python基础篇――函数
??hello!我是wakeyo_J,每天一个konwledge point,一起学python,让技术无限发散。
1. 函数的来源
??早期的高级语言属于过程语言,程序员是按照顺序一行一行的编写代码,然后顺序执行,而且经常出现大量重复的代码行。这样就导致代码非常的臃肿、调试困难、阅读麻烦,当代码要实现的功能越来越强大,相应的问题也就越来越多。为了有效解决上述问题。计算机语言学家便将功能相同的代码单独提取出来,独立实现一个功能,供需要的代码调用,这就是函数的来源。
函数代码的优点
(1)代码简练
(2)提高代码的编写效率和质量
(3)代码的功能可以自由共享
2. 函数基本定义
函数:指通过专门的代码组织,用来实现特定功能的代码段,具有相对的独立性,可以被其他代码重复调用。
- 函数是一段具有特定功能的、可重用的语句组
- 函数是一种功能的抽象,一般函数表达特定的功能
- 两个作用:降低编程难度和代码复用

- 函数定义基本语法
def <函数名>(<参数(0个或多个)>):
<函数体>
return <返回值>
- 函数使用格式说明
标准自定义函数由def关键字、函数名、“([参数]): ”、函数体、[return返回值]五部分组成。
1)def关键字
python中函数定义以def关键字开始,其后空一格跟函数名
2)自定义函数名
在python中,函数名由字母、数字、下划线组成。也就是小写字母a~z、大写字母A-Z、下划线(_)和数字0-9等组成且命名时数字不能作为名称的首字符。
(1)自定义函数名不能和现有内置函数名发生冲突,如:不能使用del命名
(2)名称本身要准确表达函数的功能,建议使用英文单词开头,英文单词之间可以用下划线,如:find_factor,可以清楚的表达“求因数”。
3)([参数]):
中括号中的参数可有可无,小括号后面的冒号(:)是python函数的基本格式要求,不能省略。这里的参数传递对象包括数字、字符串、元组、列表、字典以及类对象。
4)函数体
函数体是实现函数功能的代码段。
5)[return返回值]
return后面空一格,跟需要返回的值。带有中括号,表明函数可以由返回值,也可以没返回值。
3. 自定义函数第一步
3.1 不带参数的函数
- 不带参数函数格式
def 函数名():
函数体
- 案例
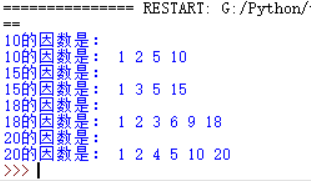
>>> def factor_no_para():
i=1
nums=10
print('%d的因数是:'%nums)
while i<=nums: #循环求10的因数
if nums%i==0: #能整除的是10的因数
print("%d"%i)
i += 1
>>> factor_no_para()
10的因数是:
1
2
5
10
>>> tt=type(factor_no_para)
>>> tt
<class 'function'>
>>>
3.2 带参数函数
- 带参数函数格式
def 函数名(参数):
函数体
- 案例
def find_factor(nums):
i=1
str1=""
print("%d的因数是:"%nums)
while i<=nums:
if nums%i==0:
str1 = str1+" "+str(i)
i += 1
print(str1)
num_L=[10,15,18,20]
i = 0
num_len=len(num_L)
while i<num_len:
find_factor(num_L[i])
i+=1
结果:

3.3 带返回值函数
- 带返回值函数格式
def 函数名([参数]):
函数体
return 返回值 #返回值支持python语言所支持的任何对象
- 函数返回值
不带return语句的函数,默认返回None值。
def factor_no_para():
i=1
nums=10
print('%d的因数是:'%nums)
while i<=nums:
if nums%i==0:
print("%d"%i)
i += 1
结果:

3. 案例
def find_factor(nums):
i=1
str1=""
print("%d的因数是:"%nums)
while i<=nums:
if nums%i==0:
str1 = str1+" "+str(i)
i += 1
return str1
num_L=[10,15,18,20]
i = 0
num_len=len(num_L)
return_str=''
while i<num_len:
return_str=find_factor(num_L[i])
print("%d的因数是:%s"%(num_L[i],return_str))
i+=1
结果:
4. 自定义函数完善
4.1 函数文档
自定义函数编写完成后,需要考虑到使用的方便性,如编程人员过了几个月或者几年后都能轻易地知道函数的功能及如何使用。由此,需要对自定义函数建立相应的函数文档。函数文档在函数中通常用三引号(’’’)来表示。
def find_factor(nums):
'''
find_factor 自定义函数
nums 传递一个正整数的参数
以字符串形式返回一个正整数的所有因数
'''
i=1
str1=""
print("%d的因数是:"%nums)
while i<=nums:
if nums%i==0:
str1 = str1+" "+str(i)
i += 1
return str1
help(find_factor)
结果:

4.2 函数健壮
def find_factor(nums):
'''
find_factor 自定义函数
nums 传递一个正整数的参数
以字符串形式返回一个正整数的所有因数
'''
i=1
str1=""
print("%d的因数是:"%nums)
while i<=nums:
if nums%i==0:
str1 = str1+" "+str(i)
i += 1
return str1
##help(find_factor)
find_factor('a')
运行结果报错:

传递参数类型出错,不支持字符串类型的值,对函数进一步改进,增加函数的健壮性。
def find_factor(nums):
'''
find_factor 自定义函数
nums 传递一个正整数的参数
以字符串形式返回一个正整数的所有因数
'''
if type(nums) != int:
print("输入值类型错误,必须是整数")
return
elif nums<=0:
print("输入值的范围出错,必须是整数!")
return
i=1
str1=""
print("%d的因数是:"%nums)
while i<=nums:
if nums%i==0:
str1 = str1+" "+str(i)
i += 1
return str1
find_factor('a')
结果:

5. 将函数放到模块中
自定义函数建立后,如果需要被其他代码文件调用(以.py为扩展名的文件);或者通过共享,让其他程序员使用;或者需要通过正式的商业发布,让全世界的程序员使用,就需要将函数代码单独放到一个可以共享的地方。在python中通过建立独立的函数模块文件(以.py为扩展名的文件),共享给其他代码文件调用。
5.1 建立函数模块
(1)在python语言编辑器中,新建立一个空白的代码文件,用于存放自定义函数代码。如建立文件名为test_function.py的空函数模块文件。
(2)编写并调试完成自定义函数代码
(3)把只属于自定义函数的代码复制到函数模块文件上,若有多个自定义函数,按顺序复制保存即可。

5.2 调用函数模块
5.2.1 用import语句导入整个函数模块
导入格式:import 函数模块名
调用模块文件中的函数格式:模块名.函数名
import test_function
print(test_function.find_factor(8))
结果:

5.2.2 用import语句导入指定函数
导入格式:from 模块名 import 函数名1[,函数名2,…]
from test_function import find_factor
print(find_factor(8))
结果:

5.2.3 用import语句导入所有函数
导入格式:from 模块名 import *
“*”代表指定模块文件里的所有函数
test_function.py模块展示:

调用代码:
from test_function import *
print(find_factor(8))
say_ok()
结果:

5.2.4 模块名、函数别名方式
在导入模块、函数过程中发现模块名、函数名过长(或函数名称冲突),可以通过as语句定义别名来解决。
格式:模块名[函数名] as 别名
>>> import test_function as t1
>>> t1.find_factor(8)
8的因数是:
' 1 2 4 8'
>>> from test_function import find_factor as f1
>>> f1(8)
8的因数是:
' 1 2 4 8'
>>>
5.3 模块搜索路径
当函数模块文件多变时,需要把函数文件独立放到一个子文件夹下,方便统一管理。但是在不同文件夹下的模块调用需要解决路径问题,不然会报“找不到模块”英文提示,且程序无法正常运行。可以用sys.path方法指定需要访问的函数模块文件。

import sys
sys.path[0]='G:\Python\test\代码\第六章\\function'
from test_function import *
print(find_factor(8))
say_ok()
6. 自定义函数第二步
6.1 参数变换
6.1.1 位置参数
位置参数就是传递参数值时,必须和函数定义的参数一一对应,位置不能打乱。
def test(name,age):
print("姓名%s,年龄%s"%(name,age))
test('wky',20)
test(20,'wky')
#结果
姓名wky,年龄20
错误位置:
姓名20,年龄wky
6.1.2 关键字参数
为了避免传递值出错,提供了“参数名=值”的方式,在调用函数时显示表示,而且无序考虑参数的位置顺序。
test(name='wky',age=20)
test(age=20,name='lyj')
test('wky',age=20) #部分指定时,左边可以不指定,从右边指定开始
结果:
姓名wky,年龄20
姓名lyj,年龄20
姓名wky,年龄20
#说明:
test(name='wky',20) #调用会出错,不支持左边指定,右边不指定方式
6.1.3 默认值
为参数预先设置默认值,当没有传递参数值时,该参数自动选自默认值。
def test(name='lyj',age=18):
print("姓名%s,年龄%s"%(name,age))
#函数调用
test(18)
test()
test('wky',20)
#结果:
姓名18,年龄18 #函数默认输入一个值的情况下,把值赋给第一个参数
姓名lyj,年龄18
姓名wky,年龄20
对于自定义函数设置默认值,允许左边的参数没有默认值,右边的有;反过来则不行。
def test(name='',age):
print("姓名%s,年龄%s"%(name,age))
6.1.4 不定长参数 、*
- 传递任意数量的参数值
使用格式:*函数名([param1,param2,…]paramX)
带“*”的paramX参数,可以以接收任意数量的值,但是一个自定义函数只能有一个带"*"的参数,而且只能放置最右边的参数中,否则自定义函数执行时报语法错误。
def watermelon(name,*attributes):
print(name)
print(type(attributes))
description=''
for get_t in attributes:
description += ' ' +get_t
print(description)
watermelon('西瓜','甜','圆形','绿色')
print('-'*30)
watermelon('西瓜','甜','圆形','绿色','红瓤','无籽')
#结果:
西瓜
<class 'tuple'>
甜 圆形 绿色
------------------------------
西瓜
<class 'tuple'>
甜 圆形 绿色 红瓤 无籽
- 传递任意数量的键值对
使用格式:函数名([param1,param2,…]**paramX)
带“**”paramX参数用法和带“*”用法类似,区别:传递的是键值对。
def watermelon(name,**attributes):
print(name)
print(type(attributes))
return attributes
print(watermelon('西瓜',taste='甜',shape='圆形',colour='绿色'))
#结果
西瓜
<class 'dict'>
{'taste': '甜', 'shape': '圆形', 'colour': '绿色'}
6.2 传递元组、列表、字典值
6.2.1 传递元组
def watermelon(name,attributes):
print(name)
print(type(attributes))
return attributes
##get_t = watermelon('西瓜',('甜','圆形','绿色'))
##print(get_t)
print(watermelon('西瓜',('甜','圆形','绿色')))
结果:

6.2.2 传递列表
def watermelon(name,attributes):
print(name)
print(type(attributes))
return attributes
##get_t = watermelon('西瓜',['甜','圆形','绿色'])
##print(get_t)
print(watermelon('西瓜',['甜','圆形','绿色']))
结果:

6.2.3 传递字典
def watermelon(name,attributes):
print(name)
print(type(attributes))
return attributes
attri={'taste':"甜",'shape':"圆形",'colour':"绿色"}
print(watermelon('西瓜',attri))
结果:

6.2.4 传递列表、字典后的问题
在自定义函数内获取从参数传递过来的列表、字典对象后,若在函数内部对它们的元素进行变动,则会同步影响外部传递的变量的元素。
def EditFrult(name,attributes):
attributes[0]=attributes[0]*0.9 #修改元素
return attributes
#调用函数
attri_L=[2,"甜","圆形","绿色"]
get_t = EditFrult("西瓜",attri_L)
print(get_t)
print(attri_L)
结果:

修改:
def EditFrult(name,attributes):
attributes[0]=attributes[0]*0.9 #修改元素
return attributes
#调用函数
attri_L=[2,"甜","圆形","绿色"]
get_t = EditFrult("西瓜",attri_L.copy())
print(get_t)
print(attri_L)
结果:

6.2.5 函数传递对象总结
函数参数值传递的对象可以分为不可变对象、可变对象。
- 不可变对象:在函数里进行值修改,会变成新的对象(在内存产生新的地址),包括:数字、字符串、元组
- 可变对象:在函数里进值修改,函数内外还是同一对象,但是值同步发生变化。包括:列表、字典
6.3 函数与变量作用域
6.3.1 全局部变量与局部变量
局部变量和全局变量是不同变量
- 局部变量是函数内部的占位符,与全局变量可能重名但不同
- 函数运算结束后,局部变量被释放
- 可以使用global保留字在函数内部使用全局变量

-
全局作用域(全局变量)
? 全局作用域在程序执行时创建,在程序执行结束时销毁
? 所有函数以外的区域都是全局作用域
? 在全局作用域中定义的变量,都是全局变量,全局变量可以在程序的任意位置进行访问

结果:
-
函数作用域(局部变量)
? 函数作用域在函数调用时创建,在调用结束时销毁
? 函数每调用一次就会产生一个新的函数作用域
? 在函数作用域中定义的变量,都是局部变量,它只能在函数内部被访问

6.3.2 global关键字
函数内部默认只能读取全局变量的值,如需要修改全局变量,则需要使用global关键字进行声明,否则在函数内修改全局变量会报英文错误。
- 规则1:
-
局部变量和全局变量是不同变量
-
局部变量是函数内部的占位符,与全局变量可能重名但不同
-
函数运算结束后,局部变量被释放
-
可以使用global保留字在函数内部使用全局变量
-
函数使用global保留字声明全局变量

- 规则2:局部变量为组合数据类型且为创建,等同于全局变量

结果:
[‘C’, ‘c’, ‘e’]

结果:
[‘C’, ‘c’]

结果:
[‘e’]
[‘C’, ‘c’]
6.3.3 闭包
闭包是介于全局变量和局部变量之间的一种特殊变量。
j = 5 #全局变量
def sum(): #外部函数
k=2 #闭包变量
def sum1(): #嵌套的内部函数
i=k+j #局部变量
return i
return sum1()
print("调用sum()结果%d"%sum())
结果:

6.3.4 nonlocal关键字
要在sum1函数中修改闭包变量k,则需要事先用nonlocal关键字声明k,才能对它进行修改操作。修改的结果k变成函数sum1的局部变量,不提倡使用该方法传递值和修改值。
6.4 匿名函数
lambda函数返回函数名作为结果
- lambda函数是一种匿名函数,就是没有名字的函数
- 使用lambda保留字定义,函数名就是返回结果
- lambda函数用于定义简单的、能够在一行内表示的函数
格式:lambda[para1,para2,…]:expression
特点:
(1)lambda后面没有跟函数名
(2)[para1,para2,…]参数是可选的,任何类型的,参数往往在后面的expression中体现
(3)expression表达式实现匿名函数功能的过程,并返回操作结果,具有通常函数return的功能
(4)整个匿名函数在一行实现所有定义。
>>> a = lambda x,y:x**y
>>> a(5,4)
625
6.5 递归函数
? 递归是解决问题的一种方式,它的整体思想,是将一个大问题分解为一个个的小问题,直到问题无法分解时,在去解决问题
? 递归式函数有2个条件
? 1. 基线条件 问题可以被分解为最小问题,当满足基线条件时,递归就不执行了
? 2. 递归条件 可以将问题继续分解的条件
#递归函数就是自己引用自己,递归函数就是在函数里自己调用自己
# 无穷递归
def fun():
fun()
fun()
#递归的两个条件
# 1.基线条件:问题可以被分解为最小的问题,当满足基线条件的时候,再去解决问题
# 2.递归条件:将问题继续分解的条件
7. 装饰器
在编程时,为了实现同样的功能,需要更改代码来实现。如果大量的修改代码,不仅增加了工作量,还不方便后期维护,更加不符合ocp规则(o:open 开放对代码的拓展,c :close 关闭对代码的修改),装饰器就是为了解决这写问题被引入的。
def fun(a,b)
print('函数开始')
print('函数结束')
return a+b
def fun1(a,b):
return a*b
'''
如果fun函数要实现fun1函数同样的输出效果,可以直接复制print进行粘贴就行,\
但是这样就出现了代码的冗余、增加工作量等情况,那是否有办法不用复制就直接那过来用呢?
'''
装饰器的使用
- 通过装饰器,可以在不修改原来函数的情况下来对函数进行扩展
- 在开发中,我们都是通过装饰器来扩展函数的功能的
#装饰器是一个特殊的闭包函数
#装饰器
def ch(fn): #定义外层函数
def new_ch(*args,**kwargs): #定义一个内层函数,使用不定长参数进行传参
print('函数开始')
fn(*args,**kwargs) #调用内层函数
print('函数结束')
return new_ch #返回内层函数名
@ch #@ch=ch(fun),装饰器的语法糖写法 ,必须紧贴需要用到装饰器的函数,即@ch必须在def fun():这个函数前
#函数
def fun(): #定义一个函数
print('我是fun函数')
#return '我是fun函数'
#函数调用方法一:通过装饰器的语法糖写法
fun()
#函数调用方法二:
# r = ch(fun) #此处是将函数名fun作为实参传递给fn,即fn = fun ,ch(fn) = new_ch = ch(fun) ,\
# # 内层函数调用ch(fn)() = new_ch() = ch(fun)()
# r()
总结
??本文属于作者原创,转载请注明出处,不足之处,希望大家能过给予宝贵的意见,如有侵权,请私信。每天一个knowledge point,一起学python,让技术无限发散。