一、基础配置引入
1. 依赖引入(二选一)
- pom.xml
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
- gradle
implementation("org.springframework.kafka:spring-kafka")
新建一个Spring Boot项目,在项目中引入如上依赖,默认情况下不填版本号(使用springboot父项目确定版本号)
2. yml配置文件
spring:
kafka:
bootstrap-servers: 223.122.137.55:9092
producer: # 生产者
retries: 3 #发送失败重试次数
acks: all #所有分区副本确认后,才算消息发送成功
# 指定消息key和消息体的序列化编码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
consumer: #消费者
# 指定消息key和消息体的反序列化解码方式,与生产者序列化方式一一对应
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties: # 这个配置参数相对默认,会在下文中介绍
spring:
json:
trusted:
packages: '*'
注意:生产者的序列化器和消费者的反序列化器是成对出现的,也就是说生产者序列化value采用JSON的方式,消费者反序列化的时候也应该采用JSON的方式。
3. 生产与消费
生产与消费什么内容呢? 今年小麦是个热点,就小麦吧
public class Wheat {
private String color;
private String category;
private double age;
@Override
public String toString() {
return "Wheat{" +
"color='" + color + '\'' +
", category='" + category + '\'' +
", age=" + age +
'}';
}
//这里省略了若干get、set方法
}
生产者测试用例
@SpringBootTest
class SpringKafkaTest {
@Resource
KafkaTemplate<String, Wheat> kafkaTemplate;
@Test
void test() {
Wheat wheat = new Wheat();
wheat.setAge(0.2);
wheat.setCategory("ck567");
wheat.setColor("yello");
//将wheat发往wheat-test这个topic
kafkaTemplate.send("wheat-test",wheat);
}
}
- KafkaTemplate是Spring针对kafka生产者封装的模板操作类,可以使用泛型,上文中的
<String,Wheat>表示发送的数据消息的key的数据类型是String,数据体value的数据类型是User。- 因为配置了
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer,所以User对象会被序列化为JSON对象之后发往kafka服务端。- 需要注意的是:在进行数据发送之前我并没有说需要在服务端新建一个主题“wheat-test”,这是因为,默认情况下当生产者发送数据的主题不存在的时候,会新建一个主题(该主题只有一个分区)。
消费者实现与测试
@Component
public class DemoConsumer {
@KafkaListener(topics = "wheat-test" , groupId = "wheat-test-group")
public void dealWheat(Wheat wheat) {
System.out.println(wheat.toString());
}
}
- 核心注解是KafkaListener,topics指定了消费哪个主题的数据,gourpId指定了消费者组的名称
- 这里使用Wheat作为方法参数,是因为kafka消费者会调用反序列化器
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer将生产者发送的Wheat对象反序列化。- 注意这里的消费者组只有一个消费者,如果希望启动多个消费者线程,可以设置
@KafkaListener(concurrency=n)。(用法:消费者线程数=主题分区数)
二、生产者同步异步分区拦截
1. Send参数说明
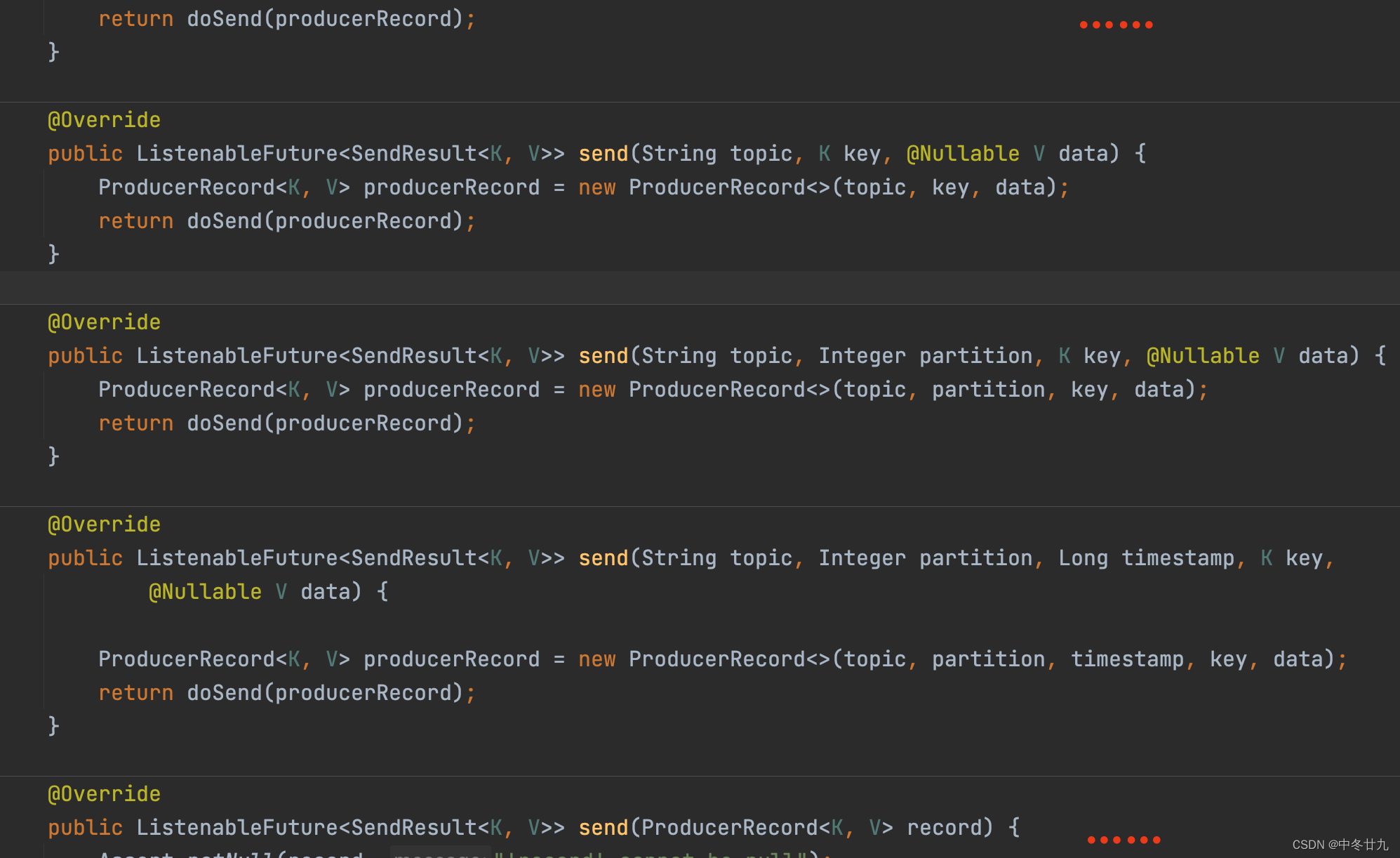
在Spring KafkaTemplate的send()方法还支持其他参数,具体如下:
- topic:Topic主题的的名称
- partition:主题的分区编号,编号从0开始。表示消息数据指定发送到该分区中
- timestamp:时间戳,一般默认当前时间戳
- key:消息的键,可以是不同数据类型,但是通常是String。具有相同key的消息被发往同一个分区,也就是说具有相同key的消息可以保证数据有序性。
- data:消息的数据,可以是不同数据类型
- ProducerRecord:消息对应的封装类,包含上述字段,较少使用
- Message:Spring自带的Message封装类,包含消息及消息头,较少使用
使用send方法的方式,发送之后就不再等待服务端对该消息的确认,如果出现异常生产者客户端不会有任何的感知。为了能够使生产者能够感知到消息是否真的发送成功了,有两种方式
- 同步发送
- 异步发送 + 回调函数
2. 异步发送
通过addCallback添加回调函数,success方法在消息发送被服务端确认成功后被调用;failure方法在消息发送失败后被调用。
@Test
public void testAsync() {
Wheat wheat = new Wheat();
wheat.setAge(0.2);
wheat.setCategory("ck567");
wheat.setColor("yello");
kafkaTemplate.send("wheat-test", wheat).addCallback(success -> {
// 消息发送到的topic
String topic = success.getRecordMetadata().topic();
// 消息发送到的分区
int partition = success.getRecordMetadata().partition();
// 消息在分区内的offset
long offset = success.getRecordMetadata().offset();
System.out.println("发送消息成功:" + topic + ",分区:" + partition + ",偏移量:" + offset);
}, failure -> {
System.out.println("发送消息失败:" + failure.getMessage());
});
}
3. 同步发送
默认情况下send()方法就是异步调用的方法,如果想实现同步阻塞的方法,需要在send方法的基础上调用get()方法。get()无参方法有一个重载方法get(long timeout, TimeUnit unit),当超过一定的时长服务端仍无消息写入成功确认,则抛出TimeoutException异常。
@Test
public void testSync() {
try {
Wheat wheat = new Wheat();
wheat.setAge(0.2);
wheat.setCategory("ck567");
wheat.setColor("yello");
// 同步发送消息
SendResult<String, Wheat> sendResult = kafkaTemplate.send("wheat-test", wheat).get(2, TimeUnit.MINUTES);
// 消息发送到的topic
String topic = sendResult.getRecordMetadata().topic();
// 消息发送到的分区
int partition = sendResult.getRecordMetadata().partition();
// 消息在分区内的offset
long offset = sendResult.getRecordMetadata().offset();
System.out.println("发送消息成功:" + topic + "-" + partition + "-" + offset);
} catch (InterruptedException | ExecutionException e) {
System.out.println("发送消息失败:" + e.getMessage());
} catch (TimeoutException e) {
System.out.println("发送消息超时无响应:" + e.getMessage());
}
}
4. 拦截器与分区配置
生产者在执行数据发送的时候,可以配置拦截器和分区器,在本专栏的之前的文章中我们已经介绍了二者的自定义方式。自定义完成之后,就是该如何使用的问题。如下:
# 可以在上面👆yml配置那里找到
properties:
interceptor.classes: com.ck567.kafka.MyProducerInterceptor
partitioner.class: com.ck567.kafka.MyProducerPartitioner
注意拦截器和分区器在Spring看来属于不常用的配置属性,对于不常用的原生配置属性,spring全都放在properties下面进行配置。也就是说原生API中,通过Properties传递给生产者的属性,在这里全部都支持。
一个是classes、一个是class,分区器只能配置一个,拦截器可以配置多个。
三、Kafka事务处理
1. 场景模拟
我们使用kafkaTemplate.send向kafka发送数据,但是发送数据之后方法内部抛出了异常。假如我们的代码含义是下面的这样的
- 用户订单支付,向kafka发送数据,为用户增加积分
- 然后把用户的订单支付结果存入数据库
订单支付未成功,可能用户余额不足,抛出异常。但是向kafka发送的数据已经发出去了,这显然不是我们希望看到的。我们期望的结果是:订单支付成功和用户积分增加成功,要么都成功,要么都失败。
2. 事务处理
下面是带事务处理的kafka生产者代码
//带事务处理的发送方式
public void rightSend(){
Order order = new Order();
order.setCurrencyType("RMB");
order.setCount(18);
order.setStatus("success");
// 声明事务:operations函数报错,消息就不会发出去。
kafkaTemplate.executeInTransaction(operations -> {
//数据发往kafka
operations.send("order-test",order);
//模拟后续业务处理发生了异常
throw new RuntimeException("fail");
});
}
注意: Spring提供了万能的
@Transactional注解,是可以用来管理kafka事务的,但是需要针对kafka做额外的配置管理。加之通常情况下,spring的注解用于数据库事务处理,如果再结合数据库多数据源、分布式事务相关的处理,很有可能会造成不可预知的问题。所以我建议使用上面这个方式。