�������ʽ
�������ʽ(Regular Expression)��һ���ı�ģʽ,������ͨ�ַ�(����,a �� z ֮�����ĸ)�������ַ�(��Ϊ"Ԫ�ַ�")
�������ʽʹ�õ����ַ�����������ƥ��һϵ��ƥ��ij���䷨������ַ���,�����������һ�����Ƿ���ij���Ӵ�����ƥ����Ӵ��滻���ߴ�ij������ȡ������ij���������Ӵ���
ʹ���������ʽ������
- �����ַ����ڵ�ģʽ
����,���Բ��������ַ���,�Բ鿴�ַ������Ƿ���ֵ绰����ģʽ�����ÿ�����ģʽ�����Ϊ������֤ - �滻�ı�
����ʹ���������ʽ��ʶ���ĵ��е��ض��ı�,��ȫɾ�����ı������������ı��滻�� - ����ģʽƥ����ַ�������ȡ���ַ���
���Բ����ĵ��ڻ����������ض����ı�
-�
�����������ʽ���������ö���Ԫ�ַ�����������Խ�С�ı���ʽ�����һ������������ı���ʽ��
���:�������ַ����ַ����ϡ��ַ���Χ���ַ����ѡ�����������Щ������������
��ͨ�ַ�
����û����ʽָ��ΪԪ�ַ������пɴ�ӡ�Ͳ��ɴ�ӡ�ַ�����������д�д��Сд��ĸ���������֡����б����ź�һЩ��������
| �ַ� | ���� |
|---|---|
| [ABC] | ƥ��[����]�е������ַ� |
| [^ABC] | ƥ�����[����]���ַ��������ַ� |
| [A-Z] | -��ʾһ������,ƥ�����д�д��ĸ |
| . | ƥ������з�(\n��\r)֮����κε����ַ�,�ȼ���[^\n \r] |
| [\s\S] | ƥ������ \s��ƥ�����пհ��ַ��������� \S�ǿհ�,���������� |
| \w | ƥ�����֡���ĸ���»��� �ȼ���[a-zA-Z0-9]! |
| \d | ƥ������ |
�Ǵ�ӡ�ַ�
| �ַ� | ���� |
|---|---|
| \cx | ƥ����xָ���Ŀ����ַ�������, \cM ƥ��һ�� Control-M ��س�����x ��ֵ����Ϊ A-Z �� a-z ֮һ������,�� c ��Ϊһ��ԭ��� ��c�� �ַ� |
| \f | ƥ��һ����ҳ�����ȼ��� \x0c �� \cL |
| \n | ƥ��һ�����з����ȼ��� \x0a �� \cJ |
| \r | ƥ��һ���س������ȼ��� \x0d �� \cM |
| \s | ƥ���κοհ��ַ�,�����ո��Ʊ�������ҳ���ȵȡ��ȼ��� [ \f\n\r\t\v] |
| \S | ƥ���κηǿհ��ַ����ȼ��� [^ \f\n\f\t\v] |
| \t | ƥ��һ���Ʊ������ȼ��� \x09 �� \cI�� |
| \v | ƥ��һ����ֱ�Ʊ������ȼ��� \x0b �� \cK��[\w]+,\w+,[\w+] �������� |
�����ַ�
һЩ�����⺬����ַ�,������˵��runoo\*b�е�*,��˵���DZ�ʾ�κ��ַ�������˼,���Ҫ�����ַ����е������ַ�,����Ҫ�����ǽ���ת��,������ǰ��һ��\
| �����ַ� | ���� |
|---|---|
| $ | ƥ�������ַ����Ľ�βλ�á���������� RegExp ����� Multiline ����,�� $ Ҳƥ�� ��\n�� �� ��\r����Ҫƥ�� $ �ַ�����,��ʹ�� $ |
| () | ���һ���ӱ���ʽ�Ŀ�ʼ�ͽ���λ�á��ӱ���ʽ���Ի�ȡ���Ժ�ʹ�á�Ҫƥ����Щ�ַ�,��ʹ�� ( �� ) |
| * | ƥ��ǰ����ӱ���ʽ��λ�����Ҫƥ�� * �ַ�,��ʹ�� * |
| + | ƥ��ǰ����ӱ���ʽһ�λ�����Ҫƥ�� + �ַ�,��ʹ�� + |
| . | ƥ������з� \n ֮����κ����ַ���Ҫƥ�� . ,��ʹ�� . |
| [ | ���һ�������ű���ʽ�Ŀ�ʼ��Ҫƥ�� [,��ʹ�� [ |
| ? | ƥ��ǰ����ӱ���ʽ��λ�һ��,��ָ��һ����̰��������Ҫƥ�� ? �ַ�,��ʹ�� ? |
| \ | ����һ���ַ����Ϊ�������ַ�����ԭ���ַ�����������á���˽���ת���������, ��n�� ƥ���ַ� ��n������\n�� ƥ�任�з������� ��\�� ƥ�� ����,�� ��(�� ��ƥ�� ��(�� |
| ^ | ƥ�������ַ����Ŀ�ʼλ��,�����ڷ����ű���ʽ��ʹ��,���÷����ڷ����ű���ʽ��ʹ��ʱ,��ʾ�����ܸ÷����ű���ʽ�е��ַ����ϡ�Ҫƥ�� ^ �ַ�����,��ʹ�� ^ |
| { | �����������ʽ�Ŀ�ʼ��Ҫƥ�� {,��ʹ�� { |
| | | ָ������֮���һ��ѡ��Ҫƥ��|,��ʹ��| |
����
����ָ���������ʽ��һ�������������Ҫ���ֶ��ٴβ�������ƥ�䡣�� ***** �� + �� ? �� {n} �� {n,} �� {n,m} ��6��
| �ַ� | ���� |
|---|---|
| * | ƥ��ǰ����ӱ���ʽ��λ���������,zo* ��ƥ�� ��z�� �Լ� ��zoo����* �ȼ���{0,} |
| + | ƥ��ǰ����ӱ���ʽһ�λ���������,��zo+�� ��ƥ�� ��zo�� �Լ� ��zoo��,������ƥ�� ��z����+ �ȼ��� {1,} |
| ? | ƥ��ǰ����ӱ���ʽ��λ�һ��������,��do(es)?�� ����ƥ�� ��do�� �� ��does�� �е� ��does�� �� ��doxy�� �е� ��do�� ��? �ȼ��� {0,1} |
| {n} | n ��һ���Ǹ�������ƥ��ȷ���� n ��������,��o{2}�� ����ƥ�� ��Bob�� �е� ��o��,������ƥ�� ��food�� �е����� o |
| {n,} | n ��һ���Ǹ�����������ƥ��n ��������,��o{2,}�� ����ƥ�� ��Bob�� �е� ��o��,����ƥ�� ��foooood�� �е����� o����o{1,}�� �ȼ��� ��o+������o{0,}�� ��ȼ��� ��o*�� |
| {n,m} | m �� n ��Ϊ�Ǹ�����,����n <= m������ƥ�� n �������ƥ�� m ��������,��o{1,3}�� ��ƥ�� ��fooooood�� �е�ǰ���� o����o{0,1}�� �ȼ��� ��o?������ע���ڶ��ź�������֮�䲻���пո� |
����
/[1-9][0-9]*/
//���������ڷ��ű���ʽ֮��,Ӧ����������Χ����ʽ
ƥ��һ��������,[1-9]���õ�һ�����ֲ��� 0,[0-9]* ��ʾ����������
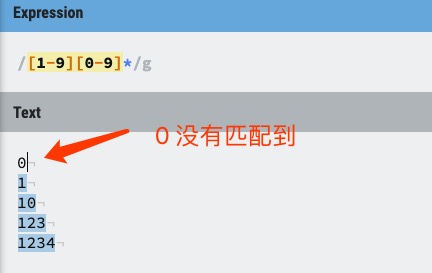
˼��:ƥ��1~99������������ʽ
***�� + ��������̰����,��Ϊ���ǻᾡ���ܶ��ƥ������,ֻ�������ǵĺ������һ�� ? �Ϳ���ʵ�ַ�̰������Сƥ��
̰�����̰��ģʽ���
���
��λ��ʹ���ܹ����������ʽ�̶���������β�����ǻ�ʹ���ܹ������������������ʽ,��Щ�������ʽ������һ�������ڡ���һ�����ʵĿ�ͷ����һ�����ʵĽ�β��
��λ�����������ַ����ʵı߽�
| �ַ� | ���� |
|---|---|
| ^ | ƥ�������ַ�����ʼ��λ�á���������� RegExp ����� Multiline ����,^ ������ \n �� \r ֮���λ��ƥ�� |
| $ | ƥ�������ַ�����β��λ�á���������� RegExp ����� Multiline ����,$ ������ \n �� \r ֮ǰ��λ��ƥ�� |
| \b | ƥ��һ�����ʱ߽�,������ո���λ�� |
| \B | �ǵ��ʱ߽�ƥ�� |
ע:
- ���ܽ������붨λ��һ��ʹ��(�ڽ������л��ߵ��ʱ߽��ǰ�����治����һ������λ��)
- ��Ҫƥ��һ���ı���ʼ�����ı�,�����������ʽ�Ŀ�ʼʹ�� ^ �ַ���
- ��Ҫƥ��һ���ı��Ľ��������ı�,�����������ʽ�Ľ�����ʹ�� $ �ַ���
ѡ��
��Բ���� () ������ѡ����������,���ڵ�ѡ����֮���� | �ָ���
() ��ʾ�������,() ���ÿ���������ƥ���ֵ��������, ���ƥ��ֵ����ͨ������ n ���鿴(n ��һ������,��ʾ�� n �������������)
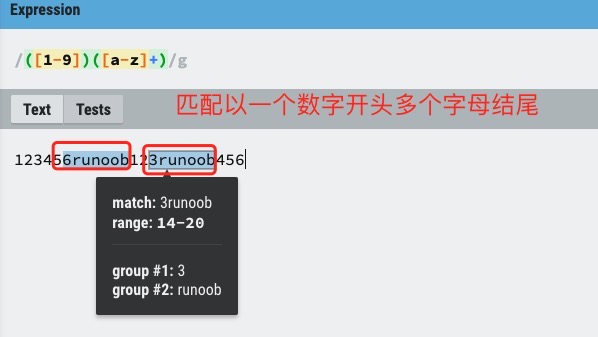

����Բ���Ż���һ��������,ʹ��ص�ƥ��ᱻ����,��ʱ���� ?: ���ڵ�һ��ѡ��ǰ���������ָ����á�
���� ?: �ǷDz���Ԫ֮һ,���������Dz���Ԫ�� ?= �� ?!,���������и���ĺ���,ǰ��Ϊ����Ԥ��,���κο�ʼƥ��Բ�����ڵ��������ʽģʽ��λ����ƥ�������ַ���,����Ϊ����Ԥ��,���κο�ʼ��ƥ����������ʽģʽ��λ����ƥ�������ַ���
| (?:pattern) | ƥ�� pattern ������ȡƥ����,Ҳ����˵����һ���ǻ�ȡƥ��,�����д洢���Ժ�ʹ�á�����ʹ�� ���� �ַ� (|)�����һ��ģʽ�ĸ��������Ǻ�����
| ----------- | ------------------------------------------------------------ |
?=��?<=��?!��?<! ��ʹ������
- exp1(?=exp2):���� exp2 ǰ��� exp1
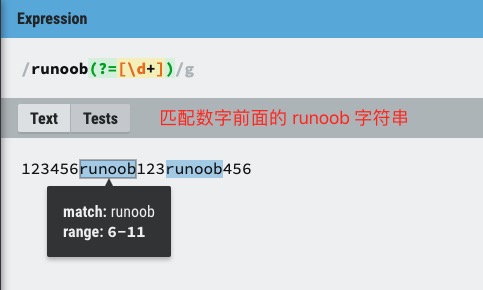
- (?<=exp2)exp1:���� exp2 ����� exp1��
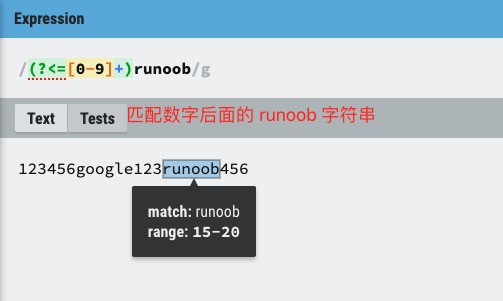
- exp1(?!exp2):���Һ��治�� exp2 �� exp1
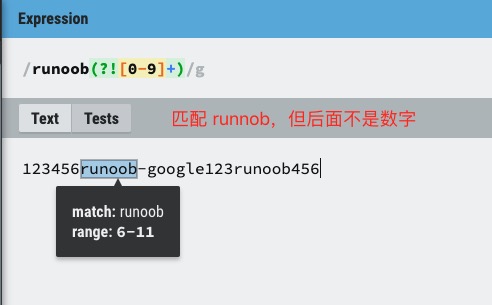
- (?<!exp2)exp1:����ǰ�治�� exp2 �� exp1
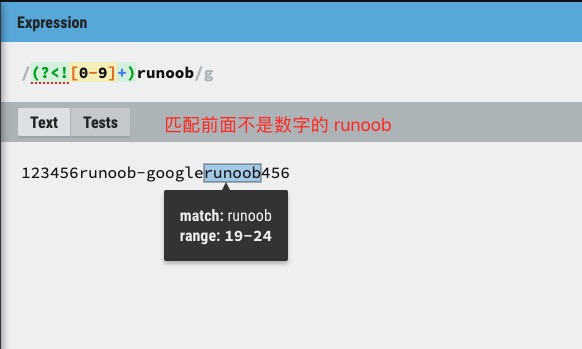
��������
��һ���������ʽģʽ��ģʽ��������Բ���Ž��������ƥ��洢��һ����ʱ��������,�������ÿ����ƥ�䶼�������������ʽģʽ�д����ҳ��ֵ�˳��洢����������Ŵ� 1 ��ʼ,���ɴ洢 99 ��������ӱ���ʽ��ÿ��������������ʹ�� \n ����,���� n Ϊһ����ʶ�ض���������һλ����λʮ��������
����ʹ�÷Dz���Ԫ�ַ� ?:��?= �� ?! ����д����,���Զ����ƥ��ı��档
Ӧ��:�ṩ�����ı���������ͬ�����ڵ��ʵ�ƥ���������
var str = "Is is the cost of of gasoline going up up";
var patt1 = /\b([a-z]+) \1\b/ig;
document.write(str.match(patt1));
����:
����ı���ʽ,���� [a-z]+ ָ����,����һ��������ĸ���������ʽ�ĵڶ������Ƕ���ǰ�������ƥ���������,��,���ʵĵڶ���ƥ�������������ű���ʽƥ�䡣\1 ָ����һ����ƥ���
���ʱ߽�Ԫ�ַ�ȷ��ֻ����������ʡ�����,���� ��is issued�� �� ��this is�� ֮��Ĵ��齫������ȷ�ر��˱���ʽʶ��
�������ʽ�����ȫ�ֱ�� g ָ�����ñ���ʽӦ�õ������ַ������ܹ����ҵ��ľ����ܶ��ƥ�䡣
����ʽ�Ľ�β���IJ����ִ�Сд i ���ָ�������ִ�Сд��
���б��ָ�����з������߿��ܳ���DZ�ڵ�ƥ��
˼��:
������� URI �ֽ�ΪЭ��(ftp��http �ȵ�)�����ַ��ҳ/·��:�������
http://www.runoob.com:80/html/html-tutorial.html
-���η�(���)
����ָ�������ƥ�����
��Dz�ж���������ʽ��,λ�ڱ���ʽ֮��,��ʽ����
/pattern/flags
| �������η� | ���� | ���� |
|---|---|---|
| i | ignore-�����ִ�Сд | ��ƥ������Ϊ�����ִ�Сд,����ʱ�����ִ�Сд: A �� a û������ |
| g | global-ȫ��ƥ�� | �������е�ƥ���� |
| m | multi line-����ƥ�� | ʹ�߽��ַ� ^ �� $ ƥ��ÿһ�еĿ�ͷ�ͽ�β,��ס�Ƕ���,�����������ַ����Ŀ�ͷ�ͽ�β gֻƥ���һ������m֮��ʵ�ֶ��� |
| s | �����ַ�Բ��**.**�а������з�\n | Ĭ������µ�Բ�� . �� ƥ������з� \n ֮����κ��ַ�,���� s ���η�֮��, . �а������з� \n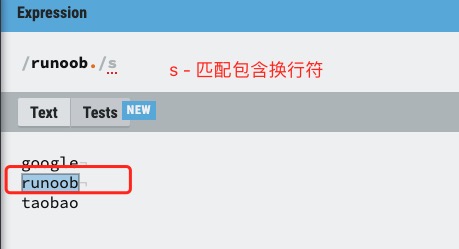 |
-Ԫ�ַ�
-��������ȼ�
| ����� | ���� |
|---|---|
| ת��� | |
| Բ���źͷ����� | |
| ���� | |
| ��λ�������(λ�ú�˳��) | |
| �滻,������ �ַ����и����滻����������ȼ�,ʹ��"m|food"ƥ��"m"��"food"����Ҫƥ��"mood"��"food",��ʹ�����Ŵ����ӱ���ʽ,�Ӷ�����"(m|f)ood" |
-ƥ�����
ģʽ,���������ʽ�������Ԫ��,������һ�������ַ����������ַ���
^,��ʾ��ģʽֻƥ����Щ�Ը���ģʽ��ͷ���ַ���
$ ��������ƥ����Щ�Ը���ģʽ��β���ַ���
�ַ� ^ �� $ ͬʱʹ��ʱ,��ʾ��ȷƥ��(�ַ�����ģʽһ��)
�ַ���
�������ʽ��,ͨ��һ�Է�����������������,�ͳ�֮Ϊ���ַ��ء�,���ʾ����һ����Χ,����ʵ��ƥ��ʱ,ֻ��ƥ��̶���ij���ַ��� ��������ָ���������ʽ��һ�������������Ҫ���ֶ��ٴβ�������ƥ��
[a-z] // ƥ�����е�Сд��ĸ
[A-Z] // ƥ�����еĴ�д��ĸ
[a-zA-Z] // ƥ�����е���ĸ
[0-9] // ƥ�����е�����
[0-9\.\-] // ƥ�����е�����,��źͼ���
[ \f\r\t\n] // ƥ�����еİ��ַ�
//����
[^a-z] //�ų�Сд��Ŀ�����������ĸ
^[^0-9][0-9]$ //��һ���ַ�����������
ȷ���ظ�����
�ڸ���������,���ǿ���Ҫƥ��һ�����ʻ�һ�����֡�һ�����������ɸ���ĸ���,һ�����������ɸ�������ɡ������ַ����ַ��غ����������({})����ȷ��ǰ������ݵ��ظ����ֵĴ���
^[[:alpha:]]{3}$ //���е�3����ĸ�ĵ���
^a{2,4}$ //aa,aaa��aaaa
^a{2,}$ //������������a���ַ���
.{2} //���е������ַ�
\t{2} //�����Ʊ���
^[a-zA-Z0-9_]{1,}$ // ���а���һ�����ϵ���ĸ�����ֻ��»��ߵ��ַ���
^[1-9][0-9]{0,}$ // ���������
^\-{0,1}[0-9]{1,}$ // �������
^[-]?[0-9]+\.?[0-9]+$ // ���еĸ�����
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Mobh7x2h-1632059988206)(C:\Users\86153\AppData\Roaming\Typora\typora-user-images\image-20210919172542793.png)]
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-N98dINxc-1632059988206)(C:\Users\86153\AppData\Roaming\Typora\typora-user-images\image-20210919172831093.png)]
�����ַ� ? �� {0,1} ����ȵ�,���Ƕ�������: 0����1��ǰ������� �� ǰ��������ǿ�ѡ��
�����ַ� ***** �� {0,} ����ȵ�,���Ƕ������� 0 ������ǰ�������
�����ַ� + �� {1,} ����ȵ�,��ʾ 1 ������ǰ�������
һЩʾ��
����(capture group)�ͷ�������
����C() �����()������ݻᱻ����һ������������
������:
���������ʽ���ӱ���ʽƥ�������,���浽�ڴ��������ֱ�Ż���ʽ����������,����������èC��������(�������ʽ�ڲ����ⲿ)��
һ��ʹ���ˡ�()"�ͻ�Ĭ���Dz����鲢��()����ʽƥ������ݲ���
��Ź���:���������Է����������Ϊ��־,��һ�����ֵķ������Ϊ1,�Դ����ơ�ע:��0��Զ������������������ʽ
�Dz�����:
��������ڵĸ�����:���ò���"()"��������ϵƥ�������Ҳ�������ò�������,����¼��Щ�������ռ���ڴ潵��ƥ��Ч��
��˷Dz�������������Ϊ�˵������ָ����èCֻ���з�����������ӱ���ʽƥ�䵽�����ݲ�������
�� (?) ��ͷ�����ǷDz�����,���������ı� Ҳ�������ϼƽ��м�����
��������
��Բ����鲶���䵽���ڵ�����,ÿ���齫���Զ��ط���һ��������ڴ�������ı���ʽ,(��ŵı��ƹ��������👆)�����������ṩ�����ظ��ַ���ķ���ķ���,���ǿɱ���Ϊ���ٴ�ƥ��ͬһ���ַ��������ָ��
(boy)\1 //�൱��(boy)(boy),ƥ��boyboy
(boy)(girl)\1\2 //ƥ��boygirlboygirl
//�Ա�(\w)\1�͵�����:
(\w)\1 //������ƥ����dz������ε��ַ�,\1���ظ�ƥ��(\w)���ֵ�����!����ƥ��aa��bb
(\w)(\w) //������ֻ�Ǽ�ƥ�������ַ�,����ƥ��ab,aa�ȡ�ע������!
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-nZbB3zOv-1632059988207)(C:\Users\86153\AppData\Roaming\Typora\typora-user-images\image-20210919201413284.png)]
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-RZTSCn1x-1632059988208)(C:\Users\86153\AppData\Roaming\Typora\typora-user-images\image-20210919201437714.png)]
���ж���(lookahead)�ͺ��ж���(loodbehind)
�������ʽ�����ж��Ժͺ��ж���һ���� 4 ����ʽ:
- (?=pattern) ������������(zero-width positive lookahead assertion)
- (?!pattern) ������������(zero-width negative lookahead assertion)
- (?<=pattern) �����������(zero-width positive lookbehind assertion)
- (?<!pattern) �����������(zero-width negative lookbehind assertion)
��ͬ ^ ������ͷ,$ ������β,\b �������ʱ߽�һ��,���ж��Ժͺ��ж���Ҳ�����Ƶ�����,����ֻƥ��ijЩλ��,��ƥ�������,��ռ���ַ�,���Ա���Ϊ**�������**����νλ��,��ָ�ַ�����(ÿ��)��һ���ַ�����ߡ����һ���ַ����ұ��Լ������ַ����м�(�������ַ�����ͷ��β��)
(?=pattern) �������ж��� �����ַ����е�һ��λ��,���Ӹ�λ��֮����ַ������ܹ�ƥ�� pattern��
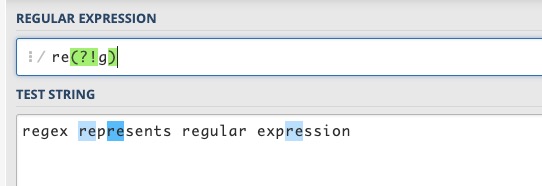
**re(?=gular)**���� re �ұߵ�λ��,���λ��֮���� gular,���������� gular ��Щ�ַ�
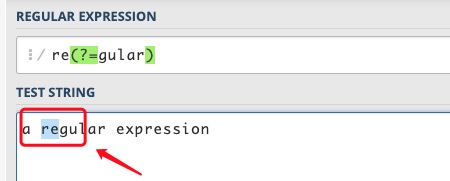
(?!pattern) �������ж��� ������(?=pattern)👆
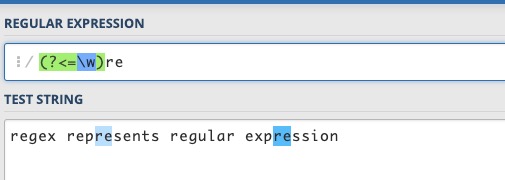
(?<=pattern) ������ж��� �����ַ����е�һ��λ��,���Ӹ�λ��֮ǰ���ַ������ܹ�ƥ�� pattern
֮���Խк��ж���,����Ϊ�������ʽ������ƥ���ַ����ͱ���ʽʱ,����ǰ������ɨ���ַ����е��ַ�,���ж��Ƿ������ʽ����,���ڱ���ʽ�������ö���ʱ,�������ʽ������Ҫ���ַ���ǰ�˼����ɨ������ַ�,�����ɨ�跽��������
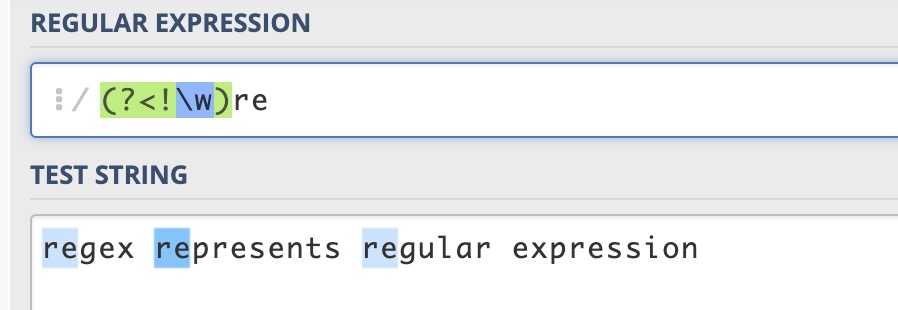
(?<!pattern) ������ж���������(?<=pattern)👆
���������
�������ʽ������ִ���ַ����ͱ���ʽƥ��ʱ�Ǵ�ǰ��������ɨ��ġ�������һ��ɨ��ָ��ֻ���ַ��߽紦����ƥ������ƶ�����ɨ�赽���ж���ʱ,���波��ƥ��ָ��δɨ�����ַ�,����ָ��;���ж���,����ƥ��ָ���Ѿ�ɨ�����ַ�,����ָ�뵽����ַ���
�����뷴��
����ʾƥ�������еı���ʽ,������ƥ�䡣
Wm-1632059988211)]
(?<!pattern) ������ж���������(?<=pattern)👆
[����ͼƬת���С�(img-VAvQcatV-1632059988214)]
���������
�������ʽ������ִ���ַ����ͱ���ʽƥ��ʱ�Ǵ�ǰ��������ɨ��ġ�������һ��ɨ��ָ��ֻ���ַ��߽紦����ƥ������ƶ�����ɨ�赽���ж���ʱ,���波��ƥ��ָ��δɨ�����ַ�,����ָ��;���ж���,����ƥ��ָ���Ѿ�ɨ�����ַ�,����ָ�뵽����ַ���
�����뷴��
����ʾƥ�������еı���ʽ,������ƥ�䡣