(一)简单的索引操作
以下索引操作十分简单,通过代码结果对比,及能清晰的看懂,不过多解释。
1 获取index:df.index
df1 = pd.DataFrame([[100.0,1.0,1.0,1.0],[1.0,1.0,1.0,1.0]],index=["A","B"],columns=list("abcd"))
print(df1)
print('源仔 '*10)
print(df1.index)
OUT:
a b c d
A 100.0 1.0 1.0 1.0
B 1.0 1.0 1.0 1.0
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
Index(['A', 'B'], dtype='object')
2 指定index :df.index = [‘x’,‘y’]
# 对已有的DataFrame的索引进行赋值
df1.index = ["a","b"]
print(df1)
OUT:
a b c d
a 100.0 1.0 1.0 1.0
b 1.0 1.0 1.0 1.0
3 重新设置index : df.reindex(list(“abcdef”))
# 重新设置index
print(df1.reindex(["a","f"]))
# a行对应DataFrame是能取到的,f索引在DataFrame没有行对应,所以全部显示NAN
# 但之后df1返回原有DataFrame的原型
OUT:
a b c d
a 100.0 1.0 1.0 1.0
f NaN NaN NaN NaN
4 指定某一列作为index :df.set_index(“a”,drop=False)
# 把当前DataFrame的某一列作为索引
print('\n')
print('源仔 '*10)
print(df1.set_index("a"))
print(df1.set_index("a").index)
# 上面把DataFrame中的a列作为索引,但是a列就没了
# 现在把当前DataFrame的某一列作为索引,并且保留这一列
print('\n')
print('源仔 '*10)
print(df1.set_index("a",drop=False))
OUT:
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
b c d
a
100.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0
Float64Index([100.0, 1.0], dtype='float64', name='a')
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
a b c d
a
100.0 100.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0
5 返回index的唯一值:df.set_index(“Country”).index.unique()
# 返回index的唯一值
print('\n')
print('源仔 '*10)
print(df1["d"].unique())
print(df1["a"].unique())
# 返回index的全部值
print('\n')
print('源仔 '*10)
t1 = list(df1.set_index("d").index)
t2 = list(df1.set_index("a").index)
print(t1,t2)
# index的长度
t3 = len(df1.set_index("d").index.unique())
t4 = len(df1.set_index("d").index)
print('\n')
print('源仔 '*10)
print(t3)
print(t4)
OUT:
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
[1.]
[100. 1.]
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
[1.0, 1.0] [100.0, 1.0]
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
1
2
6 当df1.set_index([“c”,“d”])即设置两个索引的时候是什么样子的结果呢?
# 当df1.set_index(["c","d"])即设置两个索引的时候是什么样子的结果呢?
q1 = df1.set_index(["a","d"])
q2 = df1.set_index(["a","d"]).index
q3 = df1.set_index(["a","b","d"],drop=False)
print('\n')
print('源仔 '*10)
print(q1)
print('源仔 '*10)
print(q2)
print('源仔 '*10)
print(q3)
OUT:
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
b c
a d
100.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
MultiIndex([(100.0, 1.0),
( 1.0, 1.0)],
names=['a', 'd'])
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
a b c d
a b d
100.0 1.0 1.0 100.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0 1.0 1.0
7 写一个字典形式DataFrame
# 写一个字典形式DataFrame
a = pd.DataFrame({'a': range(7),'b': range(7, 0, -1),'c': ['one','one','one','two','two','two', 'two'],'d': list("hjklmno")})
print('\n')
print('源仔 '*10)
print(a)
OUT:
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
a b c d
0 0 7 one h
1 1 6 one j
2 2 5 one k
3 3 4 two l
4 4 3 two m
5 5 2 two n
6 6 1 two o
(二)灵活运用上面的索引


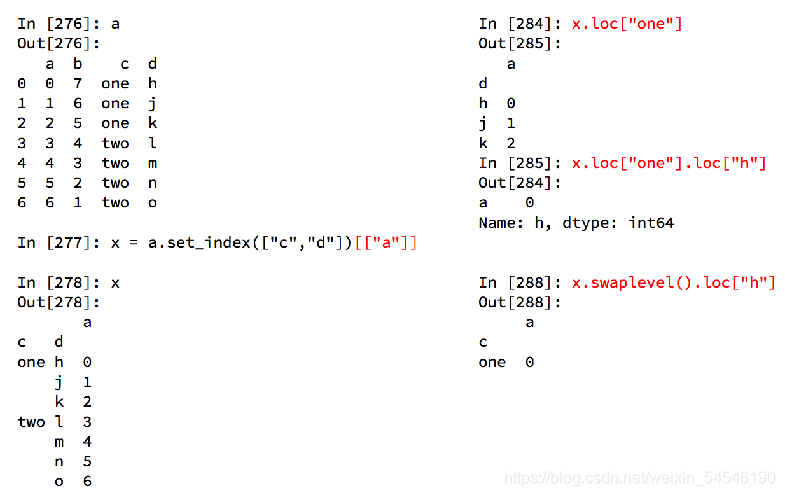
1 为下面程序做对比参照
import numpy as np
import pandas as pd
# 写一个字典形式DataFrame
df2 = pd.DataFrame({'a': range(7),'b': range(7, 0, -1),'c': ['one','one','one','two','two','two', 'two'],'d': list("hjklmno")})
print(df2)
# 取出从c、d列作为索引
b = df2.set_index(["c","d"])
print('源仔 '*10)
print(b)
# Series
c = b["a"]
print('\n')
print('源仔 '*10)
print(c)
print(type(c))
d = c["one"]["j"]
e = c["one"] # 这也是Series类型
print('\n')
print('源仔 '*10)
print(d)
print('源仔 '*10)
print(e)
OUT:
a b c d
0 0 7 one h
1 1 6 one j
2 2 5 one k
3 3 4 two l
4 4 3 two m
5 5 2 two n
6 6 1 two o
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
a b
c d
one h 0 7
j 1 6
k 2 5
two l 3 4
m 4 3
n 5 2
o 6 1
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
c d
one h 0
j 1
k 2
two l 3
m 4
n 5
o 6
Name: a, dtype: int64
<class 'pandas.core.series.Series'>
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
1
源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔 源仔
d
h 0
j 1
k 2
Name: a, dtype: int64
2 如何取内层索引
swaplevel() # 把前两列索引交换位置
# 如何取内部的索引
a1 = df2.set_index(["d","c"])["a"]
print('\n')
print('# # '*10)
print(a1)
# 如何取上述a1内部one的索引呢
print('# # '*10)
print(a1.index)
b2 = a1.swaplevel() # 把前两列索引交换位置
print('# # '*10)
OUT:
# # # # # # # # # # # # # # # # # # # #
d c
h one 0
j one 1
k one 2
l two 3
m two 4
n two 5
o two 6
Name: a, dtype: int64
# # # # # # # # # # # # # # # # # # # #
MultiIndex([('h', 'one'),
('j', 'one'),
('k', 'one'),
('l', 'two'),
('m', 'two'),
('n', 'two'),
('o', 'two')],
names=['d', 'c'])
# # # # # # # # # # # # # # # # # # # #
c d
one h 0
j 1
k 2
two l 3
m 4
n 5
o 6
Name: a, dtype: int64
# # # # # # # # # # # # # # # # # # # #
d
h 0
j 1
k 2
Name: a, dtype: int64
(三)实例
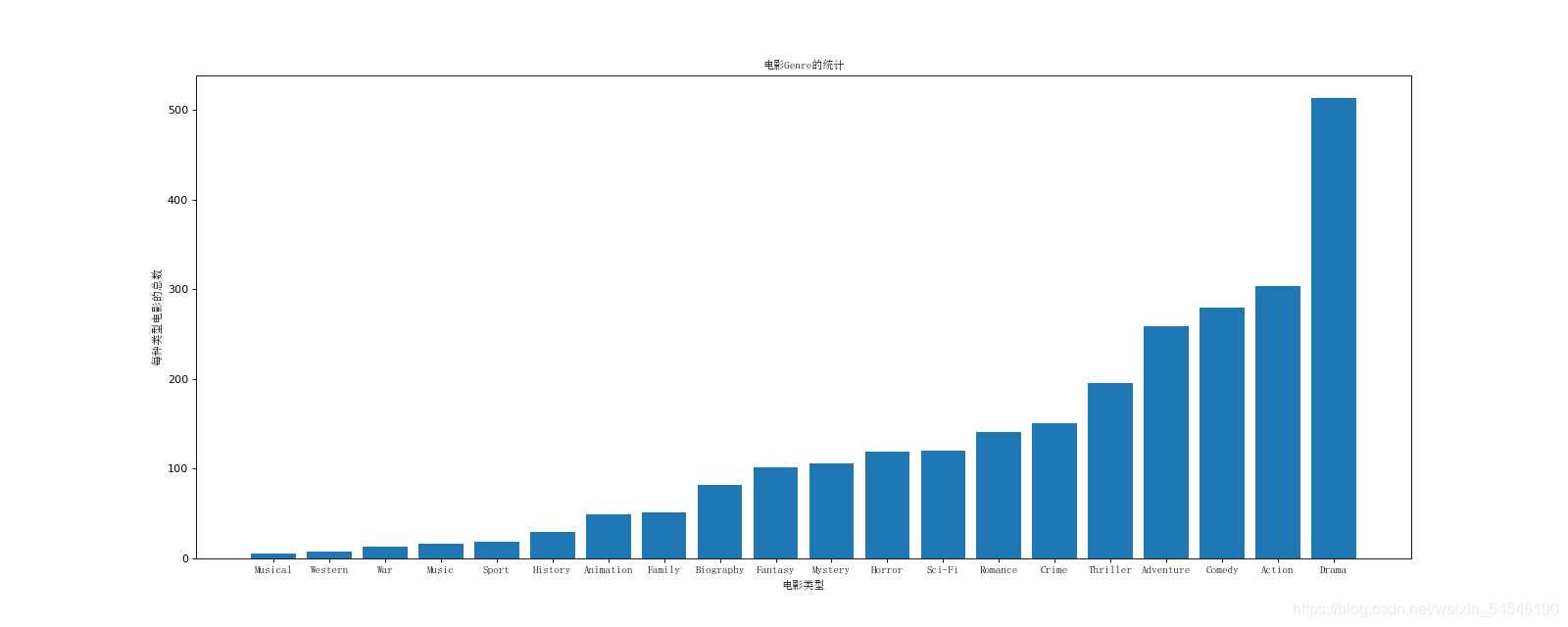
3.1 使用matplotlib呈现出店铺总数排名前10的国家
- groupby():python中groupby函数主要的作用是进行数据的分组以及分组后地组内运算!
df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式――函数名称)
详细解释可查看:python中groupby函数主要的作用
- sort_values():可以查看链接Pandas-排序函数sort_values()
# coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
file_path = "starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
# 使用matplotlib呈现出店铺总数排名前18的国家
#准备数据
data1 = df.groupby(by="Country").count()["Brand"].sort_values(ascending=False)[:10]
_x = data1.index
_y = data1.values
# 画图
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.show()
OUT:
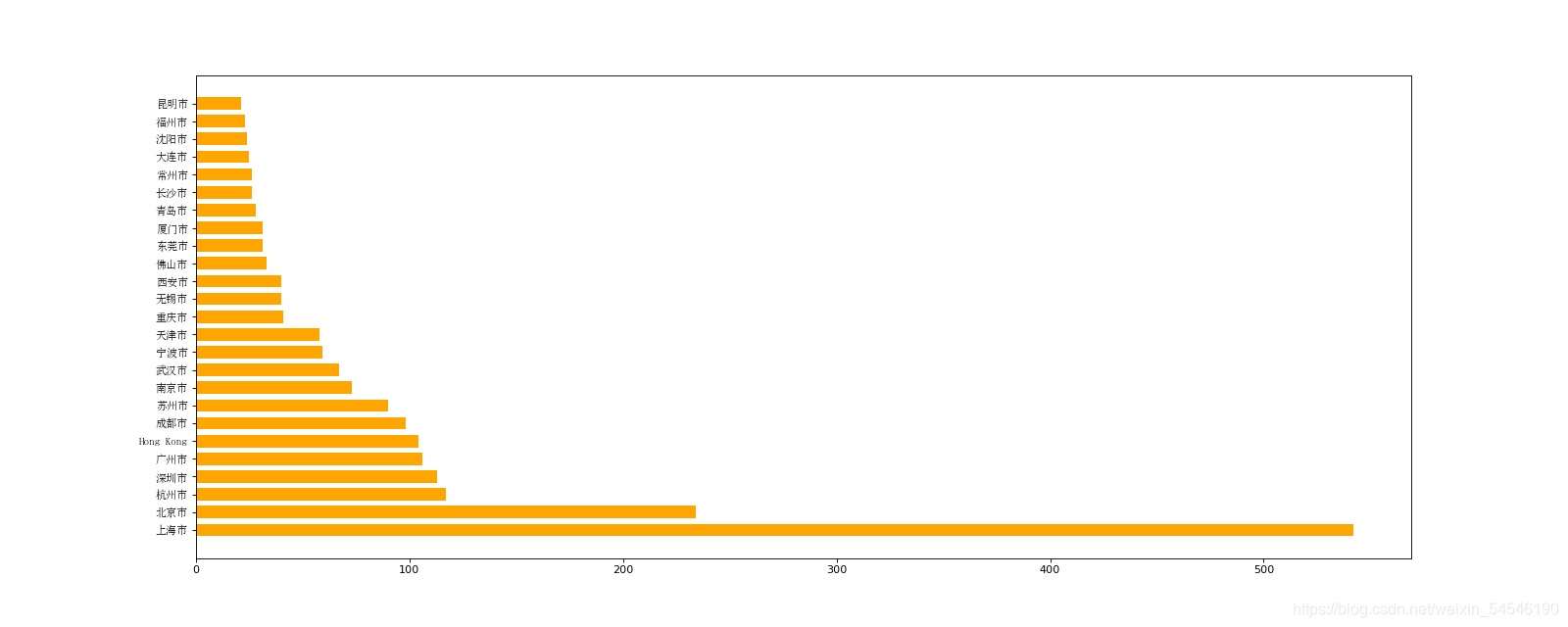
3.2使用matplotlib呈现出每个中国每个城市的店铺数量
# coding=utf-8
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname="C:/Windows/Fonts/simsun.ttc")
file_path = "starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
df = df[df["Country"]=="CN"]
# 使用matplotlib呈现出店铺总数排名前18的国家
#准备数据
data1 = df.groupby(by="City").count()["Brand"].sort_values(ascending=False)[:25]
_x = data1.index
_y = data1.values
# 画图
plt.figure(figsize=(20,8),dpi=80)
#plt.bar(range(len(_x)),_y,width=0.3,color="orange")
# 画横型条状图
plt.barh(range(len(_x)),_y,height=0.7,color="orange")
plt.yticks(range(len(_x)),_x,fontProperties = my_font)
plt.show()
OUT:
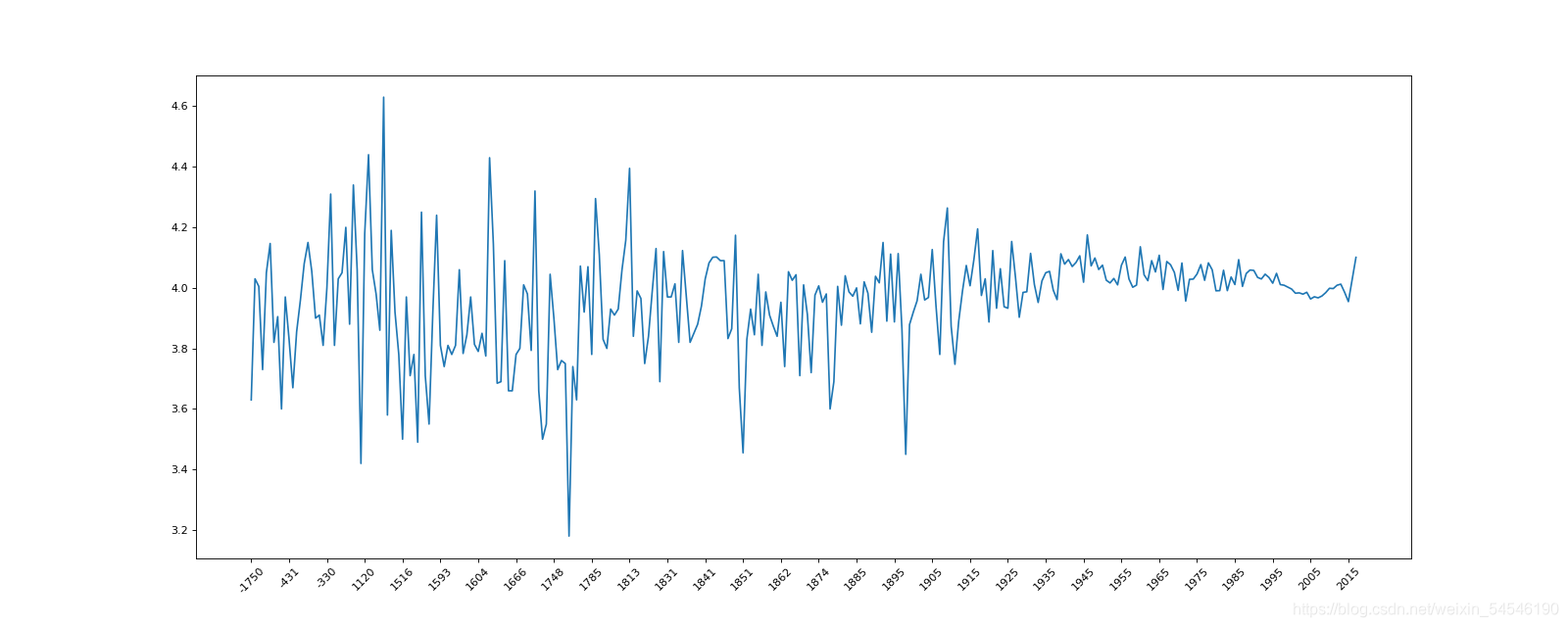
3.3 不同年份书的数量and平均评分情况
现在我们有全球排名靠前的10000本书的数据,那么请统计一下下面几个问题:
- 不同年份书的数量
- 不同年份书的平均评分情况
books.csv数据链接如下:
链接:https://pan.baidu.com/s/1uGY9dGUNV7n32kGZdWGqFw
提取码:hw3e
# coding=utf-8
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
from matplotlib import font_manager
file_path = "books.csv"
df = pd.read_csv(file_path)
print(df.head(2))
print("# # "*20)
print(df.info())
OUT:
id ... small_image_url
0 1 ... https://images.gr-assets.com/books/1447303603s...
1 2 ... https://images.gr-assets.com/books/1474154022s...
[2 rows x 23 columns]
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 23 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 10000 non-null int64
1 book_id 10000 non-null int64
2 best_book_id 10000 non-null int64
3 work_id 10000 non-null int64
4 books_count 10000 non-null int64
5 isbn 9300 non-null object
6 isbn13 9415 non-null float64
7 authors 10000 non-null object
8 original_publication_year 9979 non-null float64
9 original_title 9415 non-null object
10 title 10000 non-null object
11 language_code 8916 non-null object
12 average_rating 10000 non-null float64
13 ratings_count 10000 non-null int64
14 work_ratings_count 10000 non-null int64
15 work_text_reviews_count 10000 non-null int64
16 ratings_1 10000 non-null int64
17 ratings_2 10000 non-null int64
18 ratings_3 10000 non-null int64
19 ratings_4 10000 non-null int64
20 ratings_5 10000 non-null int64
21 image_url 10000 non-null object
22 small_image_url 10000 non-null object
dtypes: float64(3), int64(13), object(7)
memory usage: 1.8+ MB
None
不同年份书的平均评分情况
# coding=utf-8
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
from matplotlib import font_manager
file_path = "books.csv"
df = pd.read_csv(file_path)
print(df.head(2))
print("# # "*20)
print(df.info())
'''
original_publication_year 9979 non-null float64,可知当前数据有缺失,总数据因该是10000,首先因该删除缺失的数据
'''
# 不同年份书的数量
```python
# 删除整个这一列缺失的数据
data1 = df[pd.notnull(df["original_publication_year"])] # 也就是取这一列不为NaN的数据
grouped = data1.groupby(by="original_publication_year").count()["title"]
'''
grouped = data1["average_rating"].groupby(by=data1["original_publication_year"]).count()
print(grouped)
查看original_publication_year出版的数量,带负号的年份表示公元前
'''
# 平均评分情况
data1 = df[pd.notnull(df["original_publication_year"])] # 也就是取这一列不为NaN的数据
grouped = data1["average_rating"].groupby(by=data1["original_publication_year"]).mean()
print(grouped)
# 画图
_x = grouped.index
_y = grouped.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(list(range(len(_x)))[::10],_x[::10].astype(int),rotation=45)
plt.show()
OUT:
original_publication_year
-1750.0 3.630000
-762.0 4.030000
-750.0 4.005000
-720.0 3.730000
-560.0 4.050000
...
2013.0 4.012297
2014.0 3.985378
2015.0 3.954641
2016.0 4.027576
2017.0 4.100909
Name: average_rating, Length: 293, dtype: float64
(四)python数据科学库学习目录
学习python数据科学库笔记的顺序:
python数据科学库(一)
python数据科学库(二)matplotlib
python数据科学库笔记(三)Numpy
Python下载并安装第三方库(cvxpy)
python数据科学库笔记(四)pandas
python数据科学库(五 ・ 一)数字的合并与分组聚合(太具有逻辑性,多复习)
数据科学库(五 ・ 二)数字的合并与分组聚合