文件及目录操作
基本文件操作
Python中内置了 File 对象,可以执行打开文件、读取内容、写入内容、关闭文件等操作。
以下案例展示基于在 D:\Python\文件操作 文件夹中创建的相应文件。
创建和打开文件
创建和打开文件要通过 open() 函数实现。语法及参数说明如下:
file = open(filename [,mode [,buffering]])
| 参数 | 可选/必需 | 说明 |
|---|---|---|
| filename | 必需 | 要打开的文件名 |
| mode | 可选 | 打开模式 |
| buffering | 可选 | 用于指定读取文件的缓存模式。 为 0,不缓存;为 1,缓存;如果大于 1,则指定缓存区的大小。 |
| file | 必需 | open() 函数的返回值,为文件对象。在读取、写入及删除文件都必需应用该对象。 |
示例: 现在文件夹中创建 demo.py 文件,输入如下代码,并运行
file = open('test.txt','r') # 打开文件
此时文件夹下没有 status.txt 这个文件时,会报错。错误信息如下:FileNotFoundError: [Errno 2] No such file or directory: 'status.txt'
解决该问题,可以提前在文件夹下创建文件 status.txt ,让程序运行时可以找到该文件。也可以更改 open() 函数的打开模式为 w、a 等创建文件的模式:
file = open('test.txt','w') # 打开文件,如果没有文件则创建后打开
mode 参数的参数值
| 参数 | 读/写 | 二进制 | 无文件时 报错/创建 | 指针 | 覆盖/追加 | 说明 |
|---|---|---|---|---|---|---|
| r | 读 | / | 报错 | 始 | / | 以只读模式打开文件。文件的指针将会放在文件的开头 |
| rb | 读 | True | 报错 | 始 | / | 以二进制格式打开文件,并且采用只读模式。文件的指针会放在文件的开头。一般用于非文本文件,如图片、声音等 |
| r+ | 读/写 | / | 报错 | 始 | 覆盖 | 打开文件后,可以读取文件内容,也可以写入新的内容覆盖原有内容(从文件开头进行覆盖) |
| rb+ | 读/写 | True | 报错 | 始 | 覆盖 | 以二进制格式打开文件,并且采用读写模式。文件的指针将会放在文件的开头。一般用于分文本文件,如图片、声音等 |
| w | 写 | / | 创建 | 始 | 清空后写入 | 以只写模式打开文件 |
| wb | 写 | True | 创建 | 始 | 清空后写入 | 以二进制格式打开文件,并且采用只写模式。一般用于非文本文件,如图片、声音等 |
| w+ | 读/写 | / | 创建 | 始 | 清空后写入 | 打开文件后,先清空原有内容,使其变为一个空的文件,对这个空文件有读写权限 |
| wb+ | 读/写 | True | 创建 | 始 | 清空后写入 | 以二进制格式打开文件,并且采用读写模式。一般用于非文本文件,如图片、声音等 |
| a | 写 | / | 创建 | 末 | 追加 | 以追加模式打开一个文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后);否则,将创建新文件用于写入 |
| ab | 写 | True | 创建 | 末 | 追加 | 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后);否则,将创建新文件用于写入 |
| a+ | 读/写 | / | 创建 | 末 | (新建)追加 | 以读写模式打开一个文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后);否则,将创建新文件用于读写 |
| ab+ | 读/写 | True | 创建 | 末 | (新建)追加 | 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后);否则,将创建新文件用于读写 |
关闭文件
语法如下:
file.close() # 关闭文件语法,其中 file 为文件对象,改语法无参数
# 知识延伸
print(file.closed) # 用于判断文件对象是否关闭,如果关闭则返回 True;否则返回 False
在 Python 中,打开的文件操作完后并不需要立即关闭,当程序结束运行时,Python 的自动回收机制会将文件关闭。
但是在文件关闭向前,由于 Python 程序的占用,不能对文件进行其它操作。
打开文件时使用 with 语句
在前面提到,在执行 open 语句后,如果没有主动将文件关闭,则由于 Python 占用则不能对文件进行修改,所以必须要记得手动修改。
虽然 python 有回收机制,但是需要在执行完整段程序后才会关闭文件。
使用 with 方法在执行完成 open() 及 相应操作 with-body 语句时会自动关闭文件。
with expression as target:
with-body
| 参数 | 说明 |
|---|---|
| expression | 表达式,要打开文件的 open() 函数 |
| target | 变量,用于保存表达式 expression 返回的对象,方便下文引用 |
| with-body | 要执行的命令主体。 |
示例:
file = open('test.txt','w') # 打开文件,如果没有文件则创建后打开
file.write('这是一个测试')
print('直接打开文件并修改后,文件是否关闭?',file.closed)
with open('test.txt','w') as file: # 打开文件并写入
file.write('这是一个测试')
print('使用 with 语句打开文件并修改后,文件是否关闭?',file.closed)
写入文件内容
使用文件对象的 .write() 方法向文件中写入内容,语法如下:
file.wtite(sting)
示例
print('\n','='*10,' 文件写入内容 ','='*10)
file = open('test.txt','w',encoding = 'utf-8')
file.write('这是一个测试文件,现在正在尝试向文件中写入内容')
file.close()
注意: 以上代码,如果没有语句 file.close() ,则执行完毕代码,打开文件 test.txt 会发现文件为空。这是因为,如果文件没有关闭,则修改的内容存放在系统缓存区中而非文件中,其不会自动保存到文件中。故,在修改完文件时,需要关闭文件,为避免遗忘,推荐使用 with 语句。
此外,可以使用 .flush() 可以实现不关闭文件而直接将修改内容保存到文件中,示例如下:
print('\n','='*10,' 文件写入内容 ','='*10)
file = open('test.txt','w',encoding = 'utf-8') # 注意此处,可以写入编码方式
file.write('这是一个测试文件,现在正在尝试向文件中写入内容')
file.flush()
补充,向文件中写入列表:
print('\n','='*10,' 文件写入内容 ','='*10)
list = ['刘备','关羽','张飞']
with open('test.txt','w') as file:
file.writelines(list) # 向文件写入列表
with open('test.txt','r') as file:
print(file.read()) # 读取列表并输出
# 执行语句后,输出内容为 :
# 刘备关羽张飞
执行以上语句,可以看到,将列表写入文件后,并无任何分隔符对列表进行分割。如果需要分割,方法如下:
print('\n','='*10,' 文件写入内容 ','='*10)
list = ['刘备','关羽','张飞']
with open('test.txt','w') as file:
file.writelines([line + ' ' for line in list]) # 使用匿名函数,重构列表结构
with open('test.txt','r') as file:
print(file.read()) # 读取列表并输出
# 执行语句后,输出内容为 :
# 刘备 关羽 张飞
读取文件
基本语法:
file.read([size])
1. 读取指定字符,可以使用文件对象的 .read() 方法,基本语法:
file.read([size])
size 可选参数,用于指定要读取的字符个数;如果不指定,默认读取全部字符
read() 方法使用时需要注意,打开文件时,指定的打开模式只能为r ,r+
print('\n','='*10,' 文件写入内容 ','='*10)
list = ['刘备','关羽','张飞']
with open('test.txt','w') as file:
file.writelines([line + '\n' for line in list]) # 使用匿名函数,重构列表结构
with open('test.txt','r') as file:
print(file.read()) # 读取列表并输出
print('\n','='*10,' 读取 指定字符 - 前4个 ','='*10)
with open('test.txt','r') as file:
string = file.read(4) # 读取前4个字符。
print(string)
输出结果如下:
========== 文件写入内容 ==========
刘备
关羽
张飞
========== 读取 指定字符 - 前4个 ==========
刘备
关
可以看到,换行符也计算为一个字符。那么我们如何读取到 关羽 两个字符呢?
首先要了解,read(size) 方法读取的是指针所在位置之后的字符数,而文件在指定的打开模式为 r 时,指针是在文件起始位置的,前面的代码读取了前4个字符。
现在读取 关羽,需要先使用 file.seek() 方法,将光标移动到 关羽 之前,然后读取之后的两个字符。
print('\n','='*10,' 文件写入内容 ','='*10)
list = ['刘备','关羽','张飞']
with open('test.txt','w') as file:
file.writelines([line + '\n' for line in list]) # 使用匿名函数,重构列表结构
with open('test.txt','r') as file:
print(file.read()) # 读取列表并输出
print('\n','='*10,' 读取 指定字符 - 前4个 ','='*10)
with open('test.txt','r') as file:
file.seek(7) # 移动光标,注意 .seek() 方法的字符计算规则
string = file.read(4) # 读取2个字符。
print(string)
在使用 file.seek() 方法时,需要注意该方法的字符数计算方式与 file.read() 的差异
file.read(),汉字、字母、数字等均占一个字符file.seek(),字母、数字占一个字符;汉字根据编码方式,GBK 占2个字符,utf-8 占3个字符
2. 读取一行,使用文件对象的 file.readline() 方法
该方法没有参数,打开方式同样限定为 r,r+
对于一些较大的文件,一次性读取全部内容到内存,可能文件较大会影响运行,所以通常采取逐行(以换行符为标识)读取的方式。方法如下:
print('\n','='*10,' 读取多行 ','='*10)
with open('test.txt','r') as file:
number = 0 # 记录行号
while True:
number += 1
line = file.readline() # 读取一行,注意:此处的行是以换行符为标识的
if line == "" :
break # 跳出循环
print(number,line,end='\n')
print('\n', '='*29,'over','='*29)
3. 读取全部行,使用文件对象的 file.readlines() 方法
- 该方法没有参数,打开方式同样限定为
r,r+ - 该方法的返回值是一个列表,文件中的每一行为分别为列表的一个项
print('\n','='*10,' 读取多行 ','='*10)
with open('test.txt','r') as file:
string = file.readlines() # 读取全部行,会以列表形式输出
print(string)
for string_ in string: # 利用for循环,从列表中实现逐行输出
print(string_)
目录操作
os 和 os.path 模块
python中针对目录(文件夹)操作,提供了自带的 os 和 os.path 模块,以下是相关的函数
以下案例展示基于在 D:\Python\目录操作 文件夹中创建的相应文件。
os模块提供的与目录相关的函数
| 函数 | 说明 |
|---|---|
| getcwd() | 返回当前的工作目录 |
| listdir(path) | 返回指定路径下的文件和目录信息 |
| mkdir(path [,mode]) | 创建目录 |
| makedirs(path1/path2… [,mode]) | 创建多级目录 |
| rmdir(path) | 删除目录 |
| removerdirs(path1/path2… ) | 删除多级目录 |
| chdir(path) | 把 path 设置为当前工作目录 |
| walk(top [,topdown [,onerror]]) | 遍历目录树,该方法返回一个元组,包括所有路径名、所有目录列表和文件列表3个元素 |
os.path模块提供的与目录相关的函数
| 函数 | 说明 |
|---|---|
| abspath(path) | 获取文件或目录的决定路径 |
| exists(apth) | 判断目录或者文件是否存在,如果存在返回 True,否则返回 False |
| join(path,name) | 将目录与目录或者文件名拼劲起来 |
| splitext() | 分离文件名和扩展名 |
| basename(path) | 从一个目录中提取文件名 |
| dirname(path) | 从一个路径中提取文件路径,不包括文件名 |
| isdir(path) | 用于判断是否为路径 |
路径
路径分为相对路径和绝对路径,相对路径的参照路径称为当前路径。
1. 相对路径 os.getcwd()
import os # 导入 os 模块
print('当前文件目录:',os.getcwd()) # 获取当前目录。
with open('test.txt') as file: # 通过相对路径打开当前路径下的文件
pass
以上代码打开了当前代码文件所在相同文件夹地址下的 test.txt 文件。以下代码学习打开在当前路径的子目录下的 test_upper.txt 文件,应当注意以下代码中路径 分隔符 的写法
import os # 导入 os 模块
print('当前文件目录:',os.getcwd()) # 获取当前目录。
with open('子目录/test_down.txt') as file: # 通过相对路径打开子目录下的文件
# with open('子目录\\test_down.txt') as file: # 注意路径的分隔符的写法,以下两种形式也均可以
# with open(r'子目录\test_down.txt') as file:
print('已经打开:',file.read())
2. 绝对路径
可以通过 abspath() 函数获取文件的绝对路径,语法如下
os.path.abspath(path)
path 参数通常是一个 相对路径,示例如下:
import os # 导入 os 模块
print('当前文件的绝对路径:', os.path.abspath(os.getcwd())) # 获取绝对路径
# 代码输出内容:当前文件的绝对路径: D:\Python\目录操作
3. 拼接路径
可以通过 join() 函数,语法如下:
os.path.join(path1 [,path2 [,...]])
- 拼接时是按照参数列表中所列路径顺序一次排列的。
join()函数只负责拼接路径,不负责判断路径是否正确存在,需要使用其它函数进行判断,具体后文介绍。
操作实例:
import os # 导入 os 模块
print('第一个:',os.path.join(r'D:\Pathon',r'目录操作\子目录')) # 有绝对路径,拼接出来的是绝对路径
print('第二个:',os.path.join(r'Pathon',r'目录操作\子目录')) # 没有绝对路径,拼接出来的是相对路径
print('第三个:',os.path.join(r'D:\Pathon',r'C:\Python',r'目录操作\子目录')) # 有绝对路径,拼接出来的是绝对路径
# 输入结果:
# 第一个: D:\Pathon\目录操作\子目录
# 第二个: Pathon\目录操作\子目录
# 第三个: C:\Python\目录操作\子目录
判断目录是否存在
使用 exists() 函数,语法如下:
os.path.exists(path)
- 其返回值为 True 或者 False,分别表示路径存在、不存在
- 路径不区分大小写
- 相对路径的判断,是以当前目录为参照,对比所列相对路径是否为当前路径的子路径。
实例如下:
import os # 导入 os 模块
path1 = os.path.join(r'D:\PYTHON',r'目录操作\子目录') # 有绝对路径,拼接出来的是绝对路径
print('\n第一个路径为:',path1,'\n以上路径是否存在?', os.path.exists(path1))
path2 = os.path.join(r'Python',r'目录操作\子目录') # 没有绝对路径,拼接出来的是相对路径
print('\n第二个路径为:',path2,'\n以上路径是否存在?', os.path.exists(path2))
path2 = os.path.join(r'子目录',r'test_down.txt') # 没有绝对路径,拼接出来的是相对路径
print('\n第三个路径为:',path2,'\n以上路径是否存在?', os.path.exists(path2))
输出结果:
第一个路径为: D:\PYTHON\目录操作\子目录
以上路径是否存在? True
第二个路径为: Python\目录操作\子目录
以上路径是否存在? False
第三个路径为: 子目录\test_down.txt
以上路径是否存在? True
创建目录
使用 mkdir() 函数
os.mkdir(path [,mode=0o777])
| 参数 | 说明 |
|---|---|
| path | 要创建的文件路径 |
| mode | 指定数值模式,默认值为 八进制的777(即 0o777 ),在 Linex 系统下无效。通常不对其修改,也可以省略 |
- 如果要创建的路径已经存在,执行创建命令时将抛出异常
- 通常在创建文件目录前,会使用
os.path.exists(path)函数判断路径是否存在 mkdir()函数不能创建多级目录
实例操作如下:
import os
os.mkdir(r'D:\python\目录操作\好好学习')
################## 创建已存在的目录 ##########################
os.mkdir(r'D:\python\目录操作\好好学习')
# 保存信息:
# FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: 'D:\\python\\目录操作\\好好学习'import
# 可以使用如下方法,创建前先判断指定的目录是否存在
path = r'D:\python\目录操作\好好学习'
if not os.path.exists(path): # 判断目录是否存在
os.mkdir(path)
else:
print('该目录已经存在。')
################### 创建多级目录 ##############################
path = r'D:\python\目录操作\好好学习\天天\向上' # 指定多级目录
if not os.path.exists(path): # 判断目录是否存在
os.mkdir(path)
else:
print('该目录已经存在。')
# 报错信息:
# FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'D:\\python\\目录操作\\好好学习\\天天\\向上'
mkdir() 函数 + 递归方法创建多级目录
import os
def mkdir(path): # 创建一个递归函数,用于创建目录
if not os.path.isdir(path): # 判断是否是路径
mkdir(os.path.split(path)[0]) # 不存在则递归调用函数本身
else:
return # 存在则直接返回
os.mkdir(path) # 创建目录
path = r'D:\python\目录操作\好好学习\天天\向上' #指定多级目录
mkdir(path) # 调用函数
使用 makedirs() 创建多级目录
os.makedirs(name [,mode=0o777])
参数与 mkdir() 函数一样,不做赘述。实例如下:
import os
path = r'D:\python\目录操作\好好学习\天天\向上' #指定多级目录
if not os.path.exists(path): # 如果没有目录
os.makedirs(path)
else:
print('文件目录已经存在。')
删除目录
使用 os 模块的 rmdir() 函数,语法如下:
os.rmdir(path)
- 路径
path可以通过相对路径来指定,也可以通过绝对路径来指定 - 当删除的目录不存在时,会抛出异常。所以删除之前也需要判断目录是否存在
- 不能当删除非空文件夹
实例如下:
############ 删除目录 #########################
import os
path = r'D:\python\目录操作\好好学习\天天\向上'
os.rmdir(path) # 删除目录
########### 删除不存在的目录时报错 ############
os.rmdir(path) # 再次删除目录,查看异常
# 异常信息为
# FileNotFoundError: [WinError 2] 系统找不到指定的文件。: 'D:\\python\\目录操作\\好好学习\\天天\\向上'
############ 增加删除前的判断目录是否存在 ############
if os.path.exists(path): # 如果目录存在,删除
os.rmdir(path)
print('目录删除成功。')
else:
print('目录不存在。')
########## 删除多级目录时报错 ################
path = r'D:\python\目录操作\好好学习'
os.rmdir(path) # 删除多级目录
# 异常信息:
# OSError: [WinError 145] 目录不是空的。: 'D:\\python\\目录操作\\好好学习'
删除非空目录
os模块无法完成,需要使用shutil模块的.rmtree()函数shutil.rmtree(path)在删除不存在的目录时,同样会报错(不演示了)
实例如下:
import os,shutil
path = r'D:\python\目录操作\好好学习'
if os.path.exists(path): # 如果目录存在,删除、
shutil.rmtree(path)
print('目录树删除成功')
else:
print('目录不存在')
遍历目录
使用 os 模块的 walk() 函数实现,语法如下:
os.walk(top [,topdown] [, onerror] [, followlinks])
| 参数 | 可选/必需 | 说明 |
|---|---|---|
| top | 必需 | 指定要遍历内容的根目录 |
| topdown | 可选 | 指定遍历的顺序 默认值为 True,表示上而下(根目录 > 子目录)遍历;如果设置为 False,则反之 |
| onerror | 可选 | 指定错误处理方式,默认或略 |
| followlinks | 可选 | 如果为 True,表示指定在支持的系统上,访问由符号连接(软连接,相当于Win系统上的快捷方式)指向的目录,通常不指定该参数 |
函数返回值为一个元组生成器对象,其中会生成包含3个元素的元组 (dirpath,dirnames,filenames)
| 项目 | 类型 | 说明 |
|---|---|---|
| dirpath | 字符串 | 当前遍历的路径 |
| dirnames | 列表 | 当前路径下包含的子目录 |
| filenamses | 列表 | 当前路径下包含的文件 |
提前在本地创建了如下的文件目录:
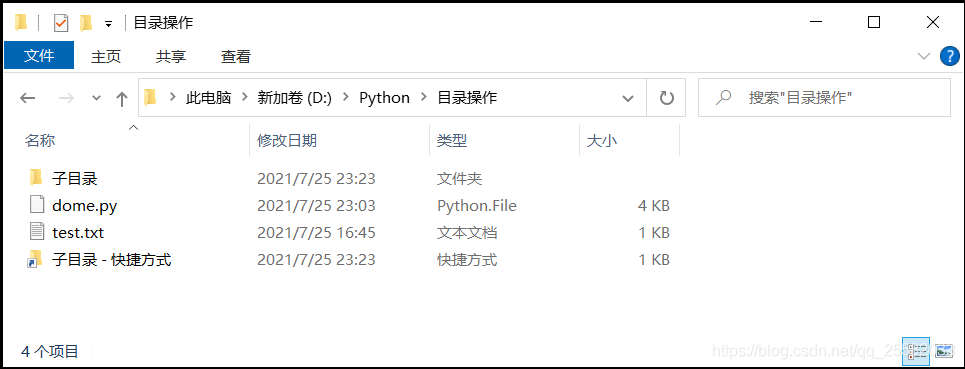
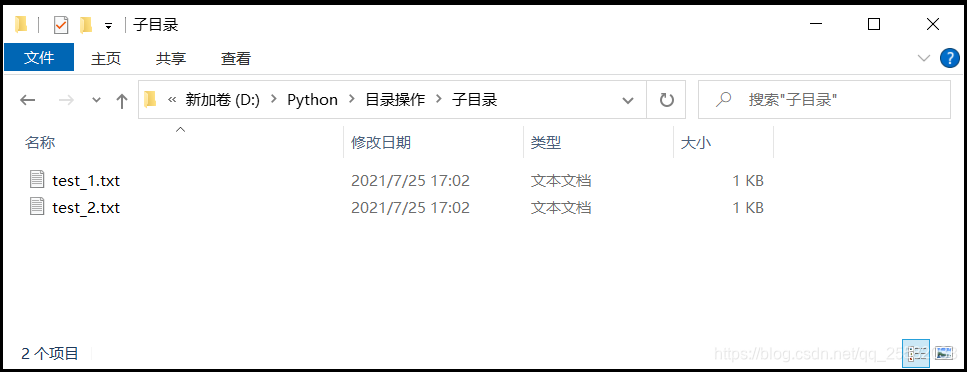
import os
path = r'D:\python\目录操作'
objPath = os.walk(path)
for p in objPath: # 输出遍历结果
print(p)
输出结果:
('D:\\python\\目录操作', ['子目录'], ['dome.py', 'test.txt', '子目录 - 快捷方式.lnk'])
('D:\\python\\目录操作\\子目录', [], ['test_1.txt', 'test_2.txt'])
可以看到,返回了两个元组,分别显示的是:
- 指定的根目录下的 地址、子目录、文件
- 指定的根目录下的子目录的 地址、子目录、文件
以下实例,输出指定目录及子目录下的所有文件的路径:
import os
path = r'D:\python\目录操作'
print(r'【%s】目录下包含的文件和目录:'%path)
for root,dirs,files in os.walk(path,topdown=True): #遍历指定目录
for name in dirs:
print(os.path.join(root,name)) # 输出遍历到的目录
for name in files:
print('\t',os.path.join(root,name)) #输出遍历的到目录
高级文件操作
删除文件
python 没有内置删除文件的函数,但在内置的 os 模块中提供了删除文件的函数 remove()。基本语法如下:
os.remove(path)
- 路径
path可以使用绝对路径和相对路径 - 删除不存在的文件时会报错,所以通常删除前先判断文件是否存在
- 只能删除文件,不能删除文件夹
实例如下:
import os
path = r'D:\Python\高级操作\子目录\test_2.txt' # 绝对路径
if os.path.exists(path): # 判断文件是否存在,如果存在则删除
os.remove(path)
else:
print('文件不存在。')
重命名文件和目录
os.rename(src,dst)
| 参数 | 说明 |
|---|---|
| src | 要重命名的目录或文件名 |
| dst | 重命名后的目录或文件名 |
- 当要重命名的路径不存在时会报错
- 要重命名的文件(夹)必需设置为
src、dst参数的最后一级名称
实例如下:
import os
########### 文件重命名 ##############
scr = r'D:\Python\高级操作\子目录\test_1.txt'
dst = r'D:\Python\高级操作\子目录\t.txt'
if os.path.exists(scr): # 判断路径是否存在
os.rename(scr,dst) # 重命名文件
else:
print('文件不存在。')
########### 目录重命名 #############
scr = r'D:\Python\高级操作\子目录'
dst = r'D:\Python\高级操作\目录'
if os.path.exists(scr): # 判断路径是否存在
os.rename(scr,dst) # 重命名文件
else:
print('目录不存在。')
获取文件的基本信息
python 中 os 模块的 star() 函数提供了获取文件基本信息的方法。基本语法如下:
object = os.stat(path)
path是要获取的文件的路径,可以是相对路径,也可以是绝对路径os.stat(path)的返回值是一个对象,提供该对象的属性可以获取文件相应的基本信息
import os
def formatTime(longtime):
'''格式化时间的函数'''
import time
return time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(longtime))
def formatByte(number):
'''格式化文件大小的函数'''
for (scale,label) in [(1024*1024*1024,'GB'),(1024*1024,'MB'),(1024,'KB')]:
if number >= scale: # 大于等于1KB
return '%.2f %s'%(number*1.0/scale,label)
elif number == 1:
return '1 字节' #
else: # <1KB
byte = '%.2f'%(number or 0)
return (byte[:-3] if byte.endswith('.00') else byte) + '字节'
fileinfo = os.stat('漩涡鸣人.jpg') # 获取文件对象
print('文件完整路径:',os.path.abspath('漩涡名人.jpg')) # 获取文件的完整路径
## 输出文件的基本信息
print('索引号',fileinfo.st_ino)
print('设备名:',fileinfo.st_dev)
print('文件大小:',formatByte(fileinfo.st_size))
print('最后一次访问使劲按:',formatTime(fileinfo.st_atime))
print('最后一次修改时间:',formatTime(fileinfo.st_mtime))
print('最后一次状态变化的时间:',formatTime(fileinfo.st_ctime))
star() 函数返回对象的常用属性
| 属性 | 说明 |
|---|---|
| st_mode | 保护模式 |
| st_ino | 索引号 |
| st_nlink | 硬链接号(被链接数目) |
| st_size | 文件大小,单位为 字节 |
| st_dev | 设备名 |
| st_uid | 用户 ID |
| st_gid | 组 ID |
| st_atime | 最后一次访问时间 |
| st_mtime | 最后一次修改时间 |
| st_ctime | 最后一次状态变化的时间(系统不同返回结果不同。例如,在 Windows 操作系统下返回的时文件创建时间 ) |