橡皮擦,一个逗趣的互联网高级网虫。
文章的起源
周末,一个群友用 1 个小时,完成一个小需求,赚了 ¥None 元。
他说:距离财富自由又近了一步,并且一度在群里不断炫富。
然后我把它的代码给公开了,估计他要失去这条财富之路了。
阅读本文你将收获
lxml库解析知识;- 粗糙的反
反爬技术; XPath语法再度了解;- 20000+漫展历史数据。
采集 20000+漫展历史数据
目标数据分析
本次要抓取的目标为:https://www.nyato.com/manzhan/?type=expired&p=1,具体数据区域如下所示。如需要更多数据,可以在此基础上,进一步进行扩展。
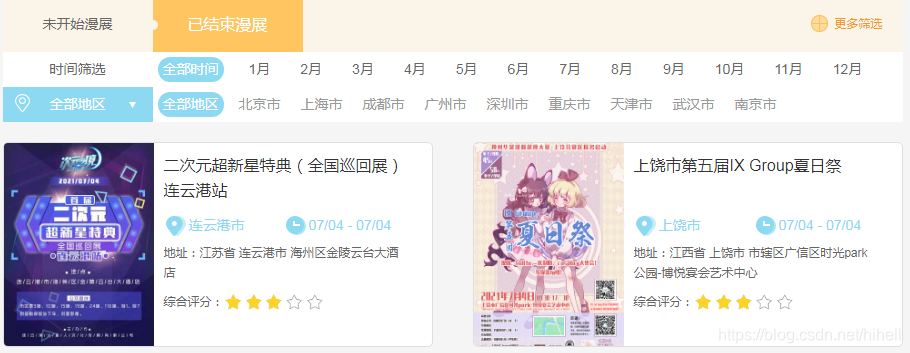
详细数据可点击上图标题,进入明细页,目标数据可参考下图红框区域所示内容。
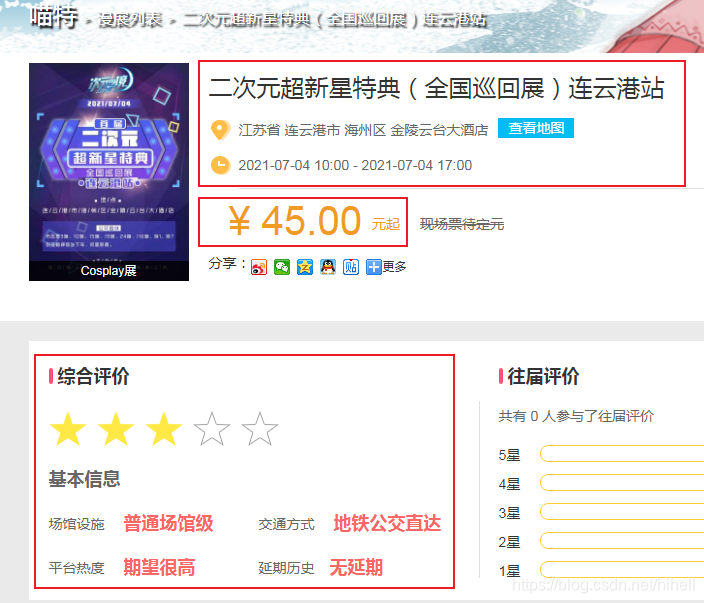
列表页与详情页规则如下
该网站的分页规则比较简单,直接修改页码号即可,详情页可以直接通过提取列表页中的连接获取。
https://www.nyato.com/manzhan/?type=expired&p=1
https://www.nyato.com/manzhan/?type=expired&p=2
https://www.nyato.com/manzhan/?type=expired&p=3
……
https://www.nyato.com/manzhan/?type=expired&p=1312
页面存在反爬逻辑
在编写代码的过程中,发现高并发访问目标网站,会出现短暂页面无法加载情况,该场景常规解决方案,使用 IP 代理池。
但本文的学习目的不在反爬,顾采用最笨拙的解决方案,异常抓取。
多次测试发现网站当判定我们是爬虫之后,会限制我们访问页面,但限制时间比较短,并且不会限制 IP,所以当页面出现异常情况时,通过 try except 重新访问页面,中间间隔一定时间,即代码存在如下结构:
try:
# 代码段
except Exception as e:
time.sleep(4)
重新调用函数名(url)
print(e)
最终运行代码,会出现如下情况,当请求页面出现空数据时,页面重新发起请求,同时停留 4 秒钟。
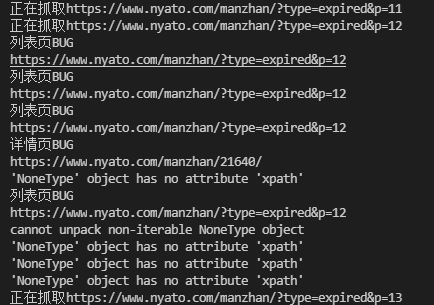
使用该思路爬取数据比较慢,如果你只需要数据,直接在文末下载即可。
整理需求如下
- 批量生成待抓取列表页;
requests请求目标数据;lxml提取目标数据;- 格式化数据;
- 保存数据。
编码时间
需求整理完毕之后,进入实际编码环节,会发现本篇博客涉及的代码比较简单。学习重点放在 lxml 提取操作的练习。
下述代码中的 USER_AGENTS 可以直接通过搜索引擎获取资源,也可以自己收集整理一份。
import requests
from lxml import etree
from fake_useragent import UserAgent
import time
import re
import random
# USER_AGENTS
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser;",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36",
]
# 保存文件
def save(long_str):
try:
with open(f"exhibition.csv", "a+", encoding="utf-8") as f:
f.write(long_str)
except Exception as e:
print(e)
# 获取详情页数据
def get_detail(url):
try:
headers = {"User-Agent": random.choice(USER_AGENTS)}
res = requests.get(url=url, headers=headers)
text = res.text
# 将 html 转换成 Element 对象
html = etree.HTML(text)
# 详细地址
address_detail = html.xpath("//span[@class='fl mr10']/text()")[0]
# 时间间隔
time_interval = html.xpath(
"//div[@class='h25 line25 s6 f14 w100s mb10']/text()")[3].strip()
# 票价
ticket_price = html.xpath("//b[@class='f40']/text()")[0]
# 匹配得分
score_url = html.xpath("//div[@class='mt10']/img/@src")[0]
score = re.search(
r"//static.nyato.cn/expo-image/stars/star-(\d\.\d).png", score_url).group(1)
# 其它信息
other = ",".join(html.xpath(
"//span[@class='sf6 f18 fwb ml15']/text()"))
return ticket_price, time_interval, address_detail, score, other
except Exception as e:
print("详情页BUG")
print(url)
time.sleep(4)
get_detail(url)
print(e)
def run(url):
try:
headers = {"User-Agent": random.choice(USER_AGENTS)}
res = requests.get(url=url, headers=headers)
text = res.text
# 将 html 转换成 Element 对象
html = etree.HTML(text)
# xpath 路径提取 @class 为选取 class 属性
lis = html.xpath("//ul[@class='w980 pt20']/li")
# 遍历 Elements 节点
for li in lis:
href = li.xpath(".//a/@href")[0]
title = li.xpath(".//a/@title")[0]
city = li.xpath(".//span[@class='w120 fl']/text()")[0].strip()
ticket_price, time_interval, address_detail, score, other = get_detail(
href)
long_str = f"{href},{title},{city},{ticket_price},{time_interval},{address_detail},{score},{other}\n"
save(long_str)
except Exception as e:
print("列表页BUG")
print(url)
time.sleep(4)
run(url)
print(e)
if __name__ == '__main__':
urls = []
for i in range(1, 1313):
urls.append(f"https://www.nyato.com/manzhan/?type=expired&p={i}")
for url in urls:
print(f"正在抓取{url}")
run(url)
print("全部爬取完毕")
上述代码在提取漫展评分时,引入了 re 模块,在字符串提取内容上,正则表达式的适配性还是比较高的。
通过正则直接从图片地址中将评分提取出来,本案例可以这样操作的原因是,分数图片有规则可循,图片连接如下,即分数图片由分数连接而成。
# 3.0 分
//static.nyato.cn/expo-image/stars/star-3.0.png
# 3.5 分
//static.nyato.cn/expo-image/stars/star-3.5.png
上述规则可通过不同的详情页,查看页面源码获得。
下面是正则提取得分部分的代码。
# 匹配得分
score_url = html.xpath("//div[@class='mt10']/img/@src")[0]
score = re.search(r"//static.nyato.cn/expo-image/stars/star-(\d\.\d).png", score_url).group(1)
本篇博客的重点依旧在 lxml 模块使用 XPath 提取数据部分。涉及到的代码如下,其中重点关注如下列表内容:
//从匹配选择的当前节点选择文档中的节点;[@class=xxxx]匹配属性;@src提取属性值;text()匹配标签内部文字。
其余需要掌握的,例如 ./ 选取当前节点,../ 选取当前节点的父节点。
address_detail = html.xpath("//span[@class='fl mr10']/text()")[0]
# 时间间隔
time_interval = html.xpath("//div[@class='h25 line25 s6 f14 w100s mb10']/text()")[3].strip()
# 票价
ticket_price = html.xpath("//b[@class='f40']/text()")[0]
# 匹配得分
score_url = html.xpath("//div[@class='mt10']/img/@src")[0]
抓取结果展示时间
本次抓取的数据,已经上传到 CSDN 下载频道,源码分享在代码频道。
完整代码下载地址:https://codechina.csdn.net/hihell/python120,NO12。
以下是爬取过程中产生的各种学习数据,如果只需要数据,可去下载频道下载~。
爬取资源仅供学习使用,侵权删。
抽奖时间
评论数过 100,随机抽取一名幸运读者,
获取 29.9 元《Python 游戏世界》专栏 1 折购买券一份,只需 2.99 元。
今天是持续写作的第 176 / 200 天。
可以关注我,点赞我、评论我、收藏我啦。
相关阅读