一、BeaufitulSoup库简介与安装
BeaufifulSoup是一个常用的第三方库,能够对给定的HTML和XML文件进行解析,并且提取其中的信息。
简单来说request库可以获取文件,但是获取来结构是混乱的,将这个文件送入BuautifulSoup库提供的方法中,能够将文件根据标签进行解析,可以处理成更具有可读性的文件。
在PyCharm中,安装BeaufulSoup库需要在文件-设置里面添加bs4库:

添加成功后,用import的方法引入这个库。下面简单使用一下BeautifulSoup库:
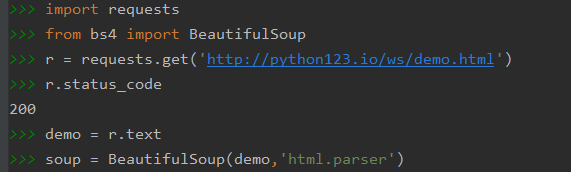
首先根据这段代码,引入requests库并且向获取一个url对应的文件,检验状态码发现是200,说明访问成功,之后将返回的response对象的text单独赋值给demo,利用BeautifulSoup将demo处理为soup,这里的BeautifulSoup库实际上是一个方法,方法有两个参数,第一个参数是一段html或者xml文件,第二个参数是解析需要用的解释器,demo本身是一段html文件,所以用html的解析器。
这样soup就已经可以根据标签进行一系列的操作了,最简单的事例是用prettify的方法,该方法可以根据标签的对应关系,在控制台打印出自动补全了缩进的html文件,可以对比一下下面两张图,效果明显:

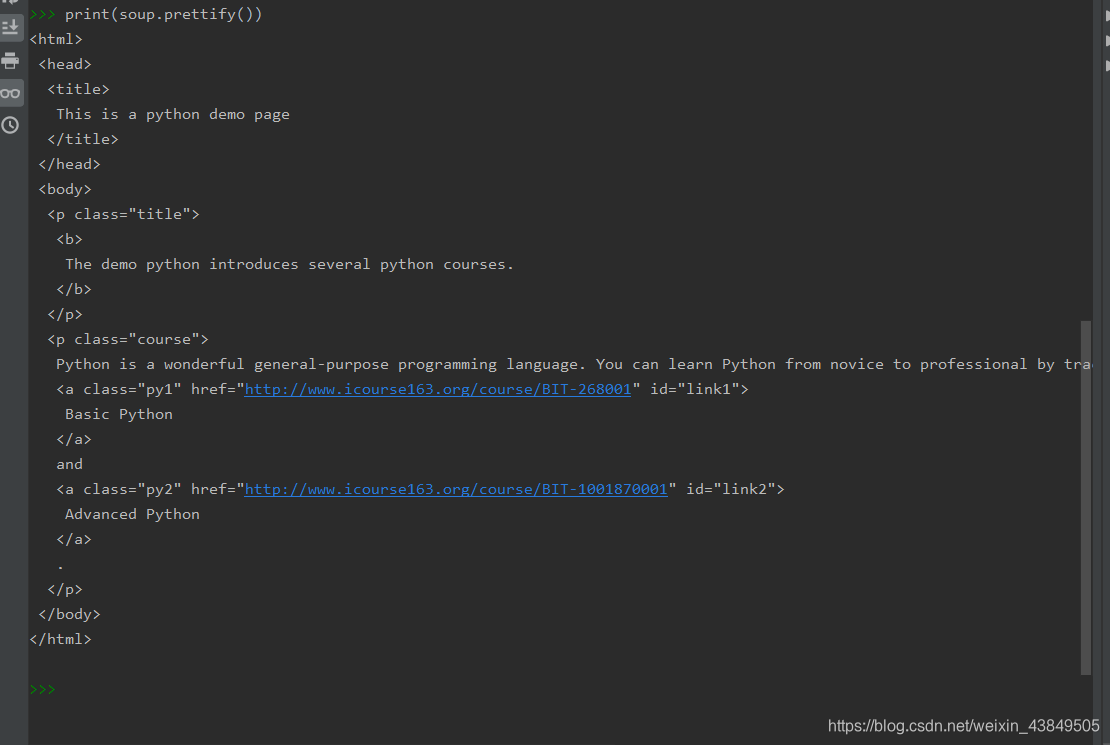
使用BeautifulSoup方法,主要是两个语句,首先引入,再利用已有的html文件或者代码,利用方法转换为soup,其他的操作在后面一一介绍。
二、BeautifulSoup库的基本元素
总的来说,BeautifulSoup库是解析、遍历、维护标签树的功能库,只要是标签类型都可以使用这个库进行解析。学过HTML的都知道,HTML是根据标签的组合来构建网页的,我们可以将一个html文件看作是一个标签构成的树,即标签树,而一个BeautifulSoup类实际上就对应着这样一棵标签树,所以通过BeautifulSoup对标签树的操作,实际上就是对html文件的操作。
BeautifulSoup类主要有下面五种基本元素,下面一一介绍一下基本元素:
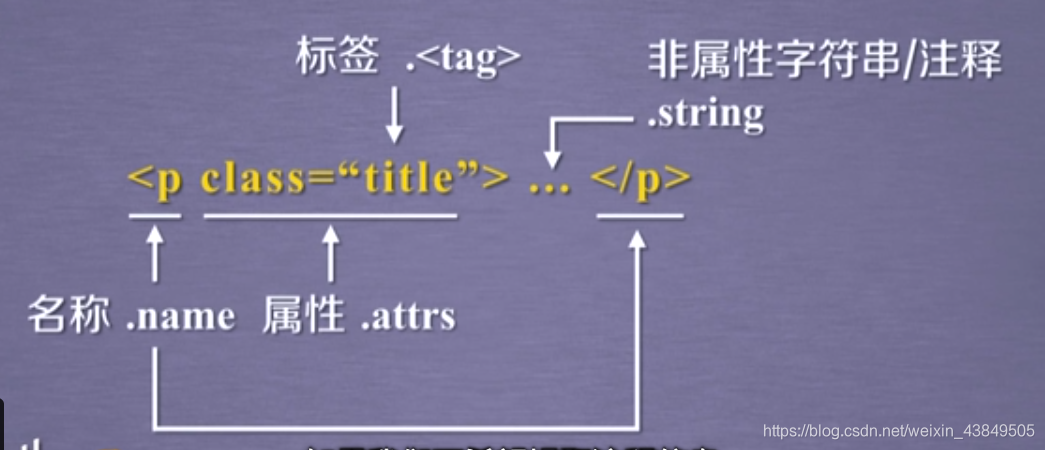
①Tag
是最基本的信息组织单元,可以根据需要的标签类型访问获得对应的标签,如果有多个相同的时候返回第一个。废话不多说上代码,继续沿用之前的demo代码:

soup已经是之前处理过的html文件,我们可以使用标签的名字来直接获取内部的内容,比如说上图就是直接获取了html文件中的title标签内部的内容,整个文档中只有一个title,所以直接返回唯一的title,如果要获取的是多次出现的,显示的是第一个,如下图所示:

②Name
对应html文件中标签的名字,返回值是标签的名,比如说要返回一个
标签的Name,返回的就是p:

③Attributes
使用attrs来获得标签的属性,也就是id、class等内容,返回的是一个字典形式。使用时首先要获得一个标签,之后再对这个标签使用attrs来查看标签的属性,代码如下:

因为返回值是一个字典,所以可以直接使用字典的操作方式进行提取:

④NavigableString
用于查看标签内非属性字符串,简单来说就是标签里面的内容部分:

这里我用string去试了三个地方,首先是p标签,返回的是p标签内部的字符串,虽然这个字符串还被b标签包裹,但是b标签并没有显示出来,说明是最里面的,而body标签内部有多个字符串,所以是无法显示的,最后title内部直接就是一个字符串,所以返回就是内部的内容。
⑤Comment
标签内字符串的注释部分,这里和上一个元素的获取方法是一样的,区别在于查看类型时会有不一样的显示:

获取方式都是使用标签名.string,但是前者的类型是comment,因为b标签内部是注释的语句,而后者是NavigableString,因为p标签内部是一般的字符串。
三、基于BeautifulSoup库的元素遍历
前面提到过HTML相当于一个标签树,结合数据结构里面的树的遍历的知识,对于标签树同样有向上、向下和平行三种遍历方式,这一部分主要是介绍一下这三种遍历的方式。
首先是向下遍历,即下行遍历,下行遍历主要是沿着子节点一直向下,这里主要有三种方法,下面一一介绍一下:
①contents
返回的是子节点构成的列表,每个子节点对应列表里面的一个表项,需要注意的是不仅仅是节点,回车也视为一个表项,由于返回的的是一个列表,所以可以根据列表的操作对节点进行读取。

上图所示的就是利用content对body进行子节点的遍历,子节点和回车组成了一个列表,用标签名.contents[]来读取具体的列表元素,而不加后缀则直接输出整个列表的内容。
②children
用于迭代,属于子节点的迭代类型,用于循环遍历儿子节点。
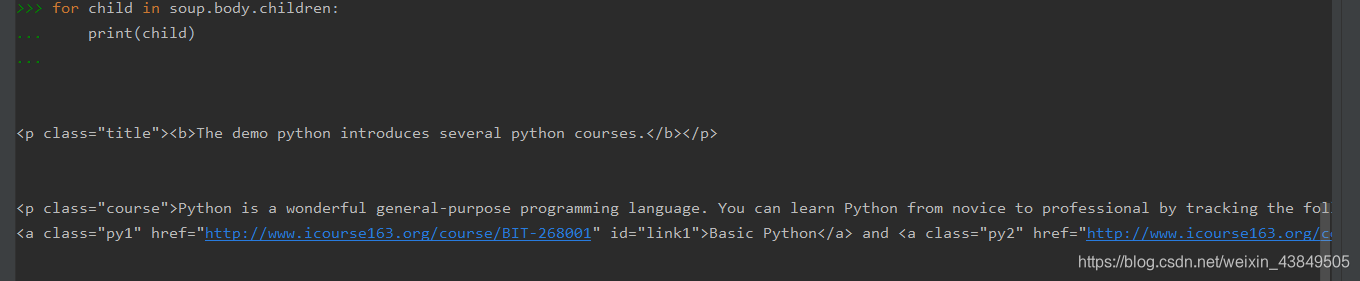
上图所示的是children的用法,可见这种方式主要是用在for循环中,直接遍历列表中的所有元素。
③descendants
和children的用法基本一样,也适用于迭代,区别在于descendants是迭代所有的子孙节点,而children只迭代儿子节点。采用这种方式可以快速对儿子节点进行遍历,结合判断可以快速筛选,比如下面的代码:

这段代码是心血来潮尝试的一下,对于所有的后代节点,如果标签的名字为p,则输出节点的内容,这样在爬图片时就可以筛选所有的img标签下载图片。但是尝试过程中也出现了一个小错误:

代码的原本意思是筛选body所有后代节点中class为py1的节点的信息,但是报错了,如果不采用迭代,而是直接使用contents读取却没有问题:

个人猜测是因为采用下行遍历无法排除换行符的影响,在遍历到‘\n’时会出错,使用contents读取也会出现这个问题:

所以可以判断这种方式只能对tag节点操作,而对于换行符节点则不能处理。
说完了下行遍历,上行遍历其实也大差不差,主要有下面两种方式:
①parent
返回的是节点的父亲标签
②parents
节点先辈标签的迭代类型,用于向上循环遍历。
这两个方式使用起来和向下遍历区别真的不大,还是拿刚才的例子:
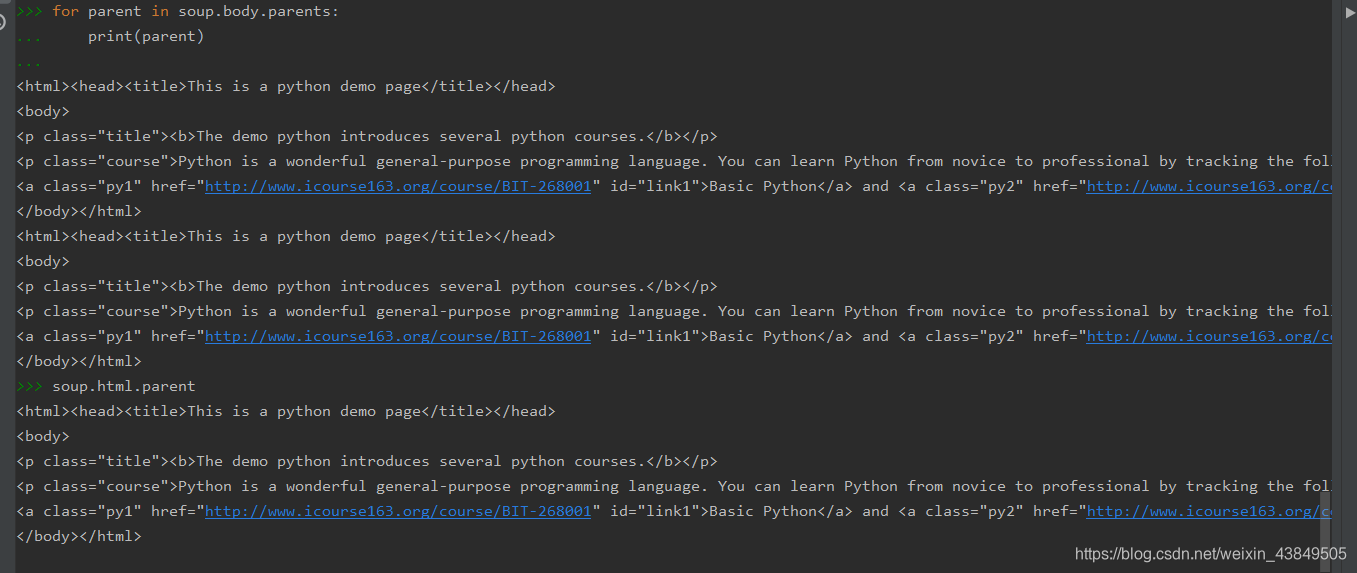
这里先是使用parents查看了body标签的所有前辈标签,可以看到body标签的上一个实际上是html标签,但是为什么输出了两次呢?
又使用parent查看了一次html标签的父标签,这个标签的父标签居然是自己,破案了,输出两次是html标签的父标签还输出了一次。
除此之外,节点的遍历还有平行遍历,平行遍历则有四种方式:
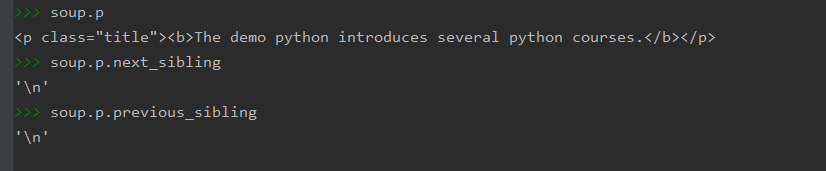
①next_sibling
按照html文本顺序返回下一个平行节点标签
②previous_sibling
按照html文本顺序返回上一个平行节点标签
这两个是成对的,一个返回前一个,另一个返回后一个:
③next_siblings
按照html文本顺序返回后续的所有平行节点标签
④previous_siblings
按照html文本顺序返回前续的所有平行节点标签

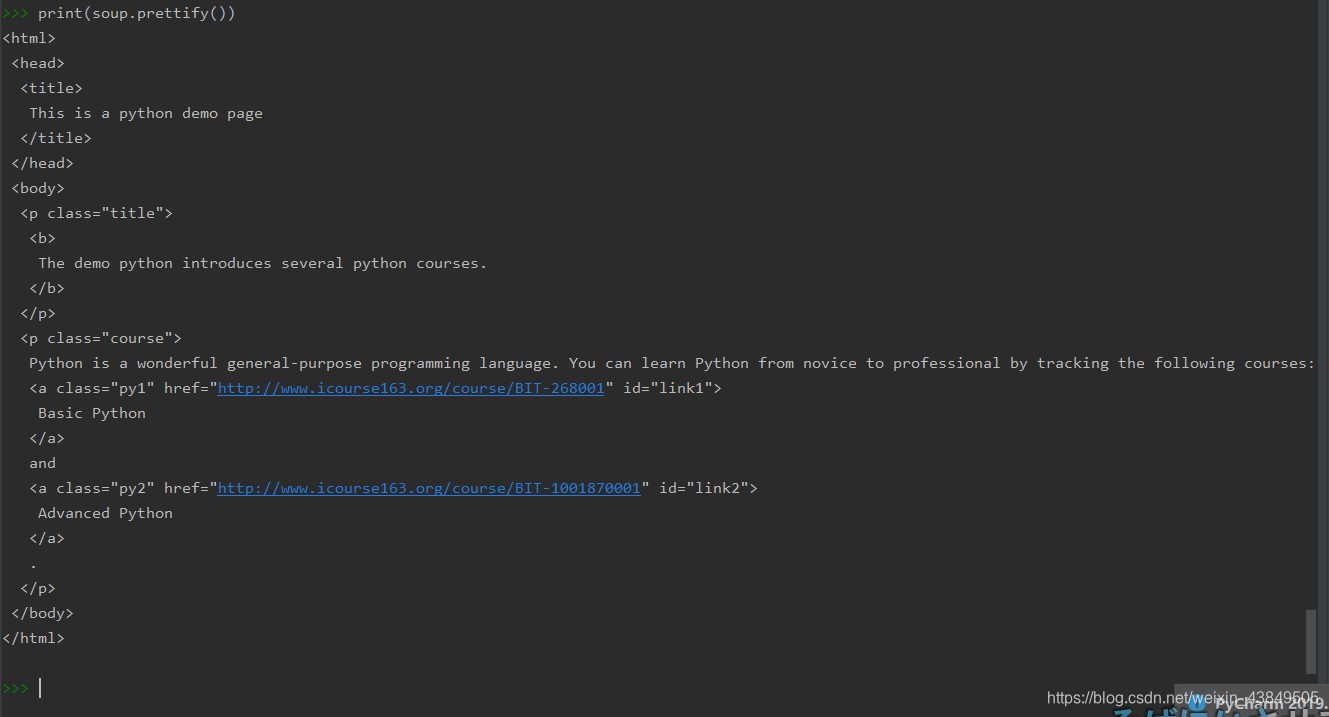
四、bs4库的prettify方法
这种方法在第一部分也使用过,主要是用于补充缩进,提高代码的可读性。
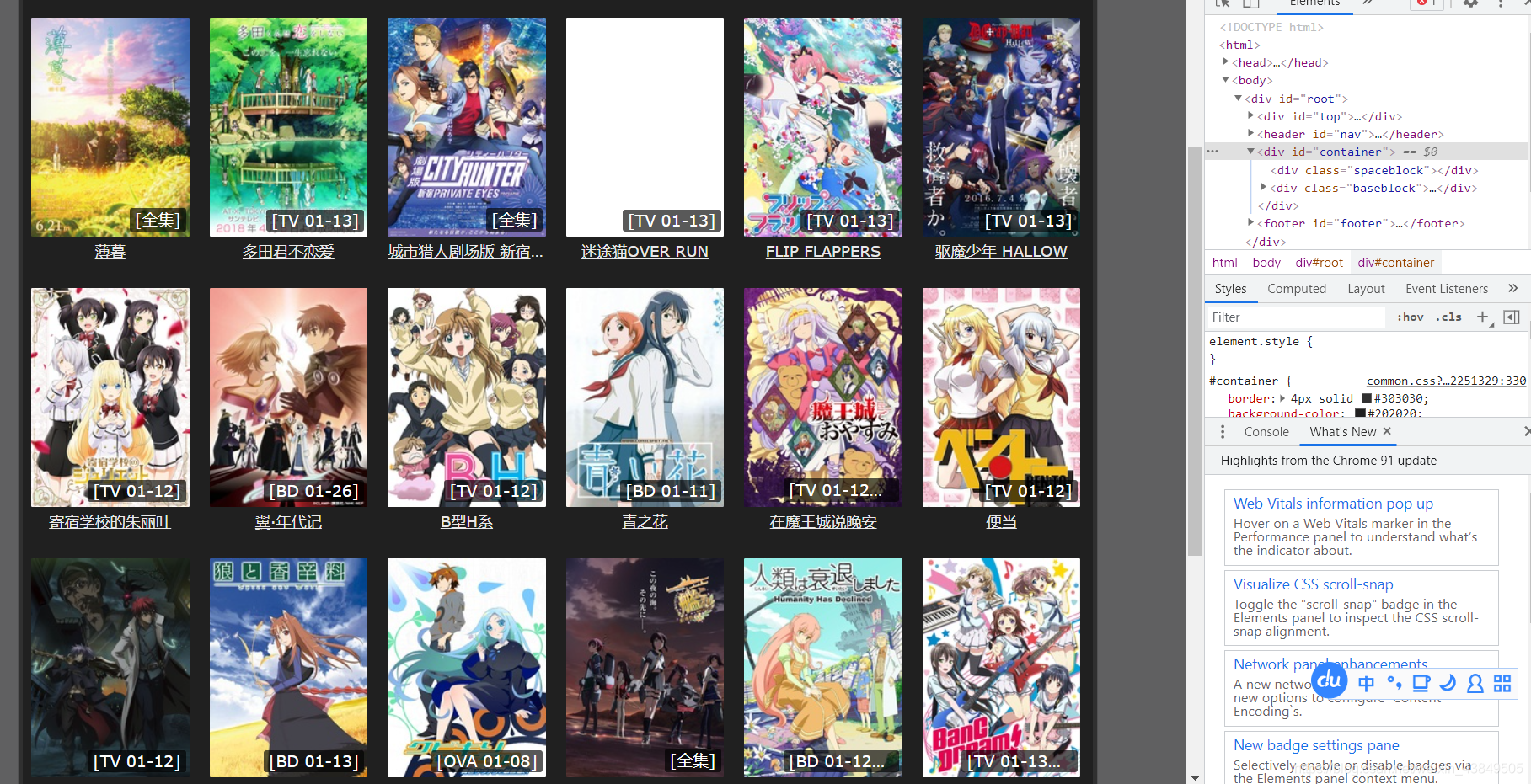
五、小实验:爬取盗版网站的缩略图
结合今天白天看的所有爬虫知识,深夜十二点来一波小实验,尝试一下爬取一个看番盗版网站的番剧缩略图,首先待爬取页面如图所示:
这里使用白天看的requests库和BeautifulSoup库,没有使用更加简单的方法,首先利用requests的get方法获取这个页面的html信息,提前写好一个url和一个本地存储目录root,之后要做的思路就是将里面所有的img标签筛选出来,利用attrs属性,将img标签里的src提取出来,这个src就是图片的位置,再利用另一个request方法,访问图片的路径,并使用os库中的内容将图片保存在本地。代码如下:
import requests
import os
from bs4 import BeautifulSoup
r = requests.get('https://www.agefans.cc/recommend')
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
url = 'https://www.agefans.cc/recommend'
root = 'C://Users//Binary//Desktop//'
try:
for children in soup.body.descendants:
if children.name == 'img':
print(children)
if not os.path.exists(root):
os.mkdir(root)
r = requests.get(children.attrs['src'])
path = root+children.attrs['src'].split('/')[-1]
with open(path, 'wb') as f:
f.write(r.content)
f.close()
except:
print("error")
运行后会在桌面上保存有一开始页面的所有缩略图:
