认识函数 :
函数分成两个阶段 :
-
函数定义阶段
-
函数调用阶段
浏览器的内存使用情况 :
- 浏览器在运行的时候, 会把电脑分配的内容进行再次分配
-
会有两个空间关联比较紧密 :
-
浏览器的 存储空间 - 关联着函数的 定义阶段
-
浏览器的 运行空间 - 关联着函数的 调用阶段
-
函数的两个阶段分别做了什么事情 :
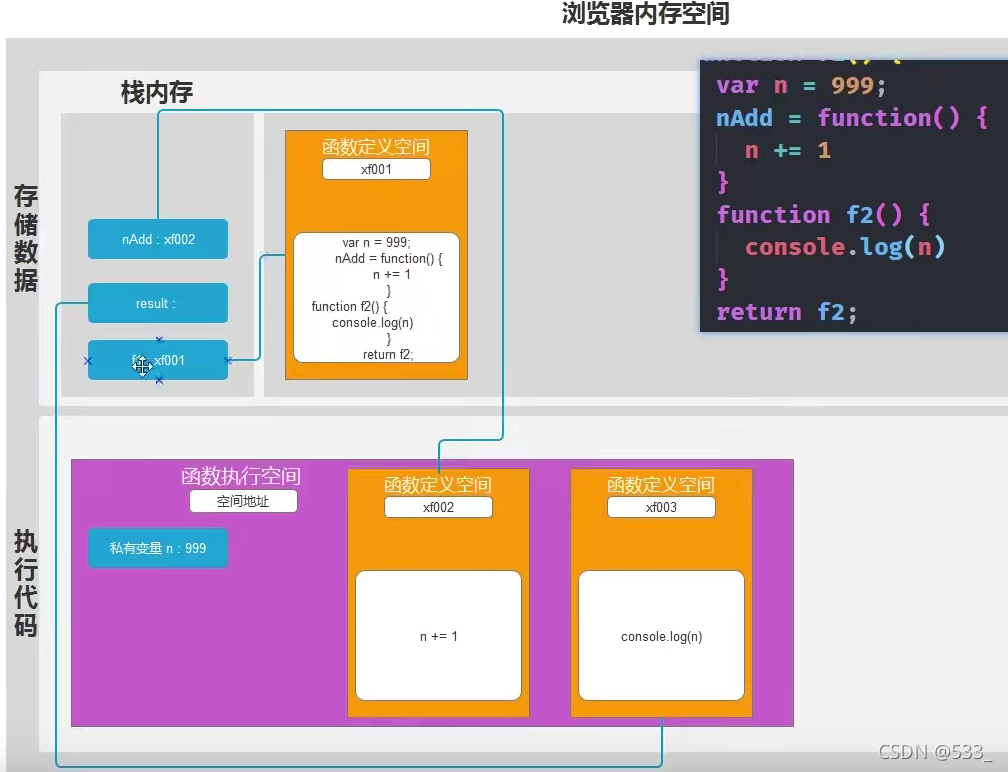
1. 函数定义阶段 :
- 在 堆内存 中开辟一段存储空间, 用来保存函数
- 把 函数体内的代码, 一模一样的复制一份, 以字符串的形式保存在这个函数空间内
此时任何变量不会进行解析
- 把函数 堆内存 中的存储空间地址赋值给变量

2. 函数调用阶段 :
- 按照 变量名(函数名) 内, 存储的地址找到函数 堆内存 中对应的存储空间
- 在 调用栈(运行空间) 内, 再次开辟一个新的函数执行空间地址,
- 把原始函数内的代码复制一份一模一样的到新的执行空间地址
- 在 新的 执行空间地址内 先进行形参赋值
- 在 新的 执行空间地址内 后进行函数内的预解析
- 在 新的 执行空间地址内 从上到下依次把函数体内的代码当做 js 代码执行一遍
- (等到函数所有代码执行完毕)会把 开辟在调用栈 内的 执行空间 销毁
函数的特点 :
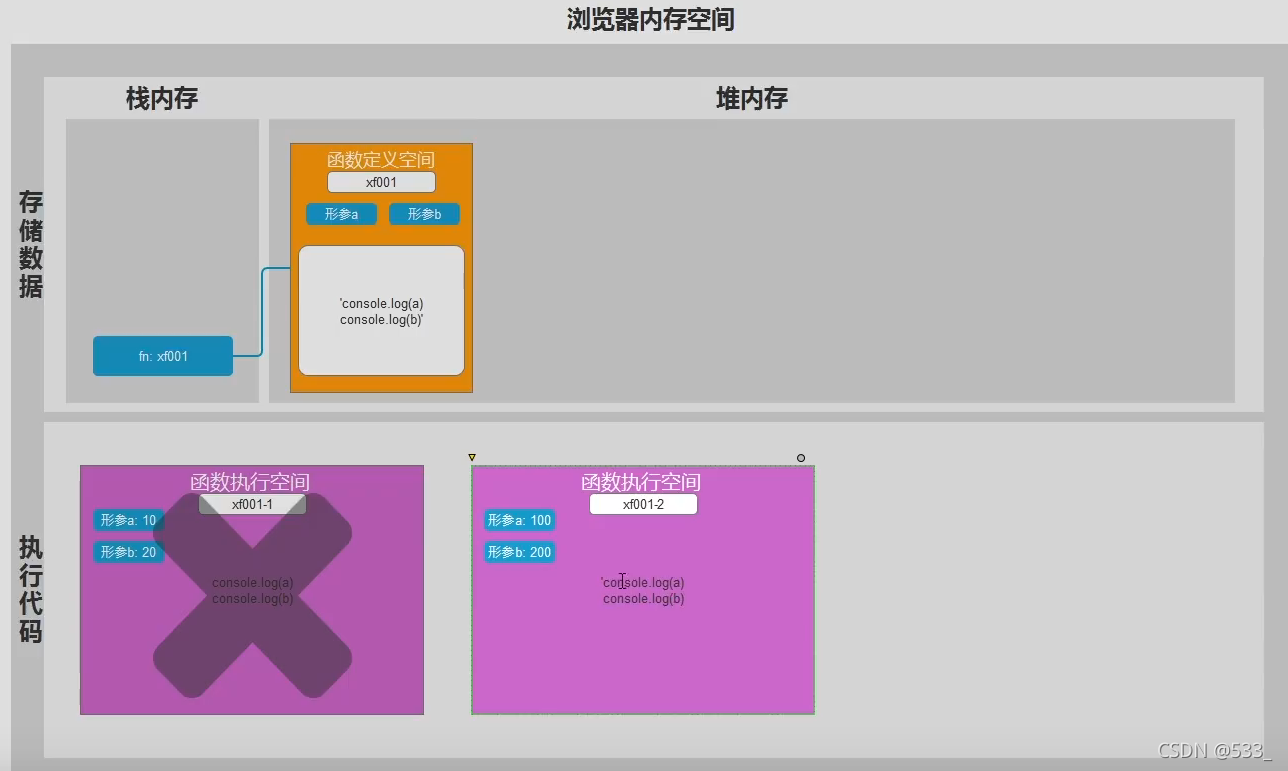
1. 保护私有变量
=> 因为每一个函数会生成一个独立的私有作用域
=> 在函数内定义的变量, 我们叫做 私有变量
=> 该变量只能在该函数作用域及下级作用域内使用, 外部不能使用
2. 函数定义时不解析变量
=> 函数定义的时候, 函数体内的代码完全不执行
=> 任何变量不做解析
=> 直到 执行 的时候才会 解析变量
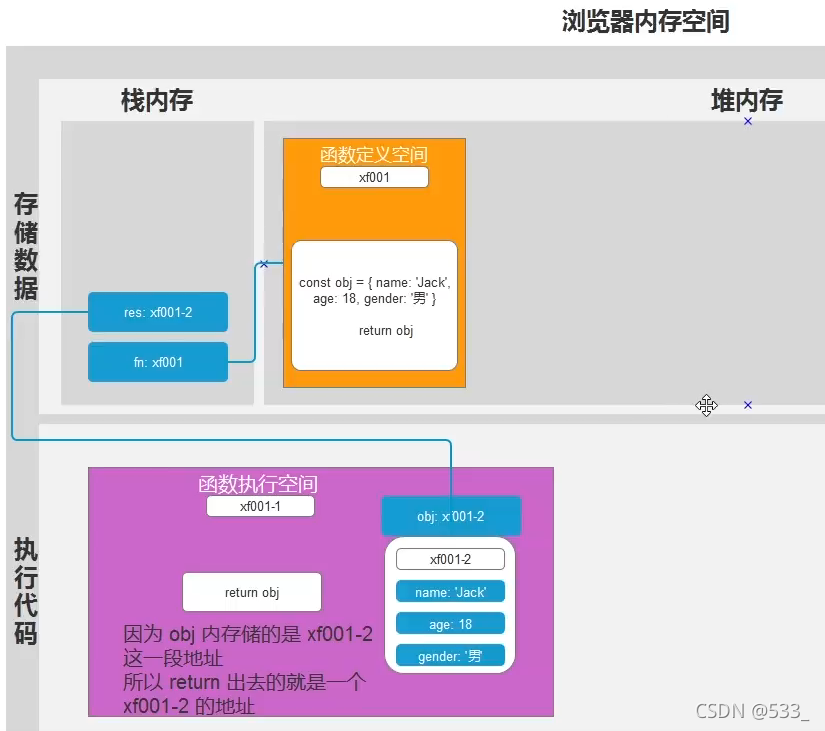
一个不会被销毁的函数执行空间 :
- 当一个函数内返回了一个 复杂数据类型
- 并且该复杂数据类型, 在函数外部有变量接受的情况
- 此时函数执行完毕的执行空间, 不会被销毁掉
- 特点: 延长变量的生命周期
function fn() {
const obj = { name: 'Jack', age: 18, gender: '男' }
// 在函数内返回了一个 复杂数据类型 obj
// 把一个复杂数据类型当做 fn 函数的返回值
return obj
}
// res 接受的就是 fn 函数内执行后的返回值内容
// 也就是 fn 函数内返回的 复杂数据类型( obj 对象 )
// 当函数体内的 return 执行完毕
// 函数就已经执行完毕了, 此时应该销毁函数的执行空间了
// 为了保证今后 res 随时可以访问到 函数内的 obj 空间
// 所以, 函数的执行空间就不允许被销毁
const res = fn()
// 如何让这个空间销毁
// 让外部接受的变量, 不在指向内部的复杂数据类型
// 只要你再次给 res 进行赋值的时候
// fn 之前的执行空间就销毁了
res = null
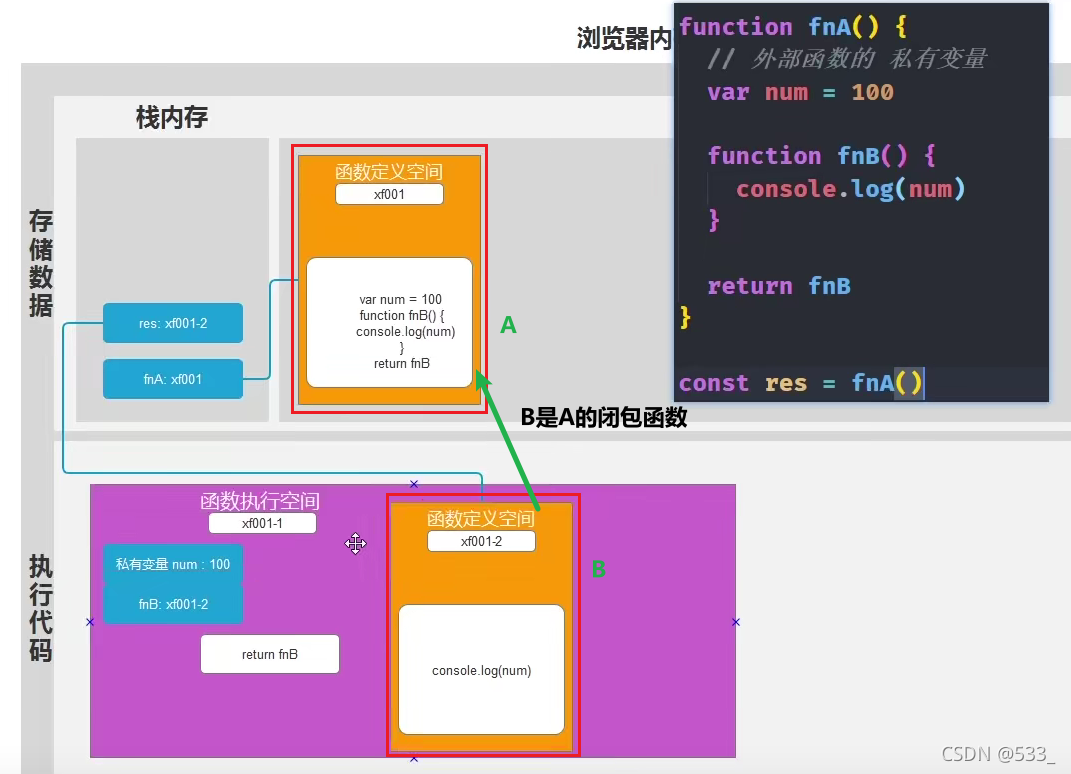
闭包
=> 需要一个不会销毁的函数执行空间
=> 函数内 直接 或者 间接 返回一个新的函数
=> 内部函数要使用着外部函数的私有变量
=> 我们管 内部函数(fnB) 叫做 外部函数(fnA) 的 闭包函数
代码
// 闭包
function fnA() {
// 外部函数的 私有变量
let num = 100
// 私有函数
function fnB() {
// 内部函数使用着外部函数的私有变量
console.log(num) // 控制台打印 => 100
return num
}
// 返回的是一个复杂数据类型
// 并且是一个函数
return fnB
}
// 外部接受
const res = fnA()
闭包的作用 :
- 可以延长变量的声明周期
=> 因为是一个不会销毁的函数空间
=> 优点: 变量声明周期延长了
=> 缺点: 需要一个 闭包 结构 - 可以在函数外部访问函数内部的私有变量
=> 需要利用闭包函数
=> 优点: 访问和使用变得更加灵活了
=> 缺点: 需要一个 闭包 结构 - 可以保护变量私有化
=> 因为只要是函数, 就可以保护私有变量
=> 优点: 变量不会污染全局
=> 缺点: 外部没有办法访问, 如果想要使用, 就得需要写一个 闭包 结构
闭包的缺点 :
- 内存泄漏
- 因为闭包的形成必须伴随一个不会销毁的空间
- 当闭包过多的时候, 就会造成内存过满的情况
- 如果闭包继续增加, 就会导致内存溢出
// 闭包
function fnA() {
// 外部函数的 私有变量
let num = 100
// 私有函数
function fnB() {
// 内部函数使用着外部函数的私有变量
console.log(num) // 控制台打印 => 100
return num
}
// 返回的是一个复杂数据类型
// 并且是一个函数
return fnB
}
// 外部接受
const res = fnA()
// 需求: 在全局访问 fn 函数的 num 变量
// 因为作用域的原因, 只能在 fn 函数内部才可以访问 num 变量
// 全局不能访问
// console.log(num) // 报错 => num is not defined
// 当我调用 res 这个函数的时候
// 你在函数 fnA 的外面是没有办法拿到 num 这个私有变量的
// res 因为是 fn 函数的内部函数, res 可以访问到 fn 函数的私有变量
// n 接受的就是 fnA 函数内定义的 私有变量 num 的值
const n = res()
console.log(n) // 控制台打印 => 100
闭包 _ 面试题 :
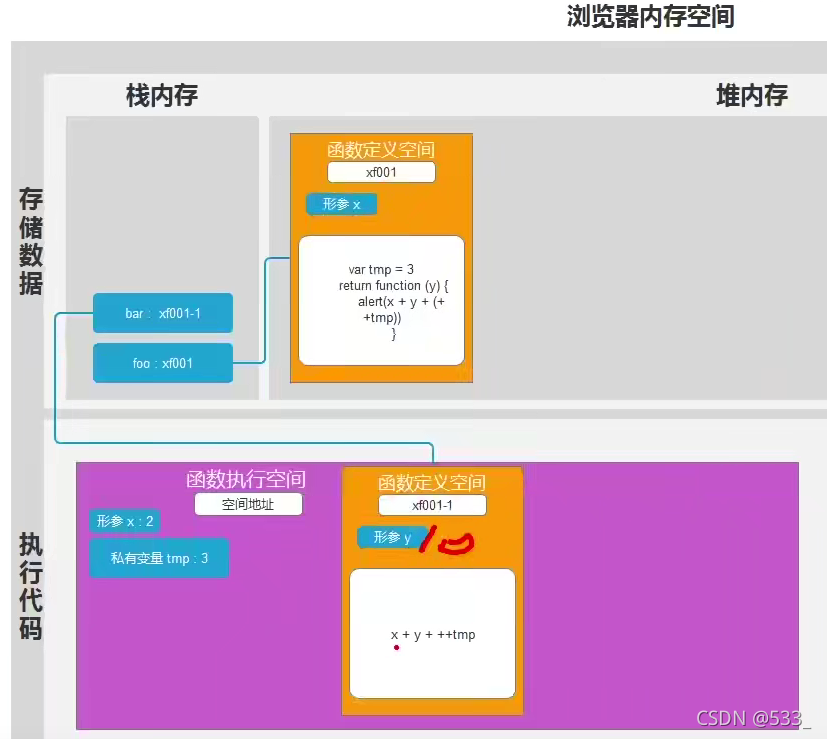
题目1
function foo(x) {
var tmp = 3
return function (y) {
console.log(x + y + (++tmp))
}
}
// 因为 foo() 的返回值是一个函数
// 所以返回值可以被直接调用
// 可以写成 foo(2)(10)
var bar = foo(2)
bar(10) // 16
/*
最终执行 bar(10) 的时候
+ x === 2
+ y === 10
+ tmp === 3
+ 运算: x + y + ++tmp
*/
题目2
function f1() {
var n = 999;
nAdd = function() {
n += 1
}
function f2() {
console.log(n)
}
return f2;
}
var result = f1();
// result 就是 f1 函数内返回的那个叫做 f2 的函数
// 打印出来就是 函数体
console.log(result) // 函数体
result() // 999
// 因为 f1 函数的执行, 导致在全局定义了一个函数, 叫做 nAdd
// 所以这里可以调用
// 因为 nAdd 的调用, 把 f1 函数内的 999 修改为 1000
nAdd()
result() // 1000