Python网络爬虫与信息提取学习笔记
Python 爬虫实训
这一篇博客里的代码都是基于一个框架
#爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态不是200,引发HTTPError异常
r.encoding=r.apparent_encoding
return r.text
except:
return"产生异常"
if __name__=="__main__":
url="http://www.baidu.com"#正常
print(getHTMLText(url))
url = "www.baidu.com"#异常
print(getHTMLText(url))
1.商品页面的爬取
爬取京东商品
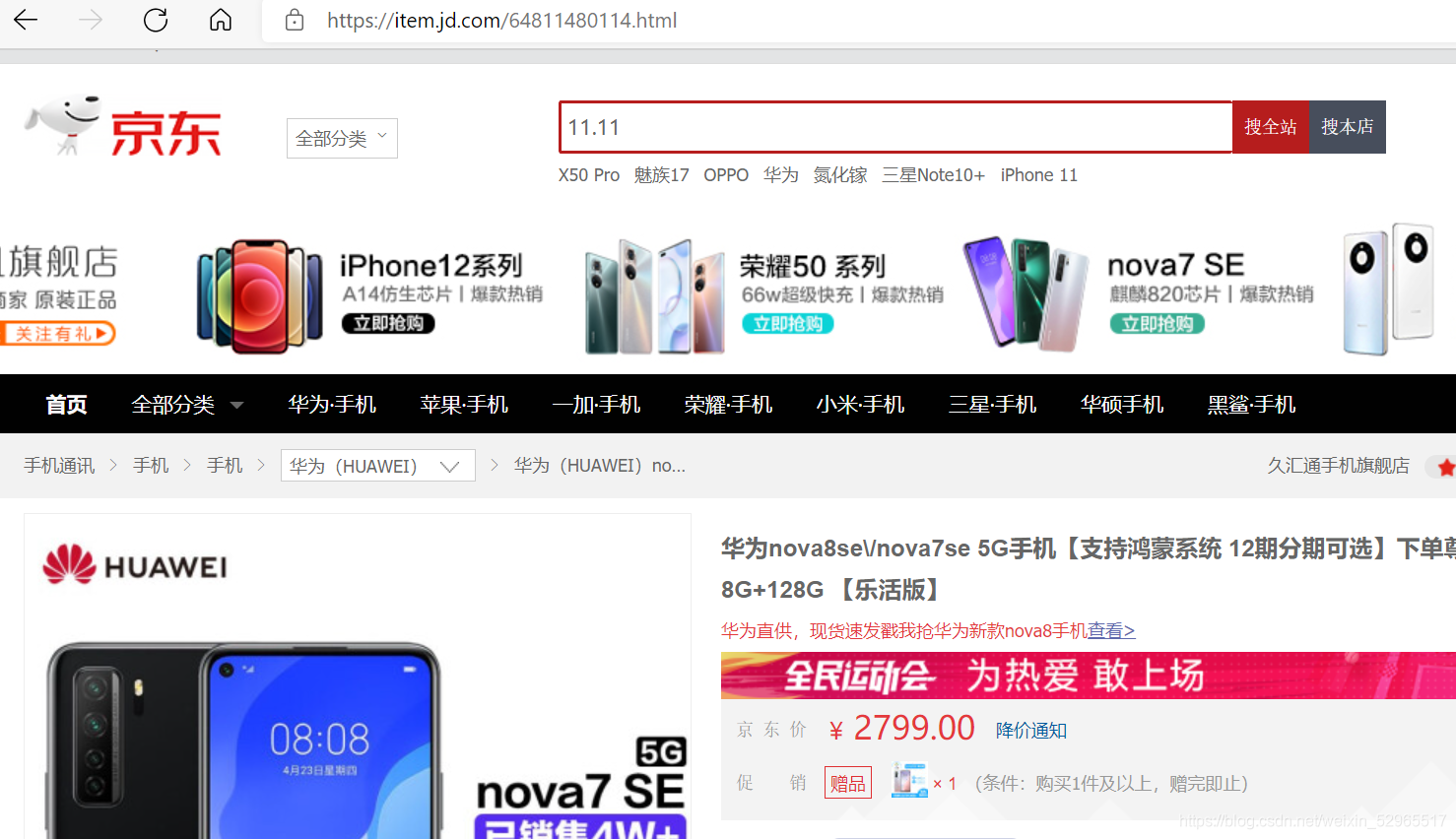
这是要爬取的商品界面,从中可以获取一些有效信息,比如:网址
爬取代码如下:
import requests
url="https://item.jd.com/64811480114.html"
try:
r = requests.get(url)
r.raise_for_status() # 如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
这个爬取是会遇到反爬取,由于我也是初学者,我还没有解决,抱歉
2. 百度/360搜索关键词提交
①ex:百度提交关键字Python
百度的关键词接口:http://biadu.com/s?wd=keyword(keyword为接口)
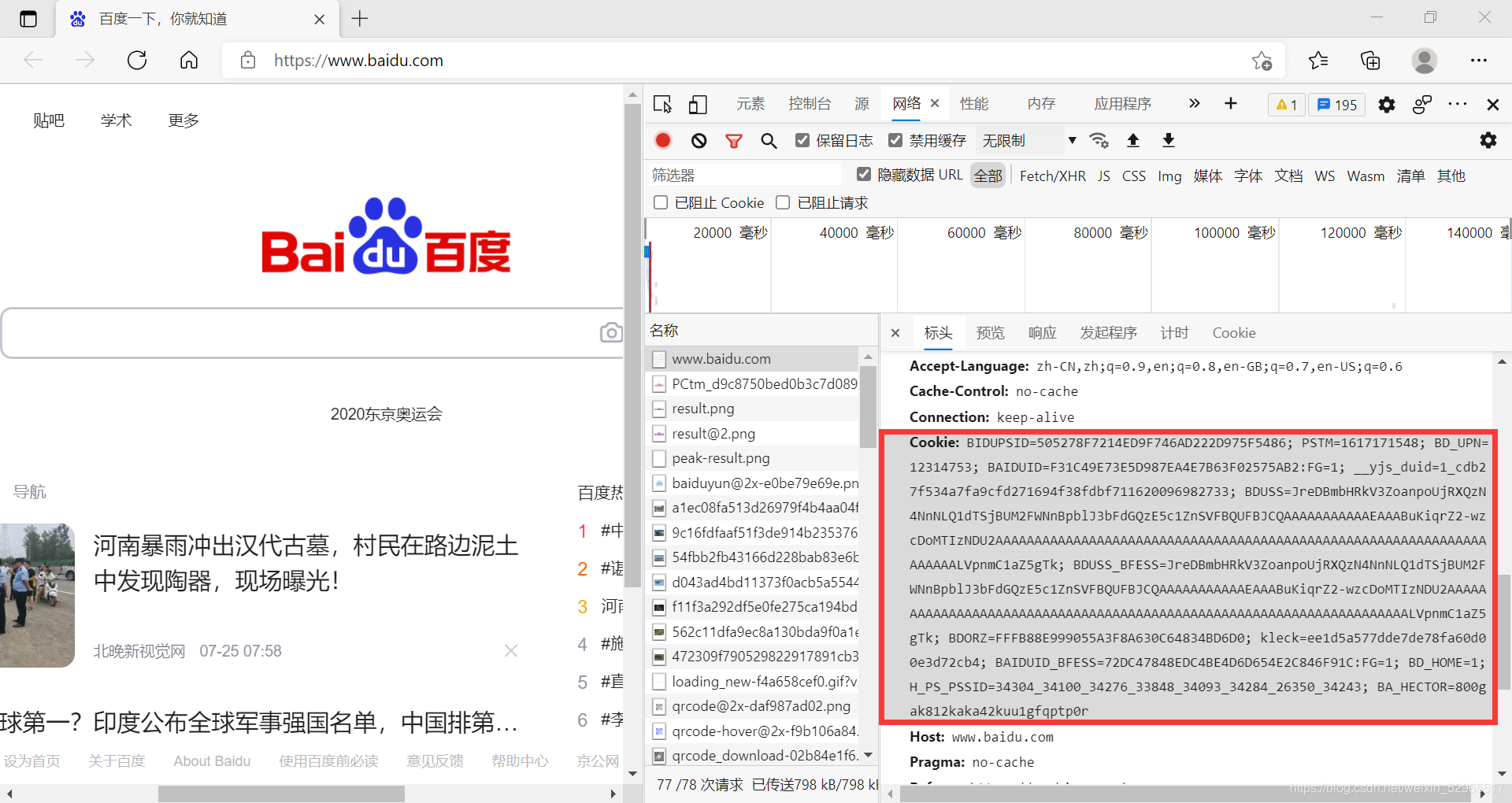
代码如下:(#号为运行结果)
import requests
keyword='Python'
try:
kv={'wd':keyword}
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55',
'Cookie': 'BIDUPSID=505278F7214ED9F746AD222D975F5486; PSTM=1617171548; BD_UPN=12314753; BAIDUID=F31C49E73E5D987EA4E7B63F02575AB2:FG=1; __yjs_duid=1_cdb27f534a7fa9cfd271694f38fdbf711620096982733; BDUSS=JreDBmbHRkV3ZoanpoUjRXQzN4NnNLQ1dTSjBUM2FWNnBpblJ3bFdGQzE5c1ZnSVFBQUFBJCQAAAAAAAAAAAEAAABuKiqrZ2-wzcDoMTIzNDU2AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALVpnmC1aZ5gTk; BDUSS_BFESS=JreDBmbHRkV3ZoanpoUjRXQzN4NnNLQ1dTSjBUM2FWNnBpblJ3bFdGQzE5c1ZnSVFBQUFBJCQAAAAAAAAAAAEAAABuKiqrZ2-wzcDoMTIzNDU2AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALVpnmC1aZ5gTk; BDRCVFR[k2U9xfnuVt6]=mk3SLVN4HKm; BD_HOME=1; delPer=0; BD_CK_SAM=1; PSINO=1; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; kleck=ee1d5a577dde7de78fa60d00e3d72cb4; H_PS_PSSID=34304_34100_34276_33848_34093_34284_26350_34243; BA_HECTOR=8gag8haha1250g0lu21gfq74o0r'}
r=requests.get("http://www.baidu.com/s",params=kv,headers=headers)
print(r.status_code)
#200
print(r.request.url)
# 'http://www.baidu.com/s?wd=Python'
print(len(r.text))
except:
print("爬取失败")
点开运行结果网址,如图:
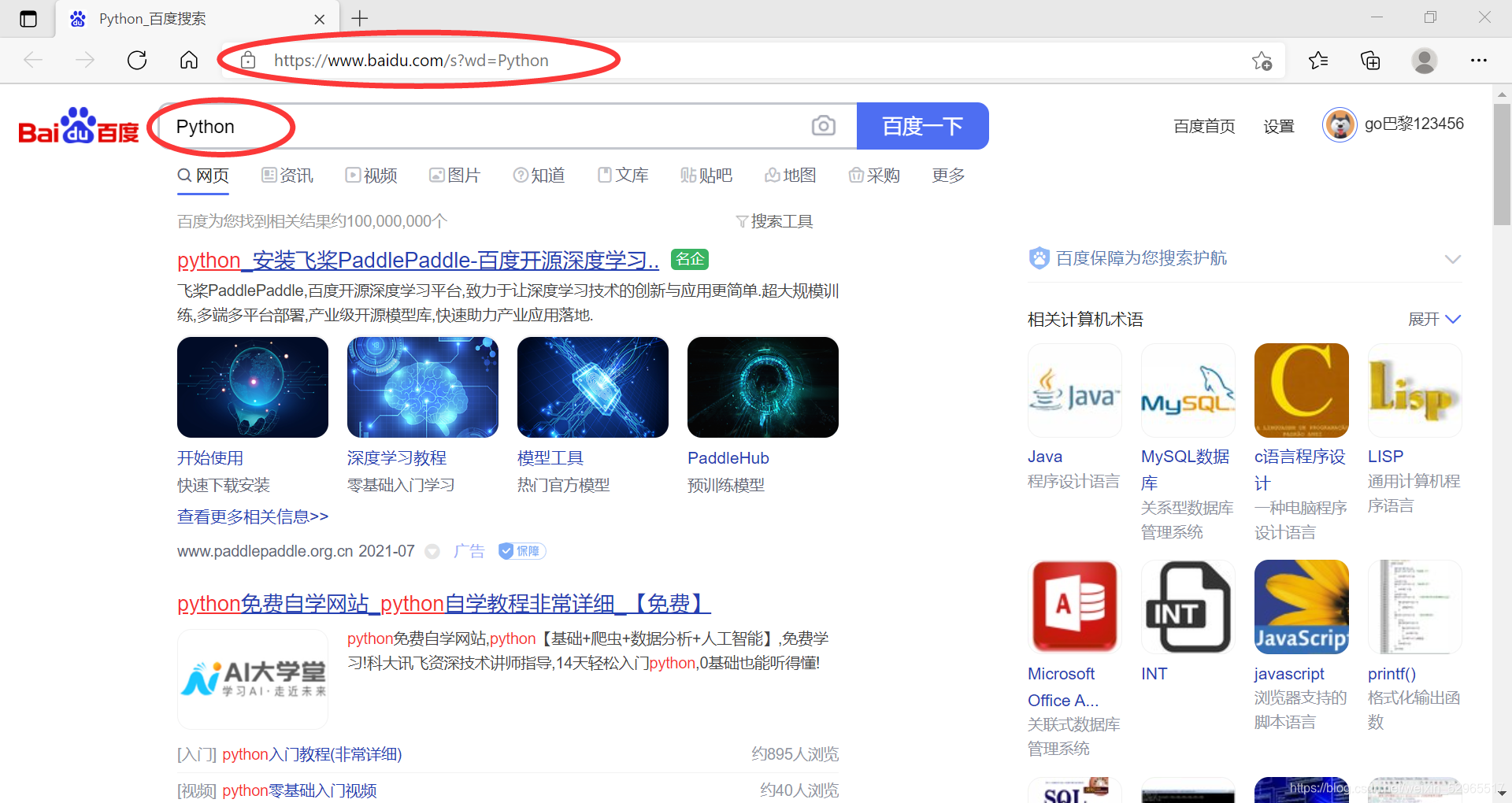
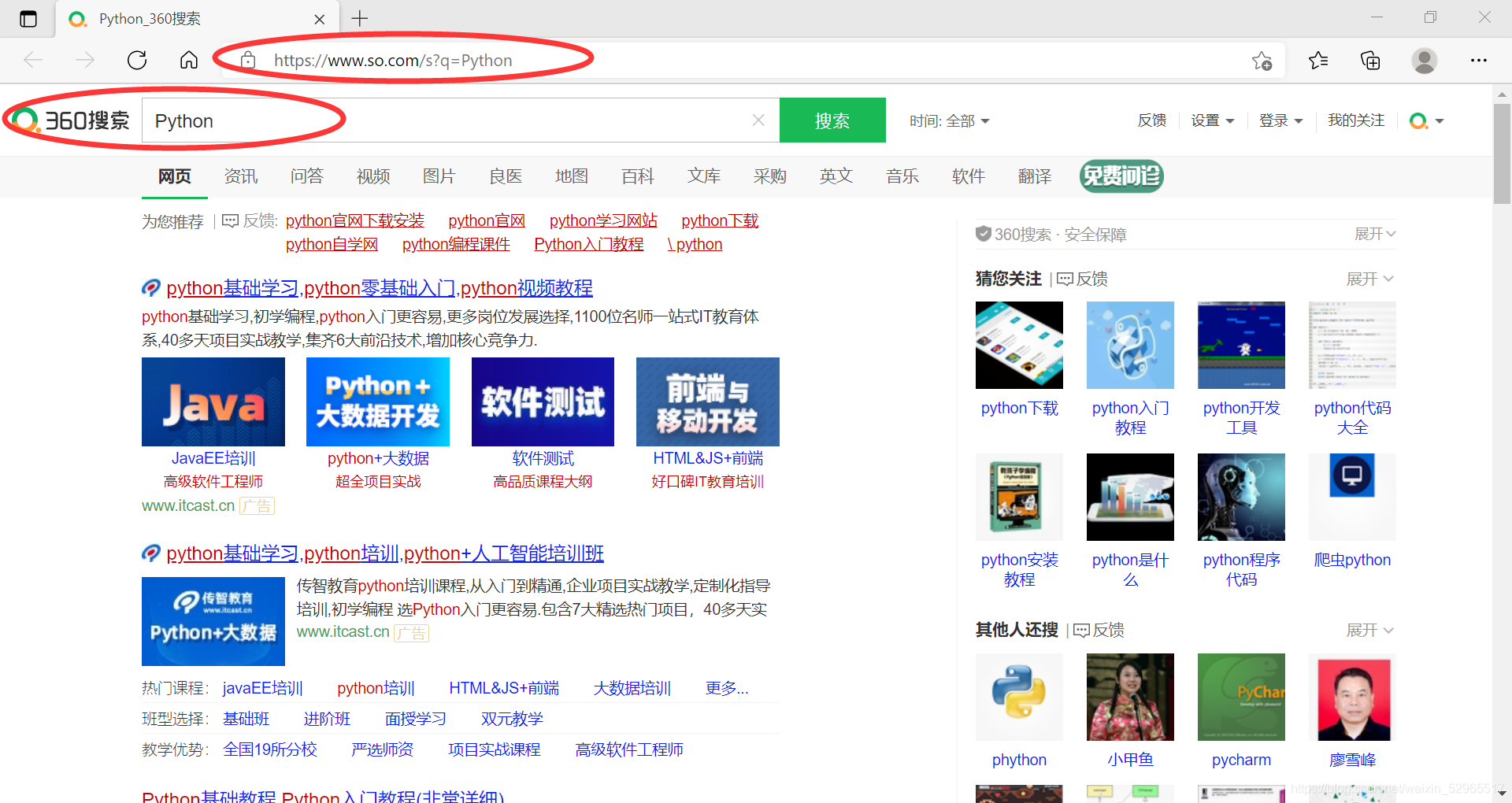
②360提交关键字
360的关键词接口:http://www.so.com/s?p=keyword(keyword为接口)
过程同①一样,代码如下:
import requests
keyword='Python'
try:
kv={'q':keyword}
r=requests.get("http://www.so.com/s",params=kv)
print(r.status_code)
#200
print(r.request.url)
# 'http://www.so.com/s?q=Python'
print(len(r.text))
except:
print("爬取失败")
代码运行结果如下图所示:
3.网络图片的存储和爬取
这种方法还可用于爬取图片、视频、动画
网络图片链接的格式:http://www.example.com/picture.jpg
例如:
这张图片的地址为https://img.zcool.cn/community/014cd256f894de32f875a944dc39ad.jpg@1280w_1l_2o_100sh.jpg
爬取代码如下:
import requests
import os
url="https://img.zcool.cn/community/014cd256f894de32f875a944dc39ad.jpg@1280w_1l_2o_100sh.jpg"
root="D://pics//"
path=root+url.split('/')[-1]#保存路径+名称
try:
if not os.path.exists(root):
os.mkdir(root)#如果根目录不存在,创建根目录
if not os.path.exists(path):#如果次项目未保存
r=requests.get(url)
with open(path,'wb') as f: #核心代码
f.write(r.content)
f.close()
print("文件保存成功")
else:#次项目已存在
print("文件已存在")
except:
print("爬取失败")
4. IP地址归属地的自动查询
import requests
text="202.204.80.112"
headers={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36", }
url="https://m.ip138.com/iplookup.asp?ip={}".format(text)
try:
r=requests.get(url,headers=headers)
r.encoding=r.apparent_encoding
print(r.text[-500:])
except:
print('爬取失败')
*print(r.text[-500:])一般只输出最后500个字符,或0~~1000或1000~2000