1.����
��ת����Bվ:�ȵ�AI��ѧ��������Python��
1.1 �����Ķ���
����:������
D
?
R
,
?���ӳ��?
f
:
D
��
R
?������?
D
?�ϵĺ���,ͨ�����Ϊ?
D \subset {\mathbf{R}}, \text { ���ӳ�� } f: D \rightarrow \mathbf{R} \text { Ϊ������ } D \text { �ϵĺ���,ͨ�����Ϊ }
D?R,?���ӳ��?f:D��R?Ϊ������?D?�ϵĺ���,ͨ�����Ϊ?
y
=
f
(
x
)
,
x
��
D
y=f(x), x \in D
y=f(x),x��D
����������,��ÿ��
x
��
D
x \in D
x��D,����Ӧ����
f
f
f,����Ψһȷ����ֵ
y
y
y ��֮��Ӧ, ���ֵ��Ϊ����
f
f
f ��
x
x
x ���ĺ���ֵ,����
f
(
x
)
,
f(x),
f(x), ��
y
=
f
(
x
)
.
y=f(x) .
y=f(x). �����
y
y
y ���Ա���
x
x
x ֮�������������ϵ,ͨ����Ϊ������ϵ. ����ֵ
f
(
x
)
f(x)
f(x) ��ȫ�������ɵļ��ϳ�Ϊ����
f
f
f ��ֵ��,����
R
f
R_{f}
Rf? ��
f
(
D
)
,
f(D),
f(D), ��
R
f
=
f
(
D
)
=
{
y
�O
y
=
f
(
x
)
,
x
��
D
}
R_{f}=f(D)=\{y \mid y=f(x), x \in D\}
Rf?=f(D)={y�Oy=f(x),x��D}
˵����,��������ʵ������ʵ������һ��ӳ��,��:
y
=
�O
x
�O
=
{
x
,
x
?
0
?
x
,
x
<
0
y=|x|=\left\{\begin{array}{ll} x, & x \geqslant 0 \\ -x, & x<0 \end{array}\right.
y=�Ox�O={x,?x,?x?0x<0?
�Ķ�����
D
=
(
?
��
,
+
��
)
,
D=(-\infty,+\infty),
D=(?��,+��), ֵ��
R
f
=
[
0
,
+
��
)
,
R_{f}=[0,+\infty),
Rf?=[0,+��), ����ͼ������ͼ��ʾ.�⺯����Ϊ����ֵ������
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-KISxeonB-1626186414712)(./image/�ߵ���ѧ/1.png)]](https://img-blog.csdnimg.cn/20210713222803739.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzU3NDQ2OTc4,size_16,color_FFFFFF,t_70)
1.2 ������
�躯��
f
:
D
��
f
(
D
)
f: D \rightarrow f(D)
f:D��f(D) �ǵ���,����������ӳ��
f
?
1
:
f
(
D
)
��
D
,
f^{-1}: f(D) \rightarrow D,
f?1:f(D)��D, �ƴ�ӳ��
f
?
1
f^{-1}
f?1 ����
f
f
f �ķ����������˶���,��ÿ��
y
��
f
(
D
)
,
y \in f(D),
y��f(D), ��Ψһ��
x
��
D
,
x \in D,
x��D, ʹ��
f
(
x
)
=
y
,
f(x)=y,
f(x)=y, ������
f
?
1
(
y
)
=
x
f^{-1}(y)=x
f?1(y)=x
�����˵,������
f
?
1
f^{-1}
f?1 �Ķ�Ӧ��������ȫ�ɺ���
f
f
f �Ķ�Ӧ������ȷ����. ����,����
y
=
x
3
,
x
��
R
y=x^{3}, x \in \mathbf{R}
y=x3,x��R �ǵ���, �������ķ���������,�䷴����Ϊ
x
=
y
1
3
,
y
��
R
x=y^{\frac{1}{3}}, y \in \mathbf{R}
x=y31?,y��R
����ϰ�����Ա�����
x
x
x ��ʾ,�������
y
y
y ��ʾ,����
y
=
x
3
,
x
��
R
y=x^{3}, x \in \mathbf{R}
y=x3,x��R �ķ�����ͨ��д��
y
=
x
1
3
,
x
��
R
y=x^{\frac{1}{3}}, x \in \mathbf{R}
y=x31?,x��R��һ���,
y
=
f
(
x
)
,
x
��
D
y=f(x), x \in D
y=f(x),x��D �ķ������dz�
y
=
f
?
1
(
x
)
,
x
��
f
(
D
)
y=f^{-1}(x), x \in f(D)
y=f?1(x),x��f(D).
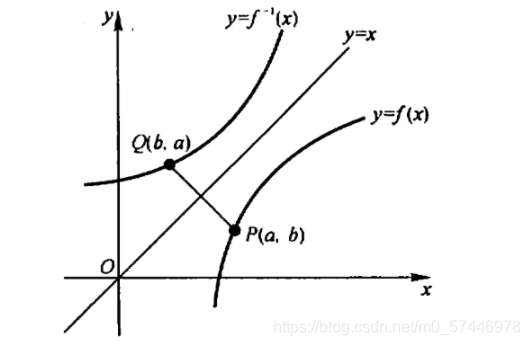
1.3 ���Ϻ���
�躯��
y
=
f
(
u
)
y=f(u)
y=f(u) �Ķ����Ϊ
D
f
,
D_{f},
Df?, ����
u
=
g
(
x
)
u=g(x)
u=g(x) �Ķ�����Ϊ
D
x
,
D_{x},
Dx?, ����ֵ��
R
g
?
D
t
,
R_{g} \subset D_{t},
Rg??Dt?, ������ʽȷ���ĺ���
y
=
f
[
g
(
x
)
]
,
x
��
D
x
y=f[g(x)], \quad x \in D_{x}
y=f[g(x)],x��Dx?
��Ϊ�ɺ���
u
=
g
(
x
)
u=g(x)
u=g(x) �뺯��
y
=
f
(
u
)
y=f(u)
y=f(u) ���ɵĸ��Ϻ���,���Ķ�����Ϊ
D
x
D_{x}
Dx? ,����
u
u
u ��Ϊ�м������
����:�����˶��Ķ���Ϊ
E
=
m
v
2
/
2
,
E=m v^{2} / 2,
E=mv2/2, ������������ٶ�Ϊ
v
=
g
t
,
v=g t,
v=gt, ������������Ķ�����ʱ��
t
t
t �ĸ��Ϻ��� :
E
=
1
2
m
g
2
t
2
E=\frac{1}{2} m g^{2} t^{2}
E=21?mg2t2
2.����
2.1 ����
����1:��֪λ����˲ʱ�ٶ�
����������ֱ���˶�,��֪�����λ����ʱ��Ĺ�ϵ��
s
=
f
(
t
)
,
s=f(t),
s=f(t), ��������
t
=
t
0
t=t_{0}
t=t0? ʱ��˲ʱ�ٶ�Ϊ
v
(
t
0
)
v(t_0)
v(t0?)
��ʱ����
t
0
t_{0}
t0? �仯��
t
0
+
��
t
t_{0}+\Delta t
t0?+��t ʱ,
������
��
s
=
f
(
t
0
+
��
t
)
?
f
(
t
0
)
\Delta \boldsymbol{s}=\boldsymbol{f}\left(\boldsymbol{t}_{0}+\Delta t\right)-\boldsymbol{f}\left(t_{0}\right)
��s=f(t0?+��t)?f(t0?)
�������������ʱ���ƽ���ٶ�
v
��
=
��
s
��
t
\bar{v}=\frac{\Delta s}{\Delta t}
v��=��t��s?.
������ƽ���ٶ���˲ʱ�ٶ���ϵ����?
��Ϊ�ڶ�ʱ�����ٶȱ仯����,���Կ���������
t
0
t_{0}
t0? ������ƽ���ٶȽ���
t
0
t_{0}
t0? ʱ�̵�˲ʱ�ٶ�.
��
v
(
t
0
)
��
��
s
��
t
(
��
t
\boldsymbol{v}\left(\boldsymbol{t}_{0}\right) \approx \frac{\Delta \boldsymbol{s}}{\Delta \boldsymbol{t}} \quad(\Delta t
v(t0?)����t��s?(��tԽС���ԽС
)
)
)
Ϊ�˵õ�˲ʱ�ٶȵľ�ȷ����,��˲ʱ�ٶ�����ɵ�ʱ���������Сʱƽ���ٶȵļ��ޡ�
��
v
(
t
0
)
=
lim
?
��
t
��
0
��
s
��
t
=
lim
?
��
t
��
0
f
(
t
0
+
��
t
)
?
f
(
t
0
)
��
t
\boldsymbol{v}\left(\boldsymbol{t}_{0}\right)=\lim _{\Delta t \rightarrow 0} \frac{\Delta \boldsymbol{s}}{\Delta t}=\lim _{\Delta t \rightarrow 0} \frac{\boldsymbol{f}\left(\boldsymbol{t}_{0}+\Delta t\right)-\boldsymbol{f}\left(\boldsymbol{t}_{0}\right)}{\Delta \boldsymbol{t}}
v(t0?)=lim��t��0?��t��s?=lim��t��0?��tf(t0?+��t)?f(t0?)?
����˲ʱ�ٶ���λ�ƶ�ʱ���˲ʱ�仯�ʡ�
����2:���ߵ�����
������
y
=
f
(
x
)
\boldsymbol{y}=\boldsymbol{f}(\boldsymbol{x})
y=f(x) �ڵ�
M
(
x
0
,
f
(
x
0
)
)
\boldsymbol{M}\left(\boldsymbol{x}_{0}, \boldsymbol{f}\left(\boldsymbol{x}_{0}\right)\right)
M(x0?,f(x0?)) �������߷���:
�������ϵ�
M
M
M ����ȡһ��
N
N
N, ��ֱ��
M
N
M N
MN (����).
����N��������������
M
M
M ʱ,�������
M
N
M N
MN��һ������λ��,�ͰѴ˼���λ������Ϊ�����ڵ�M�������ߡ�
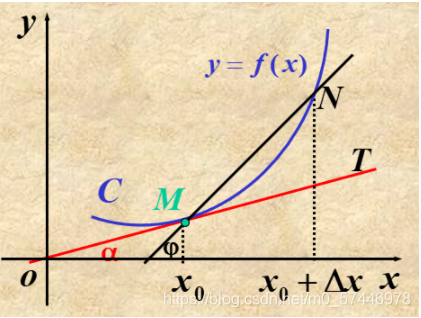
��Ӧ��,���ߵ�б�ʵ��ڸ���б�ʵļ��ޡ�����
M
N
M N
MN ��б��Ϊ
��
y
��
x
=
f
(
x
0
+
��
x
)
?
f
(
x
0
)
��
x
\frac{\Delta y}{\Delta x}=\frac{f\left(x_{0}+\Delta x\right)-f\left(x_{0}\right)}{\Delta x}
��x��y?=��xf(x0?+��x)?f(x0?)?
���ߵ�б��Ϊ
k
=
lim
?
��
x
��
0
��
y
��
x
=
lim
?
��
x
��
0
f
(
x
0
+
��
x
)
?
f
(
x
0
)
��
x
\begin{aligned} k &=\lim _{\Delta x \rightarrow 0} \frac{\Delta y}{\Delta x} \\ &=\lim _{\Delta x \rightarrow 0} \frac{f\left(x_{0}+\Delta x\right)-f\left(x_{0}\right)}{\Delta x} \end{aligned}
k?=��x��0lim?��x��y?=��x��0lim?��xf(x0?+��x)?f(x0?)??
2.2 �����Ķ���
����:�躯��
y
=
f
(
x
)
y=f(x)
y=f(x) �ڵ�
x
0
x_{0}
x0? ��ij���������ж���,���Ա���
x
x
x ��
x
0
x_{0}
x0? ��ȡ������
��
x
\Delta x
��x ;���
��
y
\Delta y
��y ��
��
x
\Delta x
��x ֮�ȵ�
��
x
��
0
\Delta x \rightarrow 0
��x��0 ʱ�� ������, ��ƺ���
y
=
y=
y=
f
(
x
)
f(x)
f(x) �ڵ�
x
0
x_{0}
x0? ���ɵ�,�����������Ϊ����
y
=
f
(
x
)
y=f(x)
y=f(x) �ڵ�
x
0
x_{0}
x0? ���ĵ���,��Ϊ
f
��
(
x
0
)
,
f^{\prime}\left(x_{0}\right),
f��(x0?), ��
f
��
(
x
0
)
=
lim
?
��
,
x
��
0
��
y
��
x
=
lim
?
��
x
��
0
f
(
x
0
+
��
x
)
?
f
(
x
0
)
��
x
f^{\prime}\left(x_{0}\right)=\lim _{\Delta, x \rightarrow 0} \frac{\Delta y}{\Delta x}=\lim _{\Delta x \rightarrow 0} \frac{f\left(x_{0}+\Delta x\right)-f\left(x_{0}\right)}{\Delta x}
f��(x0?)=��,x��0lim?��x��y?=��x��0lim?��xf(x0?+��x)?f(x0?)?
Ҳ�ɼ���
y
��
�O
x
=
x
0
\left.y^{\prime}\right|_{x=x_{0}}
y���Ox=x0??,
d
y
?
d
x
�O
x
=
x
0
\left.\frac{\mathrm{d} y}{\mathrm{~d} x}\right|_{x=x_{0}}
?dxdy?�O�O�O?x=x0?? �� 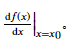
**��˵,����������������������Ա���������֮�ȵļ��ޡ�**����ʹ�ú��������Ķ����Ƶ� y = x 2 y = x^2 y=x2�ĵ���?
2.3 ����������
(1) �����ĺͲ���̵�����:
[
u
(
x
)
��
v
(
x
)
]
��
=
u
��
(
x
)
��
v
��
(
x
)
[
u
(
x
)
v
(
x
)
]
��
=
u
��
(
x
)
v
(
x
)
+
u
(
x
)
v
��
(
x
)
[
u
(
x
)
v
(
x
)
]
��
=
u
��
(
x
)
v
(
x
)
?
u
(
x
)
v
��
(
x
)
v
2
(
x
)
(
v
(
x
)
��
0
)
[u(x) \pm v(x)]^{\prime}=u^{\prime}(x) \pm v^{\prime}(x)\\ [u(x) v(x)]^{\prime}=u^{\prime}(x) v(x)+u(x) v^{\prime}(x) \\ \left[\frac{u(x)}{v(x)}\right]^{\prime}=\frac{u^{\prime}(x) v(x)-u(x) v^{\prime}(x)}{v^{2}(x)}(v(x) \neq 0)
[u(x)��v(x)]��=u��(x)��v��(x)[u(x)v(x)]��=u��(x)v(x)+u(x)v��(x)[v(x)u(x)?]��=v2(x)u��(x)v(x)?u(x)v��(x)?(v(x)��?=0)
����:
��
y
=
2
x
3
?
5
x
2
+
3
x
?
7
y=2 x^{3}-5 x^{2}+3 x-7
y=2x3?5x2+3x?7�ĵ���?
��:
y
��
=
(
2
x
3
?
5
x
2
+
3
x
?
7
)
��
=
(
2
x
3
)
��
?
(
5
x
2
)
��
+
(
3
x
)
��
?
(
7
)
��
=
2
?
3
x
2
?
5
?
2
x
+
3
?
0
=
6
x
2
?
10
x
+
3
\begin{aligned} y^{\prime} &=\left(2 x^{3}-5 x^{2}+3 x-7\right)^{\prime} \\ &=\left(2 x^{3}\right)^{\prime}-\left(5 x^{2}\right)^{\prime}+(3 x)^{\prime}-(7)^{\prime} \\ &=2 \cdot 3 x^{2}-5 \cdot 2 x+3-0=6 x^{2}-10 x+3 \end{aligned}
y��?=(2x3?5x2+3x?7)��=(2x3)��?(5x2)��+(3x)��?(7)��=2?3x2?5?2x+3?0=6x2?10x+3?
(2)���Ϻ���������:
���
u
=
g
(
x
)
u=g(x)
u=g(x) �ڵ�
x
x
x �ɵ�, ��
y
=
f
(
u
)
y=f(u)
y=f(u) �ڵ�
u
=
g
(
x
)
u=g(x)
u=g(x) �ɵ�, ��:
d
y
?
d
x
=
f
��
(
u
)
?
g
��
(
x
)
?��?
d
y
?
d
x
=
d
y
?
d
u
?
d
u
?
d
x
\frac{\mathrm{d} y}{\mathrm{~d} x}=f^{\prime}(u) \cdot g^{\prime}(x) \quad \text { �� } \quad \frac{\mathrm{d} y}{\mathrm{~d} x}=\frac{\mathrm{d} y}{\mathrm{~d} u} \cdot \frac{\mathrm{d} u}{\mathrm{~d} x}
?dxdy?=f��(u)?g��(x)?��??dxdy?=?dudy???dxdu?
����:
y
=
e
x
3
,
y=e^{x^{3}},
y=ex3, ��
d
y
d
x
\frac{d y}{d x}
dxdy?.
��
y
=
e
x
3
y=\mathrm{e}^{x^{3}}
y=ex3 �ɿ�����
y
=
e
��
��
,
u
=
x
3
y=\mathrm{e}^{\prime \prime}, u=x^{3}
y=e����,u=x3 ���϶���, ���
d
y
?
d
x
=
d
y
?
d
u
?
d
u
?
d
x
=
e
u
?
3
x
2
=
3
x
2
e
x
3
\frac{\mathrm{d} y}{\mathrm{~d} x}=\frac{\mathrm{d} y}{\mathrm{~d} u} \cdot \frac{\mathrm{d} u}{\mathrm{~d} x}=\mathrm{e}^{u} \cdot 3 x^{2}=3 x^{2} \mathrm{e}^{x^{3}}
?dxdy?=?dudy???dxdu?=eu?3x2=3x2ex3
(3)���õij��Ⱥ�������:
(
1
)
(
C
)
��
=
0
,
??????
(
2
)
(
x
��
��
)
��
=
��
x
��
��
?
1
,
(
3
)
(
sin
?
x
)
��
=
cos
?
x
,
??????
(
4
)
(
cos
?
x
)
��
=
?
sin
?
x
,
(
5
)
(
tan
?
x
)
��
=
sec
?
2
x
,
??????
(
6
)
(
cot
?
x
)
��
=
?
csc
?
2
x
,
(
7
)
(
sec
?
x
)
��
=
sec
?
x
tan
?
x
,
??????
(
8
)
(
csc
?
x
)
��
=
?
csc
?
x
cot
?
x
,
(
9
)
(
a
x
)
��
=
a
x
ln
?
a
,
??????
(
10
)
(
e
x
)
��
=
e
x
,
(
11
)
(
log
?
a
x
)
��
=
1
x
ln
?
a
,
??????
(
12
)
(
ln
?
x
)
��
=
1
x
,
(
13
)
(
arcsin
?
x
)
��
=
1
1
?
x
2
,
??????
(
14
)
(
arccos
?
x
)
��
=
?
1
1
?
x
2
,
(
15
)
(
arctan
?
x
)
��
=
1
1
+
x
2
,
??????
(
16
)
(
arccot
?
x
)
��
=
?
1
1
+
x
2
(1) (C)^{\prime}=0,\;\;\; (2) \left(x^{\prime \prime}\right)^{\prime}=\mu x^{\prime \prime-1},\\ (3) (\sin x)^{\prime}=\cos x,\;\;\; (4) (\cos x)^{\prime}=-\sin x,\\ (5) (\tan x)^{\prime}=\sec ^{2} x,\;\;\; (6) (\cot x)^{\prime}=-\csc ^{2} x,\\ (7) (\sec x)^{\prime}=\sec x \tan x,\;\;\; (8) (\csc x)^{\prime}=-\csc x \cot x,\\ (9) \left(a^{x}\right)^{\prime}=a^{x} \ln a,\;\;\; (10)\left(\mathrm{e}^{x}\right)^{\prime}=\mathrm{e}^{x},\\ (11)\left(\log _{a} x\right)^{\prime}=\frac{1}{x \ln a},\;\;\; (12) (\ln x)^{\prime}=\frac{1}{x},\\ (13) (\arcsin x)^{\prime}=\frac{1}{\sqrt{1-x^{2}}},\;\;\; (14) (\arccos x)^{\prime}=-\frac{1}{\sqrt{1-x^{2}}},\\ (15) (\arctan x)^{\prime}=\frac{1}{1+x^{2}},\;\;\; (16) (\operatorname{arccot} x)^{\prime}=-\frac{1}{1+x^{2}}\\
(1)(C)��=0,(2)(x����)��=��x����?1,(3)(sinx)��=cosx,(4)(cosx)��=?sinx,(5)(tanx)��=sec2x,(6)(cotx)��=?csc2x,(7)(secx)��=secxtanx,(8)(cscx)��=?cscxcotx,(9)(ax)��=axlna,(10)(ex)��=ex,(11)(loga?x)��=xlna1?,(12)(lnx)��=x1?,(13)(arcsinx)��=1?x2?1?,(14)(arccosx)��=?1?x2?1?,(15)(arctanx)��=1+x21?,(16)(arccotx)��=?1+x21?
2.4 �߽���
������
y
=
f
(
x
)
y=f(x)
y=f(x) �ĵ���
y
��
=
f
��
(
x
)
y^{\prime}=f^{\prime}(x)
y��=f��(x) �ɵ�,���
f
��
(
x
)
f^{\prime}(x)
f��(x) �ĵ���Ϊ
f
(
x
)
f(x)
f(x) �Ķ�����,����
y
��
��
y^{\prime \prime}
y���� ��
d
2
y
d
x
2
,
\frac{d^{2} y}{d x^{2}},
dx2d2y?, ��
y
��
��
=
(
y
��
)
��
?��?
d
2
y
d
x
2
=
d
d
x
(
d
y
d
x
)
y^{\prime \prime}=\left(y^{\prime}\right)^{\prime} \text { �� } \frac{d^{2} y}{d x^{2}}=\frac{d}{d x}\left(\frac{d y}{d x}\right)
y����=(y��)��?��?dx2d2y?=dxd?(dxdy?)
���Ƶ�,�������ĵ�����Ϊ������,�������ơ����Ͷ������ϵĵ���ͳ��Ϊ�߽�����
����:
����
ln
?
(
1
+
x
)
\ln (1+x)
ln(1+x) �� 2 ����:
��:
y
=
ln
?
(
1
+
x
)
,
y
��
=
1
1
+
x
y=\ln (1+x), y^{\prime}=\frac{1}{1+x}
y=ln(1+x),y��=1+x1?,
y
��
��
=
?
1
(
1
+
x
)
2
,
y^{\prime \prime}=-\frac{1}{(1+x)^{2}},
y����=?(1+x)21?,
3.��Ԫ����
3.1 ��Ԫ��������ظ���
(1)nά�ռ�:
��
n
n
n Ϊȡ����һ��������,������
R
n
\mathbf{R}^{n}
Rn ��ʾ
n
n
n Ԫ����ʵ����
(
x
1
,
x
2
,
?
?
,
\left(x_{1}, x_{2}, \cdots,\right.
(x1?,x2?,?,
x
n
)
\left.x_{n}\right)
xn?) ��ȫ�������ɵļ���, ��
R
n
=
R
��
R
��
?
��
R
=
{
(
x
1
,
x
2
,
?
?
,
x
n
)
�O
x
i
��
R
,
i
=
1
,
2
,
?
?
,
n
}
\mathbf{R}^{n}=\mathbf{R} \times \mathbf{R} \times \cdots \times \mathbf{R}=\left\{\left(x_{1}, x_{2}, \cdots, x_{n}\right) \mid x_{i} \in \mathbf{R}, i=1,2, \cdots, n\right\}
Rn=R��R��?��R={(x1?,x2?,?,xn?)�Oxi?��R,i=1,2,?,n}
R
n
\mathbf{R}^{n}
Rn �е�Ԫ��
(
x
1
,
x
2
,
?
?
,
x
n
)
\left(x_{1}, x_{2}, \cdots, x_{n}\right)
(x1?,x2?,?,xn?) ��ʱҲ�õ�����ĸ
x
\boldsymbol{x}
x ����ʾ, ��
x
=
(
x
1
,
x
2
,
?
?
,
\boldsymbol{x}=\left(x_{1}, x_{2}, \cdots,\right.
x=(x1?,x2?,?,
x
n
)
.
\left.x_{n}\right) .
xn?). �����е�
x
i
(
i
=
1
,
2
,
?
?
,
n
)
x_{i}(i=1,2, \cdots, n)
xi?(i=1,2,?,n) ��Ϊ��ʱ,��������Ԫ��Ϊ
R
n
\mathbf{R}^{n}
Rn �е���Ԫ,��Ϊ
0�� O. �ڽ���������,ͨ��ֱ������ϵ,
R
2
\mathbf{R}^{2}
R2 (��
R
3
\mathbf{R}^{3}
R3 )�е�Ԫ�طֱ���ƽ��(��ռ�)�еĵ����������һһ��Ӧ��
Ϊ���ڼ���
R
n
\mathbf{R}^{n}
Rn �е�Ԫ��֮�佨����ϵ,��
R
n
\mathbf{R}^{n}
Rn �ж����ߴ���������:
��
x
=
(
x
1
,
x
2
,
?
?
,
x
n
)
,
y
=
(
y
1
,
y
2
,
?
?
,
y
n
)
x=\left(x_{1}, x_{2}, \cdots, x_{n}\right), y=\left(y_{1}, y_{2}, \cdots, y_{n}\right)
x=(x1?,x2?,?,xn?),y=(y1?,y2?,?,yn?) Ϊ
R
n
\mathbf{R}^{n}
Rn ����������Ԫ��
,
��
��
R
, \lambda \in \mathbf{R}
,����R�涨:
x
+
y
=
(
x
1
+
y
1
,
x
2
+
y
2
,
?
?
,
x
n
+
y
n
)
,
��
x
=
(
��
x
1
,
��
x
2
,
?
?
,
��
x
n
)
\begin{array}{l} x+y=\left(x_{1}+y_{1}, x_{2}+y_{2}, \cdots, x_{n}+y_{n}\right), \\ \lambda x=\left(\lambda x_{1}, \lambda x_{2}, \cdots, \lambda x_{n}\right) \end{array}
x+y=(x1?+y1?,x2?+y2?,?,xn?+yn?),��x=(��x1?,��x2?,?,��xn?)?
������������������ļ���
R
n
\mathbf{R}^{n}
Rn ��Ϊ
n
n
n ά�ռ�.
R
n
\mathbf{R}^{n}
Rn �е�
x
=
(
x
1
,
x
2
,
?
?
,
x
n
)
\boldsymbol{x}=\left(x_{1}, x_{2}, \cdots, x_{n}\right)
x=(x1?,x2?,?,xn?) �͵�
y
=
(
y
1
,
y
2
,
?
?
,
y
n
)
\boldsymbol{y}=\left(y_{1}, y_{2}, \cdots, y_{n}\right)
y=(y1?,y2?,?,yn?) ��ľ���, ����
��
(
x
,
y
)
,
\rho(x, y),
��(x,y), �涨
��
(
x
,
y
)
=
(
x
1
?
y
1
)
2
+
(
x
2
?
y
2
)
2
+
?
+
(
x
n
?
y
n
)
2
\rho(x, y)=\sqrt{\left(x_{1}-y_{1}\right)^{2}+\left(x_{2}-y_{2}\right)^{2}+\cdots+\left(x_{n}-y_{n}\right)^{2}}
��(x,y)=(x1??y1?)2+(x2??y2?)2+?+(xn??yn?)2?
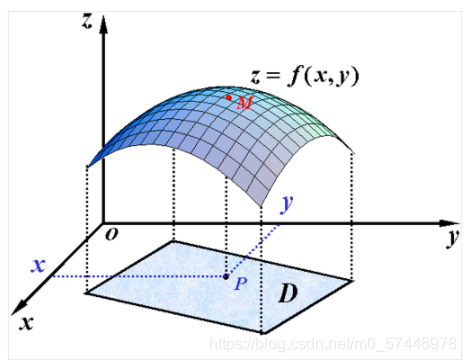
(2)��Ԫ����:
��
D
D
D ��
R
2
\mathbf{R}^{2}
R2 ��һ���ǿ��Ӽ�,��ӳ��
f
:
D
��
R
f: D \rightarrow \mathbf{R}
f:D��R ������
D
D
D �ϵĶ�Ԫ����,ͨ����Ϊ
z
=
f
(
x
,
y
)
,
(
x
,
y
)
��
D
z=f(x, y),(x, y) \in D
z=f(x,y),(x,y)��D
��
z
=
f
(
P
)
,
P
��
D
z=f(P), P \in D
z=f(P),P��D
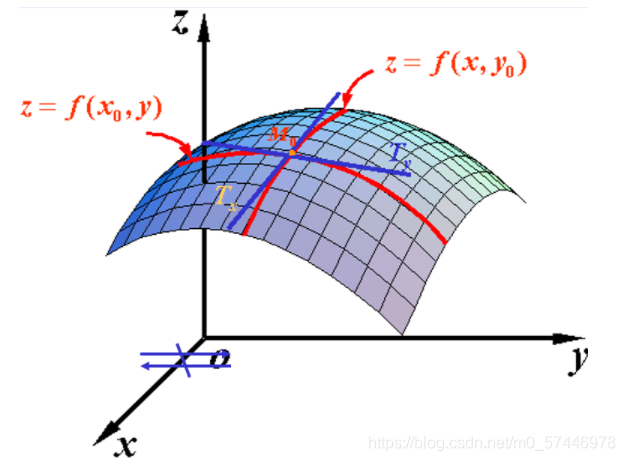
3.2 ��Ԫ������ƫ����
����:
���Ԫ����
=
f
(
x
,
y
)
=f(x, y)
=f(x,y) �ڵ�
(
x
0
,
y
0
)
\left(x_{0}, y_{0}\right)
(x0?,y0?) ��ijһ�������ж���,���̶���
y
0
y_{0}
y0? ��x��
x
0
x_{0}
x0? ��������
��
x
\Delta x
��xʱ, ��Ӧ�ĺ���������
��
x
z
=
f
(
x
0
+
��
x
,
y
0
)
?
f
(
x
0
,
y
0
)
.
\Delta_{x} z=f\left(x_{0}+\Delta x, y_{0}\right)-f\left(x_{0}, y_{0}\right) .
��x?z=f(x0?+��x,y0?)?f(x0?,y0?).
���
lim
?
��
x
��
0
��
x
z
��
x
\lim _{\Delta x \rightarrow 0} \frac{\Delta_{x} z}{\Delta x}
lim��x��0?��x��x?z? ����,�ͳƴ˼���Ϊ����
z
=
f
(
x
,
y
)
z=f(x, y)
z=f(x,y)
�ڵ�(
x
0
,
y
0
)
\left.x_{0}, y_{0}\right)
x0?,y0?) ����x��ƫ����.
����
?
z
?
x
�O
(
x
0
,
y
0
)
,
?
f
?
x
�O
(
x
0
,
y
0
)
,
z
x
�O
(
x
0
,
y
0
)
,
f
x
(
x
0
,
y
0
)
.
\frac{\partial z}{\partial x}\left|\left(x_{0}, y_{0}\right), \frac{\partial f}{\partial x}\right|\left(x_{0}, y_{0}\right)^{, z_{x} \mid\left(x_{0}, y_{0}\right)}, f_{x}\left(x_{0}, y_{0}\right) .
?x?z?�O�O�O?(x0?,y0?),?x?f?�O�O�O?(x0?,y0?),zx?�O(x0?,y0?),fx?(x0?,y0?).
��
?
z
?
x
�O
(
x
0
,
y
0
)
=
lim
?
��
x
��
0
��
x
z
��
x
=
lim
?
��
x
��
0
f
(
x
0
+
��
x
,
y
0
)
?
f
(
x
0
,
y
0
)
��
x
\left.\frac{\partial z}{\partial x}\right|_{\left(x_{0}, y_{0}\right)}=\lim _{\Delta x \rightarrow 0} \frac{\Delta_{x} z}{\Delta x}=\lim _{\Delta x \rightarrow 0} \frac{f\left(x_{0}+\Delta x, y_{0}\right)-f\left(x_{0}, y_{0}\right)}{\Delta x}
?x?z?�O�O?(x0?,y0?)?=lim��x��0?��x��x?z?=lim��x��0?��xf(x0?+��x,y0?)?f(x0?,y0?)?
����:
��
z
=
x
2
+
3
x
y
+
y
2
z=x^{2}+3 x y+y^{2}
z=x2+3xy+y2 �ڵ� (1,2) ����ƫ����.
��:
��
y
y
y ��������,��
?
z
?
x
=
2
x
+
3
y
\frac{\partial z}{\partial x}=2 x+3 y
?x?z?=2x+3y
��
x
x
x ��������,��
?
z
?
y
=
3
x
+
2
y
\frac{\partial z}{\partial y}=3 x+2 y
?y?z?=3x+2y
��(1,2)��������Ľ��,�͵�
?
z
?
x
�O
x
=
1
y
=
2
=
2
?
1
+
3
?
2
=
8
?
z
?
y
�O
x
=
1
y
=
2
=
3
?
1
+
2
?
2
=
7
\begin{array}{l} \left.\frac{\partial z}{\partial x}\right|_{x=1 \atop y=2}=2 \cdot 1+3 \cdot 2=8 \\ \left.\frac{\partial z}{\partial y}\right|_{x=1 \atop y=2}=3 \cdot 1+2 \cdot 2=7 \end{array}
?x?z?�O�O?y=2x=1??=2?1+3?2=8?y?z?�O�O�O?y=2x=1??=3?1+2?2=7?
3.3 �ݶ�����
�ݶȵı�����һ������(ʸ��),��ʾijһ�����ڸõ㴦�ķ��������Ÿ÷���ȡ�����ֵ,�������ڸõ㴦���Ÿ÷���(���ݶȵķ���)�仯���,�仯�����(Ϊ���ݶȵ�ģ)��
����:���Ԫ����
z
=
f
(
x
,
y
)
z=f(x, y)
z=f(x,y) ��ƽ������D�Ͼ���һ������ƫ����,�����ÿһ����P(x, y)���ɶ���һ������
{
?
f
?
x
,
?
f
?
y
}
=
f
x
(
x
,
y
)
i
��
+
f
y
(
x
,
y
)
j
��
,
\left\{\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}\right\}=f_{x}(x, y) \bar{i}+f_{y}(x, y) \bar{j},
{?x?f?,?y?f?}=fx?(x,y)i��+fy?(x,y)j��?, �ú����ͳ�Ϊ����
z
=
f
(
x
,
y
)
z=f(x, y)
z=f(x,y) �ڵ�P
(
x
,
y
)
(\mathrm{x}, \mathrm{y})
(x,y) ���ݶ�,����gradf
(
x
,
y
)
(\mathrm{x}, \mathrm{y})
(x,y) ��
?
f
(
x
,
y
)
\nabla f(x, y)
?f(x,y),����:
gradf
?
(
x
,
y
)
=
?
f
(
x
,
y
)
=
{
?
f
?
x
,
?
f
?
y
}
=
f
x
(
x
,
y
)
i
��
+
f
y
(
x
,
y
)
j
��
\operatorname{gradf}(\mathrm{x}, \mathrm{y})=\nabla f(x, y)=\left\{\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}\right\}=f_{x}(x, y) \bar{i}+f_{y}(x, y) \bar{j}
gradf(x,y)=?f(x,y)={?x?f?,?y?f?}=fx?(x,y)i��+fy?(x,y)j��?
����
?
=
?
?
x
i
��
+
?
?
y
j
��
\nabla=\frac{\partial}{\partial x} \bar{i}+\frac{\partial}{\partial y} \bar{j}
?=?x??i��+?y??j��? ��Ϊ(��ά��)���������ӻ�Nabla����,
?
f
=
?
f
?
x
i
��
+
?
f
?
y
j
��
\nabla f=\frac{\partial f}{\partial x} \bar{i}+\frac{\partial f}{\partial y} \bar{j}
?f=?x?f?i��+?y?f?j��? ��
����:�������
f
(
x
,
y
)
=
x
2
+
y
2
f(x,y) = x^2 + y^2
f(x,y)=x2+y2���ݶ�������

3.4 �ſ˱Ⱦ���(Jacobian����)
����
F
:
R
n
��
R
m
F: \mathbb{R}_{n} \rightarrow \mathbb{R}_{m}
F:Rn?��Rm? ��һ����nάŷ�Ͽռ�ӳ�䵽��mάŷ�Ͽռ�ĺ�����
���������m��ʵ�������:
y
1
(
x
1
,
?
?
,
x
n
)
,
?
?
,
y
m
(
x
1
,
?
?
,
x
n
)
y_{1}\left(x_{1}, \cdots, x_{n}\right), \cdots, y_{m}\left(x_{1}, \cdots, x_{n}\right)
y1?(x1?,?,xn?),?,ym?(x1?,?,xn?) ����Щ������ƫ����(�������)�������һ��m��n�еľ���,������������ν���ſ� �Ⱦ���:
[
?
y
1
?
x
1
?
?
y
1
?
x
n
?
?
?
?
y
m
?
x
1
?
?
y
m
?
x
n
]
\left[\begin{array}{ccc} \frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}} \end{array}\right]
?????x1??y1????x1??ym????????xn??y1????xn??ym???????
�ɼ�,�ݶ��������ſ˱Ⱦ��������!
����:��
F
=
(
f
1
(
x
,
y
)
,
f
(
x
,
y
)
)
T
F=(f_1(x,y),f_(x,y))^T
F=(f1?(x,y),f(?x,y))T���ſ˱Ⱦ���,����
f
1
(
x
,
y
)
=
2
x
2
+
y
2
,
f
2
(
x
,
y
)
=
x
2
+
3
y
2
f_1(x,y) = 2x^2 + y^2,f_2(x,y) = x^2 + 3y^2
f1?(x,y)=2x2+y2,f2?(x,y)=x2+3y2��


3.5 ��ɭ����(Hessian ����)
��������(Hessian Matrix),��������ɭ����ɪ�����������,��һ����Ԫ�����Ķ���ƫ�������ɵķ���,�����˺����ľֲ����ʡ�
����ѧ��,��ɭ����(Hessian matrix �� Hessian)��һ���Ա���Ϊ������ʵֵ�����Ķ���ƫ������ɵķ������,���O��һʵ������
f
(
x
1
,
x
2
,
��
,
x
n
)
f\left(x_{1}, x_{2}, \ldots, x_{n}\right)
f(x1?,x2?,��,xn?)
���
f
f
f ���еĶ���ƫ����������,��ô
f
f
f �ĺ�ɭ����ĵ�
i
j
i j
ij ��,��:
H
(
f
)
i
j
(
x
)
=
D
i
D
j
f
(
x
)
H(f)_{i j}(x)=D_{i} D_{j} f(x)
H(f)ij?(x)=Di?Dj?f(x)
����
x
=
(
x
1
,
x
2
,
��
,
x
n
)
,
x=\left(x_{1}, x_{2}, \ldots, x_{n}\right),
x=(x1?,x2?,��,xn?), ��
H
(
f
)
=
[
?
2
f
?
x
1
2
?
2
f
?
x
1
?
x
2
?
?
2
f
?
x
1
?
x
n
?
2
f
?
x
2
?
x
1
?
2
f
?
x
2
2
?
?
2
f
?
x
2
?
x
n
?
?
?
?
?
2
f
?
x
n
?
x
1
?
2
f
?
x
n
?
x
2
?
?
2
f
?
x
n
2
]
H(f)=\left[\begin{array}{cccc} \frac{\partial^{2} f}{\partial x_{1}^{2}} & \frac{\partial^{2} f}{\partial x_{1} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{1} \partial x_{n}} \\ \frac{\partial^{2} f}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{2}^{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{2} \partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^{2} f}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{n} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{n}^{2}} \end{array}\right]
H(f)=?????????x12??2f??x2??x1??2f???xn??x1??2f???x1??x2??2f??x22??2f???xn??x2??2f????????x1??xn??2f??x2??xn??2f???xn2??2f??????????
ʵ����,Hessian�������ݶ�����g(x)���Ա���x��Jacobian����
����:��
f
(
x
,
y
)
=
2
x
2
+
y
2
f(x,y)=2x^2+y^2
f(x,y)=2x2+y2�ĺ�ɭ����

4.�����ļ�ֵ����
4.1 �����ļ�ֵ����ֵ�ĸ���
��ֵ:�躯��
f
(
x
)
f(x)
f(x) �ڵ�
x
0
x_{0}
x0? ��ij����
U
(
x
0
)
U\left(x_{0}\right)
U(x0?) ���ж���,�������ȥ������U
(
x
0
)
\left(x_{0}\right)
(x0?) �ڵ���һ
x
x
x, �� A
f
(
x
)
<
f
(
x
0
)
?��?
f
(
x
)
>
f
(
x
0
)
f(x)<f\left(x_{0}\right) \text { �� } f(x)>f\left(x_{0}\right)
f(x)<f(x0?)?��?f(x)>f(x0?)
��ô�ͳ�
f
(
x
0
)
f\left(x_{0}\right)
f(x0?) �Ǻ�����һ������ֵ��Сֵ�������ļ���ֵ�ͼ�Сֵͳ��Ϊ�����ļ�ֵ, ʹ����ȡ�ü�ֵ�ĵ㱻������ֵ�㡣
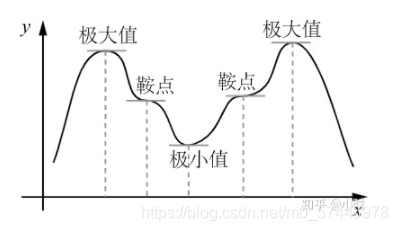
��ֵ�Ǻ������䶨������ȡ�����ֵ(����Сֵ)�ĵ�ĺ���ֵ����ֵ�Ǿֲ��Եĸ���,����ֵ��ȫ���Եĸ��
4.2 ����������
һԪ���������:
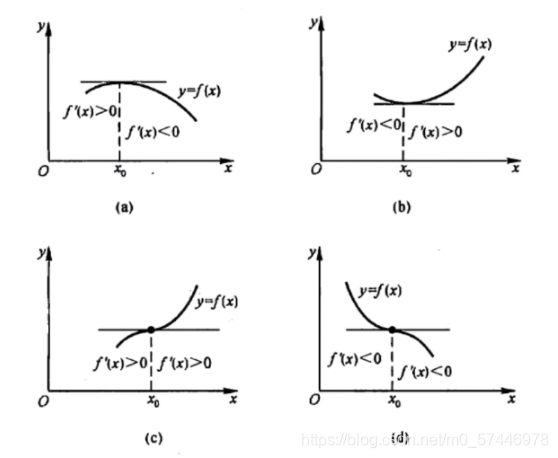
1.�ж���ֵ��һ�׳������:
�躯��
f
(
x
)
f(x)
f(x) ��
x
0
x_{0}
x0? ������,����
x
0
x_{0}
x0? ��ijȥ������
U
(
x
0
,
��
)
U\left(x_{0}, \delta\right)
U(x0?,��) �ڿɵ�
(1) ��
x
��
(
x
0
?
��
,
x
0
)
x \in\left(x_{0}-\delta, x_{0}\right)
x��(x0??��,x0?) ʱ,
f
��
(
x
)
>
0
,
f^{\prime}(x)>0,
f��(x)>0, ��
x
��
(
x
0
,
x
0
+
��
)
x \in\left(x_{0}, x_{0}+\delta\right)
x��(x0?,x0?+��) ʱ,
f
��
(
x
)
<
0
,
f^{\prime}(x)<0,
f��(x)<0, ��
f
(
x
)
f(x)
f(x) ��
x
0
x_{0}
x0? ��ȡ�ü���ֵ;
(2) ��
x
��
(
x
0
?
��
,
x
0
)
x \in\left(x_{0}-\delta, x_{0}\right)
x��(x0??��,x0?) ʱ,
f
��
(
x
)
<
0
f^{\prime}(x)<0
f��(x)<0,��
x
��
(
x
0
,
x
0
+
��
)
x \in\left(x_{0}, x_{0}+\delta\right)
x��(x0?,x0?+��) ʱ,
f
��
(
x
)
>
0
f^{\prime}(x)>0
f��(x)>0,��
f
(
x
)
f(x)
f(x) ��
x
0
x_{0}
x0? ��ȡ�ü�Сֵ
(3) ��
x
��
U
�B
(
x
0
,
��
)
x \in \dot{U}\left(x_{0}, \delta\right)
x��U�B(x0?,��) ʱ,
f
��
(
x
)
f^{\prime}(x)
f��(x) �ķ��ű��ֲ���,��
f
(
x
)
f(x)
f(x) ��
x
0
x_{0}
x0? ��û�м�ֵ
2.�ж���ֵ�Ķ��׳������:
�躯��
f
(
x
)
f(x)
f(x) ��
x
0
x_{0}
x0? �����������
f
��
(
x
0
)
=
0
,
f
��
��
(
x
0
)
��
0
f^{\prime}\left(x_{0}\right)=0, \quad f^{\prime \prime}\left(x_{0}\right) \neq 0
f��(x0?)=0,f����(x0?)��?=0 ��ô:
(1) ��
f
��
��
(
x
0
)
<
0
f^{\prime \prime}\left(x_{0}\right)<0
f����(x0?)<0 ʱ,����
f
(
x
)
f(x)
f(x) ��
x
0
x_{0}
x0? ��ȡ�ü���ֵ;
(2) ��
f
��
��
(
x
0
)
>
0
f^{\prime \prime}\left(x_{0}\right)>0
f����(x0?)>0 ʱ,����
f
(
x
)
f(x)
f(x) ��
x
0
x_{0}
x0? ��ȡ�ü�Сֵ.
��Ԫ���������
����:(��Ԫ����ȡ�ü�ֵ�ij������)�������
z
=
f
(
x
,
y
)
z=f(x, y)
z=f(x,y) �ڵ�
(
x
0
,
y
0
)
\left(x_{0}, y_{0}\right)
(x0?,y0?) ��ij�����ھ��������Ķ���ƫ����,
(
x
0
,
y
0
)
\left(x_{0}, y_{0}\right)
(x0?,y0?) ������פ��,��:
A
=
f
x
x
(
x
0
,
y
0
)
,
B
=
f
x
y
(
x
0
,
y
0
)
,
C
=
f
y
y
(
x
0
,
y
0
)
��
=
B
2
?
A
C
\begin{array}{c} A=f_{x x}\left(x_{0}, y_{0}\right), B=f_{x y}\left(x_{0}, y_{0}\right), C=f_{y y}\left(x_{0}, y_{0}\right) \\ \Delta=B^{2}-A C \end{array}
A=fxx?(x0?,y0?),B=fxy?(x0?,y0?),C=fyy?(x0?,y0?)��=B2?AC?
��:
(1)��
��
<
0
\Delta<0
��<0 ʱ,
f
(
x
,
y
)
f(x, y)
f(x,y) ��
(
x
0
,
y
0
)
\left(x_{0}, y_{0}\right)
(x0?,y0?) ȡ�ü�ֵ. ����
A
>
0
A>0
A>0 ʱȡ��Сֵ,
A
<
0
A<0
A<0 ʱȡ����ֵ.
(2)��
��
>
0
\Delta>0
��>0 ʱ,
f
(
x
0
,
y
0
)
f\left(x_{0}, y_{0}\right)
f(x0?,y0?) ���Ǽ�ֵ.
(3)��
��
=
0
\Delta=0
��=0 ʱ, ����ȷ��,���һ���ж�.
�����Ͻ��ı���:
��n��Ԫʵ����
f
(
x
1
,
x
2
,
?
?
,
x
n
)
f\left(x_{1}, x_{2}, \cdots, x_{n}\right)
f(x1?,x2?,?,xn?) �ڵ�
M
0
(
a
1
,
a
2
,
��
,
a
n
)
M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right)
M0?(a1?,a2?,��,an?) ���������ж�������ƫ��,����:
?
f
?
x
j
�O
(
a
1
,
a
2
,
��
,
a
n
)
=
0
,
j
=
1
,
2
,
��
,
n
\left.\frac{\partial f}{\partial x_{j}}\right|_{\left(a_{1}, a_{2}, \ldots, a_{n}\right)}=0, j=1,2, \ldots, n
?xj??f?�O�O�O�O?(a1?,a2?,��,an?)?=0,j=1,2,��,n
����
A
=
[
?
2
f
?
x
1
2
?
2
f
?
x
1
?
x
2
?
?
2
f
?
x
1
?
x
n
?
2
f
?
x
2
?
x
1
?
2
f
?
x
2
2
?
?
2
f
?
x
2
?
x
n
?
?
?
?
?
2
f
?
x
n
?
x
1
?
2
f
?
x
n
?
x
2
?
?
2
f
?
x
n
2
]
A=\left[\begin{array}{cccc} \frac{\partial^{2} f}{\partial x_{1}^{2}} & \frac{\partial^{2} f}{\partial x_{1} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{1} \partial x_{n}} \\ \frac{\partial^{2} f}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{2}^{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{2} \partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^{2} f}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{n} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{n}^{2}} \end{array}\right]
A=?????????x12??2f??x2??x1??2f???xn??x1??2f???x1??x2??2f??x22??2f???xn??x2??2f????????x1??xn??2f??x2??xn??2f???xn2??2f??????????
�������½��:
(1) ��A��������ʱ,
f
(
x
1
,
x
2
,
?
?
,
x
n
)
f\left(x_{1}, x_{2}, \cdots, x_{n}\right)
f(x1?,x2?,?,xn?) ��
M
0
(
a
1
,
a
2
,
��
,
a
n
)
M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right)
M0?(a1?,a2?,��,an?) ���Ǽ�Сֵ;
(2) ��A��������ʱ,
f
(
x
1
,
x
2
,
?
?
,
x
n
)
f\left(x_{1}, x_{2}, \cdots, x_{n}\right)
f(x1?,x2?,?,xn?) ��
M
0
(
a
1
,
a
2
,
��
,
a
n
)
M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right)
M0?(a1?,a2?,��,an?) ���Ǽ���ֵ;
(3) ��A��������ʱ,
M
0
(
a
1
,
a
2
,
��
,
a
n
)
M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right)
M0?(a1?,a2?,��,an?) ���Ǽ�ֵ�㡣
(4) ��AΪ�����������븺������ʱ,
M
0
(
a
1
,
a
2
,
��
,
a
n
)
M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right)
M0?(a1?,a2?,��,an?) �ǡ�����"��ֵ��,����Ҫ���������������ж���

����:����Ԫ����
f
(
x
,
y
,
z
)
=
x
2
+
y
2
+
z
2
+
2
x
+
4
y
?
6
z
f(x, y, z)=x^{2}+y^{2}+z^{2}+2 x+4 y-6 z
f(x,y,z)=x2+y2+z2+2x+4y?6z �ļ�ֵ��
��: ��Ϊ
?
f
?
x
=
2
x
+
2
,
?
f
?
y
=
2
y
+
4
,
?
f
?
z
=
2
z
?
6
,
\frac{\partial f}{\partial x}=2 x+2, \frac{\partial f}{\partial y}=2 y+4, \frac{\partial f}{\partial z}=2 z-6,
?x?f?=2x+2,?y?f?=2y+4,?z?f?=2z?6, �ʸ���Ԫ������פ���� (-1,-2,3) ��
����Ϊ
?
2
f
?
x
2
=
2
,
?
2
f
?
y
2
=
2
,
?
2
f
?
z
2
=
2
,
?
2
f
?
x
?
y
=
0
,
?
2
f
?
x
?
z
=
0
,
?
2
f
?
y
?
z
=
0
\frac{\partial^{2} f}{\partial x^{2}}=2, \frac{\partial^{2} f}{\partial y^{2}}=2, \frac{\partial^{2} f}{\partial z^{2}}=2, \frac{\partial^{2} f}{\partial x \partial y}=0, \frac{\partial^{2} f}{\partial x \partial z}=0, \frac{\partial^{2} f}{\partial y \partial z}=0
?x2?2f?=2,?y2?2f?=2,?z2?2f?=2,?x?y?2f?=0,?x?z?2f?=0,?y?z?2f?=0
����:
A
=
(
2
0
0
0
2
0
0
0
2
)
A=\left(\begin{array}{ccc}2 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2\end{array}\right)
A=???200?020?002????
��ΪA����������,�� (-1,-2,3) �Ǽ�Сֵ��,�Ҽ�Сֵ
f
(
?
1
,
?
2
,
3
)
=
?
14
f(-1,-2,3)=-14
f(?1,?2,3)=?14 ��
4.3 �����ʽԼ�����Ż�����(�������ճ��ӷ�)
����:
������Ϊ
a
2
a^{2}
a2 ��������ij�����������
����(1):��Ϊ������Լ�����Ż�����,��ʹ��4.2�ڵķ���
�賤���������ij�Ϊ
x
,
y
,
z
,
x, y, z,
x,y,z, �����
V
=
x
y
z
V=x y z
V=xyz
����ٶ������Ϊ
a
2
,
a^{2},
a2, �����Ա���
x
,
y
,
z
x, \quad y, \quad z
x,y,z ���������㸽������
2
(
x
y
+
y
z
+
x
z
)
=
a
2
2(x y+y z+x z)=a^{2}
2(xy+yz+xz)=a2
�����ֶ��Ա����и��������ļ�ֵ�����Ϊ������ֵ����û�и�������������ͽ���������ֵ�� ��������ֵ���Ի�Ϊ��������ֵ,������������,�ɽ�����2
2
(
x
y
+
y
z
+
x
z
)
=
a
2
,
2(x y+y z+x z)=a^{2},
2(xy+yz+xz)=a2, ��
z
z
z ����
x
,
y
x, \quad y
x,y ���
z
=
a
2
?
2
x
y
2
(
x
+
y
)
z=\frac{a^{2}-2 x y}{2(x+y)}
z=2(x+y)a2?2xy?
�ٰ�������
V
=
x
y
z
V=x y z
V=xyz ��,��������ͻ�Ϊ��
V
=
x
y
2
(
a
2
?
2
x
y
x
+
y
)
V=\frac{x y}{2}\left(\frac{a^{2}-2 x y}{x+y}\right)
V=2xy?(x+ya2?2xy?)
����(2):�������ճ��ӷ�
����:����
z
=
f
(
x
,
y
)
z=f(x, y)
z=f(x,y) ������
��
(
x
,
y
)
=
0
\varphi(x, y)=0
��(x,y)=0 �µļ�ֵ��
�����������պ���
L
(
x
,
y
)
=
f
(
x
,
y
)
+
��
��
(
x
,
y
)
L(x, y)=f(x, y)+\lambda \varphi(x, y)
L(x,y)=f(x,y)+����(x,y)
��ֵ������:
{
L
x
(
x
0
,
y
0
)
=
0
L
y
(
x
0
,
y
0
)
=
0
��
(
x
0
,
y
0
)
=
0
\left\{\begin{array}{l}L_{x}\left(x_{0}, y_{0}\right)=0 \\ L_{y}\left(x_{0}, y_{0}\right)=0 \\ \varphi\left(x_{0}, y_{0}\right)=0\end{array}\right.
????Lx?(x0?,y0?)=0Ly?(x0?,y0?)=0��(x0?,y0?)=0?
�ص�֮ǰ�����������,��֪
2
(
x
y
+
y
z
+
x
z
)
=
a
2
2(x y+{y} z+x z)=a^{2}
2(xy+yz+xz)=a2
�������պ�������д��
L
(
x
,
y
,
z
)
=
x
y
z
+
��
(
2
x
y
+
2
y
z
+
2
x
z
?
a
2
)
L(x, y, z)=x y z+\lambda\left(2 x y+2 y z+2 x z-a^{2}\right)
L(x,y,z)=xyz+��(2xy+2yz+2xz?a2)
�����
x
,
y
,
z
x, y, z
x,y,z ��ƫ����,��ʹ֮Ϊ��,�õ�
y
z
+
2
��
(
y
+
z
)
=
0
x
z
+
2
��
(
x
+
z
)
=
0
x
y
+
2
��
(
y
+
x
)
=
0
\begin{array}{l} y z+2 \lambda(y+z)=0 \\ x z+2 \lambda(x+z)=0 \\ x y+2 \lambda(y+x)=0 \end{array}
yz+2��(y+z)=0xz+2��(x+z)=0xy+2��(y+x)=0?
��������ʽ������������ʽ����,�ɵ�
x
y
=
x
+
z
y
+
z
,
y
z
=
x
+
y
x
+
z
\frac{x}{y}=\frac{x+z}{y+z}, \frac{y}{z}=\frac{x+y}{x+z}
yx?=y+zx+z?,zy?=x+zx+y?
���:
x
=
y
=
z
=
V
0
3
x=y=z=\sqrt[3]{V_{0}}
x=y=z=3V0??
5.̩�չ�ʽ
̩�չ�ʽ������һ������ʽ����ȥ�ƽ�һ�������ĺ���(������ʹ����ʽ����ͼ����ϸ����ĺ���ͼ��)�����һ���dz����Ӻ���,������ij���ֵ,ֱ������ʵ��,��ʱ�����ʹ��̩�չ�ʽȥ���Ƶ����ֵ,����̩�չ�ʽ��Ӧ��֮һ��̩�չ�ʽ�ڻ���ѧϰ����ҪӦ�����ݶȵ�����
����:��
n
n
n ��һ�������������������һ������a�������ϵĺ���
f
f
f ��
a
a
a �㴦
n
+
1
n+1
n+1 �οɵ�,��ô������������ϵ�����
x
x
x ����:
f
(
x
)
=
f
(
a
)
0
!
+
f
��
(
a
)
1
!
(
x
?
a
)
+
f
��
��
(
a
)
2
!
(
x
?
a
)
2
+
?
+
f
(
n
)
(
a
)
n
!
(
x
?
a
)
n
+
R
n
(
x
)
=
��
n
=
0
N
f
(
n
)
(
a
)
n
!
(
x
?
a
)
n
+
R
n
(
x
)
\begin{array}{c} f(x)=\frac{f(a)}{0 !}+\frac{f^{\prime}(a)}{1 !}(x-a)+\frac{f^{\prime \prime}(a)}{2 !}(x-a)^{2}+\cdots+\frac{f^{(n)}(a)}{n !}(x-a)^{n}+R_{n}(x) \\ =\sum_{n=0}^{N} \frac{f^{(n)}(a)}{n !}(x-a)^{n}+R_{n}(x) \end{array}
f(x)=0!f(a)?+1!f��(a)?(x?a)+2!f����(a)?(x?a)2+?+n!f(n)(a)?(x?a)n+Rn?(x)=��n=0N?n!f(n)(a)?(x?a)n+Rn?(x)?
���еĶ���ʽ��Ϊ������a����̩��չ��ʽ,
R
n
(
x
)
R_{n}(x)
Rn?(x) ��̩�չ�ʽ�����
6.�����ݶȵ��Ż������C�ݶ��½���
��ҵ:ʹ���ݶ��½������� y = c o s ( x ) y=cos(x) y=cos(x)������ x �� [ 0 , 2 �� ] x \in [0,2\pi] x��[0,2��]�ļ�Сֵ�㡣
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return np.power(x, 2)
def d_f_1(x):
'''
�����ķ�ʽ1
'''
return 2.0 * x
def d_f_2(f, x, delta=1e-4):
'''
�����ĵڶ��ַ���
'''
return (f(x+delta) - f(x-delta)) / (2 * delta)
# plot the function
xs = np.arange(-10, 11)
plt.plot(xs, f(xs))
learning_rate = 0.1
max_loop = 30
x_init = 10.0
x = x_init
lr = 0.1
x_list = []
for i in range(max_loop):
#d_f_x = d_f_1(x)
d_f_x = d_f_2(f, x)
x = x - learning_rate * d_f_x
x_list.append(x)
x_list = np.array(x_list)
plt.scatter(x_list,f(x_list),c="r")
plt.show()
print('initial x =', x_init)
print('arg min f(x) of x =', x)
print('f(x) =', f(x))
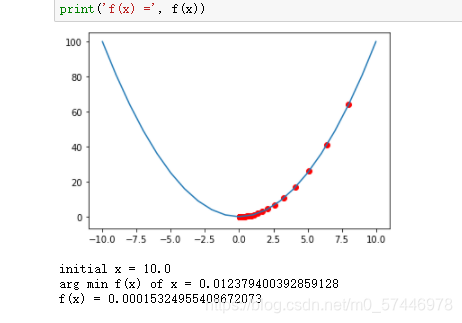
initial x = 10.0
arg min f(x) of x = 0.012379400392859128
f(x) = 0.00015324955408672073
7.�����ݶȵ��Ż������Cţ�ٵ�����
��ҵ:ʹ��ţ�ٵ��������� y = c o s ( x ) y=cos(x) y=cos(x)������ x �� [ 0 , 2 �� ] x \in [0,2\pi] x��[0,2��]�ļ�Сֵ�㡣
ţ�ٷ�:
����ţ�ٷ�����⺯��ֵΪ0ʱ���Ա���ȡֵ�ķ�����
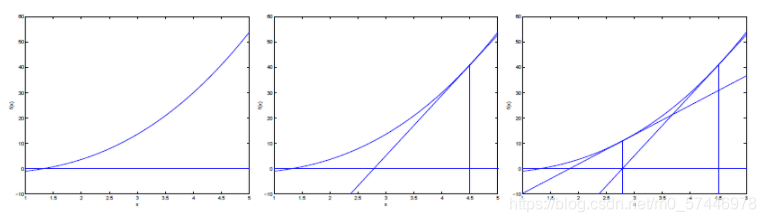
����ţ�ٷ����Ŀ�꺯������Сֵ��ʵ��ת������ʹĿ�꺯����һ��Ϊ0�IJ���ֵ����һת��������������,�����ļ�ֵ�㴦��һ����Ϊ0.
������������ڵ�ǰλ��x0��ú���������,�����ߺ�x��Ľ���x1,��Ϊ�µ�x0,�ظ��������,ֱ������ͺ���������غϡ���ʱ�IJ���ֵ����ʹ��Ŀ�꺯��ȡ�ü�ֵ�IJ���ֵ��
�������������:
�����Ĺ�ʽ����:
��
:
=
��
?
��
?
��
(
��
)
?
��
��
(
��
)
\theta:=\theta-\alpha \frac{\ell^{\prime}(\theta)}{\ell^{\prime \prime}(\theta)}
��:=��?��?����(��)?��(��)?
��
��
\theta
��������ʱ, ţ�ٷ�����ʹ������ʽ�ӱ�ʾ:
��
:
=
��
?
��
H
?
1
?
��
?
(
��
)
\theta:=\theta-\alpha H^{-1} \nabla_{\theta} \ell(\theta)
��:=��?��H?1?��??(��)
����
H
H
H������ɭ����,��ʵ����Ŀ�꺯���Բ���
��
\theta
���Ķ�������
ţ�ٷ����ݶ��½����ıȽ�
1.ţ�ٷ�:��ͨ�����Ŀ�꺯����һ����Ϊ0ʱ�IJ���,�������Ŀ�꺯����Сֵʱ�IJ�����
�����ٶȺܿ졣
��ɭ��������ڵ��������в��ϼ�С,��������С������Ч����
ȱ��:��ɭ���������㸴��,���۱Ƚϴ�,���������ţ�ٷ���
2.�ݶ��½���:��ͨ���ݶȷ���Ͳ���,ֱ�����Ŀ�꺯������Сֵʱ�IJ�����
Խ�ӽ�����ֵʱ,����Ӧ�ò��ϼ�С,�����������ֵ����������
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
%matplotlib inline
from mpl_toolkits.mplot3d import Axes3D
class Rosenbrock():
def __init__(self):
self.x1 = np.arange(-100, 100, 0.0001)
self.x2 = np.arange(-100, 100, 0.0001)
#self.x1, self.x2 = np.meshgrid(self.x1, self.x2)
self.a = 1
self.b = 1
self.newton_times = 1000
self.answers = []
self.min_answer_z = []
# ������
def data(self):
z = np.square(self.a - self.x1) + self.b * np.square(self.x2 - np.square(self.x1))
#print(z.shape)
return z
# ���ţ��
def snt(self,x1,x2,z,alpha):
rand_init = np.random.randint(0,z.shape[0])
x1_init,x2_init,z_init = x1[rand_init],x2[rand_init],z[rand_init]
x_0 =np.array([x1_init,x2_init]).reshape((-1,1))
#print(x_0)
for i in range(self.newton_times):
x_i = x_0 - np.matmul(np.linalg.inv(np.array([[12*x2_init**2-4*x2_init+2,-4*x1_init],[-4*x1_init,2]])),np.array([4*x1_init**3-4*x1_init*x2_init+2*x1_init-2,-2*x1_init**2+2*x2_init]).reshape((-1,1)))
x_0 = x_i
x1_init = x_0[0,0]
x2_init = x_0[1,0]
answer = x_0
return answer
# ��ͼ
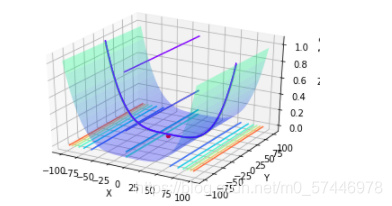
def plot_data(self,min_x1,min_x2,min_z):
x1 = np.arange(-100, 100, 0.1)
x2 = np.arange(-100, 100, 0.1)
x1, x2 = np.meshgrid(x1, x2)
a = 1
b = 1
z = np.square(a - x1) + b * np.square(x2 - np.square(x1))
fig4 = plt.figure()
ax4 = plt.axes(projection='3d')
ax4.plot_surface(x1, x2, z, alpha=0.3, cmap='winter') # ���ɱ���, alpha ���ڿ�������
ax4.contour(x1, x2, z, zdir='z', offset=-3, cmap="rainbow") # ����z����ͶӰ,Ͷ��x-yƽ��
ax4.contour(x1, x2, z, zdir='x', offset=-6, cmap="rainbow") # ����x����ͶӰ,Ͷ��y-zƽ��
ax4.contour(x1, x2, z, zdir='y', offset=6, cmap="rainbow") # ����y����ͶӰ,Ͷ��x-zƽ��
ax4.contourf(x1, x2, z, zdir='y', offset=6, cmap="rainbow") # ����y����ͶӰ���,Ͷ��x-zƽ��,contourf()����
ax4.scatter(min_x1,min_x2,min_z,c='r')
# �趨��ʾ��Χ
ax4.set_xlabel('X')
ax4.set_ylabel('Y')
ax4.set_zlabel('Z')
plt.show()
# ��ʼ
def start(self):
times = int(input("��������Ҫ����Ż��Ĵ���:"))
alpha = float(input("����������Ż��IJ���"))
z = self.data()
start_time = time.time()
for i in range(times):
answer = self.snt(self.x1,self.x2,z,alpha)
self.answers.append(answer)
min_answer = np.array(self.answers)
for i in range(times):
self.min_answer_z.append((1-min_answer[i,0,0])**2+(min_answer[i,1,0]-min_answer[i,0,0]**2)**2)
optimal_z = np.min(np.array(self.min_answer_z))
optimal_z_index = np.argmin(np.array(self.min_answer_z))
optimal_x1,optimal_x2 = min_answer[optimal_z_index,0,0],min_answer[optimal_z_index,1,0]
end_time = time.time()
running_time = end_time-start_time
print("�Ż���ʱ��:%.2f��!" % running_time)
self.plot_data(optimal_x1,optimal_x2,optimal_z)
if __name__ == '__main__':
snt = Rosenbrock()
snt.start()
�Ż���ʱ��:6.82��!