����ͨ����д��������ȡ�������ϵ���Դ
web������̽���
1.��������Ⱦ:�ڷ������DZ�ֱ�Ӱ����ݺ�HTML������һ��,ͳһ���ظ������
�ص�:��ҳ��Դ�������ܿ�������
2.�ͻ�����Ⱦ:��һ������ֻҪһ��HTMl�Ǽ�,�ڶ��������õ�����,��������չʾ. �ص�:��ҳ��Դ�����п���������(�����ڵڶ���������)
�����ڿ��������ݵ�ʱ��Ҫ��,����������
HTTP��
Э��:�������������֮��Ϊ���ܹ������Ľ��й�ͨ�����õ�һ������Э��.������Э����TCP/IP,SOAPЭ��,HTTPЭ��,SMTPЭ��ȵ�
HTTPЭ��:���ı�����Э��,������������֮������ݽ������صľ���HTTPЭ��.
HTTPЭ���һ����Ϣ��Ϊ���������(������������Ӧ)
����:
1.������->����ʽ(get/post) ����urlЭ�� Э��
2.����ͷ->��һЩ������Ҫʹ�õ�**������Ϣ**
3.
4.������->һ���һЩ�������
��Ӧ:
1.״̬��->Э�� ״̬��
2.��Ӧͷ->��һЩ�ͻ���Ҫʹ�õ�һЩ������Ϣ
3.
4.��Ӧ��->���������ص������ͻ���Ҫ�õ�����(HTML,json)��
����ͷ�������һЩ��Ҫ����
1.User-Agent:������������ݱ�ʶ(��ɶ���͵�����)
2.Referer:������(���������Ǹ�ҳ����,��������õ�)
3.cookie:�����ַ���������Ϣ(�û���½��Ϣ,������token)
��Ӧͷ�������һЩ��Ҫ����
1.cookie:�����ַ���������Ϣ(�û���½��Ϣ,������token)
2.���������Ī��������ַ���(�������Ҫ������,һ�㶼��token����,��ֹ���ֹ����ͷ���)
requests����
ʵ������
- �ѹ��������ѯ
import requests
url='https://www.sogou.com/web?query=%E9%87%91%E6%99%A8%E8%84%96%E5%AD%90%E6%9C%8914'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
res=requests.get(url=url,headers=headers).text
print(res)
2.�ٶȷ���
#�ٶȷ���url
'https://fanyi.baidu.com/?aldtype=16047#auto/zh'
#��������������������ֿͻ�����Ⱦ,����ʵ���������ݵIJ�����
import requests
url='https://fanyi.baidu.com/sug'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
chaxun=input('��������Ҫ��ѯ������')
data={
'kw':chaxun
}
#res=requests.post(url=url,headers=headers,data=data).text
#print(res) �����и����⿴������
��������Ҫ��ѯ������dog
{"errno":0,"data":[{"k":"dog","v":"n. \u72d7; \u8e69\u811a\u8d27; \u4e11\u5973\u4eba; \u5351\u9119\u5c0f\.....
�Ǹ�����
����
res=requests.post(url=url,headers=headers,data=data).json()
print(res) ֱ���������json����(��python�о����ֵ�)
{'errno': 0, 'data': [{'k': 'dog', 'v': 'n. ��; ���Ż�; ��Ů��; ����С�� v. ����; ����'}, {'k': 'DOG', 'v': 'abbr. Data Output Gate ���������'}, {'k': 'doge', 'v': 'n. �����ܶ�'}, {'k': 'dogm', 'v': 'abbr. dogmatic ������; ���ϵ�; dogmatism ��������; dogmatist'}, {'k': 'Dogo', 'v': '[����] [������ն���է��] ���; [����] [����] ����'}]}
3.�����Ӱ�������а�
ע�������������ݿ���ͨ��XHR����ɸѡ
#����ϲ�����а�url
"https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action="
#��������ǵ�һ�η��������Ӧ��url,������ȡ����
import requests
start=str((int(input('��������Ҫ���ҵ�ҳ��')))*10)
url='https://movie.douban.com/j/chart/top_list?type={}&interval_id={}\
&action=&start={}&limit={}'.format('24','100:90',start,'20')
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
res=requests.get(url=url,headers=headers)
print(res.json())
Ҳ��������д
import requests
param={
'type': '24',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '20'
}
url='https://movie.douban.com/j/chart/top_list'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
res=requests.get(url=url,headers=headers,params=param)
print(res.json())
res.close()
����ǵð���������ڹر�
���ݽ�������
1.re����
2.bs4����
3.xpath����
�����ֽ����������Ի��ʹ��
re����
�������ʽ,һ��ʹ�ñ���ʽ�ķ�ʽ���ַ�������ƥ��������
�ŵ�:�ٶȿ�,Ч�ʸ�,ȷ�Ը�
ȱ��:���������Ѷȸ�
����������ط���ֱ�������Ͼ����ѵ�
�����������ʽ




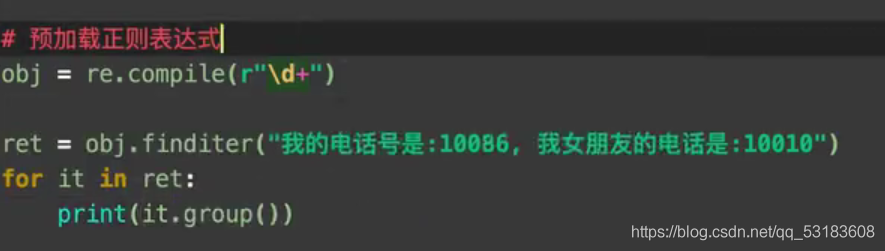
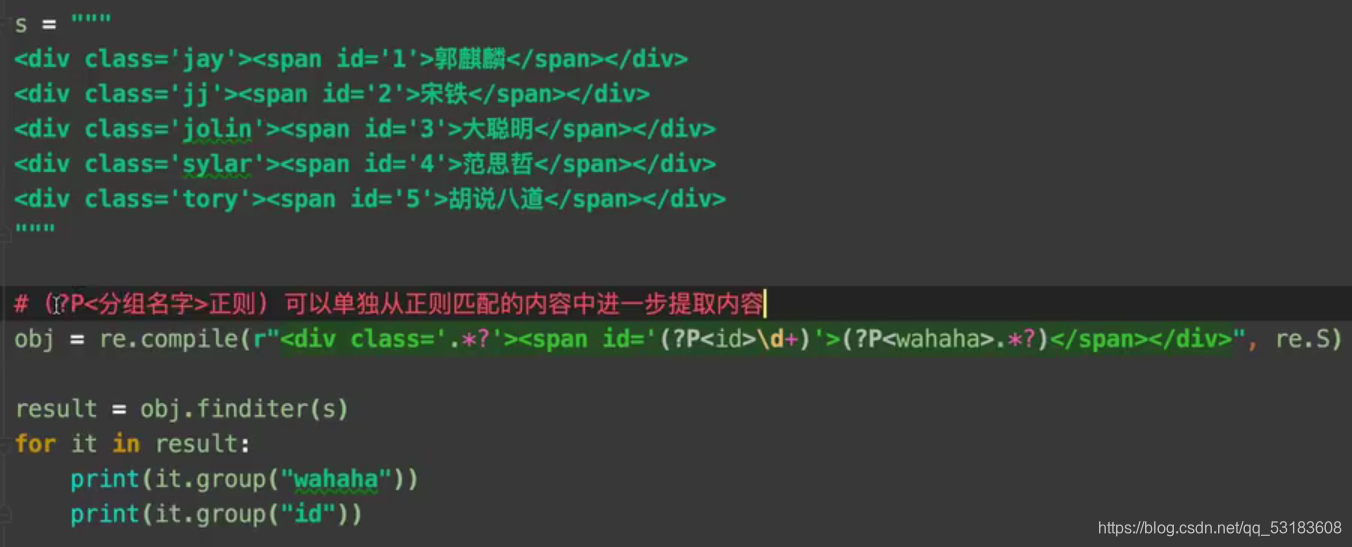
re.S����������.����ƥ�任�з���ֹ�Ͽ�
4.���ж���TOP250��Ӱ���а�
���滹������һЩxlwtģ���ʹ�÷���,�Ժ������˿��Կ�һ��
��ŵ�˼·�����������
import requests
import re
import xlwt
#1.��ȡ��ҳԴ����
url='https://movie.douban.com/top250'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
res=requests.get(url=url,headers=headers)
html=res.text
print(html)
#2.ʹ��re���н���
findname=re.compile(r' <img width="100" alt="(.*?)" src=.*?')
findneirong=re.compile(r'<p class="">(.*?)</p>',re.S)
findpjrs=re.compile(r'<div class="star">.*?<span>(.*?)</span>',re.S)
findpjfs=re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
findpy=re.compile(r'<span class="inq">(.*?)</span>')
name=findname.findall(html)
neirong=findneirong.findall(html)
pjrs=findpjrs.findall(html)
pjfs=findpjfs.findall(html)
py=findpy.findall(html)
neirong1=[]
for i in range(len(neirong)):
a=neirong[i].replace(' ','')
b=a.replace('<br>','')
c=b.replace(' ','')
neirong1.append(c)
#3.��ʼ��excel��д������
workbook = xlwt.Workbook(encoding='utf-8')
sheet=workbook.add_sheet('����TOP250',cell_overwrite_ok=True)
#ע���0 0��ʼ
tup=('��Ӱ����','�����Ա','����','��������','����')
for i in range(len(tup)):
sheet.write(0,i,tup[i])
lis=[name,neirong1,pjfs,pjrs,py]
#��ʼ��������
for i in range(20):
for j in range(5):
print(lis[j][i],end=',')
sheet.write(i,j,lis[j][i])
print()
workbook.save('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\1.����TOP250.xls')
res.close()
5.��¾�������õ�Ӱ��Ϣ
�����漰��ҳ�����ת,��html��a��ǩ������dz�����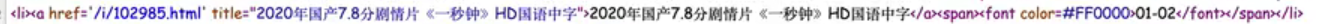
��������title�������ͣ��ʱ����ֵ����� href��Ӧ��ʱurl(������)
���ռʱ������Ҳû��ϵ,�����漰��һ��ҳ�����ת����
#��ȡ��Ӱ����
#����������ַ�������Ⱦ����ҳ
#��ҳԴ������������Ҫ��һ��
#��ô���ھͿ�ʼ��
import re
import requests
#1.��ȡ��ʼ��ҳԴ����
url='https://www.dy2018.com/'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
res=requests.get(url,headers)
res.encoding='gb2312'
html=res.text
#2.�õ���Ҫ������
findhrefs=re.compile(r'2021�ؿ���Ƭ.*?<ul>(.*?)</ul>',re.S)
findhref=re.compile(r"<li><a href='(?P<href>.*?)' title=",re.S)
finddown=re.compile(r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(.*?)">magnet',re.S)
hrefs=findhrefs.findall(html)
hrefs=findhref.findall(hrefs[0])
#ѭ���������
for href in hrefs:
download='https://www.dy2018.com/'+href
#3.��ʼ�������ҳ�����ص�ַ
#3.1���html
dlhtml=requests.get(download,headers)
dlhtml.encoding='gb2312'
dlhtml=dlhtml.text
#3.2�õ���������
down=finddown.findall(dlhtml)
print(down)
bs4����
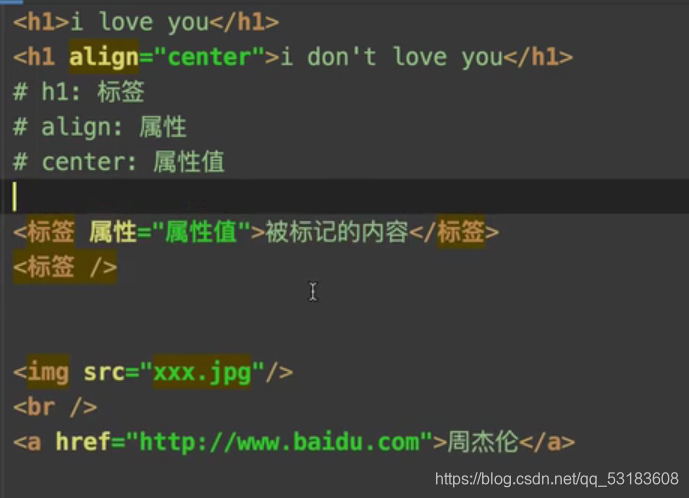
ͨ����Щ�ҵ�Ψһ����ֵ
6.�����·����г��˼�
���滹������һЩcsvģ���ʹ�÷���,�Ժ������˿��Կ�һ��
���д���ļ�ʱ������֮���пո���Լ�һ��newline=����
import csv
f=open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\�����·����г�.csv','w',newline='')
csvwriter=csv.writer(f)
csvwriter.writerow([name,di,pj,zuigao,gui,danwei,date])
f.close()
from bs4 import BeautifulSoup
import re
import requests
import csv
f=open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\�����·����г�.csv','w')
csvwriter=csv.writer(f)
#1.��������Ⱦ ��ȡ��ҳԴ����
url='http://www.xinfadi.com.cn/marketanalysis/1/list/1.shtml'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
res=requests.get(url=url,headers=headers).text
html=res
#2.��ʼ��Դ������н���
page=BeautifulSoup(html,'html.parser')
neibie=page.find('tr',class_="tr_1").text.split()
csvwriter.writerow(neibie)
#��ø��ֲ˵�����
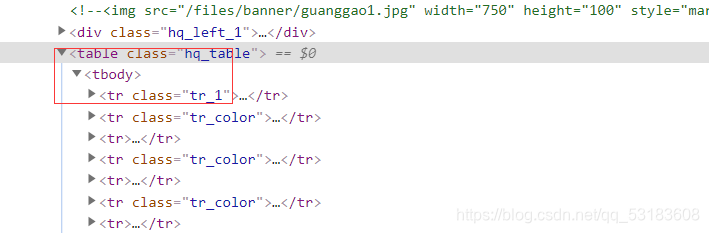
table=page.find('table',class_="hq_table")
tr=table.find_all('tr')[1::]
for i in range(len(tr)):
#��õ�ǰ��Ʒ������
tds=tr[i].find_all('td')
name=tds[0].text
di=tds[1].text
pj=tds[2].text
zuigao=tds[3].text
gui=tds[4].text
danwei=tds[5].text
date=tds[6].text
csvwriter.writerow([name,di,pj,zuigao,gui,danwei,date])
f.close()
7.ץȡ����ͼ��
ע������Ĵ���
����ͨ��getֱ�ӻ�����Զ�Ӧ��ֵ(����ֵ),��Ҫ��ñ�ǩֱ������
�����滹��һ��ϸ��:���pycharm��ʱ���ǻ����һ��������.��ô�㱣���ͼƬ��Ƶ���ǿ����ų���
�Ҽ����ļ�->��Ŀ¼���Ϊ->���ų�
ͼƬ�����������������ر���
res=requests.get(url,headers) ��ͼƬ��Ӧ�����ӷ�������
with open(�ļ���,'wb'(������д��)) as f:
f.write(res.content)
text���Ի�ö�Ӧ���ı�
��Ҫ����
#�����ҳҲ��������Ҫ�Ķ�����ҳԴ���붼�е�����
import requests
from bs4 import BeautifulSoup
#1.��ȡ��ҳԴ����
url='https://www.umei.net/bizhitupian/weimeibizhi/'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
res=requests.get(url,headers)
res.encoding="utf-8"
html=res.text
#2.������ҳԴ�������,��ȡͼƬurl
main_page=BeautifulSoup(html,'html.parser')
h2=main_page.find('div',class_="TypeList")
lis=h2.find_all('li')
for li in lis:
imgurl=li.find('img').get('src')
name=li.find('a').text
img_text=requests.get(imgurl,headers)
#3.��ʼ����ͼƬ�洢
with open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\{}.jpg'.format(name)\
,'wb') as f:
f.write(img_text.content)
f.close
break
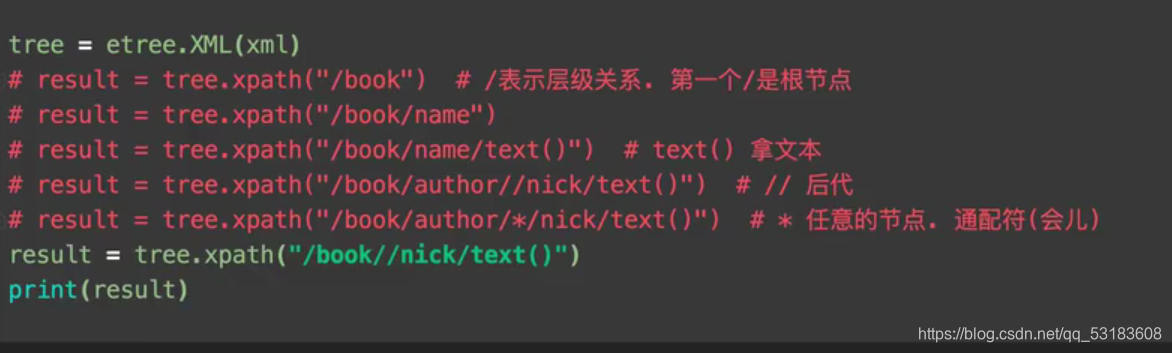
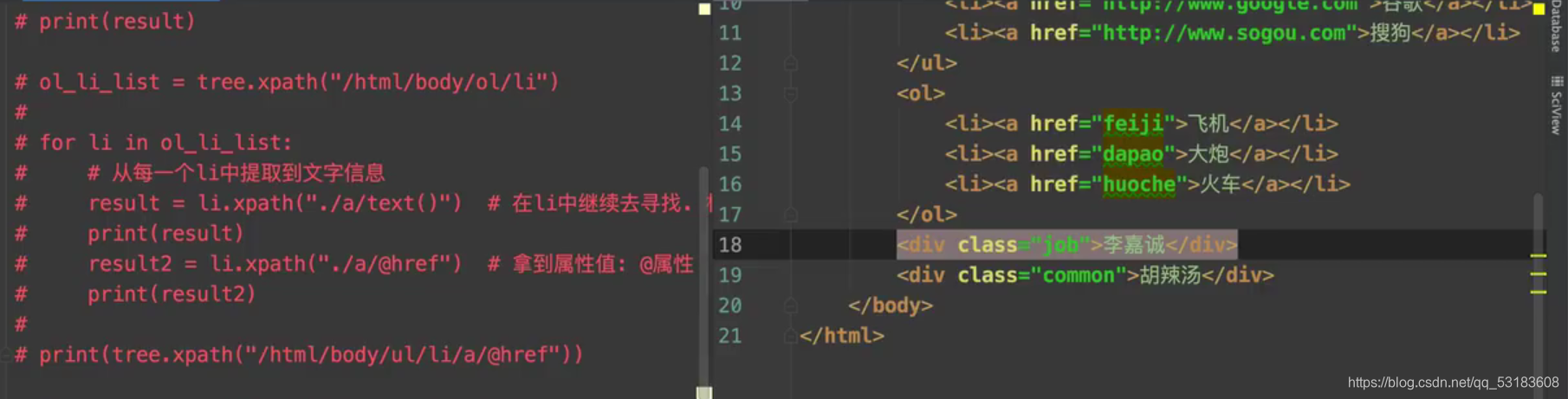
xpath����
һЩ��ϸ�ķ���
����XML�ĵ����������ݵ�һ������
html��xml���Ӽ�
����ģ��
from lxml import etree
tree=etree.HTML(html)

8.ץȡ���˽�����Ϣ
#�����ҳ����ϢҲ����������
import requests
from lxml import etree
#1.�����ҳԴ����
url='https://beijing.zbj.com/wxxcxzbjzbj/f.html?fr=zbj.sy.zyyw_2nd.lv3'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
res=requests.get(url,headers)
html=res.text
#2.���ÿһ�������
tree=etree.HTML(html)
shuju_kuais=tree.xpath('//div/div/div/div[3]//div[@class="new-service-wrap"]/div')
#2.1��ʼ����ѭ��
for shuju in shuju_kuais:
name=shuju.xpath('./div/div/a[1]//p[@class="title"]/text()')
jiage=shuju.xpath('./div/div/a[1]//span[@class="price"]/text()')
cjl=shuju.xpath('./div/div/a[1]//span[@class="amount"]/text()')
gs=shuju.xpath('./div/div/a[2]/div/p[@class="text-overflow"]/text()')
didian=shuju.xpath('./div/div/a[2]/div/div/span/text()')
print(name)
print(jiage)
print(cjl)
print(gs)
print(didian)
requests�Ľ�����
1.ģ���������½->����cookie
2.����������
3.����->��ֹIP����
ģ���������½
��ģ���½������Ҫʹ��session,�����Զ�������˵���Ļ�������һ����¼(����Я����½��cookie)
session=requests.session()
�÷���ֱ��requestsûɶ����
9.����cookie��½С˵��
���Ҳûɶ��˵�ľ���ע������ʽ,�����������ؼ��ִ���,��Ȼ���ܻᱨ��
#�����վ���㿴�����������Щ���ʱ���ǻ��е����������������
#��ʱ������Կ�һ�������ҳ��Դ����,������û�������
#��Ҳ����˵������������ʱʵ�ʷ��͵������url���������
import requests
url='https://passport.17k.com/ck/user/login'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
#1.���е�½
session=requests.session()
data={
'loginName': '19972252051',
'password': 'qhxasjcby520ccp'
}
session.post(url=url,headers=headers,data=data) #��������ڵ�½��
res=session.get(url='https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919',headers=headers)
res.encoding='utf-8'
html=res.json()
print(html)
������
10.ץȡ����Ƶ
�������漰��ѧ�ʾͶ���Щ
һ:����ȡ����url�����Ǿ���ϸ�Ķ���
��ʵ��:https://www.pearvideo.com/videoStatus.jsp?contId=1619575&mrd=0.3659542504470019
������:https://video.pearvideo.com/mp4/adshort/20210709/1626592555066-15715349_adpkg-ad_hd.mp4
��:referer��������ʼ��ʱ���д��,������.���Ǵ�ijһҳ����ת��ȥ�ľͻᱻ���Ӷ�����ȡ����
(������һ����ʵ��url�ǻ���ʾ��)
��:https://www.pearvideo.com/videoStatus.jsp?contId=1619575&mrd=0.3659542504470019
https://www.pearvideo.com/videoStatus.jsp?contId=1619575&mrd=0.4872652479179649
���Կ��������������Dz�һ����,����ʵ����ָ�����ͬһ����Ƶ,���Ը����Ҹ��˵ľ���
��ʱ��&�������ؽ�Ҫ�Ķ���
#1.������һ����Ƶ���ӷ�������
import requests
contId='https://www.pearvideo.com/video_1619575' #��url��û����
#https://www.pearvideo.com/videoStatus.jsp?contId=1619575&mrd=0.3659542504470019 ����ͨ���������ʵ��Ҫ��url
contId=contId.split('_')[1]
url='https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd=0.3659542504470019'.format(contId)
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36',
'Referer':contId
}
res=requests.get(url=url,headers=headers)
json=res.json()
#2.�Ի�õ����ݽ��н���
srcUrl=json['videoInfo']['videos']['srcUrl']
systemTime=json["systemTime"]
srcUrl=srcUrl.replace(systemTime,'cont-{}'.format(contId))
with open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\����Ƶ.mp4','wb') as f:
f.write(requests.get(srcUrl,headers).content)
#https://video.pearvideo.com/mp4/adshort/20210709/1626592555066-15715349_adpkg-ad_hd.mp4 �����ļٵ�url
#"https://video.pearvideo.com/mp4/adshort/20210709/cont-1619575-15715349_adpkg-ad_hd.mp4" ��ʵ��url
����IP
11.�ۺ���ϰ ץȡ��������������
����Ľ��ܻ�Ҫ��js��֪ʶ,���ȷ���
���߳�
from threading import Thread #�߳���
def fun():
for i in range(1000):
print('fun',i)
if __name__=='__main__':
t1=Thread(target=fun) #����������Ҫ������
t1.start() #���߳�״̬Ϊ���Կ�ʼ����״̬,�����ִ��ʱ����CPU����
for i in range(1000):
print('main',i)
���Կ�һ��������ͦ�ҵ�,ԭ���������ĵط�ֻ��һ��,����ͬʱ���
ֵ��ע��ĵط�������һ��
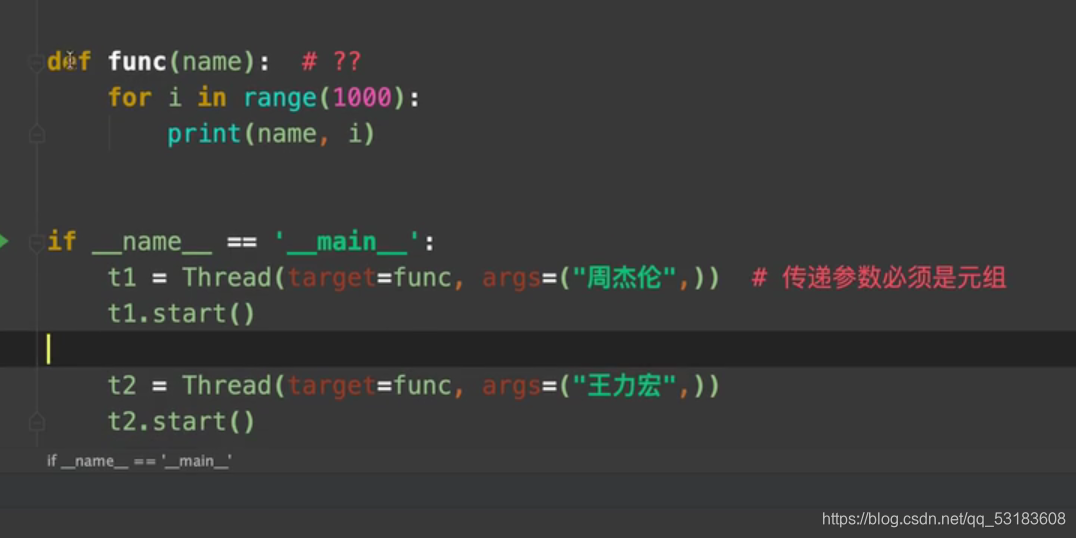
�������δ��� ֻ����Ԫ����ʽ����
ͬʱ�����еڶ���д��
class obj(Thread):
def run(self):
for i in range(1000):
print('fun',i)
if __name__=='__main__':
t=obj()
t.start()
for i in range(1000):
print('main',i)
����������ļ̳�,Ȼ������е�run������һ��,Ȼ��start֮��Ĭ��ִ�е���run����
���εĻ�����һ����ʼ������
�����
���Ĵ���Ͷ��̵߳Ĵ���dz���,����Ҫע��������DZ������Dz�һ����
from multiprocessing import Process
def fun():
for i in range(10000):
print('fun',i)
if __name__=='__main__':
t1=Process(target=fun)
t1.start()
for j in range(10000):
print('main',j)
class obj(Process):
def run(self):
for i in range(10000):
print('fun',i)
if __name__=='__main__':
t1=obj()
t1.start()
for j in range(10000):
print('main',j)
�������ֲ�����һ���������˵�һ�ȡ��1000��url,����Ҫÿһ��url����һ���̻߳��߽�����?
������߳̽�����ʱ��,�ָ���ô����?
�̳߳�:һ���Կ���һЩ�߳�,�����û�ֱ�Ӹ��̳߳��ύ����,�߳�����ĵ��Ƚ����̳߳����
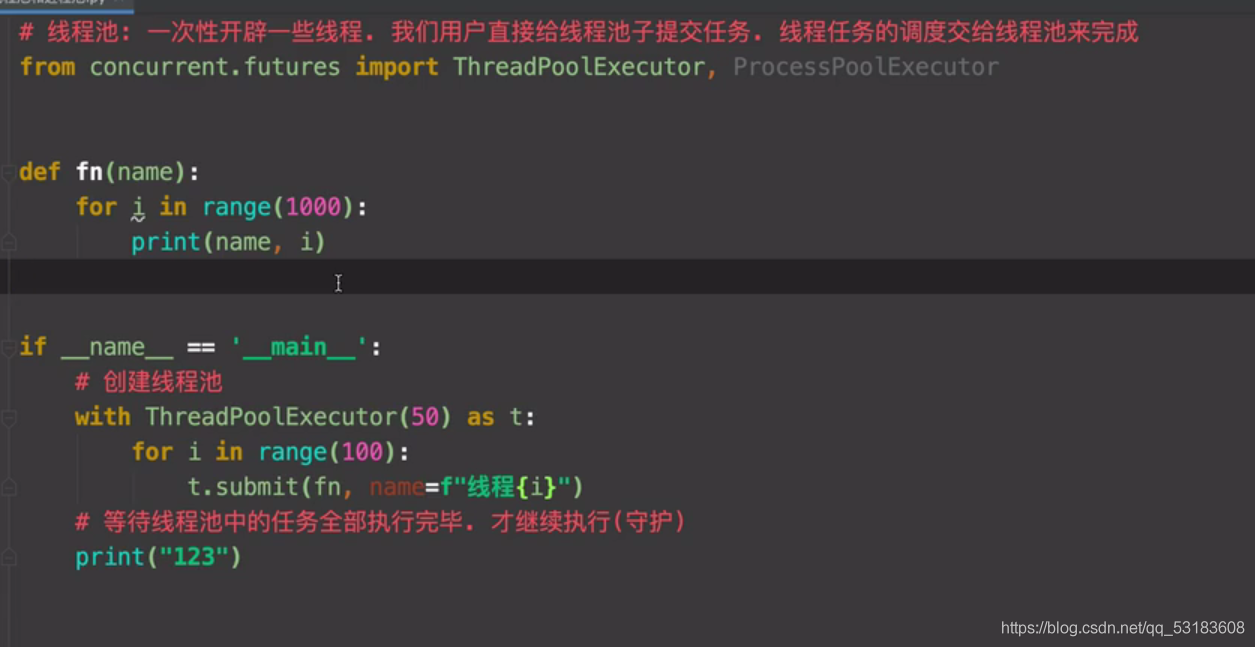
14.�̳߳���ȡ�����·����г�����
������Ҫע��һ��,�������tbody,Ҫȥ��һ����ҳԴ����������û���������(һ����û�е�,�ǹȸ�������Լ��������),дxpath����ʽ��ʱ��Ҫȥдtbody
д����һ��Ҫ��ס,�Ȱѻ����ĸ��,������һЩ����.
�����������,�Ȱ�һ����ҳ������˵���
#�Ȳ����������ѵ���ҳ�����ȡд����,�ٿ��ǻ���תҳ������
import requests
from lxml import etree
import csv
from concurrent.futures import ThreadPoolExecutor
f=open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\�����·����г�(�̳߳�).csv','w',newline='')
csvwriter=csv.writer(f)
def get_page_shuju(url):
#1.��ȡ��ҳhtml
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
res=requests.get(url=url,headers=headers)
html=res.text
#2.���н���,��ȡ��������
tree=etree.HTML(html)
trs=tree.xpath('/html/body/div[2]/div[4]/div[1]/table/tr')[1::]
for tr in trs:
#2.1��ȡ��Ҫ������
items=tr.xpath('.//text()')
items=(item.replace('\\','').replace('|','') for item in items)
#3.��ʼ����csv����
csvwriter.writerow(items)
print(url,'over')
if __name__ == '__main__':
#�����̳߳�
with ThreadPoolExecutor(100) as t:
for i in range(1, 200):
t.submit(get_page_shuju,'http://www.xinfadi.com.cn/marketanalysis/1/list/{}.shtml'.format(i))
f.close()
��
Э�̱����ϲ�ͬ�ڽ��̺��߳�,����ͨ��������ɵ�.
���̺��߳��൱�ڿ�·,����˵����50��·,������һ�����ǿ��Ե�
Э������ٿز�ͬ�ġ��ˡ�,�������ڲٿصġ��ˡ�����IO����ʱ,ת��������һ�����ˡ�,���ߵĶ���ͬһ��·
Э�̾����ʱ��Ҳ�ͣ��ѹեCPU������,ȷ���䴦�ڹ���״̬
import asyncio #����ģ��
�첽��������,���ܳ���ͬ������.time.seleep����һ��IO����,���Բ����첽ִ��.����requests���������ò���
һ��await�������,����Э�̶���ǰ��
await asyncio.sleep(�ȴ���ʱ��)
����һ��asyncio��д��
import asyncio
import time
s=time.time()
async def fun1():
print('aaaaa')
await asyncio.sleep(3)
print('aaaaa')
async def fun2():
print('bbbbb')
await asyncio.sleep(2)
print('bbbbb')
async def fun3():
print('ccccc')
await asyncio.sleep(4)
print('ccccc')
if __name__ == '__main__':
f1=fun1()
f2=fun2()
f3=fun3()
tasks=[
f1,f2,f3
]
asyncio.run(asyncio.wait(tasks))
print(time.time()-s)
��������һ��д��,��дһ��Э��������
async def fun1():
print('aaaaa')
await asyncio.sleep(3)
print('aaaaa')
async def fun2():
print('bbbbb')
await asyncio.sleep(2)
print('bbbbb')
async def fun3():
print('ccccc')
await asyncio.sleep(4)
print('ccccc')
async def main():
tasks=[
fun1(),fun2(),fun3()
]
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
print(time.time()-s)
ģ���������
#ģ��һ������Ĵ���
async def download(url):
print('����������')
await asyncio.sleep(2) #������������
print('���سɹ�')
async def main():
urls=[
'1111111111111111111',
'22222222222222222222222',
'333333333333333333333'
]
tasks=[]
for url in urls:
d=download(url) #���ﲢ����ȥ���ú���
tasks.append(d)
print(tasks)
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
��һ������,����3.8֮ǰ��python������Զ�ת����task����,����������Ҫ���Լ�ת��
����˵
tasks����б�������Ҫ�ŵ���asyncio.create_task(fun())
��Ϊrequests.get()��ͬ������,�����첽��ʹ��,������Ҫһ��������
aiohttp
import asyncio
import aiohttp
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
urls=[
'http://kr.shanghai-jiuxin.com/file/2020/0806/small5fa613a6911d1d83374fa129a030c956.jpg',
'http://kr.shanghai-jiuxin.com/file/2020/0807/small17faef411f20644e2e3e353e6315f475.jpg',
'http://kr.shanghai-jiuxin.com/file/2020/0807/small393f1cb4d5baebab6be3035cb8fa79d5.jpg'
]
async def download(url):
name=url.split('/')[-1]
async with aiohttp.ClientSession() as session:
async with session.get(url,headers=headers) as res:
print(name)
with open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\{}'.format(name)\
,'wb') as f:
f.write(await res.content.read())
print(name)
async def main():
tasks=[]
for url in urls:
tasks.append(asyncio.create_task(download(url)))
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
������д��,�ᱨ��
17.aiohttpץȡ���μ�
�о�������url�������ʱ����Ը�ֵճ�����������һ��
һ�ǿ��ܾ�������������Ƶ
���������ܸ��Ƶ�ʱ���Զ�����һ�¿��ű�Ť
��https://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%224306063500%22}��
���Ը�ֵ�ſ�һ��,%22 �� "
CTRL+f�IJ��ұ������Ѿ�������,ֱ�ӿ��Կ�����
Сϸ��ע�⿴������Ļ���,�����Ҫ�ҵ����ݷdz���һ��Ҫע��

�Ѿ�ǧ�������������������,�Ժ�Ļ�������ȥʹ���̶߳������첽,�Ҿ��ÿ��ǿ첻����
ֵ��ע�����awaitʲôʱ��д ,���������ݵĻ�ȡ, dic=await res.json()����Ҫдawait��
#�����������ݲ�û�з�����ҳԴ�������������������ҳ�����
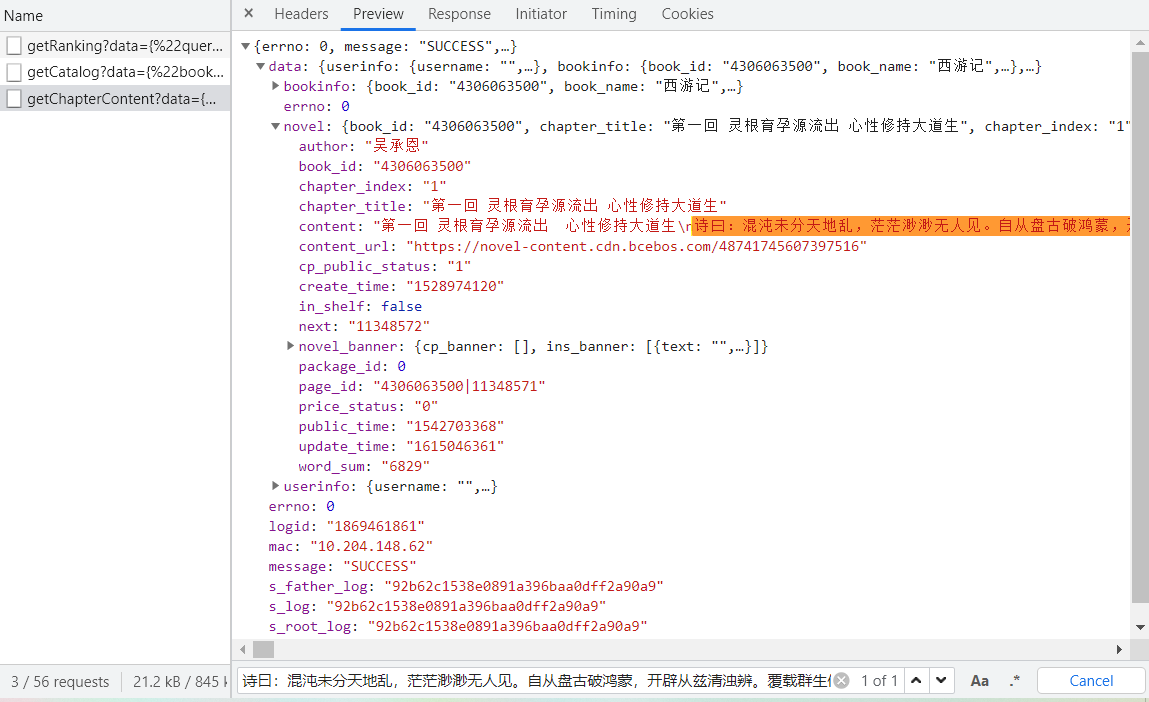
'https://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"}'
#��һ�ص���ҳ����
import json
'https://boxnovel.baidu.com/boxnovel/content?gid=4306063500&cid=11348571'
#��ͬ���������Ǹ���������û������
'https://dushu.baidu.com/api/pc/getChapterContent?data={%22book_id%22:%224306063500%22,%22cid%22:%224306063500|11348571%22,%22need_bookinfo%22:1}'
#�������ʵ�ʵ�
#���Կ�������������gid��cid���ǻ���
#������ͨ����ҳԴ�����ȡcid
import requests
import aiohttp
import asyncio
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
async def download(title,bookid,cid):
data = {
'book_id': bookid,
'cid': '{} | {}'.format(bookid, cid),
'need_bookinfo': 1
}
data=json.dumps(data)
url=f'https://dushu.baidu.com/api/pc/getChapterContent?data={data}'
print(url)
async with aiohttp.ClientSession() as session:
async with session.get(url=url,headers=headers) as res:
dic=await res.json()
with open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\���μ�\\{}.txt'.format(title)\
,'w') as f:
f.write(dic['data']['novel']['content'])
async def getCatalog(bookid):
#�ȶ������url��������,ֻ��Ҫһ�ο��Ի�����е��½�cid
url='https://dushu.baidu.com/api/pc/getCatalog?data={"book_id": '+bookid+'}'
html=requests.get(url,headers).json()
items=html['data']['novel']['items']
tasks=[]
for item in items:
title=item['title']
cid=str(item['cid'])
#����������������
tasks.append(asyncio.create_task(download(title,bookid,cid)))
await asyncio.wait(tasks)
if __name__ == '__main__':
bookid='4306063500'
asyncio.run(getCatalog(bookid))
���ץȡһ����Ƶ
һ�����Ƶ��վ����ô����Ƶ��������
�����㵱Ȼ�ǿ���ֱ������ֱ�Ӱ���Ƶ����������
��������ζ�Ų��۶�����Ƶ�㶼��Ҫȥ������,�϶�ʱҲ��Ҫ��ǰ����ȼ�����
�Ŷ����û���˵̫��,�����ϰ���˵̫��Ǯ.
������һ���������Ƶ��վ����������
�û��ϴ���Ƶ�C>ת��(����Ƶ������,2k,1080,����)�C>��Ƭ����(�ѵ����ļ����в��)
��Ƭ����:��60������Ƶ�ó�1����һ���������Եõ�60�ϵ��Ǿ�������
��Ҫһ���ļ���¼:1.��Ƶ����˳�� 2.��Ƶ���·��
M3U8 txt json -->�ı�
1.�ҵ�m3u8(�����ֶ�)
2.ͨ��m3u8���ص�ts�ļ�
3.����ͨ�������ֶ�(�����DZ���ֶ�)��ts�ļ��ϲ�Ϊһ��MP4�ļ�
��ȡ91�����
1.�����ҳ����Ƶ������ҳԴ����û�б�ǩ,���Զ϶��ǽű�����(�ͻ�����Ⱦ)
2.һ�ַ�������
��ǰ�������������ҳ��Դ��������û����Ҫ�����ݵ�ʱ��,����ֱ�Ӷ�������Ҫ�����ݵ�url��������
�������������������,�������ʼ��ҳ�淢������,��ȡ���Ӧ��url �ٷ�������(url�Ƕ�̬�仯���ɵ�)
3.����
while True:
try:
res1=requests.get(url='https://www.91kanju.com/vod-play/59859-1-1.html',headers=headers)
break
except:
pass
5.�ļ��Ķ�ȡ����,ƽʱ�õIJ���������Щ���
f.readlines() һ�¶�ȡ����,���б���ʽ����
f.readline() һ��ֻ��ȡһ��,�Ѿ��ȹ����´β����ٶ�
��ش���(�����������Ĵ���,��ȷ�Ŀ��Կ�����)
# 'https://www.91kanju.com/vod-play/59859-1-1.html'
# #������Ҫ�����������ҳ,����û����Ƶ,������������Ҫ��,m3u8����.
# #��������ץ��������Ҳ�ܿ�����ô,Ϊʲôҳ��Դ��������ҲҪ�����
#
# #�����Ҿ���,��ֱ�Ӷ�����ץ�������п�����url��������
import requests
import re
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
#
#
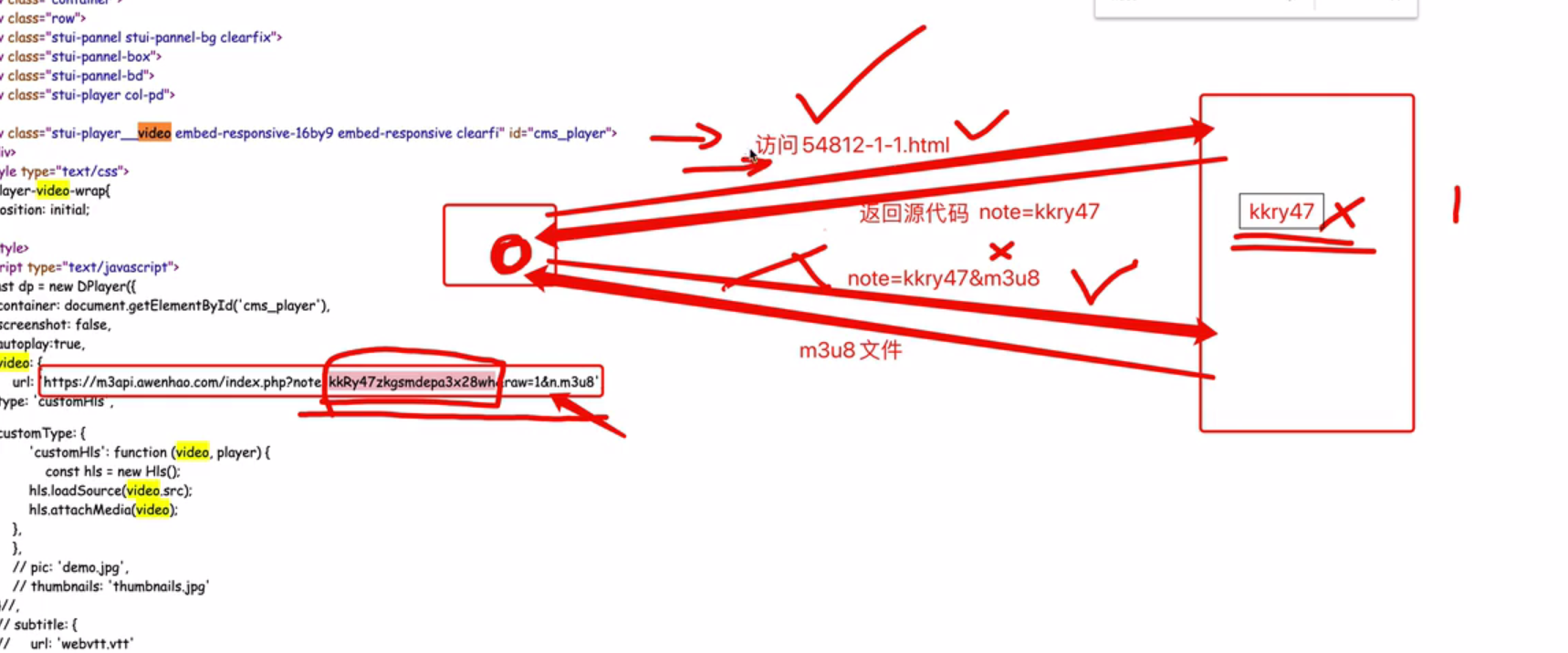
# # res=requests.get(url='https://m3api.awenhao.com/index.php?note=kkRage296dk4853hqsnxt&raw=1&n.m3u8',headers=headers)
# # print(res)
# # print(1)
# '���Է��ֺ����,����ʾ�����ҳ��404,�����������������ҳ��url�İ�'
#
# #�����ٿ���һ��ҳ���Դ����
# 'https://m3api.awenhao.com/index.php?note=kkRwn42dkmbyat9xh5g6c&raw=1&n.m3u8'
# #������������ӿ��Ժ������һ��
# 'https://m3api.awenhao.com/index.php?note=kkRage296dk4853hqsnxt&raw=1&n.m3u8'
# #�ᷢ��note��Ӧ�IJ��ֲ�һ��,����ζ�Ų�����������ı��.
#
# #��ô��Ҫ����
#
# #1.��ָ��������Ƶ��url��������
# while True:
# try:
# res1=requests.get(url='https://www.91kanju.com/vod-play/59859-1-1.html',headers=headers)
# break
# except:
# pass
#
#
# html1=res1.text
# res1.close()
# #2.��ȡurl,��Ϊ��script����xpath����ֻ����re��
# findmu=re.compile(r"url: '(?P<mu_url>.*?)',",re.S)
# mu=findmu.search(html1).group('mu_url')
#
# #����ѻ�ȡ����m3u8������������
# f=open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\��˺�Ī�ٵ��弾 ��01��.m3u8','wb')
# f.write(requests.get(url=mu,headers=headers).content)
# f.close()
# '������һ��,����m3u8�ļ�ֻ��Ҫ֪����ͬ�����Ӿ����������������Ƶ���ݵ�(����#�ŵ�)'
#��ȡ��Ӧ��url
with open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\��˺�Ī�ٵ��弾 ��01��\\��˺�Ī�ٵ��弾 ��01��.m3u8',\
'r') as f:
readlines=f.readlines()
i=1
headers1={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36',
'location':'https://puui.qpic.cn/newsapp_ls/0/12918117609/0'
}
for line in readlines:
line=line.strip()
if not line.startswith('#'):
#��ö�Ӧ���ӿ�ʼ����
res1=requests.get(url=line,headers=headers1)
with open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\�����ļ�����\\��˺�Ī�ٵ��弾 ��01��\\{}.ts'.format(i),\
'wb') as q:
q.write(res1.content)
print(line)
i+=1
�����������������ص�Ӱ�ĵط��и�����,�õ�����ַ����û������,Ӧ����302��ԭ��������û�ҵ�referer
�������ֻ�ʱ�俴����,����Ӧ��������.
������m3u8�����ȡ����url
https://m3api.awenhao.com/phls/OWU2OXhsYVRZaCtTbExkeGZwUDBwL2pIZnhsMG0xS2FTSzF3RzI2VUtRREFQNzNOcUF6TTVlK3IyeUlmZlR1cnR5L1IvL2hlckVDUFZ6d1pFQkFJWmFqbDBvVXBhSVJxeFNjZTB2aHZrSlpmR3NJMUg4eDBYZnVMQWFCd2VXT0V5REx2Y1BPalBiVlY1YVZjK2s3RWErU3JqVkw3eHZPRENhdnlqWW9jRHR4d2l4WUFmeEp3Y0pF
���url����ɶ����Ҳû��.�������������һ��url��������,���Ǹ�url������Ҫ��
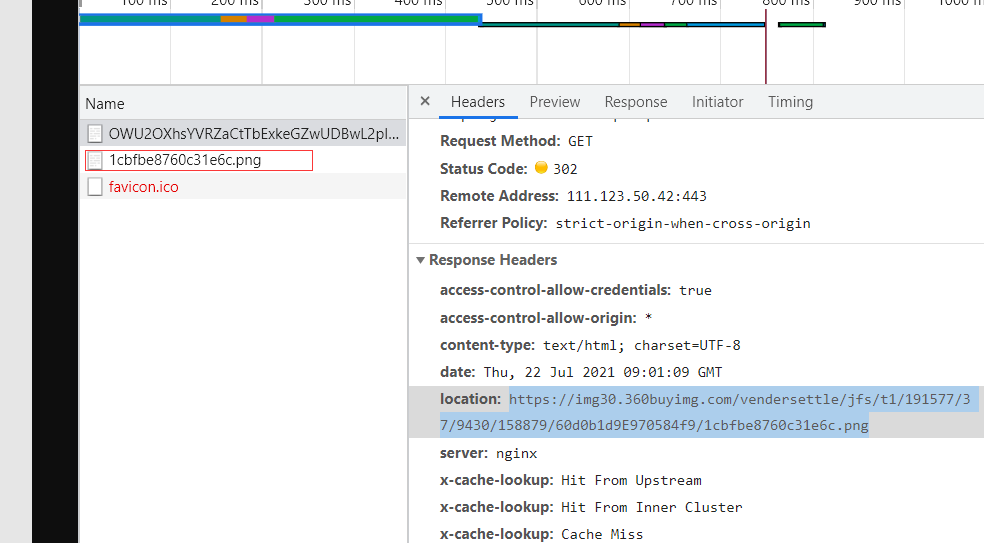
������Ӧͷ location��������Ҫ��url(������ΪʲôҪ���url???)
�Լ���
import requests
res=requests.get('https://img30.360buyimg.com/vendersettle/jfs/t1/191577/37/9430/158879/60d0b1d9E970584f9/1cbfbe8760c31e6c.png')
with open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\��˺�Ī�ٵ��弾 ��01��\\hh.ts','wb') as f:
f.write(res.content)
�������������֮����б������ǿ��ĵ��������Ǹ���Ƶ,���Կ�����Ƶ,���
���ǹؼ�������
�Ҳٲٲٲٲ�,�Ҳٲٲٲٲٲٲٲٲٲٲٲٲٲٲ�.������������������������
��������,�һ���һ��Сʱ��������һֱ�����ҵ�locationΪʲôû������,������ڸ�����
��������,�Ҹ���???
�Ҳ�Ҫ���ɵ��
����취�Ǽ�res1=requests.get(url=line,headers=headers1,allow_redirects=False) Ĭ��ΪTrue
(�������ʼ���Ǽ����ò���)
res1=requests.get(url=line,headers=headers1,allow_redirects=False)
��Ӧ����
# 'https://www.91kanju.com/vod-play/59859-1-1.html'
# #������Ҫ�����������ҳ,����û����Ƶ,������������Ҫ��,m3u8����.
# #��������ץ��������Ҳ�ܿ�����ô,Ϊʲôҳ��Դ��������ҲҪ�����
#
# #�����Ҿ���,��ֱ�Ӷ�����ץ�������п�����url��������
import requests
import re
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
# res=requests.get(url='https://m3api.awenhao.com/index.php?note=kkRage296dk4853hqsnxt&raw=1&n.m3u8',headers=headers)
# print(res)
# print(1)
'���Է��ֺ����,����ʾ�����ҳ��404,�����������������ҳ��url�İ�'
#�����ٿ���һ��ҳ���Դ����
'https://m3api.awenhao.com/index.php?note=kkRwn42dkmbyat9xh5g6c&raw=1&n.m3u8'
#������������ӿ��Ժ������һ��
'https://m3api.awenhao.com/index.php?note=kkRage296dk4853hqsnxt&raw=1&n.m3u8'
#�ᷢ��note��Ӧ�IJ��ֲ�һ��,����ζ�Ų�����������ı��.
#��ô��Ҫ����
#1.��ָ��������Ƶ��url��������
while True:
try:
res1=requests.get(url='https://www.91kanju.com/vod-play/59859-1-1.html',headers=headers)
break
except:
pass
html1=res1.text
#2.��ȡurl,��Ϊ��script����xpath����ֻ����re��
findmu=re.compile(r"url: '(?P<mu_url>.*?)',",re.S)
mu=findmu.search(html1).group('mu_url')
print(mu)
print('----------------'*30)
#����ѻ�ȡ����m3u8������������
f=open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\��˺�Ī�ٵ��弾 ��01��\\��˺�Ī�ٵ��弾 ��01��.m3u8','wb')
f.write(requests.get(url=mu,headers=headers).content)
f.close()
'������һ��,����m3u8�ļ�ֻ��Ҫ֪����ͬ�����Ӿ����������������Ƶ���ݵ�(����#�ŵ�)'
#��ȡ��Ӧ��url
with open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\��˺�Ī�ٵ��弾 ��01��\\��˺�Ī�ٵ��弾 ��01��.m3u8',\
'r') as f:
readlines=f.readlines()
i=1
for line in readlines:
line=line.strip()
if not line.startswith('#'):
#��ö�Ӧ���ӿ�ʼ����
res1=requests.get(url=line,headers=headers,allow_redirects=False)
location=res1.headers['location']
res2=requests.get(url=location,headers=headers)
with open('E:\\2021������Python����̳�+ʵս��Ŀ����(����¼��)\\��˺�Ī�ٵ��弾 ��01��\\{}.ts'.format(i),\
'wb') as q:
q.write(res2.content)
print(i)
i+=1
19.��ȡ91���縴�Ӱ�
iframe ��ҳǶ����ҳ ����ŵ�������һ����ҳ
selenium
һЩ��صIJ������������д���ر���ϸ���Կ�һ��
selenium��ز���
���˾�������������ĺ���,����ֻ�Ǹ���ʹ��,��ȥ������ص���������,��seleniumû��
������(�����������Ǽ��ܵ���Ҫ���ܵ����,����������������������)
selenium:�Զ������Թ���
���Դ������,Ȼ������һ����ȥ���������
����Ա���Դ�selenium��ֱ����ȡ��ҳ�ϵĸ�����Ϣ
���������Ҫ��������,���ǹȸ������,�����ǹȸ�����
��װ�̳�
20.����һ��selenium
from selenium.webdriver import Chrome
#��Ϊ���ǹȸ������
#1.��������������
web=Chrome(executable_path='D:\\�ȸ�������\\chromedriver.exe')
#2.��һ����ַ
web.get('http://www.baidu.com')
21.selenium�ĸ��ֲ���
1.xpath��ʹ��д����������Ҳ���ᱨ��ֻ�ǻ᷵��һ�����б�
2.paused in debuggger�����ץ������ʱ���ܻ�����������
�������
������������Ƭ
21.1дһ��requests�İ汾���Ա�
22.selenium�����л�
#��������bվ��һ��
#�Ҿ������ҵļ���������,�Dz���Ҫָ����
from selenium import webdriver
import time
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
options = webdriver.ChromeOptions()
prefs = {"":""}
prefs["credentials_enable_service"] = False
prefs["profile.password_manager_enabled"] = False
options.add_experimental_option("prefs", prefs)
options.add_experimental_option('excludeSwitches', ['enable-automation'])
#window.navigator.webdriverֵΪTrue,Ӧ�����ΪFalse(�ж��Dz��ǻ���)
options.add_argument('--disable-blink-features=AutomationControlled')
#1.�������
bro=webdriver.Chrome(executable_path='D:\\�ȸ�������\\chromedriver.exe',options=options)
bro.get("https://www.bilibili.com/")
#2.��ȡ������
bro.find_element_by_xpath('//*[@id="nav_searchform"]/input').send_keys('����',Keys.ENTER)
time.sleep(5)
# #3.����������Է�������
# bro.find_element_by_xpath('//*[@id="all-list"]/div[1]/div[2]/ul/li[3]/div/div[1]').click()
#��ᷢ��������ô�������ǻᱨ����,Ϊʲô��?
'��selenium���´���Ĭ���Dz��л�������'
#�������´��� #������Ĵ���(window_handles)
bro.switch_to.window((bro.window_handles[-1]))
#3.����������Է�������
bro.find_element_by_xpath('//*[@id="all-list"]/div[1]/div[2]/ul/li[3]').click()
#�رոô���
bro.close()
#ע����Ϊ���Զ��л�������Ҫ���Լ�ȥŪ
bro.switch_to.window((bro.window_handles[0])) #������0��ʼ
������������ֱ�ӵ�ҳ����ҳ�����л�
��������iframe����ҳ����Ƕ����ҳ���л�
������91�������վдһ��
#1.��91������վ
bro.get('https://www.91kanju.com/vod-detail/54812.html')
print(bro.title)
#2.һ�����ȶ�λ��iframeԪ��
iframe=bro.find_element_by_xpath('/html/body/div[3]/iframe[1]')
bro.switch_to.frame(iframe)
#bro.switch_to.default_content() #�л���ԭҳ��
print(bro.find_element_by_xpath('//*[@id="cscpvrich7798_ab"]').text)
23.ʵ����ͷ�����+��ȡÿ��Ʊ������
1.���ʵ����ͷ
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
option=Options()
option.add_argument('--headless')
option.add_argument('--disbale-gpu')
#1.�������
bro=webdriver.Chrome(executable_path='D:\\�ȸ�������\\chromedriver.exe',options=option)
2.���ʵ�����������ת��
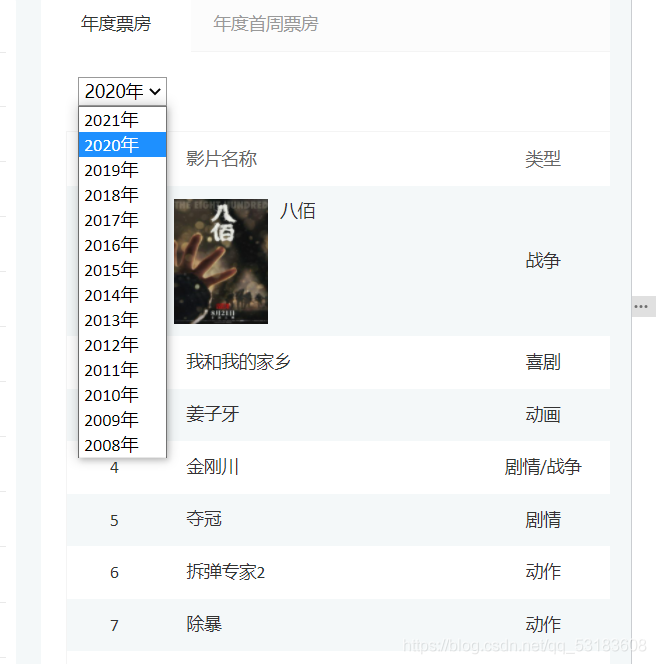
�����û�취ֱ�Ӷ�λ����
from selenium.webdriver.support.select import Select
#3.��ö�Ӧ������
select=bro.find_element_by_xpath('//*[@id="OptionDate"]')
"��Ԫ�ؽ��д����װ�������˵�"
select=Select(select)
select.select_by_index(i) #�������������л�
����IJ�������һ����,������Ѿ�ת��ҳ����.�����ǵ���ҳ������ֱ���ж�λ��
text����ֱ�ӻ�øýڵ��µ������ı�
tbody=bro.find_element_by_xpath('//*[@id="TableList"]/table/tbody') #���ҳ��û�����ӻ�����
print(tbody.text)
import time
from selenium.webdriver.support.select import Select
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
option=Options()
option.add_argument('--headless')
option.add_argument('--disbale-gpu')
#1.�������
bro=webdriver.Chrome(executable_path='D:\\�ȸ�������\\chromedriver.exe',options=option)
#2.��������
bro.get('https://www.endata.com.cn/BoxOffice/BO/Year/index.html')
#3.��ö�Ӧ������
select=bro.find_element_by_xpath('//*[@id="OptionDate"]')
"��Ԫ�ؽ��д����װ�������˵�"
select=Select(select)
#4.��ʼѭ�����ÿһ���
for i in range(len(select.options)):
#�������������л�
select.select_by_index(i) #�������������л�
time.sleep(2) #��Ҫ��������
tbody=bro.find_element_by_xpath('//*[@id="TableList"]/table/tbody') #���ҳ��û�����ӻ�����
print(tbody.text)
���ڵ���ʶ����֤��Ļ���,��������ֱ�����˼ҵij���ӥ��.����,����
����ӥ
24.����ӥ�ɳ���ӥ
1.����ֱ�ӶԶ�λԪ�ؽ�ͼ
im=bro.find_element_by_xpath(����).screenshot_as_png
��Щֻ�����ŵĵط�����Ҫд�û����������
from selenium import webdriver
from chaojiying import Chaojiying_Client
#1.�������
bro=webdriver.Chrome(executable_path='D:\\�ȸ�������\\chromedriver.exe')
#2.��������
bro.get('https://www.chaojiying.com/user/login/')
#3.�����û���,����,��֤��
bro.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input').send_keys('')
bro.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input').send_keys('')
#�����Ƕ�λ��ͼƬԪ��֮��ֱ�ӽ�ͼ����Ϊpng�ļ���
im=bro.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/div/img').screenshot_as_png
chaojiying = Chaojiying_Client('', '', '96001')
pic_str=chaojiying.PostPic(im, 1902)['pic_str']
bro.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input').send_keys(pic_str)
#�����½
bro.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input').click()
25.��½12306
1.������ô�϶�����,�����ɹ�.������Ϊ��ʶ��������Զ�������,���Բ�������
�����������ͺ���
from selenium.webdriver.chrome.options import Options
option=Options()
option.add_argument('--disable-blink-features=AutomationControlled')
#1.�������������
bro=webdriver.Chrome(executable_path='D:\\�ȸ�������\\chromedriver.exe',options=option)
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from chaojiying import Chaojiying_Client
import time
from selenium.webdriver.chrome.options import Options
option=Options()
option.add_argument('--disable-blink-features=AutomationControlled')
#1.�������������
bro=webdriver.Chrome(executable_path='D:\\�ȸ�������\\chromedriver.exe',options=option)
#2.��������
bro.get('https://kyfw.12306.cn/otn/resources/login.html')
time.sleep(2)
#3.��λ���û���½�����
bro.find_element_by_xpath('/html/body/div[2]/div[2]/ul/li[2]/a').click()
#4.�����û���,����
bro.find_element_by_xpath('//*[@id="J-userName"]').send_keys('12333333333333')
bro.find_element_by_xpath('//*[@id="J-password"]').send_keys('12333333333333333')
#5.��λ����֤��,���ó���ӥʶ��
code=bro.find_element_by_xpath('//*[@id="J-loginImg"]')
#5.1��������ӥ����,��ʶ��
chaojiying = Chaojiying_Client('', '', '96001')
pic_str=chaojiying.PostPic(code.screenshot_as_png, 9004)['pic_str']
#6.�Ի�õ�������н���,���
x_y_s=pic_str.split('|')
print(x_y_s)
for x_y in x_y_s:
x_y=x_y.split(',')
x=int(x_y[0])
y=int(x_y[1])
'����ǵ���Ҫ�ͷŲ���,��Ȼ�Ļ�����ȥִ��,���Ҳ�����ѹ(perform)'
ActionChains(bro).move_to_element_with_offset(code,x,y).click().perform()
#7.���е�½
bro.find_element_by_xpath('//*[@id="J-login"]').click()
time.sleep(4)
#8.���������Ļ���
huakuai=bro.find_element_by_xpath('//*[@id="nc_1__scale_text"]/span')
ActionChains(bro).drag_and_drop_by_offset(huakuai,huakuai.location['x'],0).perform()