单核CPU:操作系统轮流让各个任务交替进行
多核CPU:多任务分配至多个CPU上进行,但是任务远超CPU个数,操作系统也会自动分配多个任务至多个CPU轮流执行
并发:当一个CPU时,多个线程操作时,把CPU运行时间分成若干多个时间段,每个线程在一个时间段上运行,当运行一个线程时,其他线程处于挂起状态。
并行:多个CPU时,线程可能非并发,一个CPU执行一个线程时,另一个CPU也可能在执行一个线程,两个线程互不抢占CPU资源
实现多任务的方式:
包含关系: 进程 》线程 》协程
多进程模式:
多线程模式:
协程:
进程:

进程的创建:
在linux系统上可以使用fork函数创建进程,在windows系统上可以使用multiprocess模块中的Process类来创建进程。
fork()本质上属于内建函数,通过os模块导入。
从函数模型上来看,子进程永远返回0,父进程返回子进程的PID。这意味着,每个子进程的创建都会在父进程中留下标记PID,当子进程溯源其父进程时,通过getppid()就可以找到父进程的PID
import os
pid=os.fork()
if pid<0:
print('创建进程失败')
elif pid==0:
print('这是子进程')
else:
print('这是父进程')
fork()详解可见:https://blog.csdn.net/qq_38526635/article/details/81903302
multiprocessing是一个包,而Process是包里__init__模块的一个类。
start()方法:启动并发进程
target参数:要运行的任务
name参数:进程的名字
args参数:往任务中传的参数,要求是可迭代的
terminate():终止进程
关于全局变量:#验证可知关于全局变量,每个进程有一份独立的全局变量,进程之间不影响全局变量的变化(可变类型与不可变类型都每个进程独立)。
import time
from multiprocessing import Process
m=1 #全局变量的验证
def task1(s):
global m
while True:
time.sleep(s)
m+=1
print('这是进程1',m)
def task2(s):
global m
while True:
time.sleep(s)
m+=1
print('这是进程2',m)
if __name__=='__main__':
p1 = Process(target=task1,name='1',args=(1,))
#p1.name='1',args为给target传参,且必须是可迭代的
p1.start() #子进程
print(p1.name) #父进程
p2 = Process(target=task2,name='2',args(2,)) #p2.name='2'
p2.start(p2.name)
print(p2.name)
for i in range(10):
m+=1
print(m)
#验证可知关于全局变量,每个进程有一份独立的全局变量,进程之间不影响全局变量的变化执行结果如下:
1 23224
2 23224
2
3
4
5
6
7
8
9
10
11
这是进程1 49156 23224 2
这是进程2 40552 23224 2
这是进程1 49156 23224 3
这是进程1 49156 23224 4
这是进程2 40552 23224 3
这是进程1 49156 23224 5
这是进程1 49156 23224 6
这是进程2 40552 23224 4
这是进程1 49156 23224 7
这是进程1 49156 23224 8
这是进程2 40552 23224 5
这是进程1 49156 23224 9
这是进程1 49156 23224 10
这是进程2 40552 23224 6
这是进程1 49156 23224 11
这是进程1 49156 23224 12
这是进程2 40552 23224 7
这是进程1 49156 23224 13
这是进程1 49156 23224 14
这是进程2 40552 23224 8
这是进程1 49156 23224 15
...自定义进程:
????????自定义进程的主要核心就是重写Proces类,而更进一步的是重写run方法,在进程调用start方法时,进行了两步操作,1.创建一个新进程 2.执行run方法,故重写run方法,就可以作自定义的进程
#自定义进程
from multiprocessing import Process
class MyProcess(Process):
#重写run方法
def run(self):
n=1
while True:
print("{}---->这是自定义进程{}".format(n,self.name))
n+=1
if __name__=="__main__":
myprocess01=MyProcess(name="取名的自定义进程")
myprocess01.start() #当运行start方法时:1.创建新的进程 2.执行run方法,故重写run方法
myprocess02=MyProcess(name="哈哈")
'''
只想传参,而不是执行关键字传参时,也可以重写__init__方法
'''
'''
from multiprocessing import Process
class MyProcess(Process):
#重写__init__
def __init__(self,name):
super(MyProcess, self).__init__()
self.name=name
#重写run方法
def run(self):
n=1
while True:
print("{}---->这是自定义进程{}".format(n,self.name))
n+=1
if __name__=="__main__":
myprocess01=MyProcess("看看有用不")
myprocess01.start() #当运行start方法时:1.创建新的进程 2.执行run方法,故重写run方法
myprocess02=MyProcess("你说呢")
myprocess02.start()
'''进程池:

1.进程池与主进程同生共死,需要保证主进程的存在。
2.池子中开辟五个地址不同的进程,添加任务相当于一个队列,当进程中的任务结束后,后面的任务 将用结束任务的进程立即填补,继续工作。
3.回调函数:Pool中callback参数是一个func,填的是回调函数,回调函数必有参数,他接收任务完成后返回的值。
4.非阻塞式进程池的好处:当有成千上百的进程时,电脑可承受不起,但是它可以复用进程,节省开销。能最大化的利用CPU,完成多进程的任务。
非阻塞式:?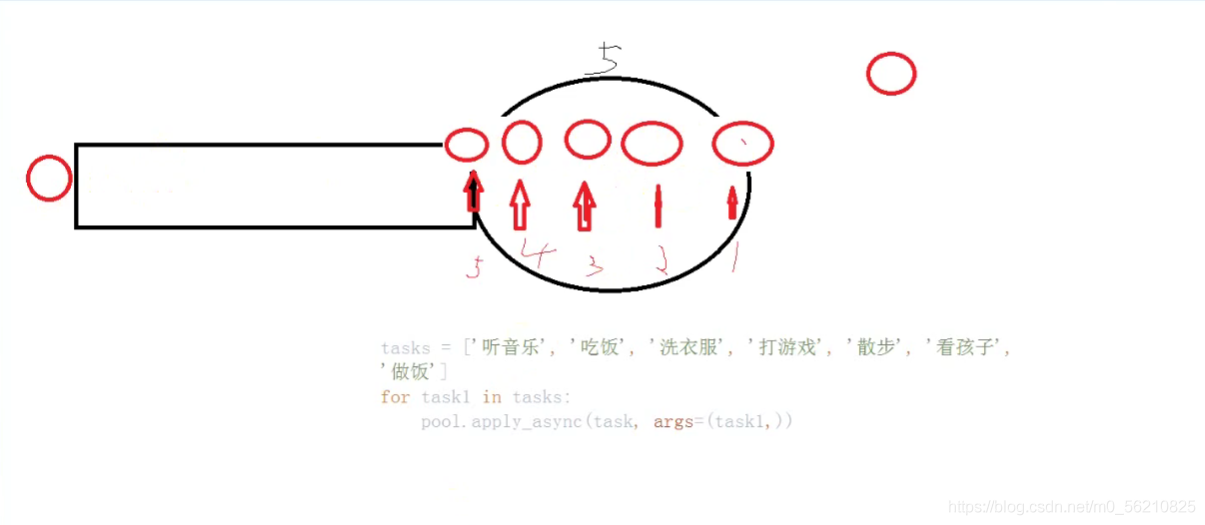
from multiprocessing import Pool
import time
from random import random
import os
def task(task_name):
print("开始做任务啦!",task_name)
start=time.time()
time.sleep(random()*2)
end=time.time()
#print("完成任务{},执行时间:{},任务号:{}".format(task_name,(end-start),os.getpid()))
return "完成任务{},执行时间:{},任务号:{}".format(task_name,(end-start),os.getpid())
def call_back_func(n): #回调函数的参数是执行进程结束返回的值
print(n)
if __name__=="__main__":
pool=Pool(5)
tasklist=["吃饭","睡觉","打游戏","听音乐","学习python","工作","写脚本","坐公交"]
for tasksub in tasklist:
pool.apply_async(task,args=(tasksub,),callback=call_back_func)
pool.close() #添加任务结束
pool.join() #当任务结束后让列表里的任务添加进池子,目的:阻塞主进程,进程池与主进程同生共死
print("task over!!!")开始做任务啦! 吃饭
开始做任务啦! 睡觉
开始做任务啦! 打游戏
开始做任务啦! 听音乐
开始做任务啦! 学习python
开始做任务啦! 工作? ? ? ? ? ? ? '''实际这个任务加载开始于下面完成任务学习python之后,但是回调函数是任务结束后输出的所以有延迟'''
完成任务学习python,执行时间:0.46526145935058594,任务号:11808
开始做任务啦! 写脚本完成任务吃饭,执行时间:0.6412773132324219,任务号:17616
开始做任务啦! 完成任务睡觉,执行时间:0.8637480735778809,任务号:11232坐公交
完成任务打游戏,执行时间:1.257415771484375,任务号:8996
完成任务听音乐,执行时间:1.3887248039245605,任务号:3208
'''这里新加进来的任务与之前完成的任务进程号一样'''
完成任务工作,执行时间:1.1936118602752686,任务号:11808? ?
完成任务写脚本,执行时间:1.8292784690856934,任务号:17616
完成任务坐公交,执行时间:1.7221262454986572,任务号:11232
task over!!!?阻塞式:
阻塞式与非阻塞式的代码上没有明显的区别,只有在调用实力对象的方法上有细微的区别,且因为是做完一个进程才开始下一个进程,所以用不上回调函数。
阻塞式并没有展示进程的优点,底层也没有队列的体现,而是进一个进程若他的任务不结束,其他进程就进不来。但是前面的进程结束了,在进程池中也依然开辟的新进程,在进程空间这一块跟非阻塞式是相同的。
from multiprocessing import Pool
import time
from random import random
import os
def task(task_name):
print("开始做任务啦!",task_name)
start=time.time()
time.sleep(random()*2)
end=time.time()
print("完成任务{},执行时间:{},任务号:{}".format(task_name,(end-start),os.getpid()))
#阻塞式没有(不需要)回调函数
#return "完成任务{},执行时间:{},任务号:{}".format(task_name,(end-start),os.getpid())
#def call_back_func(n):
#print(n)
if __name__=="__main__":
pool=Pool(5)
tasklist=["吃饭","睡觉","打游戏","听音乐","学习python","工作","写脚本","坐公交"]
for tasksub in tasklist:
pool.apply(task,args=(tasksub,)) # **注意这里的方法变化**
pool.close() #添加任务结束
pool.join() #当任务结束后让列表里的任务添加进池子,目的:阻塞主进程,进程池与主进程同生共死
print("task over!!!")开始做任务啦! 吃饭
完成任务吃饭,执行时间:0.4302506446838379,任务号:6240
开始做任务啦! 睡觉
完成任务睡觉,执行时间:0.15832018852233887,任务号:4732
开始做任务啦! 打游戏
完成任务打游戏,执行时间:1.0747206211090088,任务号:16472
开始做任务啦! 听音乐
完成任务听音乐,执行时间:0.47855663299560547,任务号:10980
开始做任务啦! 学习python
完成任务学习python,执行时间:0.046285152435302734,任务号:9820
开始做任务啦! 工作
完成任务工作,执行时间:1.6568598747253418,任务号:6240
开始做任务啦! 写脚本
完成任务写脚本,执行时间:0.661318302154541,任务号:4732
开始做任务啦! 坐公交
完成任务坐公交,执行时间:0.8052065372467041,任务号:16472
task over!!!
Process finished with exit code 0
进程通信
在学习进程间通信前先来看看两个进程间的桥梁:队列,也就是Queue类的一些方法和特性,如图,当队列满时,再往里面加数据时,将会呈现阻塞状态,当其中一个数据传输出去,后面一个数据便会顶上
?
#进程间通信
from multiprocessing import Queue
q=Queue(5) #其中的参数是队列的最大个数
q.put("a")
q.put("b")
q.put("c")
q.put("d")
q.put("e")
print(q.qsize()) #获取队列长度
q.put("f")?
?对于Queue的一些方法:
#进程间通信
from multiprocessing import Queue
q=Queue(5) #其中的参数是队列的最大个数
q.put("a")
q.put("b")
q.put("c")
q.put("d")
q.put("e")
print(q.qsize()) #获取队列长度
if not q.full(): #q.full() 布尔类型,若满了返回True, q.empty() ,若空返回True
q.put("f",block=True,timeout=3) #block:是否阻塞,timeout超时时间
else:
print("队列已满")
print(q.get()) #获得队列里的值 ,他也有参数block,符合队列的特性,若多的q.get便会阻塞
print(q.get())
print(q.get())
print(q.get())
print(q.get())
print(q.get())
print(q.get())
print(q.get())
print(q.get())
#不阻塞的方式
#q.get_nowait()
#q.put_nowait()?
? 1.在我们的进程通信上就是利用Queue的实例化对象q通过Process的参数传入两个进程中,两个进程共用一个q。
??2.但是也可能遇到q实例对象,因为一个进程执行完毕后,实例对象使用完成而被销毁,或是主进程中的东西插入到两个进程之中,所以我们也要像进程池一样,使用join方法,将进程阻塞起来,防止其他进程插队与实例对象被销毁而无法循环进行工作
?
#进程间的通信
def download(q): #传入队列的实例对象q
images=["photo1","photo2","photo3","photo4"]
for image in images:
print("正在下载",image)
sleep(2)
q.put(image)
def getfile(q):
for i in range (q.qsize()):
#获取队列的大小,而循环工作,防止q.get阻塞,也可以设置超时时间避免
image=q.get()
print("保存成功",image)
if __name__ == '__main__':
q=Queue(5)
p1=Process(target=download,args=(q,))
p2=Process(target=getfile,args=(q,))
p1.start()
p1.join() #阻塞实例对象的销毁
p2.start()
p2.join()
print("全部完成!!000000")?
正在下载 photo1
正在下载 photo2
正在下载 photo3
正在下载 photo4
全部完成!!000000
保存成功 photo1
保存成功 photo2
保存成功 photo3
保存成功 photo4
Process finished with exit code 0