事情是这样子的,前几天和一位粉丝师弟聊天。他说问问我能不能教他爬一下qq空间。我和他沟通了一下,问清楚事情原委。原来是他追求的女神发了qq空间表白墙,他想知道自己女神喜欢的是什么样的人。但是由于发表白墙的人太多,不好找,所以想某一个时间段的全部爬下来,慢慢看。
本来有一定年纪的人,不太清楚原来qq还有表白墙。好家伙,我看了下,原来是像我们那时候读大学时的微博树洞。提起微博树洞估计也得是上了年纪的人才懂。
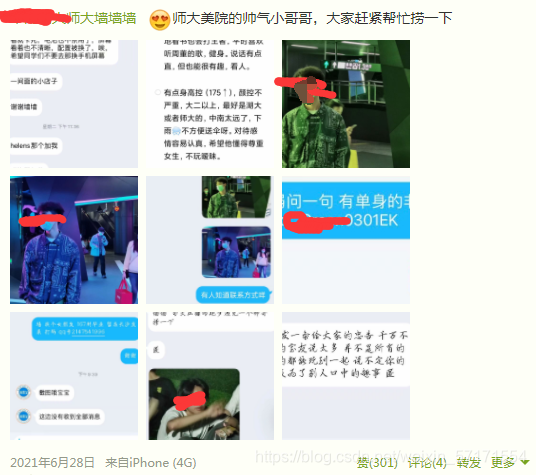
大概就是上面图那个样子的。由于帅哥太帅,以免大家嫉妒,我就挡了下。其实也就是爬空间说说而已。
如何登录
如果是爬qq空间,那么第一个问题来了,如果绕过登录?或者有什么方法可以登录呢?其实方法挺多,方法1,填上cookie,不过有的cookie经常变,也不太好用。所以第2个方法,使用浏览器驱动,模拟登录。
这里推荐使用chromedriver,这个驱动自行下载就好,网上有很多。
from selenium import webdriver selenium是web自动化工具,他可以使我们不用人工操作,也可以进行网站浏览,点击啥的。人可以做的事情,这库全部都可以完成。
driver的使用找控件
知道了使用webdriver可以解决上面的难点,那么我们就来操作一下。
# 获取浏览器驱动
dr = webdr.Chrome(executable_path='chromedr')
# 浏览器窗口最大化
dr.maximize_window()
# 浏览器地址定向为 qq 登陆页面
dr.get('网页链接')
# 所以这里需要选中一下 frame,否则找不到下面需要的网页元素
dr.switch_to.frame('login_frame')
# 自动点击账号登陆方式
dr.find_element_by_id('switcher_plogin').click()
# 账号输入框输入已知 QQ 账号
dr.find_element_by_id('u').send_keys(user)
# 密码框输入已知密码
dr.find_element_by_id('p').send_keys(pw)
# 自动点击登陆按钮
dr.find_element_by_id('login_button').click()
看上面的代码,我们可以看出dr.Chrome(executable_path=‘chromedr’)获取驱动,用dr.get来获取url返回内容,dr.find_element_by_id就是通过id来获取控件。整个过程就是模拟人工点击操作登录空间。
获取内容,并保存
qq_name = div.xpath('./div[2]/a/text()')
qq_content = div.xpath('./div[2]/pre/text()')
qq_time = div.xpath('./div[4]/div[1]/span/a/text()')
if len(qq_name) > 0
qq_name = qq_name[0]
else
qq_name = ''
if len(qq_content) > 0
qq_content = qq_content[0]
else
qq_content = ''
if len(qq_time) > 0
qq_time[0]
else
qq_time =''
print(qq_name, qq_time, qq_content)
f.write(qq_content+"\n")
这里获取内容使用了xpath,这个xpath有必要说一下。需要用到from lxml import etree。大家都知道前端网页是树形结构展示的。这里的lxml库需要自己去下载安装,直接用pip就行了。
image.png
xpath是可以直接在相应的元素右键轻松获取的。
f.write(qq_content+"\n"),最后我们保存一下内容就行
完整代码如下:
#coding: utf-8
import time
from selenium import webdriver
from lxml import etree
def DO(friend, user , pw):
print(完整代码,请移步到公众号:诗一样的代码)
"""
dr = webdriver.Chrome(executable_path='chromedriver')
dr.maximize_window()
dr.get('https://i.qq.com/'+friend)
dr.switch_to.frame('login_frame')
dr.find_element_by_id('switcher_plogin').click()
dr.find_element_by_id('u').send_keys(user)
dr.find_element_by_id('p').send_keys(pw)
dr.find_element_by_id('login_button').click()
time.sleep(10)
dr.switch_to.default_content()
dr.get('https://i.qq.com/'+friend)
next_num = 0
while 1:
for i in range(1, 6):
height = 10000 * i
strWord = "window.scrollBy(0," + str(height) + ")"
dr.execute_script(strWord)
time.sleep(4)
for div in divs:
qq_name = div.xpath('./div[2]/a/text()')
qq_content = div.xpath('./div[2]/pre/text()')
qq_time = div.xpath('./div[4]/div[1]/span/a/text()')
if len(qq_name) > 0:
qq_name = qq_name[0]
else:
qq_name = ''
if len(qq_content) > 0:
qq_content = qq_content[0]
else:
qq_content = ''
if len(qq_time) > 0:
qq_time[0]
else:
qq_time =''
print(qq_name, qq_time, qq_content)
f.write(qq_content+"\n")
if dr.page_source.find('pager_next_' + str(next_num)) == -1:
break
dr.find_element_by_id('pager_next_' + str(next_num)).click()
next_num += 1
dr.switch_to.parent_frame()
friend = '空间qq号'
user = '你的qq号'
pw = '你的qq密码'
DO(friend, user, pw)
大家觉得文章还不错的话,请一键三连吧。