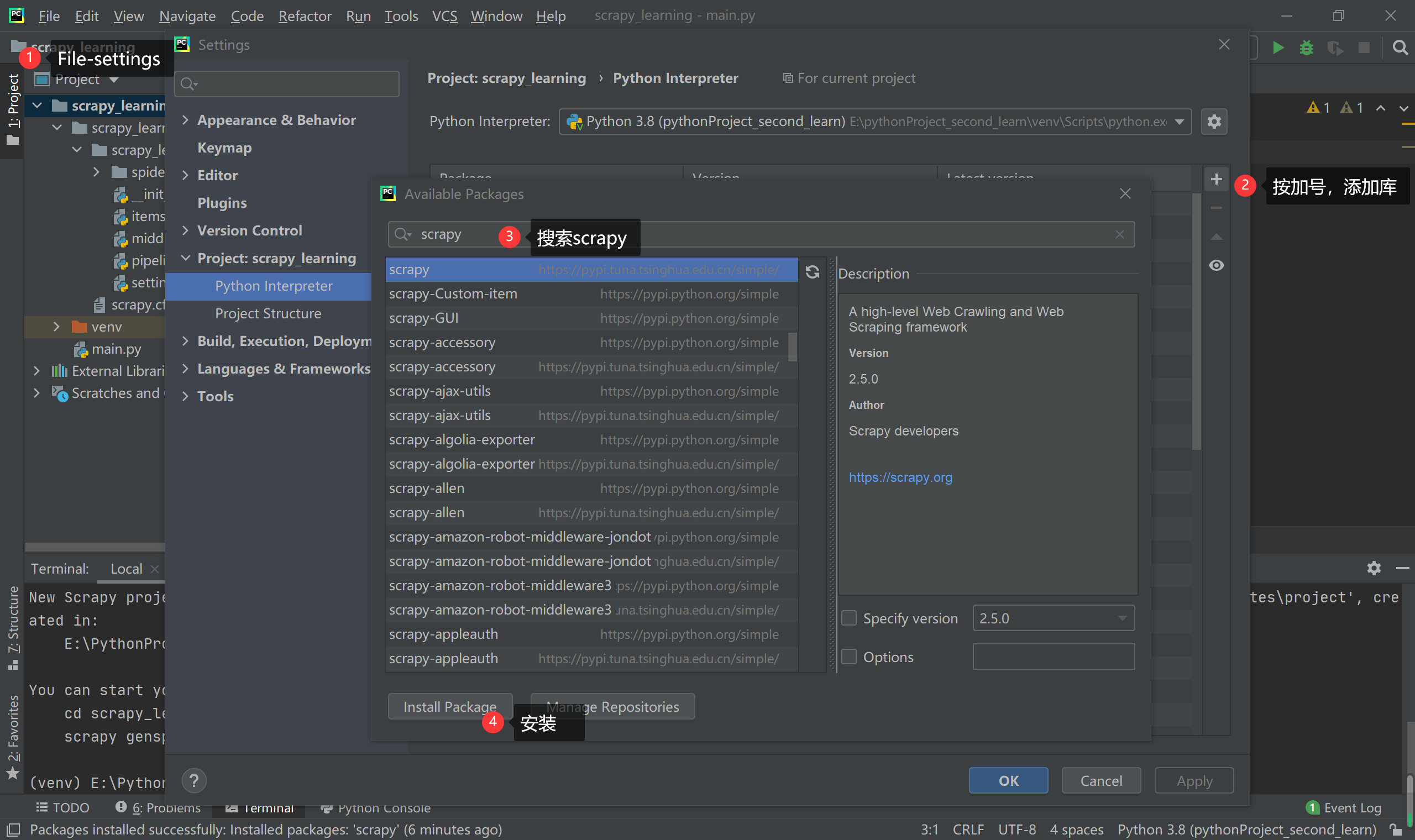
首先是scrapy库的安装
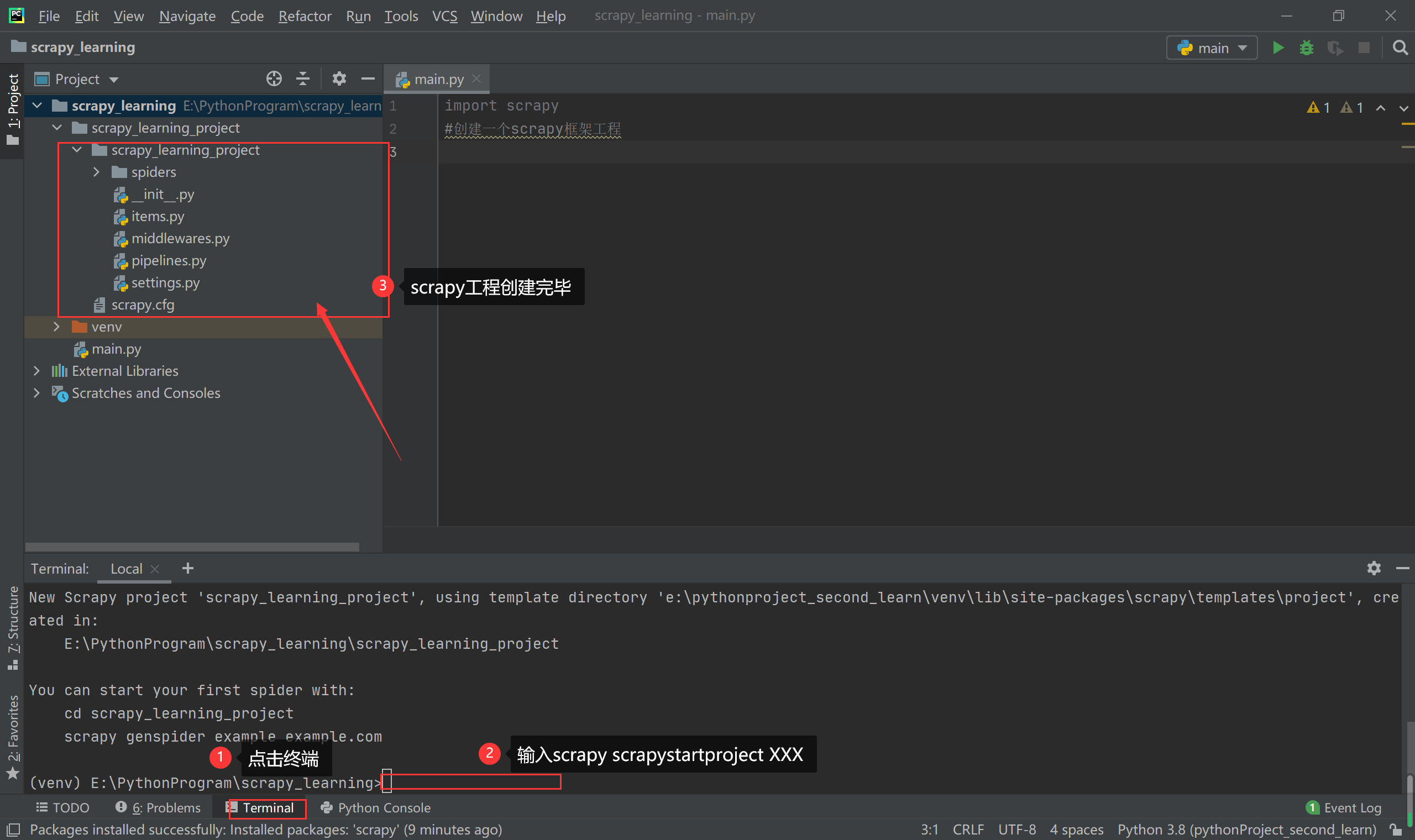
接着是scrapy工程创建,在下面的terminal中输入相应的指令进行scrapy工程的创建。scrapy startproject '工程名称'
注意:是startproject (下面图片2输入是错误的)
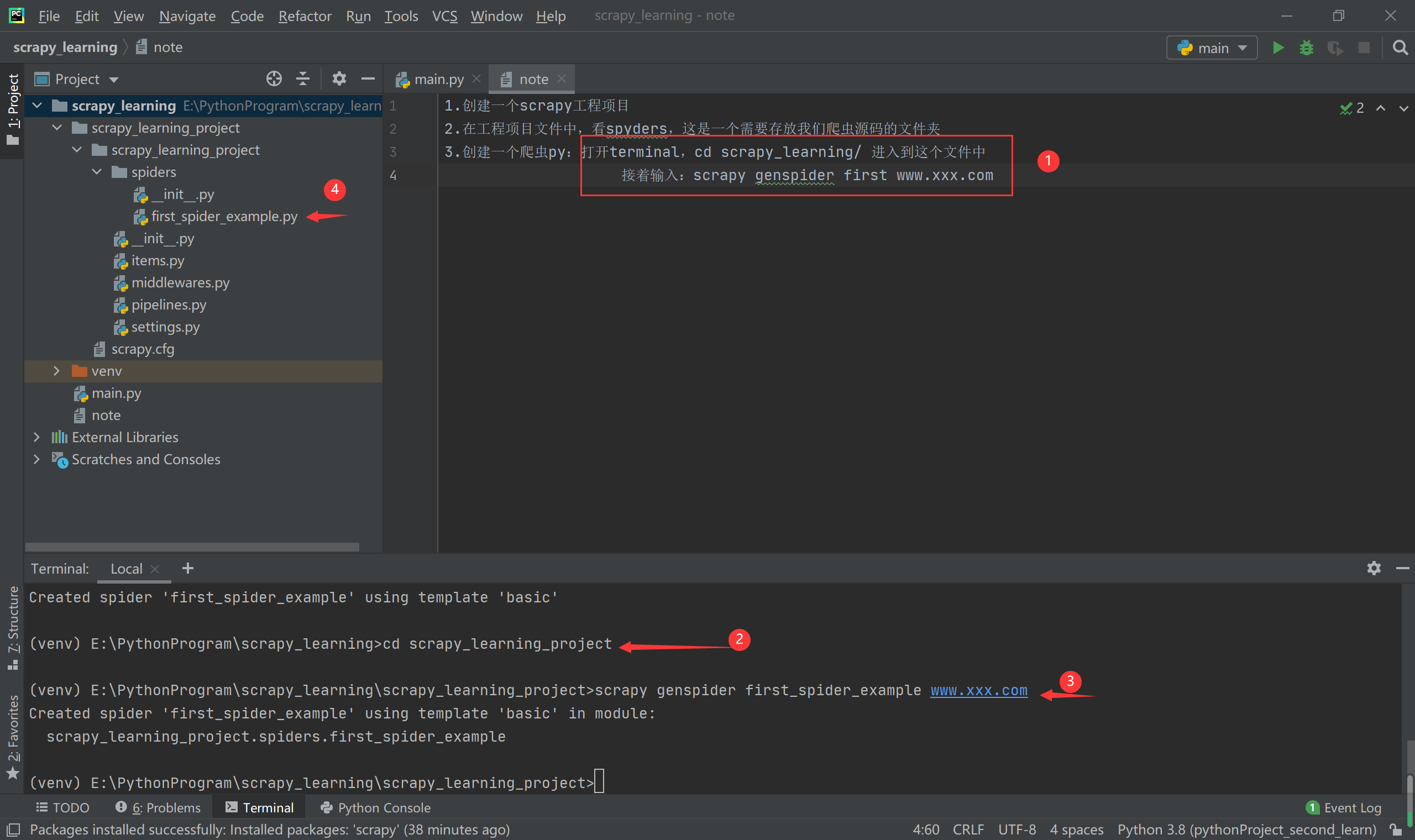
在这个工程文件夹中,spiders中是放的爬虫文件的源码,setting文件是配置文件
如果要执行一个工程就在terminal中输入scrapy crawl '爬虫工程名称'
我们来看一个刚刚创建的爬虫源码文件内容
import scrapy
class FirstSpiderExampleSpider(scrapy.Spider):
#三个属性
name = 'first_spider_example' #第一个属性是name 是爬虫文件唯一标识
allowed_domains = ['www.xxx.com'] #第二个属性是允许访问域名,(只允许访问的域名)一般都会将其注释掉
start_urls = ['http://www.xxx.com/'] #第三个属性是 起始的url列表,当执行这个爬虫文件的时候,会自动的得到所有这个起始url列表中的所有url的response对象
#用作于数据解析,
def parse(self, response):
pass