京东书籍信息及评论内容爬取
文章目录
前言
本文演示如何从京东爬取书籍信息及评论内容,使用的方法是通过JS分析进行反反爬,不是通过selenium自动化操作,有兴趣的可以参考。
一、京东书籍商品页面分析
从京东首页通过搜索“书籍”来到上图显示页面,现在我要获取这些书籍的【书名】【价格】【评论数】【评论内容】,可以发现如果直接通过requests库直接获取当前页面源代码,只能得到【书名】【价格】,【评论数】在网页源代码中是没有的,是通过JS异步加载的,【评论内容】需要进到每个商品页面去获取,我们后面再说。

这里是页面显示代码

这里是网页源代码

二、解析获取评论数
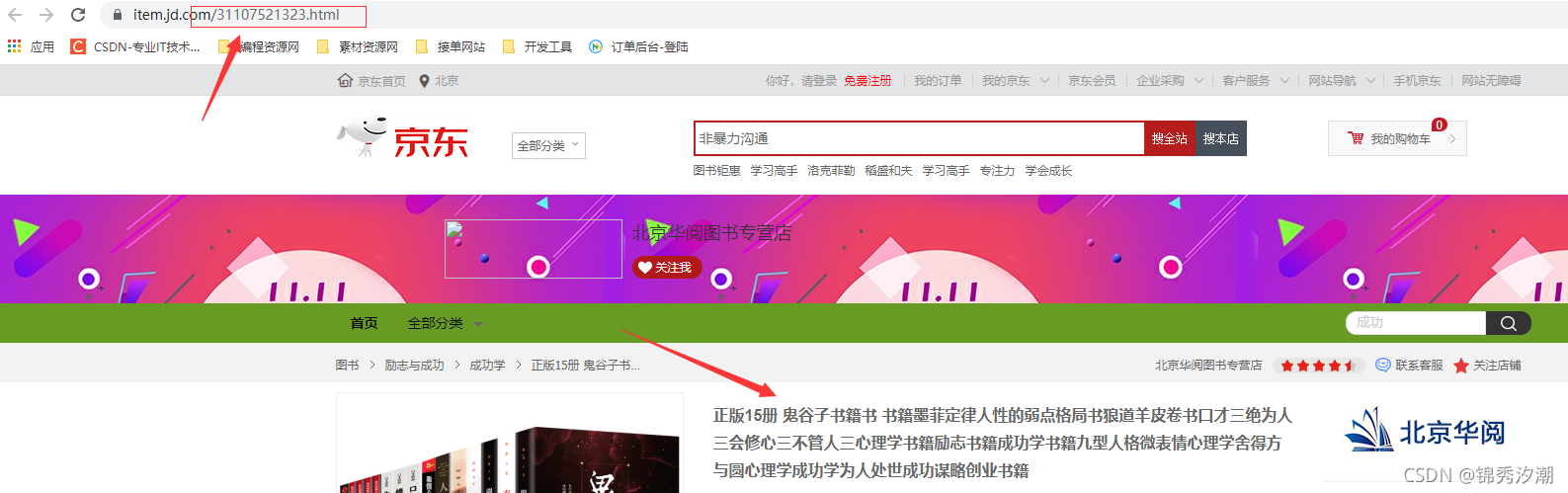
1.每个商品都有一个唯一的ID
我们不难发现,每个商品都有对应的唯一ID,访问的商品信息都是通过这个ID来确定的

2.分析标签,找到过滤词,进而找到需要的请求头
我们找到【评论数】的div标签,可以发现里面有一个链接,我们点击可以发现是进入到该书【评论内容】的详情页。

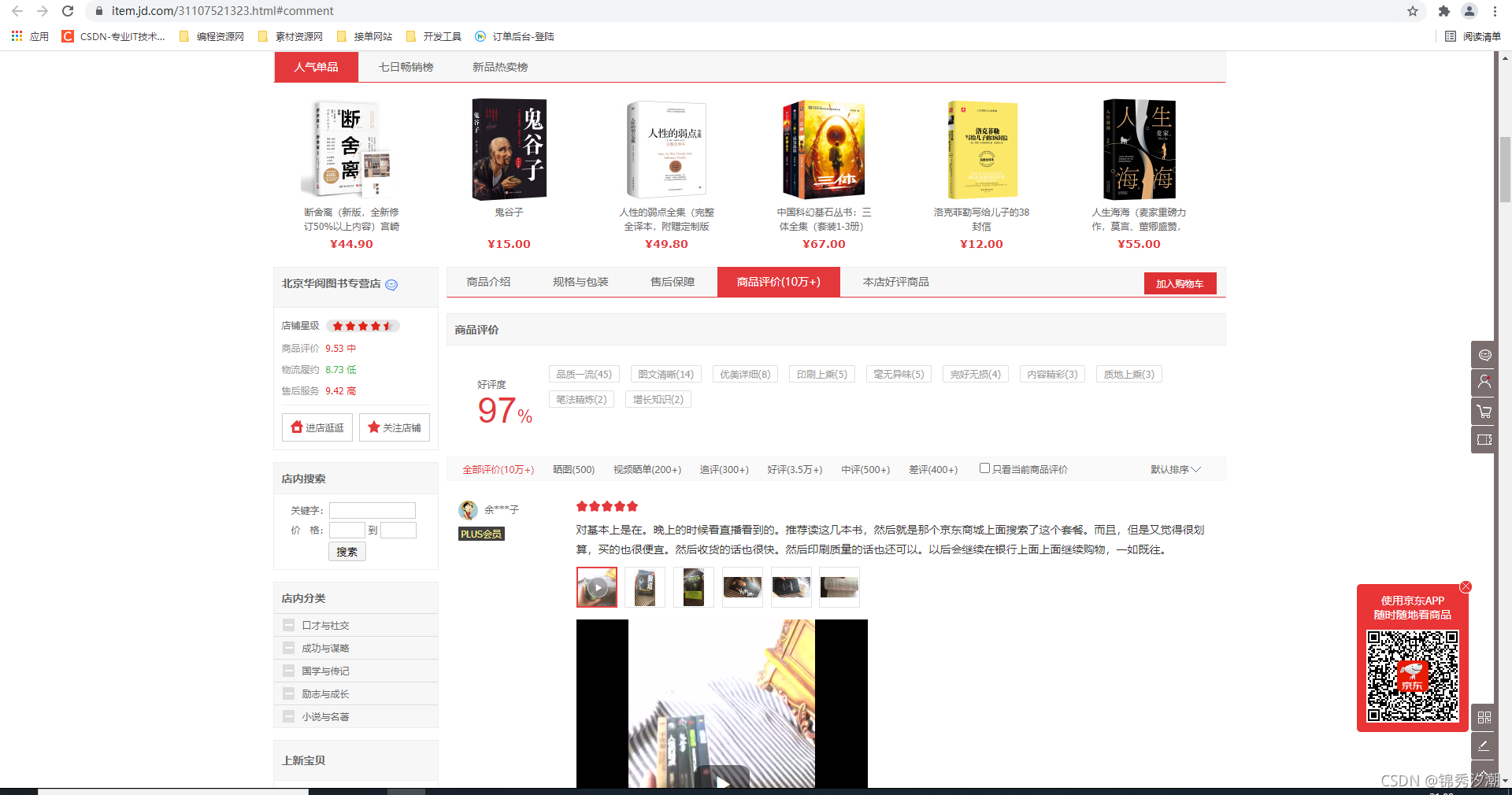
可以发现,里面有一个comment的锚点,前面的a标签的id属性也是(J_comment_31107521323),也有comment这个词,所以我们就尝试查询一下JS文件

结果发现,还真有一个含有商品ID的response返回值,进一步复制出来然后JS美化后得到如下结果
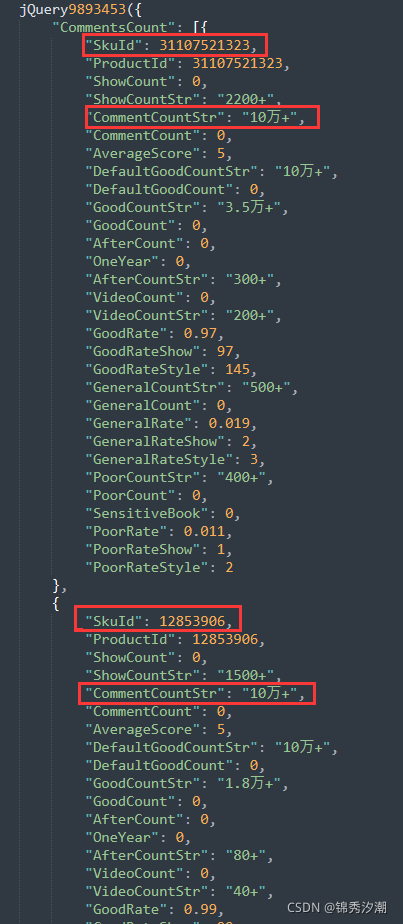
这下就发现,这里面全是商品ID+【评论数】的JSON数据,我们这下在看看请求头

请求的URL:
"https://club.jd.com/comment/productCommentSummaries.action?referenceIds=31107521323,12853906,30116314655,12811942,11970990,13018250,12676018,12498290,12685579,13014236,12653936,12198327,10035634301195,12852516,12768022,13230382,12842790,12856392,56781299750,12579171,11721635,12819136,12882834,10031271962785,11554593536,71871365788,12869807,12610467,12070013,12699287&callback=jQuery9893453&_=1638104433087"
可以发现,获取商品【评论数】数据的请求格式为:
“https://club.jd.com/comment/productCommentSummaries.action?referenceIds=[商品ID]”
3.根据请求头格式,获取商品的评论数
我们尝试一下直接访问,得到如下结果:

好了,说明是没有问题的了,现在开始获取【书名】【价格】【评论数】
import requests
from lxml import etree
import json
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
#访问书籍页面得到里面的书名,价格和商品的ID
start_url = "https://search.jd.com/Search?keyword=书籍"
resp = requests.get(start_url, headers=headers)
text = resp.text
html = etree.HTML(text)
li_list = html.xpath("//div[@id='J_goodsList']/ul/li")
books_info = []
for li in li_list:
book_ID= li.xpath("./@data-sku")[0]
title = "".join(li.xpath(".//div[@class='p-name']//em/text()"))
price = li.xpath(".//div[@class='p-price']//i/text()")[0]
book_info = [book_ID,title,price]
books_info.append(book_info)
#通过ID请求评论数数据
for i in range(0,5):
url = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds=%s"%books_info[i][0]
resp = requests.get(url, headers=headers, proxies=proxy)
text = resp.text
dic = json.loads(text) #将字符串格式转换为JSON对象
comment_num = dic['CommentsCount'][0]['CommentCountStr']
三、解析获取评论内容
1.解析商品评论内容页面
我们进入到商品页面去找评论内容,首先,我们不要下拉,也不要点击【商品评价】,可以发现,刚进入商品页面时,在网页源代码中是没有商品的评论内容的:
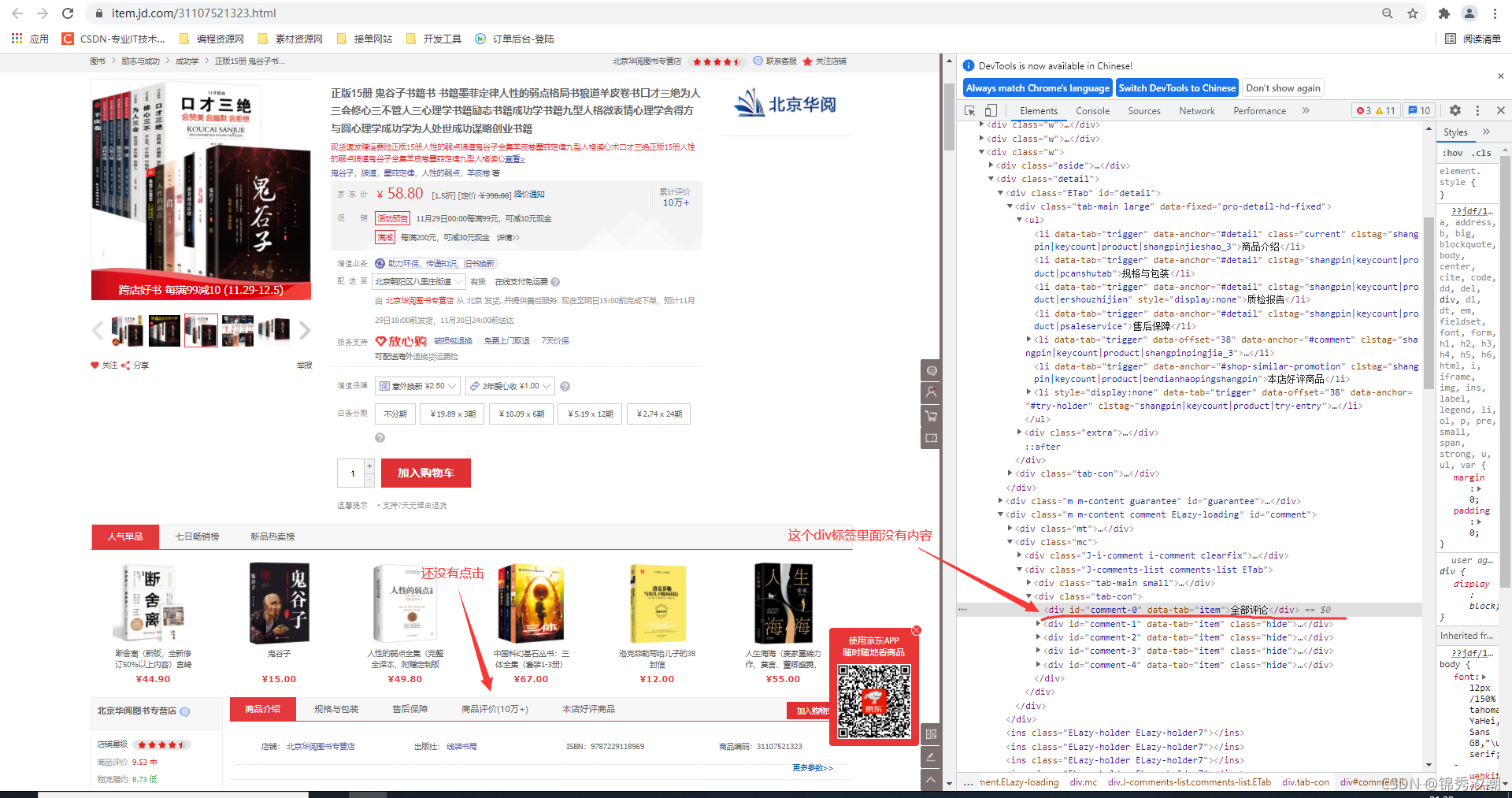
现在我们点击【商品评价】后来看:
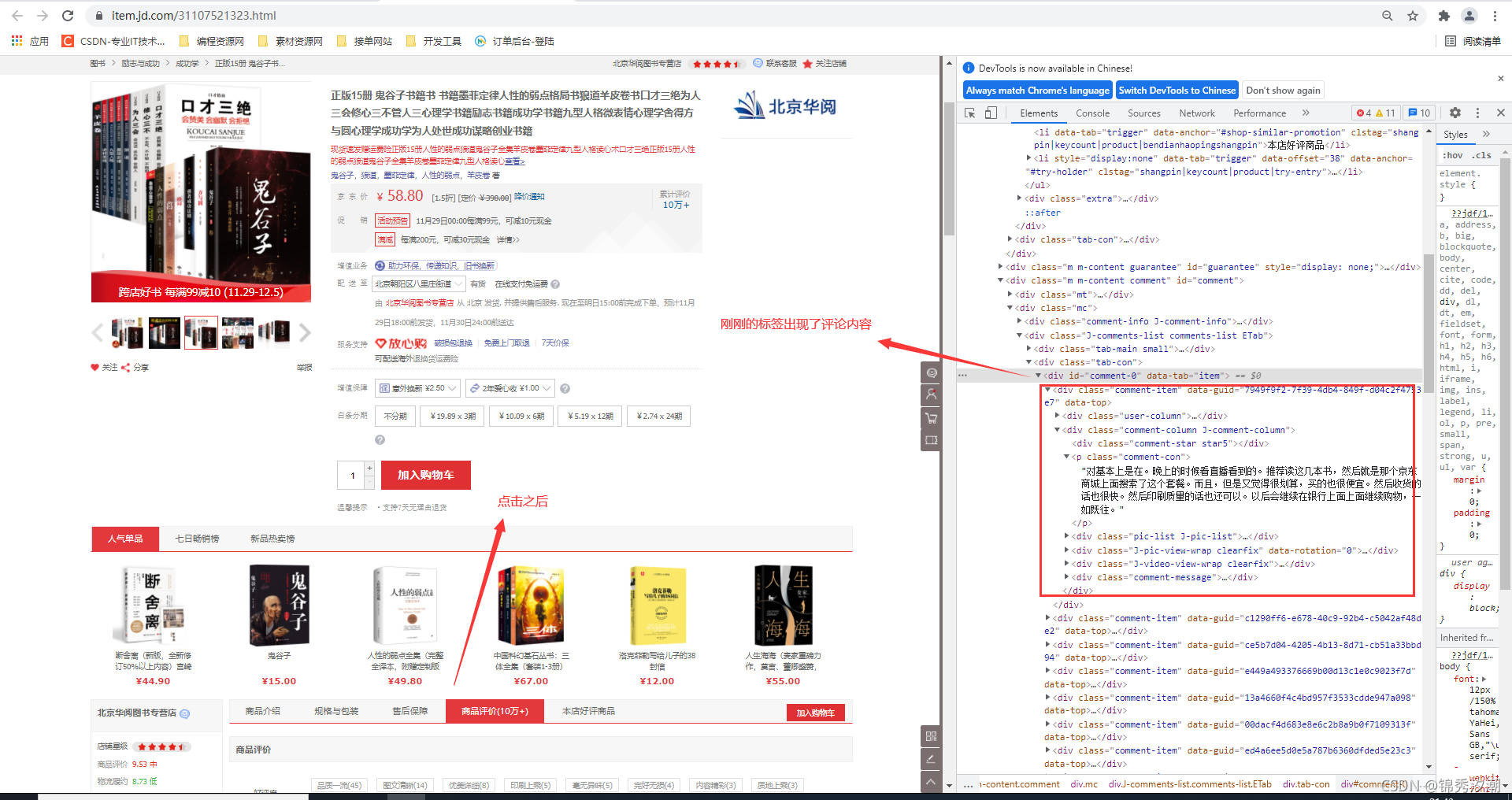
这说明评论的内容也是异步加载的,并不是一开始就出现,点击之后网页源代码中也是没有的
2.找到异步加载商品评论内容的请求格式
现在我们来到谷歌开发者工具里面的Network下,选择JS文件,过滤词还是comment,然后刷新页面:
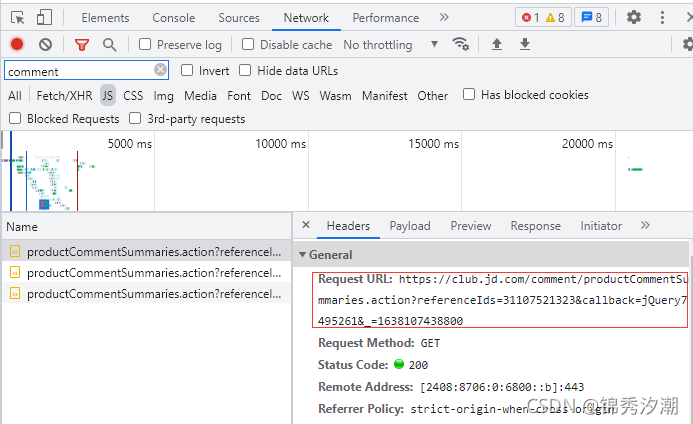
可以发现,此时只有含有商品评论数的数据返回,我们再点击【商品评价】后再看:
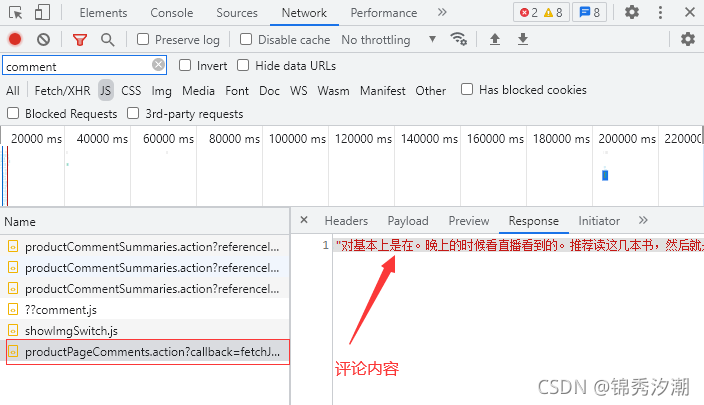
可以发现多出来了3个JS文件,我们依次点击查看,在最后一个发现里面发现了我们想要的评论内容,美化后发现和【评论数】返回的结果类似,都是JSON数据
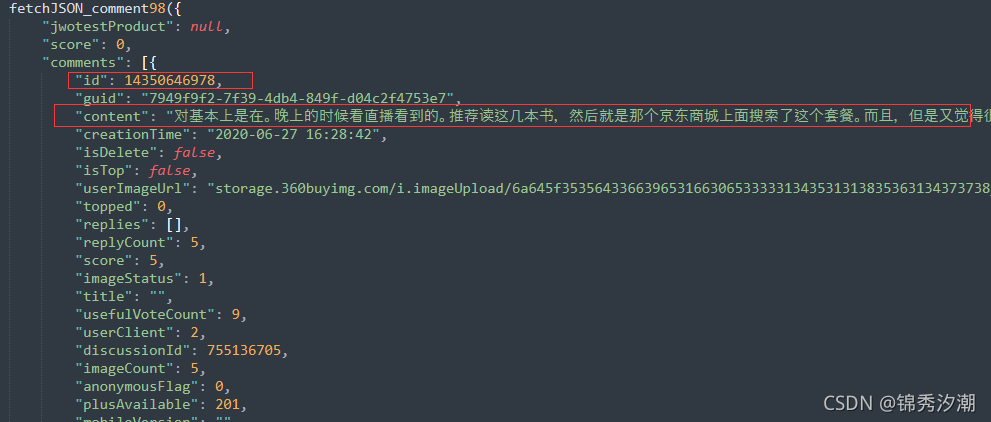
剩下的就简单了,一样分析请求头:
"https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=31107521323&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1"
格式为:
"https://club.jd.com/comment/productPageComments.action?productId=[商品ID]
&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1"
#这后面的是页码选取,有需要自己分析,我这里只选前第一页前10条评论
3.根据请求头模板,得到评论内容
这里直接上代码了
for i in range(0,5):
url = "https://club.jd.com/comment/productPageComments.action?productId=%s&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1"%books_info[i][0]
resp = requests.get(url, headers=headers)
text = resp.text
dic = json.loads(text)
dic_list = dic['comments']
comment_contents = []
for i in dic_list:
comment_content = i['content']
comment_contents.append(comment_content)
总结
爬取京东这类反爬比较强的网站,通过分析JS得到数据,虽说分析过程比较难,但是最后代码很简单,也不容易被反爬机制查出,但是用selenium自动化操作,虽说不用有很深的JS功底,也不用去分析JS文件,但是比较容易被反爬机制查出。