#(����)ʲô�ǡ�use strict��,�ô��ͻ���
use ��strict��: "�ϸ�ģʽ"��һ����JavaScript��������ʱ�Զ�ʵ�и��ϸ�����ʹ������ķ�����
�ŵ�:
- ����Javascript���һЩ�����������Ͻ�֮��,����һЩ������Ϊ;
- �����������е�һЩ����ȫ֮��,��֤�������еİ�ȫ;
- ��߱�����Ч��,���������ٶ�;
- Ϊδ���°汾��Javascript�����̵档
ȱ��:
������վ�� JS �������ѹ��,һЩ�ļ������ϸ�ģʽ,����һЩû�С���ʱ��Щ�������ϸ�ģʽ���ļ�,�� merge ��,����ַ���(��use strict��)�͵����ļ����м�,����û��ָʾ�ϸ�ģʽ,������ѹ�����˷����ֽڡ�
#(����)console.log(0.1 + 0.2)
0.1+0.2�Ľ������0.3,����0.3000000000000000004,JS�������������ʱ���Զ�������ʽ���е�,��ʮ����С���Ķ����Ʊ�ʾ���������ֳ���52λʱ,��JS���Dz��ܾ�ȷ�����,���ʱ��ʹ���������
#(����)����pop(), push(), unshift(), shift()������
push()���������������ĩ������һ������Ԫ��shift()�����������еĵ�һ��Ԫ��ɾ��unshift()���������������ǰ������һ������Ԫ��pop()�����������е����һ��Ԫ��ɾ��
#(����)��=
- ==:ֻ�DZȽ�ֵ
- ===:��Ҫ�Ƚ��������ͻ�Ҫ�Ƚ�ֵ
#(����)�¼�ð�ݺ��¼������к�����?
- �¼�ð��:�������ϡ���������Ԫ�ص�ͬһ�¼�������ʱ��,������Ԫ�����ϵ��¼�,ִ�����֮��,Ҳ�ᴥ������Ԫ����ͬ���¼���
ע��: addEventListener������������,�����������Dz���ֵ��falseΪ�¼�ð��,trueΪ�¼�����
- �¼�����:�������µ�ָ��Ԫ�ء���������Ԫ�����ϵ��¼�ʱ,�ȴ�����Ԫ��,Ȼ���ڴ��ݸ���Ԫ��
#(����)JS��������
��ES5��ʱ��,������֪����������ȷʵ�� 6��:Number��String��Boolean��undefined��object��Null��
ES6 ��������һ�� Symbol ���������͵Ķ����������,��ʼ������ʱ������ͬ��ֵ,���Խ����������ͻ������,��Ϊ��ǡ�
#(����)ʲô��typescript
- 1.����JavaScript��һ������,���ұ�������������������˿�ѡ�ľ�̬���ͺͻ��������������̡�
- 2.
TypeScript��չ��JavaScript���,�����κ����е�JavaScript������Բ��Ӹı����TypeScript�¹�����TypeScript��Ϊ����Ӧ��֮���������,������ʱ������ JavaScript ��ȷ�������ԡ�
#(����)ʲô��ģ�黯���?
ÿ��ģ���ڲ�,module����������ǰģ�顣
���������һ������,����exports����(��module.exports)�Ƕ���Ľӿڡ�����ij��ģ��,��ʵ�Ǽ��ظ�ģ���module.exports���ԡ�
#(����)����javascriptԭ�͡�ԭ����?��ʲô�ص�
ԭ��:ÿһ�����캯������һ��prototype����ָ��һ������,���������ǹ��캯��ʵ����ԭ��
ԭ����:ÿһ��ʵ������һ��__proto__����ִ��ԭ�Ͷ���,����ȡԭ�Ͷ����ϵ����Ժͷ���,ԭ�Ͷ���Ҳ��һ��__proto
����ָ������һ��ԭ�Ͷ���,�Դ�����,ֱ��ԭ���������ն�nullΪֹ,����������Ĺ��̾���ԭ����
�ص�:ʵ�ּ̳� һ����������õ���һ�������ϵ����Ժͷ���
���캯������һ��prototype����ָ��ԭ�Ͷ���
ԭ�Ͷ�����һ��consttuctor����ָ���캯��
���캯��newʵ����ʵ������
ʵ����������__proto����ָ��ԭ��
#(����)����javascript�е�������ͱ�����������
��������ָ����Դ�����ж������������������涨����β��ұ���,Ҳ����ȷ����ǰִ�д���Ա����ķ���Ȩ�ޡ�
������������:
foo; // undefined
var foo = function () {
console.log('foo1');
}
foo(); // foo1,foo��ֵ
���������:���е�����(�����ͺ���)���ᱻ���ƶ������������������ˡ�
#(����)̸̸this���������,call()��apply()������
call��apply���������ڴ�������IJ�ͬ; ��һ����������,ָ����������this��ָ��;
�ڶ���������ʼ��ͬ,apply�Ǵ�����±�ļ���,�������������,apply��������������Ϊ����,call�ӵڶ�����ʼ����IJ����Dz��̶���,���ᴫ��������Ϊ������
call��apply������Ҫ��,ƽ�����Զ���call��call��������ĸ�ʽ�����ڲ�����Ҫ�ĸ�ʽ��
#(����)js ��typeof����������������?
string,number,Boolean,undefined,object,function, symbol(es6)
#(����)ʲô�DZհ�?ΪʲôҪ����?
1)ʲô�DZհ�
����ִ�кؽ����һ���ڲ�����,�����ⲿ����������,����ڲ��������б�ִ�к���������ı���,���γ��˱հ���
�������ڲ��������ʵ��ⲿ����������ʹ�ñհ�,һ���Զ�ȡ�����еı���,�����Խ������еı����洢���ڴ���,��������������Ⱦ��������հ���Ѻ����еı���ֵ�洢���ڴ���,����ڴ�������,���Բ������ñհ�,�����Ӱ����ҳ����,����ڴ�й©��������Ҫʹ�ñհ�ʱ,Ҫ��ʱ�ͷ��ڴ�,�ɽ��ڲ㺯������ı�����ֵΪnull��
**2)�հ�ԭ�� **
����ִ�зֳ�������(Ԥ����κ�ִ�н�)��
- ��Ԥ�����,��������ڲ�����ʹ�����ⲿ�����ı���,������ڴ��д���һ�����հ����������Ӧ����ֵ,����Ѵ��ڡ��հ���,��ֻ��Ҫ���Ӷ�Ӧ����ֵ���ɡ�
- ִ�����,����ִ�������Ļᱻ����,�����ԡ��հ������������Ҳ�ᱻ����,�����ڲ����������øá��հ���������,�����ڲ��������Լ���ʹ�á��ⲿ�������еı���
�����˺�����������������,һ�������ڲ�����ĺ����Ὣ�����ⲿ�����Ļ�������ӵ���������������,����ִ�����,��ִ��������������,�����ڲ�����������������Ȼ��������������,���������ᱻ����,ֱ���ڲ��������ջٺ�ű����١�
3)�ŵ�
- ���Դ��ڲ����������ⲿ�������������еı���,�ҷ��ʵ��ı�������פ�����ڴ���,�ɹ�֮��ʹ��
- ���������Ⱦȫ��
- �ѱ����浽������������,��Ϊ˽�г�Ա����
**4)ȱ�� **
- ���ڴ������и���Ӱ�졣���ڲ����������˶��ⲿ����������,����������������,�����ڴ�ʹ����,����ʹ�ò����ᵼ���ڴ�й©
- �Դ����ٶȾ��и���Ӱ�졣�հ��IJ㼶���������õ��ⲿ�����ڲ���ʱ������������������
- ���ܻ�ȡ�������ֵ(captured value)
4)Ӧ�ó���
Ӧ�ó���һ: ����Ӧ����ģ���װ,�ڸ�ģ��淶(ES6)����֮ǰ,�����������ķ�ʽ��ֹ������Ⱦȫ�֡�
var Yideng = (function () {
// ��������Ϊģ��˽�б���,�����ֱ�ӷ���
var foo = 0;
function Yideng() {}
Yideng.prototype.bar = function bar() {
return foo;
};
return Yideng;
}());
Ӧ�ó�����: ��ѭ���д����հ�,��ֹȡ�������ֵ��
���´���,�����ĸ�Ԫ�ش����¼�,���ᵯ�� 3����Ϊ����ִ�к����õ� i ��ͬһ��,�� i ��ѭ����������� 3
for (var i = 0; i < 3; i++) {
document.getElementById('id' + i).onfocus = function() {
alert(i);
};
}
//���ñհ����
function makeCallback(num) {
return function() {
alert(num);
};
}
for (var i = 0; i < 3; i++) {
document.getElementById('id' + i).onfocus = makeCallback(i);
}
#(����)����js�̳еķ�ʽ
- ����ʽ�̳�:�Ѹ�������з�����������������
- ԭ��ʽ�̳�:ֻ�̳и���ԭ���ϵ����Ժͷ���
- ԭ�����̳�:�̳и���캯����ߵ����Ժͷ���,Ҳ�̳и���ԭ���ϵ����Ժͷ��� ȱ��C�������ഫ����
- ���ù��캯���̳�:���Ը��ഫ�ݲ��� ȱ��C�̳в��˸���ԭ�Ͷ���ķ���
- ��ϼ̳�:���ù��캯���̳�+ԭ�����̳�
#(����)��String����һ��trim()����,ȥ����ͷ�ͽ�β�Ŀո����
String.prototype.trim = function (str) {
return str.replace(/(^\s*)|(\s*$)/g, '');
}
#(����)�����dz����������
dz����(shallowCopy)ֻ��������һ��ָ��ָ���Ѵ��ڵ��ڴ��ַ,
���(deepCopy)��������һ��ָ�벢��������һ���µ��ڴ�,ʹ������ӵ�ָ��ָ������µ��ڴ�.
dz����:������ָ���Ƶ��ڴ��ַ,���ԭ��ַ�����ı�,��ôdz���Ƴ����Ķ���Ҳ����Ӧ�ĸı䡣
���:�ڼ�����п���һ���µ��ڴ��ַ���ڴ�Ÿ��ƵĶ���
#(����)���ʵ�����
����:ʹ��JSON.parse(JSON.stringify(obj))
ԭ���ǰ�һ���������л���Ϊһ��JSON�ַ���,�����������ת�����ַ�������ʽ�ٱ����ڴ�����,����JSON.parse()�����л���JSON�ַ������һ���µĶ���
ȱ����: �����undefined��symbol��funciton
ʵ��:�ݹ�+�ж�����
һ���Ĵ���
// ���� �ַ��� function�Dz���Ҫ������
function deepClone(value) {
if (value == null) return value;
if (typeof value !== 'object') return value;
if (value instanceof RegExp) return new RegExp(value);
if (value instanceof Date) return new Date(value);
// ��Ҫ�ж� value �Ƕ��������� ����Ƕ��� �Ͳ������� ������Ͳ�������
let obj = new value.constructor;
for(let key in value){
obj[key] = deepClone(value[key]); // ��һ����ǰ��ֵ�Dz���һ������
}
return obj;
}
#(����)javascript ���������ջ��ƽ�һ��
����:ָһ�鱻������ڴ�Ȳ���ʹ��,�ֲ��ܻ���,ֱ����������̽�����
JavaScript �ڴ�������(�����ַ�����)ʱ��Ϊ���Ƿ����ڴ�,����ʹ�ö�ʱ�ᡰ�Զ����ͷ��ڴ�,������̳�Ϊ�����ռ���
�ڴ����������е�ÿһ����:
�����ڴ� ��? �ڴ����ɲ���ϵͳ�����,���������ij���ʹ�������ڵͼ�����(���� C ����)��,����һ��������Ա��Ҫ�Լ���������ʽִ�еIJ�����Ȼ��,�ڸ�������,ϵͳ���Զ�Ϊ��������ڡ� ʹ���ڴ� �� ���dz���ʵ��ʹ��֮ǰ������ڴ�,�ڴ�����ʹ�÷���ı���ʱ,�ͻᷢ������д������ �ͷ��ڴ� �� �ͷ����в���ʹ�õ��ڴ�,ʹ֮��Ϊ�����ڴ�,�����Ա������á�������ڴ����һ��,��һ�����ڵͼ�������Ҳ����Ҫ��ʽ��ִ�С�
���ֳ������ڴ�й©:ȫ�ֱ���,δ����Ķ�ʱ��,�հ�,�Լ� dom ������
- ȫ�ֱ��� ���� var �����ı���,�൱�ڹ��ص� window �����ϡ���:b=1; ���:ʹ���ϸ�ģʽ
- �������Ķ�ʱ���ͻص�����
- �հ�
- û�������� DOM Ԫ������
#(����)������ promise �����ԡ���ȱ��
-
Promise��������
1��Promise������״̬:pending(������)��fulfilled(�ѳɹ�)��rejected(��ʧ��)
2��Promise�������һ���ص�������Ϊ����, �ûص�����������������,�ֱ��dzɹ�ʱ�Ļص�resolve��ʧ��ʱ�Ļص�reject;����resolve�IJ�����������ֵ����, ��������һ��Promise�����ʵ��;reject�IJ���ͨ����һ��Error�����ʵ����
3��then��������һ���µ�Promiseʵ��,��������������onResolved(fulfilled״̬�Ļص�);onRejected(rejected״̬�Ļص�,�ò�����ѡ)
4��catch��������һ���µ�Promiseʵ��
5��finally��������Promise״̬��ζ���ִ��,�÷����Ļص������������κβ���
6��Promise.all()������������Promiseʵ��,��װ��һ���µ�Promiseʵ��,�÷�������һ����Promise������ɵ�������Ϊ����(Promise.all()�����IJ������Բ�������,���������Iterator�ӿ�,�ҷ��ص�ÿ����Ա����Promiseʵ��),ע�������ֻҪ��һ��ʵ������catch����,���ᴥ��Promise.all()�������ص��µ�ʵ����catch����,��������е�ij��ʵ������������catch����,�����ᴥ��Promise.all()�������ص���ʵ����catch����
7��Promise.race()�����IJ�����Promise.all����һ��,�����е�ʵ��ֻҪ��һ�����ȸı�״̬�ͻὫ��ʵ����״̬����Promise.race()����,��������ֵ��ΪPromise.race()����������Promiseʵ���ķ���ֵ
8��Promise.resolve()�����ж���תΪPromise����,����÷����IJ���Ϊһ��Promise����,Promise.resolve()�������κδ���;�������thenable����(������then����),Promise.resolve()���ö���תΪPromise��������ִ��then����;���������һ��ԭʼֵ,������һ��������then�����Ķ���,��Promise.resolve��������һ���µ�Promise����,״̬Ϊfulfilled,�����������Ϊthen������onResolved�ص������IJ���,���Promise.resolve������������,��ֱ�ӷ���һ��fulfilled״̬�� Promise ������Ҫע�����,����resolve()�� Promise ����,���ڱ��֡��¼�ѭ����(event loop)�Ľ���ʱִ��,����������һ�֡��¼�ѭ�����Ŀ�ʼʱ��
9��Promise.reject()ͬ������һ���µ�Promise����,״̬Ϊrejected,���۴����κβ���������Ϊreject()�IJ���
2)Promise�ŵ�
��ͳһ�첽 API
- Promise ��һ����Ҫ�ŵ���������������������첽 API ,ͳһ���ڸ��ָ����� API ,�Լ������ݵ�ģʽ���ַ���
��Promise ���¼��Ա�
- ���¼���Ƚ�, Promise ���ʺϴ���һ���ԵĽ�����ڽ���������֮ǰ��֮��ע��ص��������ǿ��Ե�,�������õ���ȷ��ֵ�� Promise ������ŵ����Ȼ������,����ʹ�� Promise ������δ������¼�����ʽ������ Promise ����һ�ŵ�,�����¼�ȴ����������ʽ������
��Promise ��ص��Ա�
- ����˻ص�����������,���첽������ͬ�����������̱��������
��Promise �����Ķ���ô��ǰ����˸��õĴ�������ʽ(�������쳣����),����д����������(��Ϊ��������һЩͬ���Ĺ���,���� Array.prototype.map() )��
3)Promiseȱ��
1����ȡ��Promise,һ���½����ͻ�����ִ��,����;ȡ����
2����������ûص�����,Promise�ڲ��׳��Ĵ���,���ᷴӦ���ⲿ��
3��������Pending״̬ʱ,����֪Ŀǰ��չ����һ����(�ոտ�ʼ���Ǽ������)��
4��Promise ����ִ�лص���ʱ��,���� Promise �Dz���ʵ�����Ѿ�������,���� Promise �ı�����ջ�����IJ�̫�Ѻá�
#(����)�����һ��XMLhttprequest����
Ajax�ĺ�����JavaScript����XmlHttpRequest���ö�����Internet Explorer 5���״�����,����һ��֧���첽����ļ����������֮,XmlHttpRequestʹ������ʹ��JavaScript������������������Ӧ,���������û���ͨ��XMLHttpRequest����,Web������Ա������ҳ������Ժ����ҳ��ľֲ����¡�
#(����)������һ�� cookies,sessionStorage �� localStorage ������?
- cookie��������Զ�Я����������������ȥ��֤��
sessionStorage��localStorage�����Զ�Я��
- cookie������sessionStorage localStorageС
- ��˿�������cookie֮��,ǰ���IJ��˵�;
- cookie�������ù���ʱ��
- cookie��������״̬���ֵ�,��Ϊhttp����ʱ��״̬��
- cookie���û���һ�η��ʷ������������䷢���������,�ڶ�������ͻ�Я��
- sessionStorage �洢���ڴ��� �ر���������ݻ���ʧ
- localStorage �ر���������ݲ�����ʧ ��Ҫ�ֶ�ȥ���
#(����)������������
1)������������
�����ÿ�η�������ʱ,���ڱ��ػ����в��ҽ���Լ������ʶ,���ݻ����ʶ���ж��Ƿ�ʹ�ñ��ػ��档���������Ч,��ʹ �ñ��ػ���;����,�����������������Я�������ʶ�������Ƿ��������������HTTP����,��������̻���Ϊ��������: ǿ�ƻ����Э�̻���,ǿ��������Э�̻��档
- ǿ����,������֪ͨ�����һ������ʱ��,�ڻ���ʱ����,�´�����,ֱ���û���,����ʱ����,ִ�бȽϻ�����ԡ�
- Э�̻���,�ÿͻ����������֮����ʵ�ֻ����ļ��Ƿ���µ���֤����������ĸ�����,��������Ϣ�е�Etag��Last-Modified ͨ��������������,�ɷ�����У��,����304״̬��ʱ,�����ֱ��ʹ�û��档
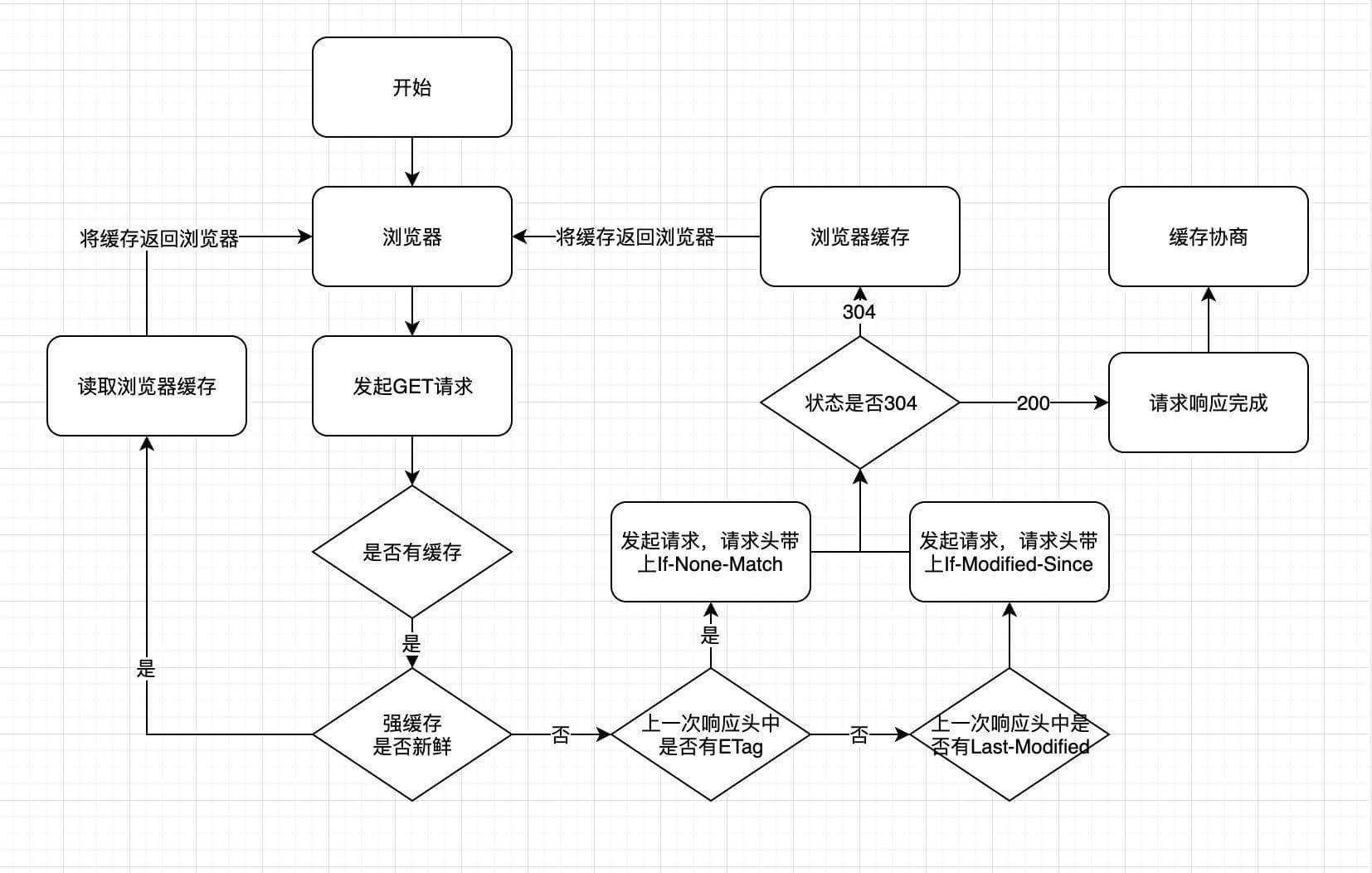
HTTP���涼�Ǵӵڶ�������ʼ��:
- ��һ��������Դʱ,������������Դ,����response header�лش���Դ�Ļ������;
- �ڶ�������ʱ,������ж���Щ�������,����ǿ�����ֱ��200,����Ͱ���������ӵ�request headerͷ�д���������,���Ƿ����Э�̻���,������304,����������᷵���µ���Դ�����ǻ���������һ����������ͼ:
 (opens new window)
(opens new window)2)ǿ����
- ǿ����������ֱ�Ӷ�ȡ��������ص���Դ,��network����ʾ����from memory����from disk
- ����ǿ�ƻ�����ֶ���:Cache-Control(http1.1)��Expires(http1.0)
- Cache-control��һ�����ʱ��,���Ա������ϴ�������ȷ����Դ֮��Ķ������ʱ����ڻ�����Ч��
- Expires��һ������ʱ�䡣���Ա��������ʱ���֮ǰ�����������ֱ�Ӵ�������ж�ȡ����,�����跢������
- Cache-Control�����ȼ���Expires�����ȼ��ߡ�ǰ�ߵij�����Ϊ�˽��Expires�������ʱ�䱻�ֶ����ĵ��»����жϴ�������⡣ ���ͬʱ������ʹ��Cache-control��
3)ǿ����-expires
- ���ֶ��Ƿ�������Ӧ��Ϣͷ�ֶ�,����������ڹ���ʱ��֮ǰ����ֱ�Ӵ�����������д�ȡ���ݡ�
- Expires �� HTTP 1.0 ���ֶ�,��ʾ���浽��ʱ��,��һ�����Ե�ʱ�� (��ǰʱ��+����ʱ��)������Ӧ��Ϣͷ��,��������ֶ�֮��,�Ϳ��Ը��������,��δ����֮ǰ����Ҫ�ٴ�����
- �����Ǿ���ʱ��,�û����ܻὫ�ͻ��˱��ص�ʱ�������,������������жϻ���ʧЧ,�����������Դ������,��ʹ��������,ʱ�������������Ҳ������ɿͻ��������˵�ʱ�䲻һ��,��ʹ����ʧЧ��
- �����ص�
- 1��HTTP 1.0 ����,������HTTP 1.0��1.1��ʹ��,�����á�
- 2����ʱ�̱�ʶʧЧʱ�䡣
- ��������
- 1��ʱ�����ɷ��������͵�(UTC),���������ʱ��Ϳͻ���ʱ����ڲ�һ��,���ܻ�������⡣
- 2�����ڰ汾����,����֮ǰ���Ŀͻ����Dz���֪�ġ�
4)ǿ����-cache-control
-
��֪Expires��ȱ��֮��,��HTTP/1.1��,������һ���ֶ�Cache-control,���ֶα�ʾ��Դ����������Чʱ��,�ڸ�ʱ����,�ͻ��˲���Ҫ���������������
-
�����ߵ��������ǰ���Ǿ���ʱ��,�����������ʱ�䡣�����о�һЩ
Cache-control�ֶγ��õ�ֵ:(�������б����Բ鿴MDN)max-age:�������Чʱ�䡣must-revalidate:���������max-age��ʱ��,������������������������,��֤��Դ�Ƿ���Ч��no-cache:��ʹ��ǿ����,��Ҫ���������֤�����Ƿ����ʡ�no-store: ���������ϵġ���Ҫ���桱���������ݶ�������,����ǿ�ƺͶԱȡ�public:���е����ݶ����Ա����� (�����ͻ��˺ʹ���������, �� CDN)private:���е�����ֻ�пͻ��˲ſ��Ի���,�������������ܻ��档Ĭ��ֵ��
-
Cache-control �����ȼ����� Expires,Ϊ�˼��� HTTP/1.0 �� HTTP/1.1,ʵ����Ŀ�������ֶζ��������á�
-
���ֶο���������ͷ������Ӧͷ����,�����ʹ�ö���ָ��:
-
�ɻ�����
:
- public:������ͻ�������������Ի���ҳ����Ϣ
- private:default,�������������ɻ���,ֻ�ܱ������û�����
- no-cache:��������ͷ���������Ӧ�û���ҳ����Ϣ,���Կɻ���,ֻ���ڻ���ǰ��Ҫ�������ȷ����Դ�Ƿ��ġ������private, ����ʱ������Ϊ��ȥʱ�䡣
- only-if-cache:�ͻ���ֻ�����ѻ������Ӧ
-
����
- max-age=:����洢���������,����������ڱ���Ϊ���ڡ�
- s-maxage=:���ù�������,����can���Ḳ��max-age��expires��
- max-stale[=]:�ͻ���Ը�����һ���Ѿ����ڵ���Դ
- min-fresh=:�ͻ���ϣ����ָ����ʱ���ڻ�ȡ���µ���Ӧ
- stale-while-revalidate=:�ͻ���Ը����ճ¾ɵ���Ӧ,�����ں�̨һ������µ���Ӧ��ʱ������ͻ���Ը����ճ¾���Ӧ ��ʱ�䳤�ȡ�
- stale-if-error=:���µļ��ʧ��,�ͻ�����Ը����ճ¾ɵ���Ӧ,ʱ������ȴ�ʱ�䡣
-
������֤�����¼���
- must-revalidate:��ҳ�����,��ȥ���������л�ȡ��
- proxy-revalidate:���ڹ������档
- immutable:��Ӧ���IJ���ʱ��ı䡣
-
����
- no-store:���Խ�ֹ����
- no-transform:���ö���Դ����ת����ת�䡣����,���ö�ͼ���ʽ����ת����
-
-
�����ص�
- 1��HTTP 1.1 ����,��ʱ������ʶʧЧʱ��,�����Expires�������Ϳͻ������ʱ������⡣
- 2����Expires���˺ܶ�ѡ�����á�
-
��������
- 1�����ڰ汾����,����֮ǰ���Ŀͻ����Dz���֪�ġ�
5)Э�̻���
- Э�̻����״̬���ɷ��������߷���200����304
- ���������ǿ����ʧЧ��ʱ���������ͷ�������˲���ǿ����,����������ͷ��������If-Modified-Since ���� If-None-Match ��ʱ��,�Ὣ����������ֵ�������ȥ��֤�Ƿ�����Э�̻���,���������Э�̻���,�᷵�� 304 ״̬,�������������,������Ӧͷ������ Last-Modified ���� ETag ���ԡ�
- �ԱȻ������������Ϻ�û�л�����һ�µ�,������� 304 �Ļ�,���صĽ�����һ��״̬�����,��û��ʵ�ʵ��ļ�����,��� ����Ӧ������ϵĽ�ʡ�������Ż��㡣
- Э�̻����� 2 ���ֶ�(��������),����Э�̻�����ֶ���:Last-Modified/If-Modified-since(http1.0)��Etag/If-None-match(http1.1)
- Last-Modified/If-Modified-since��ʾ���Ƿ���������Դ���һ���ĵ�ʱ��;Etag/If-None-match��ʾ���Ƿ�������Դ��Ψһ�� ʶ,ֻҪ��Դ�仯,Etag�ͻ��������ɡ�
- Etag/If-None-match�����ȼ���Last-Modified/If-Modified-since�ߡ�
6)Э�̻���-Э�̻���-Last-Modified/If-Modified-since
- 1.������ͨ��
Last-Modified�ֶθ�֪�ͻ���,��Դ���һ�α��ĵ�ʱ��,����Last-Modified: Mon, 10 Nov 2018 09:10:11 GMT - 2.����������ֵ������һ���¼�ڻ������ݿ��С�
- 3.��һ��������ͬ��Դʱʱ,��������Լ��Ļ������ҳ�����ȷ���Ƿ���ڵġ����档���������ͷ�н��ϴε�
Last-Modified��ֵд�뵽����ͷ��If-Modified-Since�ֶ� - 4.�������Ὣ
If-Modified-Since��ֵ��Last-Modified�ֶν��жԱȡ�������,���ʾδ��,��Ӧ 304;��֮,���ʾ����,��Ӧ 200 ״̬��,���������ݡ� - �����ص�
- 1�������ڰ汾����,ÿ������ȥ����������У�顣�������Ա������ʱ�������ͬ��304,��ͬ����200�Լ���Դ���ݡ�
- ��������
- 2��ֻҪ��Դ��,���������Ƿ���ʵ���Եı仯,���Ὣ����Դ���ؿͻ��ˡ�������������д,��������¸���Դ����������ʵ����һ���ġ�
- 3����ʱ����Ϊ��ʶ,��ʶ��һ���ڽ��ж���ĵ������ �����Դ���µ��ٶ��������µ�λ,��ô�û����Dz��ܱ�ʹ�õ�,��Ϊ����ʱ�䵥λ������롣
- 4��ijЩ���������ܾ�ȷ�ĵõ��ļ��������ʱ�䡣
- 5������ļ���ͨ����������̬���ɵ�,��ô�÷����ĸ���ʱ����Զ�����ɵ�ʱ��,�����ļ�����û�б仯,��������������á�
7)Э�̻���-Etag/If-None-match
- Ϊ�˽����������,������һ���µ��ֶ�
Etag��If-None-Match Etag�洢�����ļ��������ʶ(һ�㶼�� hash ���ɵ�),�������洢���ļ���Etag�ֶΡ�֮������̺�Last-Modifiedһ��,ֻ��Last-Modified�ֶκ�������ʾ�ĸ���ʱ��ı����Etag�ֶκ�������ʾ���ļ� hash,��If-Modified-Since�����If-None-Match��������ͬ�����бȽ�,���з��� 304, �����з�������Դ�� 200��- ������ڷ�������ʱ,������������Response header�з���������Դ��Ψһ��ʶ������һ������ʱ,�Ὣ��һ�η��ص�Etagֵ��ֵ��If-No-Matched��������Request Header�С��������������������if-no-matched���Լ��ı��ص���Դ��ETag���Ա�,���ƥ��,��304֪ͨ�������ȡ���ػ���,����200���º����Դ��
- Etag �����ȼ����� Last-Modified��
- �����ص�
- 1�����Ը��Ӿ�ȷ���ж���Դ�Ƿ���,����ʶ��һ���ڶ���ĵ������
- 2�������ڰ汾����,ÿ������ȥ����������У�顣
- ��������
- 1������ETagֵ��Ҫ������ġ�
- 2���ֲ�ʽ�������洢�������,����ETag���㷨�����һ��,�ᵼ���������һ̨�������ϻ��ҳ�����ݺ�����һ̨�������Ͻ�����֤ʱ��ETag��ƥ��������
#(����)����ͬԴ���������
ͬԴ������һ��Լ��,�������������ĵ�Ҳ������İ�ȫ����,���ȱ����ͬԴ����,����������������ܿ��ܻ��ܵ�Ӱ�졣
��Э��,����,�Ͷ˿ں���һ����ͬʱ,���ǿ���
#(����)����������
1��(���)����������CORS(������Դ����)
2) (���)node.js��nginx,�������,�ѿ�������ͬ��
3)(ǰ��)��JSON������JSONP,��JSON�Ļ�����,����script ��ǩ���Կ��������,����ͷ����
#(����)���������ַ������URL����ʾҳ��IJ���
1. ��������������URL����DNS��������,�ҵ���ʵIP,���������������;
2. ������������̨������ɺ�����,����������ļ�(html,js,css,ͼ���);
3. ������Լ��ص�����Դ(html,js,css��)���������,������Ӧ���ڲ����ݽṹ(��HTML��DOM);
4. �������������Դ�ļ�,��Ⱦҳ��,��ɡ�
#(����)JavaScript �е�������(scope)��ָʲô?
�� JavaScript ��,ÿ�����������Լ���������������������DZ����Լ����ͨ�����Ʒ�����Щ�����Ĺ���ļ��ϡ�ֻ�к����еĴ�����ܷ��ʺ����������ڵı�����
ͬһ���������еı�����������Ψһ�ġ�һ�����������Ƕ������һ���������ڡ����һ��������Ƕ������һ����������,���ڲ��������ڵĴ�����Է�����һ��������ı�����
#(����)���� JavaScript �е� null �� undefined
null��ʾһ���յĶ���,ʲôҲû��
undefined ��ʾ����Ϊ��ֵ
undefined�Ǵ�null����������
null == undefined //true
null === undefined //false
typeof null // 'object'
typeof undefined // 'undefined'
#(����)��������¼�ѭ��
**1)Ϊʲô����Event Loop **
JavaScript�������Ϊ����ͬ�����첽,���ǵĴ�����ʽҲ���Բ�ͬ,ͬ��������ֱ�ӷ������߳����Ŷ�����ִ��,�첽������������������,���ж���첽��������Ҫ������������Ŷӵȴ�,������������ڻ�����,������һ���ᱻ�Ƶ�����ջȻ�����߳�ִ�е���ջ������
����ջ:����ջ��һ��ջ�ṹ,�������û��γ�һ��ջ֡,֡�а����˵�ǰִ�к����IJ����;ֲ���������������Ϣ,����ִ�����,����ִ�������Ļ��ջ�е�����
JavaScript�����߳���,���߳���ָ js�����н�����ִ��js������߳�ֻ��һ��(���߳�),ÿ��ֻ����һ������,Ȼ��ajax������,���߳��ڵȴ���Ӧ�Ĺ����л�ȥ����������,����������¼���ע��ajax�Ļص�����,��Ӧ������ص����������ӵ���������еȴ�ִ��,��������߳�����,����˵js����ajax����ķ�ʽ���첽�ġ�
��������,������ջ�Ƿ�Ϊ���Լ���ij���������ӵ�����ջ�еĸ����̾���event loop,�����JavaScriptʵ���첽�ĺ��ġ�
2)������е� Event Loop
Micro-Task �� Macro-Task
��������¼�ѭ���е��첽����������:macro(������)���к� micro(����)���С�
������ macro-task:setTimeout��setInterval��script(�������)��I/O ������UI ��Ⱦ�ȡ�
������ micro-task: new Promise().then(�ص�)��MutationObserve�ȡ�
requestAnimationFrame
requestAnimationFrameҲ�����첽ִ�еķ���,���÷����Ȳ����ں�����,Ҳ������������MDN�еĶ���:
window.requestAnimationFrame()���������������ϣ��ִ��һ������,����Ҫ����������´��ػ�֮ǰ����ָ���Ļص��������¶������÷�����Ҫ����һ���ص�������Ϊ����,�ûص����������������һ���ػ�֮ǰִ��
requestAnimationFrame��GUI��Ⱦ֮ǰִ��,����Micro-Task֮��,����requestAnimationFrame��һ�����ڵ�ǰ֡����ִ��,����������ݵ�ǰ�IJ������о�������һִ֡�С�
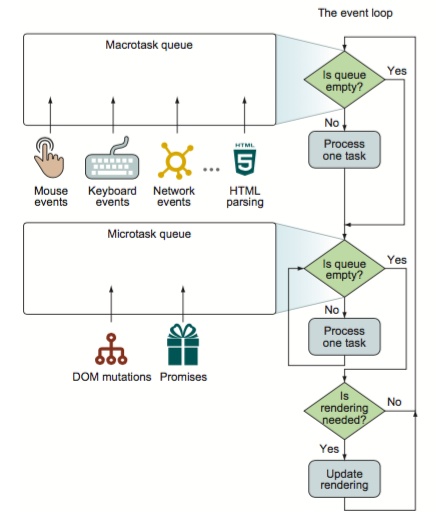
event loop����
 (opens new window)
(opens new window)- ���macrotask�����Ƿ�Ϊ��,�ǿ���2,Ϊ����3
- ִ��macrotask�е�һ������
- �������microtask�����Ƿ�Ϊ��,������4,����5
- ȡ��microtask�е�����ִ��,ִ����ɷ��ص�����3
- ִ����ͼ����
��ij��������ִ�����,��鿴�Ƿ���������С������,��ִ����������е���������,���û��,���ȡ�����������������ǰ������,ִ�к�����Ĺ�����,��������,���μ���������С�ջ�պ�,�ٴζ�ȡ��������������,�������ơ�
#(����)�����¼�ð���Լ������ֹ��?
�¼�ð����ָǶ�������Ԫ�ش���һ���¼�,Ȼ������¼�˳��Ƕ��˳���ڸ�Ԫ���ϴ�����
��ֹ�¼�ð�ݵ�һ�ַ�����ʹ�� event.cancelBubble �� event.stopPropagation()(���� IE 9)��
#(����)ʲô�Ƿ����ͽ���?��ʲô����?���ʵ��?
/** ����:
* Ӧ�ó���:���û�������ij����Ϊ(������)֮��ϣ��ÿ����Ϊ���ᴥ������,������Ϊ������,һ��ʱ����û���ٴ��ظ���Ϊ,
* �Ÿ��û���Ӧ
* ʵ��ԭ�� : ÿ�δ����¼�ʱ����һ����ʱ���÷���,����ȡ��֮ǰ����ʱ���÷�����(ÿ�δ����¼�ʱ��ȡ��֮ǰ����ʱ���÷���)
* @params fun ����ķ�������(callback) delay �ȴ�ʱ��
* */
const debounce = (fun, delay = 500) => {
let timer = null //�趨һ����ʱ��
return function (...args) {
clearTimeout(timer);
timer = setTimeout(() => {
fun.apply(this, args)
}, delay)
}
}
/** ����
* Ӧ�ó���:�û����и�Ƶ�¼�����(����),����������n����ֻ��ִ��һ�Ρ�
* ʵ��ԭ��: ÿ�δ���ʱ���ʱ��,�жϵ�ǰ�Ƿ���ڵȴ�ִ�е���ʱ����
* @params fun ����ķ�������(callback) delay �ȴ�ʱ��
* */
const throttle = (fun, delay = 1000) => {
let flag = true;
return function (...args) {
if (!flag) return;
flag = false
setTimeout(() => {
fun.apply(this, args)
flag = true
}, delay)
}
}
����:���������¼�������Ƶ����֤��һ��ʱ����һ����ִ��һ�κ�����������ֻ�����һ���¼�������Ż�ִ��һ�κ���
#(����)JSONP ��ԭ����ʲô?
�����������ͬԴ����,���� script ��ǩ�� src ���Բ��ᱻͬԴ������Լ��,���Ի�ȡ����������ϵĽű���ִ�С�jsonp ͨ������ script ��ǩ�ķ�ʽ��ʵ�ֿ���,����ֻ��ͨ�� url ����,����֧�� get ����
- Step1: ���� callback ����
- Step2: ���� script ��ǩ
- Step3: ��̨���ܵ�����,����ǰ�˴���ȥ�� callback ����,���ظ÷����ĵ���,����������Ϊ��������÷���
- Step4: ǰ��ִ�з���˷��صķ�������
#(����)�첽����JS�ķ�ʽ����Щ?
- defer,ֻ֧��
IE async:- ����
script,���뵽DOM��,������Ϻ�callBack defer���м���js�ļ�,�ᰴ��ҳ����script��ǩ��˳��ִ��async���м���js�ļ�,�����������ִ��,���ᰴ��ҳ����script��ǩ��˳��ִ��
#(����)����web��ȫ������ԭ��
-
#1)XSS:��վ�ű�����
���ǹ������뾡һ�а취������ִ�еĴ���ע�뵽��ҳ�С�
#�洢��(server��):
- ����:���ڴ����û��������ݵ���վ����,����̳��������Ʒ���ۡ��û�˽�ŵȡ�
- ��������:
- i)�����߽���������ύ��Ŀ����վ�����ݿ���
- ii)�û���Ŀ����վʱ,����˽������������ݿ���ȡ����,ƴ����HTML�з��ظ������
- iii)�û���������յ���Ӧ�����ִ��,�������еĶ������Ҳͬʱ��ִ��
- iv)���������ȡ�û�����,�����͵�ָ�������ߵ���վ,����ð���û���Ϊ,����Ŀ����վ�Ľӿ�,ִ�ж������
#������(Server��)
��洢�͵���������,�洢�͵Ķ������洢�����ݿ���,�����͵Ķ��������URL��
- ����:ͨ�� URL ���ݲ����Ĺ���,����վ��������ת�ȡ�
- ��������:
- i)�����߹��������� URL,���а���������롣
- ii)�û����ж������� URL ʱ,��վ����˽��������� URL ��ȡ��,ƴ���� HTML �з��ظ��������
- iii)�û���������յ���Ӧ�����ִ��,�������еĶ������Ҳ��ִ�С�
- iv)���������ȡ�û����ݲ����͵������ߵ���վ,����ð���û�����Ϊ,����Ŀ����վ�ӿ�ִ�й�����ָ���IJ�����
#Dom ��(�������)
DOM �� XSS ������,ȡ����ִ�ж������������������,����ǰ�� JavaScript �����İ�ȫ©��,���������� XSS �����ڷ���˵İ�ȫ©����
- ����:ͨ�� URL ���ݲ����Ĺ���,����վ��������ת�ȡ�
- ��������:
- i)�����߹��������� URL,���а���������롣
- ii)�û����ж������� URL��
- iii)�û���������յ���Ӧ�����ִ��,ǰ�� JavaScript ȡ�� URL �еĶ�����벢ִ�С�
- iv)���������ȡ�û����ݲ����͵������ߵ���վ,����ð���û�����Ϊ,����Ŀ����վ�ӿ�ִ�й�����ָ���IJ�����
#Ԥ������:(��ֹ�������ύ�������,��ֹ�����ִ�ж������)
- i)�����ݽ����ϸ���������:��HTMLԪ�صı���,JS����,CSS����,URL����ȵ�
- ����ƴ�� HTML;Vue/React ����ջ,����ʹ�� v-html / dangerouslySetInnerHTML
- ii)CSP HTTP Header,�� Content-Security-Policy��X-XSS-Protection
- ���ӹ����Ѷ�,����CSP(�����ǽ���������,���������������)
Content-Security-Policy: default-src 'self'-�������ݾ�����վ���ͬһ��Դ(��������������)Content-Security-Policy: default-src 'self' *.trusted.com-���������������ε��������������� (������������CSP�������ڵ�������ͬ)Content-Security-Policy: default-src https://yideng.com-�÷�����������ͨ��HTTPS��ʽ������yideng.com�����������ĵ�
- iii)������֤:����һЩ���������֡�URL���绰���롢�����ַ�ȵ���У���ж�
- iv)���������XSS����:Http Only cookie,��ֹ JavaScript ��ȡijЩ���� Cookie,��������� XSS ע���Ҳ����ȡ�� Cookie��
- v)��֤��
#2)CSRF:��վ����α��
�������յ��ܺ��߽����������վ,�ڵ�������վ��,������վ���Ϳ�վ���������ܺ����ڱ�������վ�Ѿ���ȡ��ע��ƾ֤,�ƹ���̨���û���֤,�ﵽð���û��Ա���������վִ��ij�������Ŀ�ġ�
#�������̾���
- i)�ܺ��ߵ�¼ a.com,�������˵�¼ƾ֤(Cookie)
- ii)�����������ܺ��߷�����b.com
- iii)b.com �� a.com ������һ������:a.com/act=xx�������Ĭ��Я��a.com��Cookie
- iv)a.com���յ������,�����������֤,��ȷ�����ܺ��ߵ�ƾ֤,����Ϊ���ܺ����Լ����͵�����
- v)a.com���ܺ��ߵ�����ִ����act=xx
- vi)�������,���������ܺ��߲�֪��������,ð���ܺ���,��a.comִ�����Լ�����IJ���
#��������
- i)GET��:����ҳ���ij�� img �з���һ�� get ����
- ii)POST��:ͨ���Զ��ύ������������վ
- iii)������:��Ҫ�յ��û��������
#Ԥ������:
CSRFͨ���ӵ�������վ����,����������վ����ֹ��������,ֻ��ͨ����ǿ�Լ���վ���CSRF�ķ���������������ȫ�ԡ�)
- i)ͬԴ���:ͨ��Header�е�Origin Header ��Referer Header ȷ��,����ͬ��������ܻ��в�һ����ʵ��,������ȫ��֤
- ii)CSRF Token У��:��CSRF Token�����ҳ����(ͨ��������Session��),ҳ���ύ������Я�����Token,��������֤Token�Ƿ� ��ȷ
- iii)˫��cookie��֤:
- ����:
- ����1:���û�������վҳ��ʱ,����������ע��һ��Cookie,����Ϊ����ַ���(����csrfcookie=v8g9e4ksfhw)
- ����2:��ǰ�����˷�������ʱ,ȡ��Cookie,�����ӵ�URL�IJ�����(������POST https://www.a.com/comment?csrfcookie=v8g9e4ksfhw)
- ����3:��˽ӿ���֤Cookie�е��ֶ���URL�����е��ֶ��Ƿ�һ��,��һ����ܾ���
- �ŵ�:
- ����ʹ��Session,���������,����ʵʩ��
- Token�����ڿͻ�����,���������������ѹ����
- �����Token,ʵʩ�ɱ�����,������ǰ���ͳһ����У��,������Ҫһ�����ӿں�ҳ�����ӡ�
- ȱ��: -Cookie�������˶�����ֶΡ� -���������©��(����XSS),�����߿���ע��Cookie,��ô�÷�����ʽʧЧ�� -���������������ĸ��롣 -Ϊ��ȷ��Cookie���䰲ȫ,�������ַ�����ʽ�����ȷ������վHTTPS�ķ�ʽ,�����û��HTTPS��ʹ�����ַ�ʽҲ���з��ա�
- ����:
- iv)Samesite Cookie����:Google�����һ�ݲݰ����Ľ�HTTPЭ��,�Ǿ���ΪSet-Cookie��Ӧͷ����Samesite����,������������� Cookie�Ǹ���ͬվ Cookie��,ͬվCookieֻ����Ϊ��һ��Cookie,������Ϊ������Cookie,Samesite ����������ֵ,Strict Ϊ�κ�����¶���������Ϊ������ Cookie ,Lax Ϊ������Ϊ������ Cookie , ��������Get����
#3)iframe ��ȫ
#˵��:
- i)Ƕ������� iframe ���кܶ�ɿص�����,ͬʱ�������� iframe ����������DZ��ٳ�֮��,Ҳ���շ���ȫ������
- ii)����ٳ�
- �����߽�Ŀ����վͨ�� iframe Ƕ�ķ�ʽǶ���Լ�����ҳ��,���� iframe ����Ϊ��,�յ��û������
- iii)��ֹ�Լ��� iframe �е������ⲿ��վ��JS
#Ԥ������:
-
i)Ϊ iframe ���� sandbox ����,ͨ�������Զ�iframe����Ϊ���и�������,���ʵ�֡���СȨ�ޡ�ԭ��
-
ii)��������� X-Frame-Options Headerͷ,�ܾ�ҳ�汻Ƕ��,X-Frame-Options ��HTTP ��Ӧͷ���������������һ��ҳ���Ƿ����Ƕ��
-
iii)���� CSP �� Content-Security-Policy ����ͷ
-
iv)���ٶ� iframe ��ʹ��
#4)����������ƶ�
#˵��:
�ļ��ϴ�����У��ʧ�ܺ�,���¶����JS�ļ��ϴ���,����� Content-Type Header ��Ĭ�Ͻ���Ϊ��ִ�е� JS �ļ�
#Ԥ������:
���� X-Content-Type-Options ͷ
#5)������������
���ٶԵ�������������ʹ��,��֮ǰ npm �İ���:event-stream ��������������ֻ���;
#6)HTTPS
#����:
�ڿͿ�������SSL Stripping���ֹ����ֶ�,ǿ����HTTPS������HTTP,�Ӷ����������м��˹�����
#Ԥ������:
ʹ��HSTS(HTTP Strict Transport Security),��ͨ���������HTTP Header�Լ�һ��Ԥ���ص��嵥,����֪���������վ����ͨ�ŵ�ʱ��ǿ���Ե�ʹ��HTTPS,������ͨ�����ĵ�HTTP����ͨ�š�����ġ�ǿ���ԡ�����Ϊ����������ں�������¶�ֱ���������˷���HTTPS����,������������������HTTP��ת��HTTPS������,������֤��������Ӳ���ȫ��ʱ��,�����Ⱦ����û�,���Ҳ��� �û�ѡ���Ƿ�������в���ȫ��ͨ�š�
#7)���ش洢����
������Ҫ���û���Ϣ���������������
#8)��̬��Դ������У��
#����
ʹ�� ���ݷַ����� (CDNs) �ڶ��վ��֮�乲���ű�����ʽ�����ļ��������վ�����ܲ���ʡ������Ȼ��,ʹ��CDNҲ���ڷ���,���������ö� CDN �Ŀ���Ȩ,����Խ������������ע�뵽 CDN �ϵ��ļ��� (����ȫ�滻���ļ�),��˿���DZ�ڵع������дӸ� CDN ��ȡ�ļ���վ�㡣
#Ԥ������
��ʹ�� base64 ���������ļ���ϣֵд���������õ� script ��ǩ�� integrity ����ֵ�м�����������Դ�������ܡ�
#9)����ٳ�
#����:
- DNS�ٳ�(����Υ��):�������̵� DNS ��¼,�ض���������վ��DNS �ٳ���Υ������Ϊ,Ŀǰ DNS �ٳ��ѱ����,���ں��ټ� DNS �ٳ�
- HTTP�ٳ�:ǰ���� HTTP ������ HTTP �����Ĵ���,��Ӫ�̱�ɽ���� HTTP ��Ӧ����(��ӹ��)��
#Ԥ������
ȫվ HTTPS
#10)�м��˹���:
�м��˹���(Man-in-the-middle attack, MITM),ָ��������ͨѶ�����˷ֱ���������ϵ,�����������յ�������,ʹͨѶ��������Ϊ��������ͨ��һ��˽�ܵ�������Է�ֱ�ӶԻ�,����ʵ�������Ự�����������������۸�������ȫ���ơ�û�н����ϸ��֤��У�����м��˹������ֵ㡣Ŀǰ���������Э�鶼�ṩ��һЩ������֤��������ֹ�м��˹������� SSL (��ȫ���ֲ�)Э�������֤����ͨѶ���û���֤���Ƿ���Ȩ���������ε�����֤����֤�����䷢,������ִ��˫��������֤�������������û���һ��δ���ܵ� WiFi�·�����վ�����м��˹�����,�����߿�������ͨѶ˫����ͨ���������µ����ݡ�
#����
- i)��һ��δ���ܵ�Wi-Fi ���߽����Ľ��ܷ�Χ�ڵ��м��˹�����,���Խ��Լ���Ϊһ���м��˲����������
- ii)Fiddler / Charles (��ƿ)��������
- iii)12306 ֮ǰ���Լ�֤��
#����
- i)�ͻ��˷����������,�����м��˽ػ�
- ii)��������ͻ��˷���Կ
- iii)�м��˽ػ�Կ,�������Լ����ϡ�Ȼ���Լ�����һ����α��ġ���Կ,�����ͻ���
- iv)�ͻ����յ�α��Ĺ�Կ��,���ɼ���hashֵ����������
- v)�м��˻�ü���hashֵ,���Լ���˽Կ���ܻ������Կ,ͬʱ���ɼٵļ���hashֵ,����������
- vi)��������˽Կ���ܻ�ü���Կ,Ȼ��������ݴ�����ͻ���
#ʹ��ץ������fiddle�����о���˵��
-
- ����ͨ��һЩ;���ڿͻ��˰�װ֤��
-
- Ȼ��ͻ��˷�����������,fiddle���м��ȡ����,�������Լ�α���֤��
-
- �ͻ����Ѿ���װ�˹����ߵĸ�֤��,������֤ͨ��
-
- �ͻ��˾ͻ�������fiddle����ͨ��,��fiddle������ȷ�ķ�����
-
- ͬʱfiddle���ԭ�еķ���������ͨ��,��ȡ�����Լ����ܵ���Կ,ȥ������Կ
#����������ʽ
-
- ��̽:��̽��һ�����������������������������ݰ��ļ���,�ͺ����Ǽ����绰һ��������:ץ������
-
- ���ݰ�ע��:������,�����Ὣ�������ݰ�ע�뵽���������е�,��Ϊ��Щ�������ݰ��������������ݰ������,�û���ϵͳ�����ѷ���������ݡ�
-
- �Ự�ٳ�:�����ǽ���һ����վ�ĵ�¼��ʱ���˳���¼���ʱ��,�����һ���Ự,����Ự�ǹ�����������������ҪĿ��,��Ϊ����Ự,�������û����������ݺ�˽����Ϣ��
-
- SSL����:HTTPS��ͨ��SSL/TLS���м��ܹ���,��SSL���빥����,��ʹSSL/TLS���ӶϿ�,���ܱ�����HTTPS,��ɲ��� ������HTTP(�������վ�dz�����)
-
- DNS��ƭ,����������ͨ�����ֵ�DNS������,���ߴ۸��û�����hosts�ļ�,Ȼ��ȥ�ٳ��û����͵�����,Ȼ��ת������������Ҫת�����ķ�����
-
- ARP��ƭ,ARP(address resolution protocol)��ַ����Э��,����������APR��©��,�õ�ǰ������֮���һ̨������,��ð��ͻ�����Ҫ����ķ����,��ͻ��˷����Լ���MAC��ַ,�ͻ����ӵõ�������������MAC��ַ,����,����������ַ�������� ������������ͨ��,��MAC����ARP�������
-
- ����������
#Ԥ������:
- i)�ÿ��ŵĵ�����CA����
- ii)������δ֪��Դ��֤��,��Ҫȥ����һЩ����ȫ���ļ�
- iii)ȷ������ʵ�URL��HTTPS��,ȷ����վʹ����SSL,ȷ������һЩ����ȫ��SSL,ֻ����:TLS1.1,TLS1.2
- iv)��Ҫʹ�ù������緢��һЩ���е���Ϣ
- v)��Ҫȥ���һЩ����ȫ�����ӻ��߶������ӻ��ʼ���Ϣ
#11)sql ע��
#����
����ͨ����SQL������뵽Web�����ݽ�������������ҳ������IJ�ѯ�ַ���,���մﵽ��ƭ���ݿ������ִ�ж����SQL����,�Ӷ��ﵽ�ͷ����� ����ֱ�ӵĽ���
#Ԥ������:
- i)��̨����������֤,�������ַ����ˡ�
- ii)ʹ�ò�������ѯ,�ܱ���ƴ��SQL,�Ͳ�Ҫƴ��SQL��䡣
#12)ǰ�����ݰ�ȫ:
#����
�����档��è�۵�Ӱ�����۲�ȵ�,����������Ϊ�����ʲ�����ҵ
#Ԥ������:
- i)font-faceƴ�ӷ�ʽ:è�۵�Ӱ�����۲�
- ii)background ƴ��:����
- iii)αԪ������:����֮��
- iv)Ԫ�ض�λ����ʽ:ȥ�Ķ�
- v)iframe �첽����:����������
#13)��������
- i)�������������������ȫ�Բ���,©��ɨ��
- ii)ʹ�õ�������Դ��������ǰ�İ�ȫ����,���Կ����ںϵ�CI��
- iii)code review ��֤��������
- iv)Ĭ����Ŀ�����ö�Ӧ�� Header ����ͷ,�� X-XSS-Protection�� X-Content-Type-Options ��X-Frame-Options Header��Content-Security-Policy �ȵ�
- v)�Ե��������Ϳ������:NSP(Node Security Platform),Snyk
#(����)��Щ����������ڴ�й©?
- �ڴ�й©ָ�κζ�����������ӵ�л���Ҫ��֮����Ȼ����
setTimeout�ĵ�һ������ʹ���ַ������Ǻ����Ļ�,�������ڴ�й©- �հ�������̨��־��ѭ��(����������˴������ұ˴˱���ʱ,�ͻ����һ��ѭ��)
#(����)�¼���������������ʲô
���� > Ŀ�� > ð��;�ڲ����,�¼�ͨ����Ԫ�����´��ݵ�Ŀ��Ԫ�ء� Ȼ��������Ŀ��Ԫ��,ð�ݿ�ʼ��
#(����)ͬ�����첽������?
- ͬ��:��������ʷ���������,�û����õ�ҳ��ˢ��,���·�����,��������,ҳ��ˢ��,�����ݳ���,�û�����������,������һ������
- �첽:��������ʷ���������,�û���������,�������˽�������������,ҳ�治ˢ��,������Ҳ�����,�û�����������
#(����)ǰ�����ѹ��ͼƬ
���Ƚ�����ѹ���Ĵ������
- ͨ��ԭ����input��ǩ�õ�Ҫ�ϴ���ͼƬ�ļ�
- ��ͼƬ�ļ�ת����imgԪ�ر�ǩ
- ��canvas��ѹ�����Ƹ�HTMLImageElement
���IJ���:
- �õ�ת�����imgԪ�غ�,��ȡ����Ԫ�صĿ��߶�,������߶Ⱦ���ʵ��ͼƬ�ļ��Ŀ��߶ȡ�
- Ȼ����һ������ȵĿ��߶�,�������������ƿ��߶�,����еȱ��������š�
- ����ý�Ҫѹ���ijߴ��,����canvasʵ��,����canvas�Ŀ��߶�Ϊѹ�������ijߴ�,����img���Ƶ�����
// ��������
const canvas = document.createElement('canvas')
const context = canvas.getContext('2d')
// ���ÿ��߶�Ϊ��ͬ��Ҫѹ��ͼƬ�ijߴ�
canvas.width = targetWidth
canvas.height = targetHeight
context.clearRect(0, 0, targetWidth, targetHeight)
//��img���Ƶ�������
context.drawImage(img, 0, 0, targetWidth, targetHeight)
#(�˽�)WebSocket��HTTP������
httpЭ��������Ӧ�ò��Э��,���ǻ���tcpЭ���,httpЭ�齨������Ҳ����Ҫ���������ֲ��ܷ�����Ϣ��
http���ӷ�Ϊ������,������,��������ÿ������Ҫ�������ֲ��ܷ����Լ�����Ϣ����ÿһ��request��Ӧһ��response������������һ���������ڱ������ӡ�����TCP���Ӳ��Ͽ����ͻ����������ͨ��,����Ҫ�пͻ��˷���Ȼ����������ؽ�����ͻ�����������,�������DZ����ġ�
WebSocket����Ϊ�˽���ͻ��˷�����http����������Դ���������Ҫ������ʱ�����ѵ���������,��ʵ���˶�·����,����ȫ˫��ͨ�š���webSocketЭ���¿ͷ��˺����������ͬʱ������Ϣ��
������WenSocket֮����������������������request����֮����ܷ�����Ϣ�����������ʱ�ķ�������������Ȩ��ʲôʱ�Ϳ��Է�����Ϣ����������
#(�˽�)��ô��ֹjs����cookie?
����HttpOnly
�������cookie��������HttpOnly����,��ôͨ��js�ű�������ȡ��cookie��Ϣ,��������Ч�ķ�ֹXSS����,
#(�˽�)̸̸���AMD��CMD������
AMD �� CMD �Ƕ���ģ�鶨��淶�����ڶ�ʹ��ģ�黯���,AMD,�첽ģ�鶨��;CMD,ͨ��ģ�鶨����AMD����ǰ��,CMD�����ͽ���CMD�� API ְ��һ,û��ȫ��require,AMD��һ��API���Զ��á�
#(�˽�)new������������ʲô?
function Person(name){
//--------------------���-----------------------
var obj = new Object(); //�����˿ն���
this = obj //obj��ֵ��this
this.proto = Person.prototype //ʵ�������ԭ�;��ǹ��캯����ԭ��
this.name = name;//����ʵ�����Ժͷ���
return this; //����this
}
#(�˽�)xml��json������
���:XML�����JSON�����
�����ٶ�:JSON��XMLִ���ٶȿ�
�ṹ����: JSON�ڽṹ�ϱ�XML����
����:JSON���ݺ�js�кܺõĽ�����