Mybatisģ��
���
ʲô��MyBatis?
MyBatis��һ������ij־ò���,��֧���Զ��� SQL���洢�����Լ���ӳ�䡣MyBatis����˼������е�JDBC�����Լ����ò����ͻ�ȡ������Ĺ�����
MyBatis����ͨ���� XML ����ע�������ú�ӳ��ԭʼ���͡��ӿں� Java POJO(��ͨ��ʽ Java ����)Ϊ���ݿ��еļ�¼��
����
�����������
Ҫʹ�� MyBatis, ֻ�轫 mybatis-x.x.x.jar �ļ�������·��(classpath)�м��ɡ�
����� Maven ����,�������������
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>x.x.x</version>
</dependency>
�� XML ��� SqlSessionFactory
ÿ������ MyBatis ��Ӧ�ö�����һ�� SqlSessionFactory ��ʵ��Ϊ���ĵġ�SqlSessionFactory ��ʵ������ͨ�� SqlSessionFactoryBuilder ��á��� SqlSessionFactoryBuilder ����Դ� XML �����ļ���һ��Ԥ�����õ� Configuration ʵ���������� SqlSessionFactory ʵ����
? �� XML �ļ��й��� SqlSessionFactory ��ʵ���dz���,����ʹ����·���µ���Դ�ļ��������á� ��Ҳ����ʹ�������������(InputStream)ʵ��,�������ļ�·���ַ����� file:// URL �������������MyBatis ����һ������ Resources �Ĺ�����,������һЩʵ�÷���,ʹ�ô���·��������λ�ü�����Դ�ļ��������ס�
String resource = "org/mybatis/example/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
MyBatis���������ļ�
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="org/mybatis/example/BlogMapper.xml"/>
</mappers>
</configuration>
����ֻ��������Դ����,��ϸ�����ں���ܽᡣ
�� SqlSessionFactory �л�ȡ SqlSession
try (SqlSession session = sqlSessionFactory.openSession()) {
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);
}
ӳ���ļ�
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.mybatis.example.BlogMapper">
<select id="selectBlog" resultType="Blog">
select * from Blog where id = #{id}
</select>
</mapper>
�����ռ������:
���ø�����ȫ����������ͬ�������뿪����
ʵ�ֽӿڰ�
������ BlogMapper ������ӳ��������˵,������һ�ַ�����������ӳ�䡣����ӳ��������Բ��� XML ������,������ʹ�� java ע�������á���������� XML �Ϳ���д�����µ�����:
package org.mybatis.example;
public interface BlogMapper {
@Select("SELECT * FROM blog WHERE id = #{id}")
Blog selectBlog(int id);
}
ʹ��ע����ӳ�������ʹ�����Եø��Ӽ��,������������һ������,Java ע�ⲻ����������,�����ñ����ӵ� SQL �����ӻ��Ҳ����� ���,�������Ҫ��һЩ�ܸ��ӵIJ���,����� XML ��ӳ����䡣
XML �����ļ�
1��properties:
�����ⲿ�����ļ�,�����Խ��ж�̬�滻��
���� db.properties �ļ��ж��������µ�����Դ��Ϣ
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/2019Home
username=root
password=root
���úõ����Կ��������������ļ��������滻��Ҫ��̬���õ�����ֵ��
<properties resource="db.properties"></properties>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
2��settings:
���� MyBatis �м�Ϊ��Ҫ�ĵ�������,���ǻ�ı� MyBatis ������ʱ��Ϊ���±������������и������õĺ��塢Ĭ��ֵ�ȡ�

һ������������ settings Ԫ�ص�ʾ������:
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="true"/>
<setting name="multipleResultSetsEnabled" value="true"/>
<setting name="useColumnLabel" value="true"/>
<setting name="useGeneratedKeys" value="false"/>
<setting name="autoMappingBehavior" value="PARTIAL"/>
<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>
<setting name="defaultExecutorType" value="SIMPLE"/>
<setting name="defaultStatementTimeout" value="25"/>
<setting name="defaultFetchSize" value="100"/>
<setting name="safeRowBoundsEnabled" value="false"/>
<setting name="safeResultHandlerEnabled" value="true"/>
<setting name="mapUnderscoreToCamelCase" value="false"/>
<setting name="localCacheScope" value="SESSION"/>
<setting name="jdbcTypeForNull" value="OTHER"/>
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>
<setting name="defaultScriptingLanguage" value="org.apache.ibatis.scripting.xmltags.XMLLanguageDriver"/>
<setting name="defaultEnumTypeHandler" value="org.apache.ibatis.type.EnumTypeHandler"/>
<setting name="callSettersOnNulls" value="false"/>
<setting name="returnInstanceForEmptyRow" value="false"/>
<setting name="logPrefix" value="exampleLogPreFix_"/>
<setting name="logImpl" value="SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING"/>
<setting name="proxyFactory" value="CGLIB | JAVASSIST"/>
<setting name="vfsImpl" value="org.mybatis.example.YourselfVfsImpl"/>
<setting name="useActualParamName" value="true"/>
<setting name="configurationFactory" value="org.mybatis.example.ConfigurationFactory"/>
</settings>
3�����ͱ���(typeAliases):
���ͱ�����Ϊ Java ��������һ����д���֡��������� XML ����,���ڽ��������ȫ��������д������:
<!-- ��ij�������� -->
<typeAliases>
<typeAlias alias="Author" type="domain.blog.Author"/>
<typeAlias alias="Blog" type="domain.blog.Blog"/>
<typeAlias alias="Comment" type="domain.blog.Comment"/>
</typeAliases>
Ҳ����ָ��һ������,MyBatis ���ڰ�������������Ҫ�� Java Bean,����:
<!-- ��ij�����µ����������ñ��� -->
<typeAliases>
<package name="domain.blog"/>
</typeAliases>
�Ƽ�ʹ��ȫ������
4�����ʹ�����(typeHandlers):
MyBatis ������Ԥ�������(PreparedStatement)�еIJ�����ӽ������ȡ��һ��ֵʱ,���������ʹ���������ȡ����ֵ�Ժ��ʵķ�ʽת����Java���͡�������һЩĬ�ϴ�����:
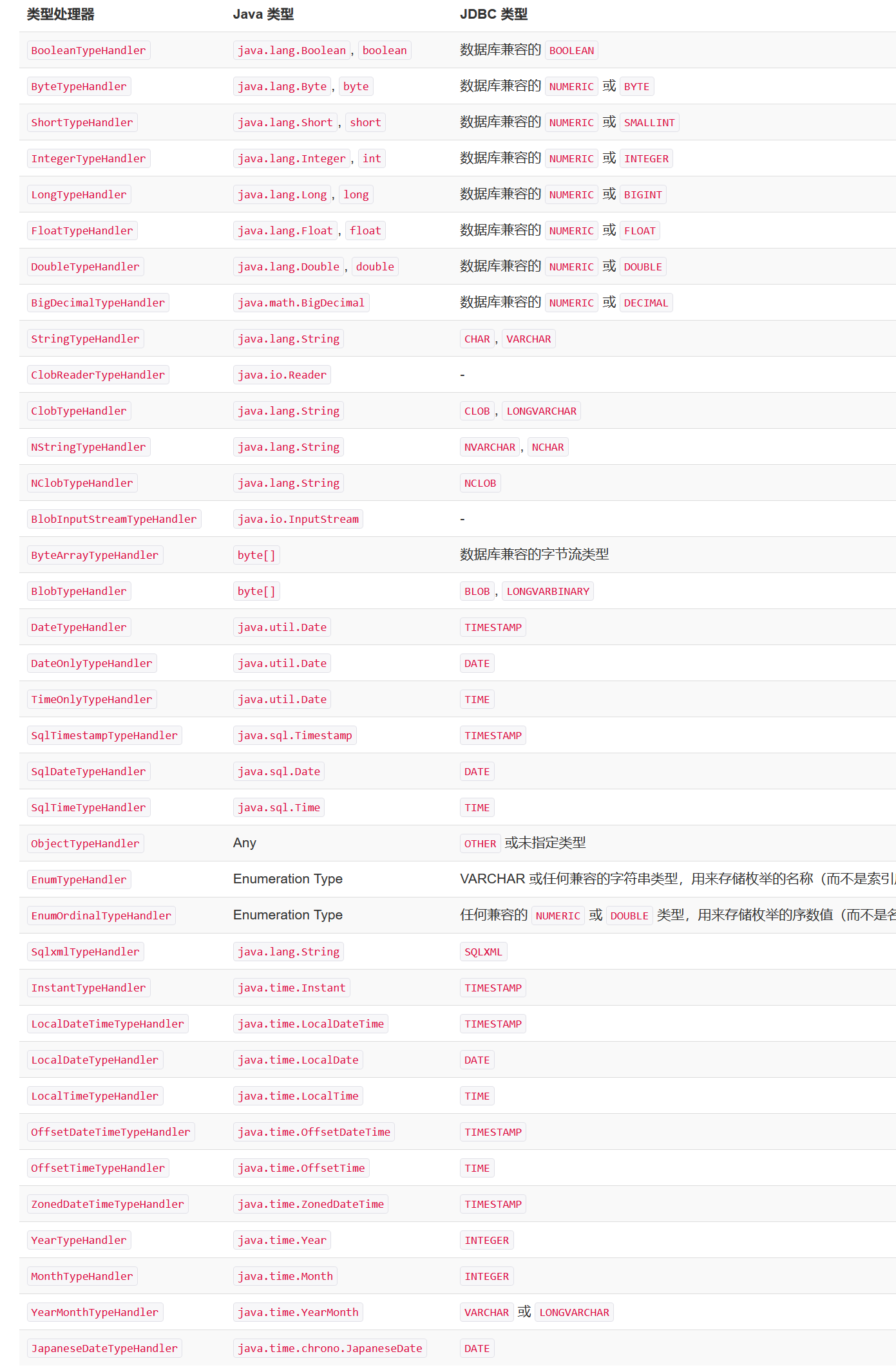
�������д���е����ʹ��������Լ������ʹ�������������֧�ֵĻ�DZ������͡���������Ϊ:ʵ��org.apache.ibatis.type.TypeHandler �ӿ�,��̳�һ���ܱ������� org.apache.ibatis.type.BaseTypeHandler ,���ҿ���(��ѡ��)����ӳ�䵽һ�� JDBC ���͡�����:
// ExampleTypeHandler.java
@MappedJdbcTypes(JdbcType.VARCHAR)
public class ExampleTypeHandler extends BaseTypeHandler<String> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {
ps.setString(i, parameter);
}
@Override
public String getNullableResult(ResultSet rs, String columnName) throws SQLException {
return rs.getString(columnName);
}
@Override
public String getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
return rs.getString(columnIndex);
}
@Override
public String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
return cs.getString(columnIndex);
}
}
<!-- mybatis-config.xml -->
<typeHandlers>
<typeHandler handler="org.mybatis.example.ExampleTypeHandler"/>
</typeHandlers>
ʹ�����������ʹ��������Ḳ�����еĴ��� Java String ���͵������Լ� VARCHAR ���͵IJ����ͽ�������ʹ�������Ҫע�� MyBatis ����ͨ��������ݿ�Ԫ��Ϣ������ʹ����������,����������ڲ����ͽ��ӳ����ָ���ֶ��� VARCHAR ����,��ʹ���ܹ�����ȷ�����ʹ������ϡ�������Ϊ MyBatis ֱ����䱻ִ��ʱ������������͡�
ͨ�����ʹ������ķ���,MyBatis ���Ե�֪�����ʹ����������� Java ����,����������Ϊ����ͨ�����ַ����ı�:
- �����ʹ�����������Ԫ��(typeHandler Ԫ��)������һ��
javaType����(����:javaType="String"); - �����ʹ���������������һ��
@MappedTypesע��ָ����������� Java �����б��������javaType������Ҳͬʱָ��,��ע���ϵ����ý������ԡ�
����ͨ�����ַ�ʽ��ָ�������� JDBC ����:
- �����ʹ�����������Ԫ��������һ��
jdbcType����(����:jdbcType="VARCHAR"); - �����ʹ���������������һ��
@MappedJdbcTypesע��ָ����������� JDBC �����б��������jdbcType������Ҳͬʱָ��,��ע���ϵ����ý������ԡ�
���� ResultMap �о���ʹ���������ʹ�����ʱ,��ʱ Java ��������֪��(�ӽ�������л��),���� JDBC ������δ֪�ġ���� Mybatis ʹ�� javaType=[Java ����], jdbcType=null �������ѡ��һ�����ʹ������� ����ζ��ʹ�� @MappedJdbcTypes ע������������ʹ����������÷�Χ,���ҿ���ȷ��,������ʽ������,�������ʹ������� ResultMap �н�������Ч�� ���ϣ������ ResultMap ����ʽ��ʹ�����ʹ�����,��ô���� @MappedJdbcTypes ע��� includeNullJdbcType=true ���ɡ� Ȼ���� Mybatis 3.4.0 ��ʼ,���ij�� Java ����ֻ��һ��ע������ʹ�����,��ʹû������ includeNullJdbcType=true,��ô������ʹ�����Ҳ���� ResultMap ʹ�� Java ����ʱ��Ĭ�ϴ�������
���,������ MyBatis ����������ʹ�����:
<!-- mybatis-config.xml -->
<typeHandlers>
<package name="org.mybatis.example"/>
</typeHandlers>
ע����ʹ���Զ����ֹ��ܵ�ʱ��,ֻ��ͨ��ע�ⷽʽ��ָ�� JDBC �����͡�
����Դ����ܹ����������ķ������ʹ�������Ϊ��ʹ�÷������ʹ�����,��Ҫ����һ�����ܸ���� class ��Ϊ�����Ĺ�����,���� MyBatis ���ڹ���һ�����ʹ�����ʵ����ʱ����һ��������ࡣ
//GenericTypeHandler.java
public class GenericTypeHandler<E extends MyObject> extends BaseTypeHandler<E> {
private Class<E> type;
public GenericTypeHandler(Class<E> type) {
if (type == null) throw new IllegalArgumentException("Type argument cannot be null");
this.type = type;
}
...
EnumTypeHandler �� EnumOrdinalTypeHandler ���Ƿ������ʹ�����,���ǽ����ڽ������IJ�����ϸ̽�֡�
5������ö������
����ӳ��ö������ Enum,����Ҫ�� EnumTypeHandler ���� EnumOrdinalTypeHandler ��ѡ��һ����ʹ�á�
����˵������洢ȡ����ֵʱ�õ�������ģʽ��Ĭ�������,MyBatis ������ EnumTypeHandler ���� Enum ֵת���ɶ�Ӧ�����֡�
ע�� EnumTypeHandler ��ij����������˵�DZȽ��ر��,�����Ĵ�����ֻ���ij���ض�����,������ͬ,���ᴦ������̳��� Enum ���ࡣ
����,���ǿ��ܲ���洢����,�෴���ǵ� DBA ����ʹ������ֵ���롣��Ҳһ����:�������ļ��а� EnumOrdinalTypeHandler �ӵ� typeHandlers �м���,����ÿ�� RoundingMode ��ͨ�����ǵ�����ֵ��ӳ��ɶ�Ӧ��������ֵ��
<!-- mybatis-config.xml -->
<typeHandlers>
<typeHandler handler="org.apache.ibatis.type.EnumOrdinalTypeHandler" javaType="java.math.RoundingMode"/>
</typeHandlers>
��Ҫ��������һ���ط��� Enum ӳ����ַ���,������һ���ط�ӳ�������ֵ��?
�Զ�ӳ����(auto-mapper)���Զ���ѡ�� EnumOrdinalTypeHandler ������ö������,�����������������ͨ�� EnumTypeHandler,�ͱ���Ҫ��ʽ��Ϊ��Щ SQL �������Ҫʹ�õ����ʹ�������
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.apache.ibatis.submitted.rounding.Mapper">
<resultMap type="org.apache.ibatis.submitted.rounding.User" id="usermap">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="funkyNumber" property="funkyNumber"/>
<result column="roundingMode" property="roundingMode"/>
</resultMap>
<select id="getUser" resultMap="usermap">
select * from users
</select>
<insert id="insert">
insert into users (id, name, funkyNumber, roundingMode) values (
#{id}, #{name}, #{funkyNumber}, #{roundingMode}
)
</insert>
<resultMap type="org.apache.ibatis.submitted.rounding.User" id="usermap2">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="funkyNumber" property="funkyNumber"/>
<result column="roundingMode" property="roundingMode" typeHandler="org.apache.ibatis.type.EnumTypeHandler"/>
</resultMap>
<select id="getUser2" resultMap="usermap2">
select * from users2
</select>
<insert id="insert2">
insert into users2 (id, name, funkyNumber, roundingMode) values (
#{id}, #{name}, #{funkyNumber}, #{roundingMode, typeHandler=org.apache.ibatis.type.EnumTypeHandler}
)
</insert>
</mapper>
ע��,����� select ������ָ�� resultMap ������ resultType��
6�����(plugins)
MyBatis ��������ӳ�����ִ�й����е�ijһ��������ص��á�Ĭ�������,MyBatis ����ʹ�ò�������صķ������ð���:
- Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
- ParameterHandler (getParameterObject, setParameters)
- ResultSetHandler (handleResultSets, handleOutputParameters)
- StatementHandler (prepare, parameterize, batch, update, query)
��Щ���з�����ϸ�ڿ���ͨ���鿴ÿ��������ǩ��������,����ֱ�Ӳ鿴 MyBatis ���а��е�Դ���롣����������IJ������Ǽ�ط����ĵ���,��ô������൱�˽�Ҫ��д�ķ�������Ϊ����Ϊ����ͼ�Ļ���д���з�������Ϊʱ,�ܿ��ܻ��ƻ� MyBatis �ĺ���ģ�顣 ��Щ���Ǹ��ײ����ͷ���,����ʹ�ò����ʱ��Ҫ�ر��ġ�
ͨ�� MyBatis �ṩ��ǿ�����,ʹ�ò���Ƿdz���,ֻ��ʵ�� Interceptor �ӿ�,��ָ����Ҫ���صķ���ǩ�����ɡ�
// ExamplePlugin.java
@Intercepts({@Signature(
type= Executor.class,
method = "update",
args = {MappedStatement.class,Object.class})})
public class ExamplePlugin implements Interceptor {
private Properties properties = new Properties();
@Override
public Object intercept(Invocation invocation) throws Throwable {
// implement pre processing if need
Object returnObject = invocation.proceed();
// implement post processing if need
return returnObject;
}
@Override
public void setProperties(Properties properties) {
this.properties = properties;
}
}
<!-- mybatis-config.xml -->
<plugins>
<plugin interceptor="org.mybatis.example.ExamplePlugin">
<property name="someProperty" value="100"/>
</plugin>
</plugins>
����IJ������������ Executor ʵ�������е� ��update�� ��������,����� Executor �Ǹ���ִ�еײ�ӳ�������ڲ�����
**����������**�����ò������ MyBatis ������Ϊ����,������ͨ����ȫ�������������ﵽĿ�ġ�ֻ��̳�����������е�ij������,�ٰ������ݵ� SqlSessionFactoryBuilder.build(myConfig) �������ɡ��ٴ�����,����ܻἫ��Ӱ�� MyBatis ����Ϊ,������֮������
7����������(environments):
MyBatis �������ó���Ӧ���ֻ���,���ֻ��������ڽ� SQL ӳ��Ӧ���ڶ������ݿ�֮��,��ʵ������ж���������Ҫ��ô��������,���������Ժ�����������Ҫ�в�ͬ������;�������ھ�����ͬ Schema �Ķ���������ݿ���ʹ����ͬ�� SQL ӳ�䡣�����������Ƶ�ʹ�ó�����
����Ҫ��ס:���ܿ������ö������,��ÿ�� SqlSessionFactory ʵ��ֻ��ѡ��һ�ֻ�����
����,������������������ݿ�,����Ҫ�������� SqlSessionFactory ʵ��,ÿ�����ݿ��Ӧһ������������������ݿ�,����Ҫ����ʵ��,��������,�������ܼ�:ÿ�����ݿ��Ӧһ�� SqlSessionFactory ʵ��
environments Ԫ�ض�����������û�����
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
ע��һЩ�ؼ���:
- Ĭ��ʹ�õĻ��� ID(����:default=��development��)��
- ÿ�� environment Ԫ�ض���Ļ��� ID(����:id=��development��)��
- ���������������(����:type=��JDBC��)��
- ����Դ������(����:type=��POOLED��)��
�����˽�һ�¼���,��Ϊ�������������Դ���� Spring �������顣���������Բο��ٷ��ĵ�
8�����ݿ⳧�̱�ʶ(databaseIdProvider)
MyBatis ���Ը��ݲ�ͬ�����ݿ⳧��ִ�в�ͬ�����,���ֶ೧�̵�֧���ǻ���ӳ������е� databaseId ���ԡ�MyBatis ����ش���ƥ�䵱ǰ���ݿ� databaseId ���Ժ����в��� databaseId ���Ե���䡣���ͬʱ�ҵ����� databaseId �Ͳ��� databaseId ����ͬ���,����ᱻ������Ϊ֧�ֶ೧������,ֻҪ������������ mybatis-config.xml �ļ��м��� databaseIdProvider ����:
<databaseIdProvider type="DB_VENDOR" />
databaseIdProvider ��Ӧ�� DB_VENDOR ʵ�ֻὫ databaseId ����Ϊ DatabaseMetaData#getDatabaseProductName() ���ص��ַ���������ͨ���������Щ�ַ������dz���,������ͬ��Ʒ�IJ�ͬ�汾�᷵�ز�ͬ��ֵ,�������ͨ���������Ա�����ʹ����:
<databaseIdProvider type="DB_VENDOR">
<property name="SQL Server" value="sqlserver"/>
<property name="DB2" value="db2"/>
<property name="Oracle" value="oracle" />
</databaseIdProvider>
���ṩ�����Ա���ʱ,databaseIdProvider �� DB_VENDOR ʵ�ֻὫ databaseId ����Ϊ���ݿ��Ʒ���������е����Ƶ�һ����ƥ���ֵ,���û��ƥ�������,��������Ϊ ��null���������������,��� getDatabaseProductName() ���ء�Oracle (DataDirect)��,databaseId ��������Ϊ��oracle����
�����ͨ��ʵ�ֽӿ� org.apache.ibatis.mapping.DatabaseIdProvider ���� mybatis-config.xml ��ע���������Լ��� DatabaseIdProvider:
public interface DatabaseIdProvider {
default void setProperties(Properties p) { // �� 3.5.2 ��ʼ,�÷���ΪĬ�Ϸ���
// ��ʵ��
}
String getDatabaseId(DataSource dataSource) throws SQLException;
}
9��ӳ����(mappers)
��Ȼ MyBatis ����Ϊ�Ѿ�������Ԫ����������,�������ھ�Ҫ������ SQL ӳ������ˡ�������,������Ҫ���� MyBatis ������ȥ�ҵ���Щ��䡣���Զ�������Դ����,Java ��û���ṩһ���ܺõĽ������,������õİ취��ֱ�Ӹ��� MyBatis ������ȥ��ӳ���ļ� �������ʹ���������·������Դ����,����ȫ����Դ��λ��(���� file:/// ��ʽ�� URL),�������Ͱ����ȡ�����:
<!-- ʹ���������·������Դ���� -->
<mappers>
<mapper resource="org/mybatis/builder/AuthorMapper.xml"/>
<mapper resource="org/mybatis/builder/BlogMapper.xml"/>
<mapper resource="org/mybatis/builder/PostMapper.xml"/>
</mappers>
<!-- ʹ����ȫ����Դ��λ��(URL)���Դ���������·������ -->
<mappers>
<mapper url="file:///var/mappers/AuthorMapper.xml"/>
<mapper url="file:///var/mappers/BlogMapper.xml"/>
<mapper url="file:///var/mappers/PostMapper.xml"/>
</mappers>
<!-- ʹ��ӳ�����ӿ�ʵ�������ȫ������
����������ְ���:��Ҫ��ӳ���ļ��ͽӿڷ���ͬ����,���ļ���������ͬ��
���û��дӳ���ļ�,����ʹ��ע��ֱ�Ӱ�SQLд�ڽӿ���,����ʹ�����ַ���ע�ᡣ
-->
<mappers>
<mapper class="org.mybatis.builder.AuthorMapper"/>
<mapper class="org.mybatis.builder.BlogMapper"/>
<mapper class="org.mybatis.builder.PostMapper"/>
</mappers>
<!-- �����ڵ�ӳ�����ӿ�ȫ��ע��Ϊӳ����
name:Dao���ڵİ���
-->
<mappers>
<package name="org.mybatis.builder"/>
</mappers>
��Ÿ���ǩ,1 ��2 ��9����,�����˽⼴��,�õ�ʱ�ٷ��ĵ���
XML ӳ���ļ�
SQL ӳ���ļ�ֻ�к��ٵļ�������Ԫ��(����Ӧ�������˳���г�):
cache- �������ռ�Ļ�������cache-ref- �������������ռ�Ļ�������resultMap- ������δ����ݿ������м��ض���,�����Ҳ����ǿ���Ԫ��sql- �ɱ�����������õĿ���������insert- ӳ��������update- ӳ��������delete- ӳ��ɾ�����select- ӳ���ѯ���
ÿ��Ԫ�ص�ϸ��:
select
<select id="selectPerson" parameterType="int" resultType="hashmap">
SELECT * FROM PERSON WHERE ID = #{id}
</select>
��������Ϊ selectPerson,����һ�� int(�� Integer)���͵IJ���,������һ�� HashMap ���͵Ķ���,���еļ�������,ֵ���ǽ�����еĶ�Ӧֵ��
ע���������:
#{id}
����� MyBatis ����һ��Ԥ�������(PreparedStatement)����,�� JDBC ��,������һ�������� SQL �л���һ����?������ʶ,�������ݵ�һ���µ�Ԥ���������,��������:
// ���Ƶ� JDBC ����,�� MyBatis ����...
String selectPerson = "SELECT * FROM PERSON WHERE ID=?";
PreparedStatement ps = conn.prepareStatement(selectPerson);
ps.setInt(1,id);
? Select Ԫ�ص�����
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-VhI5dICd-1665831936606)(https://images-1313675740.cos.ap-shanghai.myqcloud.com/images/%E6%97%A0%E6%A0%87%E9%A2%98.png)]
insert, update �� delete
<insert
id="insertAuthor"
parameterType="domain.blog.Author"
flushCache="true"
statementType="PREPARED"
keyProperty=""
keyColumn=""
useGeneratedKeys=""
timeout="20">
<update
id="updateAuthor"
parameterType="domain.blog.Author"
flushCache="true"
statementType="PREPARED"
timeout="20">
<delete
id="deleteAuthor"
parameterType="domain.blog.Author"
flushCache="true"
statementType="PREPARED"
timeout="20">
? Insert, Update, Delete Ԫ�ص�����

������ insert,update �� delete ����ʾ��:
<insert id="insertAuthor">
insert into Author (id,username,password,email,bio)
values (#{id},#{username},#{password},#{email},#{bio})
</insert>
<update id="updateAuthor">
update Author set
username = #{username},
password = #{password},
email = #{email},
bio = #{bio}
where id = #{id}
</update>
<delete id="deleteAuthor">
delete from Author where id = #{id}
</delete>
��ǰ����,�����������ù�����ӷḻ,�ڲ������������һЩ��������Ժ���Ԫ��������������������,�����ṩ�˶������ɷ�ʽ��
����,���������ݿ�֧���Զ����ɵ��������ֶ�(���� MySQL �� SQL Server ),��ô���������useGeneratedKeys=��true��,Ȼ���ڰ� keyProperty ����ΪĿ�����Ծ� OK �ˡ�����,�������� Author ���Ѿ��� id ����ʹ�����Զ�����,��ô��������Ϊ:
<insert id="insertAuthor" useGeneratedKeys="true"
keyProperty="id">
insert into Author (username,password,email,bio)
values (#{username},#{password},#{email},#{bio})
</insert>
���������ݿ֧�ֶ��в���, ��Ҳ���Դ���һ�� Author �����,�������Զ����ɵ�������
<insert id="insertAuthor" useGeneratedKeys="true"
keyProperty="id">
insert into Author (username, password, email, bio) values
<foreach item="item" collection="list" separator=",">
(#{item.username}, #{item.password}, #{item.email}, #{item.bio})
</foreach>
</insert>
���ڲ�֧���Զ����������е����ݿ�Ϳ��ܲ�֧���Զ����������� JDBC ����,MyBatis ������һ�ַ���������������
������һ����(Ҳ��ɵ)��ʾ��,����������һ����� ID(������ʵ��ʹ��,����ֻ��Ϊ��չʾ MyBatis �������������ԺͿ��ݶ�):
<insert id="insertAuthor">
<!-- ��ѯ���� -->
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select CAST(RANDOM()*1000000 as INTEGER) a from SYSIBM.SYSDUMMY1
</selectKey>
insert into Author
(id, username, password, email,bio, favourite_section)
values
(#{id}, #{username}, #{password}, #{email}, #{bio}, #{favouriteSection,jdbcType=VARCHAR})
</insert>
�������ʾ����,���Ȼ����� selectKey Ԫ���е����,������ Author �� id,Ȼ��Ż���ò�����䡣������ʵ�������ݿ��Զ������������Ƶ���Ϊ,ͬʱ������ Java ����ļ�ࡣ
selectKey Ԫ����������:
<selectKey
keyProperty="id"
resultType="int"
order="BEFORE"
statementType="PREPARED">
? selectKey Ԫ�ص�����

����
֮ǰ������������䶼�����˼IJ�����ʽ����ʵ����,������ MyBatis �dz�ǿ���Ԫ�ء����ڴ������ʹ�ó���,�㶼����Ҫʹ�ø��ӵIJ���,����:
<select id="selectUsers" resultType="User">
select id, username, password
from users
where id = #{id}
</select>
��������ʾ��˵����һ���dz�����������ӳ�䡣���ڲ�������(parameterType)�ᱻ�Զ�����Ϊint,���������������������ԭʼ���ͻ����������(����Integer �� String )��Ϊû����������,�������ǵ�ֵ����Ϊ������Ȼ��,�������һ�����ӵĶ���,��Ϊ�ͻ��е㲻һ���ˡ�����:
<insert id="insertUser" parameterType="User">
insert into users (id, username, password)
values (#{id}, #{username}, #{password})
</insert>
��� User ���͵IJ������ݵ��������,�����id��username �� password ����,Ȼ�����ǵ�ֵ����Ԥ�������IJ����С�
:������ܱ���org.apache.ibatis.binding.BindingException: Parameter 'id' not found. Available parameters are [arg2, arg1, arg0, param3, param1, param2]
ԭ����:����������,Mybatis���Զ�����Щ������װ��һ�� map ��,key ���Dz���������������ĵڼ�����ʶ��#{key} ���Ǵ���� map ��ȡֵ��
���:ֻ���ڽӿ��д�������Ǹ�ÿ����������ע�� @Param ���� MyBatis ʹ�������Զ���� key,��:

�Դ�����������˵,���ַ�ʽ���Ǹɴ����䡣��������ӳ��Ĺ���Զ��ֹ�ڴˡ�
����,�� MyBatis ����������һ��,����Ҳ����ָ��һ��������������͡�
#{property,javaType=int,jdbcType=NUMERIC}
�� MyBatis ����������һ��,�������ǿ��Ը��ݲ������������ȷ��javaType,���Ǹö�����һ�� HashMap�����ʱ��,����Ҫ��ʾָ�� javaType ��ȷ����ȷ�����ʹ�����(TypeHandler)��ʹ�á�
Ҫ����һ�����Զ������ʹ�����ʽ,����ָ��һ����������ʹ�������(�����),����:
#{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
������ֵ����,���������� numericScale ָ��С���������λ����
#{height,javaType=double,jdbcType=NUMERIC,numericScale=2}
�����ϱ���Щѡ���ǿ��,�����ʱ��,��ֻ���ָ��������,����ҪΪ����Ϊ�յ���ָ�� jdbcType ,���������齻�� MyBatis �Լ�ȥ�ƶϾ����ˡ�
#{firstName}
#{middleInitial,jdbcType=VARCHAR}
#{lastName}
�ַ����滻
Ĭ�������,ʹ�� ${} �����ʱ,MyBatis �ᴴ�� PreparedStatement ����ռλ��,��ͨ��ռλ����ȫ�����ò���(����ʹ�� ?һ��)������������ȫ,��Ѹ��,ͨ��Ҳ����ѡ����,������ʱ�������ֱ���� SQL �����ֱ�Ӳ���һ����ת����ַ��������� ORDED BY �Ӿ�,��ʱ�������:
ORDER BY ${columnName}
����,MyBatis �Ͳ����Ļ�ת����ַ����ˡ�
�� SQL ����е�Ԫ����(�����������)�Ƕ�̬���ɵ�ʱ��,�ַ����滻����dz����á��ٸ�����,������� select һ��������һ�е�����ʱ,����Ҫ����д:
@Select("select * from user where id = #{id}")
User findById(@Param("id") long id);
@Select("select * from user where name = #{name}")
User findByName(@Param("name") String name);
@Select("select * from user where email = #{email}")
User findByEmail(@Param("email") String email);
// ������ "findByXxx" ����
���ǿ���ֻд����һ������:
@Select("select * from user where ${column} = #{value}")
User findByColumn(@Param("column") String column, @Param("value") String value);
���� ${column} �ᱻֱ���滻,�� #{value} ��ʹ�� ? Ԥ����������,�������ͬ��������:
User userOfId1 = userMapper.findByColumn("id", 1L);
User userOfNameKid = userMapper.findByColumn("name", "kid");
User userOfEmail = userMapper.findByColumn("email", "noone@nowhere.com");
���ַ�ʽҲͬ���������滻�����������
�����ַ�ʽ�����û�������,�������������Dz���ȫ��,�ᵼ��DZ�ڵ� SQL ע�빥�������,Ҫô�������û�������Щ�ֶ�,Ҫô����ת�岢������Щ��������ѯ����ķ�������
��ѯ������� List :

���ص��Ǽ���,resultType ��ֵд���Ǽ�����Ԫ�ص�����

��������Ϊ Map:

���ؽ���� Map ,resultType��ֵд Map����ѯ���Ľ�� ������Ϊ key ,ֵ��Ϊvalue ��

����Dz�ѯ������¼�ҷ�װ�� Map ��,ӳ���ļ��е� resultMap ��Ȼд�����е�����,������Ҫʹ�� @MapKey ע��ָ���ĸ�������Ϊkey��

���ӳ��
ResultMap �����˼����,�Լ��������������,���ڸ���һ������,ֻ��Ҫ�������֮��Ĺ�ϵ�����ˡ�
֮ǰ���Ѿ�������ӳ������ʾ��,����û����ʽָ�� resultMap������:
<select id="selectUsers" resultType="map">
select id, username, hashedPassword
from some_table
where id = #{id}
</select>
�������ֻ�Ǽؽ����е���ӳ�䵽 HashMap �ļ���,���� resultType ����ָ������Ȼ�ڴ�����¶�����,���� HashMap ������һ���ܺõ�����ģ�͡���ij�������ܻ�ʹ�� JavaBean �� POJO(Plain Old Java Objects,��ͨ��ʽ Java ����)��Ϊ����ģ�͡�MyBatis �����߶��ṩ��֧�֡������������ JavaBean:
package com.someapp.model;
public class User {
private int id;
private String username;
private String hashedPassword;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getHashedPassword() {
return hashedPassword;
}
public void setHashedPassword(String hashedPassword) {
this.hashedPassword = hashedPassword;
}
}
���� JavaBean �Ĺ淶,����������� 3 ������:id,username �� hashedPassword����Щ���Ի��Ӧ�� select ����е�������
������һ�� JavaBean ���Ա�ӳ�䵽 ResultSet,����ӳ�䵽 HashMap һ����
<select id="selectUsers" resultType="com.someapp.model.User">
select id, username, hashedPassword
from some_table
where id = #{id}
</select>
���ͱ�������ĺð��֡�ʹ������,��Ϳ��Բ����������ȫ�����ˡ�����:
<!-- mybatis-config.xml �� -->
<typeAlias type="com.someapp.model.User" alias="User"/>
<!-- SQL ӳ�� XML �� -->
<select id="selectUsers" resultType="User">
select id, username, hashedPassword
from some_table
where id = #{id}
</select>
����Щ�����,MyBatis ����Ļ���Զ�����һ�� ResultMap,�ٸ�����������ӳ���е� JavaBean �������ϡ�==�������������������ƥ����,������ SELECT ����������б���(����һ�������� SQL ����)�����ƥ�䡣==����:
<select id="selectUsers" resultType="User">
select
user_id as "id",
user_name as "userName",
hashed_password as "hashedPassword"
from some_table
where id = #{id}
</select>
��ѧϰ�������֪ʶ��,��ᷢ�����������û��һ����Ҫ��ʽ���� ResultMap,����� ResultMap ������֮����������ȫ���Բ�����ʽ���������ǡ���Ȼ��������Ӳ�����ʽ���� ResultMap����Ϊ�˽���,��������������ڸոյ�ʾ����,��ʽʹ���ⲿ�� resultMap ������,��Ҳ�ǽ��������ƥ�������һ�ַ�ʽ��
<resultMap id="userResultMap" type="User">
<id property="id" column="user_id" />
<result property="username" column="user_name"/>
<result property="password" column="hashed_password"/>
</resultMap>
Ȼ��������������������� resultMap ���Ծ�����(ע������ȥ���� resultType ����)������:
<select id="selectUsers" resultMap="userResultMap">
select user_id, user_name, hashed_password
from some_table
where id = #{id}
</select>
�����ӳ��
MyBatis ����ʱ��һ��˼����:���ݿⲻ������Զ���������������Ǹ����ӡ�����ϣ��ÿ�����ݿⶼ�߱�������ʽ�� BCNF ��ʽ,��ϧ���Dz��������������������һ�����ݿ�ӳ��ģʽ,�����������е�Ӧ�ó���,�Ǿ�̫����,����ϧҲû�С��� ResultMap ���� MyBatis ���������Ĵ𰸡�
����,�������ӳ������������?
<!-- �dz����ӵ���� -->
<select id="selectBlogDetails" resultMap="detailedBlogResultMap">
select
B.id as blog_id,
B.title as blog_title,
B.author_id as blog_author_id,
A.id as author_id,
A.username as author_username,
A.password as author_password,
A.email as author_email,
A.bio as author_bio,
A.favourite_section as author_favourite_section,
P.id as post_id,
P.blog_id as post_blog_id,
P.author_id as post_author_id,
P.created_on as post_created_on,
P.section as post_section,
P.subject as post_subject,
P.draft as draft,
P.body as post_body,
C.id as comment_id,
C.post_id as comment_post_id,
C.name as comment_name,
C.comment as comment_text,
T.id as tag_id,
T.name as tag_name
from Blog B
left outer join Author A on B.author_id = A.id
left outer join Post P on B.id = P.blog_id
left outer join Comment C on P.id = C.post_id
left outer join Post_Tag PT on PT.post_id = P.id
left outer join Tag T on PT.tag_id = T.id
where B.id = #{id}
</select>
����������ӳ�䵽һ�����ܵĶ���ģ��,��������ʾ��һƪ����,����ijλ������д,�кܶ�IJ���,ÿƪ�����������������ۺͱ�ǩ�������������������������������,����һ���dz����ӵĽ��ӳ��(��������,����,����,���ۺͱ�ǩ�������ͱ���)�����ý���,���ǻ�һ��һ������˵������Ȼ������������������η,����ʵ�dz���
<!-- �dz����ӵĽ��ӳ�� -->
<resultMap id="detailedBlogResultMap" type="Blog">
<constructor>
<idArg column="blog_id" javaType="int"/>
</constructor>
<result property="title" column="blog_title"/>
<association property="author" javaType="Author">
<id property="id" column="author_id"/>
<result property="username" column="author_username"/>
<result property="password" column="author_password"/>
<result property="email" column="author_email"/>
<result property="bio" column="author_bio"/>
<result property="favouriteSection" column="author_favourite_section"/>
</association>
<collection property="posts" ofType="Post">
<id property="id" column="post_id"/>
<result property="subject" column="post_subject"/>
<association property="author" javaType="Author"/>
<collection property="comments" ofType="Comment">
<id property="id" column="comment_id"/>
</collection>
<collection property="tags" ofType="Tag" >
<id property="id" column="tag_id"/>
</collection>
<discriminator javaType="int" column="draft">
<case value="1" resultType="DraftPost"/>
</discriminator>
</collection>
</resultMap>
resultMap Ԫ���кܶ���Ԫ�غ�һ��ֵ������̽�ֵĽṹ��������resultMap Ԫ�صĸ�����ͼ��
���ӳ��(resultMap)
-
constructor- ������ʵ������ʱ,ע���������췽����idArg- ID ����;��dz���Ϊ ID �Ľ�������������������arg- ����ע�뵽���췽����һ����ͨ���
-
id- һ�� ID ���;��dz���Ϊ ID �Ľ������������������� -
result- ע�뵽�ֶλ� JavaBean ���Ե���ͨ��� -
association- һ���������͵Ĺ���;����������װ����������- Ƕ���ӳ�� - ����������
resultMapԪ��,���Ƕ��������ӳ�������
- Ƕ���ӳ�� - ����������
-
collection- һ���������͵ļ���- Ƕ���ӳ�� - ���Ͽ�����
resultMapԪ��,���Ƕ��������ӳ���Ӧ��
- Ƕ���ӳ�� - ���Ͽ�����
-
discriminator- ʹ�ý��ֵ������ʹ���ĸ�resultMap-
case- ����ijЩֵ�Ľ��ӳ��-
Ƕ���ӳ�� -
caseҲ��һ�����ӳ��,��˾�����ͬ�Ľṹ��Ԫ��;�������������Ľ��ӳ��? ResultMap �������б�
-
-

��һ���ֽ���ϸ˵��ÿ��Ԫ�ء�
id & result
<id property="id" column="post_id"/>
<result property="subject" column="post_subject"/>
��ЩԪ���ǽ��ӳ��Ļ�����id �� result Ԫ�ض���һ���е�ֵӳ�䵽һ������������(String,int,double,Date��)�����Ի��ֶΡ�
������֮���Ψһ��ͬ��,id Ԫ�ض�Ӧ�����Իᱻ���Ϊ����ı�ʶ��,�ڱȽ϶���ʵ��ʱʹ�á���������������������,�����ǽ��л����Ƕ���ӳ��(Ҳ��������Ƕ��)��ʱ��
����Ԫ�ض���һЩ����:
? Id �� Result ������

����
<association property="author" column="blog_author_id" javaType="Author">
<id property="id" column="author_id"/>
<result property="username" column="author_username"/>
</association>
����(association)Ԫ�ش�������һ�������͵Ĺ�ϵ������,�����ǵ�ʾ����,һ��������һ���û����������ӳ����������͵�ӳ�乤����ʽ��ࡣ����Ҫָ��Ŀ���������Լ����Ե�javaType(�ܶ�ʱ�� MyBatis �����Լ��ƶϳ���),�ڱ�Ҫ��������㻹�������� JDBC ����,������븲�ǻ�ȡ���ֵ�Ĺ���,�������������ʹ�������
�����IJ�֮ͬ����,����Ҫ���� MyBatis ��μ��ع�����MyBatis �����ֲ�ͬ�ķ�ʽ���ع���:
- Ƕ�� Select ��ѯ:ͨ��ִ������һ�� SQL ӳ����������������ĸ������͡�
- Ƕ���ӳ��:ʹ��Ƕ�Ľ��ӳ�����������ӽ�����ظ��Ӽ���
����,�����������������Ԫ�ص����ԡ��㽫�ᷢ��,����ͨ�Ľ��ӳ�����,��ֻ�� select �� resultMap ������������ͬ��

������Ƕ�� Select ��ѯ
ʾ��:
<select id="selectBlog" resultMap="blogResult">
SELECT * FROM BLOG WHERE ID = #{id}
</select>
<resultMap id="blogResult" type="Blog">
<association property="author" column="author_id" javaType="Author" select="selectAuthor"/>
</resultMap>
<select id="selectAuthor" resultType="Author">
<!-- ����� #{id} �����ϱߵ�column �ڵ�һ������в�ѯ������ -->
SELECT * FROM AUTHOR WHERE ID = #{id}
</select>
������ѯ��ʱ�� SQL ���ܻ�Ƚϸ���,���� MyBatis ���ǵ�����һ�㡣����,���ǿ��ѹ�����ѯ�ֳɶಽ������ʾ��,������ select ��ѯ:һ���������ز���(Blog),����һ��������������(Author),���Ҳ��͵Ľ��ӳ��������Ӧ��ʹ�� selectAuthor ���������� author ���ԡ�
�������������Խ��ᱻ�Զ�����,ֻҪ���ǵ���������������ƥ�䡣
���ַ�ʽ���,���ڴ������ݼ���������ݱ��ϱ��ֲ��ѡ�������ⱻ��Ϊ��N+1����ѯ���⡣�����ؽ�,N+1 ��ѯ�����������ӵ�:
- ��ִ����һ�������� SQL �������ȡ�����һ���б�(���ǡ�+1��)��
- ���б����ص�ÿ����¼,��ִ��һ�� select ��ѯ�����Ϊÿ����¼������ϸ��Ϣ(���ǡ�N��)��
�������ᵼ�³ɰ���ǧ�� SQL ��䱻ִ�С���ʱ��,���Dz�ϣ�����������ĺ����
����Ϣ��,MyBatis �ܹ��������IJ�ѯ�����ӳټ���,��˿��Խ��������ͬʱ���еĿ�����ɢ������Ȼ��,�������ؼ�¼�б�֮�����̾ͱ����б��Ի�ȡǶ������,�ͻᴥ�����е��ӳټ��ز�ѯ,���ܿ��ܻ��ú���⡣
������Ƕ���ӳ��

�������������һ���dz�������,������ʾǶ���ӳ����ι����� �������ǽ����ͱ������߱�������һ��,������ִ��һ�������IJ�ѯ���,��������:
<select id="selectBlog" resultMap="blogResult">
select
B.id as blog_id,
B.title as blog_title,
B.author_id as blog_author_id,
A.id as author_id,
A.username as author_username,
A.password as author_password,
A.email as author_email,
A.bio as author_bio
from Blog B left outer join Author A on B.author_id = A.id
where B.id = #{id}
</select>
ע���ѯ�е�����,�Լ�Ϊȷ������ܹ�ӵ��Ψһ������������,�������õı�������ʹ�ý���ӳ��dz����������ǿ���ӳ��������:
<resultMap id="blogResult" type="Blog">
<id property="id" column="blog_id" />
<result property="title" column="blog_title"/>
<association property="author" column="blog_author_id" javaType="Author" resultMap="authorResult"/>
</resultMap>
<resultMap id="authorResult" type="Author">
<id property="id" column="author_id"/>
<result property="username" column="author_username"/>
<result property="password" column="author_password"/>
<result property="email" column="author_email"/>
<result property="bio" column="author_bio"/>
</resultMap>
�������������,����Կ���,����(Blog)����(author)�Ĺ���Ԫ��ί����Ϊ ��authorResult�� �Ľ��ӳ�����������߶����ʵ����
����,�����ʾ��ʹ�����ⲿ�Ľ��ӳ��Ԫ����ӳ���������ʹ�� Author �Ľ��ӳ����Ա����á�Ȼ��,����㲻����������,�������ϲ���������еĽ��ӳ�����һ�����������ԵĽ��ӳ��Ԫ���С������ֱ�ӽ����ӳ����Ϊ��Ԫ��Ƕ�����ڡ��������ʹ�����ַ�ʽ�ĵ�Ч����:
<resultMap id="blogResult" type="Blog">
<id property="id" column="blog_id" />
<result property="title" column="blog_title"/>
<association property="author" javaType="Author">
<id property="id" column="author_id"/>
<result property="username" column="author_username"/>
<result property="password" column="author_password"/>
<result property="email" column="author_email"/>
<result property="bio" column="author_bio"/>
</association>
</resultMap>
���������(blog)��һ����ͬ����(co-author)����ô��?select ��俴��������������:
<select id="selectBlog" resultMap="blogResult">
select
B.id as blog_id,
B.title as blog_title,
A.id as author_id,
A.username as author_username,
A.password as author_password,
A.email as author_email,
A.bio as author_bio,
CA.id as co_author_id,
CA.username as co_author_username,
CA.password as co_author_password,
CA.email as co_author_email,
CA.bio as co_author_bio
from Blog B
left outer join Author A on B.author_id = A.id
left outer join Author CA on B.co_author_id = CA.id
where B.id = #{id}
</select>
����һ��,Author �Ľ��ӳ�䶨������:
resultMap id="authorResult" type="Author">
<id property="id" column="author_id"/>
<result property="username" column="author_username"/>
<result property="password" column="author_password"/>
<result property="email" column="author_email"/>
<result property="bio" column="author_bio"/>
</resultMap>
���ڽ���е���������ӳ���е�������ͬ������Ҫָ�� columnPrefix �Ա��ظ�ʹ�øý��ӳ����ӳ�� co-author �Ľ����
<resultMap id="blogResult" type="Blog">
<id property="id" column="blog_id" />
<result property="title" column="blog_title"/>
<association property="author"
resultMap="authorResult" />
<association property="coAuthor"
resultMap="authorResult"
columnPrefix="co_" />
</resultMap>
�����Ķ�����(ResultSet)

�Ӱ汾 3.2.3 ��ʼ,MyBatis �ṩ����һ�ֽ�� N+1 ��ѯ����ķ�����
ijЩ���ݿ������洢���̷��ض�������,��һ����ִ�ж�����,ÿ����䷵��һ��������� ���ǿ��������������,�ڲ�ʹ�����ӵ������,ֻ�������ݿ�һ�ξ��ܻ��������ݡ�
��������,�洢����ִ������IJ�ѯ�������������������һ��������᷵�ز���(Blog)�Ľ��,�ڶ���������(Author)�Ľ����
SELECT * FROM BLOG WHERE ID = #{id}
SELECT * FROM AUTHOR WHERE ID = #{id}
��ӳ�������,����ͨ�� resultSets ����Ϊÿ�������ָ��һ������,�������ʹ�ö��Ÿ�����
<select id="selectBlog" resultSets="blogs,authors" resultMap="blogResult" statementType="CALLABLE">
{call getBlogsAndAuthors(#{id,jdbcType=INTEGER,mode=IN})}
</select>
�������ǿ���ָ��ʹ�� ��authors�� ���������������� ��author�� ����:
<resultMap id="blogResult" type="Blog">
<id property="id" column="id" />
<result property="title" column="title"/>
<association property="author" javaType="Author" resultSet="authors" column="author_id" foreignColumn="id">
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="password" column="password"/>
<result property="email" column="email"/>
<result property="bio" column="bio"/>
</association>
</resultMap>
���Ѿ������濴������δ�������һ�������͵Ĺ��������Ǹ���ô�������кܶ�������͵Ĺ�����?��������ǽ�����Ҫ���ܵġ�
����
<collection property="posts" ofType="domain.blog.Post">
<id property="id" column="post_id"/>
<result property="subject" column="post_subject"/>
<result property="body" column="post_body"/>
</collection>
����Ԫ�غ���Ԫ�ؼ�����һ����,�������Ƶij̶�֮��,������û�б�Ҫ�ٽ��ܼ���Ԫ�ص����Ʋ��֡� ��������������ע���ǵIJ�֮ͬ���ɡ�
���������������ʾ��,һ������(Blog)ֻ��һ������(Author)����һ�������кܶ�����(Post)���ڲ�������,������������д������ʾ:
private List<Post> posts;
Ҫ����������,ӳ��Ƕ������ϵ�һ�� List ��,����ʹ�ü���Ԫ�ء�����Ԫ��һ��,���ǿ���ʹ��Ƕ�� Select ��ѯ,��������ӵ�Ƕ���ӳ�伯�ϡ�
���ϵ�Ƕ�� Select ��ѯ
����,�����ǿ������ʹ��Ƕ�� Select ��ѯ��Ϊ���ͼ������¡�
<select id="selectBlog" resultMap="blogResult">
SELECT * FROM BLOG WHERE ID = #{id}
</select>
<resultMap id="blogResult" type="Blog">
<collection property="posts" javaType="ArrayList" column="id" ofType="Post" select="selectPostsForBlog"/>
</resultMap>
<select id="selectPostsForBlog" resultType="Post">
SELECT * FROM POST WHERE BLOG_ID = #{id}
</select>
����,���ע�����ʹ�õ��Ǽ���Ԫ�ء����������ע���һ���µ� ��ofType�� ���ԡ�������Էdz���Ҫ,�������� JavaBean(���ֶ�)���Ե����ͺͼ��ϴ洢���������ֿ���������������������������Ķ�ӳ��:
<collection property="posts" javaType="ArrayList" column="id" ofType="Post" select="selectPostsForBlog"/>
����: ��posts ��һ���洢 Post �� ArrayList ���ϡ�
��һ�������,MyBatis �����ƶ� javaType ����,��˲�����Ҫ��д�����Ժܶ�ʱ������Լ��Գ�:
<collection property="posts" column="id" ofType="Post" select="selectPostsForBlog"/>
���ϵ�Ƕ���ӳ��
����������Ѿ��µ��˼��ϵ�Ƕ���ӳ�������������ġ������������� ��ofType�� ����,����������ȫ��ͬ��
����, �����ǿ�����Ӧ�� SQL ���:
<select id="selectBlog" resultMap="blogResult">
select
B.id as blog_id,
B.title as blog_title,
B.author_id as blog_author_id,
P.id as post_id,
P.subject as post_subject,
P.body as post_body,
from Blog B
left outer join Post P on B.id = P.blog_id
where B.id = #{id}
</select>
�����ٴ������˲��ͱ������±�,����Ϊÿһ�ж�������һ��������ı���,�Ա�ӳ�䱣�ּ�Ҫӳ�䲩����������¼���,����ô��:
<resultMap id="blogResult" type="Blog">
<id property="id" column="blog_id" />
<result property="title" column="blog_title"/>
<collection property="posts" ofType="Post">
<id property="id" column="post_id"/>
<result property="subject" column="post_subject"/>
<result property="body" column="post_body"/>
</collection>
</resultMap>
����:
һ��һ��ϵ,1-1 ��������Ķ˶���
һ�Զ��ϵ,1-n ������ڶ����һ��,Ҳ���Զ�����һ�ű�
��Զ��ϵ, n-n ���Ҳ�������ű��Ĺ�ϵ�ı�ʾ,����ͨ�������±�����ʾ,��Ϊֻ���������������������,����Ψһ�ı�ʶһ����¼
����
MyBatis ������һ��ǿ��������Բ�ѯ�������,�����Էdz���������úͶ��ơ�Ϊ��ʹ������ǿ�������������,���Ƕ� MyBatis 3 �еĻ���ʵ�ֽ���������Ľ���
Ĭ�������,ֻ�����˱��صĻỰ����(Ҳ��һ�����桢SqlSession����Ļ���),��������һ���Ự�е����ݽ��л��档
һ������
Reader reader = Resources.getResourceAsReader("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = sqlSessionFactory.openSession();
PersonMapper mapper1 = session.getMapper(PersonMapper.class);
Person person1 = mapper1.queryPersonById(1);
System.out.println(person1);
PersonMapper mapper2 = session.getMapper(PersonMapper.class);
Person person2 = mapper2.queryPersonById(1);
System.out.println(person2);

���Կ���,���β�ѯͬһ������ֻ������һ�� SQL ������
һ������ʧЧ�����:
1����ͬ�� SqlSession ,ʹ�ò�ͬ��һ�����档
Reader reader = Resources.getResourceAsReader("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
// ��һ���Ự
SqlSession session1 = sqlSessionFactory.openSession();
PersonMapper mapper1 = session1.getMapper(PersonMapper.class);
Person person1 = mapper1.queryPersonById(1);
System.out.println(person1);
System.out.println("==========================================");
// �ڶ����Ự
SqlSession session2 = sqlSessionFactory.openSession();
PersonMapper mapper2 = session2.getMapper(PersonMapper.class);
Person person2 = mapper2.queryPersonById(1);
System.out.println(person2);
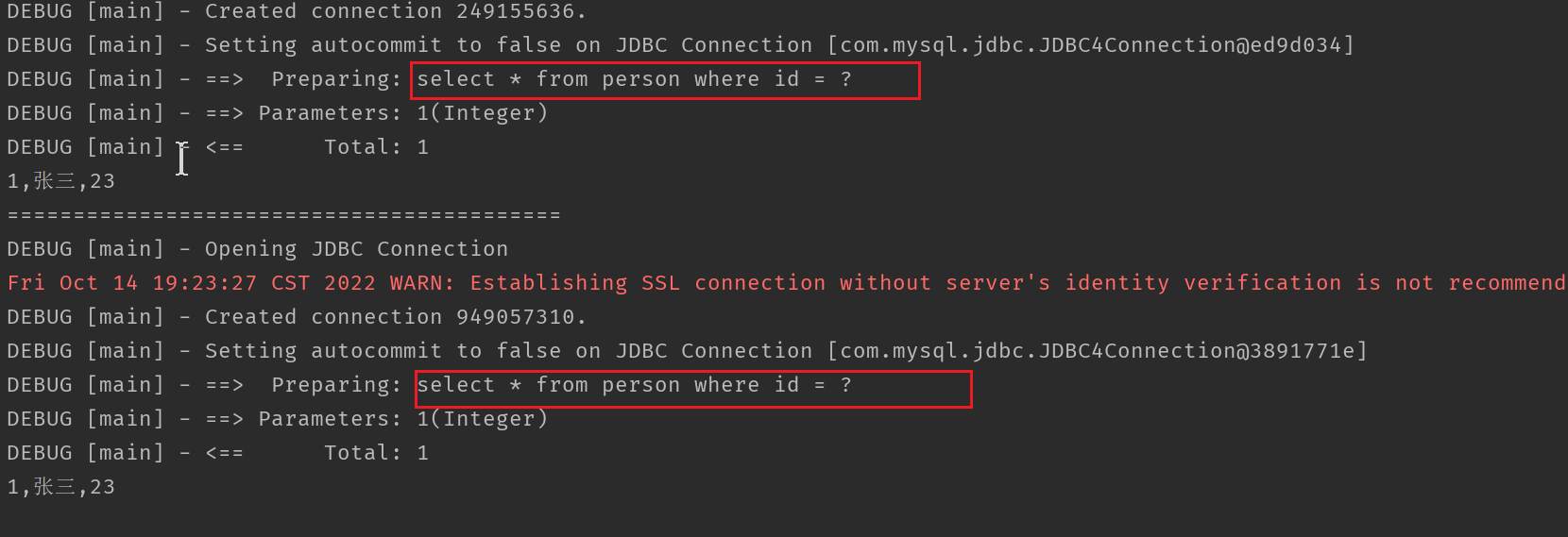
�������Կ���,��ѯͬһ������ȷ���������� SQL ���,ԭ����ʲô��?
һ�������� SqlSession ����Ļ���,ֻ����ͬһ��sqlSession�ڼ��ѯ�������ݻᱣ�������sqlSession�Ļ����С��´�ʹ�����sqlSession��ѯ��ӻ������á�
2����ѯ������ֵ��ͬ
Reader reader = Resources.getResourceAsReader("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
// ��һ���Ự
SqlSession session1 = sqlSessionFactory.openSession();
PersonMapper mapper1 = session1.getMapper(PersonMapper.class);
Person person1 = mapper1.queryPersonById(1);
System.out.println(person1);
System.out.println("==========================================");
// �ڶ����Ự
//SqlSession session2 = sqlSessionFactory.openSession();
PersonMapper mapper2 = session1.getMapper(PersonMapper.class);
Person person2 = mapper2.queryPersonById(2);
System.out.println(person2);
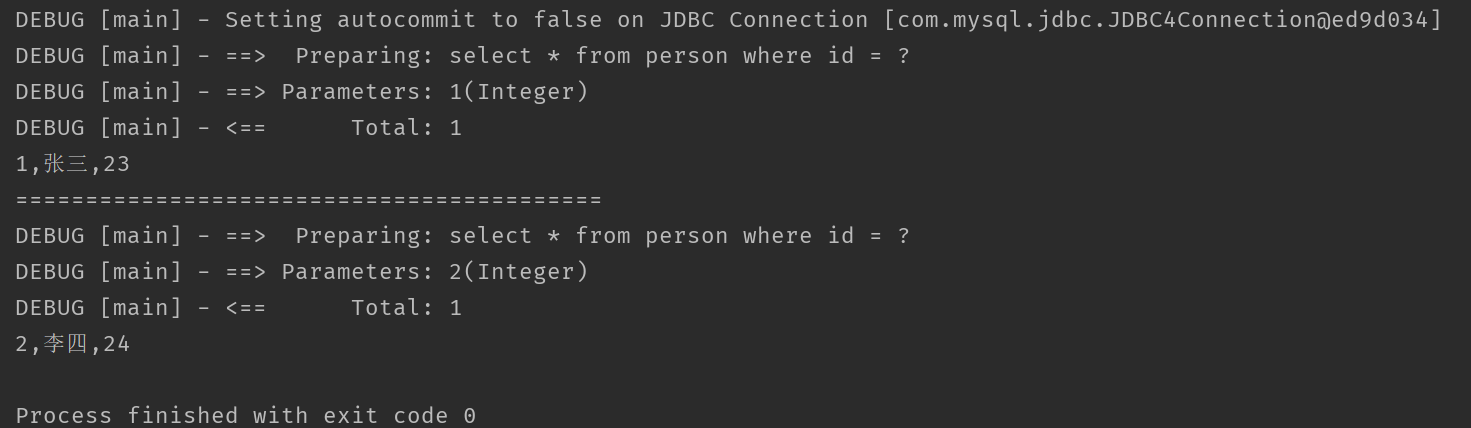
�����ͼ,��Ȼ�������� SQL ��䡣
3����ͬһ�� sqlSession �ڼ�ִ���κ�һ����ɾ�IJ���,��ɾ�IJ�����ѻ�����ա�
Reader reader = Resources.getResourceAsReader("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
// ��һ���Ự
SqlSession session1 = sqlSessionFactory.openSession();
PersonMapper mapper1 = session1.getMapper(PersonMapper.class);
Person person1 = mapper1.queryPersonById(1);
System.out.println(person1);
System.out.println("==========================================");
// ���β�ѯ�� ִ��һ����ɾ��
mapper1.updatePerson(1);
// �ڶ����Ự
//SqlSession session2 = sqlSessionFactory.openSession();
PersonMapper mapper2 = session1.getMapper(PersonMapper.class);
Person person2 = mapper2.queryPersonById(1);
System.out.println(person2);
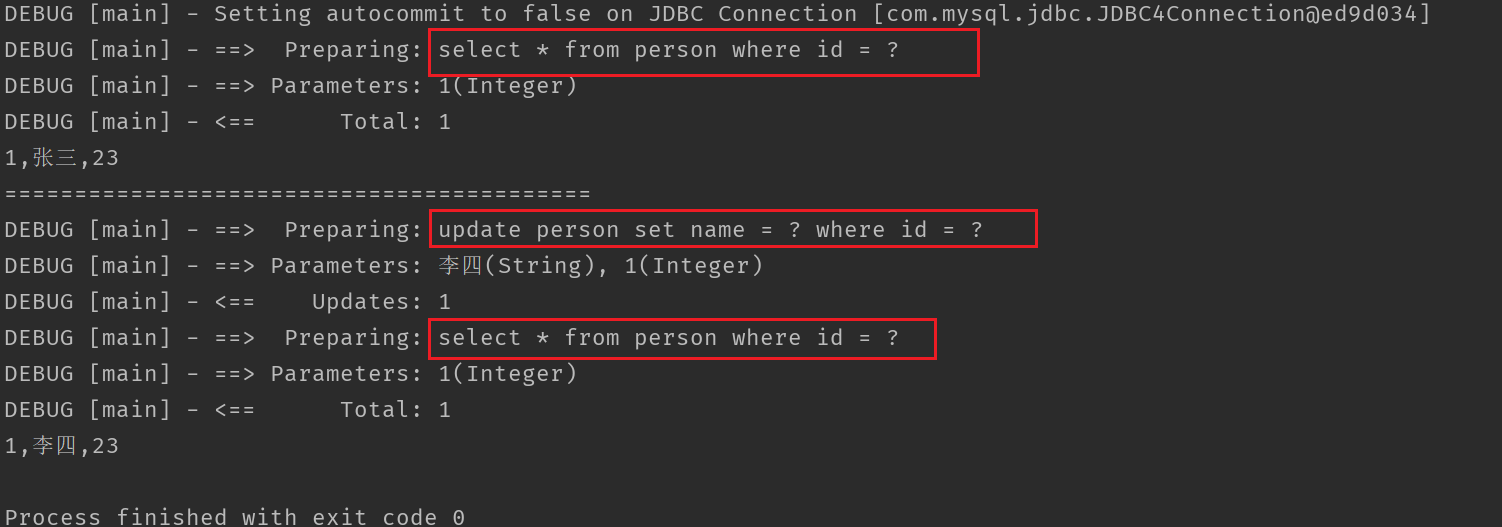
��������
Ҫ����ȫ�ֵĶ�������,ֻ��Ҫ����� SQL ӳ���ļ�������һ��:
<cache/>
�����Ͼ������������������Ч������:
- ӳ������ļ��е����� select ���Ľ�����ᱻ���档
- ӳ������ļ��е����� insert��update �� delete ����ˢ�»��档
- �����ʹ���������ʹ���㷨(LRU, Least Recently Used)�㷨���������Ҫ�Ļ��档
- ���治�ᶨʱ����ˢ��(Ҳ����˵,û��ˢ�¼��)��
- ����ᱣ���б������(���۲�ѯ������������)�� 1024 �����á�
- ����ᱻ��Ϊ��/д����,����ζ�Ż�ȡ���Ķ����ǹ�����,����ȫ�ر���������,�������������������߳�������DZ���ġ�
����ֻ������ cache ��ǩ���ڵ�ӳ���ļ��е���䡣
��Щ���Կ���ͨ�� cache Ԫ�ص��������ġ�����:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
������������ô�����һ�� FIFO ����,ÿ�� 60 ��ˢ��,�����Դ洢���������б��� 512 ������,���ҷ��صĶ�����Ϊ��ֻ����,��˶����ǽ����Ŀ��ܻ��ڲ�ͬ�߳��еĵ����߲�����ͻ��
���õ����������:
LRU�C �������ʹ��:�Ƴ��ʱ�䲻��ʹ�õĶ���FIFO�C �Ƚ��ȳ�:��������뻺���˳�����Ƴ����ǡ�SOFT�C ������:��������������״̬�������ù����Ƴ�����WEAK�C ������:�������ػ��������ռ���״̬�������ù����Ƴ�����
flushInterval(ˢ�¼��)���Կ��Ա�����Ϊ�����������,���õ�ֵӦ����һ���Ժ���Ϊ��λ�ĺ���ʱ������ Ĭ������Dz�����,Ҳ����û��ˢ�¼��,����������ڵ������ʱˢ�¡�
size(������Ŀ)���Կ��Ա�����Ϊ����������,Ҫע�����������Ĵ�С�����л����п��õ��ڴ���Դ��Ĭ��ֵ�� 1024��
readOnly(ֻ��)���Կ��Ա�����Ϊ true �� false��ֻ���Ļ��������е����߷��ػ���������ͬʵ���� �����Щ�����ܱ��ġ�����ṩ�˿ɹ۵��������������ɶ�д�Ļ����(ͨ�����л�)���ػ������Ŀ������ٶ��ϻ���һЩ,���Ǹ���ȫ,���Ĭ��ֵ�� false��
����Ի��������(��������ԡ��ɶ���ɶ�д��),����Ӧ�����Զ��建�档���������������Եġ�����ζ��,�� SqlSession ��ɲ��ύʱ,������ɲ��ع�,��û��ִ�� flushCache=true �� insert/delete/update ���ʱ,������ø��¡�
��ע��,��������úͻ���ʵ���ᱻ�� SQL ӳ���ļ��������ռ��С����,ͬһ�����ռ��е��������ͻ��潫ͨ�������ռ����һ��ÿ���������Զ����뻺�潻���ķ�ʽ,��������ȫ�ų��ڻ���֮��,�����ͨ����ÿ�������ʹ����������������ɡ�Ĭ�������,��������������:
<select ... flushCache="false" useCache="true"/>
<insert ... flushCache="true"/>
<update ... flushCache="true"/>
<delete ... flushCache="true"/>
��������Ĭ����Ϊ,��Ȼ����Զ��Ӧ���������ķ�ʽ��ʽ����һ����䡣���������ı�Ĭ�ϵ���Ϊ,ֻ��Ҫ���� flushCache �� useCache ���ԡ�����,ijЩ����������ϣ���ض� select ���Ľ���ų��ڻ���֮��,��ϣ��һ�� select �����ջ��档���Ƶ�,�����ϣ��ijЩ update ���ִ��ʱ��Ҫˢ�»��档
ʹ���Զ��建��
˼��:
�Լ�дһ��������ȥʵ�� org.apache.ibatis.cache.Cache �ӿڡ�Ȼ����Ҫʹ�û����ӳ���ļ��еı�ǩ��type����ʹ���Զ���Ļ�����
<cache type="com.domain.something.MyCustomCache"/>
�Ϳ���ʹ���ˡ�
������������ Ehcache ��������:
����,������� Jar ��:
ehcache-core-x.x.x.jar
mybatis-ehcache-x.x.x.jar
slf4j-api-x.x.x.jar
log4j-x.x.x.jar
���� mybatis-ehcache ��� jar�� ,Ehcache ������Ѿ�ʵ���� Cache �ӿ�

����ֱ��ʹ�þͿ����ˡ�
Ehcache.xml �����ļ�
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<!--
diskStore:Ϊ����·��,ehcache��Ϊ�ڴ�ʹ�������,�����Զ�����̵Ļ���λ�á�������������:
user.home �C �û���Ŀ¼
user.dir �C �û���ǰ����Ŀ¼
java.io.tmpdir �C Ĭ����ʱ�ļ�·��
-->
<diskStore path="E:\Ehcache"/>
<!--
defaultCache:Ĭ�ϻ������,��ehcache�Ҳ�������Ļ���ʱ,��ʹ�����������ԡ�ֻ�ܶ���һ����
-->
<!--
name:�������ơ�
maxElementsInMemory:���������Ŀ
maxElementsOnDisk:Ӳ����������
eternal:�����Ƿ�������Ч,һ��������,timeout���������á�
overflowToDisk: ���ڴ��л���Ķ������ ����maxElementsInMemory ,�Ƿ�ת�Ƶ�Ӳ����
timeToIdleSeconds:���ö�����ʧЧǰ����������ʱ��(��λ:��)������eternal=false������������Чʱʹ��,��ѡ����,Ĭ��ֵ��0,Ҳ���ǿ�����ʱ�������
timeToLiveSeconds:���ö�����ʧЧǰ�������ʱ��(��λ:��)�����ʱ����ڴ���ʱ���ʧЧʱ��֮�䡣����eternal=false������������Чʱʹ��,Ĭ����0.,Ҳ���Ƕ�����ʱ�������
diskPersistent:�Ƿ���������������� Whether the disk store persists between restarts of the Virtual Machine. The default value is false.
diskSpoolBufferSizeMB:�����������DiskStore(���̻���)�Ļ�������С��Ĭ����30MB��ÿ��Cache��Ӧ�����Լ���һ����������
diskExpiryThreadIntervalSeconds:����ʧЧ�߳�����ʱ����,Ĭ����120�롣
memoryStoreEvictionPolicy:���ﵽmaxElementsInMemory����ʱ,Ehcache�������ָ���IJ���ȥ�����ڴ档Ĭ�ϲ�����LRU(�������ʹ��)�����������ΪFIFO(�Ƚ��ȳ�)����LFU(����ʹ��)��
clearOnFlush:�ڴ��������ʱ�Ƿ������
memoryStoreEvictionPolicy:��ѡ������:LRU(�������ʹ��,Ĭ�ϲ���)��FIFO(�Ƚ��ȳ�)��LFU(���ٷ��ʴ���)��
FIFO,first in first out,����Ǵ�������,�Ƚ��ȳ���
LFU, Less Frequently Used,��������������ʹ�õIJ���,ֱ��һ����ǽ�һֱ�������ٱ�ʹ�õġ�����������,�����Ԫ����һ��hit����,hitֵ��С�Ľ��ᱻ������档
LRU,Least Recently Used,�������ʹ�õ�,�����Ԫ����һ��ʱ���,��������������,������Ҫ�ڳ��ط��������µ�Ԫ�ص�ʱ��,��ô���л���Ԫ����ʱ����뵱ǰʱ����Զ��Ԫ�ؽ���������档
-->
<defaultCache
maxElementsInMemory="1000"
maxElementsOnDisk="1000000"
eternal="false"
overflowToDisk="false"
timeToIdleSeconds="100"
timeToLiveSeconds="100"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"
></defaultCache>
</ehcache>
Ȼ����Ҫʹ�û����ӳ���ļ���ʹ��
<cache type="org.mybatis.caches.ehcache.EhcacheCache">
<!--ͨ��property����Ehcache.xml�е�ֵ
<property name="maxElementsInMemory" value="2000"/>
<property name="maxElementsOnDisk" value="3000"/>
-->
</cache>
��ijһ�����ռ�����,ֻ��ʹ�ø������ռ�Ļ�����л����ˢ�¡�������ܻ���Ҫ�ڶ�������ռ��й�����ͬ�Ļ������ú�ʵ����Ҫʵ����������,�����ʹ�� cache-ref Ԫ����������һ�����档
<cache-ref namespace="���������SQLӳ���ļ������ƿռ�"/>
�ܽ�:
1���������һ������Ͷ�����������ͬһ������
? ����������,һ������ر��˾�����
? һ��������,����������û�д�����,�ͻῴһ������,һ������û�о�ȥ�����ݿ�,���ݿ�IJ�ѯ�������һ�������С��ر�sqlSession���һ����������ݷ��ڶ��������С�
2���κ�ʱ�����ȿ��������桢�ٿ�һ������,�����Ҷ�û�о�ȥ��ѯ���ݿ⡣
��̬ SQL
��̬ SQL �� MyBatis ��ǿ������֮һ�������ʹ�ù� JDBC ���������ƵĿ��,��Ӧ����������ݲ�ͬ����ƴ�� SQL ����ж�ʹ��,����ƴ��ʱҪȷ�������������ӱ�Ҫ�Ŀո�,��Ҫע��ȥ���б����һ�������Ķ��š����ö�̬ SQL,���Գ��װ�������ʹ�ࡣ
ʹ�ö�̬ SQL ����һ������,�������������κ� SQL ӳ������е�ǿ��Ķ�̬ SQL ����,MyBatis ��������������һ���Ե������ԡ�
�����֮ǰ�ù� JSTL ���κλ����� XML ���Ե��ı�������,��Զ�̬ SQL Ԫ�ؿ��ܻ�о�������ʶ����MyBatis ֮ǰ�İ汾��,��Ҫ��ʱ���˽������Ԫ�ء���������ǿ��Ļ��� OGNL �ı���ʽ,MyBatis 3 �滻��֮ǰ�Ĵ�Ԫ��,�����Ԫ������,����Ҫѧϰ��Ԫ�������ԭ����һ�뻹Ҫ�١�
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
if
ʹ�ö�̬ SQL ����龰�Ǹ����������� where �Ӿ��һ���֡�����:
<select id="findActiveBlogWithTitleLike"
resultType="Blog">
SELECT * FROM BLOG
WHERE state = ��ACTIVE��
<if test="title != null">
AND title like #{title}
</if>
</select>
��������ṩ�˿�ѡ�IJ����ı����ܡ���������� ��title��,��ô���д��� ��ACTIVE�� ״̬�� BLOG ���᷵��;��������� ��title�� ����,��ô�ͻ�� ��title�� һ�н���ģ�����Ҳ����ض�Ӧ�� BLOG ���(ϸ�ĵĶ��߿��ܻᷢ��,��title�� �IJ���ֵ��Ҫ�������������ͨ����ַ�)��
���ϣ��ͨ�� ��title�� �� ��author�� �����������п�ѡ��������ô����?����,�����Ƚ���������ijɸ�������ʵ������;������,ֻ��Ҫ������һ���������ɡ�
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ��ACTIVE��
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
test :�����
trim��where��set
������ǽ� ��state = ��ACTIVE���� ���óɶ�̬����,�����ᷢ��ʲô��
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
WHERE
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
���û��ƥ�����������ô��?�������� SQL ��������:
SELECT * FROM BLOG WHERE
����˵�������һ������,��ô SQL �ֻ�������:
SELECT * FROM BLOG WHERE AND title like #{title} AND author_name like #{author.name}
���������ѯʧ��,�������ⲻ�ܼ�������Ԫ��������������������˵����Խ��,�����ڽ�������˲������������������⡣
MyBatis ��һ�������ʺϴ���������Ľ���취����������������,���Զ�������Զ����Է���������,ֻ��Ҫһ���ĸĶ�:
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
where Ԫ��ֻ������Ԫ�ط����κ����ݵ�����²Ų��� ��WHERE�� �Ӿ䡣����,���Ӿ�Ŀ�ͷΪ ��AND�� �� ��OR��,where Ԫ��Ҳ�Ὣ����ȥ����
��� where Ԫ�����������IJ�̫һ��,��Ҳ����ͨ���Զ��� trim Ԫ�������� where Ԫ�صĹ��ܡ�����,�� where Ԫ�صȼ۵��Զ��� trim Ԫ��Ϊ:
<trim prefix="" prefixOverrides="" suffix="" suffixOverrides=""></trim>
prefix:ǰ,Ϊ SQL ��������һ��ǰ
prefixOverrides:ȥ�������ַ���ǰ�������ַ�
suffix:Ϊ��������һ����
suffixOverrides:ȥ�����������ַ�
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<trim prefix="where" prefixOverrides="and" suffixOverrides="and">
<if test="state != null">
state = #{state} AND
</if>
<if test="title != null">
title like #{title} AND
</if>
<if test="author != null and author.name != null">
author_name like #{author.name} AND
</if>
</trim>
</select>
���ڶ�̬�����������ƽ���������� set��set Ԫ�ؿ������ڶ�̬������Ҫ���µ���,�������������µ��С�����:
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">
username=#{username},
</if>
<if test="password != null">
password=#{password},
</if>
<if test="email != null">
email=#{email},
</if>
<if test="bio != null">
bio=#{bio}
</if>
</set>
where id=#{id}
</update>
���������,set Ԫ�ػᶯ̬�������ײ��� SET �ؼ���,����ɾ������Ķ���(��Щ��������ʹ�����������и�ֵʱ�����)������,�����ͨ��ʹ�� trim Ԫ�����ﵽͬ����Ч��:
<trim prefix="SET" suffixOverrides=",">
...
</trim>
ע��,���Ǹ����˺�ֵ����,�����Զ�����ǰֵ��
foreach
��̬ SQL ����һ������ʹ�ó����ǶԼ��Ͻ��б���(�������ڹ��� IN ��������ʱ��)������:
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
<where>
<foreach item="item" index="index" collection="list"
open="ID in (" separator="," close=")" nullable="true">
#{item}
</foreach>
</where>
</select>
����Խ��κοɵ�������(�� List��Set ��)��Map ����������������Ϊ���ϲ������ݸ� foreach��
��ʹ�ÿɵ���������������ʱ,index ����ǰ���������,item ��ֵ�DZ��ε�����ȡ����Ԫ������ʹ�� Map ����(���� Map.Entry ����ļ���)ʱ,index �Ǽ�,item ��ֵ��
collection : ָ�����ϱ����� key����������� List ���;�д list,��ȻҲ��ָ��,��������Ҫ�ڽӿڷ���������ʹ�� @Param ע��ָ����
choose��when��otherwise
**��ʱ��,���Dz���ʹ�����е�����,��ֻ����Ӷ��������ѡ��һ��ʹ�á�**����������,MyBatis �ṩ�� choose Ԫ��,���е��� Java �е� switch ��䡣
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ��ACTIVE��
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
<!-- �� title != null ʱ,SQL��ƴ���� and title like #{title} ��һ���� ,������������ƴ��;������е�������������,��ƴ�����ĺ����������-->
script
Ҫ�ڴ�ע���ӳ�����ӿ�����ʹ�ö�̬ SQL,����ʹ�� script Ԫ�ء�����:
@Update({"<script>",
"update Author",
" <set>",
" <if test='username != null'>username=#{username},</if>",
" <if test='password != null'>password=#{password},</if>",
" <if test='email != null'>email=#{email},</if>",
" <if test='bio != null'>bio=#{bio}</if>",
" </set>",
"where id=#{id}",
"</script>"})
void updateAuthorValues(Author author);
bind
bind Ԫ���������� OGNL ����ʽ���ⴴ��һ������,���������ǰ�������ġ�����:
<select id="selectBlogsLike" resultType="Blog">
<!-- ��һ������ʽֵ��һ������ -->
<bind name="pattern" value="'%' + _parameter.getTitle() + '%'" />
SELECT * FROM BLOG
WHERE title LIKE #{pattern}
</select>
_parameter :�����������IJ���
- �����˵�������:_parameter �ʹ����������
- �����˶������:_parameter �ʹ�������������������� map
�����ݿ�֧��
��������� databaseIdProvider,��Ϳ����ڶ�̬������ʹ����Ϊ ��_databaseId�� �ı�����Ϊ��ͬ�����ݿ���ض�����䡣�������������:
<insert id="insert">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
<if test="_databaseId == 'oracle'">
select seq_users.nextval from dual
</if>
<if test="_databaseId == 'db2'">
select nextval for seq_users from sysibm.sysdummy1"
</if>
</selectKey>
insert into users values (#{id}, #{name})
</insert>
include ��sql
��������ǩҪһ��ʹ��,�����dz�ȡ�ظ��� SQL �����á�
<!--Ҫ����ͬһ���ļ��о�������д,�粻��һ���ļ�������Ҫ��һ���ļ��� namespace.id,
����һ���ļ�namespace+��һ���ļ�sqlƬ�ε�id -->
<sql id="ObjectArrayStudents">
<where>
<if test="array !=null and array.length>0 ">
<foreach collection="array" open=" and stuno in (" close=")" item="student" separator=",">
#{student.stuNo}
</foreach>
</if>
</where>
</sql>
<select id="queryStudentsWithObjectArray" parameterType="Object[]" resultType="student">
select * from student
<include refid="ObjectArrayStudents"></include>
</select>
����:
xml �е��������,�硰,<,>,����Щ����Ҫʹ��ת���ַ���
��ϸ��:w3shool api�ĵ��� HTML ISO-8859-1 �ο��ֲ�
OGNL:
����ͼ��������,��һ�ַdz�ǿ��ı���ʽ���ԡ�ͨ�������Էdz�������������������ԡ�������EL��SpEL��
- ���ʶ������� person.name
- ���÷��� person.getName()
- ���þ�̬����/���� @java.lang.Math @PI @Java.util.UUID @RandomUUID()
- ���ʼ���α����
���� α���� α���Զ�Ӧ�� Java ����
List��Set��Map Size��isEmpty List/Set/Map.size(),List/Set/Map.isEmpty()
List��Set iterator List.iterator()��Set.iterator()
Map keys��values Map.keySet()��Map.values()
Iterator next��hasNext Iterator.next()��Iterator.hasNext()
�����ܽ�
db.properties
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/2019Home
username=root
password=2105251354
mybatis-config.xmlȫ������:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="db.properties"></properties> <!--��̬�������ݿ���Ϣ-->
<!-- setting ȫ�ֲ������趨-->
<settings>
<!--������־,��ָ��ʹ�õľ�����־-->
<setting name="logImpl" value="LOG4J"/>
<!--�����ӳټ���-->
<setting name="lazyLoadingEnabled" value="true"/>
<!--�ر���������-->
<setting name="aggressiveLazyLoading" value="false"/>
<!--������������-->
<setting name="cacheEnabled" value="true"/>
</settings>
<!--�趨��/�������-->
<typeAliases>
<!--���õ�������-->
<!-- <typeAlias type="ex.Student" alias="a"></typeAlias> -->
<!--����������� (�������Դ�Сд) һ�»��Զ������е������� ����������� ������������ (��������)-->
<package name="ex"/>
</typeAliases>
<!--����ת����-->
<typeHandlers>
<!--ת���� ��(java)javaTypeת��Ϊ(���ݿ�)jdbcType-->
<typeHandler handler="ex.ex.converter.BooleanAndIntConverter" javaType="Boolean" jdbcType="INTEGER"/>
</typeHandlers>
<environments default="development">
<environment id="development">
<!--����������ύ��ʽ
JDBC:����JDBC��ʽ��������(commit rollback close)
Managed:���¼�������������й�(spring jobss),Ĭ�ϻ�ر�����
-->
<transactionManager type="JDBC"/>
<!--��������
UNPOOLED:��ͳ��JDBCģʽ(���Ƽ�)
POOLED:ʹ�����ݿ����ӳ�
JNDI:��Tomcat�л�ȡһ�����õ����ݿ����ӳ�(���ݿ����ӳ�-����Դ)
-->
<dataSource type="POOLED">
<!--�������ݿ���Ϣ-->
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--����ӳ���ļ�-->
<mapper resource="ex/ex/one/studentMapper.xml"/>
<mapper resource="ex/ex/one/studentCardMapper.xml"/>
<mapper resource="ex/ex/one/studentClassMapper.xml"/>
</mappers>
</configuration>
log4j.properties
log4j.rootLogger=DEBUG, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
ding" value=��false��/>
<!--�趨��/�������-->
<typeAliases>
<!--���õ�������-->
<!-- <typeAlias type="ex.Student" alias="a"></typeAlias> -->
<!--����������� (�������Դ�Сд) һ�»��Զ������е������� ����������� ������������ (��������)-->
<package name="ex"/>
</typeAliases>
<!--����ת����-->
<typeHandlers>
<!--ת���� ��(java)javaTypeת��Ϊ(���ݿ�)jdbcType-->
<typeHandler handler="ex.ex.converter.BooleanAndIntConverter" javaType="Boolean" jdbcType="INTEGER"/>
</typeHandlers>
<environments default="development">
<environment id="development">
<!--����������ύ��ʽ
JDBC:����JDBC��ʽ��������(commit rollback close)
Managed:���¼�������������й�(spring jobss),Ĭ�ϻ�ر�����
-->
<transactionManager type="JDBC"/>
<!--��������
UNPOOLED:��ͳ��JDBCģʽ(���Ƽ�)
POOLED:ʹ�����ݿ����ӳ�
JNDI:��Tomcat�л�ȡһ�����õ����ݿ����ӳ�(���ݿ����ӳ�-����Դ)
-->
<dataSource type="POOLED">
<!--�������ݿ���Ϣ-->
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--����ӳ���ļ�-->
<mapper resource="ex/ex/one/studentMapper.xml"/>
<mapper resource="ex/ex/one/studentCardMapper.xml"/>
<mapper resource="ex/ex/one/studentClassMapper.xml"/>
</mappers>
log4j.properties
log4j.rootLogger=DEBUG, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n