文章目录
魔改 mammoth 支持导入样式
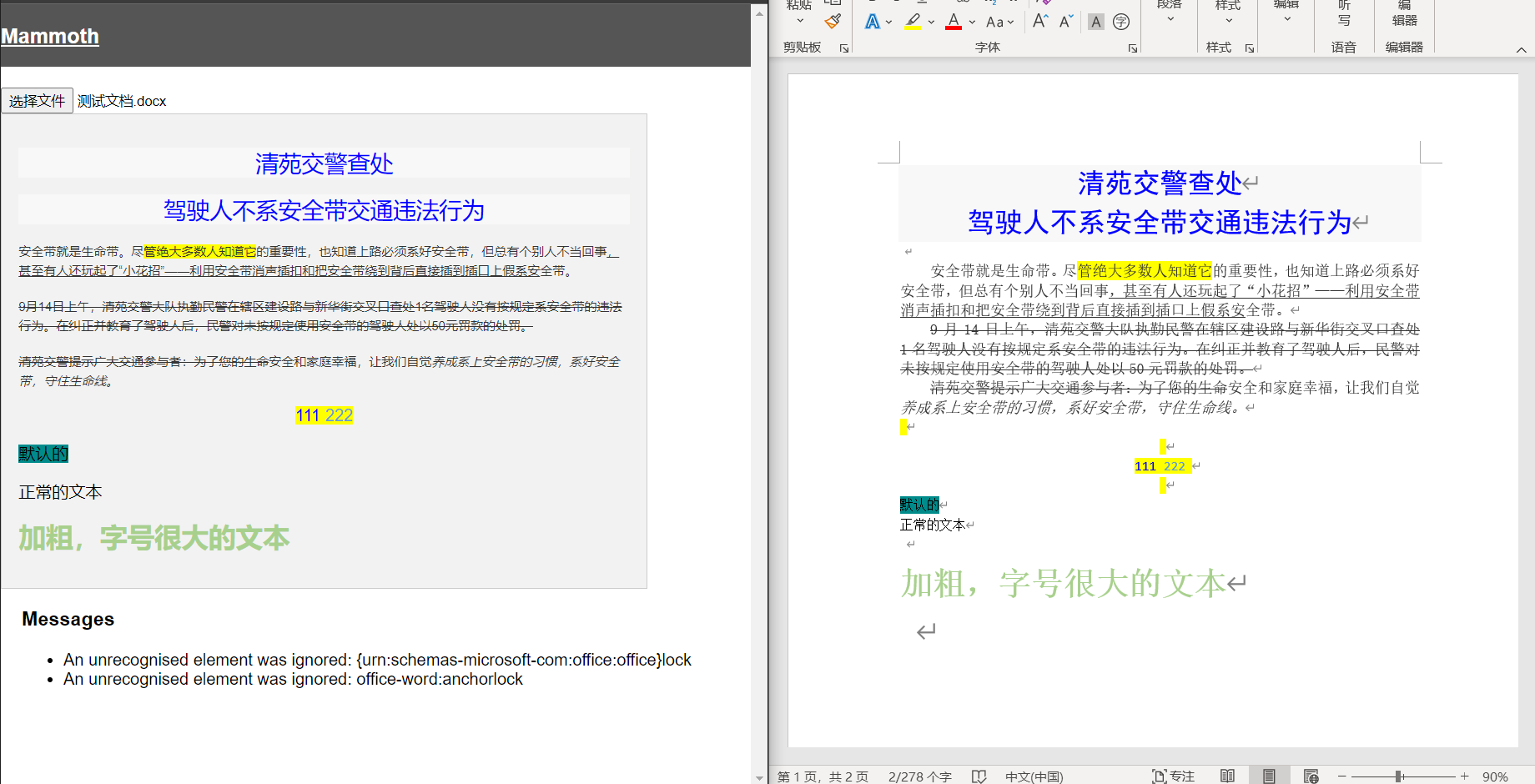
先来一张效果图,改造后导入 word 文档显示如下:
mammoth.js 简单介绍
预览效果地址 在浏览器中预览 word docx 文档示例 demo
github 链接 mwilliamson/mammoth.js
我的魔改版本 github 链接 Jioho/mammoth.js
mammoth.js 识别 word 文档的原理其实就是 解压 .docx + 解析 xml 结构,分析出来对应的节点,拼接为 html 字符串
为什么只能支持 .docx ? 简单来说就是因为 .doc 的文档不能解压。
把 .docx 后缀直接改成 .zip 然后解压你会看到大概如下的目录
.
|-- [Content_Types].xml
|-- _rels
|-- customXml
| |-- _rels
| | `-- item1.xml.rels
| |-- item1.xml
| `-- itemProps1.xml
|-- docProps
| |-- app.xml
| |-- core.xml
| `-- custom.xml
`-- word
|-- _rels
| `-- document.xml.rels
|-- document.xml
|-- fontTable.xml
|-- settings.xml
|-- styles.xml
`-- theme
`-- theme1.xml
其中需要解析的文件就是 word/document.xml。
跑通 mammoth 源码
- 编译问题
首先要跑通编译的问题,不然改了源码也打包不出来
npm install 安装依赖后,会紧接着运行一个 make mammoth.browser.min.js 的命令。这里可以看下 makefile这个文件
看到有一条:make mammoth.browser.min.js ,该命令先执行了 mammoth.browser.js(其实这个才是真正的打包) 第二步才调用 node_modules/.bin/uglifyjs 进行压缩
window 下应该是没有这个命令的(其他系统还没试过),那么就需要安装
MinGW来添加 make 命令。
安装过程我就略过了,所以这一步有兴趣的可以自行安装MinGW,然后下载感受一下不排除后面会出文章记录一下安装的过程
如果不用 make ,只需要添加 2 行运行命令。同时删除 “prepublish” 的命令,否则 npm install 的时候也会自动执行这个命令执行 make 就报错了
- package.json
"build:browser": "browserify lib/index.js --standalone mammoth > mammoth.browser.js",
"build": "npm run build:browser && uglifyjs mammoth.browser.js > mammoth.browser.min.js",
运行 npm run build 就可以看到生成对应的 .browser.js 和 min.js 了
唯一的区别就是少了原版把依赖包信息也输入进去
- eslint 和 单元测试
在没改过代码的情况下,跑一下npm run pretest 和 npm run test。正常都是可以跑通的
window 下,npm run test 可能会报错
Error: cannot resolve path (or pattern) ‘‘test/**/*.tests.js’’
其实就是 package.json 的 test 命令多了一个''的缘故,如果看到上面的报错,把 test 命令改成mocha test/**/\*.tests.js就可以了
eslint 校样只提供了校验规则,并没有提供格式化的配置。。。所以等下会把配置补上,用插件来格式化代码
配置编辑器格式化方案
eslint 和 prettier 的恩怨情仇我已经不想多说,但是有一个最重要的一点就是 函数名后面空格的问题
- 用 prettier 插件是无法配置函数名后面的空格问题的
- 用 vscode 自己的 format,然后加上配置
"javascript.format.insertSpaceBeforeFunctionParenthesis": false确实可以 50%。
还有 50%呢?匿名函数的 function (){} 后面还是带了空格
所以直接放弃挣扎,安装另外一个插件 Prettier ESLint
然后修改一下 vscode 格式化的配置:
由于我不是每个项目都会用到这份配置,所以我是在当前项目下新建的
.vscode/settings.json来单独约束这个项目
eslint 插件记得也要装,然后启用
核心就是 JS 部分格式化用的是 rvest.vs-code-prettier-eslint
{
"eslint.enable": true,
"eslint.codeAction.showDocumentation": {
"enable": true
},
"eslint.validate": ["javascript", "javascriptreact"],
"editor.formatOnSave": false,
"editor.codeActionsOnSave": {
"source.fixAll": true // 保存时使用eslint校验文件
},
"[javascript]": {
"editor.defaultFormatter": "rvest.vs-code-prettier-eslint"
}
}
Prettier ESLint 不能正常格式化
可能每个环境的情况都不一样,打开终端看报错信息才是最快的定位方法
我的情况应该是少了 prettier 库,我试过全局安装并不生效。。所以还是在项目里面装了一个

魔改一:添加 dev 更新支持
项目之前打包用的是 browserify 这个打包工具。 本想用 webpack 打包一个,后来太多坑了,放弃了
后面改为使用 watchify 用作监听文件重新触发打包,打包还是使用 browserify ,用 http-server 作为本地服务器启动
- 安装需要的依赖包
npm i watchify http-server -D
- package.json 文件添加启动命令
"dev": "node bin/dev"
- 在
bin目录下新建一个 dev 文件
var fs = require('fs')
var browserify = require('browserify')
var watchify = require('watchify')
var { createServer } = require('http-server')
var b = watchify(
browserify({
entries: 'lib/index.js',
standalone: 'mammoth',
cache: {},
packageCache: {}
})
)
b.on('update', bundle)
b.on('log', msg =>
console.log(
`${new Date().toISOString()} ${msg}
app run at http://localhost:8080/browser-demo/
`
)
)
function bundle() {
b.bundle().on('error', console.error).pipe(fs.createWriteStream('mammoth.browser.js'))
}
function server() {
createServer().listen(8080)
}
server()
bundle()
简单说一下:
- 原始打包输出的目录(mammoth.browser.js)是输出到根目录的,所以这里也保持这个设定
- 用 http-server 启动 8080 端口,这里没指定目录,所以启动目录是项目的根目录,刚好就能访问打包的文件了
- 在每次打包的时候都会输出新的 msg ,用作看到 node 服务还在运行
- 还没做进去的细节
- 还没加上本地 IP 的显示,端口被占用的时候不能自动切换
- 输出的 msg 是累加的,而不是刷新旧的 msg
等等细节问题,不过这并不影响开发,就不考虑那么多
运行 npm run dev
看源码部分,理解 xml 是如何转换为 html 的
由于源码非常的多,这里就不会一点点开始讲解,后面会直接挑 需要改动的文件 的部分代码分析其作用。
如果想了解完整的解析流程就自己多花点时间看看
印象中大概的流程是: 解压 docx 文件 -> 解析 xml -> 暴露钩子给业务做转换 -> 内置的样式映射 -> 解析节点信息为 html -> 输出完整结果
后面将会讲解的部分是 解析 xml 和 解析节点信息为 html
了解 word 的 xml 语法
先看看我准备的 word 文档截图

word/document.xml(从 word 文档改成.zip 解压出来的 xml 文件)
丢到编辑器里面设置编码为 html 格式化一下方便查看
节选某一段 xml
<w:body>
<w:p w14:paraId="0917FC78" w14:textId="77777777" w:rsidR="00875CB7" w:rsidRDefault="00875CB7" w:rsidP="00875CB7">
<w:pPr>
<w:widowControl />
<w:shd w:val="clear" w:color="auto" w:fill="F8F8F9" />
<w:spacing w:line="623" w:lineRule="atLeast" />
<w:jc w:val="center" />
<w:outlineLvl w:val="1" />
<w:rPr>
<w:rFonts w:ascii="黑体" w:eastAsia="黑体" w:hAnsi="黑体" w:cs="宋体" />
<w:color w:val="0000FF" />
<w:kern w:val="0" />
<w:sz w:val="44" />
<w:szCs w:val="44" />
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:ascii="黑体" w:eastAsia="黑体" w:hAnsi="黑体" w:cs="宋体" w:hint="eastAsia" />
<w:color w:val="0000FF" />
<w:kern w:val="0" />
<w:sz w:val="44" />
<w:szCs w:val="44" />
</w:rPr>
<w:t>清苑交警查处</w:t>
</w:r>
</w:p>
<!-- 省略其他很多内容 -->
<w:p w14:paraId="50E8C12B" w14:textId="77777777" w:rsidR="00875CB7" w:rsidRDefault="00875CB7" w:rsidP="00875CB7">
<w:pPr>
<w:rPr>
<w:rFonts w:ascii="Consolas" w:hAnsi="Consolas" w:cs="Consolas" />
<w:b />
<w:bCs />
<w:color w:val="A8D08D" />
<w:sz w:val="52" />
<w:szCs w:val="52" />
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:ascii="宋体" w:hAnsi="宋体" w:cs="Consolas" w:hint="eastAsia" />
<w:b />
<w:bCs />
<w:color w:val="A8D08D" />
<w:sz w:val="52" />
<w:szCs w:val="52" />
</w:rPr>
<w:t>加粗,字号很大的文本</w:t>
</w:r>
</w:p>
<!-- 省略 -->
</w:body>
从上面看 w:p 可以理解为一个 段落,用html来说就是p标签,然后很多属性的字段都隐藏于这个段落中。
比如
- 字体颜色
<w:color w:val="0000FF" /> - 居中显示
<w:jc w:val="center" /> - 字号大小
<w:szCs w:val="52" /> - 文字背景色
<w:highlight w:val="yellow" /> - 块状背景色
<w:shd w:val="clear" w:color="auto" w:fill="F8F8F9" />
等等
源码部分 - 解析 xml 文件内容
了解 xml 基础组成部分后,看看源码是在哪里解析这部分内容的
lib/docx/body-reader.js
找到 xmlElementReaders 代码块,里面包含了许多解析对应 xml 块的方法,如果我们想添加样式解析,需要知道我们要解析的标签在哪个 xml 模块中
以上面列出的为例:
<w:shd>就是在<w:pPr>中,这种就要放在 “w:pPr” 中去解析<w:color>在<w:rPr>中,这种就要放在 “w:rPr” 中去解析
以此类推
// 节选部分代码
var xmlElementReaders = {
'w:p': function (element) {},
'w:pPr': function (element) {
return readParagraphStyle(element).map(function (style) {
return {
type: 'paragraphProperties',
styleId: style.styleId,
styleName: style.name,
alignment: element.firstOrEmpty('w:jc').attributes['w:val'],
numbering: readNumberingProperties(style.styleId, element.firstOrEmpty('w:numPr'), numbering),
indent: readParagraphIndent(element.firstOrEmpty('w:ind'))
}
})
},
'w:r': function (element) {
return readXmlElements(element.children).map(function (children) {
var properties = _.find(children, isRunProperties)
children = children.filter(negate(isRunProperties))
var hyperlinkOptions = currentHyperlinkOptions()
if (hyperlinkOptions !== null) {
children = [new documents.Hyperlink(children, hyperlinkOptions)]
}
return new documents.Run(children, properties)
})
},
'w:rPr': readRunProperties
// ...
}
通过源码的示例可以看出,需要解析某个属性的话只需要调用封装好的方法 firstOrEmpty 然后通过attributes 获取对应的值
element.firstOrEmpty('w:jc').attributes['w:val']
源码部分 - 记录节点信息
了解如何解析 xml 属性后,在最后都会调用 对应的 document.XXX 方法,以 w:r 为例,最后调用了 new documents.Run(children, properties)
其中 document 就是从 lib\documents.js 引入,对应的 Run 方法如下:
function Run(children, properties) {
properties = properties || {}
return {
type: types.run,
children: children,
styleId: properties.styleId || null,
styleName: properties.styleName || null,
isBold: properties.isBold,
isUnderline: properties.isUnderline,
isItalic: properties.isItalic,
isStrikethrough: properties.isStrikethrough,
isAllCaps: properties.isAllCaps,
isSmallCaps: properties.isSmallCaps,
verticalAlignment: properties.verticalAlignment || verticalAlignment.baseline,
font: properties.font || null,
fontSize: properties.fontSize || null
}
}
简单来说就是:如果想添加自己的样式解析,那么需要在 lib/docx/body-reader.js 添加节点的解析,获取属性,然后在 lib\documents.js 找到对应的节点类型,添加相关的属性,这样后续的节点才能获取到对应的属性。
如果只是在 lib/docx/body-reader.js 添加了解析,没在 documents 添加映射,那属性也不会流转到下一个步骤去
源码部分 - 节点属性解析为 html
进过上面的流程后会得到一个记录节点信息的数组,数组中的内容就是节点的类型和节点对应的属性,源码部分就可以看 lib\document-to-html.js 文件
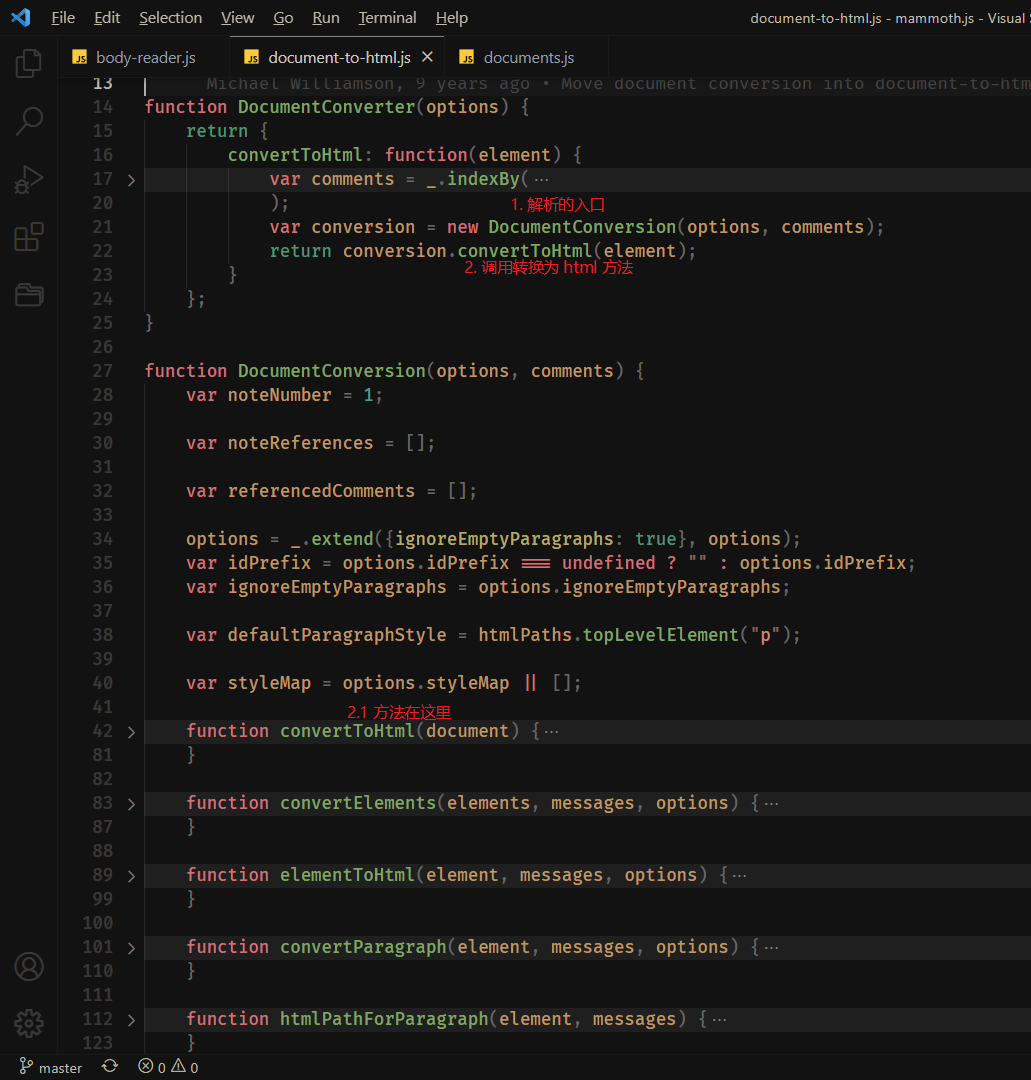
- 文件入口和执行顺序
-
解析流程如下
代码有点多,我就不拷贝出来了,可以看下图中我标记的地方
- 标记 1: flatMap 其实就是一个循环(因为节点是多层嵌套的,所以源码自己实现了一个递归的循环用于获取每个节点)
- 标记 2: 开始转换每一个节点转换为对应的 html 节点了
- 标记 3: 标记 3 和标记 4 连着一起看,在解析 xml 的时候每个节点已经被划分好了类型,所以他们对应的解析方法也是不一样的,所以最终的解析是进入到了标记 4 中对应的方法里面
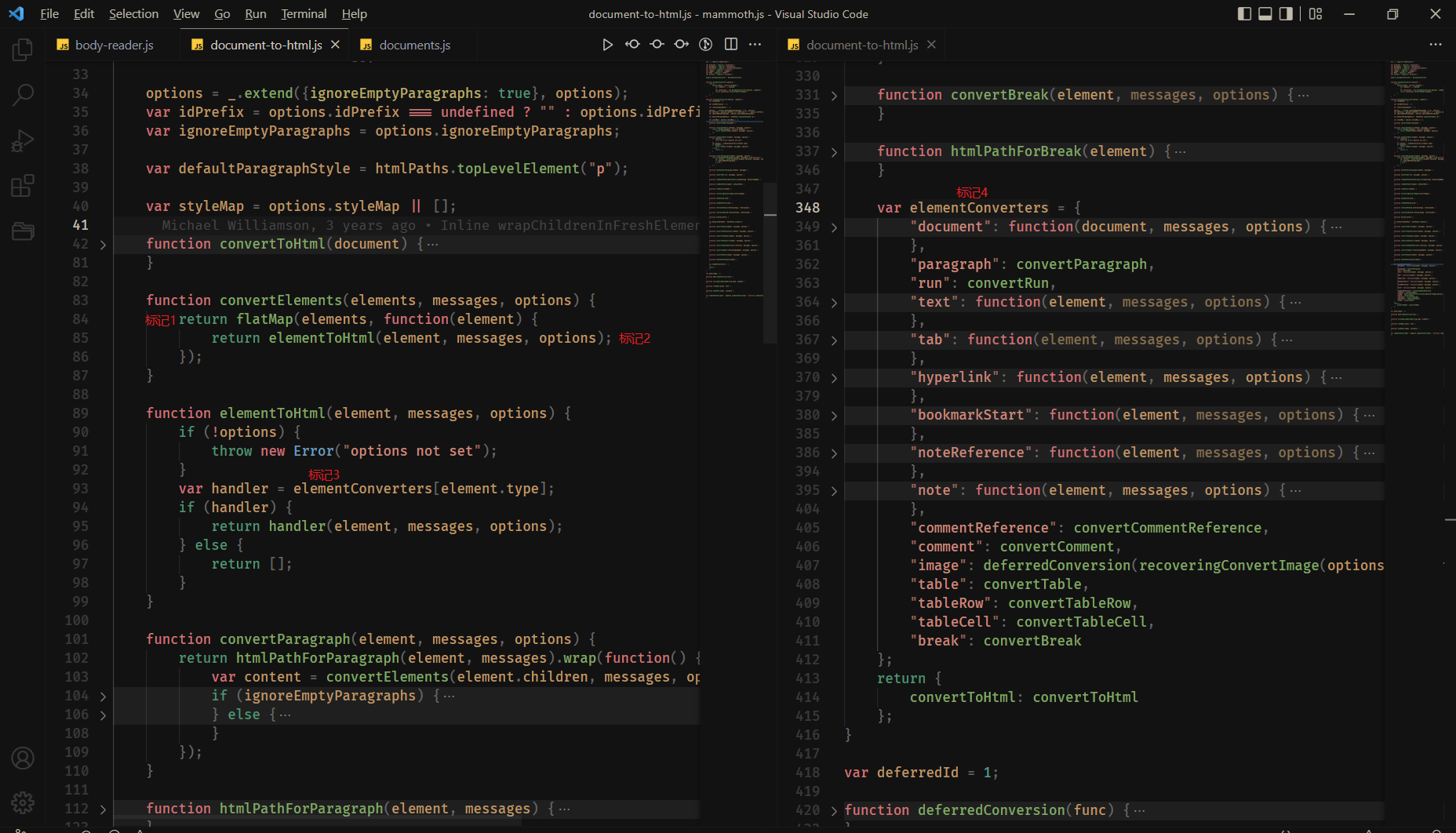
源码部分 - 如何为 html 节点写入样式
研究这个问题前先说一下节点信息是如何转换为实际 html 节点的
这部分代码都在 htmlPaths 里面,对应的模块文件是 lib\styles\html-paths.js
可以在当前的 js 文件搜索一下 htmlPaths.element 这个方法接收 3 个参数
- lib\styles\html-paths.js
// 标签名称(p/span/table...), 标签属性值(class/style/alt...), 子节点内容/其他配置
function element(tagName, attributes, options) {
options = options || {}
return new Element(tagName, attributes, options)
}
// 示例: 创建一个居中的p标签,内容为 “我是居中的内容”
element('p', { style: 'text-anlign:center;' }, '我是居中的内容')
创建虚拟节点的方式和 vue 创建虚拟节点很像,参数和用法都很像
所以我们解析出来的 style 就需要传入到 attributes 对象里面
魔改二:实现部分样式的修改
了解 xml 的一些简单语法和源码调用位置后,就可以开始考虑解析部分样式
我魔改的部分不一定值得学习(可能也不太规范),后面的内容仅供参考
接下来会用这样的一份文档作为效果演示

这个是没改之前 mammoth 解析出来的效果

说一下解析目标(基本上常用的样式也就这些了):
- 第一段落中的段落背景色
- 字体颜色,大小
- 段落中的居中
- 文字的背景色
- 下划线
添加样式属性解析
打开解压后的 word 文件夹中的word/document.xml
-
段落背景和段落对齐方式
- w:shd 段落背景
- w:jc 段落对齐方式
<w:pPr> <w:shd w:val="clear" w:color="auto" w:fill="F8F8F9" /> <w:jc w:val="center" /> </w:pPr> -
文字颜色,大小,背景色
- w:color 字体颜色
- w:szCs 字体大小
- w:highlight 背景色
<w:rPr> <w:color w:val="0000FF" /> <w:szCs w:val="44" /> <w:highlight w:val="darkCyan" /> </w:rPr> -
lib\docx\body-reader.js
找到
"w:pPr"部分,由于颜色的话有字面量颜色和 16 进制的颜色,而且背景色和字体色都会用到,所以新增一个读取颜色的方法
fontSize 、isUnderline 、alignment 3 个属性其实一开始是有解析的,只是后面没用上,那么就不需要额外的处理了,在后面的逻辑处理用上就好
var xmlElementReaders = {
// ...省略很多代码
'w:pPr': function (element) {
return readParagraphStyle(element).map(function (style) {
return {
type: 'paragraphProperties',
styleId: style.styleId,
styleName: style.name,
alignment: element.firstOrEmpty('w:jc').attributes['w:val'],
numbering: readNumberingProperties(style.styleId, element.firstOrEmpty('w:numPr'), numbering),
indent: readParagraphIndent(element.firstOrEmpty('w:ind')),
bgColor: readColor(element.firstOrEmpty('w:shd')) // 添加背景色的解析
}
})
}
// ...省略很多代码
}
function readRunProperties(element) {
return readRunStyle(element).map(function (style) {
var fontSizeString = element.firstOrEmpty('w:sz').attributes['w:val']
// w:sz gives the font size in half points, so halve the value to get the size in points
var fontSize = /^[0-9]+$/.test(fontSizeString) ? parseInt(fontSizeString, 10) / 2 : null
return {
type: 'runProperties',
styleId: style.styleId,
styleName: style.name,
verticalAlignment: element.firstOrEmpty('w:vertAlign').attributes['w:val'],
font: element.firstOrEmpty('w:rFonts').attributes['w:ascii'],
fontSize: fontSize,
isBold: readBooleanElement(element.first('w:b')),
isUnderline: readUnderline(element.first('w:u')),
isItalic: readBooleanElement(element.first('w:i')),
isStrikethrough: readBooleanElement(element.first('w:strike')),
isAllCaps: readBooleanElement(element.first('w:caps')),
isSmallCaps: readBooleanElement(element.first('w:smallCaps')),
color: readColor(element.firstOrEmpty('w:color')), // 添加文字颜色解析
bgColor: readColor(element.firstOrEmpty('w:highlight')) // 文本的背景色是 w:highlight 和段落的背景色有所不同
}
})
}
// 新增获取颜色方法
function readColor(element) {
var value = element.attributes['w:fill'] || element.attributes['w:val']
if (!value || value === 'none') {
return null
}
return /^([0-9a-fA-F]{6}|[0-9a-fA-F]{3})$/.test(value) ? '#' + value : value
}
- lib\documents.js
根据上一个文件改的类型可以看到,对应的 type 分别是 paragraphProperties 和 runProperties。在 documents 对应如下:
function Paragraph(children, properties) {
properties = properties || {}
var indent = properties.indent || {}
return {
type: types.paragraph,
children: children,
styleId: properties.styleId || null,
styleName: properties.styleName || null,
numbering: properties.numbering || null,
alignment: properties.alignment || null,
indent: {
start: indent.start || null,
end: indent.end || null,
firstLine: indent.firstLine || null,
hanging: indent.hanging || null
},
bgColor: properties.bgColor || null // 段落新增背景色属性
}
}
function Run(children, properties) {
properties = properties || {}
return {
type: types.run,
children: children,
styleId: properties.styleId || null,
styleName: properties.styleName || null,
isBold: properties.isBold,
isUnderline: properties.isUnderline,
isItalic: properties.isItalic,
isStrikethrough: properties.isStrikethrough,
isAllCaps: properties.isAllCaps,
isSmallCaps: properties.isSmallCaps,
verticalAlignment: properties.verticalAlignment || verticalAlignment.baseline,
font: properties.font || null,
fontSize: properties.fontSize || null,
// 文本新增背景色和字体颜色
bgColor: properties.bgColor || null,
color: properties.color || null
}
}
以上的解析加完后,可以到 lib\document-to-html.js 文件打印看看效果
function DocumentConverter(options) {
return {
convertToHtml: function (element) {
var comments = _.indexBy(element.type === documents.types.document ? element.comments : [], 'commentId')
var conversion = new DocumentConversion(options, comments)
// eslint 代码不允许打log,所以先临时禁用一下
// eslint-disable-next-line no-console
console.log(element)
return conversion.convertToHtml(element)
}
}
}
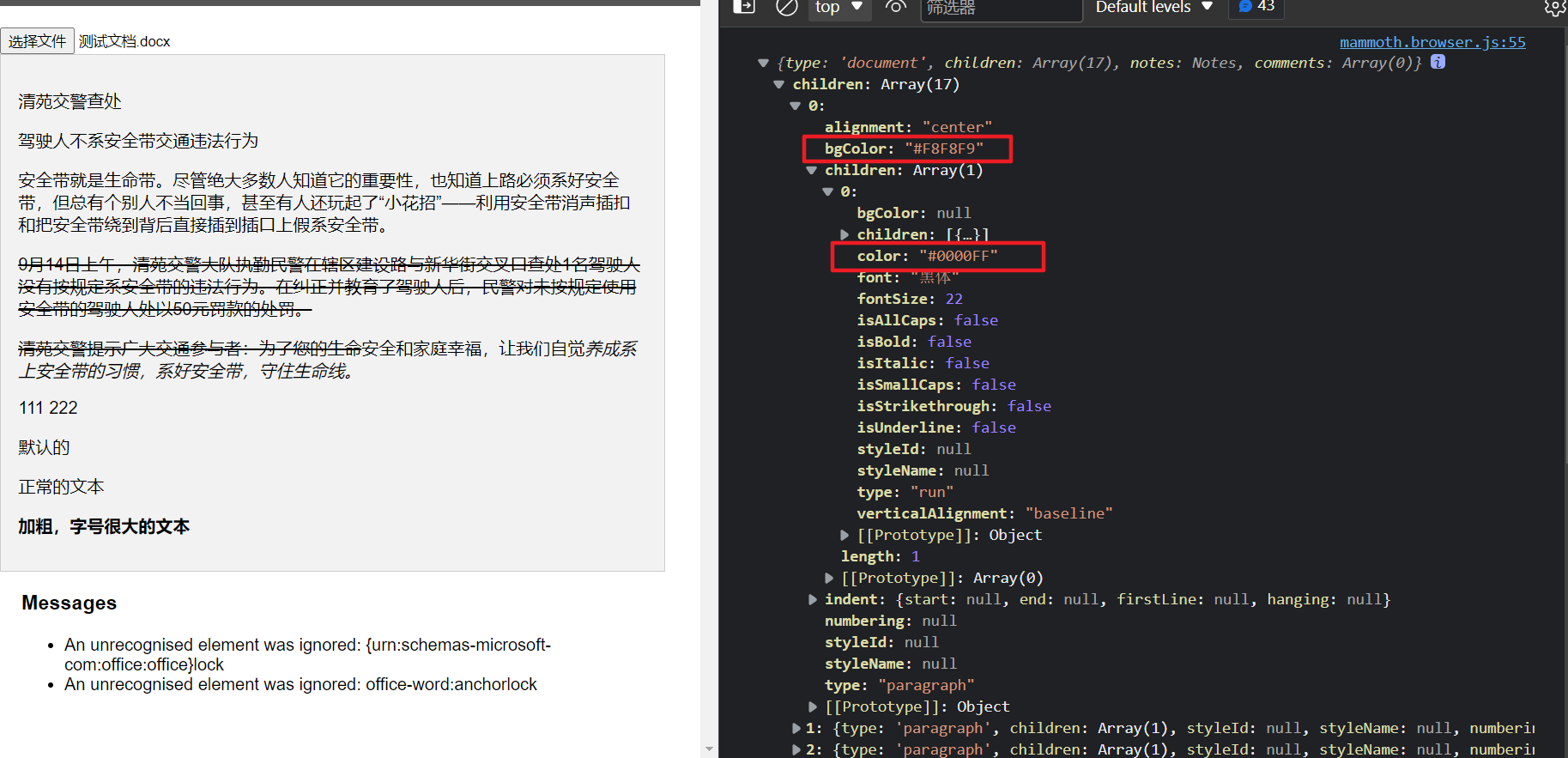
添加一个方法生成 style 内容
function DocumentConversion(options, comments) {
// 省略很多代码...
function converStyleForaAtributes(element, options) {
var styleMap = []
if (!options) {
options = {}
}
if (element.alignment && element.alignment !== 'both') {
styleMap.push({ key: 'text-align', value: element.alignment })
}
if (element.color) {
styleMap.push({ key: 'color', value: element.color })
}
if (element.bgColor) {
styleMap.push({ key: 'background-color', value: element.bgColor })
}
if (element.fontSize) {
styleMap.push({ key: 'font-size', value: element.fontSize + 'px' })
}
if (element.isUnderline) {
styleMap.push({ key: 'text-decoration', value: 'underline' })
}
var styleStr = styleMap
.map(function (item) {
return item.key + ':' + item.value
})
.join(';')
if (styleStr) {
options.style = styleStr + ';' + (options.style || '')
}
return options
}
// 省略很多代码...
}
段落添加背景色,居中格式渲染
- lib\document-to-html.js
之前看代码也有介绍,渲染的过程也是根据标签不同类型就执行不同的方法,段落对应的标识为 Paragraph
找到对应执行的方法是 convertParagraph ,这个方法里面又调用了 htmlPathForParagraph
最后创建 p 标签的是 htmlPathForParagraph 方法里面 return 的 defaultParagraphStyle。由于原先对 p 的样式是完全忽略的,所以统一返回了一个干净的 P 标签,那我们就针对这个改造一下
function htmlPathForParagraph(element, messages) {
var style = findStyle(element)
if (style) {
return style.to
} else {
if (element.styleId) {
messages.push(unrecognisedStyleWarning('paragraph', element))
}
// 把原先 defaultParagraphStyle 改为生成p标签并且添加 attributes 属性
return htmlPaths.topLevelElement('p', converStyleForaAtributes(element))
// return defaultParagraphStyle;
}
}
到这一步,p 标签的背景色和居中属性已经完成了,效果如下
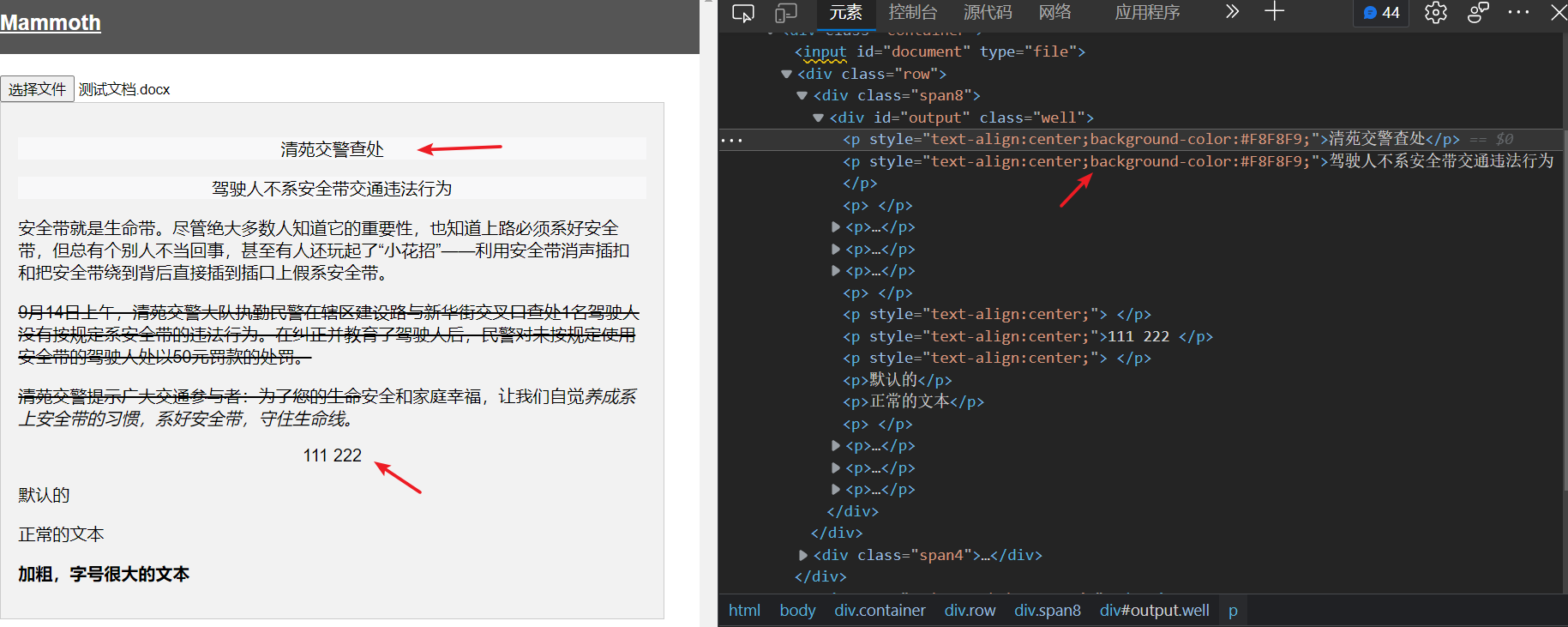
普通文本的处理
普通文本对应的是 convertRun(run, messages, options) 方法 ,可以在该方法里面打印一下 run
处理前的节点内容
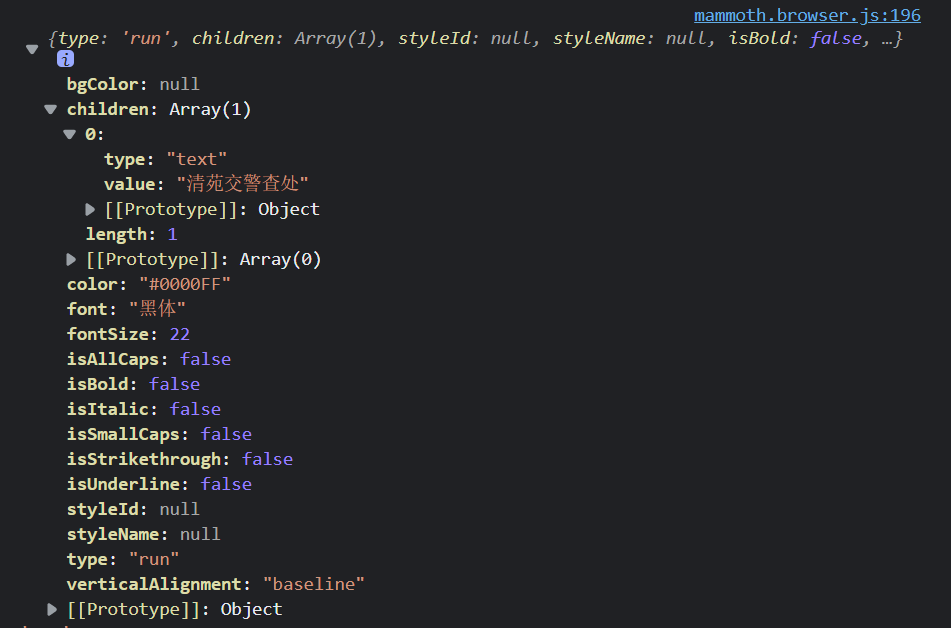
convertRun 这个方法中,会有一系列的判断,比如判断是否加粗?是否斜体,如果是的话,就包裹对应的标签
最后都会返回他的 children {type: "text",value: "xxx"}
最终 type 为 text 的类型又会重新进入 elementConverters.text 函数处理里面,返回普通的文本( return [Html.text(element.value)] ),追加在父标签下面,完成普通文本的解析
有点复杂,因为这里的解析总是互相嵌套,一层套一层,多看几遍理解一下~
理解了上面说的内容后,说一下解析普通文本的思路
- 如果真的是普通的文本(不带任何样式的)那就按原逻辑返回,保持 html 的简洁
- 如果文本有匹配中了标签,比如加粗 => strong 标签,那可以把样式直接加 strong 标签上
- 如果标签有样式,可是又没有匹配中标签,那么就需要自己补充一个 span 标签来承载样式
findHtmlPathForRunProperty这个应该是暴露给外部的钩子,也就是说这部分的样式没有默认标签可以匹配,不过暴露给了外面自定义标签来实现,除了 isStrikethrough 会有默认的 s 标签,其余的都当作没有解析把~- isUnderline 在这里完全可以用 css 实现,所以后续就把这个样式注释掉了
改造后的方法如下:
function convertRun(run, messages, options) {
console.log(run, 'run')
var nodes = function () {
return convertElements(run.children, messages, options)
}
var paths = []
// 添加了一个是否有额外的标签的判断
var tagNumber = 0
// 提前生成属性,在生成标签的时候可以顺便传入
var attributes = converStyleForaAtributes(run)
if (run.isSmallCaps) {
paths.push(findHtmlPathForRunProperty('smallCaps'))
}
if (run.isAllCaps) {
paths.push(findHtmlPathForRunProperty('allCaps'))
}
if (run.isStrikethrough) {
paths.push(findHtmlPathForRunProperty('strikethrough', 's', attributes))
tagNumber++
}
// if (run.isUnderline) {
// paths.push(findHtmlPathForRunProperty("underline"));
// }
if (run.verticalAlignment === documents.verticalAlignment.subscript) {
paths.push(htmlPaths.element('sub', attributes, { fresh: false }))
tagNumber++
}
if (run.verticalAlignment === documents.verticalAlignment.superscript) {
paths.push(htmlPaths.element('sup', attributes, { fresh: false }))
tagNumber++
}
if (run.isItalic) {
paths.push(findHtmlPathForRunProperty('italic', 'em', attributes))
tagNumber++
}
if (run.isBold) {
paths.push(findHtmlPathForRunProperty('bold', 'strong', attributes))
tagNumber++
}
var stylePath = htmlPaths.empty
var style = findStyle(run)
if (style) {
stylePath = style.to
} else if (run.styleId) {
messages.push(unrecognisedStyleWarning('run', run))
}
// 最后兜底,如果上面没生成标签,并且也有样式的话,就生成一个span标签插入
if (attributes && attributes.style && tagNumber == 0) {
paths.push(htmlPaths.element('span', attributes, { fresh: false }))
}
paths.push(stylePath)
paths.forEach(function (path) {
nodes = path.wrap.bind(path, nodes)
})
return nodes()
}
// 省略很多没改动的代码...
// 这个方法添加 attributes
function findHtmlPathForRunProperty(elementType, defaultTagName, attributes) {
var path = findHtmlPath({ type: elementType })
if (path) {
return path
} else if (defaultTagName) {
// 在创建 element 的时候传入这些属性(其实就是为了传入style)
return htmlPaths.element(defaultTagName, attributes || {}, {
fresh: false
})
} else {
return htmlPaths.empty
}
}
最终解析的效果
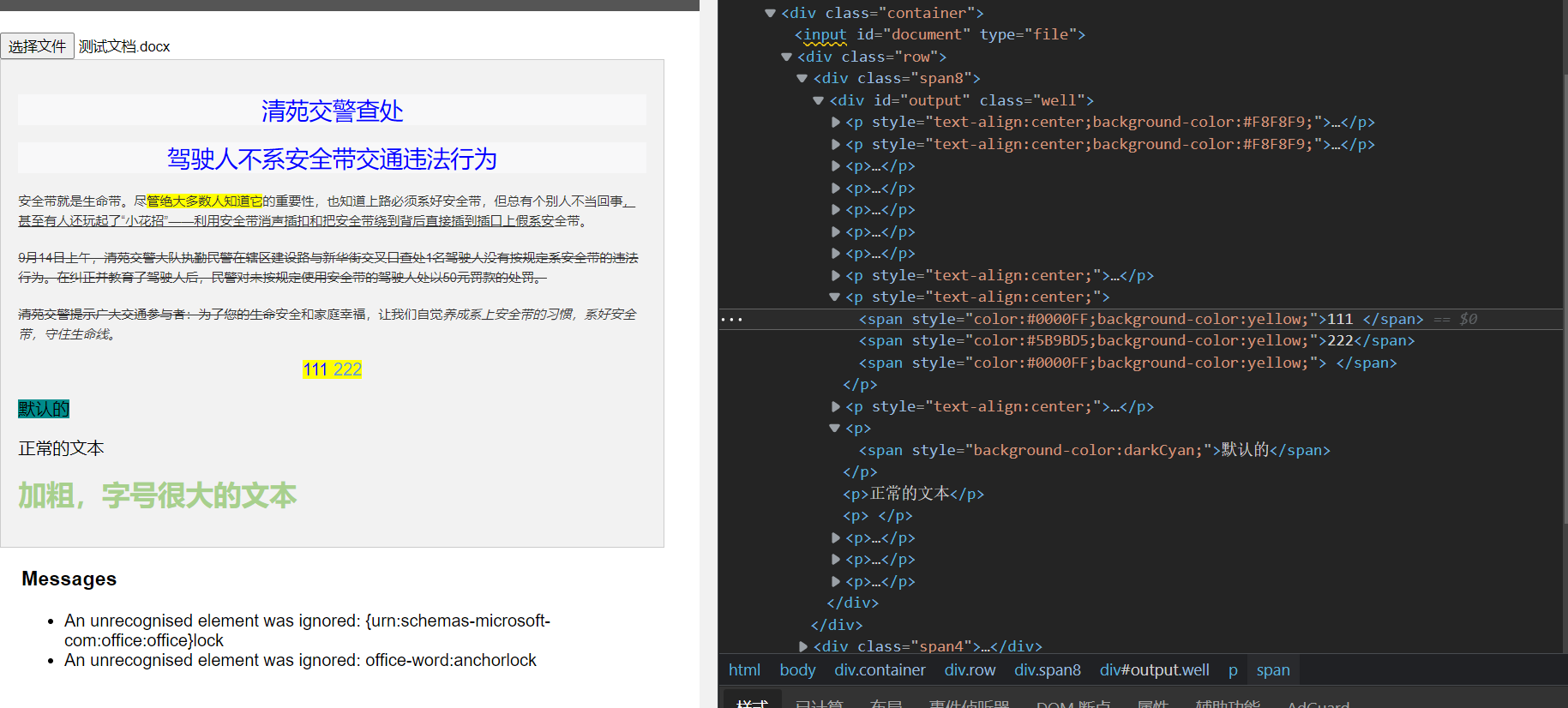
八九不离十!
当然还有很多可以优化的地方,比如相邻的 2 个 span,样式相同的时候,可以合并到一起,段落前面有个空格的时候。span 标签并不能把空格也很好的复现出来
还有单元测试中的案例也要添加上对应的 style 标签,否则单元测试会不通过
篇幅有限,不做深究
最后
整个 mammoth 库从优化打包,添加 dev 环境,到添加一些自己想要可是又没提供钩子的样式踩坑过程就到这里了~
整个库有非常多值得学习(和看不懂的地方),进过艰难的摸索和无限 console 总结出上面的最直接改源码过程。希望对你也有帮助

