1. 前言
这里完成的工作也就是利用gitee来保存图片。因为在gitee中使用Gitee pages比较方便,可以得到图片的链接地址,用来外用。而我的出发点就是看云的空间有限。那么简单的使用git命令即可将图片上传到码云平台,然后我们找到图片名字,拼接一下就可以得到这个图片的访问路径。但是感觉确实比较麻烦。
所以这里想到的一个略微简化的操作就是:
- 用一个
html页面来显示所有的图片,然后为每个图片提供一个copy link的按钮,点击即可复制到剪切板;
由于后期可能存在图片比较多的情况,所以这里可以将html页面做一个筛选加载,也就是默认就显示一天的截图,或者几天。
那么需要完成的工作就是:
- 扫描本地目录文件,然后拼接对应的
html样式,然后添加到index.html中; - 简单做一个条件加载,默认加载当天的图片资源;
- 添加
copy link的剪切板复制事件;
当然,最后我们的更新还是得依托于git push来进行新图片的更新。
实现
因为我们需要服务端文件扫描,而JavaScript是运行在客户端的,所以这里它并不能完成这个工作。所以我们还需要一个简单的后台服务程序。这里就使用nodejs来实现。首先初始化一下项目:
npm init
npx license mit
npx gitignore node
然后创建一个index.js文件:
const server = require('./server')
server.start()
这里我将开启服务的代码放置在了server.js文件中:
// server.js
var http = require('http')
const router = require('./router')
const imgscan = require('./utils/scanImgFile')
const generateCode = require('./utils/generateCode')
function start() {
const server = http.createServer(function (req, res) {
// 显示内容
router.processRoute(req, res)
// 扫描文件
var keys = imgscan.scan(req, res)
if (global.lastKeys == undefined && keys.length != 0) {
global.lastKeys = keys
generateCode.process(keys)
}
})
server.listen(3001, 'localhost', () => {
console.log(`Server running at http://localhost:3001/`)
})
}
exports.start = start
在server.js文件中需要完成对资源的加载,和对本地文件的扫描的包的调用。对于资源的加载其实也就是响应对应的URL链接地址。这里我封装在router.js:
const fs = require('fs')
const homePage = require('./pages/homePage')
const notfound = require('./pages/notfound')
const examplePages = require('./pages/examplePages')
const struils = require('./utils/stringUtil')
var urlencode = require('urlencode')
const routes = {
login: { page: examplePages.login, type: 'text/plain' },
hello: { page: examplePages.hello, type: 'text/plain' },
index: { page: homePage.home, type: 'text/html' },
errorPage: { page: notfound.notfound, type: 'text/html' },
}
function getType(req, res) {
//文件类型
return req.url.substring(req.url.length - 4, req.url.length)
}
/**
* 处理加载图片
*/
function processImage(req, res) {
var type = getType(req, res)
//资源路径
var fileName = urlencode.decode(__dirname + req.url)
//加载需要显示的图片资源
if (type == '.jpg' || type == '.png' || type == '.gif' || type == '.ico') {
fs.readFile(fileName, 'binary', function (err, file) {
if (err) {
res.writeHead(200, { 'Content-Type': 'text/plain' })
res.end('Resource not exist.')
} else {
res.writeHead(200, { 'Content-Type': 'image/jpeg' })
res.write(file, 'binary')
res.end()
}
})
return true
}
return false // 放行非图片资源
}
/**
* 处理其余链接
*/
function processURL(req, res) {
var url = ''
if (struils.trim(req.url) == '/') url = ''
else url = struils.trim(req.url.substring(1))
// 首页
if (url.length == 0 || url == '' || url == 'index.html' || url == 'index') {
routes.index.page(req, res)
} else if (url == 'login') {
res.writeHead(200, { 'Content-Type': routes.login.type })
res.end(routes.login.page())
} else if (url == 'hello') {
res.writeHead(200, { 'Content-Type': routes.hello.type })
res.end(routes.hello.page())
} else {
// 404
routes.errorPage.page(req, res)
}
}
module.exports = {
/**
* 注册路由信息
* @param {*} maps link: function
*/
registerRoute: function (req, res, maps) {
var url = req.url
},
/**
* 处理路由请求
*/
processRoute: function (req, res) {
// 处理图片
var flag = processImage(req, res)
if (!flag) {
// 其余链接
processURL(req, res)
}
},
}
这里我一共注册了四个页面,分别为login、hello、index以及错误页面。对于processRoute来处理用户链接请求,这里先响应图片资源,如果是图片资源就使用fs来加载对应的图片,需要注意的是因为图片的名字中可能存在中文和空格,所以需要对其进行base64解码:
先安装模块:
npm install urlencode
然后调用:
var urlencode = require('urlencode')
var fileName = urlencode.decode(__dirname + req.url)
进行解码。对于首页,默认可以是:
http://localhost:3001/
http://localhost:3001/index
http://localhost:3001/index.html
比较简单。这里就进入扫描本地目录文件,即scanImgFile.js文件:
// scanImgFile.js
// 扫描目录下的png图片文件
const fs = require('fs')
var maps = {}
module.exports = {
scan: function () {
var path = __dirname.substring(0, __dirname.length - 6)
fs.readdir(path, function (error, files) {
for (var i = 0; i < files.length; i++) {
var fileName = files[i].toString()
if (fileName.length > 4) {
if (
fileName.endsWith('.png') ||
fileName.endsWith('.jpg') ||
fileName.endsWith('.gif')
) {
maps[fileName] = 1
}
}
}
})
return Object.keys(maps)
},
}
还是使用fs来进行操作,因为对象的存储有点类似字典,所以这里就用对象去重。然后返回keys即可。
最后一步就是生成HTML代码,对于代码的生成,应该先写好最终的表现,然后再考虑拼接问题。在HTML页面中涉及到内容复制到剪切板:
<script>
window.onload = function () {
const baseURL = 'http://weizu_cool.gitee.io/gif-source/'
var imgs = document.getElementsByClassName('image')
var btns = document.getElementsByClassName('copy-btn')
for (var i = 0; i < btns.length; i++) {
btns[i].onclick = function () {
var image = this.parentNode.getElementsByTagName('img')[0]
var url = baseURL + image.getAttribute('src') // 获取到待拷贝字符串
var input = document.createElement('input')
input.setAttribute('readonly', 'readonly')
input.setAttribute('value', url)
document.body.appendChild(input)
input.select()
var res = document.execCommand('copy')
? '复制链接成功!'
: '复制链接失败!'
document.body.removeChild(input)
alert(res)
}
}
}
</script>
然后对于代码的生成我将目标代码分为两个部分,首部和尾部,然后进行动态拼接,即generateCode.js:
// generateCode.js
// 生成HTML文件
const fs = require('fs')
function getFileName(filename) {
return filename.substring(0, filename.length - 4)
}
module.exports = {
process: function (keys) {
var res = fs.readFileSync(__dirname + '/forePage.txt', 'utf8')
for (var i = 0; i < keys.length; i++) {
res +=
'<div class="image"><div class="image-view"><img src="' +
keys[i] +
'" /></div><p class="image-title">' +
getFileName(keys[i]) +
'</p><span class="copy-btn">copy link</span></div>'
}
res += fs.readFileSync(__dirname + '/afterPage.txt', 'utf8')
// 写文件
fs.writeFileSync('index.html', res)
},
}
最终效果,即当文件保存到本地资源目录中后,重新运行后台服务,即:node index.js
刷新就可以得到效果:
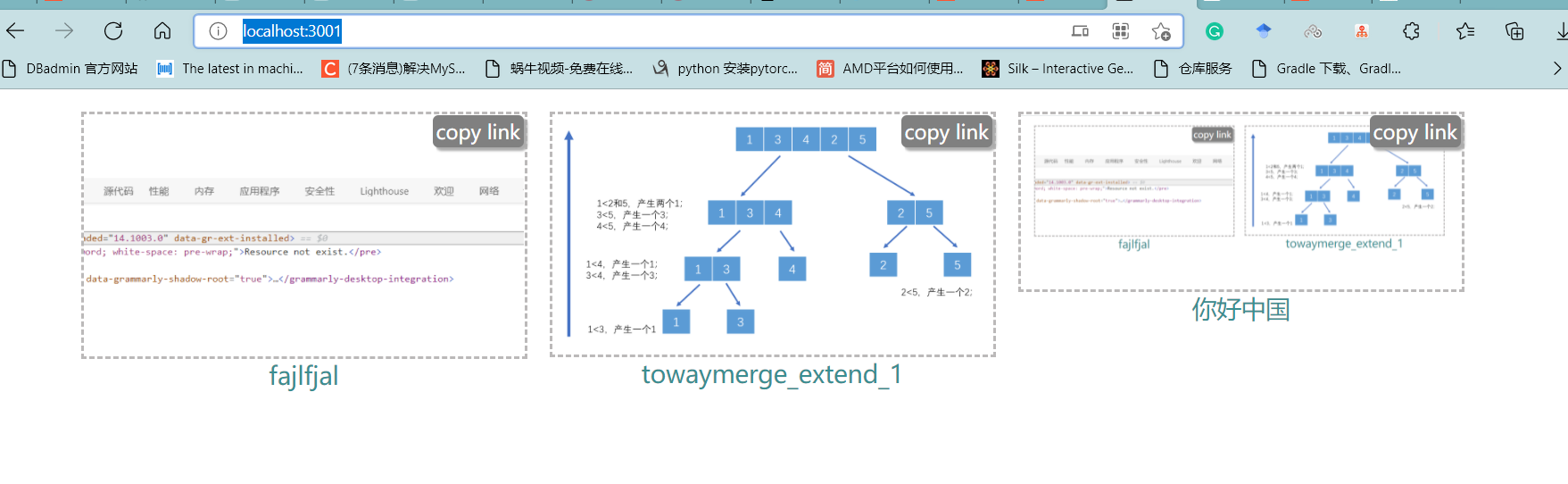
当然,因为我的目的是在服务器上保存,所以这里需要使用git push推送资源到gitee,然后重新部署一下Gitee Pages:
访问链接:http://weizu_cool.gitee.io/gif-source

然后就可以copy link进行复制链接。
But,虽然实现了,却更加复杂了!