sentinel官方文档:https://sentinelguard.io/zh-cn/docs/introduction.html
流量控制理论策略:
漏桶算法:
适用:漏桶策略适用于间隔性突发流量且流量不用即时处理的场景
代表框架:Sentinel 中的匀速排队限流策略,分布式追踪系统 Jaeger 中采集策略为速率限制类型。
有一个固定容量的水桶,桶底有一个小洞,水桶可以接收任意速率的水流,但无论水桶里有多少水,水从小洞流出的速率始终不变,桶里的水满了之后,水就会溢出。
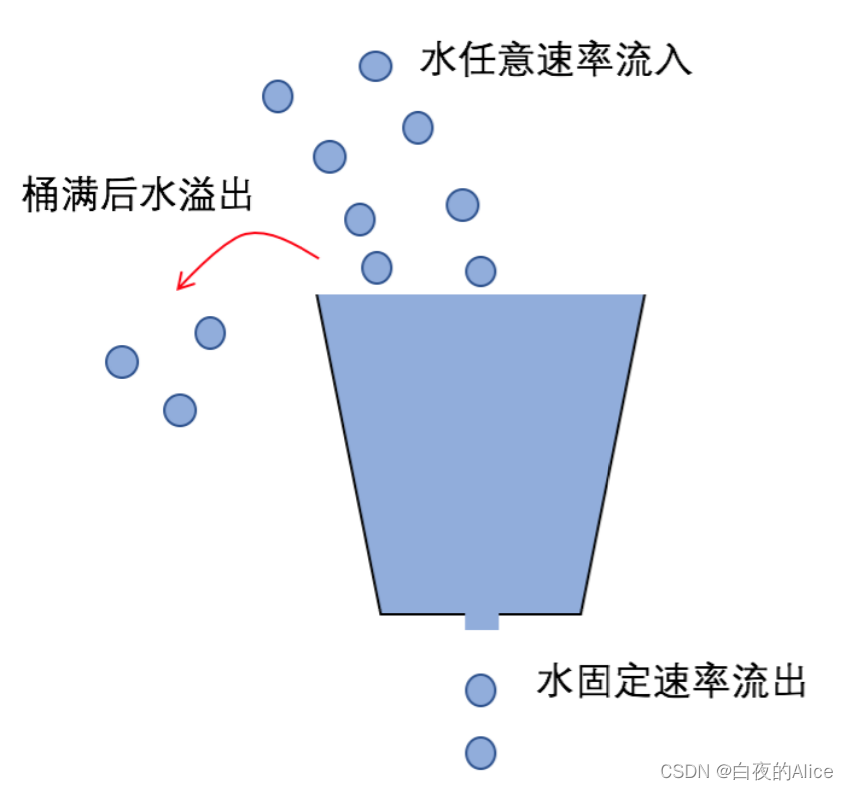
优点:平滑流量,做到了流量整形,即无论流量多大,即便是突发的大流量,输出依旧是一个稳定的流量。
缺点:对于突发流量的情况,因为服务器处理速度与正常流量的处理速度一致,会丢弃比较多的请求。
令牌桶算法:
适用:有突发特性的流量,且流量需要即时处理的场景。
代表框架:Guava 提供的限流工具类 RateLimiter。
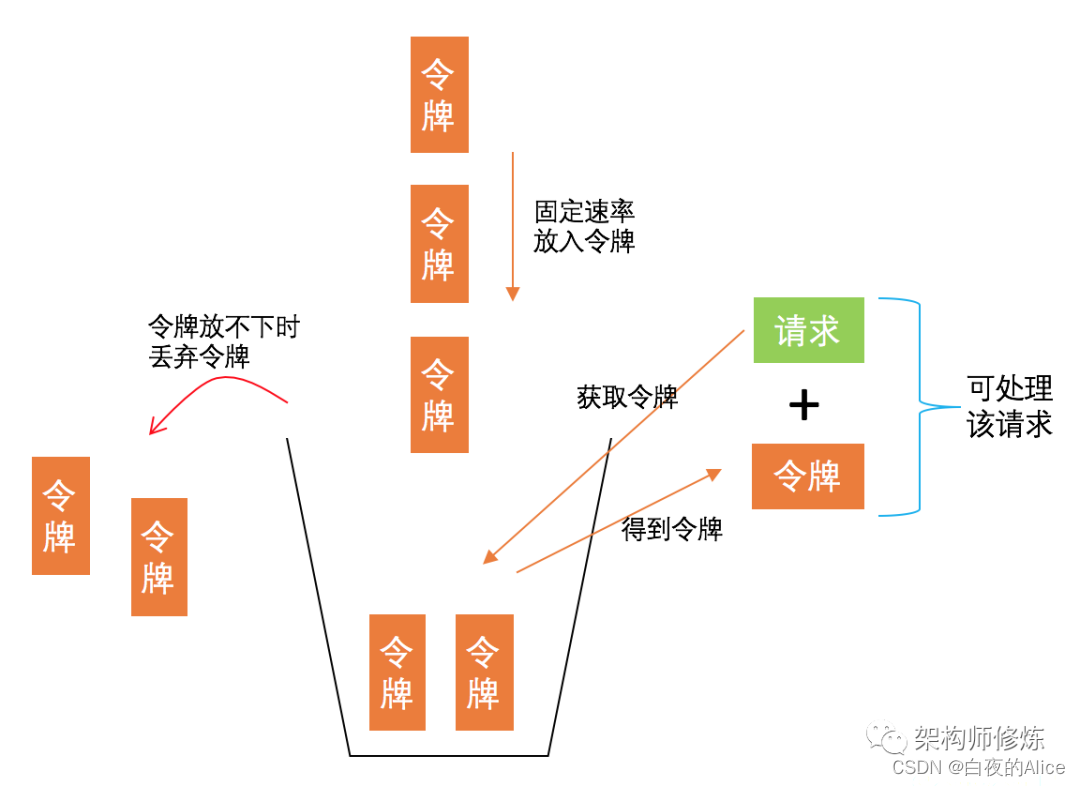
有一个固定容量的存放令牌的桶,我们以固定速率向桶里放入令牌,桶满时会丢弃多出的令牌。每当请求到来时,必须先到桶里取一个令牌才可被服务器处理,也就是说只有拿到了令牌的请求才会被服务器处理。所以,你可以将令牌理解为门卡,只有拿到了门卡才能顺利进入房间。

文章参考:https://cloud.tencent.com/developer/article/1663918
服务降级与熔断
服务降级:一般是指在服务器压力剧增的时候,根据实际业务使用情况以及流量,对一些服务和页面有策略的不处理或者用一种简单的方式进行处理,从而释放服务器资源的资源以保证核心业务的正常高效运行,提供的是不完全的服务。
例如:在双十一期间,压力特别大时,电商平台完成订单期间原本页面上展示关联商品推荐不再展示。
服务熔断:应对雪崩效应的链路自我保护机制。当某服务出现不可用或响应超时的情况时,为了防止该链路的其他服务和整个系统出现雪崩,暂时停止对该服务的调用。
sentinel
参考资料:http://c.biancheng.net/springcloud/sentinel.html
sentinel 基于以下属性组合进行流量控制。
| 属性 | 说明 | 默认值 |
|---|---|---|
| 资源名 | 流控规则的作用对象。 | - |
| 阈值 | 流控的阈值。 | - |
| 阈值类型 | 流控阈值的类型,包括 QPS 或并发线程数。 | QPS |
| 针对来源 | 流控针对的调用来源。 | default,表示不区分调用来源 |
| 流控模式 | 调用关系限流策略,包括直接、链路和关联。 | 直接 |
| 流控效果 | 流控效果(直接拒绝、Warm Up、匀速排队),不支持按调用关系限流。 | 直接拒绝 |
QPS :表示并发请求数,即每秒钟最多通过的请求数。
Sentinel 提供了 3 种熔断策略,如下表所示。
| 熔断策略 | 说明 |
|---|---|
| 慢调用比例 (SLOW_REQUEST_RATIO) | 选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大响应时间),若请求的响应时间大于该值则统计为慢调用。 当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。 经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则再次被熔断。 |
| 异常比例 (ERROR_RATIO) | 当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目且异常的比例大于阈值,则在接下来的熔断时长内请求会自动被熔断。 经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。 |
| 异常数 (ERROR_COUNT) | 当单位统计时长内的异常数目超过阈值之后会自动进行熔断。 经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。 |
官方文档上提供了另一大类的流量控制:
基于调用关系的流量控制:
-
根据调用方限流
ContextUtil.enter(resourceName, origin)方法中的origin参数标明了调用方身份。这些信息会在ClusterBuilderSlot中被统计。可通过以下命令来展示不同的调用方对同一个资源的调用数据:curl http://localhost:8719/origin?id=nodeA调用数据示例:
id: nodeA idx origin threadNum passedQps blockedQps totalQps aRt 1m-passed 1m-blocked 1m-total 1 caller1 0 0 0 0 0 0 0 0 2 caller2 0 0 0 0 0 0 0 0上面这个命令展示了资源名为
nodeA的资源被两个不同的调用方调用的统计。限流规则中的
limitApp字段用于根据调用方进行流量控制。该字段的值有以下三种选项,分别对应不同的场景:-
default:表示不区分调用者,来自任何调用者的请求都将进行限流统计。如果这个资源名的调用总和超过了这条规则定义的阈值,则触发限流。 -
{some_origin_name}:表示针对特定的调用者,只有来自这个调用者的请求才会进行流量控制。例如NodeA配置了一条针对调用者caller1的规则,那么当且仅当来自caller1对NodeA的请求才会触发流量控制。 -
other:表示针对除{some_origin_name}以外的其余调用方的流量进行流量控制。例如,资源NodeA配置了一条针对调用者caller1的限流规则,同时又配置了一条调用者为other的规则,那么任意来自非caller1对NodeA的调用,都不能超过other这条规则定义的阈值。同一个资源名可以配置多条规则,规则的生效顺序为:
{some_origin_name} > other > default
-
-
根据调用链路入口限流:链路限流
NodeSelectorSlot中记录了资源之间的调用链路,这些资源通过调用关系,相互之间构成一棵调用树。这棵树的根节点是一个名字为machine-root的虚拟节点,调用链的入口都是这个虚节点的子节点。一棵典型的调用树如下图所示:
machine-root / \ / \ Entrance1 Entrance2 / \ / \ DefaultNode(nodeA) DefaultNode(nodeA)上图中来自入口
Entrance1和Entrance2的请求都调用到了资源NodeA,Sentinel 允许只根据某个入口的统计信息对资源限流。比如我们可以设置FlowRule.strategy为RuleConstant.CHAIN,同时设置FlowRule.ref_identity为Entrance1来表示只有从入口Entrance1的调用才会记录到NodeA的限流统计当中,而对来自Entrance2的调用漠不关心。调用链的入口是通过 API 方法
ContextUtil.enter(name)定义的。 -
具有关系的资源流量控制:关联流量控制
当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢,举例来说,read_db 和 write_db 这两个资源分别代表数据库读写,我们可以给 read_db 设置限流规则来达到写优先的目的:设置 FlowRule.strategy 为 RuleConstant.RELATE 同时设置 FlowRule.ref_identity 为 write_db。这样当写库操作过于频繁时,读数据的请求会被限流。