Python办公自动化――提取pdf文件中表格并到Excel
![]()
需求描述
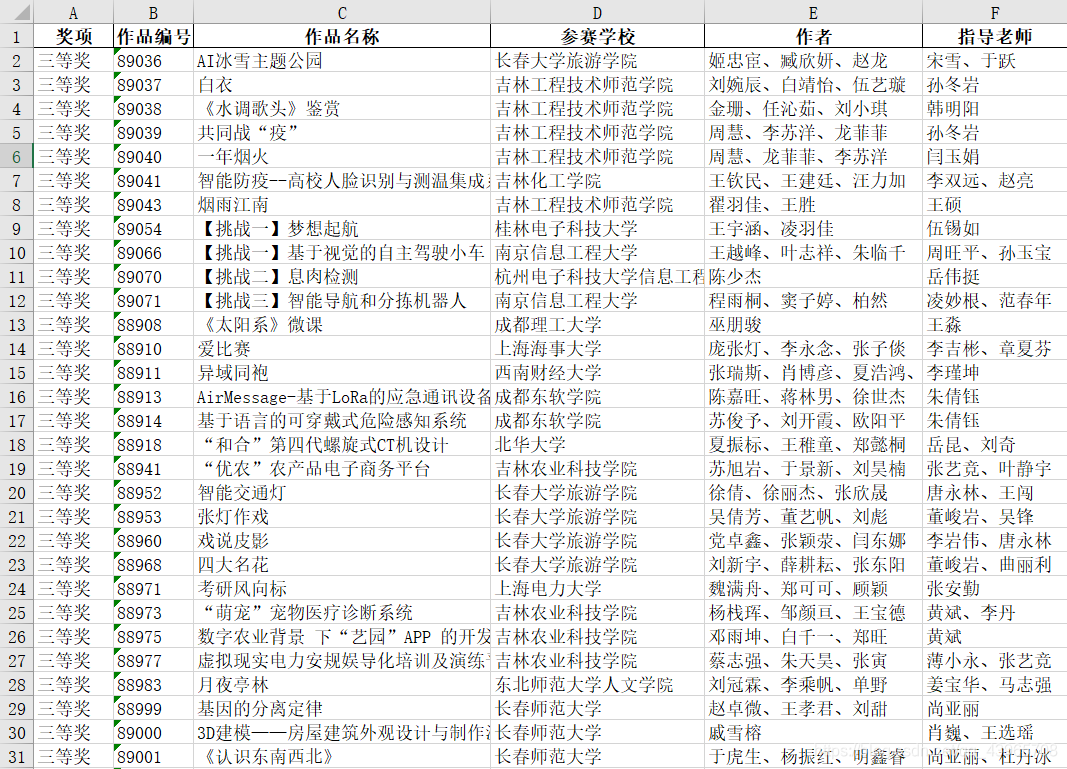
现有一 pdf 文件内容如下,文件中内容主要是表格形式的获奖名单,共158页。现要读取这些表格信息并保存到 excel 文件中。
 |
|---|
import pdfplumber
import pandas as pd
def read_pdf_2020(read_path, save_path):
pdf_2020 = pdfplumber.open(read_path)
result_df = pd.DataFrame()
for page in pdf_2020.pages:
table = page.extract_table()
df_detail = pd.DataFrame(table[1:], columns=table[0])
# 合并每页的数据集
result_df = pd.concat([df_detail, result_df], ignore_index=True)
# 删除值全部是 NaN 的列
result_df.dropna(axis=1, how='all', inplace=True)
# 重置列名
result_df.columns = ['奖项', '作品编号', '作品名称', '参赛学校', '作者', '指导老师']
result_df.to_excel(excel_writer=save_path, index=False, encoding='utf-8')
read_path = '2020年中国大学生计算机设计大赛参赛作品获奖名单.pdf'
save_path = '2020年中国大学生计算机设计大赛参赛作品获奖名单.xlsx'
df_2020 = read_pdf_2020(read_path, save_path)
运行效果:
 |
|---|
这就是本文所有的内容了,如果感觉还不错的话。? 点个赞再走吧!!!?
后续会继续分享《Python自动化办公》系列文章,如果感兴趣的话可以点个关注不迷路哦~。
