��,�����Ҫ���ʵ�ǰ�߳�,������ʹ��Thread.currentThread()����,ֱ��ʹ��this���ɻ�õ�ǰ�̡߳�
������:
�߳����Ѿ��̳���Thread��,���Բ����ټ̳�����������
/**
Ŀ��:���̵߳Ĵ�����ʽһ:�̳�Thread��ʵ�֡�
*/
public class ThreadDemo1 {
public static void main(String[] args) {
// 3��newһ�����̶߳���
Thread t = new MyThread();
// 4������start���������߳�(ִ�еĻ���run����)
t.start();
for (int i = 0; i < 5; i++) {
System.out.println("���߳�ִ�����:" + i);
}
}
}
/**
1������һ���߳���̳�Thread��
*/
class MyThread extends Thread{
/**
2����дrun����,�����Ƕ����߳��Ժ�Ҫ��ɶ
*/
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println("���߳�ִ�����:" + i);
}
}
}
3)Runnable��Callable������
-
Callable�涨(��д)�ķ�����call(),Runnable�涨(��д)�ķ�����run()��
-
Callable������ִ�к�ɷ���ֵ,��Runnable�������Dz��ܷ���ֵ�ġ�
-
Call���������׳��쳣,run���������ԡ�
-
����Callable��������õ�һ��Future����,��ʾ�첽����Ľ�������ṩ�˼������Ƿ���ɵķ���,�Եȴ���������,����������Ľ����ͨ��Future��������˽�����ִ�����,��ȡ�������ִ��,���ɻ�ȡִ�н����
3. ΪʲôҪʹ�ö��߳���**?**
-
�Ӽ�����ײ���˵: �߳̿��Ա������������Ľ���,�dz���ִ�е���С��λ,�̼߳���л��͵��� �ijɱ�ԶԶС�ڽ���������,��� CPU ʱ����ζ�Ŷ���߳̿���ͬʱ����,��������߳��������л��Ŀ�����
-
�ӵ�����������չ������˵: ���ڵ�ϵͳ��������Ҫ���������ǧ�IJ�����,�����̲߳� ��������ǿ����߲���ϵͳ�Ļ���,���úö��̻߳��ƿ��Դ�����ϵͳ����IJ��������Լ����ܡ�
4. �̵߳�״̬��ת
�̵߳��������ڼ����ֻ���״̬:
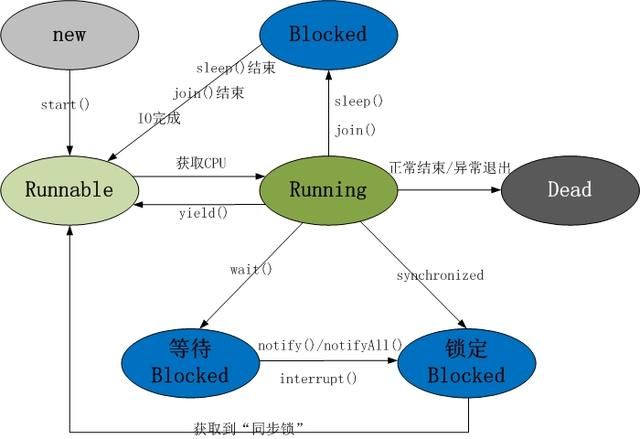
Java�߳̾������ֻ���״̬
1)�½�״̬(New):���̶߳���Դ�����,���������½�״̬,��:Thread t = new MyThread();
2)����״̬(Runnable):�������̶߳����start()����(t.start();),�̼߳��������״̬�����ھ���״̬���߳�,ֻ��˵�����߳��Ѿ���������,��ʱ�ȴ�CPU����ִ��,������˵ִ����t.start()���߳������ͻ�ִ��;
3)����״̬(Running):��CPU��ʼ���ȴ��ھ���״̬���߳�ʱ,��ʱ�̲߳ŵ�������ִ��,�����뵽����״̬��ע:����״̬�ǽ��뵽����״̬��Ψһ���,Ҳ����˵,�߳�Ҫ���������״ִ̬��,���ȱ��봦�ھ���״̬��;
4)����״̬(Blocked):��������״̬�е��߳�����ij��ԭ��,��ʱ������CPU��ʹ��Ȩ,ִֹͣ��,��ʱ��������״̬,ֱ������뵽����״̬,�� �л����ٴα�CPU�����Խ��뵽����״̬����������������ԭ��ͬ,����״̬�ֿ��Է�Ϊ����:
1.�ȴ�����:����״̬�е��߳�ִ��wait()����,ʹ���߳̽��뵽�ȴ�����״̬;
2.ͬ������ �� �߳��ڻ�ȡsynchronizedͬ����ʧ��(��Ϊ���������߳���ռ��),�������ͬ������״̬;
3.�������� �� ͨ�������̵߳�sleep()��join()����I/O����ʱ,�̻߳���뵽����״̬����sleep()״̬��ʱ. join()�ȴ��߳���ֹ���߳�ʱ. ����I/O�������ʱ,�߳�����ת�����״̬��
5)����״̬(Dead):�߳�ִ�����˻������쳣�˳���run()����,���߳̽����������ڡ�
5. ʲô���߳�����?��α�������?
����
- ����߳�ͬʱ������,�����е�һ������ȫ�����ڵȴ�ij����Դ���ͷš������̱߳������ڵ�����,��˳�����������ֹ��

��������߱������ĸ�����:
-
��������:����Դ����һ��ʱ��ֻ��һ���߳�ռ�á�
-
�����뱣������:һ��������������Դ������ʱ,���ѻ�õ���Դ���ֲ��š�
-
����������:�߳��ѻ�õ���Դ��ĩʹ����֮ǰ���ܱ������߳�ǿ�а���,ֻ���Լ�ʹ����Ϻ���ͷ���Դ��
-
ѭ���ȴ�����:���ɽ���֮���γ�һ��ͷβ��ӵ�ѭ���ȴ���Դ��ϵ��
��α����߳�����**?**
ֻҪ�ƻ������������ĸ������е�����һ���Ϳ�����
-
�ƻ���������
�����������û�а취�ƻ�,��Ϊ�����������������������ǻ����(�ٽ���Դ��Ҫ�������)
-
�ƻ������뱣������
һ�����������е���Դ��
-
�ƻ�����������
ռ�ò�����Դ���߳̽�һ������������Դʱ,������벻��,���������ͷ���ռ�е���Դ��
-
�ƻ�ѭ���ȴ�����
������������Դ��Ԥ������ijһ˳��������Դ,�ͷ���Դ�����ͷš��ƻ�ѭ���ȴ�������
-
������:(����ش�����ĵ�)
ָ����ȡ����˳��,����ij���߳�ֻ�л��A����B��,���ܶ�ij��Դ���в���,�ڶ��߳�������,��α�������?
ͨ��ָ�����Ļ�ȡ˳��,����涨,ֻ�л��A�����̲߳����ʸ��ȡB��,��˳���ȡ���Ϳ��Ա�����������ͨ������Ϊ�ǽ�������ܺõ�һ�ַ�����
-
ʹ����ʽ���е�ReentrantLock.try(long,TimeUnit)��������
6. �����ĶԱ�
Runnable VS Callable
-
Callable���� Java 1.5 ������,Ŀ�ľ���Ϊ��������Runnable��֧�ֵ�������Callable �ӿڿ��Է��ؽ�����׳�����쳣
-
Runnable �ӿڲ��᷵�ؽ�����׳�����쳣,
-
���������Ҫ���ؽ�����׳��쳣�Ƽ�ʹ�� Runnable�ӿ�,�������뿴��������Ӽ��
-
������ Executors ����ʵ�� Runnable ����� Callable ����֮����ת����
(Executors.callable(Runnable task)�� Executors.callable(Runnable task,Objectresule))
shutdown() VS shutdownNow()
-
shutdown() :�ر��̳߳�,�̳߳ص�״̬��Ϊ SHUTDOWN���̳߳ز��ٽ�����������,���Ƕ�����������ִ�������
-
shutdownNow() :�ر��̳߳�,�̵߳�״̬��Ϊ STOP���̳߳ػ���ֹ��ǰ�������е�����,��ֹͣ�����Ŷӵ����������ڵȴ�ִ�е� List��
shutdownNow��ԭ���DZ����̳߳��еĹ����߳�,Ȼ����������̵߳�interrupt�������ж��߳�,��������Ӧ�жϵ����������Զ����ֹ
isTerminated() VS isShutdown()
-
isShutDown ������ shutdown() ������Ϊ true��
-
isTerminated ������ shutdown() ������,���������ύ��������ɺ�Ϊ true
7. sleep() ������ wait() ���������ͬ��?
����
-
sleep����:��Thread��ľ�̬����,��ǰ�߳̽�˯��n����,�߳̽�������״̬����˯��ʱ�䵽��,��������,���������״̬,�ȴ�CPU�ĵ�����˯�߲��ͷ���(����еĻ�)��
-
wait����:��Object�ķ���,������synchronized�ؼ���һ��ʹ��,�߳̽�������״̬,��notify����notifyall�����ú�,��������������,ֻ������ռ�û�����֮��Ż���������״̬��˯��ʱ,���ͷŻ�������
-
sleep ����û���ͷ���,�� wait �����ͷ����� ��
-
sleep ͨ����������ִͣ��,Wait ͨ���������̼߳佻��/ͨ��
-
sleep() ����ִ����ɺ�,�̻߳��Զ����������߿���ʹ�� wait(long timeout)��ʱ���̻߳��Զ����ѡ�wait() ���������ú�,�̲߳����Զ�����,��Ҫ����̵߳���ͬһ�������ϵ� notify() ����notifyAll() ����
��ͬ
- ���߶�������ͣ�̵߳�ִ�С�
8.Ϊʲô���ǵ��� start() ����ʱ��ִ�� run() ����,Ϊʲô���Dz���ֱ�ӵ��� run() ����
-
new һ�� Thread,�߳̽������½�״̬; ����start() ��ִ���̵߳���Ӧ������,Ȼ���Զ�ִ��run() ����������,(���� start() ����,������һ���̲߳�ʹ�߳̽����˾���״̬,�����䵽ʱ��Ƭ��Ϳ��Կ�ʼ�����ˡ�)���������Ķ��̹߳�����
-
ֱ��ִ�� run() ����,��� run ��������һ�� main �߳��µ���ͨ����ȥִ��,��������ij���߳���ִ����,�����Ⲣ���Ƕ��̹߳�����
���� start �������������̲߳�ʹ�߳̽������״̬,�� run ����ֻ�� thread ��һ����ͨ��������,���������߳���ִ�С���
9. Thread���е�yield������ʲô����?
? Yield����������ͣ��ǰ����ִ�е��̶߳���,����������ͬ���ȼ����߳�ִ�С�����һ����̬��������ֻ��֤��ǰ�̷߳���CPUռ�ö����ܱ�֤ʹ�����߳�һ����ռ��CPU,ִ��yield()���߳��п����ڽ��뵽��ͣ״̬�������ֱ�ִ�С�
10.̸̸volatile��ʹ�ü���ԭ��
volatile����������:
-
volatile��֤�����������̵߳Ŀɼ���:��volatile��������,��ֵ�������̻߳��������¡���������Ϊ���̻߳�����ʹ��volatile���εı�����ֵһ�������µġ�
-
jdk1.5�Ժ�volatile��ȫ������ָ�������Ż�,ʵ���������ԡ�
11.��δ����߳�ʵ��������?
Thread �౾������ʵ�� Runnable �ӿڵ�һ��ʵ��,����һ���̵߳�ʵ���������߳�ʵ��һ�������ַ���:
- ���� Thread �����ಢ��д run()
public class MyThread extends Thread {
@Override
public void run(){
System.out.println("MyThread running");
}
}
run() ���ڵ��� start() ������ִ��,����һ���߳������� start() ������ͻ���������,�����ǵȵ� run() ����ִ����Ϻ��ٷ��ء�
MyThread myThread = new MyThread();
myThread.start();
- ʵ�� Runnable �ӿ�
public class MyRunnable implements Runnable{
@Override
public void run(){
System.out.println("MyRunnable running");
}
}
���½���ʱʵ�� Runnable �ӿ�,Ȼ���� Thread ��Ĺ��캯���д��� MyRunnable ��ʵ������,���ִ�� start() ��������;
Thread thread = new Thread(new MyRunnable());
thread.start();
12. �߳��������������
���߳���Ϊij��ԭ����� CPU ʹ��Ȩ��,���ó��� CPU ʱ��Ƭ,��ʱ�ͻ�ֹͣ����,֪���߳̽��������״̬( Runnable ),���л����ٴλ�� CPU ʱ��Ƭת�� RUNNING ״̬��һ������,���������
���Է�Ϊ��������:
- �ȴ�����(Object.wait -> �ȴ�����)
RUNNING ״̬���߳�ִ�� Object.wait() ������,JVM �Ὣ�̷߳���ȴ�����(waitting queue);
- ͬ������(lock -> ����)
RUNNING ״̬���߳��ڻ�ȡ�����ͬ����ʱ,���� ͬ�����������߳�ռ��,�� JVM �����̷߳��� ����(lock pool)��;
- ��������(sleep/join)
RUNNING ״̬���߳�ִ�� Thread.sleep(long ms) �� Thread.join() ����,�� I/O ����ʱ,JVM �Ὣ���߳���Ϊ����״̬���� sleep() ״̬��ʱ, join() �ȴ��߳���ֹ��ʱ. ���� I/O �������ʱ,�߳�����ת�������״̬( RUNNABLE );
13. �߳����������ַ�ʽ
- ��������
run() ���� call() ����ִ����ɺ�,�߳���������;
- �쳣����
�߳��׳�һ��δ����� Exception �� Error ,�����߳��쳣����;
- ���� stop()
ֱ�ӵ����̵߳� stop() �������������߳�,����һ�㲻�Ƽ�ʹ�ø��ַ�ʽ,��Ϊ�÷���ͨ������ ������;
19. synchronized �� volatile ��������ʲô?
volatile ��������ڴ�ɼ�������,��ʹ�����ж� volatile �����Ķ�д��ֱ��д������,�� ��֤ �˱����Ŀɼ��ԡ�
synchronized �������ִ�п��Ƶ�����,������ֹ�����̻߳�ȡ��ǰ����ļ����,����һ�����õ�ǰ�����б� synchronized �ؼ��ֱ����Ĵ�������������̷߳���,Ҳ����������ִ�С�����,synchronized ���ᴴ��һ�� �ڴ�����,�ڴ�����ָ�֤������ CPU �����������ֱ��ˢ��������,�Ӷ� ��֤�������ڴ�ɼ���,ͬʱҲʹ����������̵߳����в����� happens-before ���������������̵߳IJ�����
���ߵ�������Ҫ������:
-
volatile �������ڸ��� JVM ��ǰ�����ڼĴ���(�����ڴ�)�е�ֵ�Dz�ȷ����,��Ҫ�������ж�ȡ; synchronized ����������ǰ����,ֻ�е�ǰ�߳̿��Է��ʸñ���,�����̱߳�����ס��
-
volatile ����ʹ���ڱ�������;synchronized �����ʹ���� ����. ����. ���༶���
-
volatile ����ʵ�ֱ������Ŀɼ���,���ܱ�֤ԭ����(��Ϊ�IJ���һ������,�Ƕ�ȡ,�ı�,д��������������û��ԭ����);��synchronized ����� ��֤�������� �Ŀɼ��Ժ�ԭ����
-
volatile ��������̵߳�����;synchronized ���ܻ�����̵߳�������
-
volatile ��ǵı������ᱻ�������Ż�;synchronized ��ǵı������Ա��������Ż���
20. synchronized �� Lock ��ʲô����?
-
synchronized ���Ը���. ����. ��������;�� lock ֻ�ܸ�����������
-
synchronized ����Ҫ�ֶ���ȡ�����ͷ���,ʹ�ü�,�����쳣���Զ��ͷ���,�����������;�� lock ��Ҫ�Լ��������ͷ���,���ʹ�ò���û�� unLock()ȥ�ͷ����ͻ����������
-
ͨ�� Lock ����֪����û�гɹ���ȡ��,�� synchronized ȴ���쵽��
21. synchronized �� ReentrantLock ������ʲô?
1.���߶��ǿ�������
��������:������,Ҳ�����ݹ���,��������ָ������һ���߳��п��Զ�λ�ȡͬһ����,����:
һ���߳���ִ��һ�������ķ���,�÷������ֵ�������һ����Ҫ��ͬ���ķ���,����߳̿���ֱ��ִ��
���õķ���,���������»����,
���߶���ͬһ���߳�ÿ����һ��,���ļ�����������1,����Ҫ�ȵ����ļ������½�Ϊ0ʱ�����ͷ�����
2.synchronized ������ JVM �� ReentrantLock ������ API
-
synchronized �������� JVM ʵ�ֵ�,ǰ������Ҳ������ ������Ŷ��� JDK1.6 Ϊ synchronized �ؼ��ֽ����˺ܶ��Ż�,������Щ�Ż����������������ʵ�ֵ�
-
ReentrantLock �� JDK ����ʵ�ֵ�(Ҳ���� API ����,��Ҫ lock() �� unlock() ������� try/finally���������)
3.ReentrantLock �� synchronized ������һЩ������
���synchronized,ReentrantLock������һЩ�����ܡ���Ҫ��˵��Ҫ������:�ٵȴ����ж�;�ڿ�ʵ�ֹ�ƽ��;�ۿ�ʵ��ѡ����֪ͨ(�����������)
�̳߳�
1. ΪʲôҪ���̳߳�?
�̳߳��ṩ��һ�����ƺ�����Դ(����ִ��һ������)�� ÿ���̳߳ػ�ά��һЩ����ͳ����Ϣ,����
����������������
ʹ���̳߳صĺô�:
-
������Դ���ġ� ͨ���ظ������Ѵ������߳̽����̴߳�����������ɵ����ġ�
-
�����Ӧ�ٶȡ� ������ʱ,������Բ���Ҫ�ĵȵ��̴߳�����������ִ�С�
-
����̵߳Ŀɹ����ԡ� �߳���ϡȱ��Դ,��������ƵĴ���,����������ϵͳ��Դ,���ή��ϵͳ���ȶ���,ʹ���̳߳ؿ��Խ���ͳһ�ķ���,���źͼ��
2. ִ��execute()������submit()������������ʲô��?
-
execute() ���������ύ����Ҫ����ֵ������,�������ж������Ƿ��̳߳�ִ�гɹ� ���;
-
submit()���������ύ��Ҫ����ֵ���������̳߳ػ᷵��һ��future���͵Ķ���,ͨ�����future��������ж������Ƿ�ִ�гɹ�,���ҿ���ͨ��future��get()��������ȡ����ֵ,get()������������ǰ�߳�ֱ���������,��ʹ�� get(long timeout,TimeUnit unit) �������������ǰ�߳�һ��ʱ�����������,��ʱ���п�������û��ִ���ꡣ
3. ˵���̳߳غ��IJ���?
-
corePoolSize : �����̴߳�С���̳߳�һֱ����,�����߳̾Ͳ���ֹͣ��
-
maximumPoolSize :�̳߳�����߳��������Ǻ����߳�����=maximumPoolSize-corePoolSize
-
keepAliveTime :�Ǻ����̵߳�����ʱ�䡣����Ǻ����߳���keepAliveTime��û����������,�Ǻ����̻߳�������
-
workQueue :�������С�ArrayBlockingQueue,LinkedBlockingQueue��,��������߳�����
-
defaultHandler :���Ͳ��ԡ�ThreadPoolExecutor����һ����4�ֱ��Ͳ��ԡ�ͨ��ʵ��
RejectedExecutionHandler�ӿڡ�
-
AbortPolicy : �߳�������������Ĭ�ϱ��Ͳ��ԡ�
-
DiscardPolicy : �߳�����ֱ�Ӷ�����������
-
DiscardOldestPolicy : ��workQueue����������,�������߳��������¼������ִ�С�
-
CallerRunsPolicy :�̳߳�֮����߳�ֱ�ӵ���run����ִ�С�
-
-
ThreadFactory :�̹߳������½��̹߳�����
4. �̳߳�ִ�����������?
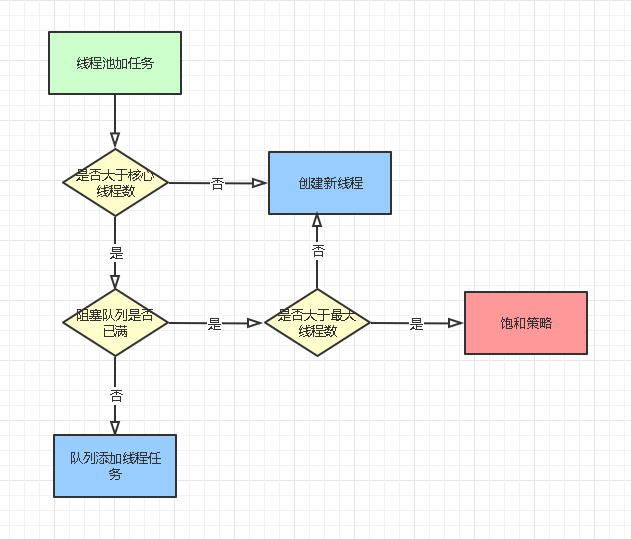
-
�̳߳�ִ��execute/submit�������̳߳���������,������С�ں����߳���corePoolSize,�̳߳��п��Դ����µ��̡߳�
-
��������ں����߳���corePoolSize,��������������������
-
���������������,��Ҫͨ���Ƚϲ���maximumPoolSize,���̳߳ش����µ��߳�,���߳���������maximumPoolSize,˵����ǰ�����̳߳����߳��Ѿ�����������,�ͻ�ִ�б��Ͳ��ԡ�
�塢MySQL
����
1. ������ʲô?
������һ��������ļ�(InnoDB���ݱ��ϵ������DZ��ռ��һ����ɲ���),���ǰ����Ŷ����ݱ������м�¼������ָ����
������һ�����ݽṹ�����ݿ�����,�����ݿ����ϵͳ��һ����������ݽṹ,��Э�����ٲ�ѯ������
���ݿ����������������ʵ��ͨ��ʹ��B���������B+������ͨ��˵,�������൱��Ŀ¼��Ϊ�˷���
�������е�����,ͨ�������ݽ��������γ�Ŀ¼������������һ���ļ�,����Ҫռ�������ռ�ġ�
MySQL�����Ľ�������MySQL�ĸ�Ч�����Ǻ���Ҫ��,�������Դ�����MySQL�ļ����ٶ���������
���ڲ��ֵ��ʱ��,ǰ�涼�м�����ƴ����ƫ�ԡ��ʻ���,Ȼ���ҵ���Ӧ�ֵ�ҳ��,����Ȼ��ʹ���
���ҳ���Ϳ���֪������Ҫ������ijһ��key��ȫ��ֵ����Ϣ�ˡ�
2. ��������Щ��ȱ��?
-
�������ŵ�
? ���Դ��ӿ����ݵļ����ٶ�,��Ҳ�Ǵ�������������Ҫ��ԭ��
? ͨ��ʹ������,�����ڲ�ѯ�Ĺ�����,ʹ���Ż�������,���ϵͳ�����ܡ�
-
������ȱ��
ʱ�䷽��:����������ά������Ҫ�ķ�ʱ��,�����,���Ա��е����ݽ������ӡ�ɾ�����ĵ�ʱ��,����ҲҪ��̬��ά��,�ή����/��/ɾ��ִ��Ч��;
�ռ䷽��:������Ҫռ�����ռ䡣
3. MySQL���ļ�����������?
1���Ӵ洢�ṹ��������:BTree����(B-Tree��B+Tree����),Hash����,full-indexȫ������,R-Tree�������������������������洢ʱ�������ʽ,
2����Ӧ�ò������:��ͨ����,Ψһ����,����������
? ��ͨ����:��һ������ֻ����������,һ���������ж����������
? Ψһ����:�����е�ֵ����Ψһ,�������п�ֵ
? ��������:����ֵ���һ������,ר�������������,��Ч�ʴ��������ϲ�
? �۴�����(�ۼ�����):������һ�ֵ�������������,����һ�����ݴ洢��ʽ������ϸ��ȡ���ڲ�ͬ��ʵ��,InnoDB�ľ۴�������ʵ������ͬһ���ṹ�б�����B-Tree����(��������˵��B+Tree)����������
? �Ǿ۴�����: ���Ǿ۴�����,���ǷǾ۴�����
3�����������ݵ�����˳�����ֵ����(����)˳���ϵ: �ۼ�����,�Ǿۼ�������
4. ˵һ˵�����ĵײ�ʵ��?
Hash����
���ڹ�ϣ��ʵ��,ֻ�о�ȷƥ�����������еIJ�ѯ����Ч,����ÿһ������,�洢���涼������е���
���м���һ����ϣ��(hash code),����Hash���������еĹ�ϣ��洢��������,ͬʱ���������б�
��ָ��ÿ�������е�ָ�롣

B-Tree����(MySQLʹ��B+Tree)
B-Tree�ܼӿ����ݵķ����ٶ�,��Ϊ�洢���治����Ҫ����ȫ��ɨ������ȡ����,���ݷֲ��ڸ����ڵ�֮�С�
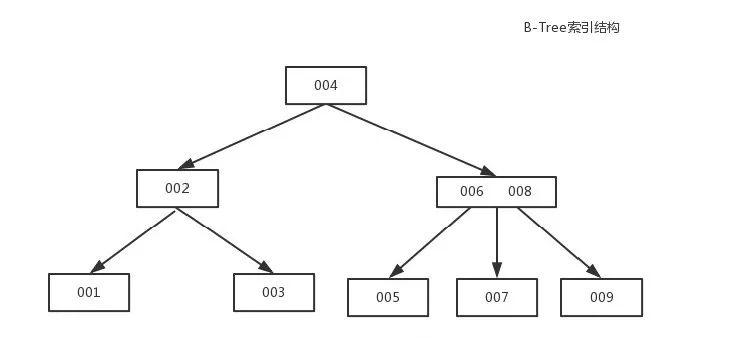
B+Tree����
��B-Tree�ĸĽ��汾,ͬʱҲ�����ݿ��������������õĴ洢�ṹ�����ݶ���Ҷ�ӽڵ���,����������
˳�����ָ��,ÿ��Ҷ�ӽڵ㶼ָ�����ڵ�Ҷ�ӽڵ�ĵ�ַ�����B-Tree��˵,���з�Χ����ʱֻ��Ҫ
���������ڵ�,���б������ɡ���B-Tree��Ҫ��ȡ���нڵ�,���֮��B+TreeЧ�ʸ��ߡ�
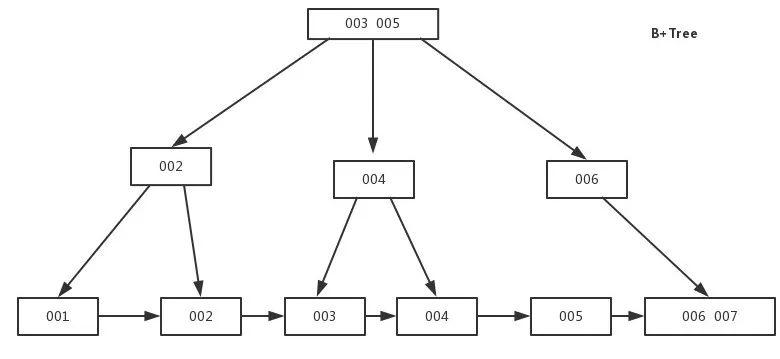
B+tree����:
-
n����tree�Ľڵ����n���ؼ���,�������������ݶ��DZ������ݵ�������
-
���е�Ҷ�ӽ���а�����ȫ���ؼ��ֵ���Ϣ,��ָ����Щ�ؼ��ּ�¼��ָ��,��Ҷ�ӽ�㱾���� �ؼ��ֵĴ�С��С����˳�����ӡ�
-
���еķ��ն˽����Կ�������������,����н����������е����(����С)�ؼ��֡�
-
B+ ����,���ݶ���IJ����ɾ������Ҷ�ڵ��Ͻ��С�
-
B+����2��ͷָ��,һ�������ĸ��ڵ�,һ������С�ؼ����Ҷ�ڵ㡣
5. Ϊʲô�����ṹĬ��ʹ��B+Tree,������B-Tree,Hash,������,�����?
B-tree: �������������ش�
-
B+���Ĵ��̶�д���۸���:B+�����ڲ��ڵ㲢û��ָ��ؼ��־�����Ϣ��ָ��,������ڲ��ڵ����B(B-)����С,���������ͬһ�ڲ��ڵ�Ĺؼ��ִ����ͬһ�̿���,��ô�̿��������ɵĹؼ�������ҲԽ��,һ���Զ����ڴ����Ҫ���ҵĹؼ���Ҳ��Խ��,��� IO��д�����ͽ��� �ˡ�
-
����B+�������ݶ��洢��Ҷ�ӽ����,��֧����Ϊ����,����ɨ��,ֻ��Ҫɨһ��Ҷ�ӽ�㼴��,����B����Ϊ���֧���ͬ���洢������,����Ҫ�ҵ����������,��Ҫ����һ���������������ɨ,����B+�������ʺ��� �����ѯ �����,����ͨ��B+���������ݿ�������
Hash:
-
��Ȼ���Կ��ٶ�λ,����û��˳��,IO���Ӷȸ�;
-
����Hash��ʵ��,ֻ��Memory�洢������ʽ֧�ֹ�ϣ���� ;
-
�ʺϵ�ֵ��ѯ,��=��in()��<=>,��֧�ַ�Χ��ѯ ;
-
��Ϊ���ǰ�������ֵ˳��洢��,�Ͳ�����B+Tree����һ����������������� ;
-
Hash�����ڲ�ѯ��ֵʱ�dz��� ;
-
��ΪHash����ʼ�������������е�ȫ������,���Բ�֧�ֲ��������е�ƥ����� ;
-
����д����ظ���ֵ�������,��ϣ������Ч�ʻ�ܵ�,��Ϊ���ڹ�ϣ��ײ���� ��
������: ���ĸ߶Ȳ�����,������ƽ��,����Ч�ʸ������й�(���ĸ߶�),����IO���۸ߡ�
�����: ���ĸ߶��������������Ӷ�����,IO���۸ߡ�
6. ��һ���۴�������Ǿ۴�����?
�� InnoDB ��,����B+ Tree��Ҷ�ӽڵ�洢����������������������,Ҳ����֮Ϊ�۴�����,��������
�洢�������ŵ���һ��,�ҵ�����Ҳ���ҵ������ݡ�
������B+ Tree��Ҷ�ӽڵ�洢��������ֵ���Ƿ���������,Ҳ����֮Ϊ�Ǿ۴�����������������
�۴�������Ǿ۴�����������:
-
�Ǿۼ�������ۼ����������������Ǿۼ�������Ҷ�ӽڵ㲻�洢���е�����,���Ǵ洢���ж�Ӧ������(�к�)
-
����InnoDB��˵,��Ҫ�����������ǻ���Ҫ����������ȥ�ۼ������н��в���,��������ݾۼ������������ݵĹ���,���dz�Ϊ�ر�����һ������һ����˳��IO,�ر��IJ����������IO����Ҫ�ر��Ĵ���Խ��,�����IO����Խ��,���Ǿ�Խ������ʹ��ȫ��ɨ�衣
-
ͨ�������, ��������(�۴�����)��ѯֻ���һ��,������������(�Ǿ۴�����)��Ҫ�ر���ѯ�������Ȼ,����Ǹ��������Ļ�,��һ�μ��ɡ�
-
ע��:MyISAM���������������Ƕ����������ǷǾ۴�����,��InnoDB�����������Ǿ۴�����,��
�������ǷǾ۴������������Լ����������������ǷǾ۴�������
7. �Ǿ۴�����һ����ر���ѯ��?
��һ��,���漰����ѯ�����Ҫ����ֶ��Ƿ�ȫ������������,���ȫ������������,��ô�Ͳ����ٽ��лر���ѯ��һ����������(����)������Ҫ��ѯ�ֶε�ֵ,����֮Ϊ"��������"��
�ٸ�������,����������Ա�����������Ͻ���������,��ô������ select score from student where score > 90 �IJ�ѯʱ,��������Ҷ�ӽڵ���,�Ѿ�������score ��Ϣ,�����ٴν��лر���ѯ��
8. ����������ʲô?Ϊʲô��Ҫע�����������е�˳��?
MySQL����ʹ�ö���ֶ�ͬʱ����һ������,��������������������������,�����Ҫ��������,��Ҫ���ս�������ʱ���ֶ�˳��ʹ��,����������������
����ԭ��Ϊ:
MySQLʹ������ʱ��Ҫ���������������ڽ�����"name,age,school"����������,��ô����������Ϊ: �Ȱ���name����,���name��ͬ,����age����,���age��ֵҲ���,����school��������
�����в�ѯʱ,��ʱ������������name�ϸ�����,��˱�������ʹ��name�ֶν��е�ֵ��ѯ,֮�����ƥ�䵽���ж���,�䰴��age�ֶ��ϸ�����,��ʱ����ʹ��age�ֶ�������������,�Դ����ơ�����ڽ�������������ʱ��Ӧ��ע�������е�˳��,һ�������,����ѯ����Ƶ�������ֶ�ѡ���Ըߵ��з���ǰ�档������Ը��������IJ�ѯ���߱��ṹ���е����ĵ�����
����
1. ���ݿ������ʽ��ʲô?
��һ��ʽ:ǿ�������е�ԭ����,�����ݿ����ÿһ�ж��Dz��ɷָ��ԭ����������
�ڶ���ʽ:Ҫ��ʵ���������ȫ���������ؼ��֡���ν��ȫ������ָ���ܴ��ڽ��������ؼ���һ���ֵ����ԡ����е�ÿ�ж����������.
������ʽ:�κη������Բ������������������ԡ��ڵڶ���ʽ�Ļ����ϸ���һ��,Ŀ����ȷ��ÿ�ж���������ֱ�����,�����Ǽ�����.
2. MySQL ֧����Щ�洢����?
MySQL ֧�ֶ��ִ洢����,���� InnoDB,MyISAM,Memory,Archive �ȵ�.�ڴ�����������,ֱ��ѡ��ʹ�� InnoDB ���涼������ʵ�,InnoDB Ҳ�� MySQL ��Ĭ�ϴ洢���档
MyISAM �� InnoDB ����������Щ:
-
InnoDB ֧������,MyISAM ��֧��
-
InnoDB ֧�����,�� MyISAM ��֧��
-
InnoDB �Ǿۼ�����,�����ļ��Ǻ���������һ���,����Ҫ������,ͨ����������Ч�ʺܸ�;MyISAM �ǷǾۼ�����,�����ļ��Ƿ����,����������������ļ���ָ��,�����������������Ƕ����ġ�
-
Innodb ��֧��ȫ������,�� MyISAM ֧��ȫ������,��ѯЧ���� MyISAM Ҫ��;
-
InnoDB ��������ľ�������,MyISAM ��һ��������������������������
-
MyISAM ���ñ�����(table-level locking);InnoDB ֧���м���(row-level locking)�ͱ�����,Ĭ��Ϊ�м�����
3. ��������ѡ��������������ֱ���ʲô?
-
����:�ڹ�ϵ����Ψһ��ʶԪ������Լ���Ϊ��ϵģʽ�ij���(���Լ�)��һ�����Կ���Ϊ��Ϊһ������,������������һ��Ҳ������Ϊһ������������������ѡ����������
-
��ѡ��:����С����,��û������Ԫ�صij�����
-
����:���ݿ���жԴ������ݶ�������Ψһ��������ʶ�������л����Ե���ϡ�һ��������ֻ����һ������,��������ȡֵ����ȱʧ,������Ϊ��ֵ(Null)����ϵģʽ���û�����ʹ�ú�ѡ��������
-
���:��һ�����д��ڵ���һ�����������ƴ˱��������
4. SQL Լ�����ļ���?
-
NOT NULL: ���ڿ����ֶε�����һ������Ϊ��(NULL)��
-
UNIQUE: �ؼ��ֶ����ݲ����ظ�,һ���������ж�� Unique Լ����
-
PRIMARY KEY: Ҳ�����ڿؼ��ֶ����ݲ����ظ�,������һ����ֻ��������һ����
-
FOREIGN KEY: ����Ԥ���ƻ���֮�����ӵĶ���,Ҳ�ܷ�ֹ�Ƿ����ݲ��������,��Ϊ����������ָ����Ǹ����е�ֵ֮һ��
-
CHECK: ���ڿ����ֶε�ֵ��Χ��
5. MySQL �е� varchar �� char ��ʲô����?
char ��һ�������ֶ�,���������� char(10) �Ŀռ�,��ô����ʵ�ʴ洢��������.���ֶζ�ռ�� 10 ����
��,�� varchar �DZ䳤��,Ҳ����˵�����ֻ�����,ռ�õĿռ�Ϊʵ���ַ�����+1,���һ���ַ��洢
ʹ���˶�Ŀռ�.
�ڼ���Ч��������,char > varchar,�����ʹ����,���ȷ��ij���ֶε�ֵ�ij���,����ʹ�� char,����Ӧ��
����ʹ�� varchar.����洢�û� MD5 ���ܺ������,��Ӧ��ʹ�� char��
6. MySQL�� in �� exists ����
MySQL�е�in����ǰ�������ڱ���hash ����,��exists����Ƕ������loopѭ��,ÿ��loopѭ���ٶ��ڱ����в�ѯ��һֱ��Ҷ���Ϊexists��in����Ч��Ҫ��,����˵����ʵ�Dz�ȷ�ġ������Ҫ���ֻ����ġ�
�����ѯ����������С�൱,��ô��in��exists��������������һ����С,һ���Ǵ��,���Ӳ�ѯ�������exists,�Ӳ�ѯ��С����in��not in ��not exists:�����ѯ���ʹ����not in,��ô�����������ȫ��ɨ��,û���õ�����;��notextsts���Ӳ�ѯ��Ȼ���õ����ϵ����������������Ǹ�����,��not exists����not inҪ�졣
7. drop��delete��truncate������
���߶���ʾɾ��,����������һЩ���:
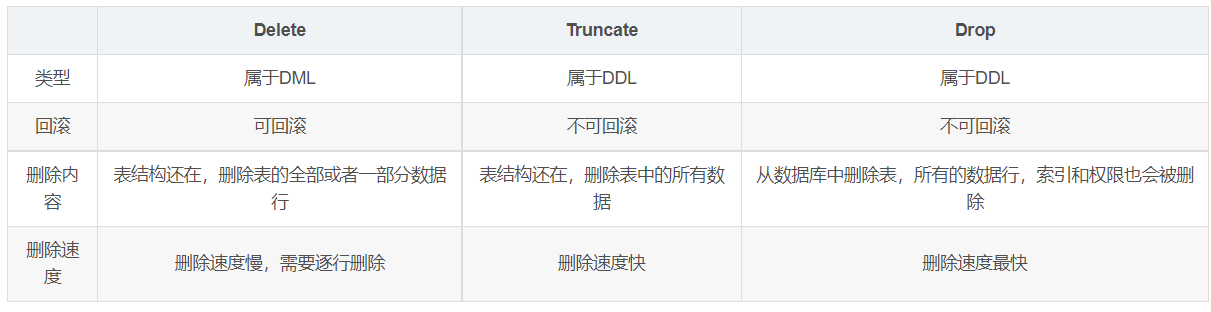
delete�ı��ṹ����,ֻ�ǰ�����ɾ������,��drop�ѱ�Ҳ���ɵ��ˡ�
8. ʲô�Ǵ洢����?����Щ��ȱ��?
�洢������һЩԤ����� SQL ��䡣
1������ֱ������:�洢���̿���˵��һ����¼��,������һЩ T-SQL �����ɵĴ����,��Щ T
SQL ��������һ������һ��ʵ��һЩ����(�Ե�����������ɾ�IJ�),Ȼ���ٸ���������ȡһ��
����,���õ�������ܵ�ʱ������������ˡ�
2���洢������һ��Ԥ����Ĵ����,ִ��Ч�ʱȽϸ�,һ���洢����������� T_SQL ��� ,���Խ�����
��ͨ����,���ͨ������,����һ���̶���ȷ�����ݰ�ȫ
����,�ڻ�������Ŀ��,��ʵ�Dz�̫�Ƽ��洢���̵�,�Ƚϳ����ľ��ǰ���ġ�Java �����ֲᡷ�н�ֹʹ��
�洢����,�Ҹ��˵�������,�ڻ�������Ŀ��,����̫��,��Ŀ����������Ҳ�Ƚ϶�,��Ա��������ڴ�ͳ����
ĿҲ����Ƶ��,�������������,�洢���̵Ĺ���ȷʵ��û����ô����,ͬʱ,������Ҳû��д�ڷ������ô
�á�
9. MySQL ִ�в�ѯ�Ĺ���
-
�ͻ���ͨ�� TCP ���������������� MySQL ������,��������Ը��������Ȩ����֤��������Դ����
-
�黺����(���жϻ����Ƿ�����ʱ,MySQL ������н�����ѯ���,����ֱ��ʹ�� SQL ���Ϳͻ��˷�����������ԭʼ��Ϣ������,�κ��ַ��ϵIJ�ͬ,����ո�ע��ȶ��ᵼ�»���IJ����С�)
-
�����(SQL ��Ƿ�д����)�� ��ΰ�������Ԥ������,������ݱ����������Ƿ����,�����������Ƿ�������塣
-
�Ż����Ƿ�ʹ������,����ִ�мƻ���
-
����ִ����,�����ݱ��浽�������,ͬʱ�������ݻ��浽��ѯ������,���ս���������ظ��ͻ��ˡ�
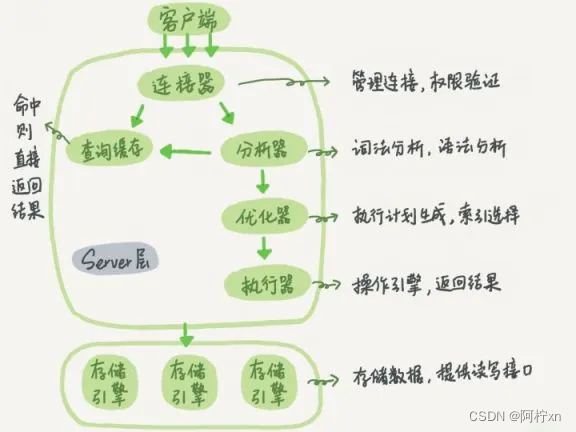
�������ִ�лḴ��һ�㡣��Ҫ�����Ƿ���������,д binlog,ˢ��,�Ƿ�ִ�� commit��
����
1. ʲô�����ݿ�����?
������һ�����ɷָ�����ݿ��������,Ҳ�����ݿⲢ�����ƵĻ�����λ,��ִ�еĽ������ʹ���ݿ��һ��һ����״̬�䵽��һ��һ����״̬�����������ϵ�һ�����,Ҫô��ִ��,Ҫô����ִ����
�������Ҳ�������ó���˵���Ӿ���ת���ˡ�
����С��Ҫ��С��ת��1000Ԫ,���ת�˻��漰�������ؼ���������:��С����������1000Ԫ,��С����������1000Ԫ����һ������������֮��ͻȻ���ִ����������ϵͳ����,����С�������ٶ�С������û������,�����Ͳ����ˡ�������DZ�֤�������ؼ�����Ҫô���ɹ�,Ҫô��Ҫʧ�ܡ�
2. ����һ��������е��ĸ�����
�������һ��ԭ���ԵIJ���,��Щ����Ҫôȫ������,Ҫôȫ������������������ݿ��һ��һ����״̬ת������һ��һ����״̬��
-
ԭ���������������ݿ����������λ,�����а����ĸ�����Ҫô����,Ҫô������
-
һ����������ִ�еĽ��������ʹ���ݿ��һ��һ����״̬�䵽��һ��һ����״̬����˵����ݿ�ֻ�����ɹ������ύ�Ľ��ʱ,��˵���ݿ��һ����״̬��������ݿ�ϵͳ �����з�������,��Щ������δ��ɾͱ����ж�,��Щδ�����������ݿ�����������һ������д���������ݿ�,��ʱ���ݿ�ʹ���һ�ֲ���ȷ��״̬,����˵�� ��һ�µ�״̬��
-
��������һ�������ִ�в������������������һ�������ڲ���//������ʹ�õ����ݶ��������������Ǹ����,����ִ�еĸ�������֮�䲻�ܻ�����š�
-
��������Ҳ��������,ָһ������һ���ύ,�������ݿ��е����ݵĸı��Ӧ���������Ե�����������������������ϲ�Ӧ�ö���ִ�н�����κ�Ӱ�졣
3. ˵һ��MySQL �����ָ��뼶��
- Read Uncommitted(��ȡδ�ύ����)
�ڸø��뼶��,���������Կ�������δ�ύ�����ִ�н���������뼶���������ʵ��Ӧ��,��Ϊ��������Ҳ������������ö��١���ȡδ�ύ������,Ҳ����֮Ϊ���(Dirty Read)��
- Read Committed(��ȡ�ύ����)
���Ǵ�������ݿ�ϵͳ��Ĭ�ϸ��뼶��(������ MySQL Ĭ�ϵ�)���������˸���ļ���:һ������ֻ�ܿ����Ѿ��ύ���������ĸı䡣���ָ��뼶�� Ҳ֧����ν �� �����ظ���(NonrepeatableRead),��Ϊͬһ���������ʵ���ڸ�ʵ�����������ܻ����µ� commit,����ͬһ select ���ܷ��ز�ͬ�����
- Repeatable Read(���ض�)
���� MySQL ��Ĭ��������뼶��,��ȷ��ͬһ����Ķ��ʵ���ڲ�����ȡ����ʱ,�ῴ��ͬ���������С�����������,��ᵼ���� һ�����ֵ�����:�ö� (Phantom Read)��
- Serializable(�ɴ��л�)
ͨ��ǿ����������,ʹ֮���������ͻ,�Ӷ�����ö����⡣����֮,������ÿ�������������ϼ��Ϲ����������������,���ܵ��´����ij�ʱ�������������
[����ͼƬת���С�(img-kyfB1qlo-1653698680510)]
4. ʲô�����?�ö�?�����ظ���?
1�����:���� A ��ȡ������ B ���µ�����,Ȼ�� B �ع�����,��ô A ��ȡ����������������
2�������ظ���:���� A ��ζ�ȡͬһ����,���� B ������ A ��ζ�ȡ�Ĺ�����,���������˸��²��ύ,�������� A ��ζ�ȡͬһ����ʱ,��� ��һ�¡�
3���ö�:ϵͳ����Ա A �����ݿ�������ѧ���ijɼ��Ӿ��������Ϊ ABCDE �ȼ�,����ϵͳ����Ա B �������ʱ�������һ����������ļ�¼,��ϵͳ����Ա A �Ľ������ֻ���һ����¼û�иĹ���,�ͺ������˻þ�һ��,��ͽлö���
�����ظ�����������,�ö�������������ɾ��(���˻�������),�����һ������ع�Ӱ������һ������
5. �����ʵ��ԭ��
�����ǻ���������־�ļ�(redo log)�ͻع���־(undo log)ʵ�ֵġ�
ÿ�ύһ����������Ƚ��������������־д�뵽������־�ļ����г־û�,���ݿ�Ϳ���ͨ��������־����֤�����ԭ���Ժͳ־��ԡ�
ÿ����������ʱ,������� undo log,�����Ҫ�ع�,����� undo log �ķ���������������,���� insert һ����¼�� delete һ����¼��undo log ��Ҫʵ�����ݿ��һ���ԡ�
6. MySQL������־������?
innodb ������־���� redo log �� undo log��
undo log ָ����ʼ֮ǰ,�ڲ����κ�����֮ǰ,���Ƚ�����������ݱ��ݵ�һ���ط���redo log ָ�����в������κ�����,�����µ����ݱ��ݵ�һ���ط���
������־��Ŀ��:ʵ�����߽���ʧ��,������־�ļ����������ó�
7. ʲô��MySQL�� binlog?
MySQL�� binlog ����¼�������ݿ���ṹ���(���� CREATE��ALTER TABLE)�Լ���������(INSERT��UPDATE��DELETE)�Ķ�������־��binlog �����¼ SELECT �� SHOW �������,��Ϊ������������ݱ�����û����,�������ͨ����ѯͨ����־���鿴 MySQL ִ�й���������䡣
MySQL binlog ���¼���ʽ��¼,�����������ִ�е����ĵ�ʱ��,MySQL �Ķ�������־������ȫ�͵ġ�binlog ����ҪĿ���Ǹ��ƺͻָ���
binlog �����ָ�ʽ,������ȱ��:
-
statement: ���� SQL ����ģʽ,ijЩ���ͺ����� UUID, LOAD DATA INFILE ���ڸ��ƹ��̿��ܵ������ݲ�һ������������
-
row: �����е�ģʽ,��¼�����еı仯,�ܰ�ȫ������ binlog �����������ģʽ��ܶ�,��һЩ����������������ʱ�� binlog �л����ɺܶ������,���ܵ��´ӿ��ӳٱ��
-
mixed: ���ģʽ,���������ѡ���� statement ���� row ģʽ��
8. �������п��Ի��ʹ�ô洢������?
������Ҫ��ͬһ��������ʹ�ö��ִ洢����,MySQL�������㲻��������,���������²�Ĵ洢����ʵ�ֵġ�
����������л��ʹ���������ͺͷ������͵ı�(����InnoDB��MyISAM��),�������ύ������²�����ʲô���⡣
�������������Ҫ�ع�,�������͵ı��ϵı����������,��ᵼ�����ݿ�ڲ�һ�µ�״̬,�������������,��������ս������ȷ��������,Ϊÿ�ű�ѡ����ʵĴ洢����dz���Ҫ��
��
1. ΪʲôҪ����?
������û������ش�ȡ����ʱ,�����ݿ��оͻ�����������ͬʱ��ȡͬһ���ݵ���������Բ����������ӿ��ƾͿ��ܻ��ȡ�ʹ洢����ȷ������,�ƻ����ݿ��һ���ԡ�
��֤���û������±�֤���ݿ������Ժ�һ���ԡ�
2. �����������ȷ����ݿ�������Щ?
�ڹ�ϵ�����ݿ���,�������������Ȱ����ݿ�����Ϊ�м���(INNODB����)��������(MYISAM����)��ҳ����(BDB���� )��
���:
-
�м�����MySQL������������ϸ��һ����,��ʾֻ��Ե�ǰ�������н��м������м����ܴ��������ݿ�����ij�ͻ�������������С,�������Ŀ���Ҳ����м�����Ϊ������ �� ��������
-
������,������;���������;����������С,��������ͻ�ĸ������,������Ҳ��ߡ�
������:
-
��������MySQL��������������һ����,��ʾ�Ե�ǰ���������ű�����,��ʵ�ּ�,��Դ���Ľ���,����MySQL����֧�֡��ʹ�õ�MYISAM��INNODB��֧�ֱ�������������������Ϊ����������(������)�����ռд��(������)��
-
����С,������;�����������;�������ȴ�,��������ͻ�ĸ������,��������͡�
ҳ����
-
ҳ������MySQL���������Ƚ����м����ͱ������м��һ�������������ٶȿ�,����ͻ��,�м���ͻ��,���ٶ���������ȡ�����Ե�ҳ��,һ���������ڵ�һ���¼��BDB֧��ҳ����
-
�����ͼ���ʱ����ڱ���������֮��;���������;�������Ƚ��ڱ���������֮��,������һ��
MyISAM��InnoDB�洢����ʹ�õ���:
-
MyISAM������(table-level locking)��
-
InnoDB֧���м���(row-level locking)�ͱ�����,Ĭ��Ϊ�м���
3. ����������Ϸ�MySQL������Щ����?
���������������,���������������
-
������: �ֽ��������� ���û�Ҫ�������ݵĶ�ȡʱ,�����ݼ��Ϲ�����������������ͬʱ���϶����
-
������: �ֽ���д���� ���û�Ҫ�������ݵ�д��ʱ,�����ݼ�����������������ֻ���Լ�һ��,����������������,����������⡣
�������������˵�����û�����Ϊ������,һ����������,����û�һ���ǿ��Խ��ܵġ� һ������������סһ��,�����ڼ�,����������ס�Ļ����뿴���Ķ������ԡ�
��������ȡ���ھ���Ĵ洢����,InnoDBʵ�����м���,ҳ����,��������
���ǵļ��������Ӵ�С,��������Ҳ�ǴӴ�С��
4. ���ݿ���ֹ����ͱ�������ʲô?��ôʵ�ֵ�?
���ݿ����ϵͳ(DBMS)�еIJ������Ƶ�������ȷ���ڶ������ͬʱ��ȡ���ݿ���ͬһ����ʱ���ƻ�����ĸ����Ժ�ͳһ���Լ����ݿ��ͳһ�ԡ��ֹ۲�������(�ֹ���)�ͱ��۲�������(������)�Dz���������Ҫ���õļ����ֶΡ�
-
������:�ٶ��ᷢ��������ͻ,����һ�п���Υ�����������ԵIJ������ڲ�ѯ�����ݵ�ʱ��Ͱ�����������,ֱ���ύ����ʵ�ַ�ʽ:ʹ�����ݿ��е�������
-
�ֹ���:���費�ᷢ��������ͻ,ֻ���ύ����ʱ����Ƿ�Υ���������������������ݵ�ʱ�������������,ͨ��version�ķ�ʽ������������ʵ�ַ�ʽ:һ���ʹ�ð汾�Ż��ƻ�CAS�㷨ʵ��
��������ʹ�ó���:
��������������Ľ���,����֪��������������ȱ��,������Ϊһ�ֺ�����һ��,���ֹ���������д�Ƚ��ٵ������(�������),����ͻ��ĺ��ٷ�����ʱ��,��������ʡȥ�����Ŀ���,�Ӵ���ϵͳ��������������
������Ƕ�д�����,һ��ᾭ��������ͻ,��ͻᵼ���ϲ�Ӧ�û�ϵĽ���retry,���������ǽ���������,����һ���д�ij������ñ������ͱȽϺ��ʡ�
5. InnoDB�������������ôʵ�ֵ�?
InnoDB�ǻ����������������
��: select * from tab_with_index where id = 1 for update;
for update ���Ը��������������������,���� id ��������������,��� id ������������ôInnoDB����ɱ���,��������̸��
6. ʲô������?��ô���?
������ָ��������������ͬһ��Դ���ռ��,�����������Է�����Դ,�Ӷ����¶���ѭ��������
�����Ľ�������ķ���
1�������ͬ����Ტ����ȡ�����,����Լ������ͬ��˳����ʱ�,���Դ���������ᡣ
2����ͬһ��������,����������һ����������Ҫ��������Դ,����������������;
3�����ڷdz����ײ���������ҵ��,���Գ���ʹ����������������,ͨ�������������������������ĸ���;
���ҵ�������ÿ����÷ֲ�ʽ����������ʹ���ֹ���
7. ���뼶�������Ĺ�ϵ
��Read Uncommitted������,��ȡ���ݲ���Ҫ�ӹ�����,�����Ͳ�������ĵ������ϵ���������ͻ
��Read Committed������,��������Ҫ�ӹ�����,���������ִ�����Ժ��ͷŹ�����;
��Repeatable Read������,��������Ҫ�ӹ�����,�����������ύ֮ǰ�����ͷŹ�����,Ҳ���DZ���ȴ�����ִ������Ժ���ͷŹ�������
SERIALIZABLE ����������ǿ�ĸ��뼶��,��Ϊ�ü�������������Χ�ļ�,��һֱ������,ֱ��������ɡ�
8. �Ż�����������?
-
ʹ�ýϵ͵ĸ��뼶��
-
�������,����ʹ������ȥ��������,�������Ӿ�ȷ,�Ӷ���������ͻ
-
ѡ������������С,����¼��ʾ����ʱ,���һ���������㹻�������������,�����ݵĻ�,�������������,�����������빲����,��ʱ������������,�����ᵼ������
-
��ͬ�ij������һ�����ʱ��,Ӧ����Լ��һ����ͬ��˳����ʸ���,����һ��������,�����ܵĹ̶�˳��Ļ�ȡ���е��С��������ļ��������Ļ��ᡣ
-
����ʹ�����������������,�������Ա����϶���Բ��������Ӱ��
-
��Ҫ���볬��ʵ����Ҫ��������
-
���ݲ�ѯ��ʱ���DZ�Ҫ,��Ҫʹ�ü�����MySQL��MVCC����ʵ�������еIJ�ѯ���ü���,�Ż���������:MVCCֻ��committed read(���ύ)�� repeatable read (���ظ���)���ָ��뼶��
-
�����ض�������,����ʹ�ñ�������ߴ����ٶȻ��ż��������Ŀ��ܡ�
�ֿ�ֱ�
1. ΪʲôҪ�ֿ�ֱ�?
�ֱ�
�����㵥������ǧ��������,��ȷ�����ܿ�סô?���Բ���,����������̫��,�Ἣ��Ӱ����� sqlִ�е�����,���˺������ sql ���ܾ��ܵĺ����ˡ�һ����˵,�����ҵľ�������,�������������ʱ��,���ܾͻ���Բ�һЩ��,��͵÷ֱ��ˡ�
�ֱ����ǰ�һ���������ݷŵ��������,Ȼ���ѯ��ʱ����Ͳ�һ���������簴���û� id ���ֱ�,��һ���û������ݾͷ���һ�����С�Ȼ�������ʱ�����һ���û��Ͳ����Ǹ����ͺ��ˡ��������Կ���ÿ�������������ڿɿصķ�Χ��,����ÿ�����̶��� 200 �����ڡ�
�ֿ�
�ֿ������һ����һ�����Ǿ������,���֧�ŵ����� 2000,һ��Ҫ������,����һ�������ĵ��Ⲣ��ֵ����ñ�����ÿ�� 1000 ����,��Ҫ̫����ô����Խ�һ��������ݲ�ֵ��������,���ʵ�ʱ��ͷ���һ������ˡ�

MYSQL�Ż�
��һ:ѡ������ʵ��ֶ����ԡ�
mysql�ڴ������ݿ��ʱ��϶������ݿ��еı�ԽСԽ��,����������߲�ѯ���ٶȡ�������ʵ������������,ÿ����ܲ������������������������ʮ��Ϊ��λ��,��ʱ��Ҫ��ֵؿ����ڽ���ʱ���ֶγ����ˡ�����˵�ڴ洢�绰�ŵ�ʱ��,�������д��CHAR(255),����Ȼ������ݿ�����ܶ��Ҫ�Ŀռ��˷�,����CHAR(11)�Ϳ��Խ�������⡣
�ڶ�:ʹ�����Ӳ�ѯ(join)�����Ӳ�ѯ��
�Ӳ�ѯ���ŵ��ǿ���ʹ�ü�SELECT���Ϳ����������Ϊ���ӵIJ�ѯ����,���һ��ܱ������������������������ʱҲ���Կ���ʹ�����Ӳ�ѯ�����,�Ͼ����Ӳ�ѯ����Ҫ���Ӳ�ѯһ�����ڴ��д�����ʱ��,�ٴ���ʱ���й�������,�Ӷ��ӿ��ѯ�ٶȡ�
����:ʹ��union���ϲ�ѯ��
union�����������ϵĺ���,�����Խ����SELECT���IJ�ѯ������ϵ�һ����ѯ��,�Ӷ�������ֶ�������ʱ���Ĺ��̡�����union����һ���ô�����ʹ�������Ժ��Զ���ɾ����,һ��Ҳ��ռ���ڴ�ռ䡣�����ǡ����˷���ȥ,ƬҶ��մ����ѽ��
Ҫ��ѯ�Ľ�������ڶ����,�Ҷ����û��ֱ�ӵ����ӹ�ϵ,����ѯ����Ϣһ��ʱ
�ص�:��
1��Ҫ�������ѯ���IJ�ѯ������һ�µ�!
2��Ҫ�������ѯ���IJ�ѯ��ÿһ�е����ͺ�˳�����һ��
3��union�ؼ���Ĭ��ȥ��,���ʹ��union all �������ظ���
����:ͨ��������������
���������ݿ����ʱ��һ��������̸�ĸ���,������4������,�����Dz��ɱ���ĵ��ŷ�ʽ֮һ,�����Ա�֤���ݵ������ԡ�һ���ԡ�������һ�仰���ܽᡰȥ�����յ�,�Ǿͻص�ԭ�㡣
����:��������
���������ܹ���֤���ݿ�������Ժ�һ����,������������ʵҲ����һЩ�ˡ���Ϊ����������һ���Ķ�ռ��,������û��ִ�������ǰ,�û�����������������ֻ�ܵȴ�,һֱ�ȵ����е��������˲��ܼ���ִ�С�����û��������ر���ʱ��,������ϵͳ�������ӳ����⡣
���Կ���ͨ���������ķ���,��֤��û��ִ�е�UNLOCKTABLESָ��֮ǰ���б�LOCKTABLE���εر��IJ�ѯ��䲻�ᱻ���롢ɾ�����ġ�
����:����ʹ�������
����������ڵ����þ��DZ�֤�����֮��IJ���������,ʹ�����������Ч����������֮��Ĺ����ԡ�
����:��ȷʹ��������
������������ݿ����ܵ�����ķ���,�ܹ���ȷ��ʹ������,�ܹ�������߲�ѯЧ�ʡ�
����Ҳ���ܹ�Ϊ���е��ж���������,��Ϊ��������ռ���ڴ�,ά������Ҳ���鷳,������һ��˫�н�,����������ʹ�õ�ʱ����Ҫ����ʵ�������ȷʹ�ò��С�
�ڰ�:�Ż���ѯ��䡣
һ���õIJ�ѯ����ܹ������Ե���߲�ѯЧ��,��֮�ͻ����������Dz��dz���д���ˡ�
��ôʲô��������ѯ������Ǻõ���?���Բο����¼���Ҫ��
1���ڱȽϵ�ʱ��������ͬ���ֶ�֮����бȽϡ����粻�ܽ�һ������������INT�ֶκ�BIGINT�ֶν��бȽϡ�
2���ѽ��������������ֶ��ϲ�Ҫʹ�ú���,�����ᵼ������ʧЧ��
3����ѯʱ������ʹ��like����ѯ,��Ϊ�ǻ����ĵ�һ����ϵͳ������
����Redis
����
1. Redis��ʲô?����������ȱ��?
Redis��������һ��Key-Value���͵��ڴ����ݿ�,����Memcached,�������ݿ�������ڴ浱�в���,����ͨ���첽���������ݿ��е�����flush��Ӳ���Ͻ��б��档
��Ϊ�Ǵ��ڴ����,Redis�����ܷdz���ɫ,ÿ����Դ������� 10��ζ�д����,����֪��������Key-Value ���ݿ�
�ŵ�:
-
��д���ܼ���, Redis�ܶ����ٶ���110000��/s,д���ٶ���81000��/s��
-
֧�����ݳ־û�,֧��AOF��RDB���ֳ־û���ʽ��
-
֧������, Redis�����в�������ԭ���Ե�,��˼����Ҫô�ɹ�ִ��Ҫôʧ����ȫ��ִ��������������ԭ���Եġ��������Ҳ֧������,��ԭ����,ͨ��MULTI��EXECָ���������
-
���ݽṹ�ḻ,����֧��string���͵�value��,��֧��hash��set��zset��list�����ݽṹ��
-
֧�����Ӹ���,�������Զ�������ͬ�����ӻ�,���Խ��ж�д���롣
-
�ḻ������ �C Redis��֧�� publish/subscribe, ֪ͨ, key ���ڵ����ԡ�
ȱ��:
-
���ݿ������ܵ������ڴ������,���������������ݵĸ����ܶ�д,���Redis�ʺϵij�����Ҫ�����ڽ�С�������ĸ����ܲ����������ϡ�
-
����崻�,崻�ǰ�в�������δ�ܼ�ʱͬ�����ӻ�,�л�IP���������ݲ�һ�µ�����,������ϵͳ�Ŀ�����
2. RedisΪʲô��ô��?
-
**�ڴ�洢:**Redis��ʹ���ڴ�(in-memeroy)�洢,û�д���IO�ϵĿ��������ݴ����ڴ���,������HashMap,HashMap �����ƾ��Dz��ҺͲ�����ʱ�临�Ӷȶ���O(1)��
-
���߳�ʵ��( Redis 6.0��ǰ):Redisʹ�õ����̴߳�������,�����˶���߳�֮���߳��л�������Դ���õĿ�����ע��:���߳���ָ�����ں�������ģ����,��������ģ��ʹ��һ���߳�������,��һ���̴߳���������������
-
������IO:Redisʹ�ö�·����IO����,��epoll��ΪI/O��·���ü�����ʵ��,�ټ���Redis�������¼�����ģ�ͽ�epoll�е����ӡ���д���رն�ת��Ϊ�¼�,��������I/O���˷ѹ����ʱ�䡣
-
�Ż������ݽṹ:Redis��������ֱ��Ӧ�õ��Ż����ݽṹ��ʵ��,Ӧ�ò����ֱ��ʹ��ԭ�������ݽṹ��������
6. Redis�ij��ó�������Щ?
1������
�������ڼ����������д�����վ�����õı�ɱ��,���������û��治���ܹ�������վ�����ٶ�,���ܴ�
�����ݿ��ѹ����Redis�ṩ�˼����ڹ���,Ҳ�ṩ�����ļ���̭����,����,����Redis���ڻ�
��ij��Ϸdz��ࡣ
2�����а�
�ܶ���վ�������а�Ӧ�õ�,�義�����¶���������Ʒ��ʱ����������а�ȡ�Redis�ṩ������
���������ʵ�ָ��ָ��ӵ����а�Ӧ�á�
3��������
ʲô�Ǽ�����,�������վ��Ʒ�����������Ƶ��վ��Ƶ�IJ������ȡ�Ϊ�˱�֤����ʵʱЧ,ÿ��������ø�+1,��������ʱ���ÿ�ζ��������ݿ��������������ս��ѹ����Redis�ṩ��incr������ʵ�ּ���������,�ڴ����,���ܷdz���,�dz���������Щ����������
4���ֲ�ʽ�Ự
��Ⱥģʽ��,��Ӧ�ò���������һ��ʹ�������Դ���session���ƹ��ܾ�������,��Ӧ��������Ը��ӵ�ϵͳ��,һ�㶼����Redis���ڴ����ݿ�Ϊ���ĵ�session����,session��������������,������session�����ڴ����ݿ������
5���ֲ�ʽ��
�ںܶ������˾�ж�ʹ���˷ֲ�ʽ����,�ֲ�ʽ���������ļ�����ս�Ƕ�ͬһ����Դ�IJ�������,��ȫ��ID������桢��ɱ�ȳ���,����������ij�������ʹ�����ݿ�ı��������ֹ�����ʵ��,���ڲ������ߵij�����,�������ݿ�����������Դ�IJ��������Dz�̫�����,���Ӱ�������ݿ�����ܡ���������Redis��setnx��������д�ֲ�ʽ����,������÷���1˵����ȡ���ɹ�,�����ȡ��ʧ��,ʵ��Ӧ����Ҫ���ǵ�ϸ��Ҫ���ࡣ
6�� �罻����
���ޡ��ȡ���ע/����ע����ͬ���ѵ����罻��վ�Ļ�������,�罻��վ�ķ�����ͨ����˵�Ƚϴ�,���Ҵ�ͳ�Ĺ�ϵ���ݿ����Ͳ��ʺϴ洢�������͵�����,Redis�ṩ�Ĺ�ϣ�����ϵ����ݽṹ�ܷܺ���ĵ�ʵ����Щ���ܡ��������еĹ�ͬ����,ͨ��Redis��set�ܹ��ܷ���ó���
7�������б�
Redis�б��ṹ,LPUSH�������б�ͷ������һ������ID��Ϊ�ؼ���,LTRIM�����������б�������,�����б���ԶΪN��ID,�����ѯ���µ��б�,ֱ�Ӹ���IDȥ����Ӧ������ҳ���ɡ�
8����Ϣϵͳ
��Ϣ�����Ǵ�����վ�����м��,��ActiveMQ��RabbitMQ��Kafka�����е���Ϣ�����м��,��Ҫ��
��ҵ�����������弰�첽����ʵʱ�Ե͵�ҵ��Redis�ṩ�˷���/���ļ��������й���,��ʵ��һ������Ϣ����ϵͳ������,������ܺ�רҵ����Ϣ�м����ȡ�
7. Redis��������������Щ?
�����ֳ�����������:String��Hash��Set��List��SortedSet���Լ������������������:Bitmap��
HyperLogLog��Geospatial ,����HyperLogLog��Bitmap�ĵײ㶼�� String ��������,Geospatial ��
�ײ��� Sorted Set �������͡�
���ֳ��õ���������:
1��String:String����õ�һ����������,��ͨ��key- value �洢�����Թ�Ϊ���ࡣ����Value�ȿ���������Ҳ�������ַ�����ʹ�ó���:����key-value����Ӧ�á��������: ����, ��˿����
2��Hash:Hash ��һ����ֵ(key => value)�Լ��ϡ�Redishash ��һ�� string ���͵� field �� value ��
ӳ���,hash �ر��ʺ����ڴ洢����,���ҿ��������ݿ���updateһ������һ��ֻ��ijһ������
ֵ��
3��Set:Set��һ���������Ȼȥ�صļ���,��Key-Set������ṩ�˽�����������һϵ��ֱ�Ӳ������ϵķ���,������ͬ���ѡ���ͬ��עʲô�Ĺ���ʵ���ر㡣
4��List:List��һ��������ظ��ļ���,����ѭFIFO��ԭ��,�ײ�������˫������ʵ�ֵ�,���֧��������˫�ز��ҡ�ͨ��List,���ǿ��Ժܷ���Ļ�����������»ظ�����Ĺ���ʵ�֡�
5��SortedSet:������java�е�TreeSet,��Set�Ŀ�����档���֧�����ȼ�����,ά����һ��score�IJ�����ʵ�֡����������а�ʹ�Ȩ�ص���Ϣ���еȳ�����
�־û�
1. Redis�־û�����
��.spring
1. ʹ��Spring��ܵĺô���ʲô?
-
����:Spring ��������,�����İ汾��Լ2MB
-
���Ʒ�ת:Springͨ�����Ʒ�תʵ������ɢ���,�����Ǹ������ǵ�����,�����Ǵ�������������Ķ�����
-
��������ı��(AOP):Spring֧����������ı��,���Ұ�Ӧ��ҵ������ϵͳ����ֿ�
-
����:Spring ����������Ӧ���ж�����������ں�����
-
MVC���:Spring��WEB����Ǹ�������ƵĿ��,��Web��ܵ�һ���ܺõ����Ʒ
-
�������:Spring �ṩһ����������������ӿ�,������չ������������������ȫ������(JTA)
-
�쳣����:Spring �ṩ�����API�Ѿ��弼����ص��쳣(������JDBC,Hibernate or JDO�׳���)ת��Ϊһ�µ�unchecked �쳣��
2. ʲô�� Spring IOC ����?
Spring ��ܵĺ����� Spring ������������������,������װ����һ��,�������Dz��������ǵ�������
��������Spring ����ʹ������ע�����������Ӧ�ó�������������ͨ����ȡ�ṩ������Ԫ����������
�������ʵ����,���ú���װ��ָ���Ԫ���ݿ���ͨ�� XML,Java ע��� Java �����ṩ��
3. ʲô������ע��?����ͨ�������ַ�ʽ�������ע��?
������ע����,�����ش�������,������������δ������ǡ�������ֱ���ڴ����н�����ͷ���������
һ��,�������������ļ�����Щ�����Ҫ��Щ������ IoC ����������װ����һ��
ͨ��,����ע�����ͨ�����ַ�ʽ���,��:
-
���캯��ע��
-
setter ע��
-
�ӿ�ע��
�� Spring Framework ��,��ʹ�ù��캯���� setter ע�롣
4. ���� BeanFactory �� ApplicationContext?
IOC�����Ķ�����Ľӿھ������ǵ�BeanFactory,����ְ�����:ʵ��������λ������Ӧ�ó����еĶ�������Щ������������BeanFactoryֻ�Ǹ��ӿ�,������IOC�����ľ���ʵ��,����Spring���������˺ܶ���ʵ��,�� DefaultListableBeanFactory��XmlBeanFactory��ApplicationContext��
BeanFactory��ApplicationContext����spring��ܵ�����IOC����,����һ��ʹ��ApplicationnContext,�䲻��������BeanFactory������,ͬʱ�����и������չ��
BeanFacotry��spring�бȽ�ԭʼ��Factory����XMLBeanFactory����һ�ֵ��͵�BeanFactory��
ԭʼ��BeanFactory��֧��spring��������,��AOP���ܡ�WebӦ�õ���
ApplicationContext����BeanFactory�����й���,ͨ�������BeanFactory����
ApplicationContext��һ�ָ��������ܵķ�ʽ�����Լ��������Ľ��зֲ��ʵ�ּ̳�,ApplicationContext�����ṩ�����µĹ���:
? MessageSource, �ṩ���ʻ�����Ϣ����
? ��Դ����,��URL���ļ�
? �¼�����
? ������(�м̳й�ϵ)������ ,ʹ��ÿһ�������Ķ�רע��һ���ض��IJ��,����Ӧ�õ�web��;
BeanFactory����ȱ��:
-
�ŵ�:Ӧ��������ʱ��ռ����Դ����,����ԴҪ��ϸߵ�Ӧ��,�Ƚ�������;
-
ȱ��:�����ٶȻ������˵��һЩ�������п��ܻ���ֿ�ָ���쳣�Ĵ���,����ͨ��Bean������
����Bean�������ڻ��һЩ��
ApplicationContext����ȱ��:
- �ŵ�:���е�Bean��������ʱ�����˼���,ϵͳ���е��ٶȿ�;��ϵͳ������ʱ��,���Է�
��ϵͳ�е��������⡣
- ȱ��:�ѷ�ʱ�IJ����ŵ�ϵͳ���������,���еĶ�����Ԥ����,ȱ������ڴ�ռ�ýϴ�
5. ���ֹ��캯��ע��� setter ע��
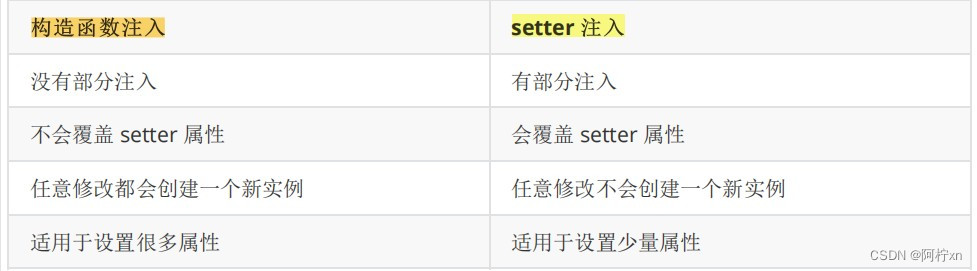
7. Spring �е� bean ������������Щ**?**
-
singleton : Ψһ bean ʵ��,Spring �е� bean Ĭ�϶��ǵ����ġ�
-
prototype : ÿ�����ᴴ��һ���µ� bean ʵ����
-
request : ÿһ��HTTP�������һ���µ�bean,��bean���ڵ�ǰHTTP request����Ч��
-
session : :��һ��HTTP Session��,һ��Bean�����Ӧһ��ʵ��������������ڻ���web��
Spring ApplicationContext����������
- global-session: ȫ��session������,�����ڻ���portlet��webӦ���в�������,Spring5�Ѿ�û
���ˡ�Portlet���ܹ������������(����:HTML)Ƭ�ε�С��Java Web��������ǻ���portlet��
��,������servletһ������HTTP������,�� servlet ��ͬ,ÿ�� portlet ���в�ͬ�ĻỰ
8. �������IoC��DI?
IOC���ǿ��Ʒ�ת,ͨ��˵�������Dz����Լ�����ʵ������,��Щ������Spring��bean���������Ǵ�
����������Ҳ��Spring�ĺ���˼��,ͨ������ӿڱ�̵ķ�ʽ����ʵ�ֶ�ҵ������Ķ�̬�����������
ζ��IOC��Spring��Խ��������϶����ڵġ���ʵ��Ӧ����,Springͨ�������ļ�(xml����
properties)ָ����Ҫʵ������java��(�����������ַ���),������Щjava���һ���ʼ��ֵ,ͨ����
�ض�ȡ�����ļ�,��Spring�ṩ�ķ���(getBean())�Ϳ��Ի�ȡ��������Ҫ�ĸ���ָ�����ý��г�ʼ��
��ʵ������
- �ŵ�:IOC������ע�������Ӧ�ó���Ĵ���������ʹ��Ӧ�ó���IJ��Ժܼ�,��Ϊ�ڵ�Ԫ����
�в�����Ҫ������JNDI���һ��ơ���ʵ���Լ����ٵĸ��Ż���ʹ������ϵ���ʵ�֡�IOC����
֧�����Ե������ӳټ��ط���
DI:DI��Dependency Injection,��������ע�롱:���֮��������ϵ�������������ھ���,�����˵,
����������̬�Ľ�ij��������ϵע�뵽���֮�С�����ע���Ŀ�IJ���Ϊ����ϵͳ���������,����
Ϊ������������õ�Ƶ��,��Ϊϵͳ�һ��������չ��ƽ̨��ͨ������ע�����,����ֻ��Ҫͨ
��������,�������κδ���Ϳ�ָ��Ŀ����Ҫ����Դ,���������ҵ����,������Ҫ���ľ����
��Դ���Ժδ�,��˭ʵ�֡�
9. ��һ��������ΪSpring�� bean ��ע������Щ**?**
����һ��ʹ�� @Autowired ע���Զ�װ�� bean,Ҫ������ʶ�ɿ����� @Autowired ע���Զ�װ���
bean ����,��������ע���ʵ��:
- @Component :ͨ�õ�ע��,�ɱ�ע������Ϊ Spring ��������һ��Bean��֪�������ĸ���,
����ʹ��@Component ע���ע��
-
@Repository : ��Ӧ�־ò㼴 Dao ��,��Ҫ�������ݿ���ز�����
-
@Service : ��Ӧ�����,��Ҫ�漰һЩ���ӵ���,��Ҫ�õ� Dao�㡣
-
@Controller : ��Ӧ Spring MVC ���Ʋ�,��Ҫ�û������û������� Service �㷵�����ݸ�ǰ��ҳ�档
10. spring ֧�ּ��� bean scope?
Spring bean ֧�� 5 �� scope:
-
Singleton - ÿ�� Spring IoC ��������һ����ʵ����
-
Prototype - ÿ���������һ���µ�ʵ����
-
Request - ÿһ�� HTTP �������һ���µ�ʵ��,���Ҹ� bean ���ڵ�ǰ HTTP ��������Ч��
-
Session - ÿһ�� HTTP �������һ���µ� bean,ͬʱ�� bean ���ڵ�ǰ HTTP session ����Ч��
-
Global-session - �����ڱ��� HTTP Session ������,�����������ڻ��� portlet �� web Ӧ����
�������塣Portlet �淶������ȫ�� Session �ĸ���,�������й���ij�� portlet web Ӧ�õĸ���
��ͬ�� portlet ���������� global session �������ж���� bean ������ȫ�� portlet Session ��
�������ڷ�Χ�ڡ�������� web ��ʹ�� global session ����������ʶ bean,��ô web ���Զ���
�� session ������ʹ�á�
�����û�ʹ��֧�� Web �� ApplicationContext ʱ,��������ſ��á�
13. ʲô�� spring װ��?
�� bean �� Spring �����������һ��ʱ,������Ϊװ��� bean װ�䡣 Spring ������Ҫ֪����Ҫʲô
bean �Լ�����Ӧ�����ʹ������ע������ bean ����һ��,ͬʱװ�� bean��
Spring �����ܹ��Զ�װ�� bean��Ҳ����˵,����ͨ����� BeanFactory �������� Spring �Զ�����
bean ��Э���ߡ�
�Զ�װ��IJ�ͬģʽ:
-
no - ����Ĭ������,��ʾû���Զ�װ�䡣Ӧʹ����ʽ bean ���ý���װ�䡣
-
byName - ������ bean ������ע������������ƥ�䲢װ���������� XML �ļ�������ͬ���ƶ���� bean��
-
byType - ����������ע����������������Ե������� XML �ļ��е�һ�� bean ����ƥ��,��ƥ�䲢װ�����ԡ�
-
���캯�� - ��ͨ��������Ĺ��캯����ע����������д����IJ�����
-
autodetect - ������������ͨ�����캯��ʹ�� autowire װ��,�������,����ͨ�� byType �Զ�װ��
14. �Զ�װ����ʲô����?
15. Spring�г���ͬ��bean��ô��?
-
ͬһ�������ļ���ͬ����Bean,�������涨���Ϊ
-
��ͬ�����ļ��д���ͬ��Bean,������������ļ��Ḳ���Ƚ����������ļ�
-
ͬ�ļ���ComponentScan��@Bean����ͬ��Bean��ͬ�ļ���@Bean�Ļ���Ч,
@ComponentScanɨ�����������Ч��ͨ��@ComponentScanɨ����������ȼ�����͵�,ԭ��
������ɨ�������Bean���������ȱ�ע���
16. Spring ��ô���ѭ����������?
17. Spring �еĵ��� bean ���̰߳�ȫ����?
18. ʲô�� AOP?
AOP(Aspect-Oriented Programming), �� ����������, ���� OOP( Object-Oriented Programming,
���������) �ศ���, �ṩ���� OOP ��ͬ�ij��������ṹ���ӽ�.
�� OOP ��, ��������(class)��Ϊ���ǵĻ�����Ԫ, �� AOP �еĻ�����Ԫ�� Aspect(����)
19. AOP ����Щʵ�ַ�ʽ?
ʵ�� AOP �ļ���,��Ҫ��Ϊ������:
-
��̬���� - ָʹ�� AOP ����ṩ��������б���,�Ӷ��ڱ���ξͿ����� AOP ������,���Ҳ��Ϊ����ʱ��ǿ;
- ����ʱ��֯(���������ʵ��)
- �����ʱ��֯(������������ʵ��)��
-
��̬���� - ������ʱ���ڴ��С���ʱ������ AOP ��̬������,���Ҳ����Ϊ����ʱ��ǿ��
- JDK ��̬����:ͨ�����������ձ���������,����Ҫ�����������ʵ��һ���ӿ� ��JDK��̬�����ĺ����� InvocationHandler �ӿں� Proxy �� ��
-
CGLIB ��̬����: ���Ŀ����û��ʵ�ֽӿ�,��ô Spring AOP ��ѡ��ʹ�� CGLIB ����̬����Ŀ���� �� CGLIB ( Code Generation Library ),��һ���������ɵ����,����������ʱ��̬������ij���������,ע��, CGLIB ��ͨ���̳еķ�ʽ���Ķ�̬����,������ij���౻���Ϊ final ,��ô������ʹ�� CGLIB ����̬�����ġ�
20. Spring AOP and AspectJ AOP ��ʲô����?
Spring AOP ���ڶ�̬������ʽʵ��;AspectJ ���ھ�̬������ʽʵ�֡�
Spring AOP ��֧�ַ�������� PointCut;�ṩ����ȫ�� AOP ֧��,����֧�����Լ���� PointCut��
21. Spring ������õ�����Щ���ģʽ?
-
�������ģʽ : Springʹ�ù���ģʽͨ�� BeanFactory �� ApplicationContext ���� bean ����
-
�������ģʽ : Spring AOP ���ܵ�ʵ�֡�
-
�������ģʽ : Spring �е� Bean Ĭ�϶��ǵ����ġ�
-
ģ�巽��ģʽ : Spring �� jdbcTemplate �� hibernateTemplate ���� Template ��β�Ķ����ݿ��������,���Ǿ�ʹ�õ���ģ��ģʽ��
-
��װ�����ģʽ : ���ǵ���Ŀ��Ҫ���Ӷ�����ݿ�,���Ҳ�ͬ�Ŀͻ���ÿ�η����и�����Ҫ��ȥ���ʲ�ͬ�����ݿ⡣����ģʽ�����ǿ��Ը��ݿͻ��������ܹ���̬�л���ͬ������Դ��
-
�۲���ģʽ: Spring �¼�����ģ�;��ǹ۲���ģʽ�ܾ����һ��Ӧ�á�
-
������ģʽ :Spring AOP ����ǿ��֪ͨ(Advice)ʹ�õ���������ģʽ��spring MVC ��Ҳ���õ���������ģʽ���� Controller ��
22. Spring ����ʵ�ַ�ʽ����Щ?
���ʽ�������:����ζ�������ͨ����̵ķ�ʽ��������,���ַ�ʽ�����˺ܴ�������,������ά����
����ʽ�������:���ַ�ʽ��ζ������Խ����������ҵ�������롣��ֻ��Ҫͨ��ע�����XML���ù�������
23. Spring��ܵ������������Щ�ŵ�?
-
���ṩ�˿粻ͬ����api(��JTA��JDBC��Hibernate��JPA��JDO)��һ�±��ģ�͡�
-
��Ϊ�����������ṩ�˱�JTA�����ิ������API����API��
-
��֧������ʽ���������
-
���ܺõؼ�����Spring�ĸ������ݷ��ʳ���
24. spring������Ĵ�������
- PROPAGATION_REQUIRED: ֧�ֵ�ǰ����,�����ǰû������,���½�һ���������������
ѡ��
-
PROPAGATION_SUPPORTS: ֧�ֵ�ǰ����,�����ǰû������,���Է�����ʽִ�С�
-
PROPAGATION_MANDATORY: ֧�ֵ�ǰ����,�����ǰû������,���׳��쳣��
-
PROPAGATION_REQUIRES_NEW: �½�����,�����ǰ��������,�ѵ�ǰ�������
-
PROPAGATION_NOT_SUPPORTED: �Է�����ʽִ�в���,�����ǰ��������,�Ͱѵ�ǰ�������
-
PROPAGATION_NEVER: �Է�����ʽִ��,�����ǰ��������,���׳��쳣��
-
PROPAGATION_NESTED:�����ǰ��������,����Ƕ��������ִ�С������ǰû������,�������PROPAGATION_REQUIRED���ƵIJ�����
25. SpringMVC ����ԭ���˽���?
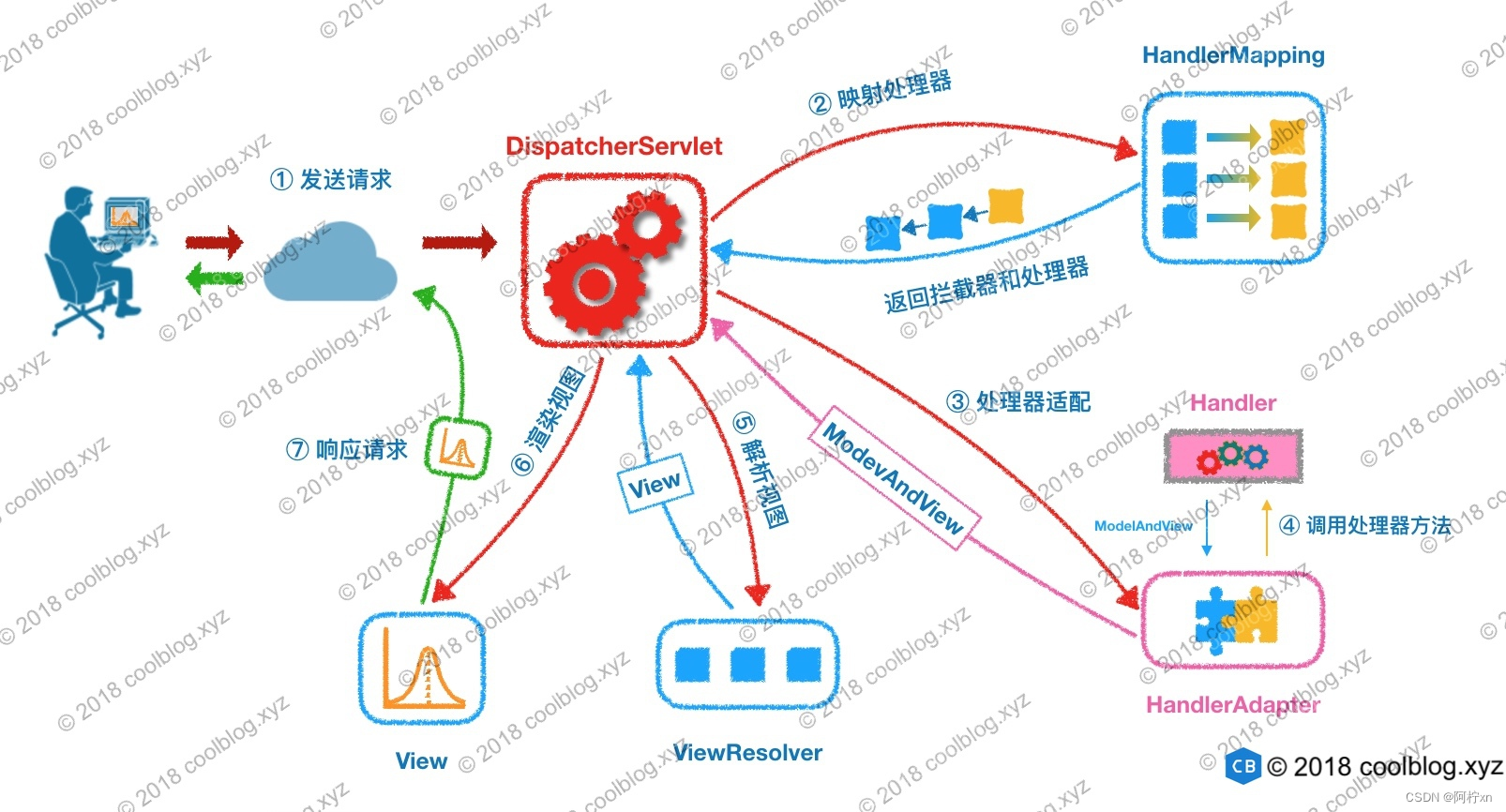
�� �û�����������ǰ�˿�����DispatcherServlet��
�� DispatcherServlet�յ��������HandlerMapping������ӳ������
�� ������ӳ�����ҵ�����Ĵ�����(���Ը���xml���á�ע����в���),���ɴ�������������������(���
��������)һ�����ظ�DispatcherServlet��
�� DispatcherServlet����HandlerAdapter��������������
�� HandlerAdapter����������þ���Ĵ�����(Controller,Ҳ�к�˿�����)��
�� Controllerִ����ɷ���ModelAndView��
�� HandlerAdapter��controllerִ�н��ModelAndView���ظ�DispatcherServlet��
�� DispatcherServlet��ModelAndView����ViewReslover��ͼ��������
�� ViewReslover�����ؾ���View��
�� DispatcherServlet����View������Ⱦ��ͼ(����ģ�������������ͼ��)��DispatcherServlet��Ӧ�û���
27. @Controller ע����ʲô��?
@Controller ע����һ����Ϊ Spring Web MVC ������ Controller��Spring MVC �Ὣɨ�赽��ע
�����,Ȼ��ɨ�������������� @RequestMapping ע��ķ���,����ע����Ϣ,Ϊ�����������һ
����Ӧ�Ĵ���������,������� HandlerMapping �� HandlerAdapter����н�������
��Ȼ,�������� @Controller ע�����ַ�ʽ����,�㻹����ʵ�� Spring MVC �ṩ�� Controller ��
�� HttpRequestHandler �ӿ�,��Ӧ��ʵ����Ҳ�ᱻ��Ϊһ������������
28. @RequestMapping ע����ʲô��?
@RequestMapping ע��,�������Ѿ�������,���ô������� HTTP ����,URI����Ϣ,��������
������ͷ�������ӳ�������ע�����������������,Ҳ���������ڷ�������,��������һ����������
���������� URI ǰ
29. @RestController �� @Controller ��ʲô����?
@RestController ע��,�� @Controller ������,������ @ResponseBody ע��,�����ʺ�Ŀǰǰ
��˷���ļܹ���,�ṩ Restful API ,�������� JSON ���ݸ�ʽ����Ȼ,����ʲô�������ݸ�ʽ,����
�ͻ��˵� ACCEPT ����ͷ��������
30. @RequestMapping �� @GetMapping ע��IJ�֮ͬ ��������?
-
@RequestMapping :��ע������ͷ�����; @GetMapping ����ע���ڷ�����
-
@RequestMapping :�ɽ��� GET��POST��PUT��DELETE ������; @GetMapping �� @RequestMapping �� GET ����������,Ŀ����Ϊ����������ȡ�
31. @RequestParam �� @PathVariable ����ע�������
����ע�ⶼ���ڷ�������,��ȡ����ֵ�ķ�ʽ��ͬ, @RequestParam ע��IJ���������Я���IJ����л�ȡ,�� @PathVariable ע�������� URI �л�ȡ
32. ���� JSON ��ʽʹ��ʲôע��?
����ʹ�� @ResponseBody ע��,����ʹ�ð��� @ResponseBody ע��� @RestController ע�⡣
��Ȼ,������Ҫ�����Ӧ��֧�� JSON ��ʽ���� HttpMessageConverter ʵ���ࡣ����,Spring MVC
Ĭ��ʹ�� MappingJackson2HttpMessageConverter
33. ʲô��springmvc�������Լ����ʹ����?
Spring�Ĵ�������ӳ����ư�����������������,����ϣ�����ض�����Ӧ����ijЩ����ʱ,����,����û�����ʱ,��Щ�������dz����á�����������ʵ��org.springframework.web.servlet����HandlerInterceptor���˽ӿڶ��������ַ���:
-
preHandle:��ִ��ʵ�ʴ�������֮ǰ���á�
-
postHandle:��ִ����ʵ�ʳ���֮����á�
-
afterCompletion:������������á�
34. Spring MVC �� Struts2 ����ͬ?
39. ΪʲôҪ��SpringBoot?
��ʹ��Spring��ܽ��п����Ĺ�����,��Ҫ���úܶ�Spring��ܰ�������,��spring-core��springbean��spring-context��,����Щ����ͨ�������ظ����ӵ�,������Ҫ���ܶ���ʹ�ü������������ظ�����,�翪��ע�⡢������־�ȡ�Spring Boot������������Щ����Ҫ�IJ���,�ṩĬ������,��Ȼ��ЩĬ�������ǿ������ĵ�,���ٴ������������SpringӦ�á�
������ʹ��SpringBoot��һЩ�ô�:
-
�Զ�����,ʹ�û�����·����Ӧ�ó��������ĵ�����Ĭ��ֵ,��ȻҲ���Ը�����Ҫ��д���������㿪����Ա������
-
����Spring Boot Starter ��Ŀʱ,����ѡ��ѡ����Ҫ�Ĺ���,Spring Boot��Ϊ�����������ϵ��
-
SpringBoot��Ŀ���Դ����jar�ļ�������ʹ��Java-jar����������н�Ӧ�ó�����Ϊ������JavaӦ�ó������С�
-
�ڿ���webӦ�ó���ʱ,springboot������һ��Ƕ��ʽTomcat������,�Ա���������Ϊ������Ӧ�ó������С�(Tomcat��Ĭ�ϵ�,��Ȼ��Ҳ��������Jetty��Undertow)
-
SpringBoot�����������õķǹ�������(���簲ȫ�ͽ������)��
41. Spring Boot �ĺ���ע�����ĸ�?����Ҫ���ļ���ע����ɵ�?
�����������ע����@SpringBootApplication,��Ҳ�� Spring Boot �ĺ���ע��,��Ҫ��ϰ���������
3 ��ע��:
@SpringBootConfiguration:����� @Configuration ע��,ʵ�������ļ��Ĺ��ܡ�
@EnableAutoConfiguration:���Զ����õĹ���,Ҳ���Թر�ij���Զ����õ�ѡ��,��ر�����Դ
�Զ����ù���: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })��
@ComponentScan:Spring���ɨ�衣
42. ��������� Spring Boot �е� Starters?
Starters��������Ϊ������,��������һϵ�п��Լ��ɵ�Ӧ�������������,�����һվʽ���� Spring����������,������Ҫ������ʾ���������������������ʹ�� Spring JPA �������ݿ�,ֻҪ����spring-boot-starter-data-jpa ��������������ʹ���ˡ�
Starters������������Ŀ����Ҫ�õ�������,�����ܿ��ٳ���������,����һϵ�еõ�֧�ֵĹ���������������
�ˡ�MyBatis
1. MyBatis��ʲô?
-
Mybatis��һ����ORM(�����ϵӳ��)���,���ڲ���װ��JDBC,�����������������ӡ�����statement�ȷ��ӵĹ���,�����߿���ʱֻ��Ҫ��ע��α�дSQL���,�����ϸ����sqlִ������,���ȸߡ�
-
��Ϊһ����ORM���,MyBatis ����ʹ�� XML ��ע�������ú�ӳ��ԭ����Ϣ,�� POJOӳ������ݿ��еļ�¼,�����˼������е� JDBC ������ֶ����ò����Լ���ȡ�������
-
ͨ��xml �ļ���ע��ķ�ʽ��Ҫִ�еĸ��� statement ��������,��ͨ��java����� statement��sql�Ķ�̬��������ӳ����������ִ�е�sql���,�����mybatis���ִ��sql�������ӳ��Ϊjava�����ء�(��ִ��sql������result�Ĺ���)��
-
����MyBatisרע��SQL����,���ȸ�,���ԱȽ��ʺ϶����ܵ�Ҫ��ܸ�,��������仯�϶����Ŀ,�绥������Ŀ��
2. Mybaits����ȱ��
�ŵ�:
-
����SQL�����,�൱���,�����Ӧ�ó���������ݿ�������������κ�Ӱ��,SQLд��XML��,���sql������������,����ͳһ����;�ṩXML��ǩ,֧�ֱ�д��̬SQL���,�������á�
-
��JDBC���,������50%���ϵĴ�����,������JDBC��������Ĵ���,����Ҫ�ֶ���������;
-
�ܺõ���������ݿ����(��ΪMyBatisʹ��JDBC���������ݿ�,����ֻҪJDBC֧�ֵ����ݿ�MyBatis��֧��)��
-
�ܹ���Spring�ܺõļ���;
-
�ṩӳ���ǩ,֧�ֶ��������ݿ��ORM�ֶι�ϵӳ��;�ṩ�����ϵӳ���ǩ,֧�ֶ����ϵ���ά����
ȱ��:
-
SQL���ı�д�������ϴ�,���䵱�ֶζࡢ��������ʱ,�Կ�����Ա��дSQL���Ĺ�����һ��Ҫ��
-
SQL������������ݿ�,�������ݿ���ֲ�Բ�,��������������ݿ⡣
3. Ϊʲô˵Mybatis�ǰ��Զ�ORMӳ�乤��?����ȫ�Զ�������������?
Hibernate����ȫ�Զ�ORMӳ�乤��,ʹ��Hibernate��ѯ����������߹������϶���ʱ,���Ը��ݶ���
��ϵģ��ֱ�ӻ�ȡ,��������ȫ�Զ��ġ�
��Mybatis�ڲ�ѯ���������������϶���ʱ,��Ҫ�ֶ���дsql�����,����,��֮Ϊ���Զ�ORMӳ��
���ߡ�
4. Hibernate �� MyBatis ������
��ͬ��:���Ƕ�jdbc�ķ�װ,���dz־ò�Ŀ��,������dao��Ŀ�����
��ͬ��
1��ӳ���ϵ
MyBatis ��һ�����Զ�ӳ��Ŀ��,����Java������sql���ִ�н���Ķ�Ӧ��ϵ,���������ϵ���ü�
����
Hibernate ��һ��ȫ��ӳ��Ŀ��,����Java���������ݿ���Ķ�Ӧ��ϵ,���������ϵ���ø��ӡ�
2�� SQL�Ż�����ֲ��
Hibernate ��SQL����װ,�ṩ����־�����桢����(������ MyBatis ǿ��)������,����ṩ
HQL(Hibernate Query Language)�������ݿ�,���ݿ�����֧�ֺ�,������������ܡ������Ŀ��
Ҫ֧�ֶ������ݿ�,���뿪������,��SQL����Ż����ѡ�
MyBatis ��Ҫ�ֶ���д SQL,֧�ֶ�̬ SQL�������б�����̬���ɱ�����֧�ִ洢������������������
�Դ�Щ��ֱ��ʹ��SQL���������ݿ�,��֧�����ݿ�����,��sql����Ż����ס�
3���������׳̶Ⱥ�ѧϰ�ɱ�
Hibernate �����������,ѧϰʹ���ż���,�ʺ�����������ȶ�,��С�͵���Ŀ,����:�칫�Զ���
ϵͳ
MyBatis �����������,ѧϰʹ���ż���,�ʺ�������仯Ƶ��,���͵���Ŀ,����:��������������
ϵͳ
�ܽ�
MyBatis ��һ��С�ɡ����㡢��Ч����ֱ�ӡ����Զ����ij־ò���,
Hibernate ��һ��ǿ���㡢��Ч�����ӡ���ӡ�ȫ�Զ����ij־ò��ܡ�
5. JDBC�������Щ����֮��,MyBatis����ν����Щ�����?
1�����ݿ����Ӵ������ͷ�Ƶ�����ϵͳ��Դ�˷ѴӶ�Ӱ��ϵͳ����,���ʹ�����ݿ����ӳؿɽ�������⡣
���:��SqlMapConfig.xml�������������ӳ�,ʹ�����ӳع������ݿ����ӡ�
2��Sql���д�ڴ�������ɴ��벻��ά��,ʵ��Ӧ��sql�仯�Ŀ��ܽϴ�,sql�䶯��Ҫ�ı�java���롣
���:��Sql���������XXXXmapper.xml�ļ�����java������롣
3�� ��sql��䴫�����鷳,��Ϊsql����where������һ��,���ܶ�Ҳ������,ռλ����Ҫ�Ͳ���һһ��Ӧ��
���: Mybatis�Զ���java����ӳ����sql��䡣
4�� �Խ���������鷳,sql�仯���½�������仯,�ҽ���ǰ��Ҫ����,����ܽ����ݿ��¼��װ��pojo��������ȽϷ��㡣
���:Mybatis�Զ���sqlִ�н��ӳ����java����
6. MyBatis��̲�����ʲô����?
1������SqlSessionFactory
2��ͨ��SqlSessionFactory����SqlSession
3�� ͨ��sqlsessionִ�����ݿ����
4�� ����session.commit()�ύ����
5�� ����session.close()�رջỰ
7. MyBatis��Hibernate����Щ��ͬ?
1��Mybatis �� hibernate ��ͬ,������ȫ��һ�� ORM ���,��Ϊ MyBatis ��Ҫ ����Ա�Լ���д Sql
��䡣
2��Mybatis ֱ�ӱ�дԭ��̬ sql,�����ϸ���� sql ִ������,���ȸ�,�dz� �ʺ϶Թ�ϵ����ģ��Ҫ
�ߵ���������,��Ϊ������������仯Ƶ��,һ���� ��仯Ҫ��Ѹ������ɹ�����������ǰ����
mybatis ���������ݿ�����, �����Ҫʵ��֧�ֶ������ݿ������,����Ҫ�Զ������ sql ӳ����
��,��������
3��Hibernate ����/��ϵӳ������ǿ,���ݿ����Ժ�,���ڹ�ϵģ��Ҫ��ߵ� ����,�����
hibernate �������Խ�ʡ�ܶ����,���Ч��
8. Mybaits ���ŵ�:
1������ SQL �����,�൱���,�����Ӧ�ó���������ݿ�������������� ��Ӱ��,SQL д��
XML ��,��� sql ������������,����ͳһ����;�ṩ XML ��ǩ,֧�ֱ�д��̬ SQL ���,�������á�
2���� JDBC ���,������ 50%���ϵĴ�����,������ JDBC ��������Ĵ����� ��Ҫ�ֶ���������;
3���ܺõ���������ݿ����(��Ϊ MyBatis ʹ�� JDBC ���������ݿ�,����ֻҪ JDBC ֧�ֵ����ݿ�MyBatis ��֧��)��
4���ܹ��� Spring �ܺõļ���;
5���ṩӳ���ǩ,֧�ֶ��������ݿ�� ORM �ֶι�ϵӳ��;�ṩ�����ϵӳ�� ��ǩ,֧�ֶ����ϵ���ά��
9. MyBatis ��ܵ�ȱ��:
1��SQL ���ı�д�������ϴ�,���䵱�ֶζࡢ��������ʱ,�Կ�����Ա��д SQL ���Ĺ�����һ��Ҫ��
2��SQL ������������ݿ�,�������ݿ���ֲ�Բ�,��������������ݿ⡣
10. #{}��${}������?
-
#{}��ռλ��,Ԥ���봦��;${}��ƴ�ӷ�,�ַ����滻,û��Ԥ���봦����
-
Mybatis�ڴ���#{}ʱ,#{}������������ַ�������,�ὫSQL�е�#{}�滻Ϊ?��,����PreparedStatement��set��������ֵ��
-
Mybatis�ڴ���ʱ , �� ԭ ֵ �� �� , �� �� �� {}ʱ,��ԭֵ����,���ǰ�ʱ,��ԭֵ����,���ǰ�{}�滻�ɱ�����ֵ,�൱��JDBC�е�Statement����
-
�����滻��,#{} ��Ӧ�ı����Զ����ϵ����� ����;�����滻��,${} ��Ӧ�ı���������ϵ��� �� ����
-
#{} ������Ч�ķ�ֹSQLע��,���ϵͳ��ȫ��;${} ���ܷ�ֹSQL ע��
-
#{} �ı����滻����DBMS ��;${} �ı����滻���� DBMS ��
11. ͨ��һ��Xmlӳ���ļ�,����дһ��Dao�ӿ���֮�� Ӧ,��ô���Dao�ӿڵĹ���ԭ����ʲô?Dao�ӿ���� ������������ͬʱ,������������?
Dao�ӿڼ�Mapper�ӿڡ��ӿڵ�ȫ��������ӳ���ļ��е�namespace��ֵ;�ӿڵķ�����,����ӳ���ļ���Mapper��Statement��idֵ;�ӿڷ����ڵIJ���,���Ǵ��ݸ�sql�IJ�����Mapper�ӿ���û��ʵ�����,�����ýӿڷ���ʱ,�ӿ�ȫ����+��������ƴ���ַ�����Ϊkeyֵ,��Ψһ��λһ��MapperStatement��
Dao�ӿ���ķ���,�Dz������ص�,��Ϊ��ȫ����+�������ı����Ѱ�Ҳ�����
Dao�ӿڵĹ���ԭ����JDK��̬����,Mybatis����ʱ��ʹ��JDK��̬����ΪDao�ӿ����ɴ���proxy����,��������proxy�����ؽӿڷ���,ת��ִ��MappedStatement��������sql,Ȼ��sqlִ�н�����ء�
12. ��Mapper����δ��ݶ������?
1����Dao�㺯���ж������,��ô���Ӧ��xml��,#{0}�������յ���Dao���еĵ�һ������,#{1}�� ��Dao�еĵڶ�������,�Դ����ơ�
2��ʹ��@Paramע��:��Dao��IJ�����ǰ��@Paramע��,ע���ڵIJ�����Ϊ���ݵ�Mapper�еIJ�������
3�����������װ��Map,��HashMap����ʽ���ݵ�Mapper�С�
13. Mybatis��̬sql��ʲô��?ִ��ԭ����ʲô?����Щ ��̬sql?
Mybatis��̬sql������xmlӳ���ļ���,�Ա�ǩ����ʽ��д��̬sql,ִ��ԭ���Ǹ��ݱ���ʽ��ֵ�����
���ж�,����̬ƴ��sql�Ĺ��ܡ�
Mybatis�ṩ��9�ֶ�̬sql��ǩ:trim��where��set��foreach��if��choose��when��otherwise��bind
14. xmlӳ���ļ���,��ͬ��xmlӳ���ļ�id�Ƿ�����ظ�?
��ͬ��xmlӳ���ļ�,���������namespace,��ôid�����ظ�;���û������namespace,��ôid�����ظ�;
ԭ����namespace+id����ΪMap<String,MapperStatement>��keyʹ�õ�,���û��namespace,��ʣ��id,��ôid�ظ��ᵼ�����ݻ��า�ǡ�����namespace,��Ȼid�Ϳ����ظ�,namespace��ͬ,namespace+id��ȻҲ��ͬ��
15. Mybatisʵ��һ��һ�м��ַ�ʽ?��������ô������?
�����ϲ�ѯ��Ƕ�ײ�ѯ���ַ�ʽ��
���ϲ�ѯ�Ǽ��������ϲ�ѯ,ͨ����resultMap��������association�ڵ�����һ��һ����Ϳ������;
Ƕ�ײ�ѯ���Ȳ�һ����,�������������Ľ�������id,��ȥ����һ���������ѯ����,Ҳ��ͨ��
association����,������һ�����IJ�ѯ��ͨ��select���õġ�
MyBatis������÷�ʽ:
һ��һ����:ʹ��������
һ�Զ�����:ʹ��+������
��Զ�����:ʹ��+������

