����Ŀ¼
��������Դ�롢��������:
����: https://pan.baidu.com/s/10XCx8SKrduFXnkx998fi2Q
��ȡ��:
ugwj
(һ)python���ݿ�ѧ��ѧϰĿ¼
ѧϰpython���ݿ�ѧ��ʼǵ�˳��:
pycharm���ñ���ͼƬ
python���ݿ�ѧ��(һ)
python���ݿ�ѧ��(��)matplotlib
python���ݿ�ѧ��ʼ�(��)Numpy
python���ݿ�ѧ��ʼ�(��)pandas
Python���ز���װ��������(cvxpy)
���importError :numpy.core.multiarrary failed to import
python���ݿ�ѧ��(�� �� һ)���ֵĺϲ������ۺ�(̫��������)
���ݿ�ѧ��(�� �� ��)���ֵĺϲ������ۺ�
���ݿ�ѧ��(�� �� ��)������������
python�Ե����ļ����ݽ���(�鿴������������˼·������)����ϸ����
(��)��ͬ���͵Ľ�������Ĵ���(�Ľ���)
��һƪ���ǽ�����python�Ե����ļ����ݽ���(�鿴������������˼·������)����ϸ����(������python��ѧ��)���Ǵ��뻹����Ը���,�������Ǹ���һ�´�������:
# coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# ͨ��pandas����������ʾ����,Ϊ�˶���ʾһЩ��������
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 1000)
df = pd.read_csv("./911.csv")
print(df.head(5))
#��ȡ����
# print()df["title"].str.split(": ")
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
# ��ʾ��cate_list����һ��df.shape[0]��1�е�DataFrame����,�����ӵ�df������cate��ǩһ����
'''
cate = np.array(cate_list).reshape((df.shape[0],1))
df["cate"] = pd.DataFrame(cate)
'''
# print(df.head(5))
print(df.groupby(by="cate").count()["title"])
# df.groupby()��ϸ��������https://blog.csdn.net/huguozhiengr/article/details/83384160
# ����cate����(cateһ�������ַ���),��ͳ��һ�¸���,ͳ�Ƹ����ǰ���title��ǩ��һ�е�����ͳ�Ƶġ�
OUT:
lat lng desc zip title timeStamp twp addr e
0 40.297876 -75.581294 REINDEER CT & DEAD END; NEW HANOVER; Station ... 19525.0 EMS: BACK PAINS/INJURY 2015-12-10 17:10:52 NEW HANOVER REINDEER CT & DEAD END 1
1 40.258061 -75.264680 BRIAR PATH & WHITEMARSH LN; HATFIELD TOWNSHIP... 19446.0 EMS: DIABETIC EMERGENCY 2015-12-10 17:29:21 HATFIELD TOWNSHIP BRIAR PATH & WHITEMARSH LN 1
2 40.121182 -75.351975 HAWS AVE; NORRISTOWN; 2015-12-10 @ 14:39:21-St... 19401.0 Fire: GAS-ODOR/LEAK 2015-12-10 14:39:21 NORRISTOWN HAWS AVE 1
3 40.116153 -75.343513 AIRY ST & SWEDE ST; NORRISTOWN; Station 308A;... 19401.0 EMS: CARDIAC EMERGENCY 2015-12-10 16:47:36 NORRISTOWN AIRY ST & SWEDE ST 1
4 40.251492 -75.603350 CHERRYWOOD CT & DEAD END; LOWER POTTSGROVE; S... NaN EMS: DIZZINESS 2015-12-10 16:56:52 LOWER POTTSGROVE CHERRYWOOD CT & DEAD END 1
cate
EMS 320326
Fire 96177
Traffic 223395
Name: title, dtype: int64
(��)pandas�е�ʱ������
3.1 ����һ��ʱ�䷶Χ(5������)
pandas.date_range(start=None, end=None, periods=None, freq=��D��, tz=None)
# start��end�Լ�freq����ܹ�����start��end��Χ����Ƶ��freq��һ��ʱ������
# start��periods�Լ�freq����ܹ����ɴ�start��ʼ��Ƶ��Ϊfreq��periods��ʱ������
start:string��datetime-like,Ĭ��ֵ��None,��ʾ���ڵ���㡣
end:string��datetime-like,Ĭ��ֵ��None,��ʾ���ڵ��յ㡣
periods:integer��None,Ĭ��ֵ��None,��ʾ��Ҫ����������������ٸ���������ֵ;�����None�Ļ�,��ôstart��end���벻��ΪNone��
freq:string��DateOffset,Ĭ��ֵ�ǡ�D��,��ʾ����Ȼ��Ϊ��λ,�����������ָ����ʱ��λ,���硯5H����ʾÿ��5��Сʱ����һ�Ρ�
tz:string��None,��ʾʱ��,����:��Asia/Hong_Kong����

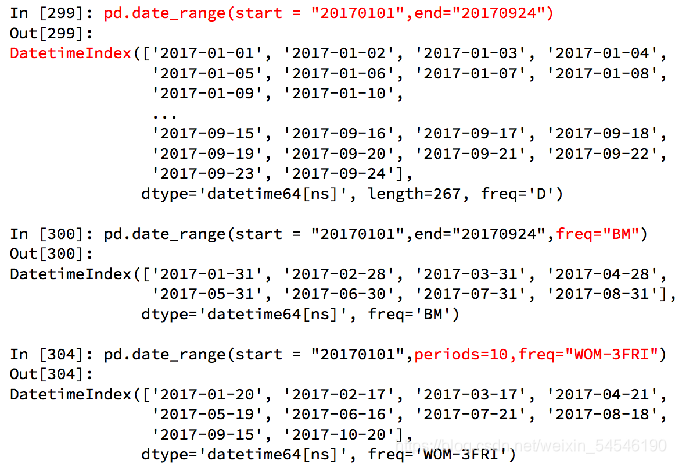
3.1.1date_range(start=��20171230��,end=��20180131��,freq=��D��)
a = pd.date_range(start="20171230",end="20180131",freq="D")
OUT
DatetimeIndex(['2017-12-30', '2017-12-31', '2018-01-01', '2018-01-02',
'2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06',
'2018-01-07', '2018-01-08', '2018-01-09', '2018-01-10',
'2018-01-11', '2018-01-12', '2018-01-13', '2018-01-14',
'2018-01-15', '2018-01-16', '2018-01-17', '2018-01-18',
'2018-01-19', '2018-01-20', '2018-01-21', '2018-01-22',
'2018-01-23', '2018-01-24', '2018-01-25', '2018-01-26',
'2018-01-27', '2018-01-28', '2018-01-29', '2018-01-30',
'2018-01-31'],
dtype='datetime64[ns]', freq='D')
3.1.2date_range(start=��20171230��,end=��20180131��,freq=��10D��)
b = pd.date_range(start="20171230",end="20180131",freq="10D")
OUT
DatetimeIndex(['2017-12-30', '2018-01-09', '2018-01-19', '2018-01-29'], dtype='datetime64[ns]', freq='10D')
3.1.3 date_range(start=��20171230��,periods=10,freq=��D��)
c = pd.date_range(start="20171230",periods=10,freq="D")
OUT
DatetimeIndex(['2017-12-30', '2017-12-31', '2018-01-01', '2018-01-02',
'2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06',
'2018-01-07', '2018-01-08'],
dtype='datetime64[ns]', freq='D')
3.1.4date_range(start=��20171230��,periods=10,freq=��M��)
d = pd.date_range(start="20171230",periods=10,freq="M")
OUT
DatetimeIndex(['2017-12-31', '2018-01-31', '2018-02-28', '2018-03-31',
'2018-04-30', '2018-05-31', '2018-06-30', '2018-07-31',
'2018-08-31', '2018-09-30'],
dtype='datetime64[ns]', freq='M')
3.1.5date_range(start=��20171230��,periods=10,freq=��H��)
e = pd.date_range(start="20171230",periods=10,freq="H")
OUT
DatetimeIndex(['2017-12-30 00:00:00', '2017-12-30 01:00:00',
'2017-12-30 02:00:00', '2017-12-30 03:00:00',
'2017-12-30 04:00:00', '2017-12-30 05:00:00',
'2017-12-30 06:00:00', '2017-12-30 07:00:00',
'2017-12-30 08:00:00', '2017-12-30 09:00:00'],
dtype='datetime64[ns]', freq='H')
3.2 ��DataFrame��ʹ��ʱ������
import pandas as pd
import numpy as np
# ����ʱ������Ϊdataframe��index
index=pd.date_range("20170101",periods=10)
df=pd.DataFrame(np.random.rand(10),index=index)
# ����һ����ʱ������Ϊ������dataframe
# Ϊʲôʱ�����п�����Ϊ������?
# ��Ϊʱ��������pandas����һ��DatetimeIndex����һ������ ����ʱ����������
print(index)
print("# # "*6)
print(df)
OUT
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04',
'2017-01-05', '2017-01-06', '2017-01-07', '2017-01-08',
'2017-01-09', '2017-01-10'],
dtype='datetime64[ns]', freq='D')
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
0
2017-01-01 0.807795
2017-01-02 0.150785
2017-01-03 0.068778
2017-01-04 0.823891
2017-01-05 0.233198
2017-01-06 0.018804
2017-01-07 0.202627
2017-01-08 0.072681
2017-01-09 0.330796
2017-01-10 0.755146
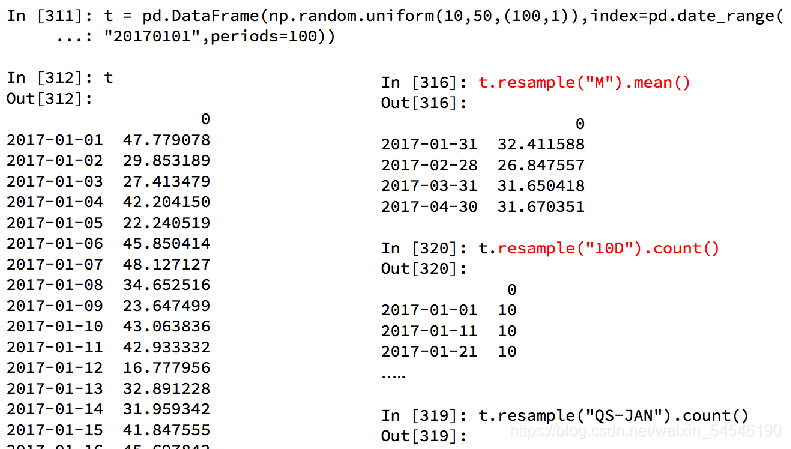
3.3 pandas�ز���
3.3.1 pandas�ز�������
�ز���:ָ���ǽ�ʱ�����д�һ��Ƶ��ת��Ϊ��һ��Ƶ�ʽ��д����Ĺ���,����Ƶ������ת��Ϊ��Ƶ������Ϊ������,��Ƶ��ת��Ϊ��Ƶ��Ϊ������.pandas�ṩ��һ��resample�ķ�������������ʵ��Ƶ��ת��
���pandas.DataFrame.resample����ʱ��ۺϲ���
pandas.DataFrame.resample����
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None,
label=None, convention='start', kind=None, loffset=None,
limit=None, base=0, on=None, level=None)
rule : ��ʾĿ��ת����ƫ���ַ��������,һ����ʱ�����,���硰M��,��A��,��Q��,��BM��,��BA��,��BQ���͡�W��;
axis : int, optional, default 0
closed : {��right��, ��left��};�������һ���ǹرյ�,���ڳ���M��,��A��,��Q��,��BM��,��BA��,��BQ���͡�W��֮�������Ƶ��ƫ��,Ĭ��ֵΪ����,��Ĭ��ֵ��Ϊ���ҡ�
label : {��right��, ��left��};���ڱ��bins,�������һ���ǹرյ�,���ڳ���M��,��A��,��Q��,��BM��,��BA��,��BQ���͡�W��֮�������Ƶ��ƫ��,Ĭ��ֵΪ����,��Ĭ��ֵ��Ϊ���ҡ�
convention : {��start��, ��end��, ��s��, ��e��}:For PeriodIndex only, controls whether to use the start or end of rule
kind: {��timestamp��, ��period��}, optional;Pass ��timestamp�� to convert the resulting index to a DateTimeIndex or ��period�� to convert it to a PeriodIndex. By default the input representation is retained.
loffset : �������²�����ʱ���ǩ
on : ����DataFrame,Ҫʹ�õ��ж����������������²������б���������ʱ�����Ƶ����ݡ�
(��) ͳ�Ƴ�911�����в�ͬ�·ݵ绰�����ı仯���
4.1 pd.to_datetime()
�ص��ʼ��911���ݵİ�����,���ǿ���ʹ��pandas�ṩ�ķ�����ʱ���ַ���ת��Ϊʱ������
df["timeStamp"] = pd.to_datetime(df["timeStamp"],format="")
format����������¿��Բ���д,���Ƕ���pandas����ʽ����ʱ���ַ���,���ǿ���ʹ�øò���,����������ġ�
# coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# ͨ��pandas����������ʾ����
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 1000)
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df.set_index("timeStamp",inplace=True)
print(df)
OUT
lat lng desc zip title twp addr e
timeStamp
2015-12-10 17:10:52 40.297876 -75.581294 REINDEER CT & DEAD END; NEW HANOVER; Station ... 19525.0 EMS: BACK PAINS/INJURY NEW HANOVER REINDEER CT & DEAD END 1
2015-12-10 17:29:21 40.258061 -75.264680 BRIAR PATH & WHITEMARSH LN; HATFIELD TOWNSHIP... 19446.0 EMS: DIABETIC EMERGENCY HATFIELD TOWNSHIP BRIAR PATH & WHITEMARSH LN 1
2015-12-10 14:39:21 40.121182 -75.351975 HAWS AVE; NORRISTOWN; 2015-12-10 @ 14:39:21-St... 19401.0 Fire: GAS-ODOR/LEAK NORRISTOWN HAWS AVE 1
2015-12-10 16:47:36 40.116153 -75.343513 AIRY ST & SWEDE ST; NORRISTOWN; Station 308A;... 19401.0 EMS: CARDIAC EMERGENCY NORRISTOWN AIRY ST & SWEDE ST 1
2015-12-10 16:56:52 40.251492 -75.603350 CHERRYWOOD CT & DEAD END; LOWER POTTSGROVE; S... NaN EMS: DIZZINESS LOWER POTTSGROVE CHERRYWOOD CT & DEAD END 1
... ... ... ... ... ... ... ... ..
2020-05-26 09:17:31 40.087810 -75.304726 SCARLET DR & COLWELL LN; PLYMOUTH; 2020-05-26 ... 19428.0 Fire: GAS-ODOR/LEAK PLYMOUTH SCARLET DR & COLWELL LN 1
2020-05-26 09:30:06 40.058569 -75.126960 COVENTRY AVE & VALLEY RD; CHELTENHAM; Station... 19027.0 EMS: RESPIRATORY EMERGENCY CHELTENHAM COVENTRY AVE & VALLEY RD 1
2020-05-26 09:35:44 40.151622 -75.120972 EASTON RD & ELLIS RD; UPPER MORELAND; 2020-05-... 19090.0 Fire: FIRE ALARM UPPER MORELAND EASTON RD & ELLIS RD 1
2020-05-26 09:40:28 40.175388 -75.108397 HARDING AVE & WILLIAMS LN; HATBORO; Station 3... 19040.0 EMS: UNRESPONSIVE SUBJECT HATBORO HARDING AVE & WILLIAMS LN 1
2020-05-26 09:36:34 40.079811 -75.293981 E 11TH AVE; CONSHOHOCKEN; 2020-05-26 @ 09:36:3... 19428.0 Fire: FIRE INVESTIGATION CONSHOHOCKEN E 11TH AVE 1
4.2 ͳ�Ƴ�911�����в�ͬ�·ݵ绰������
#ͳ�Ƴ�911�����в�ͬ�·ݵ绰������
count_by_month = df.resample("M").count()
# Pandas�е�resample,���²���,�Ƕ�ԭ�������´�����һ������,��һ���Գ���ʱ�������������²�����Ƶ��ת���ı�ݵķ�����M:ָ���²�ͬ���ࡣ
print(count_by_month.head())
OUT
lat lng desc zip title twp addr e
timeStamp
2015-12-31 7916 7916 7916 6902 7916 7911 7916 7916
2016-01-31 13096 13096 13096 11512 13096 13094 13096 13096
2016-02-29 11396 11396 11396 9926 11396 11395 11396 11396
2016-03-31 11059 11059 11059 9754 11059 11052 11059 11059
2016-04-30 11287 11287 11287 9897 11287 11284 11287 11287
4.3 ͳ�Ƴ�911������title��ͬ�·ݵ绰������
#ͳ�Ƴ�911����title�в�ͬ�·ݵ绰������
count_by_month = df.resample("M").count()["title"]
print(count_by_month.head())
OUT:
timeStamp
2015-12-31 7916 # �����������2015��12�����в�ͬ�ճ��ֽ����¼������ĺ͡�
2016-01-31 13096
2016-02-29 11396
2016-03-31 11059
2016-04-30 11287
Freq: M, Name: title, dtype: int64
4.4 ��ͼ
#��ͼ
_x = count_by_month.index
_y = count_by_month.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.show()

������һ������,�����Dz��Dz�ϣ��ͼ��x�ı�ǩ�к���00.00.00,��������ô����ȥ����!(��Datatime������и�ʽ��)
_x = count_by_month.index
_y = count_by_month.values
for i in _x: # �鿴_x�����з���
print(dir(i))
break
OUT
['__add__', '__array_priority__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__pyx_vtable__', '__radd__', '__reduce__', '__reduce_cython__', '__reduce_ex__', '__repr__', '__rsub__', '__setattr__', '__setstate__', '__setstate_cython__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__weakref__', '_date_repr', '_repr_base', '_round', '_short_repr', '_time_repr', 'asm8', 'astimezone', 'ceil', 'combine', 'ctime', 'date', 'day', 'day_name', 'day_of_week', 'day_of_year', 'dayofweek', 'dayofyear', 'days_in_month', 'daysinmonth', 'dst', 'floor', 'fold', 'freq', 'freqstr', 'fromisocalendar', 'fromisoformat', 'fromordinal', 'fromtimestamp', 'hour', 'is_leap_year', 'is_month_end', 'is_month_start', 'is_quarter_end', 'is_quarter_start', 'is_year_end', 'is_year_start', 'isocalendar', 'isoformat', 'isoweekday', 'max', 'microsecond', 'min', 'minute', 'month', 'month_name', 'nanosecond', 'normalize', 'now', 'quarter', 'replace', 'resolution', 'round', 'second', 'strftime', 'strptime', 'time', 'timestamp', 'timetuple', 'timetz', 'to_datetime64', 'to_julian_date', 'to_numpy', 'to_period', 'to_pydatetime', 'today', 'toordinal', 'tz', 'tz_convert', 'tz_localize', 'tzinfo', 'tzname', 'utcfromtimestamp', 'utcnow', 'utcoffset', 'utctimetuple', 'value', 'week', 'weekday', 'weekofyear', 'year']
����Ҫ�õ�������strftime�ķ���
4.5 Python time strftime() ����
Python���õ�strftime( )����:ʵ�ֱ���ʱ��\���ڵĸ�ʽ��(�������ʽ�������ַ�����Ҫ����и�ʽ��)��
��ʽ�� ˵��
%a ���ڵ�Ӣ�ĵ��ʵ���д:������һ, �� Mon
%A ���ڵ�Ӣ�ĵ��ʵ�ȫƴ:������һ,���� Monday
%b �·ݵ�Ӣ�ĵ��ʵ���д:��һ��, �� Jan
%B �·ݵ����ĵ��ʵ���д:��һ��, �� January
%c ����datetime���ַ�����ʾ,��03/08/15 23:01:26
%d ���ص��ǵ�ǰʱ���ǵ�ǰ�µĵڼ���
%f ��ı�ʾ: ��Χ: [0,999999]
%H ��24Сʱ�Ʊ�ʾ��ǰСʱ
%I ��12Сʱ�Ʊ�ʾ��ǰСʱ
%j ���� �����ǵ���ĵڼ��� ��Χ[001,366]
%m �����·� ��Χ[0,12]
%M ���ط����� ��Χ [0,59]
%P ���������绹������CAM or PM
%S �������� ��Χ [0,61]�������ֲ�˵����
%U ���ص����ǵ���ĵڼ��� ������Ϊ��һ��
%W ���ص����ǵ���ĵڼ��� ����һΪ��һ��
%w �����ڵ��ܵ�����,��ΧΪ[0, 6],6��ʾ������
%x ���ڵ��ַ�����ʾ :03/08/15
%X ʱ����ַ�����ʾ :23:22:08
%y �������ֱ�ʾ����� 15
%Y �ĸ����ֱ�ʾ����� 2015
%z ��utcʱ��ļ�� (����DZ���ʱ��,���ؿ��ַ���)
%Z ʱ������(����DZ���ʱ��,���ؿ��ַ���)
#��ͼ
_x = count_by_month.index
_y = count_by_month.values
#for i in _x:
# print(dir(i))
# break
_x = [i.strftime("%Y%m%d") for i in _x]
# %Y%m%d : ��ʾ������
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.show()

(5)ͳ�Ƴ�911�����в�ͬ�·ݲ�ͬ���͵ĵ绰�Ĵ����ı仯���
���ȿ�һ��ע������:df.set_index()һ��д��pd.DataFrame()���档
df.set_index() ʹ�����������õ�(����)����,df.reset_index()��ԭ����.
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
'''
1. keys:label or array-like or list of labels/arrays,�������Ҫ����Ϊ����������,�����ǵ�������,�����Ƕ������
2. drop:bool, default True,ɾ��Ҫ��������������
3. append:bool, default False,����������
4. inplace:bool, default False,�Ƿ�Ҫ�������ݼ�
5. verify_integrity:bool, default False,����������Ƿ��ظ�������,������Ƴٵ���Ҫʱ���С�����ΪFalse�����ƴ˷���������
'''
# coding=utf-8
#911�����в�ͬ�·ݲ�ͬ���͵ĵ绰�Ĵ����ı仯���
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#��ʱ���ַ���תΪʱ����������Ϊ����
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
#������,��ʾ����
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
# print(np.array(cate_list).reshape((df.shape[0],1)))
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1))) # DataFrame��������0,1,2,3,��������
print(df.head())
df.set_index("timeStamp",inplace=True) # ���������911.csv������timeStamp��һ��
# DataFrame����ͨ��set_index����,����ʹ�����������õ�������������
print("$ $ "*20)
print(df.head())
