��������:
- ��ϰJS��ѧ֪ʶ
- ѧϰC���Բ����ļ��ķ���
- �ܽ�C����֪ʶ
JS��ϰ
������JavaScriptʵ�ְ�����������:
- ECMAScript:����
- DOM:�ĵ�����ģ��
- BOM:���������ģ��
1. �����
1.1 �
- ���ִ�Сд:ECMAScript��һ�ж����ִ�Сд��
- ��ʶ��:���������ԡ������������������ơ�
��ʶ�������ǰ������и�ʽ�������������һ�����ַ�:
��һ���ַ�������һ����ĸ���»���( _ ) ��һ�� ��Ԫ����( $ )��
�����ַ���������ĸ���»��ߡ���Ԫ���Ż����֡�
���չ���,ECMAScript ��ʶ�������շ���������
��ʶ�������ǹؼ��ֺͱ����ַ���
- ע��:ECMAScript����C���Է���ע��,��������ע�ͺͿ�ע�͡�
����ע��:// ע������
��ע��:
/* ע������
����ע�� */
Ҳ����д��:
/*
* ����ע��
* ����ע��
*/
- �ϸ�ģʽ:ECMAScript5�������ϸ�ģʽ,ECMAScript3�в��淶д�������ϸ�ģʽ�»ᱻ����,���ڲ���ȫ�Ļ���׳�����
�������ű������ϸ�ģʽ:"use strict";
����ָ��ij���������ϸ�ģʽ��ִ��:
function doSomething (){
"use strict";
//������
}
- ���
����:
????ÿһ����䶼Ҫ��;����
????һ����������ͬһ����,���ܻ���
????ÿһ����䶼Ҫ��ռһ��(����淶)
JS���� :һ����صĴ���ļ���
????��{ }��������һЩ����������,�������̿��ơ�����������С�
????JavaScript�����ִ�д�������д������ͬ
1.2 �ؼ����뱣����
�ؼ����뱣���ֶ�����������ʶ����
- �ؼ���:��������;����ִ���ض��IJ���
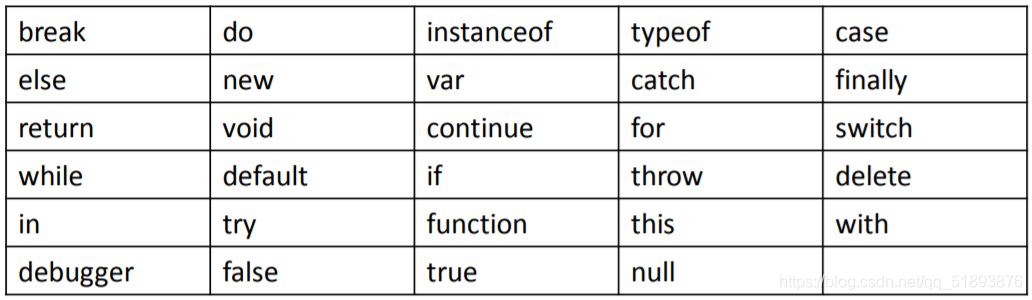
- ������:��������û���ض���;,�������DZ�����������Ϊ�ؼ���ʹ�õ�

1.3. ����
�����������Ǹ�ijһ��ֵ������ע���ơ�
- ����������: ʹ��var�ؼ�������һ��������
var a;
- ��������ֵ: ʹ��=Ϊ������ֵ��
a = 123;
- ������ֵͬʱ����:
var a = 123;
1.4 ��������
JavaScript��һ����5�ֻ�����������:
-
��ֵ����(
number)
һ�����ֶ�����ֵ����(����������,ʮ����,ʮ�����Ƶ�)
NAN(not number),һ�������� -
�ַ�������(
string)
��һ�����ð�������������(�����Ż���˫����) -
��������(
boolean)
ֻ������ֵ(true ���� false) -
null����(
null)
ֻ��һ��ȡֵ,����null,��ʾ�յ���˼ -
undefined����(
undefined)
ֻ��һ��ȡֵ,����undefined,��ʾû��ֵ����˼
1.5 �ж��������͵Ĺؼ���
isNaN�ؼ���
isNAN�����ж�һ�������Dz�����
// ���������һ������
var n1 = 100;
console.log(isNaN(n1)); //=> false
// �����������һ������
var s1 = 'Jack'
console.log(isNaN(s1)); //=> true
typeof�ؼ���
JavaScript�з���������,��ô������ʱ����Ҫ֪�����Ǵ洢��������ʲô���͵�����,ʹ�� typeof �ؼ����������ж�
�: typeof ����
/* �������͵ı��� */
var age = 18;
var name=" ";
var isFun = true;
var a;
console.log(typeof age); //number
console.log(typeof name); //string
console.log(typeof a); //undefined
console.log(typeof isFun); //boolean
1.6 �������͵�ת��
- ��������ת��ΪBoolean����
ת����ʽ Boolean() value?true:false !!value
//��������ת��Ϊboolean���� ʹ��Boolean()����
console.log(Boolean(undefined));// false
console.log(Boolean(null));// false
console.log(Boolean(0));// false
console.log(Boolean(NaN));// false
console.log(Boolean(1));// true
console.log(Boolean(""));// false
console.log(Boolean("abc"));// true
console.log(Boolean({}));// �����κζ���ת������true
if (new Boolean(false)) {
console.log("ִ��");
} // ���Ϊִ��,ԭ������Ϊif() if�жϻ��Զ�ִ��Boolean()����,�����κζ���ת������true
- ��������ת��ΪNumber����
ת����ʽ Number() +value parseFloat parseInt
//��������ת��Ϊnumber����
console.log(Number(undefined)); // NaN alerting
console.log(Number(null)); // 0
console.log(Number(true));// 1
console.log(Number(false));// 0
console.log(Number(""));//0
console.log(Number("abc"));// NaN
console.log(Number("123.345xx")); //NaN
console.log(Number("32343,345xx")); //NaN
console.log(Number({ x: 1, y: 2 })); //NaN
console.log(parseFloat("123.345xx")); // 123.345
console.log(parseFloat("32343,345xx")); // 32343
console.log(parseInt("123.345xx"));//123
console.log(parseInt("32343,345xx")); //32343
- ��������ת��ΪString����
ת����ʽ String() ����+value value.toString();
//��������ת��Ϊstring����
console.log(String(undefined)); //undefined
console.log(String(null));// null
console.log(String(true));// true
console.log(String(false));//false
console.log(String(0));// 0
console.log(String(234));// 234
console.log(String({ x: 1, y: 2 }));// [object] [Object]
- ��ʽ����ת��
ʹ�ù�ϵ�����ʱ��ת��(==��>��<���������ͺͻ������ͱȽ�ʱ)
ʹ�����������ʱ��ת��(��img��+ 3 + ��.jpg��; ��25��-0;)
ʹ���������ʱ��ת��( !!0; )
ִ���������ʱ��ת��(if(obj){��})
// ��ʽ����ת��
var a = 1;
var b = 2;
console.log(a > b, typeof(a > b)); // false boolean
var c = 3 + '2'; //32 3->'3'
var d = '3' - 2 //1 '3'->3
var e = !!a;
console.log(typeof e); // boolean
- ��ʽ����ת��(ʹ���������)
Boolean()��Number()��String()��Object()
��תΪ�ַ���(toString()��toFixed()��toPrecision()��toExponential())
�ַ���תΪ����(parseInt()��parseFloat())
����ת��Ϊԭʼֵ(toString()��valueOf())
1.7 �����
�����Ҳ�в�����,ͨ����������Զ�һ������ֵ�������㲢��ȡ��������
- ���������
+�ӷ�����
ֻ�з������߶������ֵ�ʱ��,�Ż���мӷ�����
ֻҪ��������һ�����ַ���,�ͻ�����ַ�����ƴ��-����
��ִ�м�������
���Զ������߶�ת�������ֽ�������*�˷�
��ִ�г˷�����
���Զ������߶�ת�������ֽ�������/����
��ִ�г�������
���Զ������߶�ת�������ֽ�������%����
��ִ��ȡ������
���Զ������߶�ת�������ֽ�������=��ֵ����
���ǰ� = �ұߵ�ֵ ��ֵ�� = ��ߵı�����
var num = 100;+=
var age = 18;
a += 10; //a += 10 �ȼ��� a = a + 10
console.log(a) // 28
-=
var a = 10;
a -= 10; //a -= 10 �ȼ��� a = a - 10
console.log(a); //=> 0
*=
var a = 10;
a *= 10; //a *= 10 �ȼ��� a = a * 10
console.log(a); //=> 100
/=
var a = 10;
a /= 10; //a /= 10 �ȼ��� a = a / 10
console.log(a); //=> 1
%=
var a = 10;
a %= 10; //a %= 10 �ȼ��� a = a % 10
console.log(a); //=> 0
- ��ϵ�����
-
==
�ȽϷ������ߵ�ֵ�Ƿ����,������������
1 == '1' ==>>true
����ֵ��һ����,���Եõ�true -
===ȫ��
�ȽϷ������ߵ�ֵ �����������Ƿ����
1 === '1'==>false
����ֵ��Ȼһ��,������Ϊ��Ϊֵ���������Ͳ�һ��,����Ϊfalse -
!=
�ȽϷ��� ���ߵ�ֵ�Ƿ� ����
1 != '1'==>false
��Ϊ���ߵ�ֵ����ȵ�,�����ڱȽϵ����Dz��ȵ�ʱ��õ�false -
!==��ȫ��
�ȽϷ������ߵ�ֵ�������Ƿ�
1 != '1' true
��Ϊ�����������Ͳ�һ��,���Եõ�true -
>=
�Ƚ���ߵ�ֵ�Ƿ� ���ڻ���� �ұߵ�ֵ
1 >= 1true
1 >= 0true
1 >= 2false -
<=
�Ƚ���ߵ�ֵ�Ƿ� С�ڻ���� �ұߵ�ֵ
1 <= 2true
1 <= 1true
1 <= 0false -
>
�Ƚ���ߵ�ֵ�Ƿ� ���� �ұߵ�ֵ
1 > 0true
1 > 1false
1 > 2false -
<
�Ƚ���ߵ�ֵ�Ƿ� С�� �ұߵ�ֵ
1 < 2true
1 < 1false
1 < 0false
- �������
&&
���� �� ������
������߱���Ϊ true �����ұ�Ҳ�� true,�Ż᷵�� true
ֻҪ��һ�߲��� true,��ô�ͻ᷵�� false
true && truetrue
true && falsefalse
false && truefalse
false && falsefalse||
���� �� ������
���ŵ����Ϊ true �����ұ�Ϊ true,���᷵�� true
ֻ�����߶��� false ��ʱ��Ż᷵�� false
true || truetrue
true || falsetrue
false || truetrue
false || falsefalse!
���� ȡ�� ����
������ true ��,���� false
������ false ��,���� true
!truefalse
!falsetrue
- �����Լ�����(һԪ�����)
++
�����������㡣�ֳ�����,ǰ��++ �� ����++
ǰ��++,���Ȱ�ֵ�Զ� +1,�ٷ���
var a = 10;
console.log(++a);
// �᷵�� 11,���Ұ� a ��ֵ��� 11
var num = 10;
num++
console.log(num)
// �᷵�� 11,���Ұ� a ��ֵ��� 11
����++,���Ȱ�ֵ����,���Զ�+1
var a = 10;
console.log(a++);
// �᷵�� 10,Ȼ��� a ��ֵ��� 11
--�����Լ�����
�ֳ�����,ǰ��-- �� ���èC
�� ++ ���������һ��
- ���������
JavaScript �������˻���ijЩ�����Ա������и�ֵ�������������
�:variablename=(condition)?value1:value2;
ִ������:���conditionΪtrue,��ִ�����1,������ִ�н��,���Ϊfalse,��ִ�����2,������ִ�н����
-
���������
ʹ�ö��ſ�����һ�������ִ�ж�β�����
����:var num1=1, num2=2, num3=3;
ʹ�ö���������ָ������������˳ ������ִ�С� -
��������ȼ�
��������ȼ����ϵ������μ�С,����ͬ�������,���ô�����������ִ�еķ�����

1.8�����
-
���
ǰ������˵����ʽ������������ݿ��������������һ �������еĵ���,��������(statement)�����������������һ��һ���� ���Ļ��ˡ������һ������Ļ�����λ,JavaScript�ij��������һ��һ����乹�ɵ�,ÿһ�����ʹ��;��β��
JavaScript�е����Ĭ������������˳��ִ�е�,��������Ҳ����ͨ��һЩ���̿����������������ִ��˳�� -
�����
��������ڴ����� {} ����д�����,�Դ˽��������ļ�����Ϊһ�������ʹ�á�
����:
{
var a = 123;
a++;
alert(a);
}
һ��ʹ�ô���齫��Ҫһ��ִ�е������з���,��Ҫע�����,������β����Ҫ���ֺ���
1.9 ���̿������
- �������
���������ͨ���ж�ָ������ʽ��ֵ������ִ�л�������ijЩ���,��������������:
if��else
switch��case
if��else
if��else�����һ��������Ŀ������,����JavaScript������������ִ����䡣
��һ����ʽ:
if(expression)
??????statement
var age = 16;
if (age < 18) {
console.log("���");
}
�ڶ�����ʽ:
if(expression)
??????statement
else
??????statement
var age = 16;
if (age < 18) {
console.log("���");
} else {
console.log("�ѳ���");
}
��������ʽ:
if(expression1)
??????statement
else if(expression2)
??????statement
else
??????statement
var age = 18;
if (age < 18) {
console.log("��18����");
} else if (age == 18) {
console.log("�Ѿ�18����");
} else {
console.log("����18����")
}
switch��case
switch��case����һ�����̿�����䡣
switch���������ڶ�����֧ʹ��ͬһ�����������
���ʽ:
switch (���) {
??????case ����ʽ1:
?????? ??????���...
??????case ����ʽ2:
?????? ??????���...
??????default:
?????? ??????���...
}
һ������case�����������һֱ���е�����,����һ�����case������break��Ϊ���Ľ�����
var today = 1;
switch (today) {
case 1:
console.log("����һ"); //��today��ֵΪ1,�����������һ��
break;
case 2:
console.log("���ڶ�");
break;
case 3:
console.log("������");
break;
case 4:
console.log("������");
break;
case 5:
console.log("������");
break;
case 6:
console.log("������");
break;
case 7:
console.log("������");
break;
default:
console.log("�������"); //��today��ֵ����7��С��,������������
}
- ѭ�����
ѭ�������������һ��,Ҳ�ǻ����Ŀ������,ֻҪ����һ������������һֱִ��,�������ѭ�����:
while
do��while
for
while
while�����һ���������ѭ�����,while���Ҳ����Ϊwhileѭ����
���ʽ:
while(��������ʽ){
??????���...
}
var i = 1;
while (i <= 10) { //���1��10
console.log(i);
i++;
}
do��while
do��while��while�dz�����,ֻ����������ѭ����β�������Ƕ���������ʽ��ֵ,���,do��whileѭ��������ִ��һ�Ρ������while,do��while��ʹ��������� �Ǻܶࡣ
���ʽ:
do{
??????���...
}while(��������ʽ);
var i = 1;
do {
console.log(i);
i++;
} while (i <= 10); //���1��10
for
for���Ҳ��ѭ���������,����Ҳ����Ϊforѭ������ѭ��������һ�����������Կ���ѭ��ִ�еĴ���, �������������ؼ������dz�ʼ���������¡�for��� �ͽ�������������ȷΪ�����һ���֡�
���ʽ:
for(��ʼ������ʽ ; ��������ʽ ; ���±���ʽ){
??????���...
}
for (var i = 1; i <= 10; i++) { //���1��10
console.log(i);
}
- ��ת����
break:���������һ��ѭ��,������ѭ����switch�����ʹ�á�
continue:��������ѭ��,ִ����һ��ѭ��,ֻ����ѭ����ʹ�á�
�����Ҫ�������ѭ����������ָ��λ��,����Ϊѭ����䴴��һ��label,����ʶ��ǰ��ѭ��,��:
outer: for (var i = 0; i < 10; i++) {
for (var j = 0; j < 10; j++) {
if (j == 5) {
break outer;
}
console.log(j);
}
}
2.����������
2.1 ԭʼֵ������ֵ
????ECMAScript�������������ֲ�ͬ���͵�����:ԭʼֵ������ֵ���ڰ�һ��ֵ��������ʱ,JavaScript�������ȷ�����ֵ��ԭʼֵ��������ֵ��
ԭʼֵ:ԭʼֵ�Ǵ洢��ջ�еļ����ݶ�,���ǵ�ֱֵ�Ӵ洢�ڱ������ʵ�λ�á�ԭʼֵ��ʾ��ʾ��һ������,����ԭʼֵ�ı�������ֵ����,�����洢�ڱ����ڴ��е�ʵ��ֵ��ECMAScript �������6��ԭʼֵ:Undefined��Null��Boolean��Number��String��Symbol��
����ֵ:����ֵ�Ǵ洢�����еĶ���,�洢�ڱ�������ֵ��һ��ָ��,ָ��洢������ڴ洦����ֵ��ʾ��ʾ�ж��ֵ(ԭʼֵ����������ֵ)���ɵĶ���������ֵ�ı��������������ʵġ�ʵ�ʲ�������ʱ,���ʵ��DZ��������ڴ��ַ,���ö��������(ECMAScript ������ֱ�ӷ��ʶ�����ڴ�ռ�)��
- ��̬����
????�ڶ��巽ʽ��,ԭʼֵ������ֵ������,�����ȴ���һ������,�ٸ�����һ��ֵ�������������������ڱ���������ֵ֮��,�����ֵ��β�����
????��������ֵ����,���������������ʱ���ӡ��ĺ�ɾ���ñ��������ԡ�������ԭʼֵԭʼֵ����������,���ܸ�ԭʼֵ�������Բ��ᱨ������ ֻ������ֵ���Զ�̬���Ӻ������ʹ�õ�������
ע��:ԭʼֵ�ij�ʼ������ֻʹ��ԭʼ��������ʽ������ʼ��ʱʹ�� new �ؼ��ִ����˶���,�� JavaScript ��Ϊ�䴴��һ�� Object ���͵�ʵ��,������Ϊ�Ծ���ԭʼֵ���ơ�
-
����ֵ
ԭʼֵ������ֵ��ͨ��������ֵʱҲ��ͬ��
????ԭʼֵ�����洢��ջ��,��ͨ��������һ��ԭʼֵ������һ��ԭʼֵʱ,ԭʼֵ�ᱻ���Ƶ��±�����λ�á��˺��±�����ԭ�������Զ���,�������š��ı�����һ��������ֵ����ʹ��һ������ֵ�����ı䡣
????����ֵ�ڱ���һ������������һ������ʱ,�����±����д��ָ��ԭ������ָ��,����±�����ԭ������ָ��ͬһ������,����Ҫ�������±�����ֵ���˺�,��������ֵ��ʹ����������ֵ�������ı䡣 -
���ݲ���
????ECMAScript�����в������ǰ�ֵ���ݵ�,����ζ�ź������ֵ�������ֵ�ĸ���һ�������Ƶ������ڲ��IJ����С�
���ݱ���ֵ�ĸ��Ʒ�������֪��:
????????�ڰ�ֵ���ݲ���ʱ,ֵ�ᱻ���Ƶ�һ���ֲ�����,����ȫ����ʵ��;
????????�������ô��ݲ���ʱ,ֵ���ڴ��е�λ�ûᱻ������һ���ֲ�����,����ζ�ŶԸþֲ��������Ļᷴӳ�������ⲿ(��ʹ�þֲ��������ں������ⲿ��ԭ����������ֵҲ�����ı�),���� ECMAScript ���Dz�����ʵ�ֵġ�
????????�ʲ�������ֻ�ܰ�ֵ���ݡ�
ע��:ECMAScript �к����IJ������Ǿֲ������� -
ȷ������
��������ֵ�Ķ���(���ɶ��ֵ���ɵĶ���),���е�����ֵ���� Object ���͵�ʵ��,���ͨ�� instanceof ����������κ�����ֵ�Ƿ��� Object ���캯�����᷵�� true�� ͬ��,ԭʼֵ���Ƕ���,���� instanceof ����κ�ԭʼֵ���᷵�� false��typeof������:�����ж�һ��ԭʼֵ����������,�Ƿ�Ϊ�ַ�������ֵ������ֵ�� undefined��
instanceof������:�����ж�����ֵ������ʲô���͵Ķ���,�Ϊ result = variable instanceof constructor������ֵΪ true ���� false.
ע��:typeof�����������ڼ�⺯��ʱҲ�᷵�� ��function����typeof ���������ʽ�᷵�� ��function�� ���� ��object��,ȡ�����������
2.2 ִ����������������
ִ���������ĸ�����JavaScript�зdz���Ҫ��������ִ�������ľ��������ǿ��Է�����Щ����,�Լ����ǵ���Ϊ��ÿ��ִ�������Ķ���һ�������ı�������,��ִ���������ж�������б����ͺ���������������ϡ�
ȫ��������:ȫ����������������ִ�������ġ����������,ȫ�������ľ���window����,�������ͨ�� var �����ȫ�ֱ����ͺ��������Ϊ window ��������Ժͷ���,��ʹ�� let �� const �Ķ����������ᶨ����ȫ����������,������������������Ч����ͬ��
ִ���������������д��붼��ִ����Ϻ�ᱻ����,ȫ����������Ӧ�ó����˳�ǰ�Żᱻ����,��ر���ҳ���˳��������
ÿ���������ö����Լ���ִ����������������ִ�������뺯��ʱ,�����������ı��Ƶ�һ��������ջ�ϡ��ں���ִ����֮��,������ջ�ᵯ���ú���������,������Ȩ������֮ǰ��ִ�������ġ�ECMAScript �����ִ��������ͨ�����������ջ���п��Ƶġ�
�������еĴ�����ִ�е�ʱ��,�ᴴ�����������һ����������������������������˸����������еĴ����ڷ��ʱ����ͺ���ʱ��˳��������ִ�е������ĵı������� ʼ��λ��������������ǰ�ˡ�
����������Ǻ���,������������������������������ֻ��һ���������:arguments��(ȫ����������û�����������)���������е���һ����������������������,����һ��������������һ�����������ġ��Դ�����ֱ��ȫ��������;ȫ�������ĵı�������ʼ�����������������һ����������
����ִ��ʱ����ʶ��������ͨ��������������������ʶ��������ɵġ���������ʼ�մ�������������ǰ�˿�ʼ,Ȼ��������,ֱ���ҵ���ʶ����(���û���ҵ���ʶ��,��ôͨ���ᱨ����)
�ֲ��������ж���ı����������ھֲ����������滻ȫ�ֱ�����
ע��:������������Ϊ�ǵ�ǰ�������еı���,���Ҳ���������е�����������ѭ��ͬ�ķ��ʹ���
-
�ӳ���������
��Ȼִ����������Ҫ�� ȫ���������� ��������������(eval()�����ڲ����ڵ�����������),����������ʽ����ǿ����������ijЩ���ᵼ������������ǰ����ʱ����һ��������,����������ڴ���ִ�к�ᱻɾ����ͨ������������»�����������,������ִ�е���������һ�����ʱ:
try/catch ����catch ��;
with ���;
�����������,��������������ǰ������һ���������� with �����˵,������������ǰ������ ָ���Ķ���;��catch ������,��ᴴ��һ���µ� ��������,���������������Ҫ�׳��Ĵ������������� -
û�п鼶������
JavaScript����û�п鼶����������������C������,�ɻ����ŷ�յĴ���鶼���Լ���������(����JS�е�ִ�л���),��˿��������ж���ֲ���������JavaScript������С��������Ϊ����������
- ��������
ʹ��var�����ı������Զ������ӵ���ӽ��Ļ����С���û��ʹ��var�ؼ�������������ʱ,�����ᱻ���ӵ�ȫ�ֻ����С� - ��ѯ��ʶ��
��ij������������һ����ʶ��ʱ,����ͨ��������ȷ���ñ�ʶ������ʲô���塣ִ�й��̻�ӵ�ǰ������������ǰ�˿�ʼ,������ѯ������ھֲ���������������,����������̾�ֹͣ��������ھֲ���û��������,������������������������,ֱ��ȫ�ֻ���Ϊֹ�����ȫ�ֻ�����Ҳû���ҵ�,˵���ñ���δ������
3. ��������
�������͵�ֵ(����)���������͵�һ��ʵ������ECMAscript��,����������һ�����ݽṹ,���ڽ����ݺ�����֯��һ����Ҳ������Ϊ��,�������ֳƺ�������������ECMAscript�Ӽ�������һ��������������,���������߱���ͳ���������������֧�ֵ���ͽӿڵȻ����ṹ������������ʱ��Ҳ��Ϊ������,��Ϊ������������һ����������е����Ժͷ�����
3.1 Object
Object ������ ECMAScript ��ʮ�ֳ��á���Ȼ Object ��ʵ��û�ж��ٹ���,�����ʺ��洢����Ӧ�ó���佻��������
���� Object ���͵�ʵ�������ַ���:
- ʹ�� new �������� Object ���캯������:(��1)
ver person = new Object();
person.name = "ZhouHang";
person.age: 29;
- ʹ��������������ʾ����**�����������Ƕ�����ļ�д��ʽ,Ŀ����Ϊ�˼����������ԵĶ���Ĵ�����**��:(��2)
var person = {
name:"ZhouHang",
age:29
}; //�˶δ��붨������������ͬ��person����
- person ����ĸ�ֵ��������ʾ����Ҫ�ڴ�һ��ֵ����ʱ�γ���һ������ʽ��������(����ʽ������ָ�����ڴ�����ֵ��������)
- �������({)�����ڱ���ʽ��������,��ʾ������������ʼ,����ʾһ������ʽ�Ŀ�ʼ��(���� { �����������������,���� if ������������,���ʾһ������Ŀ�ʼ��)
- ���������ڶ����������зָ�����,��ͬһ�����������������һ�����Ժ�д���š�
- �ڶ�����������ʾ����,�������������ַ�������ֵ����ֵ���Ի��Զ�ת��Ϊ�ַ�������:(��3)
var person = {
name:"ZhouHang",
age:29,
5:true
};
- Ҳ��������������ʾ��������ֻ��һ��Ĭ�����Ժͷ����Ķ���,ֻ���ڴ�������дһ���ո�:(��4)
var person = {};
person.name = "ZhouHang";
person.age = 29;
//����1��Ч
ע��:
- ��ʹ�ö����������������ʱ,������ʵ�ʵ��� Object ���캯����
- ��Ȼ���ַ���������,��ʹ�ö�����������ʾ����������Ҹ������ۡ�
���ԵĴ�ȡҲ�����ַ���:
- ���:(��5)
var person = {
name:"ZhouHnag",
age:29
};
console.log(person.name);
2.�������
ʹ���������ʱ,Ҫ��������ʹ�����������ַ�����ʽ:(��6)
var person = {
name:"ZhouHnag",
age:29
};
console.log(person["name"]);
- ���ִ�ȡ��ʽ�ӹ�����û������,��ʹ�������������ͨ�������������ԡ�
- ����������а������ܻᵼ���������ַ����߰����ؼ��֡�������ʱ,����ʹ�������������:(��7)
person["first name"] = "ZhouHang";
// ��Ϊ"first name"�а���һ���ո�,���Բ���ʹ�õ�������ʡ�
???(���������ǿ���������ĸ�����ַ���,��ʱ��ֻ��Ҫ�����������ȡ������)
- �������ѡ�����Դ�ȡ��ʽ,���Ƿ�������ʱ����ʹ�ñ�����
3.2 Array
Array �� ECMAScript �г� Object ����õ����͡�
ECMAScript ���������������Ե������кܴ�������ȻҲ����������,��������ÿ����λ���Դ洢�������͵����ݡ����� ECMAScript ��������̬��С��,�������������Ӷ��Զ�������
- ��������
1. ʹ�� Array ���캯��:
(��8)
var name = new Array();
?
- ���֪������Ԫ�ص�����,����Ը����캯������һ��ֵ,Ȼ�� length ���Իᱻ�Զ�����������Ϊ���ֵ:(��9)
var name = new Array(10); //����һ����ʼ length Ϊ10������
- Ҳ���Ը� Array ���캯������Ҫ�����Ԫ�ء�
var name = new Array("ZhouHang","Nicholas","");
ע��:��������ʱ���Ը����캯����һ��ֵ������,������ֵ����ֵ,��ᴴ��һ������Ϊָ����ֵ������;��������ֵ���������͵�,��ᴴ��һ��ֻ�������ض�ֵ�����顣��:(��10)
var name = new Array(8); //����һ��ֻ����8��Ԫ�ص�����
var color = new Array("red"); //����һ��ֻ����һ��Ԫ��,���ַ���"red"������
- ʹ�� Array ���캯��ʱ,Ҳ����ʡ�� new ��������
2.ʹ��������������ʾ����
������������ָ���������а����Զ��ŷָ���Ԫ���б�:(��11)
var colors = Array["red","blue","yellow","purple"]; //����һ������3��Ԫ�ص�����
var names = Array[]; //����һ��������
var values = Array[1,2]; //����һ������2��Ԫ�ص�����
var values2 = Array[1,3,]; //����һ������2��Ԫ�ص�����(���Ƽ�����д)
ע��:ͬ����һ��,��ʹ��������������ʾ����������ʱ������� Array ������
3. from ()����:ES6���������ڴ�������ľ�̬����,���ڽ�������ṹת��Ϊ����ʵ����
4. of ()����:ES6�����ĵڶ������ڴ�������ľ�̬����,���ڽ�һ�����ת��Ϊ����ʵ����
-
�����λ
ʹ��������������ʼ������ʱ,����ʹ��һ��������������λ��ECMAScript �Ὣ����֮����Ӧ����λ�õ�ֵ���ɿ�λ��ES6 ���������Ὣ��Щ��λ���ɴ��ڵ�Ԫ��,ֻ��ֵΪ undefined;�� ES6��ǰ�ĵķ��������������λ,��������Ϊ�����졣
��ʵ����Ӧ��������ʹ�������λ�� -
��������
Ҫȡ�û����������ֵ,��Ҫʹ�����������ṩ��Ӧֵ�����������������������ṩ��������ʾҪ���ʵ�ֵ���������С�����������Ԫ����,�ش洢����Ӧλ�õ�Ԫ�ء������һ��ֵ���ø����������������������,�����鳤�Ȼ��Զ���չ��������ֵ��1����:(��12)
var names = ["ZhouHnag","ShiJiu","wang"]; //����һ���ַ�������
alert(names[0]); //��ʾ��һ��
names[2] = "Jie"; //�ĵ�����Ϊ"Jie"
names[3] = "wangsjijiu"; //���ӵ�����"wangshijiu"
- ������
alert(names[0];)��ʾһ������һ��ָ����Ϣ(names�����еĵ�һ��Ԫ��)��һ�� OK ��ť�ľ�ʾ��alert() �ڴ��ַ���������ͼ:(��13)
- ������Ԫ�ص����������� length ������,�������ֵʼ�շ���0�����0��ֵ������ length���Բ���ֻ����,ͨ���� length ����,���Դ�ĩβɾ��������Ԫ�ء������� length ����Ϊ��������Ԫ������ֵ,��û�б�������Ӧֵ��Ԫ�ػ��� undefined ��䡣(��14)
var names = ["ZhouHang","LiNing","cat"];
alert(names[3]); //undefined
alert(names[2]); //cat
names.length = 4; //lengthֵ��������Ԫ����
alert(names[3]); //undefined
names[names.length] = "wo"; //����һ��Ԫ��
alert(names[3]); //undefined
alert(names[4]); //wo
ע��:������������4 294 967 295��Ԫ�ء����������Ӹ�����,��ᵼ���׳�����;����������ֵ��Ϊ��ʼֵ��������,��ᵼ�½ű�����ʱ������Ĵ���
- �������
�ж�һ�������Dz�������,��һ������� ECMAScript ���⡣��ֻ��һ����ҳ(ֻ��һ��ȫ��������)�������,ʹ�� instanceof ���������ɡ�������ҳ��ƶ����ͬ��ȫ��ִ��������ʱ,��Ҫʹ�� Array.isArray() ����,�����������עһ��ֵ���ĸ�ȫ��ִ���������д�����
�: instanceof ������:
if(value instanceof Array){
//��������
}
Array.isArray() ����:
if(Array.isArray(value)){
//��������
}
- ת������
��������� toLocaleString()��toString() �� valueOf () ����:
valueOf() ���ص������鱾����
toString() ������������ÿ��ֵ�ĵ�Ч�ַ���ƴ�Ӷ��ɵ�һ�����ŷָ����ַ���,���������ÿ��ֵ��Ҫ���� toString() ����,�Եõ����յ��ַ�����
toLocaleString() ��������Ҳ�᷵���� toString()�� valueOf()������ͬ��ֵ,��Ҳ��������ˡ������������
toLocaleString()����ʱ,��Ҳ�ᴴ��һ������ֵ���Զ��ŷָ����ַ���������ǰ��������Ψһ�IJ�֮ͬ������,��һ��Ϊ��ȡ��ÿһ���ֵ,���õ���ÿһ���
toLocaleString()����,������ toString()������
- ����̳е� toLocaleString()��toString()�� valueOf()����,��Ĭ������¶����Զ��ŷָ����ַ�������ʽ��������������ʹ�� join()����,�����ʹ�ò�ͬ�ķָ�������������ַ�����join()����ֻ����һ������,�������ָ������ַ���,Ȼ�ذ���������������ַ�������:(��15)
var colors = ["red", "green", "blue"];
alert(colors.join(",")); //red,green,blue
alert(colors.join("||")); //red||green||blue
������ join() �����κβ���,���ߴ��� undefined,����ʹ�ö�����Ϊ�ָ�����
ע��:��������е�ijһ���ֵ�� null ���� undefined,��ô��ֵ�� join()��toLocaleString()��toString()�� valueOf()�������صĽ�����Կ��ַ�����ʾ��
- ջ����
������������ջһ��,ջ��һ���Ƚ����(LIFO)�Ľṹ,Ҳ����������ӵ����ȱ�ɾ����������IJ���(��Ϊ����)��ɾ��(����) ֻ��ջ��һ���ط�����,��ջ����
ECMAScript �����ṩ�� push() �� pop () ����,��ʵ������ջ����Ϊ��
- push() �����������������IJ���,�����������ӵ�����ĩβ,������������³�����
- pop() ��������ɾ����������һ��,ͬʱ��������� length ֵ,������ɾ����ֵ��
ջ��������������������κη���һ��ʹ�á�
- �����
�������Ƚ��ȳ�(FIFO)����ʽ���Ʒ��ʡ����б�ĩβ��������,�����б���ͷ��ȡ���ݡ�ʹ�� shiift() �� push(),�������鵱�ɶ�����ʹ�á�shift() ������ɾ������ĵ�һ�������,Ȼ�����鳤�ȼ�һ��
ECMAScript ���ṩ��unshift() ����,unshift() ��ִ�и� shift() �෴�IJ���**�����鿪ͷ����������ֵ,Ȼ��������ij��ȡ�**ͨ��ʹ�� unshift() �� pop() ,�������෴������ģ�����,�������鿪ͷ����������,������ĩβȡ�����ݡ�
- ����
���������ַ������Զ�Ԫ����������:reverse() �� sort().
reverse() ����:������Ԫ�ط�������
�������,��������sort() ������
sort() ����:��������������������Ԫ�ء�
sort () ����ÿһ���ϵ���String() ת�ͺ���,Ȼ��Ƚ��ַ���������˳��
��ʹ�����Ԫ�ض�����ֵ,��Ҳ���Ȱ�����ת��Ϊ�ַ����ٱȽϡ�������Ͳ���һ������,��ֵ����Ӧ���ַ�����С��ϵ����һ������ֵ����һ�¡����,sort() ���Խ���һ���ȽϺ���,�����ж��ĸ�ֵӦ��������ǰ�档
�ȽϺ���������������,�����һ������Ӧ�����ڵڶ���������ǰ��,�ͷ��ظ�ֵ;��������������,�ͷ���0;�����һ������Ӧ�����ڵڶ��������ĺ���,�ͷ�����ֵ��
(��16)
function compare(value1,value2) {
if(value1 < value2) {
return -1;
} else if(value1 > value2){
return 1;
} else {
return o;
}
} //����ȽϺ������������ڴ��������������,������������������ sort() ����������:
var values =[2,5,6,3,7];
values.sort(compare);
alert(values); //2,3,5,6,7
- �ȽϺ���Ҳ���Բ�������Ч��,ֻ��Ҫ�ѷ���ֵ����һ�¼���:(��17)
function compare(value1,value2) {
if(value1 < value2) {
return 1;
} else if(value1 > value2){
return -1;
} else {
return o;
}
}
var values =[2,5,6,3,7];
values.sort(compare);
alert(values); //7,6,5,3,2
- �˱ȽϺ���������дΪһ����ͷ����:
var values = [2,5,6,3,7];
values.sort((a,b) => a < b ? 1 : a > b ? -1 : 0);
alert(values); // 7,6,5,3,2
���ֻ���뷴ת�����˳��,reverse()����Ҳ���졣
ע��:reverse()��sort()�����ص������ǵ���������á�
��������Ԫ������ֵ,��������valueOf()����������ֵ�Ķ���(��Date����),����ȽϺ���������д�ø���,��Ϊ��ʱ����ֱ���õڶ���ֵ��ȥ��һ��ֵ,�ȽϺ�������Ҫ����С��0��0�ʹ���0����ֵ,��˼���������ȫ��������Ҫ��
- ���鷽��
�����еIJ���Ԫ�صķ���:
- concat()����
������������ȫ��Ԫ�ػ����ϴ���һ��������(�����Ȼᴴ��һ����ǰ����ĸ���,Ȼ���ٰ����IJ������ӵ�����ĩβ,�������¹���������)��
�������һ����������,��concat()�����Щ�����ÿһ����ӵ�������顣���������������,��ֱ�Ӱ��������ӵ��������ĩβ�� - slice()����
slice()�������� ���� һ������ԭ��������һ������Ԫ�ص�������,�ɽ���һ������������:����Ԫ�ص���ʼ����������������
���ֻ��һ������,��slice()�᷵�ظ�����������ĩβ������Ԫ�ء��������������,��slice()���شӿ�ʼ����������������Ӧ������Ԫ��(���в���������������Ӧ��Ԫ��)��ע��,�ò�����Ӱ��ԭʼ���顣
ע��: ���slice()�IJ����и�ֵ,��ô������ֵ���ȼ��������ֵ�Ľ��ȷ��λ�á�����,�ڰ���5��Ԫ�ص������ϵ���slice(-2,-1),���൱�ڵ���slice(3,4)���������λ��С�ڿ�ʼλ��,�ؿ����顣
- splice()����
splice()��������ҪĿ��,�� �������м����Ԫ��,���� 3 �ֲ�ͬ�ķ�ʽʹ�ø÷���:
- ɾ��
��Ҫ��splice()�� 2 ������:Ҫɾ���ĵ�һ��Ԫ�ص�λ����Ҫɾ����Ԫ�����������Դ�������ɾ��������Ԫ��,����splice(0, 2)��ɾ��ǰ����Ԫ��; - ����
��Ҫ��splice()�� 3 ������:��ʼλ����0(Ҫɾ����Ԫ������)��Ҫ�����Ԫ��,������������ָ����λ�ò���Ԫ�ء�����������֮���Դ����ĸ������������,���� ������ Ҫ�����Ԫ�ء�����,splice(2, 0, ��red��, ��green��)�������λ�� 2 ��ʼ�����ַ���"red"��"green"�� - �滻
splice()��ɾ��Ԫ�ص�ͬʱ������ָ��λ�ò�����Ԫ��,ͬ��Ҫ����3������: ��ʼλ����Ҫɾ��Ԫ�ص�������Ҫ�����������Ԫ����Ҫ�����Ԫ��������һ����ɾ����Ԫ������һ�¡�����,splice(2, 1, ��red��, ��green��)����λ�� 2 ɾ��һ��Ԫ��,Ȼ��Ӹ�λ�ÿ�ʼ�������в���"red"��"green"��
splice()����ʼ�շ�������һ������,�������������б�ɾ����Ԫ��(���û��ɾ��Ԫ��,�ؿ�����)��
- ������λ�÷���
��������ķ����а��ϸ���������Ͱ����Ժ���������
- �ϸ����
ECMAScript�ṩ�� 3 ���ϸ���ȵ���������:
indexOf():�������һ�ʼ��������;
lastIndexOf():���������һ�ʼ��ǰ����;
includes():�������һ�ʼ����������
indexOf()��lastIndexOf()������Ҫ���ҵ�Ԫ���������е�λ��,���û�ҵ���-1��
includes()���ز���ֵ,��ʾ�Ƿ������ҵ�һ����ָ��Ԫ��ƥ�����ڱȽϵ�һ������������ÿһ��ʱ,��ʹ��ȫ��(===)�Ƚ�,Ҳ����˵��������ϸ������
- ���Ժ���
ECMAScript Ҳ�������ն���Ķ��Ժ�����������,ÿ������������ô˺��������Ժ����ķ���ֵ��������Ӧ������Ԫ���Ƿ���Ϊƥ�䡣
���Ժ������� 3 �� ����:Ԫ�������� �� ���鱾��������Ԫ���������е�ǰ������Ԫ��,�����ǵ�ǰԪ�ص�����,�������������������顣���Ժ���������ֵ,��ʾ�Ƿ�ƥ�䡣
find()����: ���� ��һ��ƥ��� Ԫ��;
findIndex()����:���� ��һ��ƥ��Ԫ�ص� ������
����ͬ�㡿:
��ʹ���˶��Ժ���;
�������������������С������ʼ;
Ҳ�����յ� 2 ����ѡ����,����ָ�����Ժ����ڲ�this��ֵ��
- ��������
ECMAScript Ϊ���鶨���� 5 �� ����������ÿ������������������:��ÿһ��Ϊ�������еĺ���,�Լ���ѡ����Ϊ�������������ĵ����������(Ӱ�캯����this��ֵ)������ÿ�������ĺ������� 3 �� ����:����Ԫ�ء�Ԫ������ �� ���鱾����
����� 5 ����������:
- every():������ÿһ����д���ĺ���,�����ÿһ���������true,��÷�������true;
- filter():������ÿһ����д���ĺ���,��������true������������֮��;
- forEach():������ÿһ����д���ĺ���,û�з���ֵ;
- map():������ÿһ����д���ĺ���,���� ��ÿ�κ������õĽ�����ɵ���;
- some():������ÿһ����д���ĺ���,�����һ�������true,��÷�������true��
ע��: �� 5 ������������ı�������ǵ����顣
- �鲢����
ECMAScript Ϊ ���� �ṩ������ �鲢����:
- reduce():�������һ�ʼ ���� �����һ��;
- reduceRight():�����һ�ʼ ���� ����һ�
- ��������������������������,���ڴ˻����Ϲ���һ�����շ���ֵ���Ҷ�������������:��ÿһ������еĹ鲢����,�Լ� ��ѡ����֮Ϊ�鲢���ij�ʼֵ ��
- ����reduce()��reduceRight()�IJ��麯������4������:��һ���鲢ֵ����ǰ������ǰ������������鱾�����ú������ص��κ�ֵ������Ϊ��һ�ε���ͬһ�������ĵ�һ��������
- ���û�и����������������ѡ�ĵڶ�������(��Ϊ�鲢���ֵ),���һ�ε�����������ĵڶ��ʼ,��˴����鲢�����ĵ�һ������������ĵ�һ��,�ڶ�������������ĵڶ��
- ʹ��reduce()����ִ���ۼ�������������ֵ�IJ���
- reduceRight()������reduce()����,ֻ�������෴��
- ������ʹ��reduce() ����reduceRight() ֻȡ������������Ԫ�صķ�����
3.3 Date
������Ϊ��ij���ض��������͵�ʵ�����¶���ͨ��ʹ��new���������һ�����캯�������������캯���������������¶���ĺ�����
ECMAScript���ṩ��:
Date.now()����,���ر�ʾ����ִ��ʱ���ں�ʱ��ĺ�����;
Date.parse()��������һ����ʾ���ڵ��ַ�������,���Խ�����ַ���ת��Ϊ��ʾ�����ڵĺ�������
���ֱ�Ӱѱ�ʾ���ڵ��ַ�������Date���캯��,��ôDate���ں�̨����Date.parse()
ע��:Date.UTC()Ҳ�ᱻDate���캯����ʽ����,����һ������:��������´������DZ�������,����GMT���ڡ�
3.4 RegExp
ECMAScriptͨ��RegExp����֧���������ʽ���������ʽʹ������Perl�ļ���������:
let expression = /pattern/flags;
ÿ���������ʽ���Դ��������flags(���),���ڿ����������ʽ����Ϊ����������˱�ʾƥ��ģʽ�ı�ǡ�
g:ȫ��ģʽ,��ʾ�����ַ�����ȫ������,�������ҵ���һ��ƥ������ݾͽ���i:�����ִ�Сд,��ʾ�ڲ���ƥ��ʱ����pattern���ַ����Ĵ�Сд��
m ����ģʽ,��ʾ���ҵ�һ���ı�ĩβʱ��������ҡ�y:ճ��ģʽ,��ʾֻ���Ҵ�lastIndex��ʼ��֮����ַ�����u:Unicodeģʽ,����Unicodeƥ�䡣s:dotAllģʽ,��ʾԪ�ַ�.ƥ���κ��ַ�(����\n��\r)��
RegExpʵ������Ҫ������exec(),��Ҫ������ϲ�����ʹ�á��������ֻ����һ������,��ҪӦ��ģʽ���ַ���������ҵ���ƥ����,�ذ�����һ��ƥ����Ϣ������;���û�ҵ�ƥ����,��null;
�������ʽ����һ��������test(),����һ���ַ������������������ı���ģʽƥ��,���������true,����false���������������ֻ�����ģʽ�Ƿ�ƥ��,������Ҫʵ��ƥ�����ݵ������test()��������if����С�
�����������ʽ����ô������,�̳еķ���toLocaleString()��toString()�������������ʽ����������ʾ���������ʽ��valueOf()���������������ʽ������
3.5 ԭʼֵ��װ����
Ϊ�˷������ԭʼֵ,ECMAScript�ṩ�� 3 ���������������:Boolean��Number �� String��
ÿ���õ�ij��ԭʼֵ�ķ���������ʱ,��̨���ᴴ��һ����Ӧԭʼ��װ���͵Ķ���,����¶����ԭʼֵ�ĸ��ַ�����
ʵ����,ÿ����ȡһ����������ֵ��ʱ��,��̨�ͻᴴ��һ����Ӧ�Ļ�����װ���͵Ķ���,�Ӷ��������ܹ�����һЩ������������Щ���ݡ���̨��������:
(1) ���� String/Boolean/Number ���͵�һ��ʵ��;
(2) ��ʵ���ϵ���ָ���ķ���;
(3) �������ʵ��
���������������װ���͵���Ҫ������Ƕ���������ڡ�ʹ�� new �������������������͵�ʵ��,��ִ�����뿪��ǰ������֮ǰ��һֱ�������ڴ��С����Զ������Ļ�����װ���͵Ķ���,��ֻ������һ�д����ִ��˲��,Ȼ�����������١�����ζ�����Dz���������ʱΪ��������ֵ�������Ժͷ�����
- Boolean
Boolean ���͵�ʵ����д��valueOf()����,���ػ�������ֵtrue ��false;��д��toString()����,�����ַ���"true"��"false"������,Boolean ������ECMAScript �е��ô�����,��Ϊ��������������ǵ���⡣ - String
- �ַ�������:���ڷ����ַ������ض��ַ��ķ���:charAt() ��charCodeAt() ��������������һ������,������0���ַ�λ��,���� ��λ�õ��ַ���
- �ַ�����������:
concat()ƴ���ַ���
slice()�ָ��ַ���, ����Ϊ��ֵʱ,���� ��ĸ�ֵ���ַ����ij������
substr()��������,��һ����������ʼλ��(ֻ��һ�������������ص�ǰλ�õ����������ַ�),�ڶ�������(��ѡ)��Ҫ���صĸ��� ����Ϊ��ֵʱ,�����ĵ�һ�����������ַ����ij���,�������ĵڶ��� ����ת��Ϊ 0��
substring()��slice() һ��,���Dz���Ϊ����ʱ,�Ὣ���в�����ת��Ϊ0. - �ַ���λ�÷���:indexOf() ��lastIndexOf() ������ķ�������
- �ַ�����Сдת��:
toLowerCase() ����ת��ΪСд;
toUpperCase() ����ת��Ϊ��д;
toLocaleLowerCase() �� toLocaleUpperCase()������������ض�������ʵ�� - �ַ�����ģʽƥ�䷽��: match()��search()��replace()�� split()
localecompare()��������Ƚ������ַ���,���������� ֵ�е�һ��:
? ����ַ�������ĸ����Ӧ�������ַ�������֮ǰ,��һ������(������������-1);
? ����ַ��������ַ�������,�� 0;
? ����ַ�������ĸ����Ӧ�������ַ�������֮��,��һ������(������������ 1)�� fromCharCode()�ǽ���һ�� ����ַ�����,Ȼ������ת����һ���ַ���
- Number
Number ��������ֵ��Ӧ���������͡�Ҫ���� Number ����,�����ڵ��� Number ���캯��ʱ�����д�����Ӧ����ֵ��
Number ������д�� valueOf()��toLocaleString()�� toString()��������д��� valueOf()�������ض����ʾ�Ļ������͵���ֵ,���������������ַ�����ʽ����ֵ��
���˼̳еķ���֮��,Number ���ͻ��ṩ��һЩ���ڽ���ֵ��ʽ��Ϊ�ַ����ķ�����toFixed()�����ᰴ��ָ����С��λ������ֵ���ַ�����ʾ, toExponential()����������ָ����ʾ��(Ҳ�� e ��ʾ��)��ʾ����ֵ���ַ�����ʽ��
3.6 �������ö���
���ö�����������ʽʵ�������ö���,��Ϊ�����Ѿ�ʵ�������ˡ����������ö������Object��Array �� String,������Ҫ�������������������ö���:Global �� Math��
- Global����
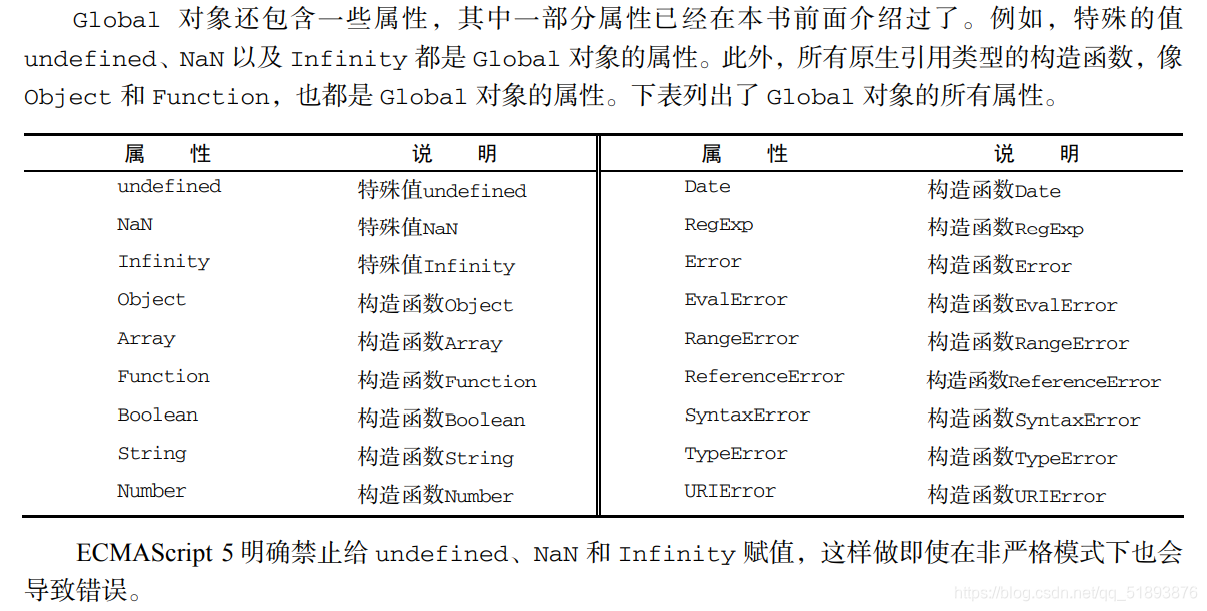
Global���ᱻ������ʽ����,ECMA-262�涨Global����Ϊһ�ֶ�����,������Ե��Dz������κζ�������Ժͷ�����
��ʵ��,������ ȫ�ֱ��� �� ȫ�ֺ��� ���ֶ�������ȫ���������ж���ı����ͺ���������Global��������� �� ����isNaN()��isFinite()��parseInt()��parseFloat(),ʵ���϶��� Global ����ķ�����������Щ,Global �����ϻ�������һЩ������
- URL���뷽��
���ڱ���ͳһ��Դ��ʶ��(URI),�Ա㴫�����������Ч��URI���ܰ���ijЩ�ַ�(����ո�)��ʹ��URI���뷽��������URI������������ܹ���������,ͬʱ���������UTF-8�����滻��������Ч�ַ���
���뷽��:
ecnodeURI()����:���ڶ�����URI���б���;���� ��www.wrox.com/illegal value.js����
encodeURIComponent()����:���ڱ���URI�е��������,����ǰ��URL�е� " illegal value.js "
let uri = "http://www.wrox.com/illegal value.js#start";
// "http://www.wrox.com/illegal%20value.js#start"
console.log(encodeURI(uri)); // �ո��滻Ϊ%20
// "http%3A%2F%2Fwww.wrox.com%2Fillegal%20value.js%23start"
console.log(encodeURIComponent(uri));
encodeURI()�����������URL����������ַ�(����ð�š�б�ܡ��ʺš�����),��encodeURIComponent()����������ֵ����зDZ��ַ���
ע��: һ����˵,ʹ�� encodeURIComponent() ��ʹ�� encodeURI() ��Ƶ�ʸ���,������Ϊ�����ѯ�ַ��������ȱ����URI�Ĵ������ࡣ
��encodeURI()��encodeURIComponent()�������decodeURI()������decodeURIComponent()����:
decodeURI()����:ֻ��ʹ��encodeURI()��������ַ����롣����,%20�ᱻ�滻Ϊ�ո�,��%23���ᱻ�滻Ϊ����(#),��Ϊ���Ų�����encodeURI()�滻�ġ�
decodeURIComponent()����:�������б�encodeURIComponent()������ַ�,�����Ͼ��ǽ�����������ֵ��
- eval����
eval()����������ECMAScript��������ǿ�����,������һ�������� ECMAScript ������ ��
eval("console.log('hi')");
`�ȼ���
console.log("hi");
ͨ��eval()ִ�еĴ������ڸõ�������������,��ִ�еĴ������������ӵ����ͬ�����������������ڰ����������еı���������eval()�����ڲ������á�
let msg = "hello world";
eval("console.log(msg)"); // "hello world"
Ҳ������eval()�ڲ�����һ�����������,Ȼ�����ⲿ���������á�
eval("function sayHi() { console.log('hi'); }");
sayHi();
ͨ��eval()������κα����ͺ��������ᱻ����,������Ϊ�ڽ��������ʱ��,�����DZ�������һ���ַ����еġ�ֻ����eval()ִ�е�ʱ��Żᱻ������
ע��:
1.�ϸ�ģʽ��,��eval()�ڲ������ı����ͺ��������ⲿ���ʡ�ͬ��,���ϸ�ģʽ��,��ֵ��evalҲ�ᵼ�´���;
2.���ʹ����ַ�����������Ȼ�dz�ǿ��,��Ҳ��Σ������ʹ��eval()ʱ��������,�ر��ǽ����û���������ʱ����Ϊ�÷������XSS���ñ�¶���ܴ�Ĺ����档�����û����ܲ���ᵼ������վ��Ӧ�ñ����Ĵ��롣
- Global��������
- window ����
������� window ����ʵ��Ϊ Global ����Ĵ�����������ȫ���������������ı����ͺ���������� window ������ ��
��һ�ֻ�ȡ Global ����ķ�ʽ,������ʾ:
let global = function() {
return this;
}();
���δ��봴������������,������this��ֵ��
��һ��������û����ȷ(ͨ����Ϊij������ķ���,����ͨ��call()/apply() )ָ��thisֵ�������ִ��ʱ,thisֵ���� Global ���� ���,����һ������this�ĺ��������κ�ִ���������л�ȡ Global �����ͨ�÷�ʽ��
- Math
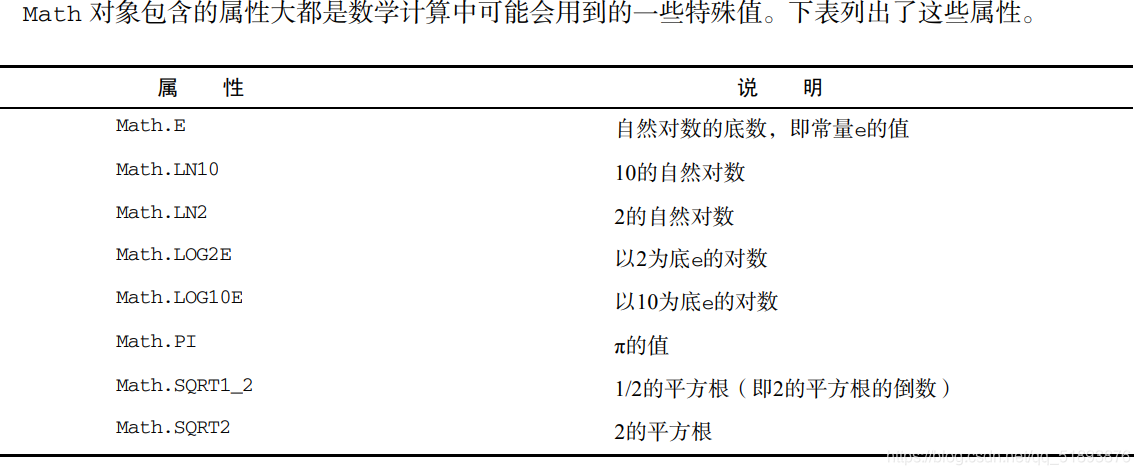
Math�������ڱ�����ѧ��ʽ����Ϣ�ͼ���,���ṩ��һЩ������������Ժͷ�����
Math�������ṩ�ļ���Ҫ��ֱ���� JavaScript ʵ�ֵ����ö�,��ΪMath�����ϵļ���ʹ����JavaScript �����и���Ч��ʵ�ֺʹ�����ָ�
ע��:ʹ�� Math ����ľ��Ȼ��������������ϵͳ��ָ���Ӳ������ ��
- Math��������
- min() �� max() ����
����ȷ��һ����ֵ�е���Сֵ�����ֵ,������������������
let max = Math.max(3, 54, 32, 16);
console.log(max); // 54
let min = Math.min(3, 54, 32, 16);
console.log(min); // 3
�������������Ա���ʹ�ö����ѭ����if�����ȷ��һ����ֵ�������Сֵ��
�����е����ֵ����Сֵ,��������������ʹ����չ������(...):
let values = [1, 2, 3, 4, 5, 6, 7, 8];
let max = Math.max(...values);
- Math���뷽��
��С��ֵ����Ϊ������4������:
Math.ceil()����:�������� Ϊ��ӽ�������;Math.floor()����:�������� Ϊ��ӽ���������;Math.round()����:ִ�� ��������;Math.fround()����:������ֵ��ӽ��� ������(32λ)����ֵ��
- 6.2.4 Math.random()����
Math.random()��������һ��0~1��Χ�ڵ������,���а���0��������1����Ӧ������ʾ������Ի�������ŵ���ҳ��
��һ�����������ѡ��һ����:
1)��ʽ:
number = Math.floor(Math.random() * total_number_of_choices + first_possible_value)
��ʽ��ʹ����Math.floor()����,��ΪMath.random()ʼ�շ���С��,�������һ�����ټ���һ����Ҳ��С����
2)����:
��1~10��Χ�����ѡ��һ����,��������:
let num = Math.floor(Math.random() * 10 + 1);
�������� 10 �����ܵ�ֵ(1~10),������С��ֵΪ1��
�����ѡ��һ��2~10��Χ�ڵ�ֵ,���������:
let num = Math.floor(Math.random() * 9 + 2);
2~10ֻ��9����,���Կ�ѡ����(total_number_of_choices)��9,����С���ܵ�ֵ(first_possible_value)Ϊ2��
- ��������
4. ����
4.1 �������
- ��������
ECMAScript ������������:�������Ժͷ���������
1).��������
����������һ������ֵ��λ�á������λ�ÿ��Զ�ȡ��д��ֵ������������4����������Ϊ������:
Configurable- ��ʾ�ܷ�ͨ��deleteɾ�����ԴӶ����¶�������,�ܷ������Ե�����,�����ܷ��������Ϊ����������,Ĭ��ֵΪtrue
Enumerable- ʾ�ܷ�ͨ��for-inѭ����������,Ĭ��ֵΪtrue
Writeable- �ܷ�д��
Value- ����������Ե�����ֵ,д�����Ե�ʱ���ֵ������,Ĭ��ֵΪ undefined
Object.defineProperty()- ��Ĭ������
��:
var person = {}
Object.defineProperty(person, "name", {
writable: false,
value: "limy"
})
console.log(person.name); // limy
person.name = "limy1"
console.log(person.name); // limy
?????????2).����������
Configurable - ��ʾ�ܷ�ͨ��deleteɾ�����ԴӶ����¶�������,�ܷ������Ե�����,�����ܷ��������Ϊ����������,Ĭ��ֵΪtrue;
Enumerable - ʾ�ܷ�ͨ��for-inѭ����������,Ĭ��ֵΪtrue;
Get - ��ȡ����ʱ���õĺ���;
Set - д������ʱ���õĺ���;
���������Բ���ֱ�Ӷ���,��Ҫͨ��Object.defineProperty()
��:
var book = {
_year: 2018,
edition: 1
};
Object.defineProperty(book,"year", {
get: function() {
return this._year
},
set: function(newValue) {
if(newValue > 2018) {
this._year = newValue;
this.edition += newValue - 2018;
}
}
});
book.year = 2019;
alert(book.edition); // 2
-
����������
ECMAScript 5 ������һ��Object.defineProperties()���������������������ͨ��������һ�ζ�����������
����������������������:��һ������Ҫ���Ӻ��������ԵĶ���,�ڶ���������������һ��������Ҫ���ӻ��ĵ�����һһ��Ӧ��
֧�� Object.defineProperties()������������� IE9+��Firefox 4+��Safari 5+��Opera 12+��Chrome�� -
��ȡ���Ե�����
ʹ�� ECMAScript 5 ��Object.getOwnPropertyDescriptor()����,����ȡ�ø������Ե���������
�������������������:�������ڵĶ����Ҫ��ȡ�����������������ơ�����ֵ��һ������,����Ƿ���������,�������������� configurable��enumerable��get �� set;�������������,�������������� configurable��enumerable��writable �� value��
�� JavaScript ��,��������κζ������� DOM �� BOM ����,ʹ�� Object.getOwnPropertyDescriptor()������֧������������������ IE9+��Firefox 4+��Safari 5+��Opera 12+�� Chrome
4.2 ��������
-
����ģʽ
����ģʽ��������������һ�ֹ�Ϊ��֪�����ģʽ,����ģʽ�����˴����������Ĺ��̡���������һ�ֺ���,�Ѷ���ŵ�������,�ú�����װ���������ϸ�ڡ�
����ģʽ����˴��븴��(������������ƶ���)������,ȴû�н������ʶ������⡣���������ж�����Object ���͡�Ϊ�˽����һ����,���������캯��ģʽ�� -
���캯��ģʽ
����֪��,ECMAScript �еĹ��캯�������������ض����͵Ķ����� Object �� Array ������ԭ�����캯��,������ʱ���Զ�������ִ�л����С�����,Ҳ���Դ����Զ���Ĺ��캯��,�Ӷ������Զ���������͵����Ժͷ�����
���캯������ͨ������Ψһ������ǵ��÷�ʽ��ͬ,���캯���Ͼ�Ҳ�Ǻ���,�����ڶ��幹�캯������������κκ���,ֻҪͨ�� new ������������,�����Ϳ�����Ϊ���캯��;���κκ���,�����ͨ�� new ������������,��������ͨ����Ҳ������ʲô������
���캯��������ĸ���ƶ���Ҫ��д��,�ǹ��캯������Сд��ĸ��ͷ����˿��Ը��õر����ߡ�
ʹ�� new ���������ù��캯����ִ�����²���:
- ���ڴ��д���һ���¶���;
- �����캯�����������¶���(��� this ��ָ��������¶���);
- ִ�й��캯���еĴ���(Ϊ����¶�����������);
- �����¶���
�����Զ���Ĺ��캯����ζ�Ž������Խ�����ʵ����ʶΪһ���ض�������;�������ǹ��캯��ģʽ����ڹ���ģʽ���ŵ㡣
���캯������ķ�������ÿ��ʵ���϶�����һ��,��ᵼ����ͬ�ĺ����ᱻ�ظ����塣����������ͨ���Ѻ������嵽���캯���ⲿ������������������취��Ȼ�������ͬ���ĺ����ظ����������,ȴҲ������ȫ�������������ֲ�����ԭ��ģʽ�������һ���⡣
- ԭ��ģʽ
ÿ����������һ�� prototype(ԭ��)����,���������һ��ָ��,ָ��һ������,������������;�ǰ����������ض����͵�����ʵ�����������Ժͷ������� prototype ����ͨ�����ù��캯�����������Ǹ�����ʵ����ԭ�Ͷ�����
ʹ��ԭ�Ͷ���ĺô������������ж���ʵ�������������������Ժͷ������������ڹ��캯���ж������ʵ������Ϣ,���ǿ��Խ���Щ��Ϣֱ�����ӵ�ԭ�Ͷ����С�
- ����ԭ�Ͷ���
���ۺ�ʱ,ֻҪ������һ���º���,�ͻ����һ���ض��Ĺ���Ϊ�ú�������һ��prototype����,�������ָ������ԭ�Ͷ�����
��Ĭ�������,����ԭ�Ͷ����Զ����һ��constructor(���캯��)����,���������һ��ָ�� prototype �������ں�����ָ�롣��ͨ��������캯��,���ǻ��ɼ���Ϊԭ�Ͷ��������������Ժͷ�����
�������Զ���Ĺ��캯��֮��,��ԭ�Ͷ���Ĭ��ֻ��ȡ�� constructor ����;������������,���Ǵ� Object �̳ж����ġ������ù��캯������һ����ʵ����,��ʵ�����ڲ�������һ��ָ��(�ڲ�����),ָ���캯����ԭ�Ͷ���ECMA-262 �� 5 ���й����ָ���[[Prototype]]����Ȼ�ڽű���û�б��ķ�ʽ����[[Prototype]],�� Firefox��Safari �� Chrome ��ÿ�������϶�֧��һ������__proto__(_proto_����������ȡ�����õ�ǰ�����prototype ����);��������ʵ����,������ԶԽű�������ȫ���ɼ��ġ�����,������Ӵ�����ʵ���빹�캯����ԭ�Ͷ���֮��,�����Ǵ�����ʵ���빹�캯��֮����
��Ȼ������ʵ���ж������ʵ�[[Prototype]],������ͨ��
isPrototypeOf()������ȷ������֮���Ƿ�������ֹ�ϵ���ӱ����Ͻ�,���[[Prototype]]ָ����� isPrototypeOf()�����Ķ���,��ô��������ͷ��� true
ECMAScript 5 ������һ���·���,�� Object.getPrototypeOf(),������֧�ֵ�ʵ����,�����������[[Prototype]]��ֵ��
ÿ�������ȡij�������ij������ʱ,����ִ��һ������,Ŀ���Ǿ��и������ֵ����ԡ��������ȴӶ���ʵ��������ʼ�������ʵ�����ҵ��˾��и������ֵ�����,�ظ����Ե�ֵ;���û���ҵ�,����������ָ��ָ���ԭ�Ͷ���,��ԭ�Ͷ����в��Ҿ��и������ֵ����ԡ������ԭ�Ͷ������ҵ����������,�ظ����Ե�ֵ��
��Ȼ����ͨ������ʵ�����ʱ�����ԭ���е�ֵ,��ȴ����ͨ������ʵ����дԭ���е�ֵ�����������ʵ����������һ������,����������ʵ��ԭ���е�һ������ͬ��,�����Ǿ���ʵ���д���������,�����Խ�������ԭ���е��Ǹ����ԡ�
��:
function Person(){
}
Person.prototype.name = "Nicholas";
Person.prototype.age = 29;
Person.prototype.job = "Software Engineer";
Person.prototype.sayName = function(){
alert(this.name);
};
var person1 = new Person();
var person2 = new Person();
person1.name = "Greg";
alert(person1.name); //"Greg"��������ʵ��
alert(person2.name); //"Nicholas"��������ԭ��
��Ϊ����ʵ������һ������ʱ,������Ծͻ�����ԭ�Ͷ����б����ͬ������;���仰˵,�����������ֻ����ֹ���Ƿ���ԭ���е��Ǹ�����,���������Ǹ����ԡ���ʹ�������������Ϊ null,Ҳֻ����ʵ���������������,������ָ���ָ��ԭ�͵����ӡ�����,ʹ�� delete �������������ȫɾ��ʵ������,�Ӷ��������ܹ����·���ԭ���е����ԡ�
��:
function Person(){
}
Person.prototype.name = "Nicholas";
Person.prototype.age = 29;
Person.prototype.job = "Software Engineer";
Person.prototype.sayName = function(){
alert(this.name);
};
var person1 = new Person();
var person2 = new Person();
person1.name = "Greg";
alert(person1.name); //"Greg"��������ʵ��
alert(person2.name); //"Nicholas"��������ԭ��
delete person1.name;
alert(person1.name); //"Nicholas"��������ԭ��
ʹ�� hasOwnProperty()�������Լ��һ�������Ǵ�����ʵ����,���Ǵ�����ԭ���С���������Ǵ� Object �̳�����,��ֻ���������Դ����ڶ���ʵ����ʱ,�Ż᷵�� true��ͨ��ʹ�� hasOwnProperty()����,ʲôʱ����ʵ���ʵ������,ʲôʱ����ʵ���ԭ�����Ծ�һ������ˡ�
ECMAScript 5 �� Object.getOwnPropertyDescriptor()����ֻ������ʵ������,Ҫȡ��ԭ�����Ե�������,����ֱ����ԭ�Ͷ����ϵ���Object.getOwnPropertyDescriptor()������
- ԭ����
in������
�����ַ�ʽʹ�� in ������:����ʹ������ for-in ѭ����ʹ�á�
�ڵ���ʹ��ʱ,in ����������ͨ�������ܹ����ʸ�������ʱ���� true,���۸����Դ�����ʵ���л���ԭ���С�
�������Դ�����ʵ���л��Ǵ�����ԭ����,ֻҪͬʱʹ�� hasOwnProperty()������ in ������,�Ϳ���ȷ�������Ե����Ǵ����ڶ�����,���Ǵ�����ԭ���С� ��Ϊ in ������ֻҪͨ�������ܹ����ʵ����Ծͷ��� true,hasOwnProperty()ֻ�����Դ�����ʵ����ʱ�ŷ��� true,��ֻҪ in ���������� true ��hasOwnProperty()���� false,�Ϳ���ȷ��������ԭ���е����ԡ�
��ʹ�� for-in ѭ��ʱ,���ص��������ܹ�ͨ��������ʵġ���ö�ٵ�(enumerated)����,���мȰ���������ʵ���е�����,Ҳ����������ԭ���е����ԡ�������ԭ���в���ö������(����[[Enumerable]]���Ϊ false ������)��ʵ������Ҳ���� for-in ѭ���з���,��Ϊ���ݹ涨,���п�����Ա��������Զ��ǿ�ö�ٵġ���ֻ���� IE8 ������汾������ (IE ���ڰ汾��ʵ���д���һ�� bug,�����β���ö�����Ե�ʵ�����Բ�������� for-in ѭ����)��
Ҫȡ�ö��������п�ö�ٵ�ʵ������,��ʹ��ES5��object.keys()�������÷�������һ��������Ϊ����,����һ���������п�ö�����Ե��ַ������顣
function Person(){};
Person.prototype.name = 'Lily';
Person.prototype.age = 17;
Person.prototype.job = 'Teacher';
Person.prototype.sayName = function(){
alert(this.name);
}
var keys = Object.keys(Person.prototype);
alert(keys); //"name,age,job,sayName";
alert(Array.isArray(keys)); //true
alert(keys.length); //4
var person1 = new Person();
person1.name = "Candy";
person1.job = "Singer";
var keys2 = Object.keys(person1);
alert(keys2); //"name,job";
constructor ���Բ���ö�١�����������ʵ������(�����Ƿ��ö��),���ʹ��Object.getOwnPropertyName() ������
function Person(){};
Person.prototype.name = 'Lily';
Person.prototype.age = 17;
Person.prototype.job = 'Teacher';
Person.prototype.sayName = function(){
alert(this.name);
}
var keys = Object.getOwnPropertyName(Person.prototype);
alert(keys); //"constructor,name,age,job,sayName";
�� Person.prototype ����Ϊ����һ���Զ����������������¶���,�Ǹ�Ϊ��ԭ��������������,����������ȫ��д��Ĭ�ϵ� prototype ����,ʹ�� constructor ���Բ���ָ��Person��(ָ��Object���캯��)��
��ͨ�����·�ʽ��constructor��������ָ��Person:
function Person(){};
Person.prototype = {
constructor: Person, //����constructor����
name: 'Lily',
age: 17,
job: 'Teacher',
sayName: function(){
alert(this.name);
}
};
�����ַ�ʽ�ᵼ������ [[Enumerable]](��ö��)���Ա�����Ϊtrue��
��ԭ�Ͷ����������κ��Ķ���������ʵ���Ϸ�ӳ����,�������ȴ�����ʵ������ԭ��:
var friend = new Person();
Person.prototype.sayHi = function(){
alert('Hi!');
};
friend.sayHi(); //"Hi!"
��������д����ԭ�Ͷ���,����Ͳ�һ����:
var friend = new Person();
Person.prototype = {
construcor: Person,
name: 'Candy',
age: 22,
job: 'Dancer',
sayName: function(){
alert(this.name);
}
};
friend.sayName(); //error
��Ϊ,���ù��캯��ʱ��Ϊʵ������һ��ָ�����ԭ����ָ��,����ԭ����Ϊ����һ������͵�ͬ���ж���ʵ�������ԭ��֮�����ϵ��
ʵ���е�ָ���ָ��ԭ��,����ָ���캯����
��дԭ�Ͷ����ж�������ԭ�����κ�֮ǰ�Ѿ����ڵĶ���ʵ��֮�����ϵ,�������õ���Ȼ�������ԭ�͡�
ԭ�Ͷ���ı�:�������а�����������ֵʱ,��ʵ������Ӧ����������ֵ���������ԭ���е���������ֵ��
- ���ʹ�ù��캯��ģʽ��ԭ��ģʽ
�����Զ������͵������ʽ,�������ʹ�ù��캯��ģʽ��ԭ��ģʽ�����캯��ģʽ���ڶ���ʵ������,��ԭ��ģʽ���ڶ��巽�����������������,ÿ��ʵ���������Լ���һ��ʵ�����Եĸ���,��ͬʱ�ֹ����ŶԷ���������,����ȵؽ�ʡ���ڴ档����,���ֻ��ģʽ��֧�����캯�����ݲ�����
���ֹ��캯����ԭ�ͻ�ɵ�ģʽ,��Ŀǰ�� ECMAScript ��ʹ����㷺����ͬ����ߵ�һ�ִ����Զ������͵ķ���������˵,�������������������͵�һ��Ĭ��ģʽ��
- ��̬ԭ��ģʽ
��̬ԭ���ǰ�������Ϣ����װ���˹��캯����,��ͨ���ڹ��캯���г�ʼ��ԭ��(���ڱ�Ҫ�������),�ֱ�����ͬʱʹ�ù��캯����ԭ�͵��ŵ㡣���仰˵,����ͨ�����ij��Ӧ�ô��ڵķ����Ƿ���Ч,�������Ƿ���Ҫ��ʼ��ԭ��,��:
function Person(name,age,job){
this.name = name;
this.age = age;
this.job = job;
//����
if(typeof this.sayName != "function"){
Person.prototype.sayName = function(){
alert(this.name);
}
}
}
var friend = new Person("Tony",21,"teacher");
friend.sayName();
- sayName()���������ڵ������,�ŻὫ�����ӵ�ԭ���С�
- ��δ���ֻ���ڳ��ε��ù��캯��ʱ�Ż�ִ�С��˺�,ԭ���Ѿ���ɳ�ʼ��,����Ҫ����ʲô����,���������ԭ����������,�ܹ�����������ʵ���еõ���ӳ,���,���ַ���ȷʵso good��
- ����,if�����Ŀ����dz�ʼ��֮��Ӧ�ô��ڵ��κ����Ժͷ�������������һ���if�����ÿ�����Ժͷ���,ֻҪ�������һ�����ɡ�
���ڲ�������ģʽ�����Ķ���,������ʹ��instanceof������ȷ���������͡�
ע��:ʹ�ö�̬ԭ��ģʽʱ,����ʹ�ö�����������дԭ��,������Ѿ�������ʵ�����������дԭ��,�ͻ��ж�����ʵ����ԭ��֮�����ϵ��
- �������캯��
��ǰ���ļ���ģʽ�������õ������,����ʹ������(parasitic)���캯��ģʽ���������캯���Ļ���˼���Ǵ���һ������,�ú��������ý����Ƿ�װ��������Ĵ���,Ȼ���ٷ����´����Ķ���;���ӱ����Ͽ�,��������ֺ����ǵ��͵Ĺ��캯������:
function Person(name, age, job){
var o = new Object();
o.name = name;
o.age = age;
o.job = job;
o.sayName = function(){
alert(this.name);
};
return o;
}
var friend = new Person("Nicholas", 29, "Software Engineer");
friend.sayName(); //"Nicholas"
�����������,Person ����������һ���¶���,������Ӧ�����Ժͷ�����ʼ���ö���,Ȼ���ַ������������
����ʹ�� new ����������ʹ�õİ�װ�����������캯��֮��,���ģʽ������ģʽ��ʵ��һģһ���������캯���ڲ�����ֵ�������,Ĭ�ϻ᷵���¶���ʵ������ͨ���ڹ��캯����ĩβ����һ�� return ���,������д���ù��캯��ʱ���ص�ֵ�����ģʽ��������������������Ϊ�������캯�������봴��һ�����ж��ⷽ������������,�����ڲ���ֱ���� Array ���캯��,��˿���ʹ�����ģʽ��
���ڼ������캯��ģʽ,��Ҫע�����:����,���صĶ����빹�캯�������빹�캯����ԭ������֮��û�й�ϵ,��Ҳ����˵,���캯�����صĶ������ڹ��캯���ⲿ�����Ķ���û��ʲô��ͬ��Ϊ��,�������� instanceof ��������ȷ���������������ڴ�����������,���ǽ����ڿ���ʹ������ģʽ���� ����,��Ҫʹ������ģʽ��
- �����캯��ģʽ
������˹�����˸���(Douglas Crockford)������ JavaScript �е�������(durable objects)������������,ָ����û�й�������,�����䷽��Ҳ������ this �Ķ���
���������ʺ���һЩ��ȫ�Ļ�����(��Щ�����л��ֹʹ�� this �� new),�����ڷ�ֹ���ݱ�����Ӧ�ó���(�� Mashup����)�Ķ�ʱʹ�á�
�����캯����ѭ��������캯�����Ƶ�ģʽ,�������㲻ͬ:
- �´��������ʵ������������ this;
- ���Dz�ʹ�� new ���������ù��캯����
4.3 �̳�
�̳��� OO �����е�һ����Ϊ�˽���ֵ��ĸ������ OO ���Զ�֧�����ּ̳з�ʽ:�ӿڼ̳���ʵ�ּ̳���
�ӿڼ̳�ֻ�̳з���ǩ��,��ʵ�ּ̳���̳�ʵ�ʵķ��������ں���û��ǩ��,�� ECMAScript ����ʵ�ֽӿڼ̳С�ECMAScript ֻ֧��ʵ�ּ̳�,������ʵ�ּ̳���Ҫ������ԭ������ʵ�ֵġ�
- ԭ����
ECMAScript ��������ԭ�����ĸ���,����ԭ������Ϊʵ�ּ̳е���Ҫ�����������˼��������ԭ����һ���������ͼ̳���һ���������͵����Ժͷ������ع�һ�¹��캯����ԭ�ͺ�ʵ���Ĺ�ϵ:ÿ�����캯������һ��ԭ�Ͷ���,ԭ�Ͷ�����һ��ָ���캯����ָ��,��ʵ��������һ��ָ��ԭ�Ͷ�����ڲ�ָ�롣�ʶ�,ʹԭ�Ͷ��������һ�����͵�ʵ��,��ʵ�ּ̳�:
A.prototype = new B(); //�̳���B
������ԭ�Ͷ��������һ�����͵�ʵ�������ʱ��ԭ�Ͷ�����һ��ָ����һ��ԭ�͵�ָ��,��Ӧ��,��һ��ԭ����Ҳ������һ��ָ����һ�����캯����ָ�롣������һ��ԭ��������һ�����͵�ʵ��,��ô������ϵ��Ȼ����,��˲��ݽ�,������ʵ����ԭ�͵��������������νԭ�����Ļ������
ԭ�����̳е�ʵ�ʾ�����дԭ�Ͷ���
���Զ�ȡģʽ����һ��ʵ������ʱ,���Ȼ���ʵ��������������,��û���ҵ�������,����������ʵ����ԭ�͡���ͨ��ԭ�����̳е������,�������̾͵�������ԭ�����̳����ϡ�
�����������Ͷ�Ĭ�ϼ̳���Object,����̳�Ҳ��ͨ��ԭ����ʵ�ֵġ����Ժ�����1Ĭ��ԭ�Ͷ���Object��ʵ����P164
ȷ��ԭ�ͺ�ʵ��֮��Ĺ�ϵ:ʹ�� instanceof �� isPrototypeOf() ������
alert(A instanceof B); //boolean
// A��B��ʵ��,��true,��֮����false
alert(A.prototype.isPrototypeOf(B)); //boolean
//A��ԭ��Ҳ��B��ԭ��
ע:
- ��ԭ�����ӷ����Ĵ���һ��Ҫ�����滻ԭ�͵����֮��
- ��ͨ��ԭ����ʵ�ּ̳�ʱ,����ʹ�ö�������������ԭ�ͷ���,��������дԭ�ͷ�����
- ԭ�����̳еı�:����Դ�ڰ�����������ֵ��ԭ��,������������ֵ��ԭ�����Իᱻ����ʵ��������
ԭ����������:
- ����Ҫ��������������������ֵ��ԭ�͡���ԭ��ģʽ��ѧ���˰�����������ֵ��ԭ�����Իᱻ����ʵ������;��Ҳ����ΪʲôҪ�ڹ��캯����,��������ԭ�Ͷ����ж������Ե�ԭ����ͨ��ԭ����ʵ�ּ̳�ʱ,ԭ��ʵ���ϻ�����һ�����͵�ʵ��������,ԭ�ȵ�ʵ������Ҳ��˳�����µر�������ڵ�ԭ�������ˡ�
- �ڴ��������͵�ʵ��ʱ,���������͵Ĺ��캯���д��ݲ�����ʵ����,Ӧ��˵��û�а취�ڲ�Ӱ�����ж���ʵ���������,�������͵Ĺ��캯�����ݲ������м��ڴ�,�ټ���ǰ��ո����۹�������ԭ���а�����������ֵ������������,ʵ���к��ٻᵥ��ʹ��ԭ������
- �������캯��
�ڽ��ԭ���а�����������ֵ������������Ĺ�����,������Աʹ��һ�ֽ������ù��캯���ļ���(��ʱҲ����α������̳�)�����ù��캯���Ļ���˼���൱��,�����������캯�����ڲ����ó������캯������Ϊ����ֻ���������ض�������ִ�д���Ķ���,���ͨ��ʹ��apply()��call()����Ҳ�������´��ݵĶ�����ִ�й��캯��:
function SuperType(){
this.colors = ["red", "blue", "green"];
}
function SubType(){
//�̳��� SuperType
SuperType.call(this);
}
var instance1 = new SubType();
instance1.colors.push("black");
alert(instance1.colors); //"red,blue,green,black"
var instance2 = new SubType();
alert(instance2.colors); //"red,blue,green"
- ���ݲ���
�����ԭ��������,���ù��캯����һ���ܴ������,���������������캯�����������캯�����ݲ�����
function SuperType(name){
this.name = name;
}
function SubType(){
//�̳��� SuperType,ͬʱ�������˲���
SuperType.call(this, "Nicholas");
//ʵ������
this.age = 29;
}
var instance = new SubType();
alert(instance.name); //"Nicholas";
alert(instance.age); //29
SuperType ֻ����һ������ name,�ò�����ֱ�Ӹ���һ�����ԡ��� SubType ���캯���ڲ����� SuperType ���캯��ʱ,ʵ������Ϊ SubType ��ʵ�������� name ���ԡ�Ϊ��ȷ��SuperType ���캯��������д�����͵�����,�����ڵ��ó������캯����,������Ӧ�����������ж�������ԡ�
- ���ù��캯��������
��������ǽ��ù��캯��,��ôҲ��������캯��ģʽ���ڵ����⡪���������ڹ��캯���ж���,��˾������ú����ˡ�����,�ڳ����͵�ԭ���ж���ķ���,�������Ͷ���Ҳ�Dz��ɼ���,����������Ͷ�ֻ��ʹ�ù��캯��ģʽ����˽��ù��캯���ļ���Ҳ���ٵ���ʹ�á�
-
��ϼ̳�
��ϼ̳�(combination inheritance),��ʱ��Ҳ����α����̳�,ָ���ǽ�ԭ�����ͽ��ù��캯���ļ�����ϵ�һ��,�Ӷ����Ӷ���֮����һ�ּ̳�ģʽ���䱳���˼·��ʹ��ԭ����ʵ�ֶ�ԭ�����Ժͷ����ļ̳�,��ͨ�����ù��캯����ʵ�ֶ�ʵ�����Եļ̳С�����,��ͨ����ԭ���϶��巽��ʵ���˺�������,���ܹ���֤ÿ��ʵ���������Լ������ԡ�
��ϼ̳б�����ԭ�����ͽ��ù��캯����ȱ��,�ں������ǵ��ŵ�,��Ϊ JavaScript ����õļ̳�ģʽ������,instanceof �� isPrototypeOf()Ҳ�ܹ�����ʶ�������ϼ̳д����Ķ�����
ȱ��:����ʲô�����,����������γ������캯��,һ�����ڴ���������ԭ�͵�ʱ��,��һ�������������캯���ڲ��� -
ԭ��ʽ�̳�
����ԭ�Ϳ��Ի������еĶ����¶���,ͬʱ��������˴����Զ������͡�
function object(o){
function F(){};
F.prototype = 0;
return new F();
}
�� object()�����ڲ�,�ȴ�����һ����ʱ�ԵĹ��캯��,Ȼ����Ķ�����Ϊ������캯���� ԭ��,����������ʱ���͵�һ����ʵ�����ӱ����Ͻ�,object()�Դ������еĶ���ִ����һ��dz������
����ԭ��ʽ�̳�,Ҫ����������һ�����������Ϊ��һ������Ļ������������ôһ������Ļ�,���������ݸ� object() ����,Ȼ���ٸ��ݾ�������Եõ��Ķ�������ļ��ɡ�
ECMAScript 5 ͨ������ Object.create(����,(��ѡ)�¶�����������ԵĶ���)�����淶����ԭ��ʽ�̳С�
var person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
var anotherPerson = Object.create(person);
anotherPerson.name = "Greg";
anotherPerson.friends.push("Rob");
var yetAnotherPerson = Object.create(person);
yetAnotherPerson.name = "Linda";
yetAnotherPerson.friends.push("Barbie");
alert(person.friends); //"Shelby,Court,Van,Rob,Barbie"
Object.create()�����ĵڶ���������Object.defineProperties()�����ĵڶ���������ʽ��ͬ:ÿ�����Զ���ͨ���Լ�������������ġ������ַ�ʽָ�����κ����Զ��Ḳ��ԭ�Ͷ����ϵ�ͬ�����ԡ�
ע��:��û�б�Ҫ��ʦ���ڵش������캯��,��ֻ����һ����������һ���������Ƶ������,ԭ��ʽ�̳�����ȫ����ʤ�εġ�����������,������������ֵ������ʼ�ն��Ṳ����Ӧ��ֵ,����ʹ��ԭ��ģʽһ����
ȱ��:������������ֵ������ʼ�ն��Ṳ����Ӧ��ֵ,����ʹ��ԭ��ģʽһ����
- ����ʽ�̳�
����ʽ(parasitic)�̳�����ԭ��ʽ�̳н�����ص�һ��˼·,����ͬ��Ҳ���ɿ��˸����ƶ���֮�ġ�����ʽ�̳���˼·��������캯������ģʽ����,������һ�������ڷ�װ�̳й��̵ĺ���,�ú������ڲ���ij�ַ�ʽ����ǿ����,���������������������й���һ�����ض���
- ����Ҫ���Ƕ���������Զ������ͺ��캯���������,����ʽ�̳�Ҳ��һ�����õ�ģʽ��ǰ��ʾ���̳�ģʽʱʹ�õ� object()�������DZ����;�κ��ܹ������¶���ĺ����������ڴ�ģʽ��
- ʹ�ü���ʽ�̳���Ϊ�������Ӻ���,�����ڲ��������������ö�����Ч��;��һ���빹�캯��ģʽ���ơ�
- �������ʽ�̳�
��Ȼ ��ϼ̳� ����Ϊ��JavaScript ����õļ���ģʽ,������Ȼ��һ������:��������ʲô�����,�������������������캯��:һ�����ڴ���������ԭ�͵�ʱ��,��һ�������������캯���ڲ��������������,����취����ʹ���������ʽ�̳���
�������ʽ�̳�,����ͨ�����ù��캯�����̳�����,ͨ��ԭ�����Ļ����ʽ���̳з������䱳��Ļ���˼·��:����Ϊ��ָ�������͵�ԭ�Ͷ����ó����͵Ĺ��캯��,��������Ҫ���Ǿ��dz�����ԭ�͵�һ���������ѡ�
������,����ʹ�ü���ʽ�̳����̳г����͵�ԭ��,Ȼ���ٽ����ָ���������͵�ԭ�͡�
�������ʽ�̳еĻ���ģʽ������ʾ:
function inheritPrototype(subType, superType){
var prototype = object(superType.prototype); //��������
prototype.constructor = subType; //��ǿ����
subType.prototype = prototype; //ָ������
}
�ŵ�:Ч�ʸ�,ֵ����һ�γ�����ԭ�͵Ĺ��캯��,ԭ�������ܱ��ֲ���,������ʹ��instanceof��isPrototypeOf( )����������ļ̳з�ʽ��
5. ��������ʽ
���庯���ķ�ʽ������:һ������������,��һ�־�����������ʽ��
- ��������
������������������ġ�
function functionName(arg0, arg1, arg2) {
//������
}
������ function �ؼ���,Ȼ���Ǻ���������,�����ָ���������ķ�ʽ��Firefox��Safari��Chrome�� Opera ��������������һ���DZ���name����,ͨ��������Կ��Է��ʵ�������ָ�������֡�������Ե�ֵ��Զ���ڸ��� function �ؼ��ֺ���ı�ʶ����
//ֻ�� Firefox��Safari��Chrome �� Opera ��Ч
alert(functionName.name); //"functionName"
����������һ����Ҫ��������������������(function declaration hoisting),��˼����ִ�д���֮ǰ���ȶ�ȡ���������������ζ�����Ѻ����������ڵ���������������
- ��������ʽ
��������ʽ�м��ֲ�ͬ�����ʽ�������������һ����ʽ��
var functionName = function(arg0, arg1, arg2){
//������
};
������ʽ�����������dz���ı�����ֵ���,������һ��������������ֵ������ functionName����������´����ĺ���������������(anonymous function),��Ϊ function �ؼ��ֺ���û�б�ʶ����(����������ʱ��Ҳ����ķ�ﺯ����)���������� name �����ǿ��ַ�����
��������ʽ����������ʽһ��,��ʹ��ǰ�����ȸ�ֵ��
5.1 �ݹ�
�����ĵݹ�:һ��������ִ�й����е���������
һ������ĵݹ�׳˺���:
function factorial(num){
if (num <= 1){
return 1;
} else {
return num * factorial(num-1);
}
}
��Ȼ����������濴��ûʲô����,������Ĵ���ȴ���ܵ���������:
var anotherFactorial = factorial;
factorial = null;
alert(anotherFactorial(4)); //����!
���ϴ����Ȱ� factorial()���������ڱ��� anotherFactorial ��,Ȼ�� factorial ��������Ϊ null,���ָ��ԭʼ����������ֻʣ��һ�������ڽ��������� anotherFactorial()ʱ,���ڱ���ִ�� factorial(),�� factorial �Ѿ������Ǻ���,���Ծͻᵼ�´��������������,ʹ�� arguments.callee ���Խ��������⡣
arguments.callee ��һ��ָ������ִ�еĺ�����ָ��,��˿���������ʵ�ֶԺ����ĵݹ���á���:
function factorial(num){
if (num <= 1){
return 1;
} else {
return num * arguments.callee(num-1);
}
}
�ӴֵĴ�����ʾ,ͨ��ʹ�� arguments.callee ���溯����,����ȷ�������������ú�������������������,�ڱ�д�ݹ麯��ʱ,ʹ�� arguments.callee �ܱ�ʹ�ú����������ա�
�����ϸ�ģʽ��,����ͨ���ű����� arguments.callee,����������Իᵼ�´�����,����ʹ��������������ʽ�������ͬ�Ľ��������:
var factorial = (function f(num){
if (num <= 1){
return 1;
} else {
return num * f(num-1);
}
});
���ϴ��봴����һ����Ϊ f()��������������ʽ,Ȼ������ֵ������ factorial������Ѻ�����ֵ������һ������,���������� f ��Ȼ��Ч,���Եݹ������������ȷ��ɡ����ַ�ʽ���ϸ�ģʽ�ͷ��ϸ�ģʽ�¶��е�ͨ��
5.2 �հ�
����Ҫ��ȷ�������������ͱհ��Dz�ͬ�ĸ��
�հ���ָ��Ȩ������һ�������������еı����ĺ����������հ��ij�����ʽ,������һ���������ڲ�������һ��������
Ҫ����հ�,��Ҫ�������������ĸ��
��������:��̨��ÿ��ִ�л�������һ����ʾ�����Ķ�����������
Scope����:�������ⲿ�����е�����������
���������ı���:һ��ָ����������ָ���б�,��ֻ���õ���������������
һ��˵��,������ִ����Ϻ�,�ֲ������ͻᱻ����,�ڴ��н�����ȫ��������(ȫ��ִ�л����ı�������)��
����,���ڱհ���˵,�ڱհ���δ����֮ǰ,�����ڵ��ⲿ������ִ����Ϻ�,����ⲿ������ִ�л��������������ᱻ����,������������Ȼ�������ڴ���;ֱ���հ����ٺ�,�հ����ⲿ�����Ļ����Żᱻ������
���ڱհ���Я���������ĺ���������,��˻�ռ�ñ���������������ڴ档����ʹ�ñհ��ᵼ���ڴ�ռ�ù���,���Ǿ��Ա�Ҫ,��Ҫʹ�ñհ���
- �հ������
�����������������û���������һ��������,���հ�ֻ��ȡ�ð����������κα��������һ��ֵ(�հ����������������������,������ij������ı�����)
/*�����᷵��һ����������,ÿ������������ 10��
��Ϊÿ�����������������ж�������createFunctions()�����Ļ����,
�����������õĶ���ͬһ������ i��
�� createFunctions()�������غ�,���� i ��ֵ�� 10,
��ʱÿ�������������ű������ i ��ͬһ������ ����,������ÿ�������ڲ� i ��ֵ���� 10��*/
function createFunctions(){
var result = new Array();
for (var i=0; i < 10; i++){
result[i] = function(){
return i;
};
}
return result;
}
���ǿ���ͨ��������һ����������ǿ���ñհ�����Ϊ����Ԥ��:
/*������һ����������,��������ִ�и����������Ľ���������顣
�ڵ���ÿ����������ʱ,���Ǵ����˱��� i��
���ں��������ǰ�ֵ���ݵ�,���ԾͻὫ���� i �ĵ�ǰֵ���Ƹ����� num��
����������������ڲ�,�ִ�����������һ������ num �ıհ���
����һ��,result �����е�ÿ�����������Լ� num ������һ������,��˾Ϳ��Է��ظ��Բ�ͬ����ֵ�ˡ�*/
function createFunctions(){
var result = new Array();
for (var i=0; i < 10; i++){
result[i] = function(num){
return function(){
return num;
};
}(i);
}
}
- ����this����
�ڱհ���ʹ��this������ܻᵼ��һЩ���⡣
this������������ʱ���ں�����ִ�л�����:
- ��ȫ�ֺ�����,this����window;
- ������������Ϊij������ķ�������ʱ,this�����Ǹ�������
����,����������ִ�л�������ȫ����,�����this����ͨ����ָwindow(����һ���������ʹ�� call() �� apply() �ı��˺���ִ�л���)������ʱ�����ڱ�д�հ��ķ�ʽ��ͬ,��һ����ܲ�����ô���ԡ���:
var name = "this is my name";
var object = {
name: "Ethan",
getNameFunc: function () {
return function () {
return this.name;
};
}
};
alert(object.getNameFunc()()); //this is my name
- ע:alert����ĺ�������������:
��һ������ִ��getNameFunc()����,������һ����������,���û�еڶ������ž����ӡ����������������(��getNameFunc()������return֮�������);
����еڶ�������,˵��ִ������������,����������������ȫ�ֻ�����ִ�е�,��˻���ȫ���в�����Ϊname�����Բ�����,�ھ�����д�ӡ������
Ҫ�����ⲿ�����еĻ����,���ⲿ��������Ҫ����һ����������,������ʹ��this��
argumentsҲ�����,������ڱհ��з����ⲿ�����е�arguments����������һ�����л����е�arguments,�ͰѶ���ʱ�ⲿ������arguments���ñ��浽��һ��������,�ڱհ���ʹ������������ʰ����հ����ⲿ������arguments��
- �ڴ�й©
����IE9֮ǰ�İ汾��Jscript�����COM����ʹ���˲�ͬ��������������,��˱հ���IE��һЩ�Ͱ汾�оʹ���һЩ���⡣������˵,����հ������������б�����һ��HTMLԪ��,��ô����ζ�Ÿ�Ԫ��������������:
function assignHandler(){
var element = document.getElementById("someElement");
element.onclick = function(){
alert(element.id);
};
}
����ķ�����������һ����������հ������õ�ֵ(��������������ѭ������):
function assignElement() {
var element = document.getElementById("someElement");
var id = element.id;
element.onclick = function () {
alert(id);
};
element = null;
}
�����հ����ⲿ�����Ϳ��Խ�element��ֵ��Ϊnull�Ա�����ڴ�,�հ�������ⲿ������
�����element��ֵΪnull,���ջᱻ���ա�
���ǽ���������һ��,����������ڴ�й©�����⡣
5.3 ģ�¿鼶������
JavaScript û�п鼶������ĸ������ζ���ڿ�����ж���ı���,ʵ�������ڰ��������ж�������д����ġ�����:
function outputNumbers(count) {
for(var i=0; i<count; i++) {
alert(i);
}
alert(i); //����
}
// ��������ж�����һ��forѭ��,������i�ij�ʼֵ������Ϊ0����Java��C++��������,����iֻ����forѭ�����������ж���,ѭ��һ������,����i
//�ͻᱻ���١�������JavaScript��,����i�Ƕ�����outputNumbers()�Ļ�����е�,��˴����ж��忪ʼ,�ȿ����ں����ڲ��洦����������ʹ
//�������������ͬһ������,Ҳ����ı�����ֵ��
JavaScript��������������Ƿ���������ͬһ������;�����������,��ֻ��Ժ����������Ӷ�����(����,����ִ�к��������еı�����ʼ��)������������������ģ�¿鼶��������������⡣
�����鼶������(ͨ����Ϊ˽��������)�������������������ʾ:
//�������ú�������ʽ
(function()) {
//�����ǿ鼶������
})();
���ϴ��붨�岢����������һ������������
��������ʽ�ĺ�����Ը�Բ���������,����ͨ����������������һ��Բ���Ž���ת���ɺ�������ʽ��
������ʲô�ط�,ֻҪ��ʱ��ҪһЩ����,�Ϳ���ʹ��˽��������,����:
function outputNumbers(count) {
(function() {
for(var i=0; i<count; i++) {
alert(i);
}
})();
alert(i); //����һ������!
}
���ּ���������ȫ���������б����������ⲿ,�Ӷ�������ȫ�������������ӹ���ı����ͺ�����һ����˵,���Ƕ�Ӧ����������ȫ�������������ӱ����ͺ�������һ���кܶ����Ա��ͬ����Ĵ���Ӧ�ó�����,�����ȫ�ֱ����ͺ�����������������ͻ����ͨ������˽��������,ÿ��������Ա�ȿ���ʹ���Լ��ı���,�ֲ��ص��ĸ���ȫ����������:
<font size=5>(function(){
var now = new Date();
if (now.getMonth() == 0 && now.getDate() == 1){
alert("Happy new year!");
}
})();
// ��������δ������ȫ����������,��������ȷ����һ���� 1 �� 1 ��;���������һ��,�ͻ�����
//����ʾһ��ף���������Ϣ�����еı��� now ���������������еľֲ�����,�����Dz�����ȫ���������д�������
�����������Լ��ٱհ�ռ�õ��ڴ�����,��Ϊû��ָ���������������á�ֻҪ����ִ�����,�Ϳ����������������������ˡ�
5.4 ˽�б���
�ϸ�����,JavaScript ��û��˽�г�Ա�ĸ���;���ж������Զ��ǹ��еġ�����,������һ��˽�б����ĸ���κ��ں����ж���ı���,��������Ϊ��˽�б���,��Ϊ�����ں������ⲿ������Щ������
˽�б������������IJ������ֲ��������ں����ڲ����������������
�����һ�������ڲ�����һ���հ�,��ô�հ�ͨ���Լ�����������Ҳ���Է��ʸú����ڲ��ı�������������һ��,�Ϳ����������ڷ���˽�б����Ĺ��з�����
���ǰ���Ȩ����˽�б�����˽�к����Ĺ��з�����Ϊ��Ȩ����(privileged method)���������ڶ����ϴ�����Ȩ�����ķ�ʽ��
- ��һ�����ڹ��캯���ж�����Ȩ����,����ģʽ����:
function MyObject(){
//˽�б�����˽�к���
var privateVariable = 10;
function privateFunction(){
return false;
}
//��Ȩ����
this.publicMethod = function (){
privateVariable++;
return privateFunction();
};
}
���ģʽ�ڹ��캯���ڲ�����������˽�б����ͺ�����Ȼ��,�ּ����������ܹ�������Щ˽�г�Ա����Ȩ�������ܹ��ڹ��캯���ж�����Ȩ����,����Ϊ��Ȩ������Ϊ�հ���Ȩ�����ڹ��캯���ж�������б����ͺ�������������Ӷ���,���� privateVariable �ͺ��� privateFunction()ֻ��ͨ����Ȩ���� publicMethod()�����ʡ��ڴ��� MyObject ��ʵ����,����ʹ�� publicMethod()��һ��;����,û���κΰ취����ֱ�ӷ���privateVariable �� privateFunction()��
����˽�к���Ȩ��Ա,����������Щ��Ӧ�ñ�ֱ���ĵ�����,����:
function Person (name) {
����this.getName = function () { // ��Ȩ����
��������return name;
����};
����this.setName = function (value) { //��Ȩ����
��������name = value
����}
}
���캯���ж�����Ȩ����Ҳ��һ��ȱ��,���ÿ��ʵ�����ᴴ��ͬ��һ���·���,��ʹ�þ�̬˽�б�����ʵ����Ȩ�������Ա���������⡣
- ��̬˽�б���
ͨ����˽���������ж���˽�б�������,ͬ��Ҳ���Դ�����Ȩ����,�����ģʽ������ʾ:
(function(){
//˽�б�����˽�к���
var privateVariable = 10;
function privateFunction(){
return false;
}
//���캯��
MyObject = function(){
};
//����/��Ȩ����
MyObject.prototype.publicMethod = function(){
privateVariable++;
return privateFunction();
};
})();
���ģʽ������һ��˽��������,�������з�װ��һ�����캯������Ӧ�ķ�������˽����������,���ȶ�����˽�б�����˽�к���,Ȼ���ֶ����˹��캯�����乫�з��������з�������ԭ���϶����,��һ�������˵��͵�ԭ��ģʽ����Ҫע�����,���ģʽ�ڶ��幹�캯��ʱ��û��ʹ�ú�������,����ʹ���˺�������ʽ,��������ֻ�ܴ����ֲ�����������ͬ����ԭ��,����Ҳû�������� MyObject ʱʹ�� var �ؼ��֡���Ϊ��ʼ��δ�������ı���,���ǻᴴ��һ��ȫ�ֱ��������,MyObject �ͳ���һ��ȫ�ֱ���,�ܹ���˽��������֮�ⱻ���ʵ�������,���ϸ�ģʽ�¸�δ�������ı�����ֵ�ᵼ�´�����
���ģʽ���ڹ��캯���ж�����Ȩ��������Ҫ����,������˽�б����ͺ�������ʵ�������ġ�������Ȩ��������ԭ���϶����,�������ʵ����ʹ��ͬһ���������������Ȩ����,��Ϊһ���հ�,���DZ����Ŷ�������������á�
��������������е�һ�����,�ͻ���һ���̶���Ӱ������ٶȡ���������ʹ�ñհ���˽�б�����һ�������IJ���֮����
- ģ��ģʽ
ǰ���ģʽ������Ϊ�Զ������ʹ���˽�б�������Ȩ�����ġ���������˹��˵��ģ��ģʽ(module pattern)����Ϊ��������˽�б�������Ȩ��������ν����(singleton),ָ�ľ���ֻ��һ��ʵ���Ķ��������չ���,JavaScript ���Զ����������ķ�ʽ��������������ġ���:
var singleton = {
name: value,
method : function () {
//�����Ĵ���
}
};
ģ��ģʽͨ��Ϊ��������˽�б�������Ȩ�����ܹ�ʹ��õ���ǿ,�����ʽ����:
var singleton = function(){
//˽�б�����˽�к���
var privateVariable = 10;
function privateFunction(){
return false;
}
//��Ȩ/���з���������
return {
publicProperty: true,
publicMethod : function(){
privateVariable++;
return privateFunction();
}
};
}();
���ģ��ģʽʹ����һ�����ض����������������������������ڲ�,���ȶ�����˽�б����ͺ�����Ȼ��,��һ��������������Ϊ������ֵ���ء����صĶ�����������ֻ�������Թ��������Ժͷ�����������������������������ڲ������,������Ĺ��з�����Ȩ����˽�б����ͺ������ӱ���������,�������������������ǵ����Ĺ����ӿڡ�����ģʽ����Ҫ�Ե�������ijЩ��ʼ��,ͬʱ����Ҫά����˽�б���ʱ�Ƿdz����õġ�
������봴��һ��������ijЩ���ݶ�����г�ʼ��,ͬʱ��Ҫ����һЩ�ܹ�������Щ˽�����ݵķ���,��ô�Ϳ���ʹ��ģ��ģʽ��������ģʽ������ÿ���������� Object ��ʵ��,��Ϊ����Ҫͨ��һ����������������ʾ������ʵ��,��Ҳû��ʲô;�Ͼ�,����ͨ��������Ϊȫ�ֶ�����ڵ�,���Dz��Ὣ�����ݸ�һ�����������,Ҳ��û��ʲô��Ҫʹ��
instanceof���������������������ˡ�
- ��ǿ��ģ��ģʽ
���˽�һ���Ľ���ģ��ģʽ,���ڷ��ض���֮ǰ���������ǿ�Ĵ�����������ǿ��ģ��ģʽ�ʺ���Щ����������ij�����͵�ʵ��,ͬʱ����������ijЩ���Ժ�(��)�������������ǿ���������:
var singleton = function() {
//˽�б�����˽�к���
var privateVariable = 10;
function privateFunction() {
retur false;
}
//��������
var object = new CustomType();
//������Ȩ/�������Ժͷ���
object.publicProperty = true;
object.publicMethod = function() {
privateVariable++;
return privateFunction();
};
//�����������
return object;
}();
���ǰ����ʾģ��ģʽ�������е�application���������BaseComponent��ʵ��,��ô�Ϳ���ʹ�����´��롣
var singleton = function () {
//˽�б���
var privateVariable = 10;
//˽�з���
function privateFunction() {
return false;
}
//��Ȩ��������Ȩ����
return {
publicProperty : true,
publicMethod : function () {
privateVariable++;
return privateFunction();
}
};
}();
C�����ļ�����
1.�������뻺����
1.1������
��C�������,�ӳ����ƽ�,�Ƴ��ֽ�,�����ֽ����ͽ����������������ݵĽ�������������ʽ���еġ�����C�����ļ��Ķ�дʱ,�����Ƚ��С����ļ�������,������������ڴ�������,�����ر��ļ����������ǹر���������
1.2������
�ڳ���ִ��ʱ,���ṩ�Ķ����ڴ�,��������ʱ�����ִ�е����ݡ�����������Ϊ����ߴ�ȡЧ��,��Ϊ�ڴ�Ĵ�ȡ�ٶȱȴ�����������öࡣ
��ʹ�ñ�I/O����(������ͷ�ļ�stdio.h��)ʱ,ϵͳ���Զ����û�����,��ͨ������������д�ļ����������ļ���ȡʱ,���ȴ�������,�������ϵ��ļ���Ϣ��������������,Ȼ������ٴӻ������ж�ȡ�������ݡ���ʵ��,��д���ļ�ʱ,����������д�������,������д�뻺����,ֻ���ڻ����������ر��ļ���ʱ,�ŻὫ����д����̡�
2.�ļ�����
�ı��ļ��Ͷ������ļ�:
�ı��ļ������ַ�����ķ�ʽ���б���ġ�
�������ļ����ڴ��е�����ԭ�ⲻ���Ľ��б���,�����ڷ��ַ�Ϊ�������ݡ���ʵ,���е����ݶ��������Ƕ������ļ����������ļ����ŵ����ڴ�ȡ�ٶȿ�,ռ�ÿռ�С��
3.�ļ���ȡ��ʽ
˳���ȡ��ʽ�������ȡ��ʽ:
˳���ȡ���Ǵ�������,һ��һ�ʶ�ȡ�ļ������ݡ�д������ʱ,�����ݸ������ļ���ĩβ�����ִ�ȡ��ʽ�������ı��ļ���
�����ȡ��ʽ����Զ������ļ�Ϊ����������һ�������ĵ�λ���������ݵĶ�ȡ��д��,ͨ���ԽṹΪ��λ��
4. �ļ���������
C������û������������,���е�����������ܶ��� ANSI C�ṩ��һ����⺯����ʵ�֡��ļ��������⺯����:
- �ļ��Ĵ�
fopen():���ļ� - �ļ��Ĺر�
fclose():�ر��ļ� - �ļ��Ķ�д
fgetc():��ȡһ���ַ�
fputc():д��һ���ַ�
fgets():��ȡһ���ַ���
fputs():д��һ���ַ���
fprintf():д���ʽ������
fscanf():��ʽ����ȡ����
fread():��ȡ����
fwrite():д������ - �ļ�״̬���
feof():�ļ��Ƿ����
ferror():�ļ���/д�Ƿ����
clearerr():����ļ������־
ftell():�ļ�ָ��ĵ�ǰλ�� - �ļ�ָ�붨λ
rewind():���ļ�ָ���Ƶ���ʼ��
fseek():�ض�λ�ļ�ָ��
��������:
��r��:��ֻ������ʽ���ı��ļ�(�����������)
��w��:��ֻд����ʽ���ı��ļ�(�����������½�,��֮,����ļ���ʼλ��д,����ԭ����)
��a��:���ӵ���ʽ���ı��ļ�(��������,���½�;��֮,��ԭ�ļ�����)
��r+��:�Զ�д����ʽ���ı��ļ�(��ʱ,��ͷ��ʼ;дʱ,������ֻ������ռ�Ŀռ�) ��wb��:��ֻд����ʽ�������ļ�
��rb��:��ֻ������ʽ�������ļ�
��ab��:���ӵ���ʽ��һ���������ļ�
��rb+��:�Զ�д����ʽ�������ļ���
��w+��:���Ƚ���һ�����ļ�,����д����,Ȼ���ͷ��ʼ��(���ļ�����,ԭ���ݽ�ȫ����ʧ)
��a+��:�����롱a����ͬ��ֻ�����ļ�β�������ݺ�,���Դ�ͷ��ʼ��
��wb+��:�����롱w+����ͬ��ֻ���ڶ�дʱ,������λ�ú������ö���д����ʼλ��
��ab+��:�����롱a+����ͬ��ֻ�����ļ�β��������֮��,������λ�ú������ÿ�ʼ������ʼλ��
- ���ļ�
FILE *fopen( const char *filename, const char *mode );
filename:�ļ���·��
mode:��ģʽ
��:
int main()
{
FILE* f;
f = fopen("file.txt", "w");
if (f != NULL)
{
fputs("fopen example", f);
fclose(f);
f=NULL;
}
return 0;
}
ע��:
�ļ��Ƿ�ɹ�
�ر��ļ�
�ļ�ָ���ÿ�
- �ر��ļ�
����ԭ��:int fclose( FILE *stream );
stream:��
��:
if(fclose(f)!=0)
{
printf("File cannot be closed/n");
exit(1);
}
else
{
printf("File is now closed/n");
}
- ��ȡ�ַ�
int fgetc ( FILE * stream );
stream:��
��:
#include <stdio.h>
int main ()
{
FILE * pFile;
int c;
int n = 0;
pFile = fopen ("D:\\myfile.txt", "r");
if (pFile == NULL) perror ("Error opening file"); // ��ʧ��
else
{
while (c != EOF)
{
c = fgetc (pFile); // ��ȡһ���ַ�
if (c == '$') n++; // ͳ����Ԫ���� '$' ���ļ��г��ֵĴ���
}
fclose (pFile); // һ���ǵ�Ҫ�ر��ļ�
printf ("The file contains %d dollar sign characters ($).\n",n);
}
return 0;
}
- д���ַ�
int fputc( int c, FILE *stream );
c:Ҫд����ַ�
stream:��
��:
char ch;
FILE* pf = fopen("file.txt", "w");
if (pf == NULL)
{
perror("error opening file");
exit(0);
}
ch = getchar();
while (ch != '$')
{
fputc(ch, pf);
ch = getchar();
}
fclose(pf);
- ��ȡ�ַ���
char * fgets ( char * str, int num, FILE * stream );
str:����ȡ�������ݸ��Ƶ���Ŀ���ַ���
num:һ�ζ�ȡ�Ĵ�С
stream:��
��:
char buf[10] = { 0 };
FILE *pf = fopen("file.txt", "r");
if (pf == NULL)
{
perror("open file for reading");
exit(0);
}
fgets(buf, 9, stdin);
printf("%s", buf);
fclose(pf);
- д���ַ���
int fputs( const char *string, FILE *stream );
string:Ҫд����ַ���
stream:һ�ζ�ȡ�Ĵ�С
��:
char buf[10] = { 0 };
FILE *pf = fopen("file.txt", "r");
if (pf == NULL)
{
perror("open file for reading");
exit(0);
}
fgets(buf, 9, stdin);
fputs(buf, stdout);
fclose(pf);
- ��ȡ���ݿ�
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
ptr:Ŀ���ڴ��
size:һ�ζ�ȡ���ֽڴ�С
count:һ�ζ�ȡ���ٸ� size
stream:��
��:
#include <stdio.h>
#include <string.h>
int main()
{
FILE *pFile = fopen("file.txt", "rb");
if (pFile == NULL)
{
perror ("Error opening file");
return 0;
}
char buf[100] = { 0 };
while (!feof(pFile)) //û�е��ļ�ĩβ
{
memset(buf, 0, sizeof(buf));
size_t len = fread(buf, sizeof(char), sizeof(buf), pFile);
printf("buf: %s, len: %d\n", buf, len);
}
fclose(pFile);
}
-
д�����ݿ�
size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
ͬ��,������,�Ͳ���ϸ�����ˡ� -
�ļ�ָ���ض�λ
int fseek ( FILE * stream, long int offset, int origin );
stream:��
offset:���Ӧ origin λ�ô���ƫ����,��λΪ�ֽ�
origin:ָ���λ��
#define SEEK_CUR 1 // ��ǰλ��
#define SEEK_END 2 // ĩβ
#define SEEK_SET 0 // ��ͷ -
��ȡָ��λ��
long int ftell ( FILE * stream );
stream:�� -
��ȡ�ļ���С
��:
long n;
fseek(pf,0,SEEK_END);
n=ftell(pf);
- �ļ�ָ���Ƶ���ʼ��
void rewind( FILE *stream );
stream:�� - ����ļ������־
void clearerr( FILE *stream );
stream:�� - �ļ����Ƿ�������ļ�β
int feof( FILE *stream );
stream:�� - �������ļ�
int rename ( const char * oldname, const char * newname );
oldname:ԭ��
newname:���� - ɾ���ļ�
int remove ( const char * filename );
filename:�ļ���·��