өЪТ»ХВ:Matplotlib»жНј
КЦ¶Ҝ·ҙЕАіж,ҪыЦ№ЧӘФШ: ФӯІ©өШЦ· https://blog.csdn.net/lys_828/article/details/119253495(CSDNІ©Цч:Be_melting)
ЦӘК¶КбАнІ»ТЧ,ЗлЧрЦШАН¶ҜіЙ№ы,ОДХВҪц·ўІјФЪCSDNНшХҫЙП,ФЪЖдЛыНшХҫҝҙөҪёГІ©ОДҫщКфУЪОҙҫӯЧчХЯКЪИЁөД¶сТвЕАИЎРЕПў
1 MatplotlibёЕДоУл°ІЧ°
Matplotlib НјРОҝЙКУ»Ҝ Python °ь,ЛьМṩБЛТ»ЦЦёЯ¶ИҪ»»ҘКҪҪзГж,ұгУЪҙујТДЬ№»Чціц¶аЦЦУРОьТэБҰөДНіјЖНјұн;Н¬Кұ,ҝЙТФК№УГХвР©№ӨҫЯҙҙҪЁёчЦЦНјРО:°ьАЁјтөҘөДЙўөгНјЎўХэПТЗъПЯ,ЙхЦБКЗИэО¬НјРО;
ФЪ Python ҝЖС§јЖЛгЙзЗш,ҫӯіЈК№УГЛьНкіЙКэҫЭҝЙКУ»ҜөД№ӨЧч;ФЪҪУПВАҙөДКбАн,С§П°Т»ПВХвёцҝвөДЙсЖж№ҰДЬ!
Из№ыК№УГөДКЗAnaconda»·ҫі,ФЪПВФШИнјюНкұПәу,MatplotlibДЈҝйТІҫНЧФ¶Ҝ°ІЧ°ФЪ»·ҫіЦРБЛ,Из№ыКЗұҫөШ»·ҫі,ҫНРиТӘҙтҝӘГьБоРРҪшРР°ІЧ°,ІЩЧчИзПВ
2 MatplotlibК№УГ
2.1 »жЦЖХЫПЯНј
әЛРДҙъВл:plt.plot()
2.1.1 ЧојтөҘөДНјРО
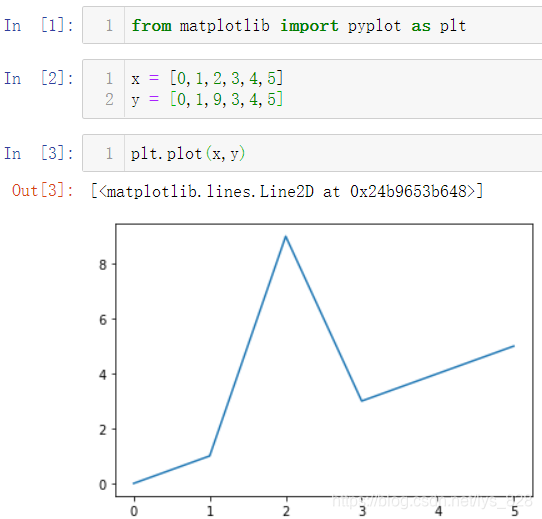
ЧојтөҘөДХЫПЯНј,Ц»ёш¶ЁxәНyөДКэҫЭ,ҪшРРНјРО»жЦЖ
from matplotlib import pyplot as plt
x = [0,1,2,3,4,5]
y = [0,1,9,3,4,5]
plt.plot(x,y)
КдіцҪб№ыИзПВ:(Г»УРИОәОНјұнРЮКОФӘЛШ,ҪцёщҫЭКэҫЭіцНј)
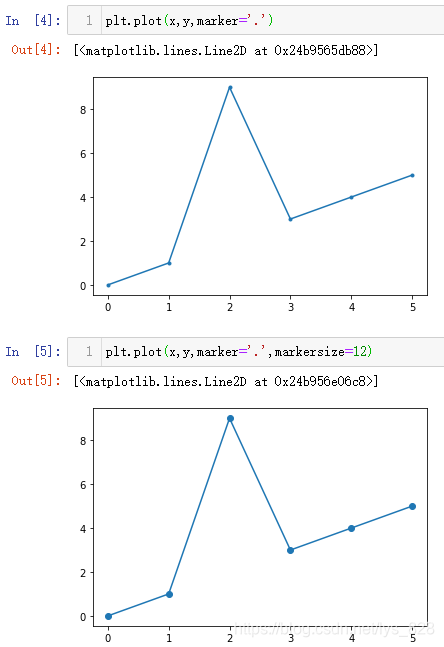
2.1.2 МнјУНјРОұкјЗ
әЛРДІОКэ:marker/markersize
ХвБҪёцІОКэ·ЦұрҝШЦЖұкјЗУРОЮ(СщКҪ)әНҙуРЎіЯҙз
#ҝШЦЖұкјЗТФ.ПФКҫ
plt.plot(x,y,marker='.')
#ҝШЦЖұкјЗ.өДПФКҫҙуРЎОӘ12
plt.plot(x,y,marker='.',markersize=12)
КдіцҪб№ыИзПВ:(markersizeІОКэК№УГКЗФЪУРmarkerІОКэөДЗ°МбПВ)
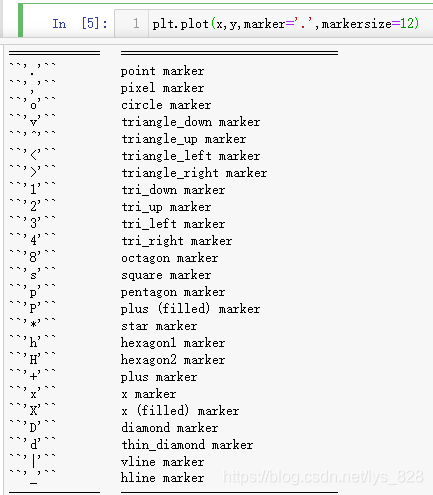
№ШУЪmarkerұкјЗөДСщКҪ,ҝЙТФЦұҪУөчіцІОҝјОДөөҪшРРІйФД,КдіцҪб№ыИзПВ
ұИИзИОТвМфАпГжЖдЦРөДТ»ёцҪшРР»жЦЖ,КдіцҪб№ыИзПВЎЈіэБЛИэҪЗРОЦ®Нв,АпГжөДЖдЛьІОКэҝЙТФёщҫЭЧФјәөДРиЗуҪшРРЙиЦГ
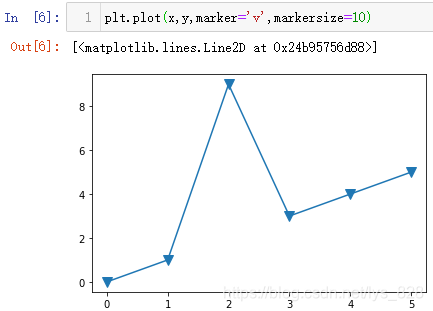
2.1.3 ЙиЦГНјРОСХЙ«
әЛРДІОКэ:color
plt.plot(x,y,marker='v',markersize=10,color='g')
КдіцҪб№ыИзПВ:(НјПЯәНұкјЗ¶јҪшРРБЛСХЙ«өДёДұд)
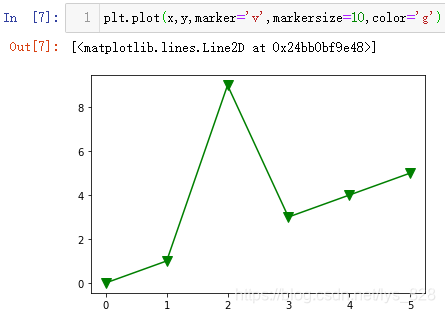
ІйҝҙЛөГчОДөө,ҝҙТ»ПВcolorІОКэҝЙТФЦё¶ЁДДР©СХЙ«,КдіцИзПВ
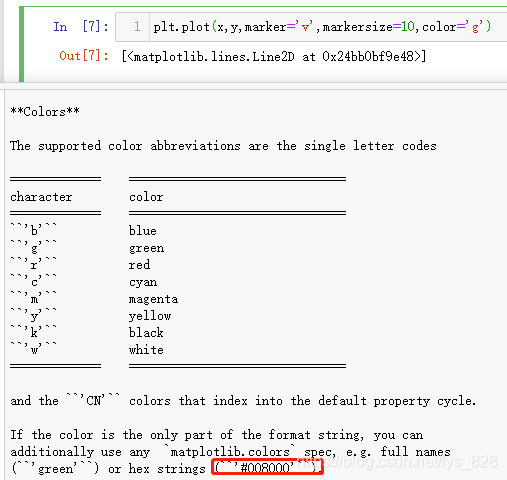
ҝЙТФ·ўПЦёГІОКэјИҝЙТФК№УГіЈјыСХЙ«өДИ«Жҙ,ТІҝЙТФК№УГјтРҙ,ЧоЦШТӘөДТ»ёцМбРСҫНКЗЙПГжНјЖ¬ЙПәмҝтөДІҝ·Ц,ҝЙТФНЁ№эЦё¶ЁИэФӯЙ«өД·ҪКҪҪшРРЧФ¶ЁТеЎЈ
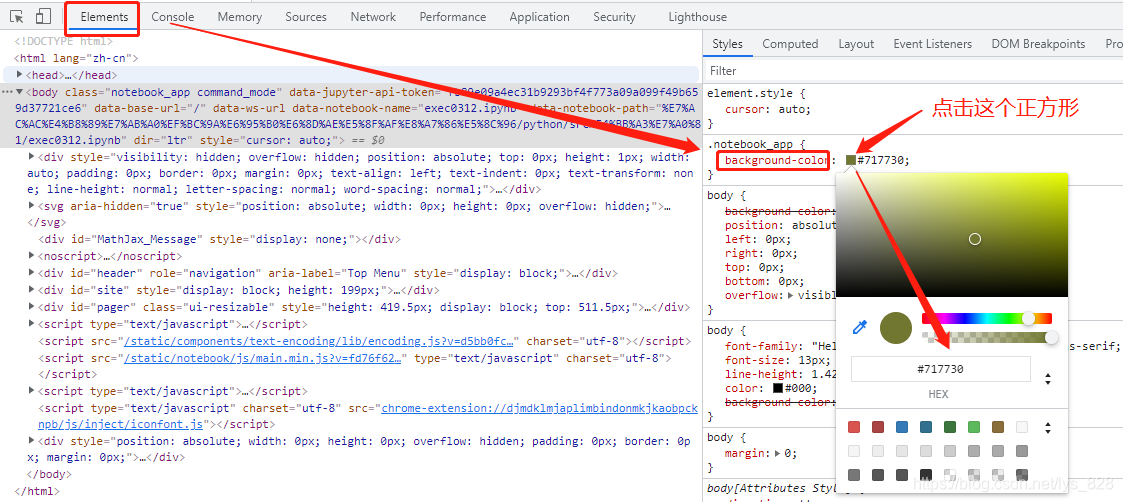
№ШУЪИэ·ҪЙ«ІйХТҝЙТФЦұҪУ°Щ¶ИЛСЛчТ»ПВ,ХТөҪТ»Р©өчЙ«°е,ТІҝЙТФЦұҪУФЪНшТіЙП°ҙЧЎF12јьөчіцөчКФҪзГж,И»әуАпГжөДИОәОТ»ёц°ьә¬colorІОКэІҝ·Цөг»чТ»ПВҫН»біцПЦөчЙ«°е,ІЩЧчИзПВ
ұИИзҫНСЎУГЙПГжЦё¶ЁөДСХЙ«ҪшРР»жЦЖ(ХвСщҫНДЬЧФ¶ЁТеЦё¶ЁИОәОПлТӘөДСХЙ«)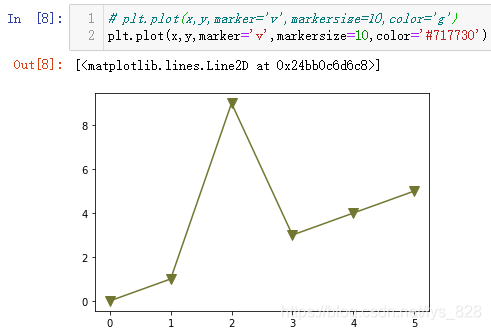
2.1.3 ЙиЦГНјПЯҝн¶И
әЛРДІОКэ:linewidth/lw
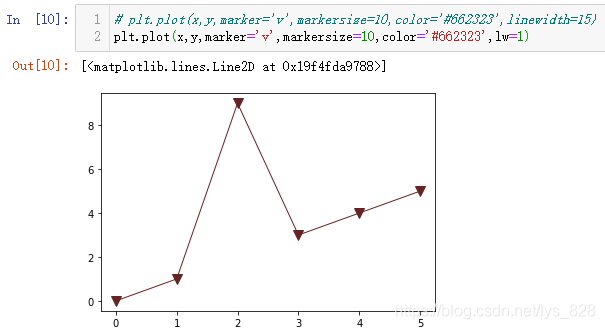
ХвёцІОКэҝЙТФК№УГИ«ЖҙТІҝЙТФК№УГјтРҙ,ЙПГжСХЙ«ІОКэТІҝЙТФИ«ЖҙәНјтРҙ,ИзПВ
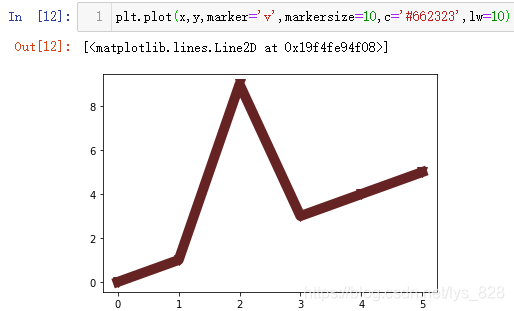
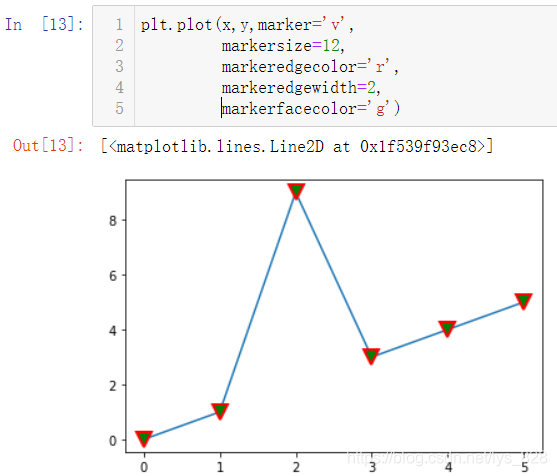
2.1.4 өҘ¶АЙиЦГНјРОәНұкјЗСХЙ«
УРР©КұәтРиТӘҪшРРНјПЯСХЙ«әНұкјЗСХЙ«өДөҘ¶АЙиЦГ,ҫНРиТӘУГЙПБнНвјёёцІОКэ,markeredgecolor(ұкјЗұЯФөСХЙ«)Ўўmarkeredgewidth(ұкјЗұЯФөҝн¶И)Ўўmarkerfacecolor(ұкјЗМоідСХЙ«)
2.1.5 ПФКҫұкМв
әЛРДҙъВл:
- ПФКҫxЦбұкМв:
plt.xlabel() - ПФКҫyЦбұкМв:
plt.ylabel() - ПФКҫНјПсұкМв:
plt.title() - ЙиЦГЦРОДЧЦМеПФКҫ:
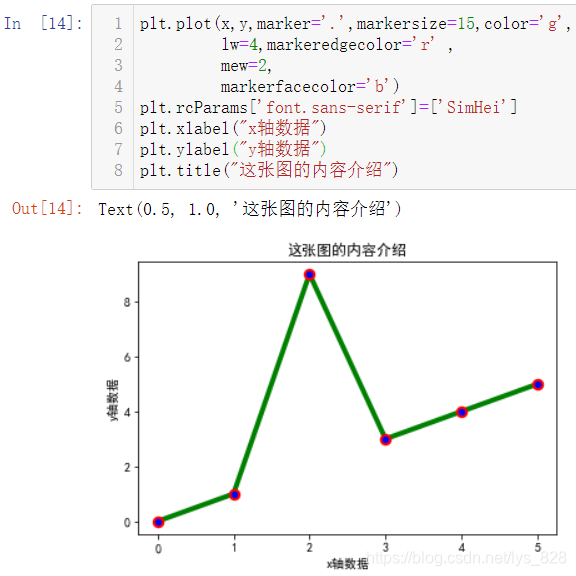
plt.rcParams['font.sans-serif']=['SimHei']
plt.plot(x,y,marker='.',markersize=15,color='g',
lw=4,markeredgecolor='r' ,
mew=2,
markerfacecolor='b')
plt.rcParams['font.sans-serif']=['SimHei']
plt.xlabel("xЦбКэҫЭ")
plt.ylabel("yЦбКэҫЭ")
plt.title("ХвХЕНјөДДЪИЭҪйЙЬ")
КдіцҪб№ыИзПВ:
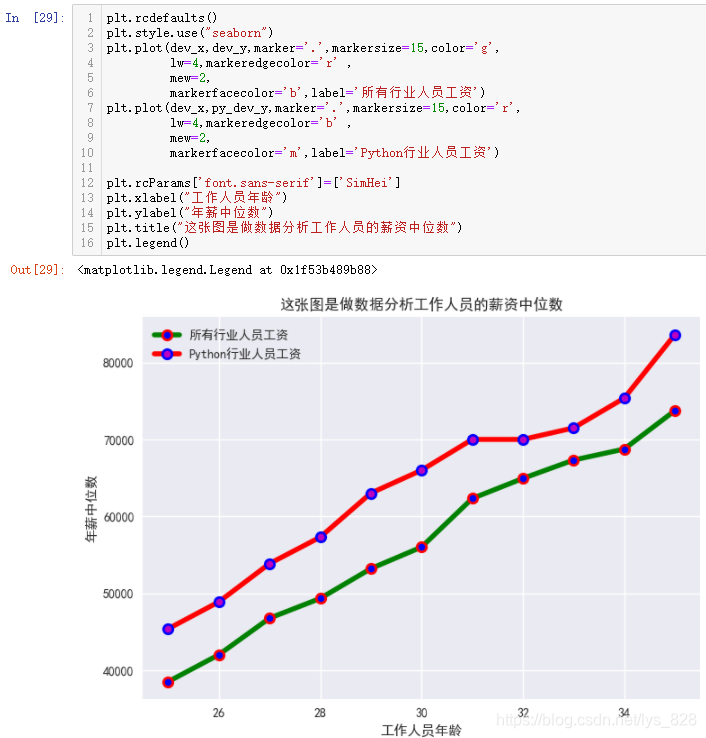
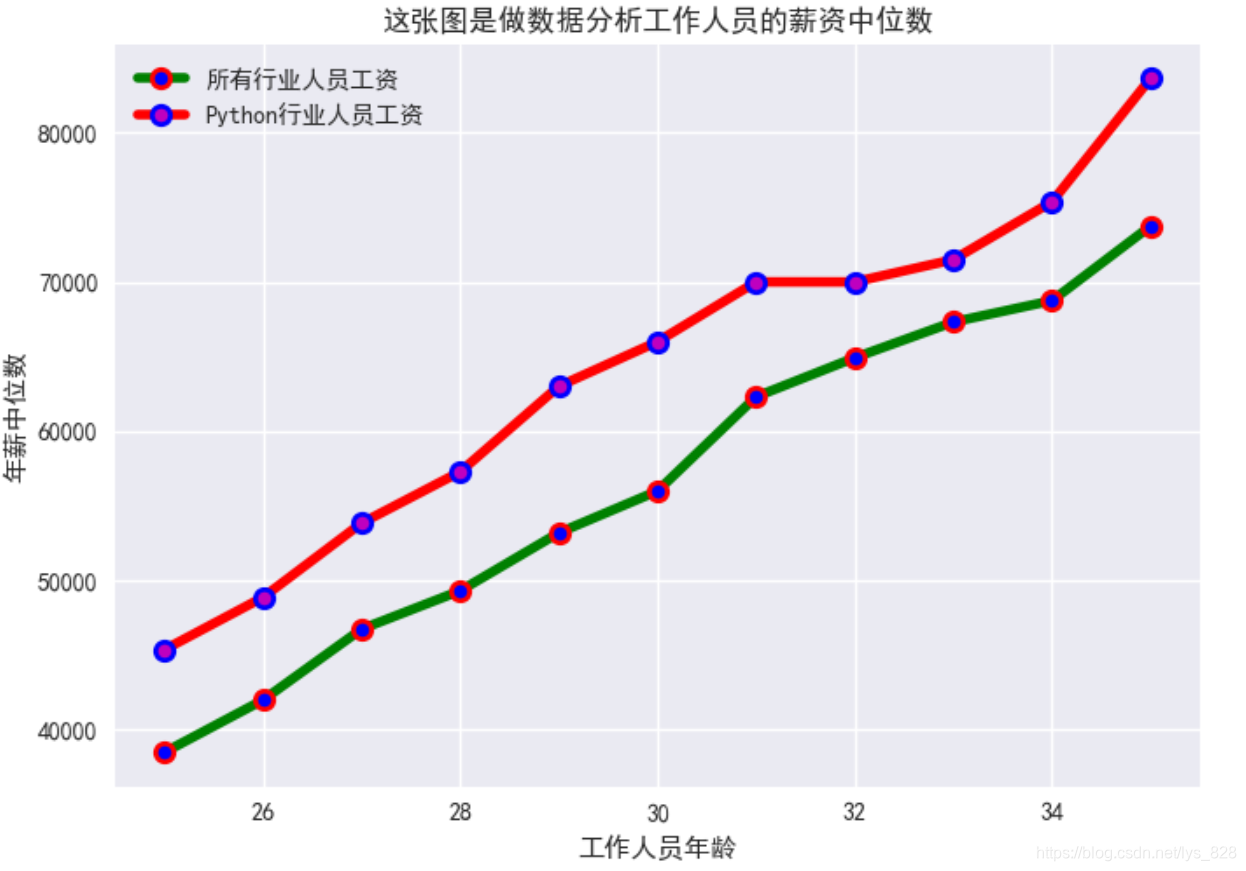
2.1.6 Н¬xЦб¶аХЫПЯНј
ҫНКЗК№УГН¬Т»ёцxЦб,И»әуёщҫЭЦё¶ЁөД¶а·ЭКэҫЭҪшРР»жЦЖ¶аёцyЦө,ІвКФКэҫЭәНЦҙРРҙъВлИзПВ
#xКэҫЭ
dev_x = [25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35]
#y1КэҫЭ
dev_y = [38496, 42000, 46752, 49320, 53200,
56000, 62316, 64928, 67317, 68748, 73752]
#y2КэҫЭ
py_dev_y = [45372, 48876, 53850, 57287, 63016,
65998, 70003, 70000, 71496, 75370, 83640]
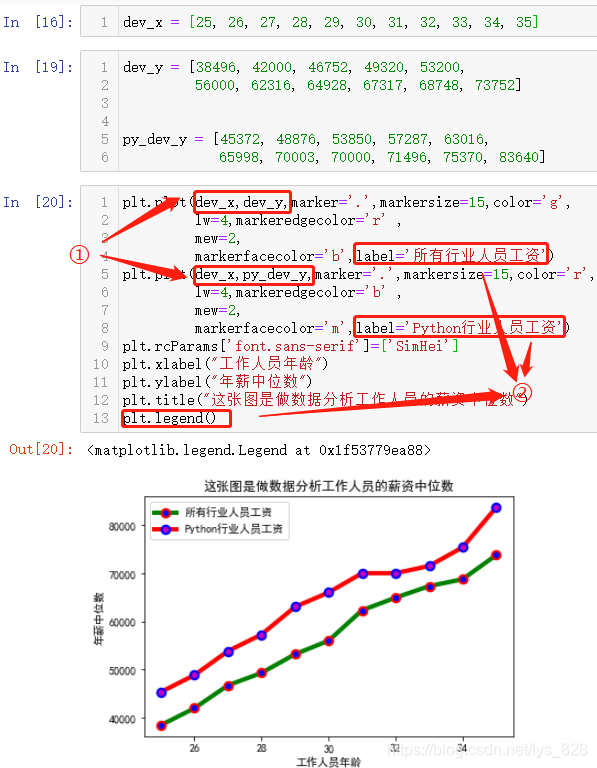
plt.plot(dev_x,dev_y,marker='.',markersize=15,color='g',
lw=4,markeredgecolor='r' ,
mew=2,
markerfacecolor='b',label='ЛщУРРРТөИЛФұ№ӨЧК')
plt.plot(dev_x,py_dev_y,marker='.',markersize=15,color='r',
lw=4,markeredgecolor='b' ,
mew=2,
markerfacecolor='m',label='PythonРРТөИЛФұ№ӨЧК')
plt.rcParams['font.sans-serif']=['SimHei']
plt.xlabel("№ӨЧчИЛФұДкБд")
plt.ylabel("ДкРҪЦРО»Кэ")
plt.title("ХвХЕНјКЗЧцКэҫЭ·ЦОц№ӨЧчИЛФұөДРҪЧКЦРО»Кэ")
plt.legend()
КдіцҪб№ыИзПВ:(ЧўТвўЩІҝ·ЦҫНКЗПФКҫН¬Цб¶аХЫПЯ»жЦЖ,ҫНКЗХл¶ФН¬Т»ёцxКэҫЭ,ёш¶ЁyІ»Н¬,И»әуўЪІҝ·Ц,ҫНКЗ»жЦЖіцөД¶аёцНјРОТӘҪшРР·Цұж, ХвКұәтҝЙТФНЁ№эёшГҝёцНјРОЦё¶Ёlabel,ЧоәуРиТӘЕдәПplt.legend(),ұкЗ©ҫНПФКҫіцАҙБЛ)
2.1.7 НјРО·зёс
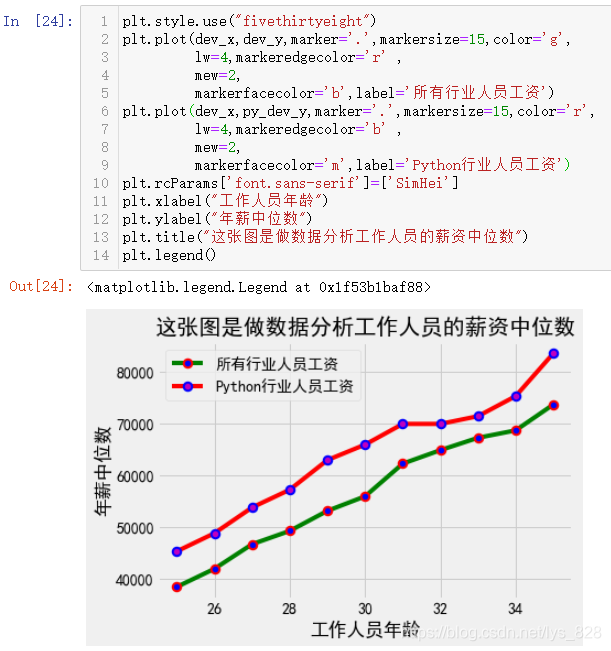
ЙПГжөДНјРО¶јКЗК№УГҝХ°ЧөД»ӯІјҪшРР»жЦЖ,ЖдКөТІҝЙТФЦұҪУјУФШФӨЙи»ӯІјәН·зёсАаРН,ҫЯМеҝЙТФК№УГөД·зёсСщКҪҝЙТФНЁ№эplt.style.availableІйҝҙ,Т»№ІУР26ҝоСщКҪ,КдіцИзПВ

ұИИзЛжұгЦё¶ЁТ»ёцСщКҪ,ҫЯМеөДҙъВлЦёБоОӘ:plt.style.use("fivethirtyeight"),·ЕЦГФЪ»жЦЖНјРОөДЧоҝӘКјөДөЪТ»РР
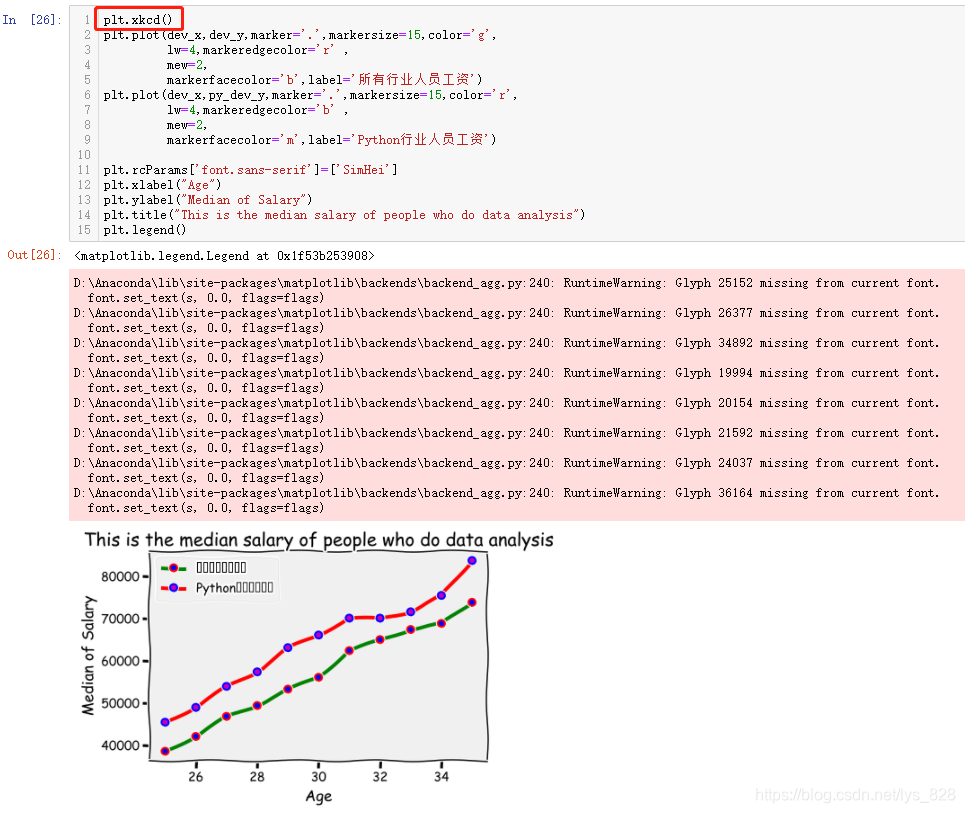
¶ФУЪДЪЦГөД·зёсҝЙТФёщҫЭЧФјәөДРиЗуҪшРРЗР»»,ҙЛНв»№УРТ»ЦЦQ°жҝЁНЁөД»жНј·зёсКЗЦұҪУ·вЧ°ОӘәҜКэ,ЦҙРРҙъВлОӘ:plt.xkcd(),КдіцҪб№ыИзПВ(ХвЦЦ·зёсРиТӘіцПЦөДЧЦ¶јОӘУўОД,ЦРОД»біцПЦХТІ»өҪ¶ФУҰЧЦМеөДМбРС)
»№РиТӘЧўТвөҪТ»өгҫНКЗФЪН¬Т»ёцnotebookЦРЦҙРРКұәт,өұЦё¶ЁТ»ёцЦчМвәу,әуГжөДЛщУР»жНјСщКҪ¶ј»бКЗН¬Т»ёцЦчМв,Из№ыІ»РиТӘХвёцЦчМв,ЦШРВЙиЦГЦчМв,ҝЙТФК№УГЦҙРРҙъВл:plt.rcdefaults(),ТІКЗФЪ»жНјҙъВлөДөЪТ»РРМнјУ,КдіцҪб№ыИзПВ
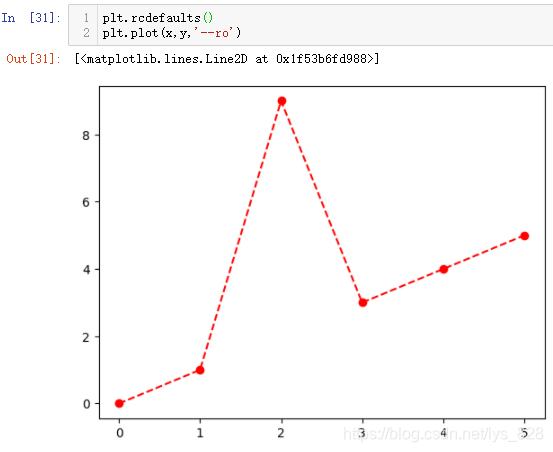
2.1.8 ёсКҪ»ҜСщКҪ
іэБЛЗ°ГжөДҫЯМеІОКэөДЙиЦГТФј°ФӨЦГөДёчЦЦ·зёсСщКҪ,matplotlibЦР»№УРТ»ёцfmtёсКҪ»ҜСщКҪ,ПИёшіцТ»ёцјтөҘөДКҫАэИзПВ
ҫЯМеК№УГ·ҪКҪҫНКЗөЪИэёцІОКэҪшРРО»ЦГҙ«ІО,ПкПёөДК№УГ·ҪКҪҝЙТФІОХХТ»ПВЛөГчОДөө,ИзПВ(ҝЙТФЦё¶ЁұкјЗЎўПЯөДСщКҪәНСХЙ«)
ХвЦЦ·ҪКҪҝЙТФјтөҘҝмҪЭіцНј,Из№ыКЗТӘҪшРРНјұнПкПё»ҜөДЙиЦГ,ұИИзҙЦПё,ёчЧйСщКҪөДЙиЦГөИ,»№КЗТӘК№УГөҪҫЯМеөДІОКэёіЦө,ТтҙЛЙПГжЧЬ№ІУРИэЦЦ№ШУЪСщКҪЙиЦГөД·ҪКҪ,ёщҫЭКөјКРиЗуҪшРРСЎФсјҙҝЙ
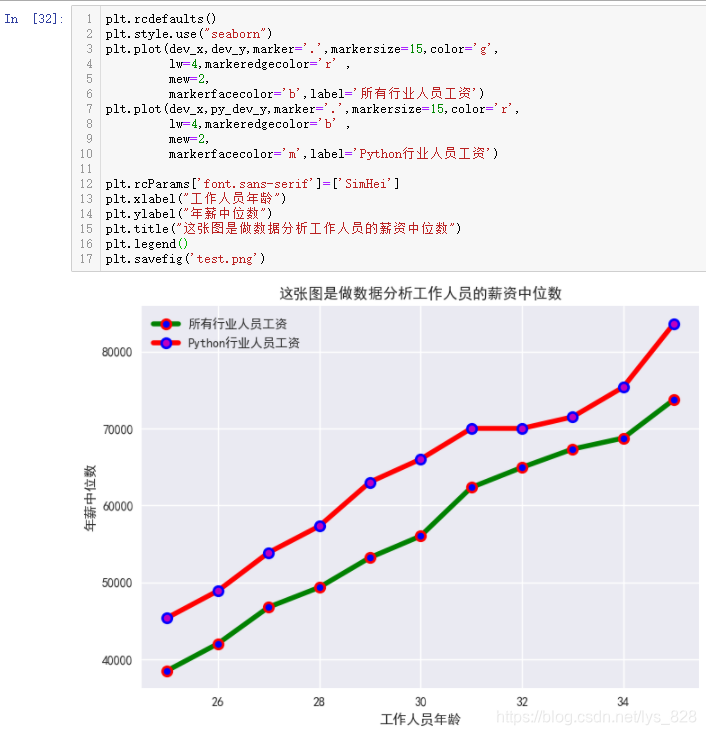
2.1.9 ұЈҙжНјЖ¬
әЛРДҙъВл:plt.savefig()
ХвёцҙъВлРиТӘ·ЕЦГФЪ»жНјЗшөДЧоәуТ»РРЦР,КдіцИзПВ
ҙЛНвУРТ»ёцәЬЦШТӘөДІОКэҫНКЗdpi,Из№ыЦұҪУД¬ИПКдіц,ЧоЦХөДНјЖ¬өД·ЦұжВКәЬәЬІо,·Еҙуәу»бҝҙөДІ»КЗәЬЗеію,»№УРіцПЦДЈәэөДПЦПу,НЁ№эЦё¶Ёdpi,ҫНҝЙТФК№өГНјЖ¬өД·ЦұжВКМбЙэ,ұИИзВЫОДЦРіЈјыөДТӘЗуdpi=600,ПВГжҫН¶ФұИД¬ИПКдіцөДНјРОәНЦё¶Ёdpi=600әуөДНјПсФЪН¬Т»ұИАэПВөДҪб№ы
Д¬ИПөДКдіц:
dpi=600өДКдіцҪб№ы:(БҪХЯөДҪб№ыФЪЙъіЙНкұПәуЧФјәҙтҝӘәуҫН»бУРГчПФёРҫхөҪЗеОъУлДЈәэөД¶ФұИ)
2.2 »жЦЖЦщЧҙНј
ХвАпІ»¶ФМхЧҙНјәНЦщЧҙНјҪшРРПё·Ц,Д¬ИПХвёцБҪёцНјРОҫНКЗТ»ёцАаРНөДНјПсЎЈМхРОНј:МхРОНјУГіӨМхРОұнКҫГҝТ»ёцАаұр(АаұрКэҫЭ),іӨМхРОөДіӨ¶ИұнКҫАаұрөДЖөКэ,ҝн¶ИұнКҫАаұр
әЛРДҙъВл:plt.bar()/plt.barh()
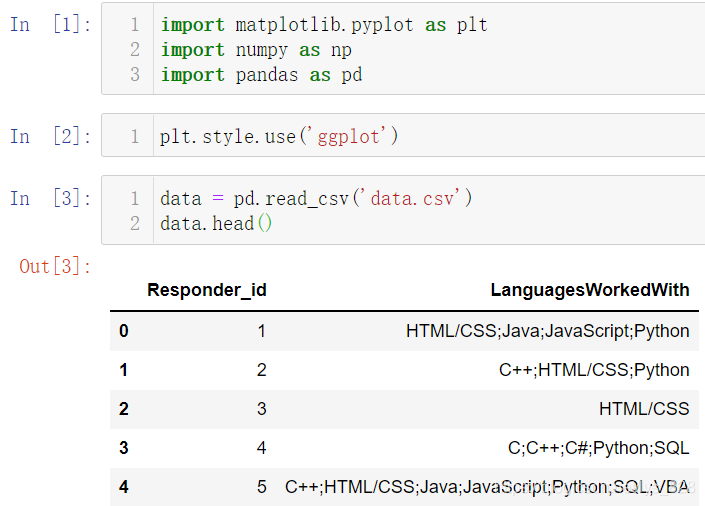
2.2.1 ҙҰАн»жНјКэҫЭ
јЩ¶ЁІвКФКэҫЭКЗGithubЙПГжөДПоДҝІЦҝвЦРГҝёцПоДҝЛщК№УГөҪөДұаіМУпСФ,¶БИЎөДКэҫЭДЪИЭИзПВ(өЪТ»БРҫНКЗ¶ФУҰөДПоДҝұаәЕ,өЪ¶юБРҫНКЗПоДҝЦРК№УГөҪөДУпСФ,К№УГggplotөД»жНј·зёс)
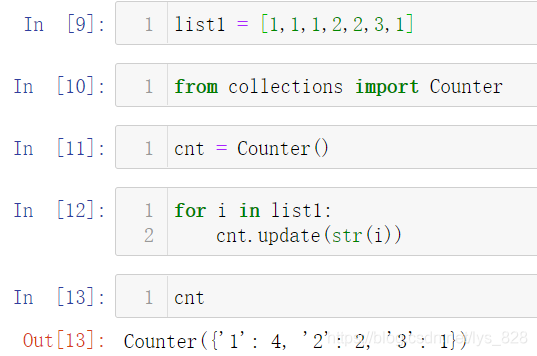
И»әуОТГЗөДДҝөДҫНКЗ¶ФөЪ¶юБРЦРөДұаіМУпСФҪшРРјЖКэ,Іў»жЦЖМхРОНј,№ККЧПИТӘҪвҫцөДОКМвҫНКЗ¶ФұаіМУпСФХвТ»БРҪшРРјЖКэ,јЖКэЦ®З°ҪшРРТ»ёцјтөҘөДІвКФКҫАэ,·ҪұгёьәГөДАнҪв
list1 = [1,1,1,2,2,3,1]
#өјИлјЖКэЖчәҜКэ
from collections import Counter
#МнјУјЖКэЖч
cnt = Counter()
#ұйАъСӯ»·ГҝТ»ёцКэҫЭ
for i in list1:
#ёьРВјЖКэЖч
cnt.update(str(i))
КдіцҪб№ыОӘ:(јЖКэөДІЩЧч№І·ЦОӘЛДІҪ,јыЙПГжөДҙъВлҪвОц,ЧоәуЙъіЙөДКэҫЭ,ҫНКЗКдіцГҝТ»ёцФӘЛШТФј°¶ФУҰөДјЖКэҪб№ы)
ДЗГҙҫНҝЙТФЦұҪУКЗҪ«ҙЛ·Ҫ·ЁУҰУГөҪөЪ¶юБРјЖКэЦР,РиТӘЧўТвCounterУҰёГЦШЦГјЖКэ(ТІҫНКЗЦШРВҪшРРёіЦө)
cnt = Counter()
lang = data.LanguagesWorkedWith
for i in lang[:]:
# print (i.split(';'))
cnt.update(i.split(';'))
cnt
КдіцҪб№ыОӘ:(Ц»ҪШИЎІҝ·ЦКдіцҪб№ы)
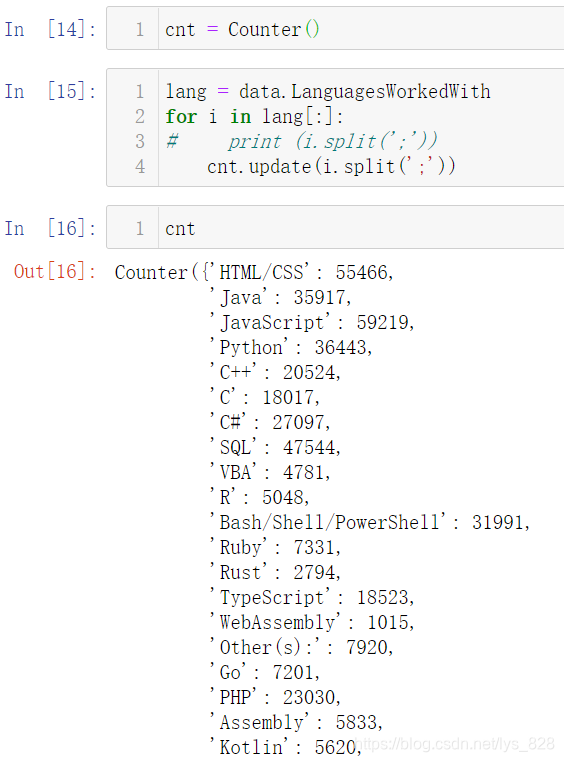
ҪУЧЕҫНКЗ»сИЎјЖКэҪб№ыЦРөДјьәН¶ФУҰөДЦө·ЦұрЧйіЙxәН¶ФУҰөДy,CounterЦРУРТ»ёцәҜКэҝЙТФ»сөГЗ°К®ГыөДјЖКэДЪИЭ:most_common(10),АЁәЕЦРөДКэЦөҝЙТФЧФРРЦё¶Ё
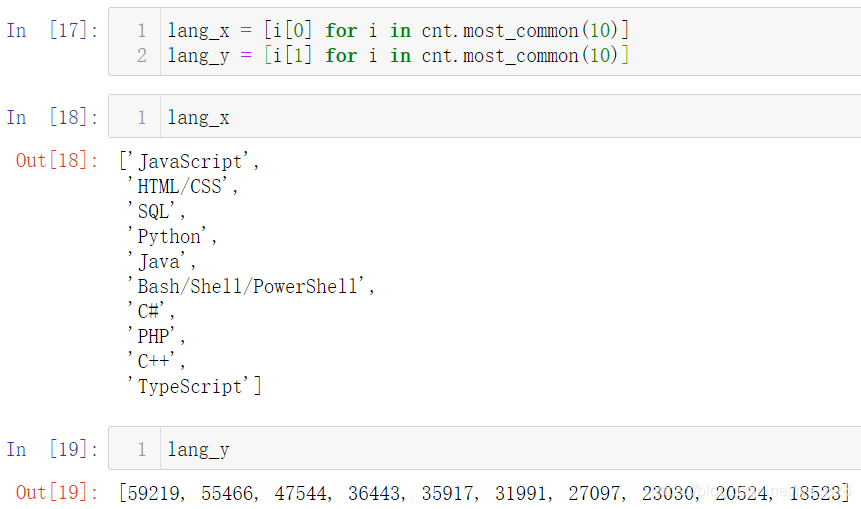
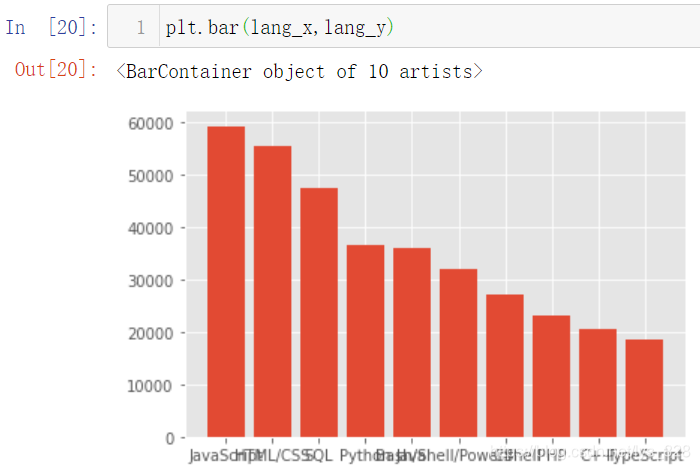
ЦБҙЛ»жЦЖНјРОРиТӘөДxәНyөДКэҫЭҫНЧјұёНкұП,»жНјИзПВ
2.2.2 ҙҰАнxЦбұкЗ©№эГЬОКМв
Хл¶ФЙПГжөДКдіцҪб№ы,ПФИ»ЧоЦХxЦбөДұкЗ©РЕПў№эУЪГЬјҜ,ПФКҫР§№ыІ»јС,ХвКұәтУРИэЦЦҪвҫц·ҪКҪ,өЪТ»ЦЦКЗұИҪПіЈјыөД·ҪКҪ:ҪшРР»ӯІјөчҙу;өЪ¶юЦЦ·ҪКҪ:ҪшРРxyЦбҪ»»»;өЪ¶юЦЦҫНКЗ¶ФxЦбұкЗ©РЕПўҪшРРРэЧӘ
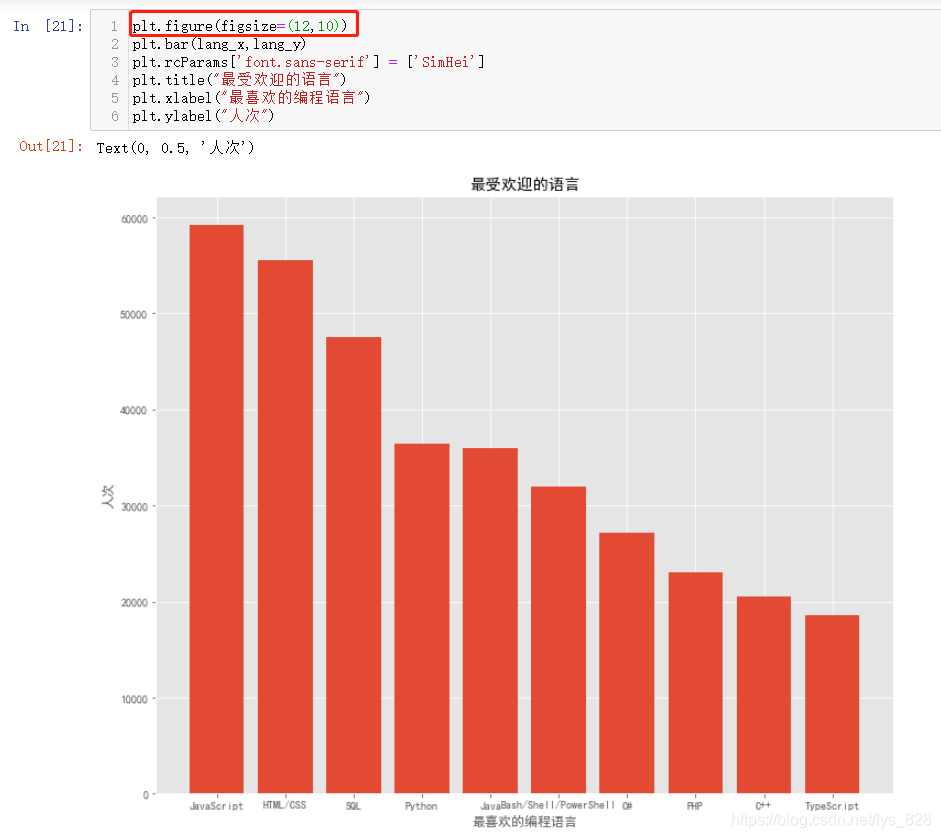
(1)өЪТ»ЦЦ·ҪКҪ
әЛРДҙъВл:plt.figure(figsize=(12,10)),АЁәЕЦРБҪёцІОКэҙъұнНјұнөДіӨәНҝн
(2)өЪ¶юЦЦ·ҪКҪ
әЛРДҙъВл:plt.barh(lang_x,lang_y),ЧўТвХвАпКЗbarh,ЙПГжКЗbarЎЈ·Ҫ·ЁТ»ҝЙТФҝҙіцУРКұәтКЗҝЙТФҪвҫцұкЗ©РЕПў№эГЬөДЗйҝц,ө«КЗХвАпЦРјдУРТ»ёцұкЗ©РЕПў,јҙұгКЗА©ҙуБЛ»ӯІј»№КЗ»бҙжФЪХЪөІөДПЦПу,ЛщТФҝЙТФіўКФТ»ПВөЪ¶юЦЦ·ҪКҪ,КдіцҪб№ыИзПВ(ҙЛКұЧоіӨөДДЗёцұкЗ©РЕПўҫНІ»»бұ»ХЫөюБЛ)
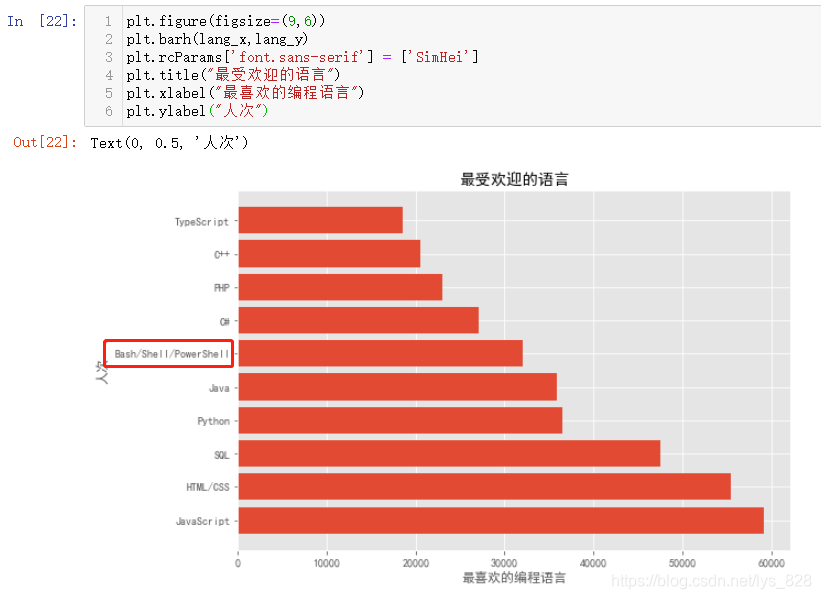
ЙПГжөДНјЖ¬Из№ыҪшРР·ҙПтөДЕЕРтЦұҪУ¶ФxәНyЗу·ҙРтҫНҝЙТФБЛ,ТтОӘКЗБРұнКэҫЭ,ёГКэҫЭАаРНУРёцreverse()әҜКэ,ҫНҝЙТФКөПЦ,ЧоЦХКдіцөДҪб№ыИзПВ(Ліҙш°СЗ°ГжГ»УРРЮёДөДxәНyұкМвХыёД№эАҙ)
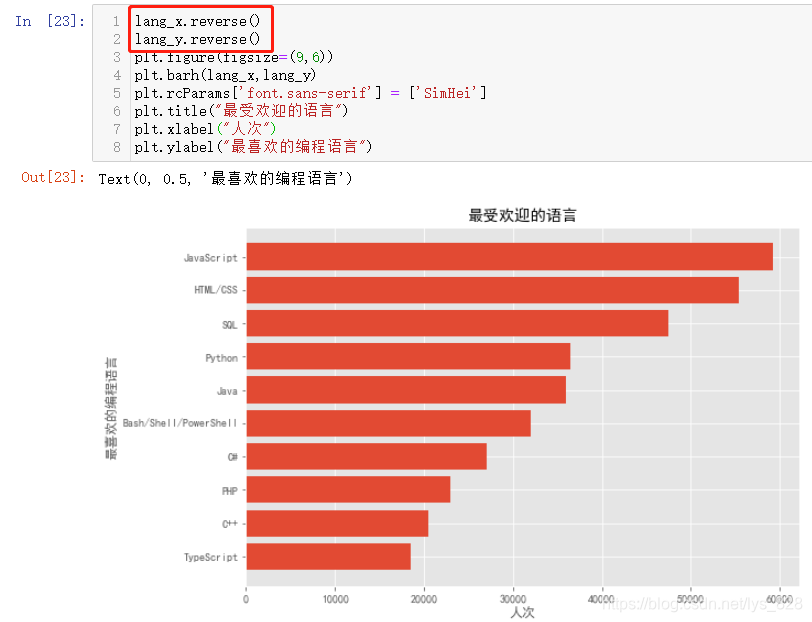
(3)өЪИэЦЦ·ҪКҪ
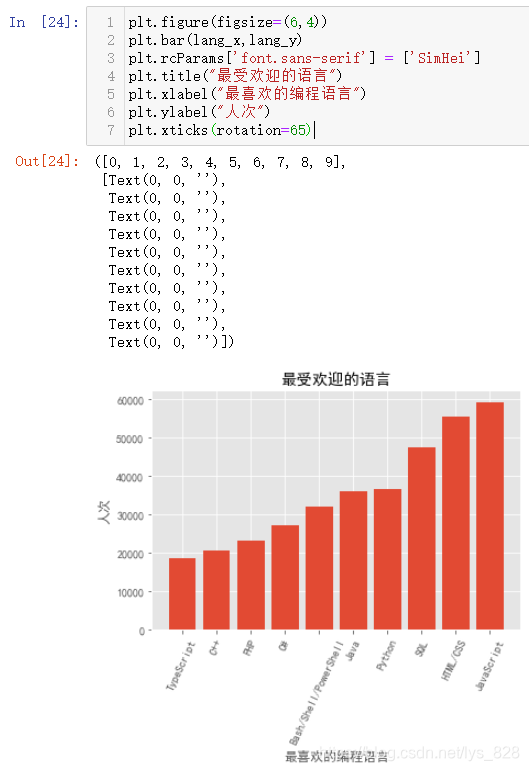
әЛРДҙъВл:plt.xticks(rotation=65)
Из№ыТ»¶ЁТӘјб¶ЁК№УГЧЭПтМхЧҙНј,ҫНҝЙТФІЙУГРэЧӘxЦбұкЗ©РЕПўөД·ҪКҪНкіЙ
2.2.3 »жЦЖЧЭПт¶СөюНј
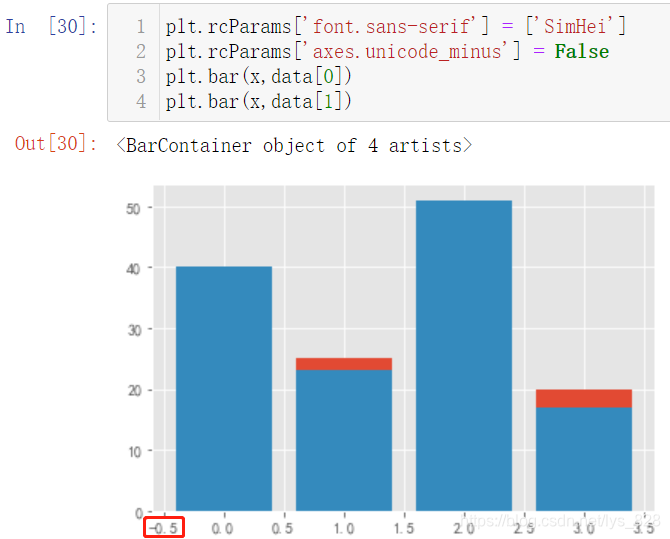
Из№ыЦұҪУәН»жЦЖХЫПЯНјТ»Сщ,Ҫ«БҪёцМхРОНј»жЦЖФЪТ»ёцНјЦРҝҙТ»ПВКдіцҪб№ы(БҪёцНјРОЦұҪУҪшРРЦШөюБЛ,ө«ІўІ»КЗ¶Сөю,Г»УРҙпөҪОТГЗПлТӘөДҪб№ы,¶шЗТ·ўПЦ·ыёәәЕГ»УР°м·ЁХэіЈПФКҫ)
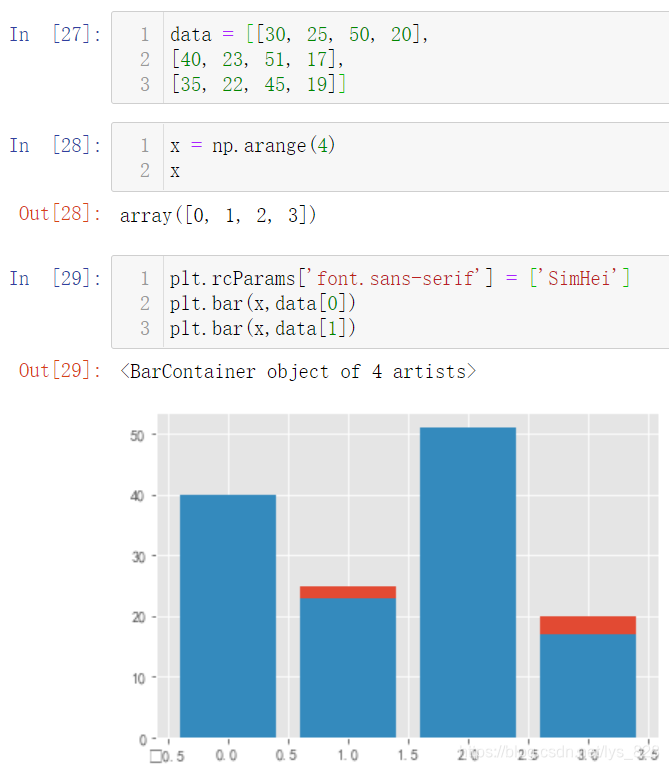
КЧПИҪвҫцёәәЕөДОКМв:plt.rcParams['axes.unicode_minus'] = False,ҙЛНвТІҝЙТФі№өЧҪвҫц№ШУЪЦРОДұаВләН·ыәЕПФКҫөДОКМв,ҝЙТФІОҝјХвёцКбАн:MatplotlibҝвФЛРРЗ°ПөНіІОКэЙиЦГ(ЦРОДј°ёәәЕІ»ПФКҫЎўНшёсПЯј°НёГч¶ИЎўҝМ¶ИПФКҫ)
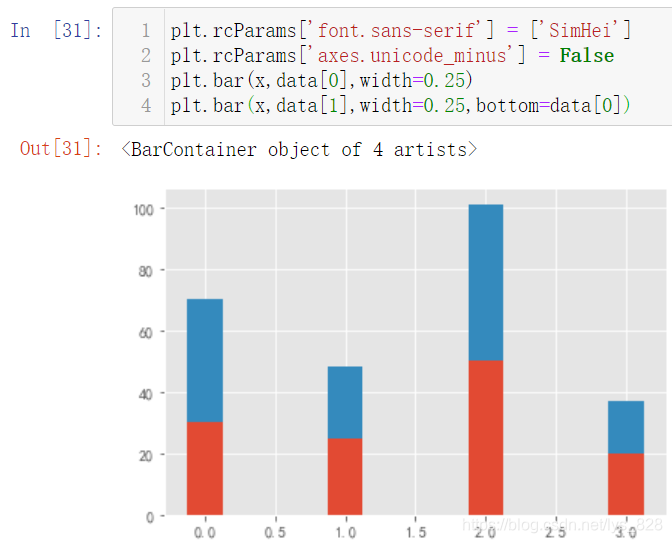
ЖдҙОҪвҫцЦШөюөДОКМв,ЖдКөҫНКЗТӘЗуөЪ¶юёц»жЦЖөДНјРОКЗ»щУЪөЪТ»ёцНјРО»щҙЎЦ®ЙП,әЛРДІОКэ:bottom=data[0],»№ҝЙТФЕдәПЧЕwidthІОКэҪшРРёчМхЧҙНјјдёфөДЙиЦГ
2.2.4 »жЦЖәбПт¶СөюНј
ХвАпҫНТӘУГөҪЙПГжөДwidthІОКэ,ҙЛНв»№ТӘҙоЕдЧЕxІОКэөДЖ«ТЖБҝҪшРР,ЗТЖ«ТЖБҝТӘәНwidthіЙұИАэ,КдіцҪб№ыИзПВ

ҪУПВАҙҫНКЗРЎРЮ,ҪшРРxЦбұкЗ©РЕПўөДЦё¶Ё»№УРҫНКЗГҝёцСХЙ«ҙъұнөДНјАэРЕПў
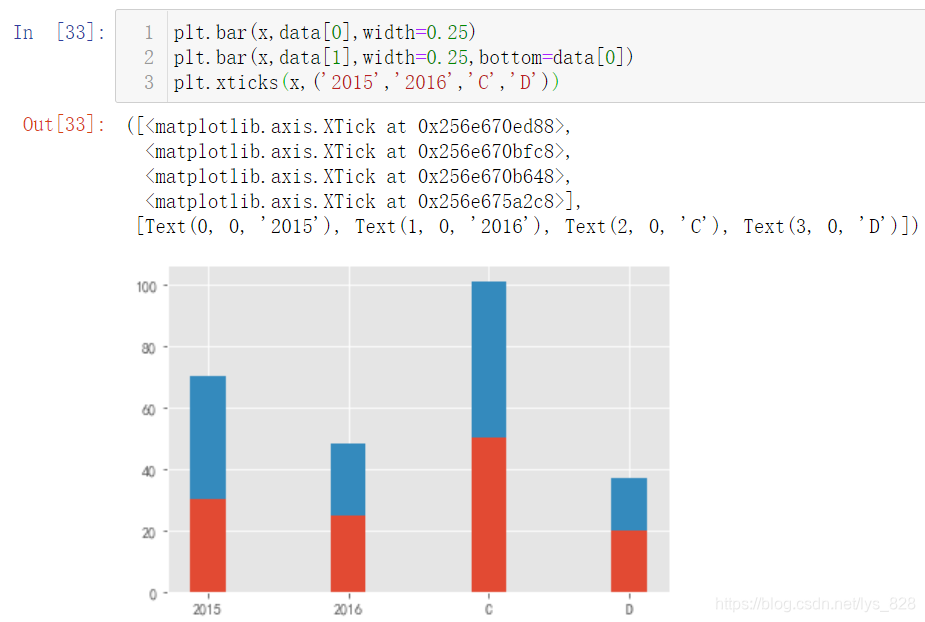
ПИҪвҫцxЦбұкЗ©РЕПў,әЛРДҙъВл:plt.xticks(x,('2015','2016','C','D')),ҫНКЗ°СДгТӘПФКҫөДҝМ¶И·ЕЦГУЪәуТ»ёцАЁәЕЦР,КдіцҪб№ыИзПВ
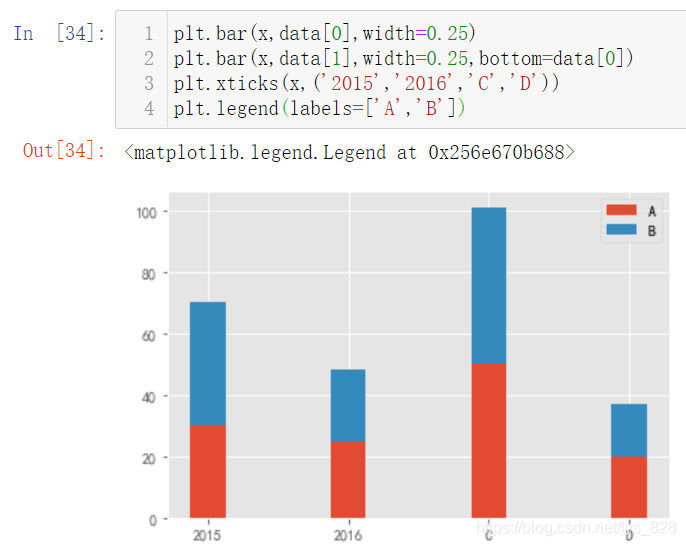
И»әуҪвҫцНјАэөДОКМв,ҝЙТФәНЦ®З°Т»СщФЪ»жЦЖНјРОөДКұәтЦё¶ЁlabelІОКэ,ТІҝЙТФСЎФсФЪplt.legend()әҜКэЦРЦұҪУЦё¶Ё
2.3 »жЦЖЦұ·ҪНј
әЛРДҙъВл:plt.hist()
Цұ·ҪНјКЗТ»ЦЦНіјЖұЁёжНј(Хл¶ФБ¬РшКэҫЭ),РОКҪЙПТІКЗТ»ёцёцөДіӨМхРО,ө«КЗЦұ·ҪНјУГіӨМхРОөДГж»эұнКҫЖөКэ;ЛщТФ,іӨМхРОөДёЯ¶ИұнКҫЖөКэЧйҫа,ҝн¶ИұнКҫЧйҫа,ЖдіӨ¶ИәНҝн¶ИҫщУРТвТе
2.3.1 Цё¶Ё·ЦПдКэБҝ
ПИөјИлИэҪЈҝН(pandas,numpyәНmatplotlib),И»әујЩ¶ЁІвКФКэҫЭИзПВ
from matplotlib import pyplot as plt
import pandas as pd
import numpy as np
ages = [18,19,21,25,26,26,30,32,38,45,55]
bins = [20,30,40,50,60]
plt.hist(ages)
КдіцҪб№ыОӘ:(ЛдИ»УРbinsёіЦөұдБҝ,ө«КЗФЪ»жЦЖЦұ·ҪНјКұГ»УРҙ«өЭёГІОКэ,ПөНі»б°ҙХХД¬ИП·ЦЧйҪшРР»жЦЖ)
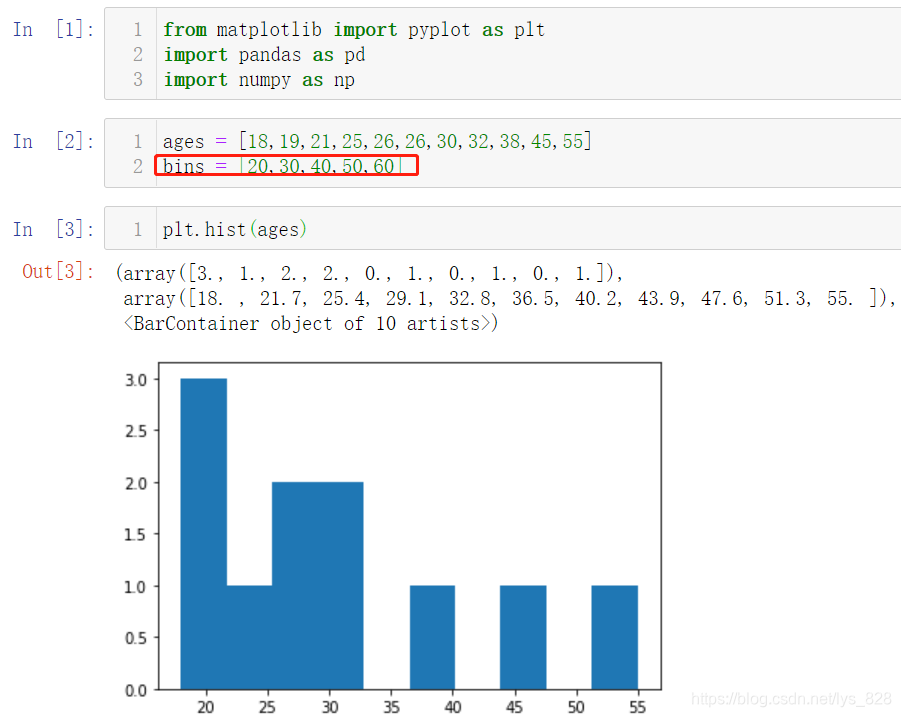
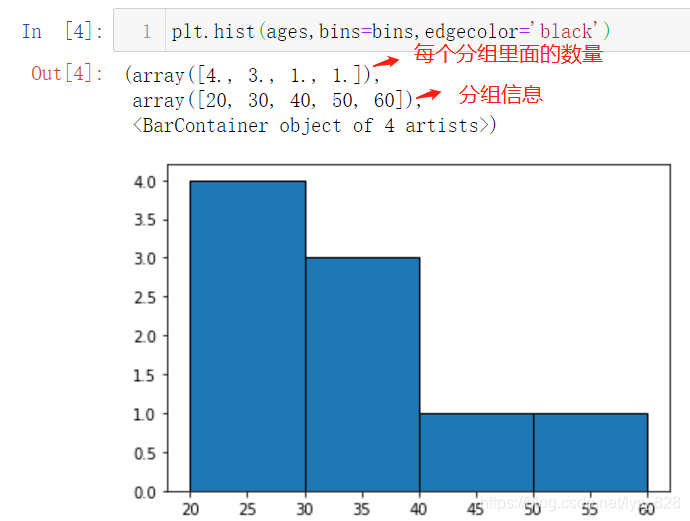
И»әу°ҙХХЦё¶ЁөД·ЦЧйҪшРР»жЦЖ,ІўЙиЦГТ»ПВұЯФөөД·ЦёоПЯ(КдіцҪб№ыЦРҫН°ҙХХПлТӘөД·ЦЧйҪшРР)
2.3.2 »жЦЖұкЧўПЯ
іэБЛјтөҘөДҪшРРІвКФКэҫЭөД»жНјНв,»№ҝЙТФЦұҪУөјИлCsvОДјюЦРөДКэҫЭ,ҪшРР»жЦЖ,ІЩЧчИзПВ(ЖдКөЦ»РиТӘ°СТӘ»жЦЖөДДЗТ»БРЧцОӘұдБҝҙ«өЭөҪТ»ёцІОКэО»ЦГЙПјҙҝЙ)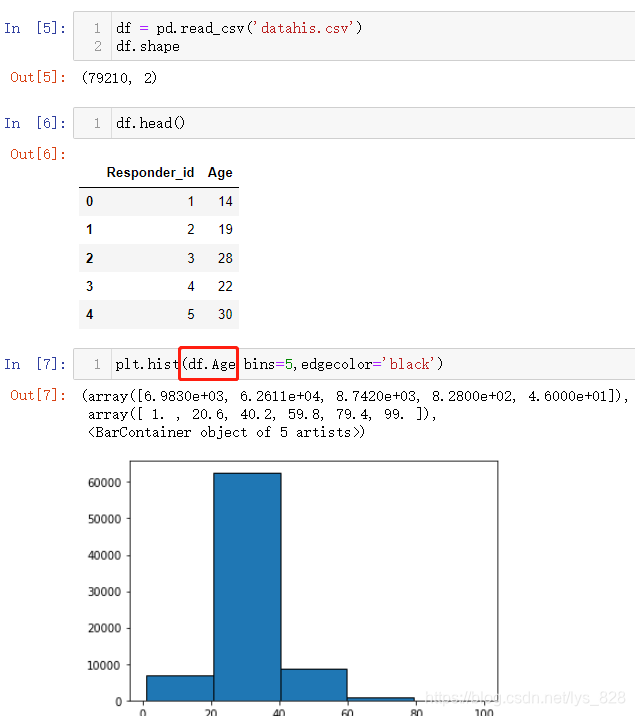
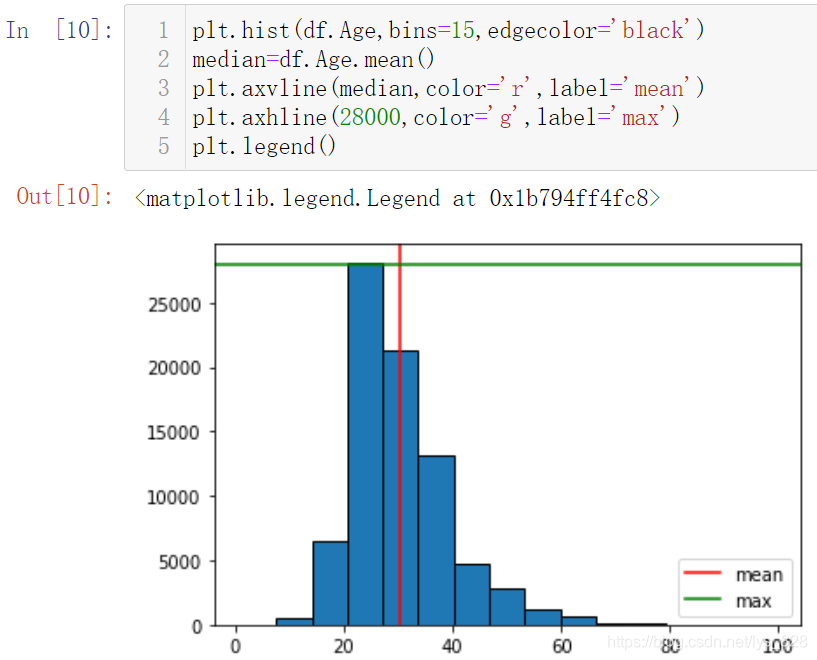
УРКұәтРиТӘФЪНјРОЙПМнјУТ»Р©ёЁЦъПЯ,ұИИзТӘЦӘөАЧоҙуЦөәНЦРО»КэФЪКІГҙО»ЦГөИ,РиТӘУГөҪөДҙъВлЦёБоОӘ:
- ЧЭПт:
plt.axvline(median,color='r',label='mean') - әбПт:
plt.axhline(28000,color='g',label='max')
2.4 »жЦЖ¶СөюНј
әЛРДҙъВл:df.plot(kind='bar',stacked=True)
З°ГжјтөҘөДҪйЙЬБЛМхЧҙНјөД¶СөюНј»жЦЖ,ЖдКөХЯХЫПЯНјТІҝЙТФҪшРР¶Сөю,ҪУПВАҙұИҪППкПёөДҪйЙЬ¶СөюНјөД»жЦЖ
2.4.1 ҫЙЦӘК¶І№ідНкЙЖ
КЧПИөјИлДЈҝйҪшРРІвКФКэҫЭЧјұё
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#К№УГТ»ёцСщКҪ
plt.style.use('fivethirtyeight')
#Т»ёцx,ИэёцyКэҫЭ
minutes = [1, 2, 3, 4, 5, 6, 7, 8, 9]
player1 = [1, 2, 3, 3, 4, 4, 4, 4, 5]
player2 = [1, 1, 1, 1, 2, 2, 2, 3, 4]
player3 = [1, 5, 6, 2, 2, 2, 3, 3, 3]
КдіцҪб№ыИзПВ:
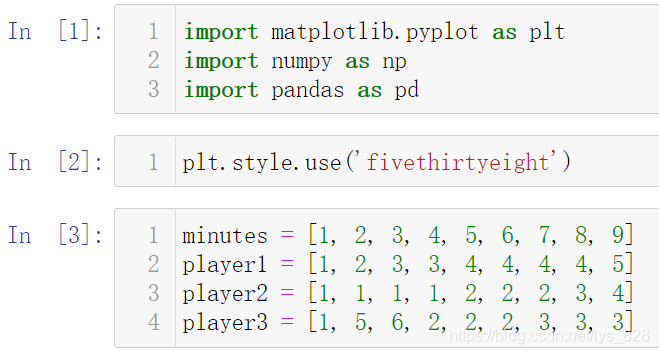
ОӘБЛ·ҪұгxЦбО»ЦГөДјЖЛг,ЛщТФТӘҪ«БРұнКэҫЭЧӘ»ҜОӘarrayКэҫЭАаРН,·ҪұгјУјх,ІўЦё¶ЁГҝёцМхРОЧҙөДЖ«ТЖБҝ

ЧоәуҫНКЗ»жЦЖ¶СөюМхРОНј,ПИ»жЦЖәбПт¶СөюНј,ҙъВлИзПВ
plt.figure(figsize=(9,6))
plt.bar(index_x-w,player1,width=w)
plt.bar(index_x,player2,width=w)
plt.bar(index_x+w,player3,width=w)
plt.xticks(list(range(1,10)))
plt.legend(labels=['1','2','3'])
КдіцҪб№ыИзПВ:(ЦРјдөДТ»ёцКэҫЭҫНКЗОӘФӯұҫөДxЦбКэҫЭ,З°әуБҪёцҫНКЗҪшРРјхјУЖ«ТЖБҝ,ЧоәуМнјУЦё¶ЁұнxұкЗ©әН¶ФУҰНјАэұкЗ©)
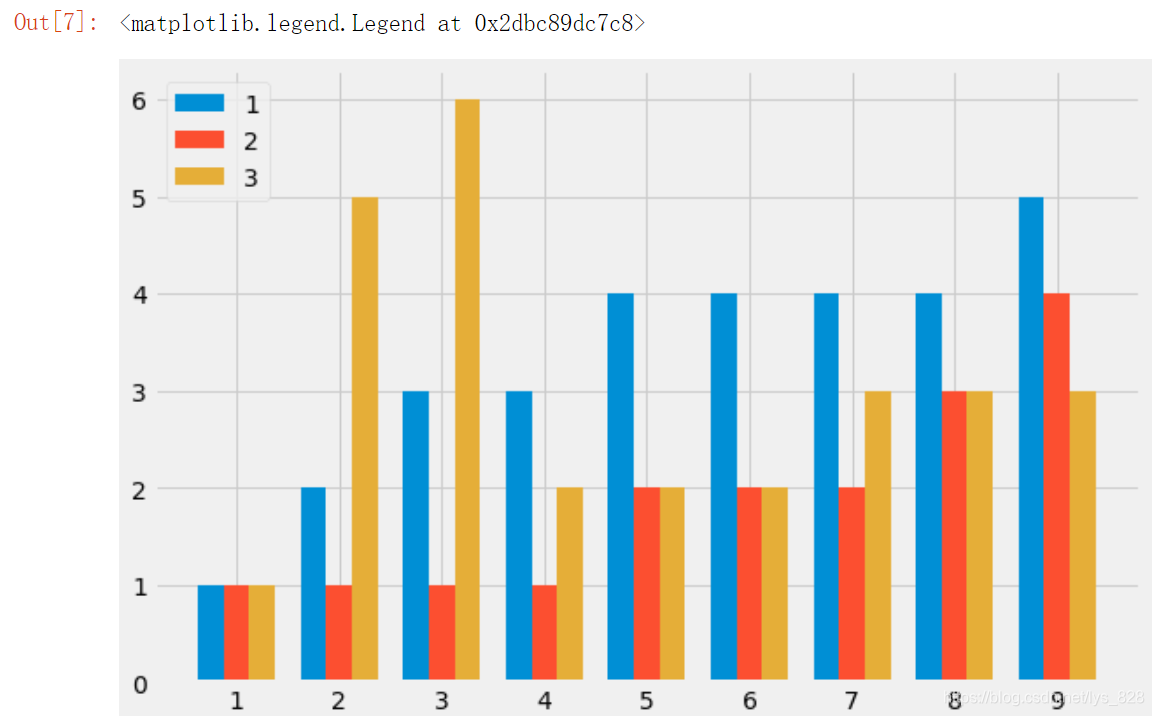
ҪУЧЕ»жЦЖЧЭПт¶СөюНј,ХвАпГжУРТ»ёцРЎҝУ,ҫНКЗbottomІОКэІ»ДЬЦұҪУҪшРРјтөҘөДplayer1+player2

ФӯТтФЪУЪБҪёцБРұнПајУ,ЧоәуөДҪб№ыКЗТФФӘЛШЧ·јУөДРОКҪРОіЙРВБРұн,¶шІ»КЗБҪБҪ¶ФУҰО»ЦГПајУ,ҙҰАнөД·ҪКҪәНЗ°ГжxЦбКэҫЭҙҰАнөДТ»СщЧӘ»ҜОӘarrayКэҫЭАаРНјҙҝЙ,ІвКФҪб№ыИзПВ

ЧоәуҫНКЗҝЙТФНкГА»жЦЖЧЭПт¶СөюМхРОНј
2.4.2 РВЦӘК¶НШХ№СУЙм
ҪУПВАҙҫНІ»КЗЦұҪУК№УГmatplotlibЦРөДplt»жЦЖНјРО,¶шКЗЦұҪУК№УГDataFrameөД»жНјҪУҝЪҪшРР»жЦЖ,№№ФмІвКФКэҫЭИзПВ
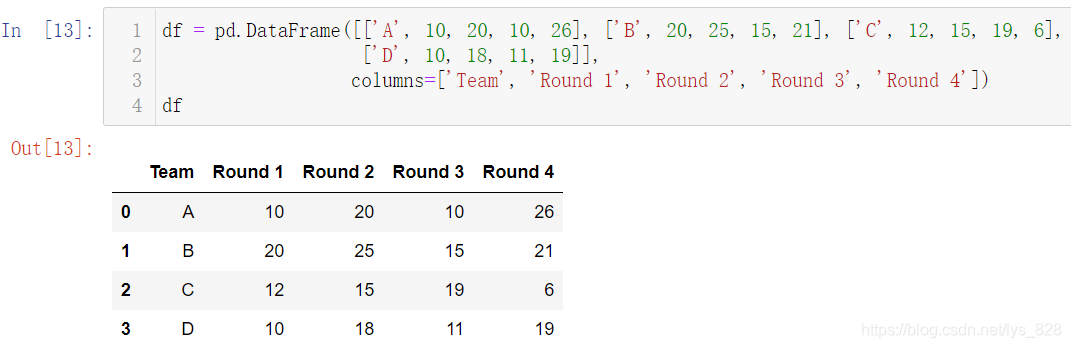
df = pd.DataFrame([['A', 10, 20, 10, 26], ['B', 20, 25, 15, 21], ['C', 12, 15, 19, 6],
['D', 10, 18, 11, 19]],
columns=['Team', 'Round 1', 'Round 2', 'Round 3', 'Round 4'])
df
КдіцҪб№ыОӘ:
И»әу»жЦЖ¶СөюМхЧҙНјҫНКЗТ»РРҙъВлјҙҝЙ,КЧПИ»жЦЖәбПт¶СөюМхЧҙНј,әЛРДҙъВл:df.plot(x='Team',kind='bar')
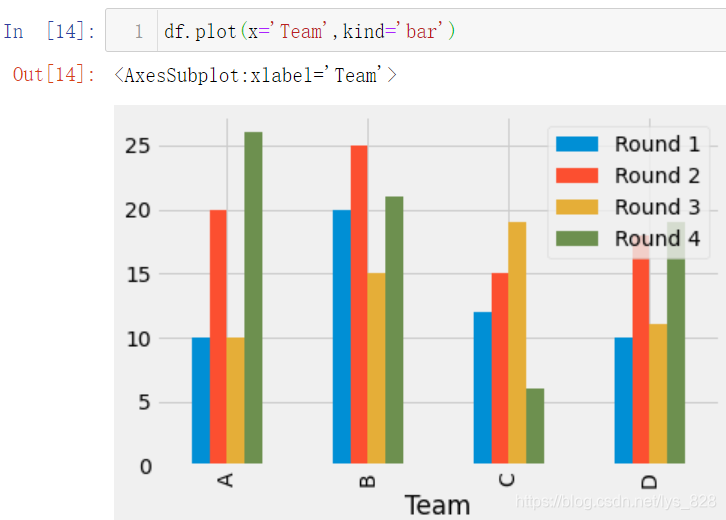
ФЩ»жЦЖЧЭПт¶СөюМхЧҙНј,әЛРДҙъВл:df.plot(x='Team',kind='bar',stacked=True)
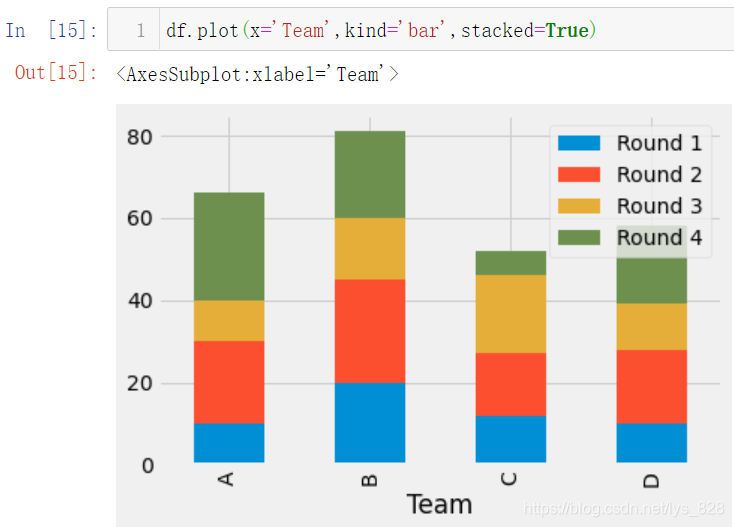
ҝЙТФ·ўПЦЦұҪУНЁ№эDataFrame»жЦЖ¶СөюНјі¬ј¶јтөҘ,КЎИҘБЛәГ¶аТ»өгөгјЖЛгөДІЩЧч,Т»ІҪөҪО»
2.4.3 ¶СөюЦұПЯНј
іэБЛМхЧҙНј,ХЫПЯНјХХСщҝЙТФҪшРР¶Сөю,ХвЦЦ¶СөюНщНщҫНұдіЙБЛГж»эНј,ГҝёцХЫПЯЦ®јдО§іЙөДЗшУтҫНКЗұнКҫұЛҙЛјдПаІоөДМеБҝ,әЛРДҙъВл:plt.stackplot(x,y1,y2,y3)
ІвКФКэҫЭИзПВ
x = [1, 2, 3, 4, 5]
y1 = [1, 1, 2, 3, 5]
y2 = [0, 4, 2, 6, 8]
y3 = [1, 3, 5, 7, 9]
»жЦЖ¶СөюНјәНЧФ¶ЁТеСХЙ«ІЩЧч,ЧоЦХҪб№ыИзПВ(ҝЙТФНЁ№эlocІОКэЦё¶ЁПФКҫНјАэөДО»ЦГ,ҝЙТФНЁ№эЧЦ·ыҙ®Цё¶ЁТІҝЙТФНЁ№эЧшұкЦё¶Ё,ҫЯМеөДҝЙТФІйҝҙТ»ПВЛөГчКЦІб)
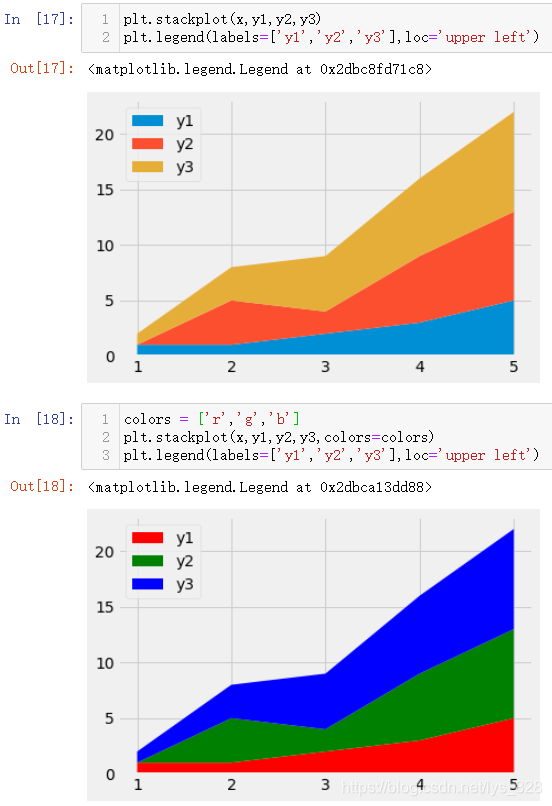
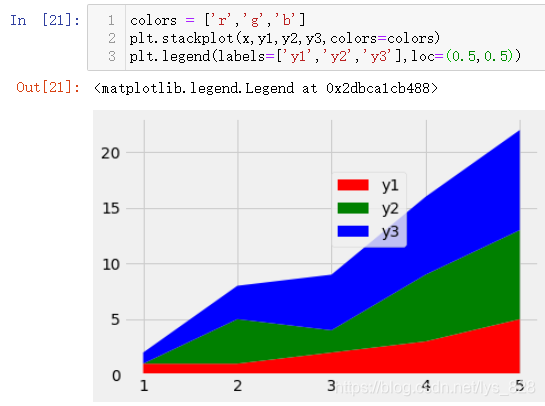
locІОКэҝЙТФИЎөГЧЦ·ыҙ®¶ФУҰөДО»ЦГИзПВ

ҙЛНвК№УГЧшұкҪшРРНјАэөДО»ЦГ·ЕЦГИзПВ(ХвЦЦ»щұҫЙПҫНКЗФЪЦё¶ЁЙПГжЧЦ·ыҙ®¶ФУҰөДО»ЦГІ»ВъТвөД»щҙЎЙПҪшРРО»ЦГөДОўөч)
Из№ыРиТӘёьҪшТ»ІҪБЛҪв°Щ·ЦұИ¶СөюМхЧҙНјөД»жЦЖ,КбАнДЪИЭҝЙТФҪшРРІОҝј:·вЧ°ҪУҝЪЦұҪУАыУГDataFrame»жЦЖ°Щ·ЦұИ¶СөюМхЧҙНј
2.5 »жЦЖҙшУРТхУ°Гж»эөДХЫПЯНј
әЛРДҙъВл:plt.fill_between()
өјИлИэҪЈҝНДЈҝйәНІвКФКэҫЭ
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = pd.read_csv('data06.csv')
data.head()
КдіцҪб№ыИзПВ:(Из№ыОДјю¶БИЎК§°Ь,јЗөðѹвұкТЖ¶ҜЦБЧоәуТ»РР,°ҙТ»ПВНЛёсјь»ШөҪУРКэҫЭөДТ»РРұЈҙжәуФЩ¶БИЎ)
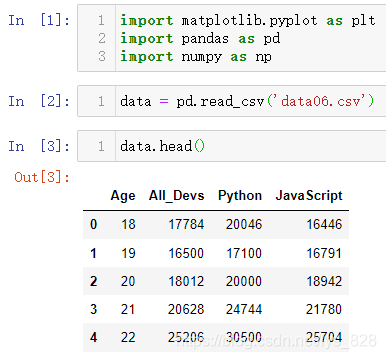
јтөҘөШ»жЦЖіцЛщУРөДРРТөРҪЧКәНpythonРҪЧКөДЗйҝц
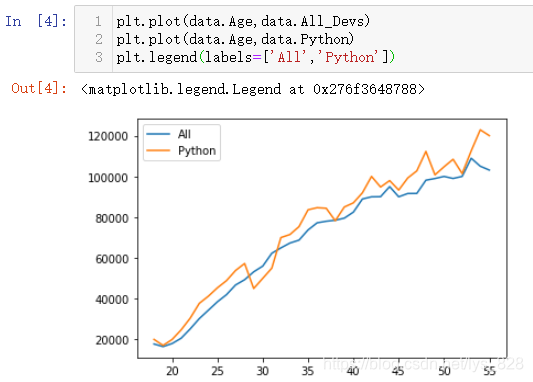
ОТГЗДҝұкҫНКЗКөПЦұкЧўіцҙуУЪЛщУРөДРРТөРҪЧКәНРЎУЪpythonРҪЧКөДІҝ·Ц,ІўЗТТФІ»Н¬өДСХЙ«ҪшРРұнКҫ,ДЗГҙҫНҝҙТ»ПВfill_between()ЦұҪУК№УГ»бУРКІГҙР§№ы,ұИИзЦё¶ЁxОӘДкБд,y1ОӘЛщУРөДРРТөРҪЧК
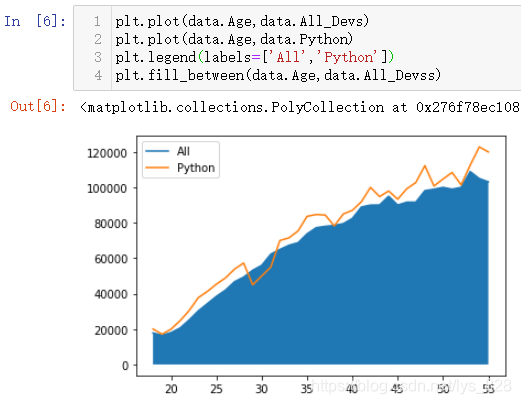
әҜКэЦР»№УРy2ІОКэәНwhereІОКэҪшРР¶ФұИөДПЮ¶Ё,ұИИзy2Цё¶ЁТ»ёц№М¶ЁЦө,И»әуwhereҫНКЗЦё¶ЁУлХвёц№М¶ЁЦөөД¶ФұИИзПВ(ЧоәуТ»РРМнјУБЛБҪёцПФКҫНёГч¶ИalphaәНСХЙ«өДІОКэ)
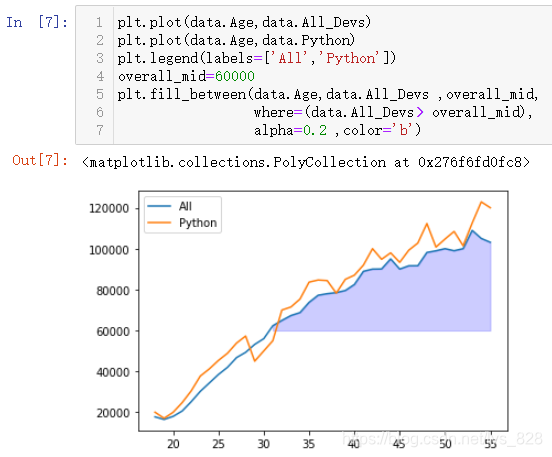
УЙҙЛҫНУРБЛЖф·ў,јИИ»КЗТФpythonөДРҪЧКәНИ«РРТөөДРҪЧКЧчОӘұкЧј,ДЗГҙy1ҫНКЗpythonөДРҪЧК,y2ҫНКЗИ«РРТөөДРҪЧК,ФЪҪшРРwhere¶ФұИКұәтЦ»ДЬСЎИЎТ»Іа,№КҝЙТФҪшРРБҪҙОәҜКэөДөчУГ,ХвСщҫНДЬКөПЦЧоіхөДДҝөД
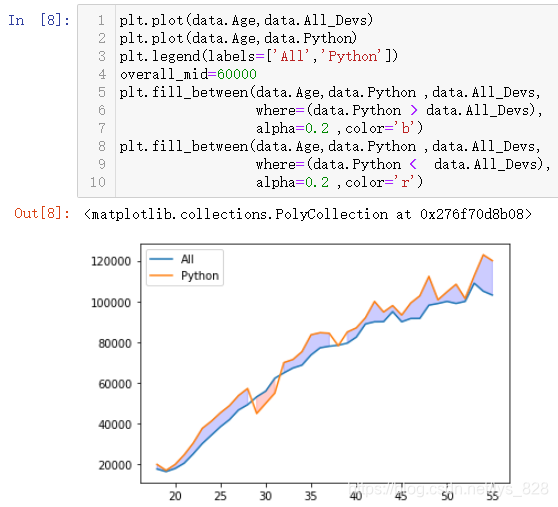
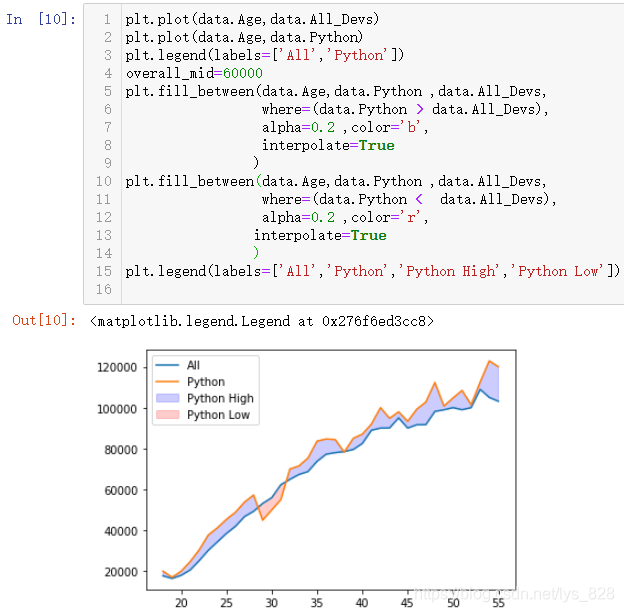
ҙУЙПНјЦРҝЙТФҝҙіцҪ»ІжөДІҝ·ЦЗшУтҙжФЪЧЕҝХ°Ч,ТтОӘХвІҝ·ЦКэҫЭИұК§өјЦВ,ДЗГҙТІҝЙТФНЁ№эinterpolateДвәПІоЦөҪшРРМоід,ҫЯМеКөПЦҫНКЗЦё¶Ёinterpolate=True,КдіцҪб№ыИзПВ(НкГАҪвҫцОКМв)
2.6 »жЦЖұэНј
әЛРДҙъВл:plt.pie()
2.6.1 »жЦЖұэНјПа№ШІОКэҪйЙЬ
өјИлИэҪЈҝНДЈҝйТФј°ІвКФК№УГөДКэҫЭ
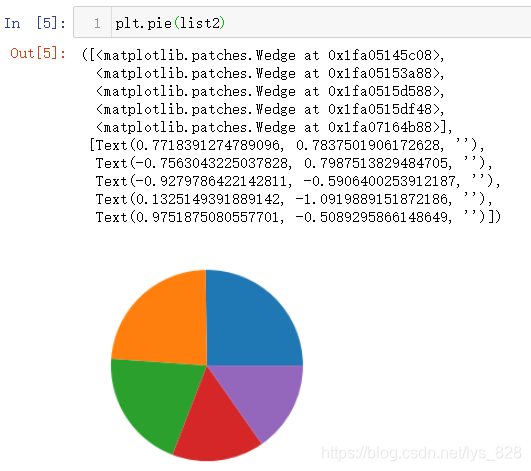
»жЦЖЧојтөҘөДұэНј,ЦұҪУК№УГ:plt.pie(list2),ЖдЦРlist2ҫНКЗТӘҪшРР»жНјөДКэЦөКэҫЭ,КдіцҪб№ыИзПВ(НјПсЙПГжөДОДЧЦКдіцІҝ·ЦҫНКЗ»жЦЖөДХвёцНј¶ФУҰөДРЕПў,°ьә¬БЛНјРОөДұЯҪзәНёчёцІҝ·ЦөДЙИРОЧйҝй)
әҜКэЦРіЈУГөДІОКэИзПВ:
- ұкЗ©:
labels - Іҝ·ЦН»іц:
explode - ТхУ°:
shadow - КэҫЭұкЧў:
autopct - ЖрКјҪЗ¶И:
startangle - ұЯФөЙиЦГ:
wedgeprops
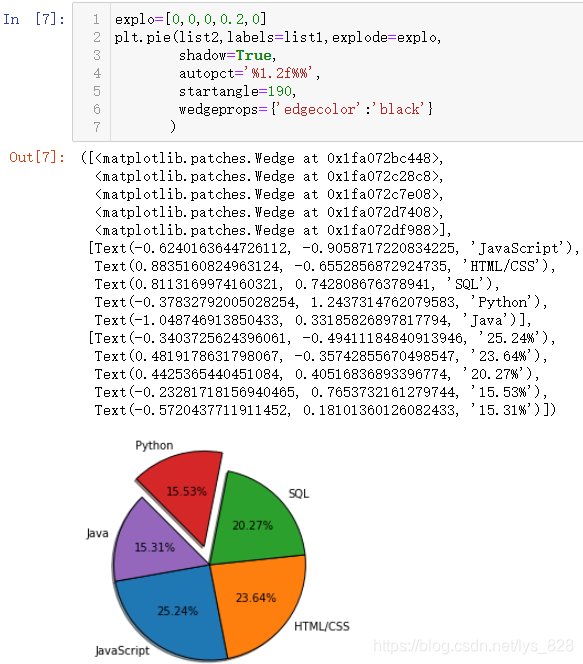
explo=[0,0,0,0.2,0]
plt.pie(list2,labels=list1,explode=explo,
shadow=True,
autopct='%1.2f%%' ,
startangle=190,
wedgeprops={'edgecolor':'black'}
)
КдіцҪб№ыИзПВ:(№ШУЪlabelsІОКэҫНКЗЦё¶ЁКэЦө¶ФУҰөДұкЗ©РЕПў;explodeІОКэКЗТФБРұнРОКҪёшіц,БРұнФӘЛШөДёцКэТӘәН»жЦЖөДұкЗ©өДКэБҝТ»ЦВ,Д¬ИПЦөОӘ0Кұ,ёГұкЗ©ҙъұнөДЙИРОІ»Н»іц,ҙуУЪ0КұПФКҫН»іц,ОӘБЛГА№ЫөДР§№ыХвёцН»іцЦөТ»°гІ»ТӘМ«ҙу;shadowІОКэҫНКЗёшұэНјФцјУТ»ёцТхУ°Р§№ы,ИГНјРОҝҙЙПИҘёьБўМе;autopctІОКэКЗёшНјРОјУЙПОДЧЦұкЧў,ПФКҫ°Щ·ЦұИөДРОКҪ,К№УГКұәтҫН°ҙХХПВГжөДКйРҙҫНҝЙ,И»әуұЈБфөДО»КэРЮёД.әНfЦ®јдөДКэЦөјҙҝЙ;startangleІОКэұнКҫөчХыНјРОөДО»ЦГ,ОӘБЛГА№ЫҝЙТФҪшРРРэЧӘҪЗ¶И;wedgepropsІОКэЙиЦГұЯФөКфРФ,іэБЛұЯФөСХЙ«Нв»№ҝЙТФЙиЦГҙЦПё,ТІКЗНЁ№эЧЦөдөД·ҪКҪҙ«ИлІОКэ)
2.6.2 КэҫЭКөІЩ
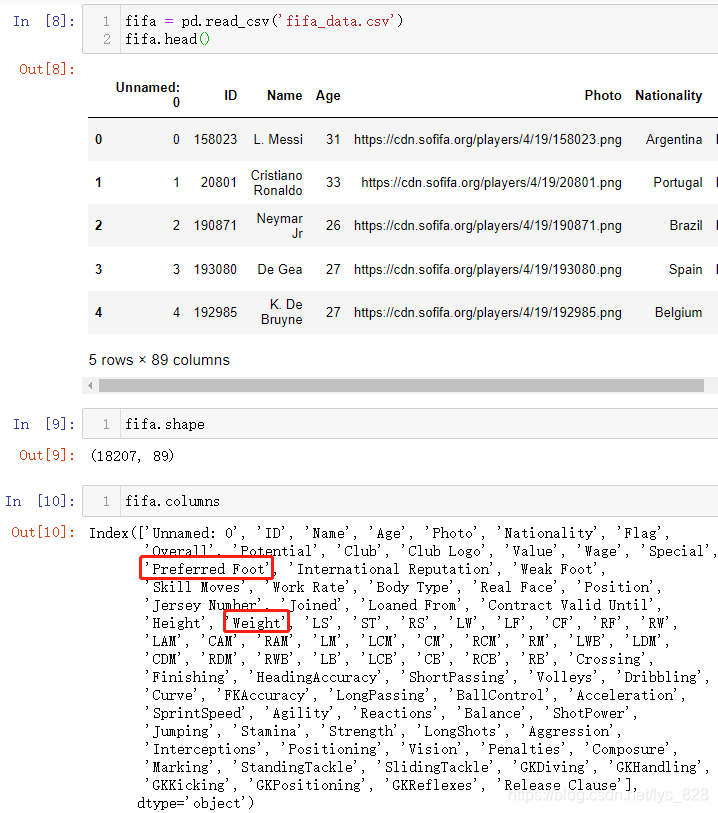
ІвКФКэҫЭОӘЧгЗтіЎЙПөДЗтФұМЯЗтөДРЕПўНіјЖ,јУФШКэҫЭИзПВ(КэҫЭБҝЧЬ№ІУР18207Мх,89ёцЧЦ¶О,ө«КЗОТГЗРиТӘҫНКЗПВГжәмҝтұкіцөДЧЦ¶О:ЗтФұМЯЗтЖ«ПтК№УГДДТ»Ц»ҪЕТФј°ЗтФұөДМеЦШЧЦ¶О)
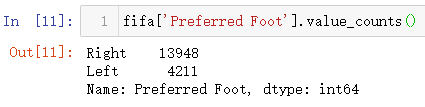
КЧПИ»жЦЖТ»ёцјтөҘөгНјРО,ҫНКЗ¶ФЗтФұМЯЗтК№УГДДЦ»ҪЕөДЖ«әГҪшРРНіјЖХјұИ»жЦЖұэНј,НіјЖ·ЦАаКэҫЭөДКэБҝК№УГҙъВл:fifa['Preferred Foot'].value_counts(),КдіцИзПВ(¶ФДіТ»ЧЦ¶ОЦРіцПЦөДАаұрҪшРРНіјЖ,ҫНКЗНіТ»өДұкЧјDataFrame['ЧЦ¶ОГы'].value_counts())
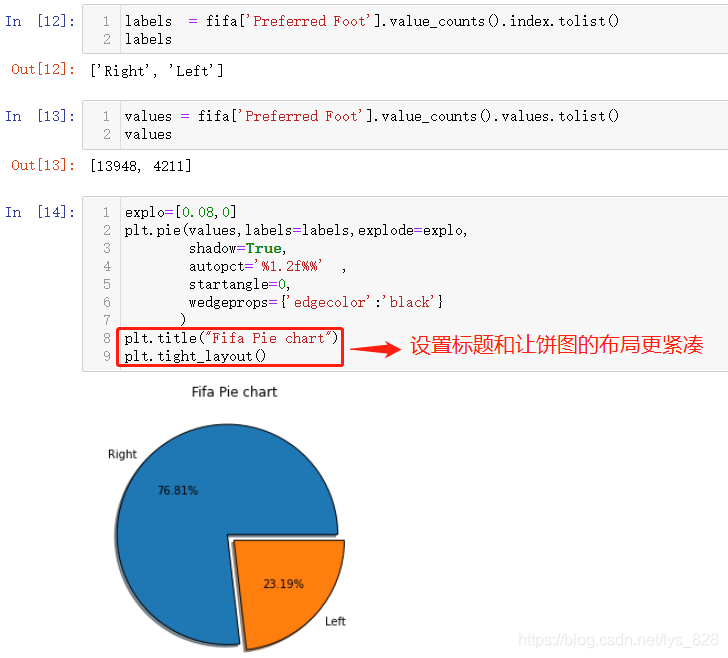
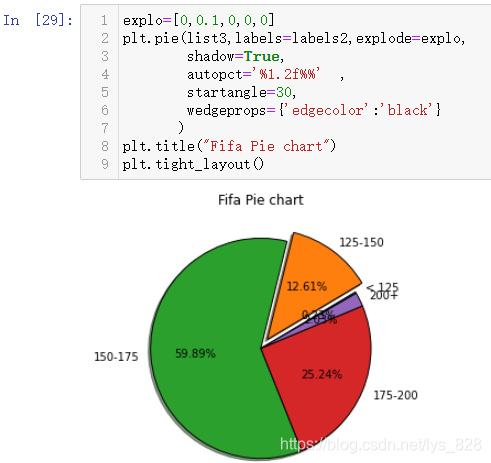
УРБЛКэҫЭәуҫНҝЙТФЦұҪУҪшРР»жЦЖБЛ,ПИҪшРРКэЦөәНұкЗ©өДёіЦө,И»әу°СЙПГж»жЦЖұэНјөДҙъВлёҙЦЖХіМщТ»ПВ,РЮёДІҝ·ЦДЪИЭјҙҝЙ
labels = fifa['Preferred Foot'].value_counts().index.tolist()
labels
values = fifa['Preferred Foot'].value_counts().values.tolist()
values
explo=[0.08,0]
plt.pie(values,labels=labels,explode=explo,
shadow=True,
autopct='%1.2f%%',
startangle=0,
wedgeprops={'edgecolor':'black'}
)
plt.title("Fifa Pie chart")
plt.tight_layout()
КдіцҪб№ыИзПВ:(·ЦАајЖКэНіјЖЦ®әу,¶ФУҰөДКэҫЭАаРНОӘSeries,ҝЙТФНЁ№эindex»сИЎөЪТ»БРұкЗ©КэҫЭ,values»сИЎөЪ¶юБРКэЦөКэҫЭ,И»әуtolist()ҫНКэҫЭЙъіЙОӘБРұнКэҫЭ,ЧоәуҝЙТФМнјУұэНјөДұкМвәНЙиЦГҪфҙХІјҫЦ)
өЪТ»ёцјтөҘөДКөІЩұэНјНкіЙБЛ,ҪУПВАҙҫНКЗТ»ёцЙФОўёҙФУТ»өгөДЗтФұМеЦШөДұэНј»жЦЖ,КЧПИҝҙТ»ПВёГЧЦ¶ОөДДЪИЭЗйҝц,ИзПВ(УЙУЪКэҫЭБҝҪПҙу,ХвАпЦ»ПФКҫЗ°10Мх,ҝЙТФ·ўПЦ»щұҫЙПГҝМхКэҫЭәуГж¶јУРlbsөДәуЧә)
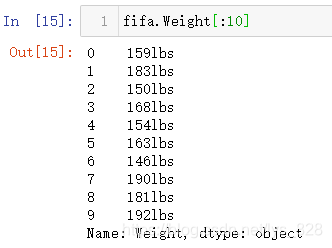
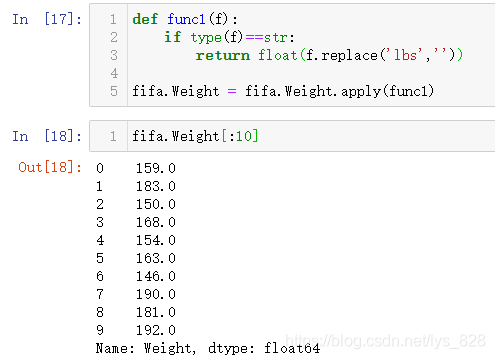
РиТӘҙҰАнТ»ПВХвёцәуЧә,І»№эХвАпІ»РиТӘСйЦӨКЗІ»КЗГҝМхКэҫЭәуГж¶јУРlbs,ТтОӘК№УГөДҙҰАн·ҪКҪКЗЦұҪУҪ«lbsМж»»ОӘҝХ,Из№ыУРөДКэҫЭЦРГ»УРlbs,ТІҫНІ»РиТӘМж»»,КҫАэҙъВлЦёБо:float('159lbs'.replace('lbs',''))ЎЈУҰУГФЪИ«ІҝөДЧЦ¶ОКэҫЭЦР,ІЩЧчИзПВ
def func1(f):
if type(f)==str:
return float(f.replace('lbs',''))
fifa.Weight = fifa.Weight.apply(func1)
КдіцҪб№ыОӘ:(¶ФұИЙП·ҪІйҝҙөДЗ°10МхКэҫЭТФј°КдіцөДdtypeКэҫЭАаРН,ҝЙТФәЛКөәуЧәТСҫӯМж»»НкұП,ЗТКэҫЭАаРНТІұдіЙБЛfloat)
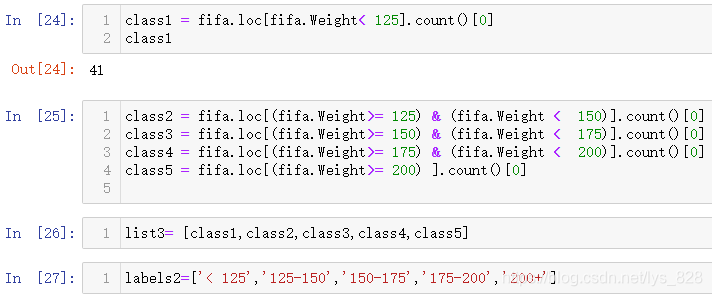
Ц®З°»жЦЖөДұэНјК№УГөДКЗ·ЦАаұкЗ©КэҫЭ,ХвАпөДКэҫЭКЗКэЦөРНБ¬РшКэҫЭ,ТӘПл»жЦЖұэНјҫНРиТӘПИҪшРРКэҫЭ·ЦПдІЩЧч(ТІҫНКЗ°ҙХХМеЦШ·¶О§ҪшРР·ЦЧй,·ЦЧйөДІЩЧчТІҫНКЗЦ®З°өДpandasЦРҪйЙЬөДЛчТэИЎЦө),јЩ¶Ё·ЦЧй·¶О§:[125,125-150,150-175,175-200,200],И»әуөГөҪ¶ФУҰГҝёцЗшјдөДјЖКэәН¶ФУҰөДұкЗ©labels
УРБЛКэҫЭәНұкЗ©ҫНҝЙТФНкіЙұэНјөД»жЦЖ,»№КЗёҙЦЖХіМщҙъВл,РЮёДТ»ПВАпГжөДІҝ·ЦұдБҝјҙҝЙ,КдіцөДұэНјИзПВ
ҙЛНвТІҝЙТФК№УГЗ°ГжұЈҙжНјЖ¬өД·Ҫ·Ё,Ҫ«ЙъіЙөДНјРОұЈҙжФЪұҫөШ
2.7 »жЦЖЙўөгНј
әЛРДҙъВл:plt.scatter()
2.7.1 »жЦЖЙўөгНјПа№ШІОКэҪйЙЬ
өјИлДЈҝйәНПа№ШөДІвКФКэҫЭ,Іў»жЦЖЧојтөҘөДЙўөгНј
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
x = [5, 7, 8, 5, 6, 7, 9, 2, 3, 4, 4, 4, 2, 6, 3, 6, 8, 6, 4, 1]
y = [7, 4, 3, 9, 1, 3, 2, 5, 2, 4, 8, 7, 1, 6, 4, 9, 7, 7, 5, 1]
plt.scatter(x,y)
КдіцҪб№ыИзПВ:
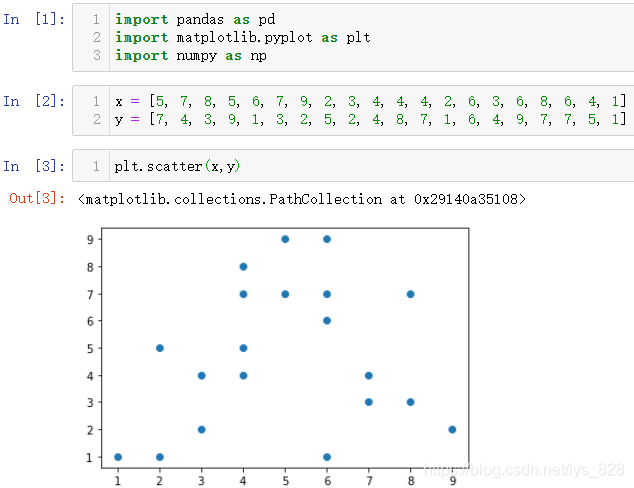
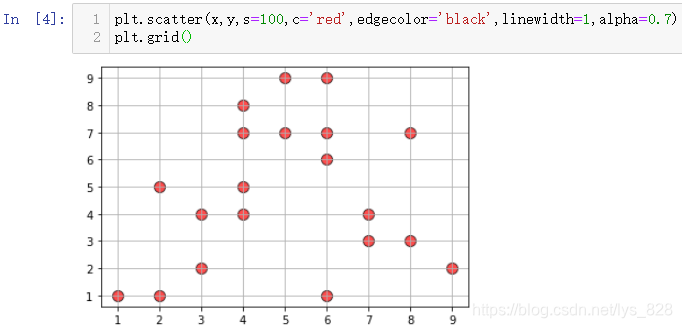
ЙўөгНјЦРөДіЈУГөДІОКэИзПВ:
- ЙиЦГЙўөгҙуРЎ:
s - ЙиЦГЙўөгСХЙ«:
c - ЙиЦГЙўөгұЯФөСХЙ«:
edgecolor - ЙиЦГЙўөгұЯФөПЯҝн:
linewidth - ЙиЦГЙўөгНёГч¶И:
alpha - ЙиЦГЙўөгЙ«ЖЧНј:
cmap
ұИИз»жЦЖҙшУРәЪЙ«ұЯФө,ПЯҝнОӘ1өДәмЙ«НёГч¶ИОӘ0.7ҙуРЎОӘ100өДЙўөгНј(ІўҝӘЖфНшёсПЯ:plt.grid())
plt.scatter(x,y,s=100,c='red',edgecolor='black',linewidth=1,alpha=0.7)
plt.grid()
КдіцҪб№ыИзПВ:
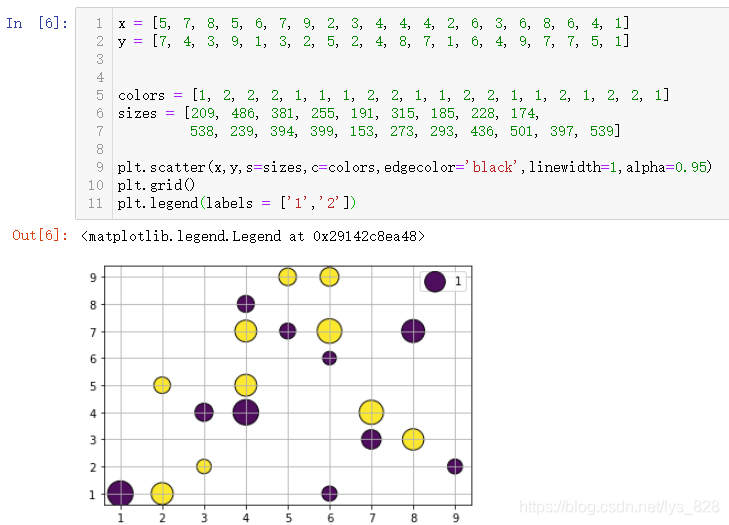
ҙЛНвcәНsБҪёцІОКэҝЙТФК№УГБРұнөД·ҪКҪҪшРРҙ«ІО,ЧоәуКдіцөДСХЙ«әНҙуРЎҫН»бёщҫЭБРұнЦРөДКэЦөҪшРРұд»Ҝ,іЈіЈУГУЪ»жЦЖ·ЦАаЙўөгНј,ИзПВ
x = [5, 7, 8, 5, 6, 7, 9, 2, 3, 4, 4, 4, 2, 6, 3, 6, 8, 6, 4, 1]
y = [7, 4, 3, 9, 1, 3, 2, 5, 2, 4, 8, 7, 1, 6, 4, 9, 7, 7, 5, 1]
colors = [1, 2, 2, 2, 1, 1, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 1, 2, 2, 1]
sizes = [209, 486, 381, 255, 191, 315, 185, 228, 174,
538, 239, 394, 399, 153, 273, 293, 436, 501, 397, 539]
plt.scatter(x,y,s=sizes,c=colors,edgecolor='black',linewidth=1,alpha=0.95)
plt.grid()
plt.legend(labels = ['1','2'])
КдіцҪб№ыИзПВ:(ЧўТвЧоәуТ»РРҙъВл,°ҙХХЦ®З°С§№эөДДЪИЭ¶Ф·ЦАаКэҫЭМнјУұкЗ©,ЧоЦХКдіцөДҪб№ыЦРІўІ»Г»УРПФКҫіцПлТӘөДСщКҪ)
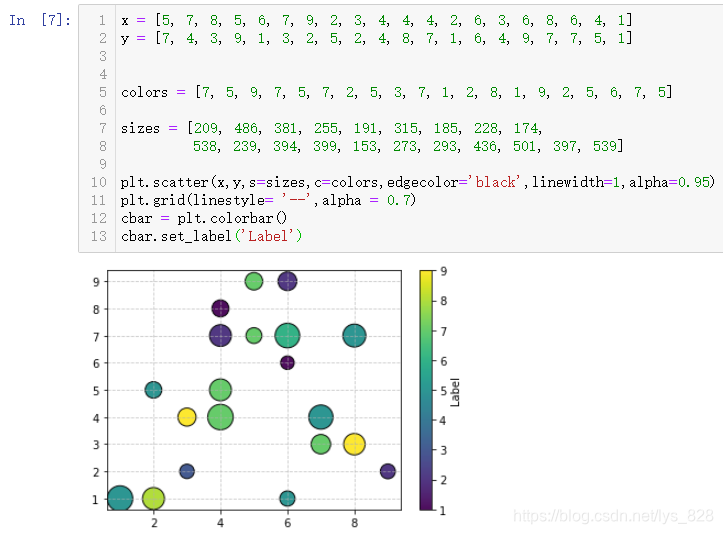
ИзәОПФКҫіцІ»Н¬СХЙ«ҙъұнөДТвТе,ЙПГжҙъВлөДЧоәуТ»ҫдОЮР§БЛ,ҫНРиТӘБнНвөД·ҪКҪҪшРР,ҪвҫцОКМвөД·ҪКҪҫНКЗМнјУСХЙ«Мх,ҙъВлЦёБоОӘ:cbar = plt.colorbar()
x = [5, 7, 8, 5, 6, 7, 9, 2, 3, 4, 4, 4, 2, 6, 3, 6, 8, 6, 4, 1]
y = [7, 4, 3, 9, 1, 3, 2, 5, 2, 4, 8, 7, 1, 6, 4, 9, 7, 7, 5, 1]
colors = [7, 5, 9, 7, 5, 7, 2, 5, 3, 7, 1, 2, 8, 1, 9, 2, 5, 6, 7, 5]
sizes = [209, 486, 381, 255, 191, 315, 185, 228, 174,
538, 239, 394, 399, 153, 273, 293, 436, 501, 397, 539]
plt.scatter(x,y,s=sizes,c=colors,edgecolor='black',linewidth=1,alpha=0.95)
plt.grid(linestyle= '--',alpha = 0.7)
cbar = plt.colorbar()
cbar.set_label('Label')
КдіцҪб№ыИзПВ:(¶ФУЪНшёсПЯ,ЖдЦРТІУРәЬ¶аөДК№УГІОКэ,ұИИзХвАпПФКҫРйПЯ,Н¬КұТІУРНёГч¶ИөДЙиЦГ,¶ФУЪСХЙ«МхТІКЗИзҙЛ,КөАэ»ҜЦ®әуТІУРәЬ¶аөДәҜКэҝЙТФК№УГ,ұИИзМнјУұкЗ©)
2.7.2 КэҫЭКөІЩ
ІвКФКэҫЭОӘУ°Ж¬өД№ЫҝҙКэБҝТФј°өгФЮКэБҝРЕПў,УРИэёцЧЦ¶О,¶БИЎКэҫЭИзПВ
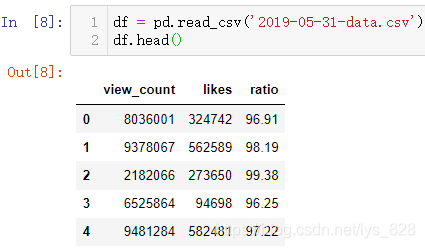
јтөҘ»жЦЖЙўөгНј,Ҫ«№ЫҝҙКэБҝТФј°өгФЮКэБҝҙ«Ил»жЦЖНјРОИзПВ(ХвАпxәНyөДЦё¶Ё,ЦұҪУҪ«ТӘ»жЦЖөДЧЦ¶О·ЕФЪ¶ФУҰөДО»ЦГЙПјҙҝЙ)
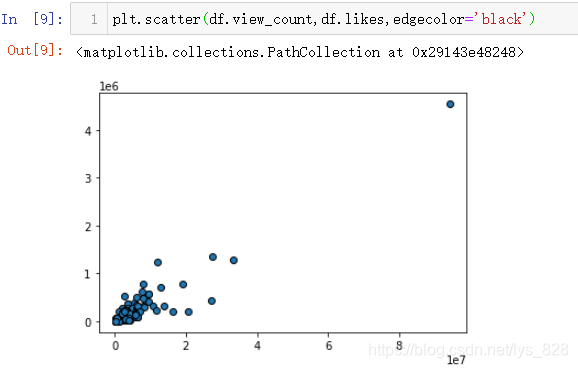
¶ФУЪҙЛАаКэҫЭБҝөДБҝј¶әЬҙуөДЗйҝц(ұИИзЧоәуxЦбөДЧшұк¶јөҪБЛ10өД7ҙО·Ҫ),ҝЙТФІЙУГ¶ФКэЧӘ»Ҝ,Ҫ«xЦбөДКэҫЭЧӘ»ҜОӘ¶ФКэұнКҫ,ҙъВлЦёБо:plt.xscale('log'),plt.yscale('log')
plt.figure(figsize=(10,6))
plt.scatter(df.view_count,df.likes,edgecolor='black',linewidth=1,alpha=0.9,c=df.ratio,cmap='summer')
plt.xscale('log')
plt.yscale('log')
cbar =plt.colorbar()
cbar.set_label('Like/Dislike ')
КдіцҪб№ыИзПВ:(ЦұҪУЦё¶ЁcСХЙ«,СХЙ«өДПФКҫ»бәНЧЦ¶ОЦРөДИЎЦөУРәЬЗҝөД№ШБӘ,Из№ыЧЦ¶ОЦРөДКэЦөј«ІоҪПҙу,ЧоәуөДСХЙ«өД¶ФұИІоұрТІ»бәЬҙу,ОӘБЛИГНјРОПФКҫТ»ёцҪПОӘәНРіөДЙ«өч,ҝЙТФөчУГcmapІОКэҪшРРөчХы)

2.8 КұРтКэҫЭҝЙКУ»Ҝ
2.8.1 ЧЦ·ыҙ®КұјдКэҫЭәНDatetimeКұјдКэҫЭ»жНј¶ФұИ
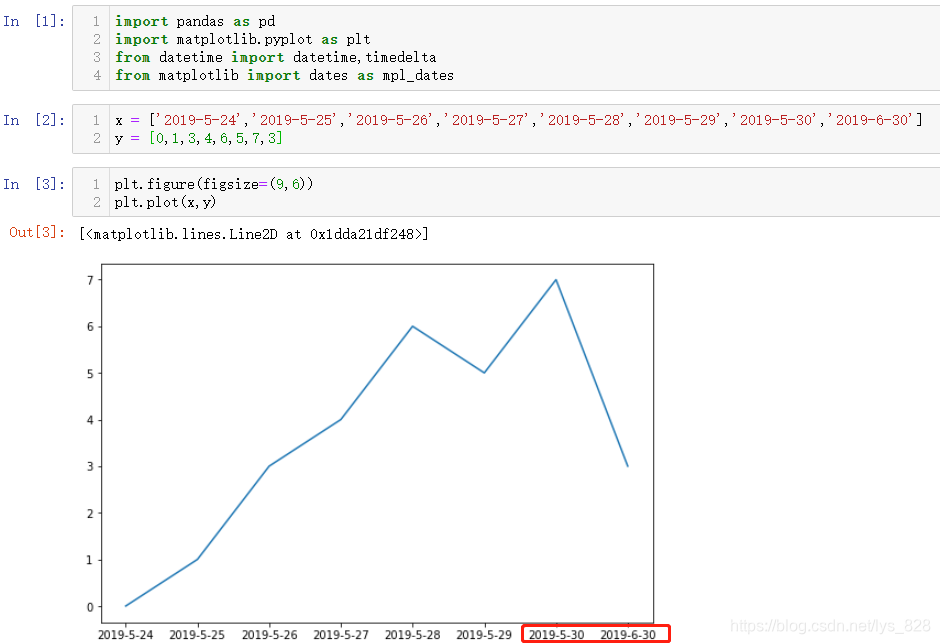
Из№ыұнКҫКұјдөДКэҫЭЧцОӘxЦбРЕПў,КұјдКэҫЭөДАаРН»бУ°ПмЧоЦХөДЧчНјХ№Кҫ,ҫЯМеҝЙТФ·ЦОӘГ»УРҙҰАнөДЧЦ·ыҙ®КэҫЭАаРНөДКұјдКэҫЭәНЧӘ»ҜәуөДDatetimeКұјдАаРНКэҫЭЎЈКЧПИПИҝҙТ»ПВЧЦ·ыҙ®КэҫЭАаРНөДКұјдЦұҪУЧчОӘxЦбРЕПў,өјИлөЪИэ·ҪҝвәНІвКФКэҫЭ,јтөҘ»жЦЖХЫПЯНј
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime,timedelta
from matplotlib import dates as mpl_dates
x = ['2019-5-24','2019-5-25','2019-5-26','2019-5-27','2019-5-28','2019-5-29','2019-5-30','2019-6-30']
y = [0,1,3,4,6,5,7,3]
plt.figure(figsize=(9,6))
plt.plot(x,y)
КдіцҪб№ыИзПВ:(ІвКФҪб№ыЦРЧоәуБҪёцКұјдЧЦ·ыҙ®КЗПаБЪПФКҫ)
Из№ыҪ«ЧЦ·ыҙ®КұјдАаРНКэҫЭЧӘ»ҜОӘDatetimeКэҫЭАаРН,ФЩҪшРР»жЦЖ,¶ФұИКдіцҪб№ыИзПВ:(ЖЪјдКЎВФөДИХЖЪКұјдТІ»бұ»ПФКҫіцАҙ,КұЖЪБ¬Рш)
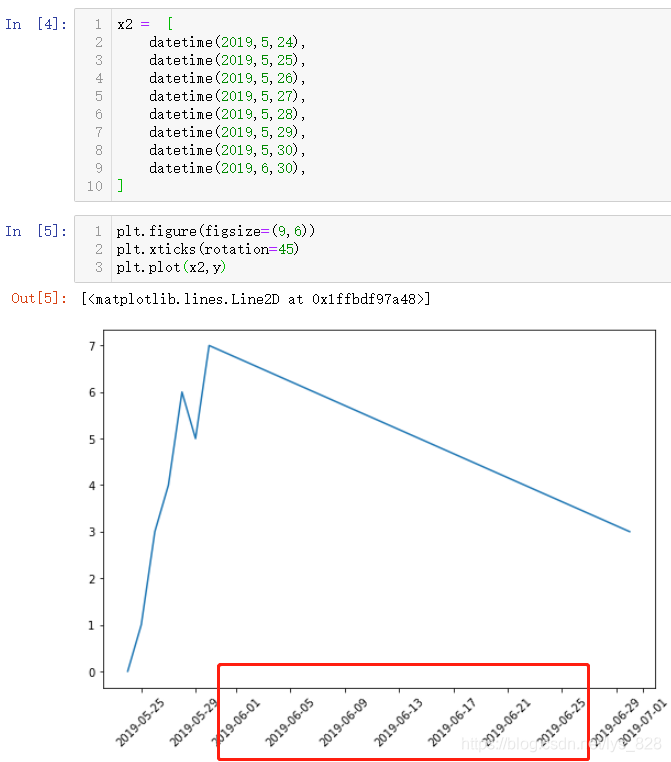
¶ФұИЧЦ·ыҙ®КұјдКэҫЭәНDatetimeКұјдКэҫЭЧчОӘxЦб»жЦЖНјРО,ҝЙТФ·ўПЦЗ°ХЯЦ»КЗҪ«КұјдЧчОӘТ»ёцСщАэ,әцВФБЛКұјдөДБ¬РшРФ,¶шәуХЯЦӨКөМеПЦБЛКұјдБ¬РшРФ,ФЪ»жЦЖНјРОЙПГ»УРәцВФЦРјдИұК§өДКұјд
2.8.2 ¶ҜКЦКөІЩ
ІвКФКэҫЭОӘДіТ»№ЙЖұКэҫЭ,¶БИЎҪб№ыИзПВ:
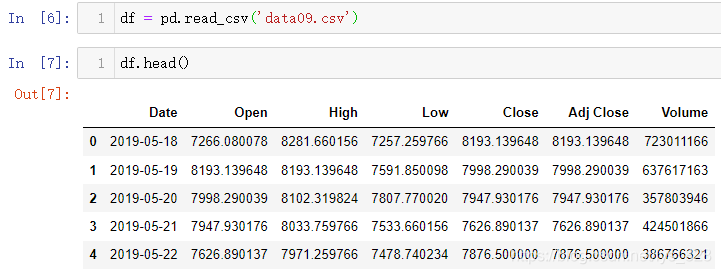
·ўПЦDateЧЦ¶ОЦРҙжФЪКұјдКэҫЭ,РиТӘІйҝҙ¶ФУҰөДКэҫЭАаРН,ҙъВлЦёБо:type(df.Date[0])ЎЈНЁ№эјтөҘІйҝҙЧЦ¶ОЦРөДТ»ёцКэҫЭөДАаРНҫНЦӘөАХвёцЧЦ¶ОКЗІ»КЗ·ыәППлТӘөДКэҫЭАаРН,Ҫб№ыКдіцөДКұјдёсКҪОӘЧЦ·ыҙ®
РиТӘҪшТ»ІҪЧӘ»Ҝ,И»әу»жЦЖНјРО(ЧӘ»»әуөДКэҫЭАаРНҫНКЗКэҫЭҫЯМеDatetimeКэҫЭАаРН,И»әу»жЦЖөДНјРО»гЧЬxЦбҙжФЪЧЕРЕПўёІёЗөДПЦПу,ҝЙТФІОҝјЗ°ГжҪІҪвөДИэЦЦ·ҪКҪҪшРРҪвҫц)
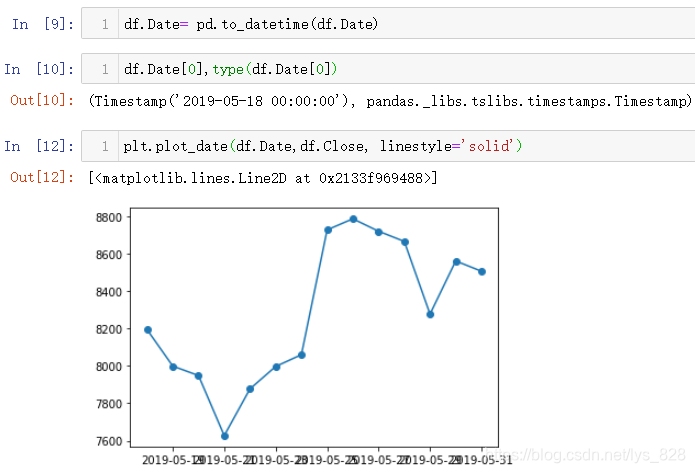
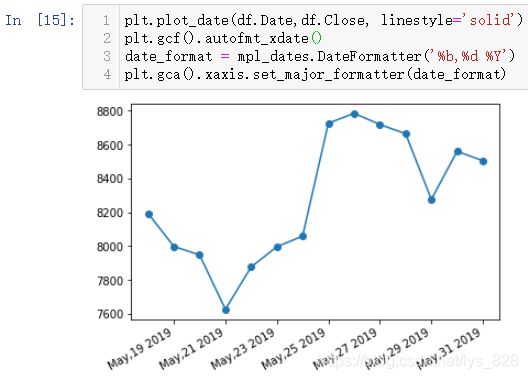
ХвАпФЩҪйЙЬөЪЛДЦЦҙҰАнxЦбРЕПўЦШөюөД·Ҫ·Ё(Хл¶ФКұјд»тХЯКұЖЪКэҫЭ),ҙъВлЦёБо:plt.gcf().autofmt_xdate()
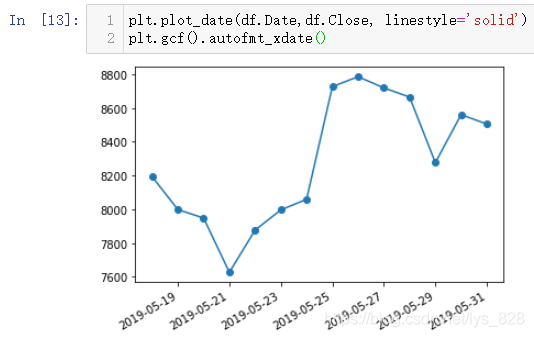
¶шЗТКдіцөДКұјд»№ҝЙТФ°ҙХХёсКҪ»ҜөД·ҪКҪҪшРР,ҙъВлЦёБо:
date_format = mpl_dates.DateFormatter('%b,%d %Y')
plt.gca().xaxis.set_major_formatter(date_format)
КдіцҪб№ыИзПВ:(ХвБҪМхҙъВлЦ»КЗҪшРРxЦбПФКҫКұјдөДёсКҪөчХы,І»»бёДұдД¬ИПөДПФКҫО»ЦГ,РиТӘЕдәПЙПТ»МхЦёБоҙъВлҪшРРО»ЦГөчХыёсКҪ»ҜКдіц)
2.9 КөКұКэҫЭҝЙКУ»Ҝ
2.9.1 КөКұКэҫЭ»жЦЖөДФӯАнТФј°ДЈҝйөчУГ
З°ГжҪйЙЬөДјтөҘІвКФКэҫЭ»тХЯЦұҪУҙУCsvЦР¶БИЎөДКэҫЭ¶јКЗКфУЪҫІМ¬КэҫЭ,ҪУПВАҙҫНКЗҪйЙЬ№ШУЪКөКұКэҫЭҝЙКУ»ҜЎЈКЧПИҪшРРТ»ёцРЎКҫАэСЭКҫ,·ҪұгАнҪвКөКұКэҫЭПФКҫөДФӯАн
КЧПИЦұҪУёшіцІвКФҙъВл
#өјИлТӘК№УГөДДЈҝй
import pandas as pd
import matplotlib.pyplot as plt
import random
from itertools import count #УГУЪјЖКэ
from IPython.display import HTML
#Йи¶Ё·зёс
plt.style.use('fivethirtyeight')
#ҙҙҪЁБҪёцҝХБРұн,УГУЪКХјҜКэҫЭ
x1=[]
y1=[]
#јЖКэЦөіхКј»Ҝ,ОӘ0
index =count()
def animate():
#»щУЪЗ°ГжөДөчУГҪб№ы+1,ІъЙъТ»ёцx
x1.append(next(index))
#ІъЙъТ»ёцy
y1.append(random.randint(0,10))
#ГҝҙО»жЦЖНкұПәуҪшРРНјРОөДІБіэ
plt.cla()
#ФЩҙО»жЦЖНјРО
plt.plot(x1,y1)
animate()
КдіцҪб№ыОӘ:(ГҝҙОЦҙРР¶ј»бЛўРВНјЖ¬,өұКэҫЭБҝФц¶аөДКұәт,xәНyЦб·¶О§ЧоҙуЦөТІФЪ·ўЙъёДұд)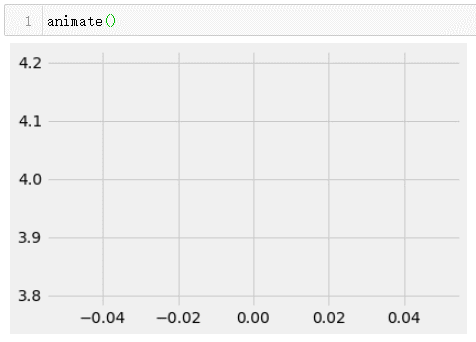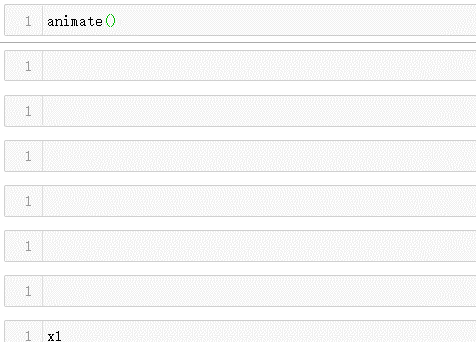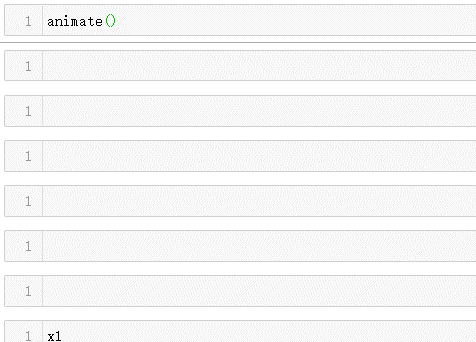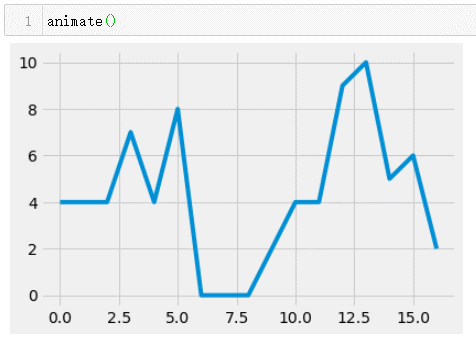
КөКұ¶ҜМ¬НјЖ¬өД»жЦЖҫНКЗЙПГж»жЦЖөДФӯАн,ө«КЗёХёХСЭКҫөД¶ҜМ¬Р§№ыРиТӘЧФјәТ»ҙОТ»ҙОөДФЛРР,ЧоәуҪб№ыТІКЗТ»ЦЎТ»ЦЎөДЛўРВ,Из№ыөчУГДЈҝйҪшРР»жЦЖФтІ»»біцПЦЙПГжМш¶ҜөДПЦПу
#өјИл»жЦЖ¶ҜМ¬НјЖ¬өДДЈҝй
from matplotlib.animation import FuncAnimation
#РиТӘЦШРВјЖКэ,әҜКэЦРұШРлТӘУРТ»ёцІОКэ
index =count()
def animate1(i):
x1.append(next(index))
y1.append(random.randint(0,10))
plt.cla()
plt.plot(x1,y1)
#Цё¶Ё»жЦЖөДНјПс:plt.gcf(),ҫЯМеФхГҙСщ»жЦЖ:animate,ЛўРВ»жЦЖөДјдёф:interval=1000ҙъұнЧЕ1Гл
ani = FuncAnimation(plt.gcf(),animate,interval=1000)
#Ҫ«¶ҜМ¬НјЖ¬ЙъіЙОӘhtmlРОКҪ,ҝЙТФЦұҪУФЪnotebookөДcellПВКдіцІўЗТІйҝҙ
HTML(ani.to_jshtml())
КдіцҪб№ыОӘ:(ЧоЦХ»бЙъіЙТ»ёцҙшУРҝШЦЖ°ҙЕҘөД¶ҜМ¬Нј,ҝЙТФҪшРРјУЛЩ»тХЯјхЛЩ,ЙхЦБЦұҪУМшөҪНјРОҝӘКј»тХЯҪбКшО»ЦГ)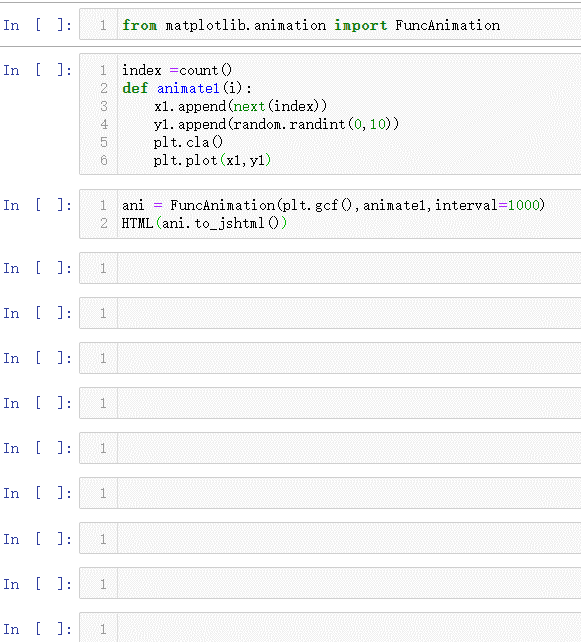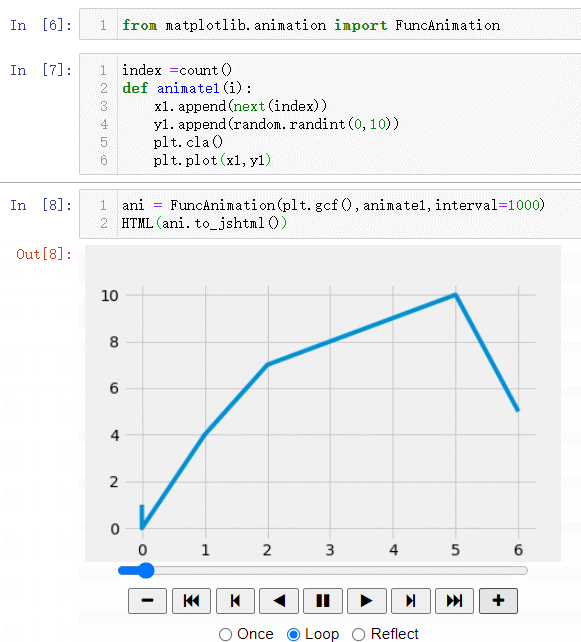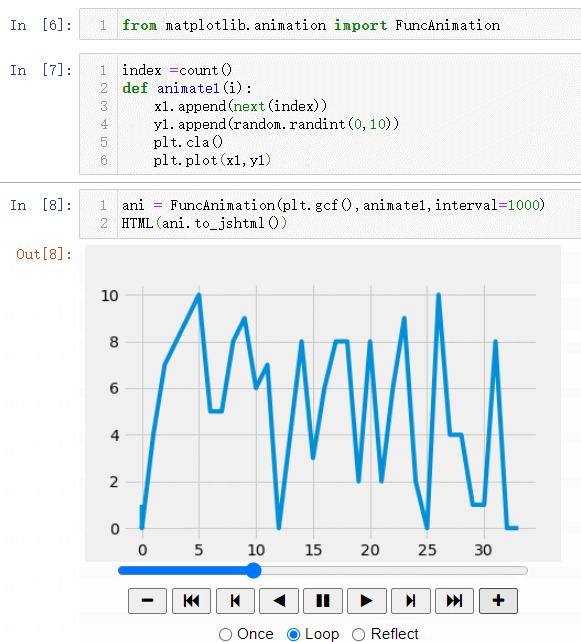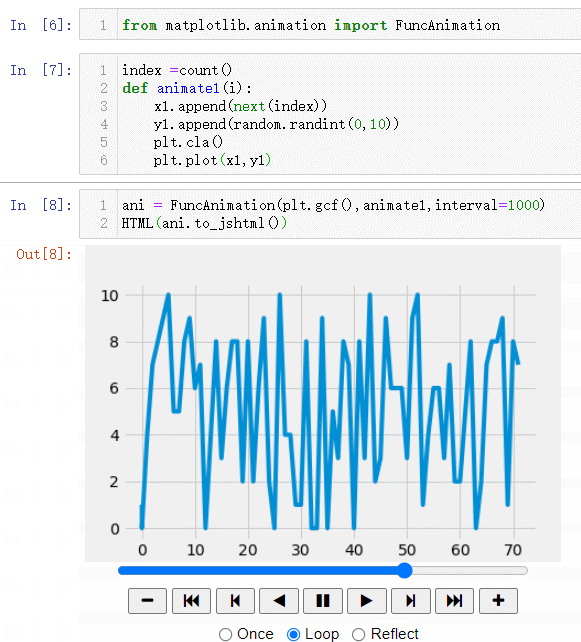
2.9.2 ¶ҜКЦКөІЩ
ЙПГжК№УГөДКэҫЭ¶јКЗЛж»ъІъЙъөДЛж»ъКэ,ҪУПВАҙҫНКЗҙҙҪЁТ»ёцОДјю,ФЩҪ«ЙъіЙөДКэҫЭТ»ЦұЧ·јУөҪёГОДјюЦР,ДЈДв¶ҜМ¬КөКұКэҫЭ
јЩ¶ЁФӨЙъіЙөДКэҫЭОӘ№ЙЖұКэҫЭ,xОӘРтәЕ,y1ОӘappleөД№ЙјЫ;y2ОӘgoogleөД№ЙјЫ;y3О»amazonөД№ЙјЫ,xөД»щКэОӘ0,y1-y3өД»щКэ¶јКЗ1000,јҙЙъіЙөДКэҫЭ»гЧЬРтәЕКЗҙУ1ҝӘКј,y1-y3өДКэЦөФЪ1000ЙППВёЎ¶Ҝ
import csv
import random
import time
x_value = 0
y1 = 1000
y2 = 1000
y3 = 1000
#ЙиЦГОДјюөДЧЦ¶ОГыіЖ
fieldname=["x","y1","y2","y3"]
#ПИҪ«ЧЦ¶ОГыіЖРҙИлcsvОДјю»гЧЬ
with open('data110.txt','w') as csvfile:
csv_w = csv.DictWriter(csvfile,fieldnames=fieldname)
csv_w.writeheader()
#ФЩНЁ№эОЮПЮСӯ»·өД·ҪКҪПлҙҙҪЁөДОДјюЦРРҙИлКэҫЭ
while True:
with open('data110.txt','a') as csvfile:
csv_w = csv.DictWriter(csvfile,fieldnames=fieldname)
info = {
"x" : x_value,
"y1" : y1 ,
"y2" : y2 ,
"y3" : y3 ,
}
x_value +=1
y1 = y1 + random.randint(-10,10)
y2 = y2 + random.randint(-5,5)
y3 = y3 + random.randint(-15,15)
csv_w.writerow(info)
time.sleep(0.3)
ҙъВлЦҙРРәуОДјюЦРКдіцөДҪб№ыОӘ:(Ц»ҪШИЎІҝ·Ц,ГҝҙОЛўРВҫН»бУРРВөДКэҫЭІъЙъ,ЙиЦГөДЛўРВКұјдОӘ0.3Гл)

ҪУЧЕҫНКЗ¶БИЎЙъіЙөДКэҫЭҪшРР»жЦЖНјРО,әҜКэЦР»сИЎКэҫЭКЗНЁ№э¶БИЎCsvОДјю,И»әуЦё¶ЁxТФј°ТӘ»жЦЖөДy,ЧоЦХЙъіЙөДҪб№ыИзПВ
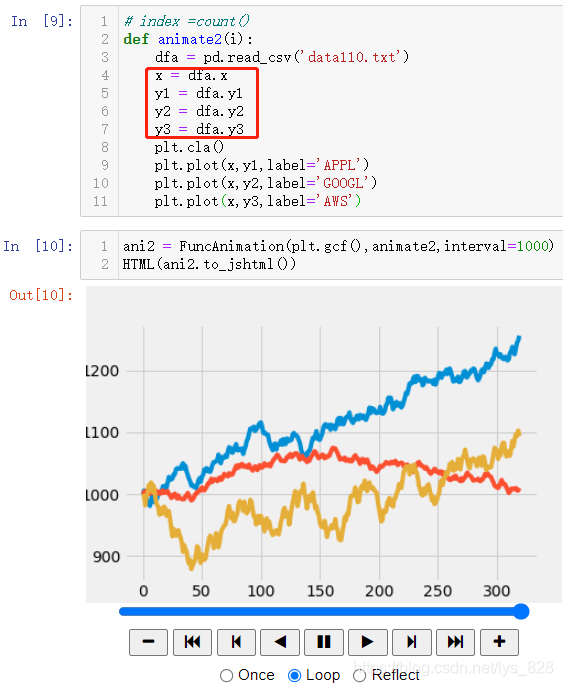
2.10 НјұнөД¶аЦШ»жЦЖ
әЛРДҙъВл:plt.subplots()/fig.add_subplot()/plt.subplot2grid()
НјұнөД¶аЦШ»жЦЖ,јҙКЗ¶ФЧУНјөД»жЦЖ,Ц®З°өД»жНј¶јКЗ°С¶аМхДЪИЭ·ЕФЪТ»ёцНјРОЙП,ҪУПВАҙҪйЙЬ°СГҝТ»ёц¶ФУҰөДДЪИЭ·ЕФЪТ»ёцЧУНјЙПЎЈ»Ш№ЛТ»ПВФӯАҙ»жЦЖөДНјПс№эіМ
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("fivethirtyeight")
data = pd.read_csv("data11.csv")
data.head()
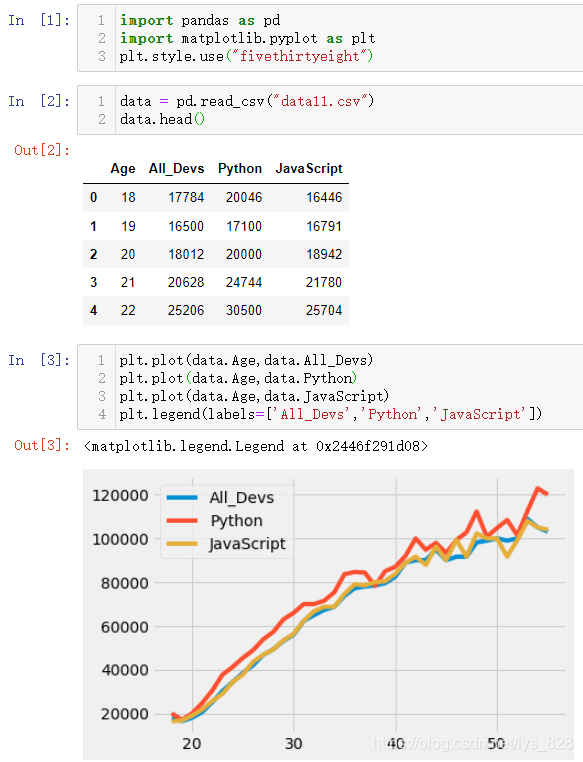
plt.plot(data.Age,data.All_Devs)
plt.plot(data.Age,data.Python)
plt.plot(data.Age,data.JavaScript)
plt.legend(labels=['All_Devs','Python','JavaScript'])
КдіцҪб№ыИзПВ:(ЛщУР»жЦЖөДХЫПЯҫщФЪТ»ХЕНјЙП)
2.10.1 НЁ№эplt.subplots»жЦЖЧУНј
Из№ыТӘ°СГҝТ»НјАэ¶ФУҰөДНјПсөҘ¶АҪшРР»жЦЖ,РиТӘБЛҪвТ»ПВplt»жЦЖНјПсөД№№іЙ,ЦұҪУ»жЦЖҫНПаөұУЪКЗТ»ёцfig,И»әуfigАпГжҝЙТФУР¶аёцaxЧйіЙ,axЙПГжҝЙТФ»жЦЖНјРО,ТтҙЛТІҫНҝЙТФУГ»жЦЖЧУНј,ПИҝҙplt.subplots()»жЦЖ1РР3БРөДҪб№ы·ө»ШөД¶ФПуҪб№ы,КдіцИзПВ

¶ФУҰБҪёцұдБҝ,ЖдЦРfigҫНКЗЦёХыёц»жНјөДҙуИЭЖч,°ьә¬БЛЛщУРөДax
axҫН¶ФУҰЦё¶ЁөДёчЧУНј,КэҫЭАаРНҫНКЗТ»ёцarrayБРұн

Т»°гЦӘөАТӘ»жЦЖөДРРәНБР¶јКЗЧФ¶ЁТеКдИл,ТтҙЛЙъіЙөДЧУНјКэБҝҫНТСҫӯЗеіюБЛ,ЛщТФҪЁТйК№УГТ»ёцФӘЧжөД·ҪКҪҪ«¶ФУҰөДЧУНј·ЦұрёіЦөёш¶ФУҰөДұдБҝ,ХвСщҝЙТФјхЙЩЦШёҙөДҙъВл,КҫАэИзПВ
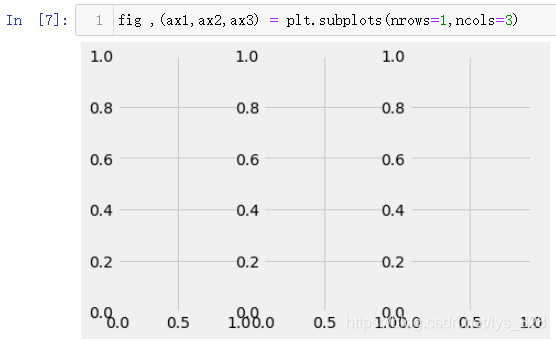
АыУГҙҙҪЁөДЧУНј,Ҫ«КэҫЭ»жЦЖФЪ¶ФУҰөДО»ЦГЙП,ҙъВлИзПВ
fig ,(ax1,ax2,ax3) = plt.subplots(nrows=1,ncols=3)
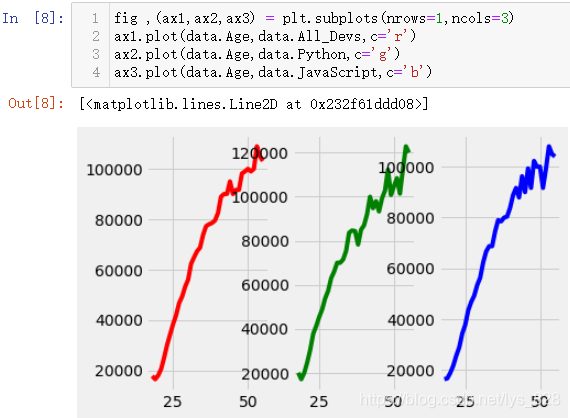
ax1.plot(data.Age,data.All_Devs,c='r')
ax2.plot(data.Age,data.Python,c='g')
ax3.plot(data.Age,data.JavaScript,c='b')
КдіцҪб№ыОӘ:(ЦұҪУіцөДНј»бұИҪПҙЦІЪ,ҝЙТФҝҙіцНјПсЦ®јд№эУЪҪфГЬ)
°ҙХХЦ®З°ҪйЙЬөДөЪТ»ЦЦ·ҪКҪА©ҙу»ӯІјҝҙҝҙР§№ы,ҙъВлЦёБо:plt.figure(figsize=(12,8)),КдіцҪб№ыЦР·ўПЦХвРРЦёБоФЪҙЛҙҰГ»УРЙъР§,ФӯТтҫНФЪУЪПВГж»жЦЖөДХвХЕНј¶јКЗТФfigПВөДЧУНјaxҪшРР»жЦЖ,ІўІ»КЗЦұҪУНЁ№эpltҪшРР»жЦЖ,ОЮ·ЁёДұдНјПсөД»ӯІјҙуРЎ,Н¬Ан¶ФУЪНјАэөДМнјУТІКЗ
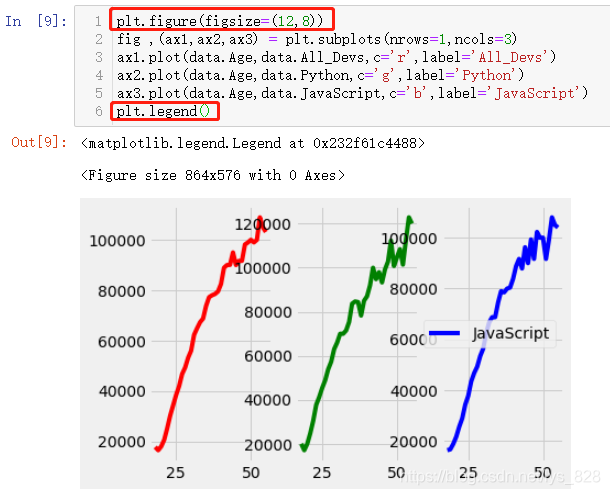
ХэИ·өДІЩЧчКЗФЪplt.subplots()әҜКэЦРЦё¶Ё»жЦЖ»ӯІјөДІОКэ,НЁ№эax»жЦЖНјАэ
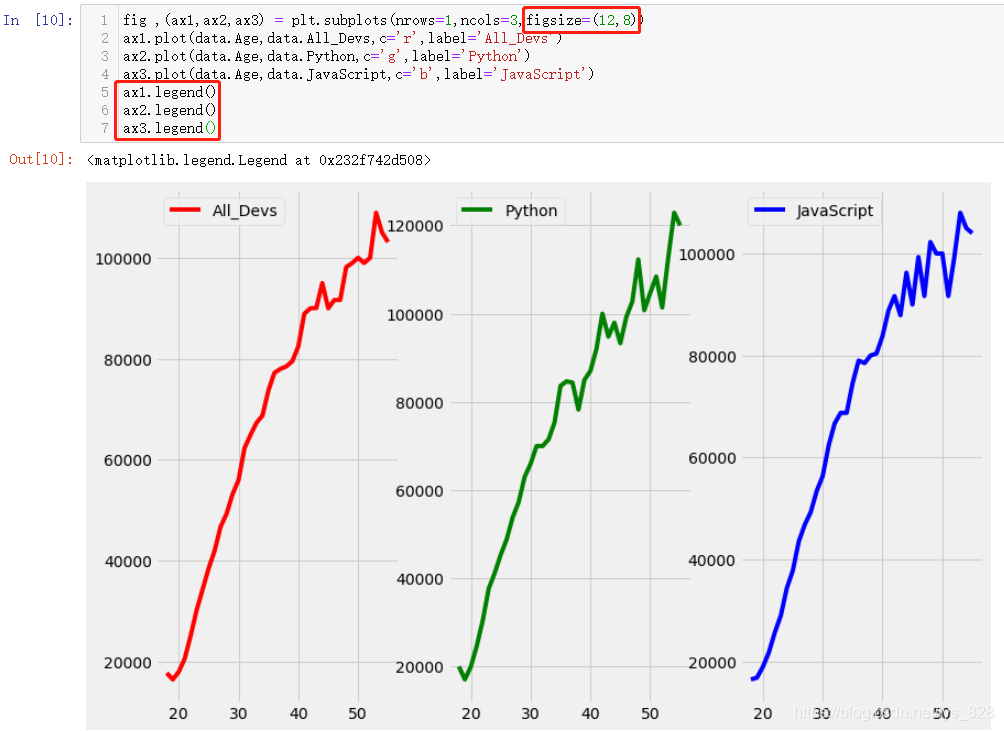
¶аХЕЧУНј·ЕФЪН¬Т»РР»тХЯН¬Т»БРЧФ¶ҜҫНРОіЙБЛТ»ЦЦ¶ФұИ,ОӘБЛёьН»іцұЛҙЛЦ®јдөДІоТм,УҰёГУРТ»ёцО¬¶ИөДІОХХұкЧјКЗПаН¬өД,ұИИз¶ј·ЕФЪРР,¶ФұИЧФИ»КЗyЦө;Из№ы·ЕЦГФЪН¬Т»БР,¶ФұИөДҫНКЗxЦө,ТтҙЛУРұШТӘҪ«ТӘ¶ФұИөДО¬¶ИұкЧј»ҜОӘНіТ»,РиТӘУГөҪөДІОКэОӘ:sharexәНshareyЎЈКдіцҪб№ыИзПВ,ТФpythonОӘЦчТӘјјДЬөДРҪЧКТӘұИХыёцұаіМРРТөәНJSөДРҪЧКөДЧоҙуЦө¶јёЯ
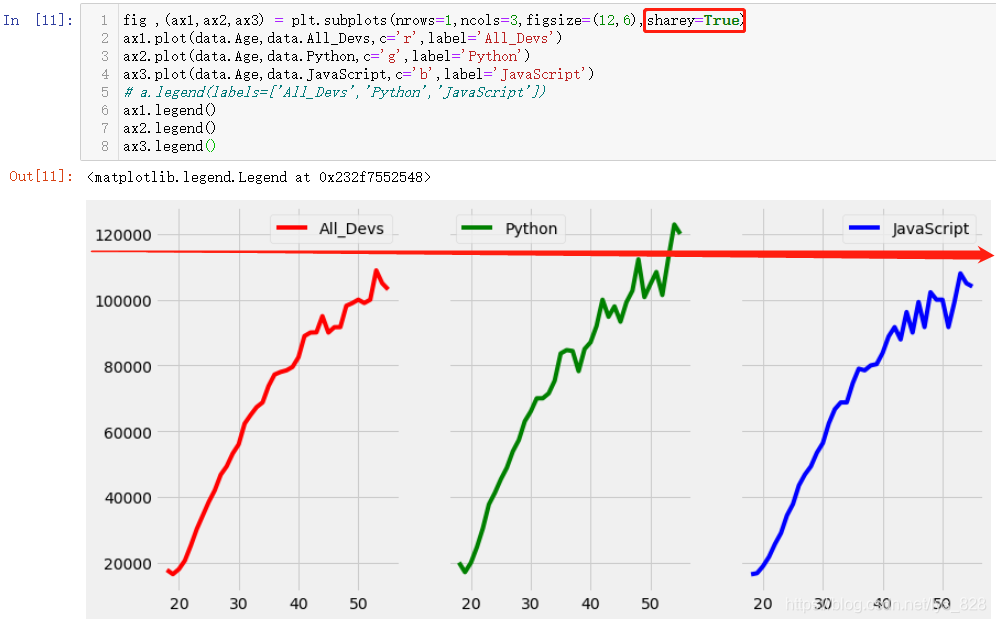
»жНјөД·зёсҝЙТФЧФРРҪшРРЗР»»,З°ГжТСҫӯҪйЙЬ№эИзәОК№УГДЪЦГөДТ»Р©»жНј·зёс,ұИИзЗР»»іЙОӘseaborn,ЕЕБРөД·ҪКҪұдіЙ1РР3БР(ХвАпД¬ИПҫНКЗТСҫӯxЦбҝМ¶И·¶О§Т»ЦВ,ТІҫНІ»УГЦё¶ЁsharexІОКэ,ЖдЛьСщКҪөДіцНјТІҝЙТФКФКФ,ХТёцЧФјәЗгПтөДјҙҝЙ)
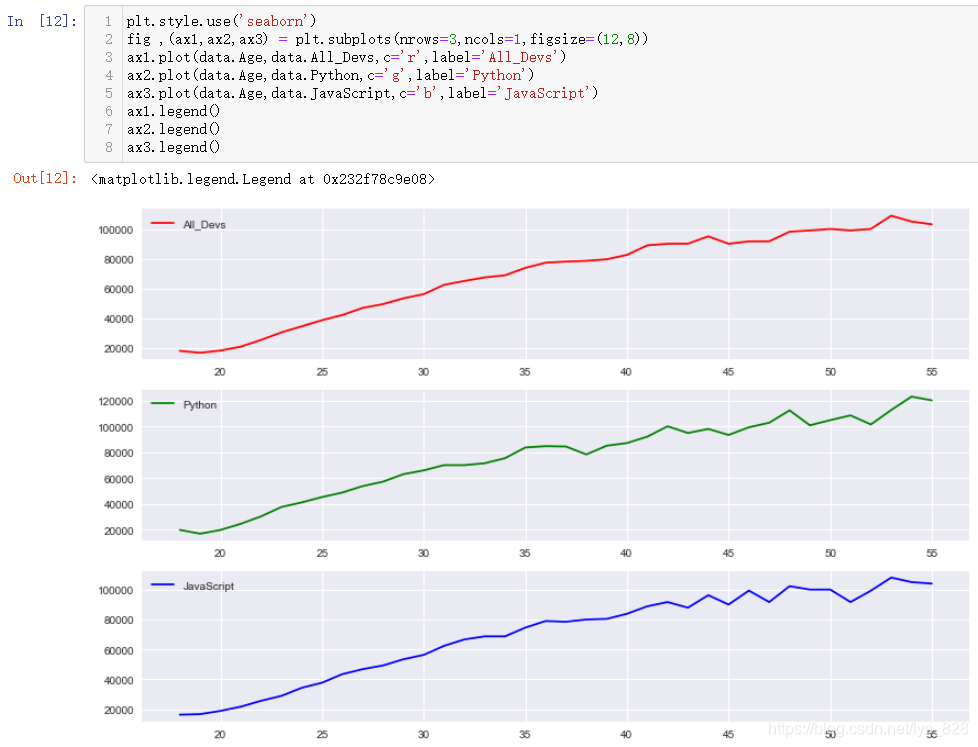
2.10.2 НЁ№эfig.add_subplot»жЦЖЧУНј
ХвЦЦ·ҪКҪКЗПИҪ«НјПсКөАэ»Ҝ,И»әуФЪПт¶ФПуЦРМнјУЧУНј
fig = plt.figure(figsize=(12,6))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(212)
КдіцҪб№ыОӘ:(әҜКэЦРөДКэЧЦҪвКН:ax1әНax2ЛщФЪРРөДҙъВлұнКҫ»жЦЖ2РР2БРЦРөЪ1РРөДөЪ1ёцәНөЪ2ёцөДО»ЦГНјРО,ЦчТӘТЙ»уөгФЪУЪөЪИэРРҙъВлұнКҫ»жЦЖ2РР1БРөЪ2РРөДО»ЦГ,ХвАпөД1БРҫНКЗҪ«ЙПГж»жЦЖөД2ёцНјРОҝҙіЙБЛТ»ёцХыМе)
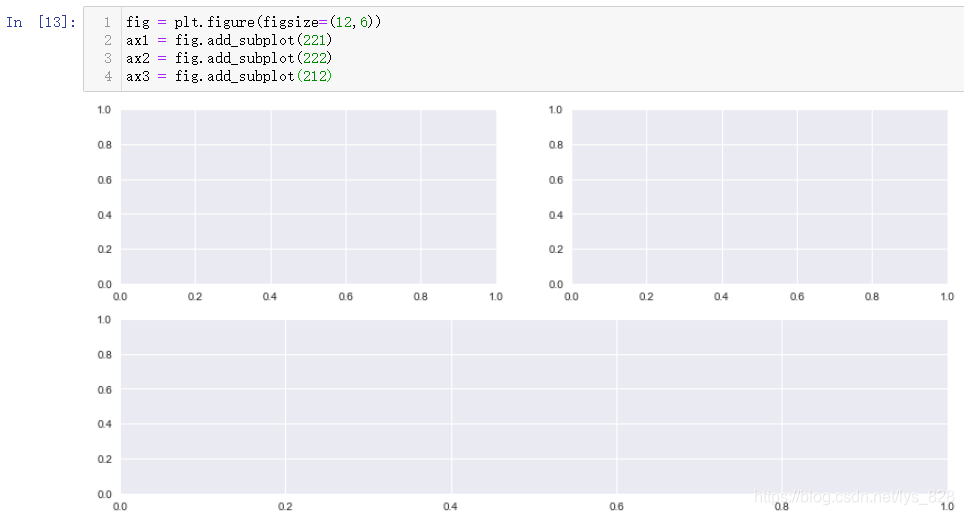
И»әу»щУЪҙЛ»жЦЖЧУНј,КдіцҪб№ыИзПВ(јИИ»figКЗКөАэ»ҜөД¶ФПу,ЦұҪУҝЙТФК№УГЛьөчУГПФКҫНјАэөДәҜКэ,ө«КЗЧоЦХөГР§№ыКЗ°СЛщУРөДНјАэ·ЕФЪБЛТ»Жр,Из№ыТӘөҘ¶АПФКҫНјАэ»№КЗРиТӘөҘ¶ЛК№УГaxҪшРРЦё¶Ё)
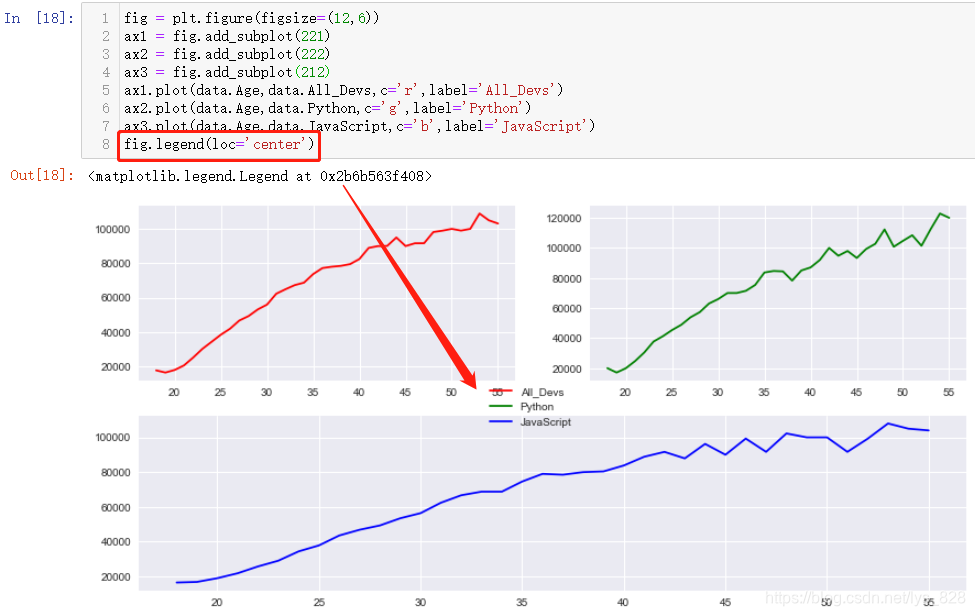
өҘ¶АК№УГaxЦё¶ЁНјАэ,КдіцҪб№ыИзПВ(ХвКұәтҫНГ»УРЗ°ГжөДәҜКэөД№ІПнxЦб»тХЯyЦбөДІОКэ,ХвЦЦ·Ҫ·ЁөДК№УГЦчТӘФЪУЪО»ЦГІјҫЦЙПУРУЕКЖ)
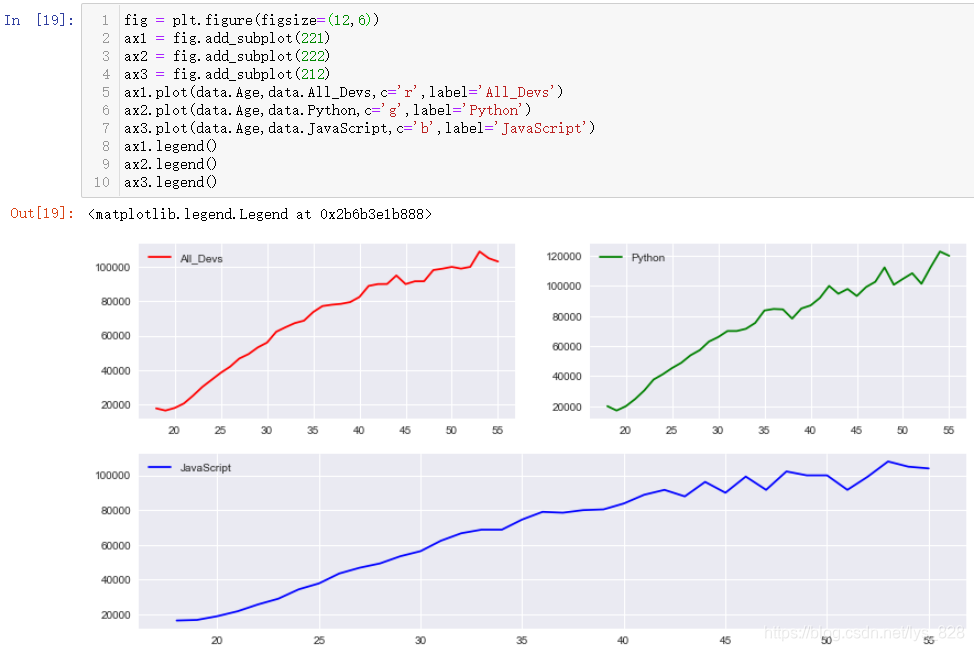
2.10.3 НЁ№эplt.subplot2grid»жЦЖЧУНј
НЁ№эөЪ2ЦЦ·ҪКҪ»жНј,УРТ»ёцәЬИЭТЧёгГФәэөДөгҫНКЗҪшРРҝзРР»тХЯҝзБРәПІў,ТтҙЛОӘБЛК№өГХвёц№эіМёьЗеОъ,ҝЙТФҝјВЗК№УГplt.subplot2grid·ҪКҪҪшРРО»ЦГІјҫЦ,ЦұҪУёшіцҙъВлКҫАэ
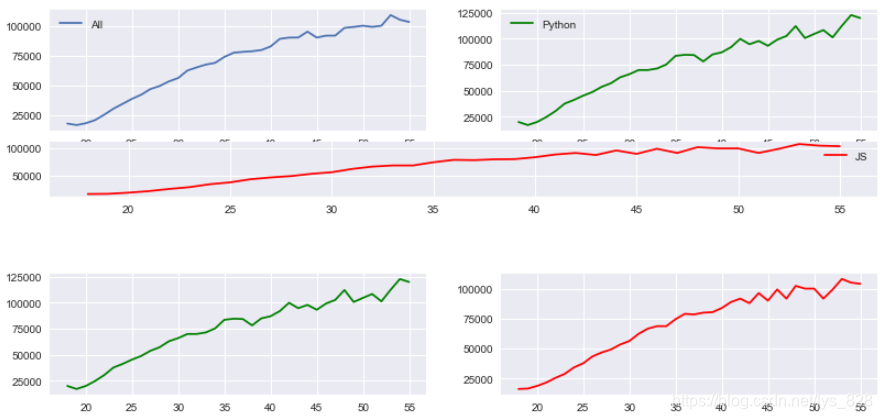
fig = plt.figure(figsize=(12,6))
ax1 = plt.subplot2grid((6,2),(0,0),rowspan=2,colspan=1)
ax2 = plt.subplot2grid((6,2),(0,1),rowspan=2,colspan=1)
ax3 = plt.subplot2grid((6,2),(2,0),rowspan=1,colspan=2)
ax4 = plt.subplot2grid((6,2),(4,0),rowspan=2,colspan=1)
ax5 = plt.subplot2grid((6,2),(4,1),rowspan=2,colspan=1)
ax1.plot(data.Age,data.All_Devs,label='All')
ax2.plot(data.Age,data.Python,label='Python',color='g')
ax3.plot(data.Age,data.JavaScript,label='JS',color='r')
ax4.plot(data.Age,data.Python,label='Python',color='g')
ax5.plot(data.Age,data.JavaScript,label='JS',color='r')
ax1.legend()
ax2.legend()
ax3.legend()
КдіцҪб№ыОӘ:(әҜКэЦРөДөЪТ»ёцІОКэ(6,2)КЗЦё¶ЁТӘ»жЦЖөДНјРОРРәНБР,№І6РР2БР;өЪ¶юёцІОКэҫНКЗНјРО»жЦЖөДЖрКјО»ЦГ,ұИИз(0,0),ҙъұнөЪ1РРөЪ1БРөДО»ЦГ;өЪ3,4ёцІОКэҫНКЗНјРОҝз№эөДРРәНБРөДКэБҝ,ұИИзrowspan=2,colspan=1ҙъұнНјРОҝз2РР,Ц»Хј1БРЎЈax3»жЦЖөДНјРОҪвОц:»жЦЖөДНјПс¶јКЗФЪ6РР2БРөД»ӯІјЙП,ЖрКјөгФЪөЪ3РРөЪ1БР,И»әуҝз1РРҝз2БР)
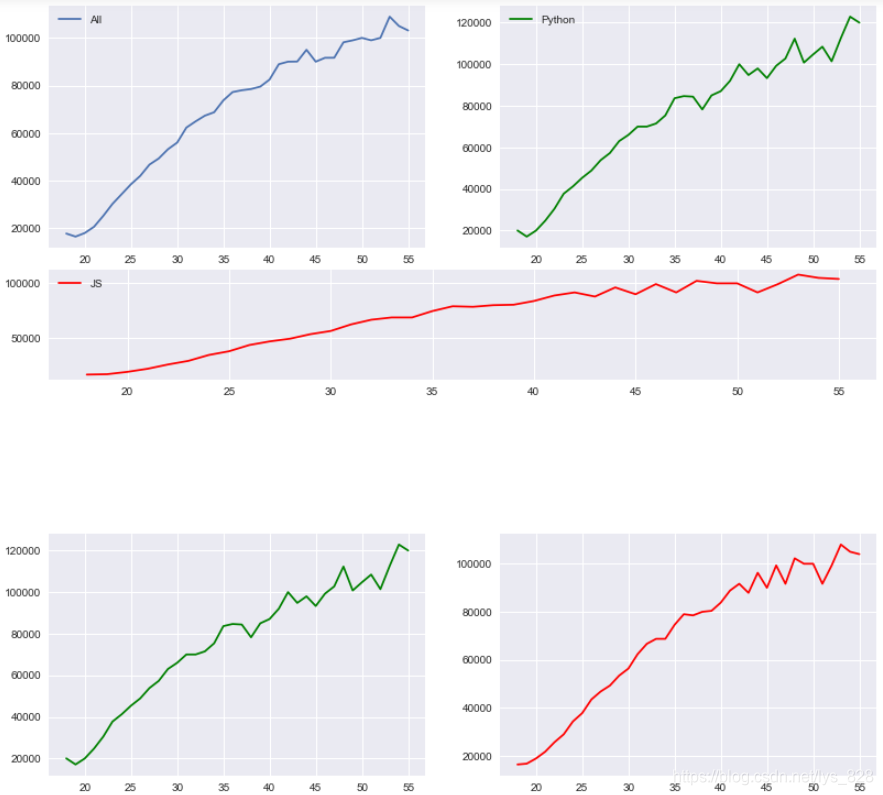
НЁ№эЙПНј·ўПЦөЪ3ёцНјПс°СЙПГжөЪ1,2НјПсөДxЦбҝМ¶ИРЕПўёІёЗБЛ,ХвЦЦҝЙТФіўКФНЁ№эЦё¶Ё»ӯІјҙуРЎҪшРРҪвҫц,КдіцИзПВ(ұИИзЦё¶Ёfigsize=(12,10),ТІҫНКЗФцјУТ»ПВНјРОөДёЯ¶И,ЧФИ»ФЪЧЭПтЙПҫНУөј·БЛ)
ТФЙПҫНКЗ№ШУЪMatplotlib»жНјЦӘК¶өгөДИ«ІҝКбАн,өұИ»К№УГmatplotlib»жНјөДСщКҪІ»Ц№ХвГҙ¶а,ёь¶аөДНјРОәНСщКҪ¶јҝЙТФНЁ№э№ЩНшёшөДНјРОТСҫӯ¶ФУҰөДФҙҙъВл»сИЎөҪ,УРРЛИӨөДҝЙТФФЩҝҙҝҙ№Щ·ҪөДКҫАэ:Matplotlib№Щ·ҪКҫАэНјҝв
НкҪбИц»Ё,??©c(ЎгЁҢЎг)ҘО?