目录
Tip: 依旧是菜鸡们的期末项目作业,这次是要求组队在5天内完成一个爬虫+数据展示汇报。于是乎5个人赶鸭子上架现学现写,赶在最后一天完成了任务,不过ppt就不放出来了。本着拯救学弟学妹于水火之中的想法再次写成博文发出来。不过这次我主要是项目管理和部分爬虫编写,后面的部分可能没法解释地非常详细还请见谅。
关键词:Selenium、jupyter数据分析展示、html5、mysql数据库
github和gitee链接放在文尾,有需要的自取(记得点个星呀!)
1.项目概述
这个项目最初也是在github的爬虫项目集合中看到的,但是翻遍网上的各种教程,全是用的一份18年的公开数据集直接进行分析,跳过了数据爬取的数据,于是一番讨论之下我们决定自己爬数据自己分析。

如图所示,项目先是获取了1w左右的用户名,然后利用官方api获取了约2000局比赛的24w条数据,最后汇总出6张展示图
整体结果展示见ttzg.site(我也不知道什么时候网站我就会拿来干别的事了 且看且珍惜)
2.用户名爬取
首先在pubg.op.gg.网站爬取用户名,网站上能够通过用户名获取到其近3年的比赛记录,其中有每局队友的用户名。
所以以一个用户作为种子,将与其一起游玩的队友用户名存入一个队列,再依次出队,以该用户为种子拓展。
(不要在意入队和出队搞错了!懒得换图了233)
那么当时爬虫是我和其中一个同学负责,一学期没听课,赶忙百度爬虫,知道了Selenium与Scrapy,于是乎先是尝试抓包。
结果发现get后面跟着一长串看不懂的值,最后还是采取用Selenium模拟点击的方法。
页面一次只显示20条信息,需要通过点击more显示新的20条比赛信息,同时需要翻至页面底部以防按钮被广告挡住,点击靠css定位,用户名获取使用xpath定位。
if status:
# 拉倒页面底部 避免底部广告干扰
js = "var q=document.documentElement.scrollTop=10000"
self.browser.execute_script(js)
# 使用try..except 解决数据不够以及按钮没加载的情况 将直接跳过
try:
e1 = self.browser.find_element_by_css_selector(".total-played-game__btn.total-played-game__btn--more")
self.browser.execute_script("arguments[0].click();", e1)
sleep(1)
for j in range(20):
self.browser.find_element_by_css_selector(".matches-item__btn.matches-item__btn--members").click()
self.browser.implicitly_wait(20)
except BaseException:
status = False
else:
break
# 根据外层数据的xpath来定位用户名的位置
list = tree.xpath('//*[@id="matchDetailWrap"]/div[3]/div[1]/div/div/div[2]/ul/li')
# 总比赛用户信息
l_all = []
for i in list:
# 通过用户名的xpath不同 来进行规律性遍历
m = i.xpath('./div[1]/div[6]/div/div/ul/li')
for li in m:
try:
n1 = li.xpath('./div/a/text()')[0]
except BaseException:
n1 = None
pass
l_all.append(str(n1))
while [] in l_all:
l_all.remove([])
最后将数据整理成一条sql语句进行插入,经实际操作证明,一条一条插入极其缓慢
# 创建游标对象
cursor = self.con.cursor()
try:
# 对多条sql语句进行合并
sql = "insert ignore into userinfo values "
for i in list:
sql += '(' + "'" + str(i) + "'" + '),'
sql = sql[:-1] + ';'
cursor.execute(sql)
self.con.commit()
cursor.close()
return 0
except Exception as e:
print(e)
self.con.rollback()
return 1
3.比赛数据获取
pubg官方提供了开发者接口,可以在https://developer.pubg.com/上注册账号申请一个api进行数据获取。在默认情况下api只允许最快10个每分钟的访问请求,可以通过提交申请提高访问频率。

由于查阅官方文档后发现数据获取采取的是request-json的形式,组员不是很熟悉,最后使用的github上的一个整合库chicken-dinner进行查询
在这一个阶段需要先整理出后续分析需要的数据以便数据的整理与保存,我们根据网上其它一些教程和时间等情况,整理出下列研究问题以及所需要的数据。

PUBG对于每场比赛的数据是以事件日志的方式统一保存的,对局中每一种类型的事件会保存在一个日志里,经过查找,一场比赛的日志包含以下类型数据:

这种数据的保存方式像是一种树形结构,如果想要获取所需数据,及叶子,则需要通过到达叶子的分支才能获取,也就是说,想要获取一个数据,需要不断查找日志中的标签和属性,直到查到最后一个结点,即数据结点。
如:获取玩家本场比赛,地图名,玩家名,击杀数,助攻数,队伍排名,骑行距离,步行距离,造成伤害等信息
# 获取比赛玩家花名册
rosters = match.rosters
for roster in rosters:
roster_participants = roster.participants
team_number = len(roster_participants)
for participants in roster_participants:
player_details[participants.name] = {}
player_details[participants.name]["team_people"] = team_number
player_details[participants.name]["kills"] = participants.stats["kills"]
player_details[participants.name]["assists"] = participants.stats["assists"]
player_details[participants.name]["ride_distance"] = participants.stats["ride_distance"]
以上代码中,先获取本局游戏所有玩家的花名册,花名册的元素为玩家的实例,并通过其属性获取所需信息。
其余信息的整合过程不做展示,可以自行查看。
最后生成形如这样的数据表
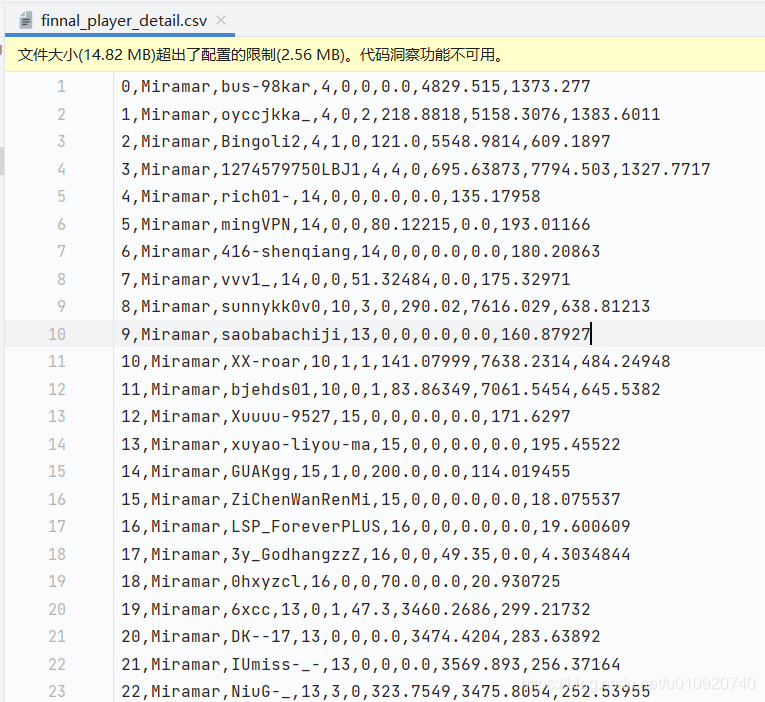
这里需要额外注意的是,当数据量超过5w时,组合成一条sql语句会超过大小,但是一条一条发速度极其缓慢,亲测10几分钟也就2k条,最后是以5w为界将数据存入的数据库
4. 数据分析和整理展示
1,获取表格
首先得到一个由爬虫技术而创建的csv表格。

利用jupyter的可实时编辑效果对数据进行分析再发展。
导入表格
agg2=pd.read_csv('/html/death_player_detail.csv',encoding='ISO-8859-1')

2,数据分析
在导入表格后,对数据进行处理,并且导出处理后的数据
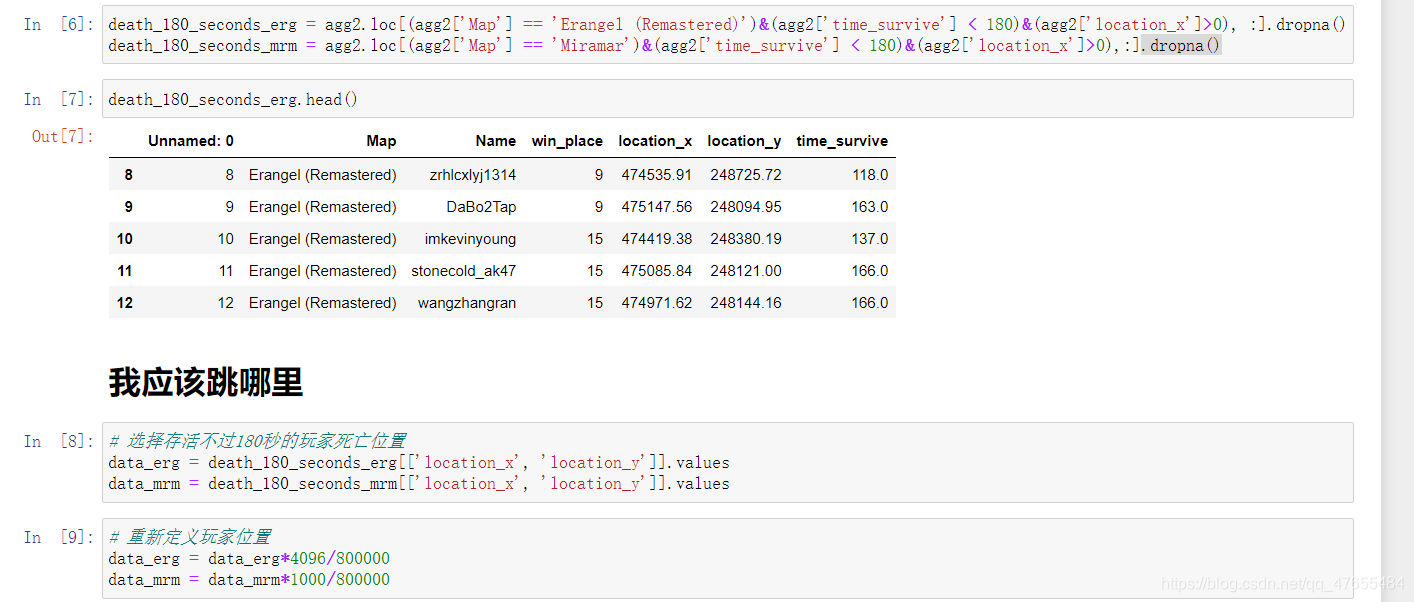
death_180_seconds_erg = agg2.loc[(agg2['Map'] == 'Erangel (Remastered)')&(agg2['time_survive'] < 180)&(agg2['location_x']>0), :].dropna()
death_180_seconds_mrm = agg2.loc[(agg2['Map'] == 'Miramar')&(agg2['time_survive'] < 180)&(agg['location_x']>0),:].dropna()
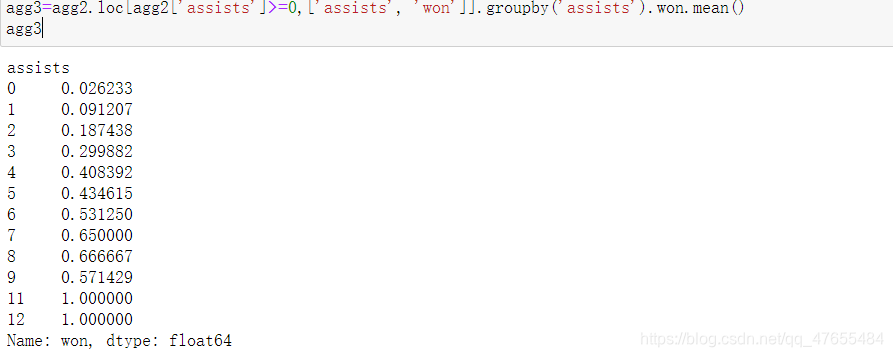
agg2.loc[agg2['assists']>=0,['assists', 'won']].groupby('assists').won.mean().plot.bar(figsize=(15,6), rot=0)
plt.xlabel('助攻次数', fontsize=14)
plt.ylabel("吃鸡概率", fontsize=14)
plt.title('助攻次数与吃鸡概率的关系', fontsize=14)
agg3=agg2.loc[agg2['assists']>=0,['assists', 'won']].groupby('assists').won.mean()
agg3
3,利用matplotlib,seaborn等函数对将处理后的数据进行可视化。

gg2.loc[agg2['kills'] < 40, ['kills', 'won']].groupby('kills').won.mean().plot.bar(figsize=(15,6), rot=0)
plt.xlabel('击杀人数', fontsize=14)
plt.ylabel("吃鸡概率", fontsize=14)
plt.title('击杀人数与吃鸡概率的关系', fontsize=14)
4,将导出的数据结果带入带Echarts中,放入HTML中

<div id="assists">
<script type="text/javascript">
var chartDom = document.getElementById('assists');
var myChart = echarts.init(chartDom);
var option;
option = {
title:{
text:'助攻数据和吃鸡关系',
left:'center'
},
xAxis: {
type: 'category',
data: ['0', '1', '2', '3', '4', '5', '6','7','8','9','11','12']
},
yAxis: {
type: 'value'
},
series: [{
data: [0.26233, 0.091207, 0.187438, 0.299882, 0.408392, 0.434615,0.531250,0.650000,0.666667,0.571429,1.000000,1.000000],
type: 'line',
smooth: true
}]
};
option && myChart.setOption(option);
</script>
</div>
5, 网页展示
本来我自己有一个阿里云的轻型服务器,结果实在受不了备案这种bug,最后买的国外的vps,没想到是centos的。最后是用宝塔系统一键部署的(本来还想搞个mysql双机热备,被centos装mysql烦死了,折腾大半天没搞得成)


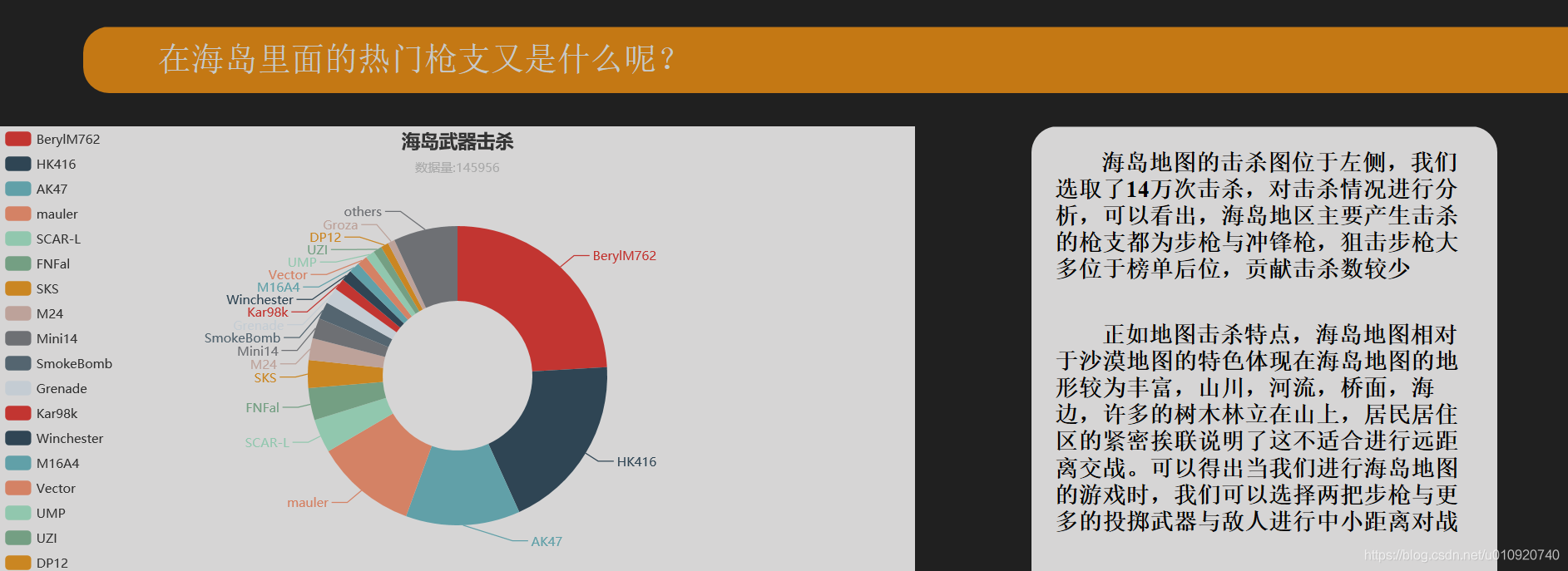
效果展示如下(缩放会有问题 实在是不会做网站)

5. 总结
那么大概就是这样吧,5个人5天搞完真挺不容易的,因为都是边学边写,还要做好代码库管理和开发日志展示ppt那些。
详细代码和技术文档开发日志等见github与gitee
初学不易,希望点个赞点个星支持一下,爱你们。