ИпЫЙЛьКЯЬхЕФЪ§бЇИХФю
ИпЫЙЛьКЯЬхЪЧгЩШєИЩИіИпЫЙЫцЛњБфСПЯпадзщКЯЖјГЩ,БэЪОЮЊ
GMM
=
ЁЦ
k
=
1
K
ІС
k
?
G
a
u
s
s
i
a
n
k
?
,
?
ЁЦ
k
ІС
k
=
1
?
,
?
ІС
k
>
0
?
,
?
?
ІС
k
\text{GMM} = \sum_{k=1}^K \alpha_k \cdot Gaussian_k\ ,\ \sum_k \alpha_k =1\ ,\ \alpha_k>0\ ,\ \forall \alpha_k
GMM=k=1ЁЦK?ІСk??Gaussiank??,?kЁЦ?ІСk?=1?,?ІСk?>0?,??ІСk?
га
K
K
KИіЗжСП,вВГЦДиЁЃИУФЃаЭжївЊУцЯђОлРрШЮЮё,ЛљБОЙлЕуЮЊЁАЪ§ОнДгФГвЛДиЩњГЩЁБЁЃЖдгкаТЪфШыЕФЪ§Он,ашвЊФЃаЭИјГіЪєгкФФвЛИіДиЕФХаЖЯЁЃ
ЩњГЩGMMЗжВМФЃаЭ
ашвЊжИЖЈЕФВЮЪ§га:ДиЕФЪ§СП
K
K
K,ИїДиЕФОљжЕ(ЮЛжУ)
ІЬ
i
\mu_i
ІЬi?ЁЂаЗНВюОиеѓ(вђЮЊЪЧЖўЮЌ)вдМАЛьКЯБШР§ЯђСП
ІС
\alpha
ІСЁЃПМТЧЕНЯожЦЬѕМў
ІВ
k
ІС
k
=
1
?
,
?
ІС
k
>
0
?
,
?
?
ІС
k
\Sigma_k \alpha_k=1 \ ,\ \alpha_k>0\ ,\ \forall \alpha_k
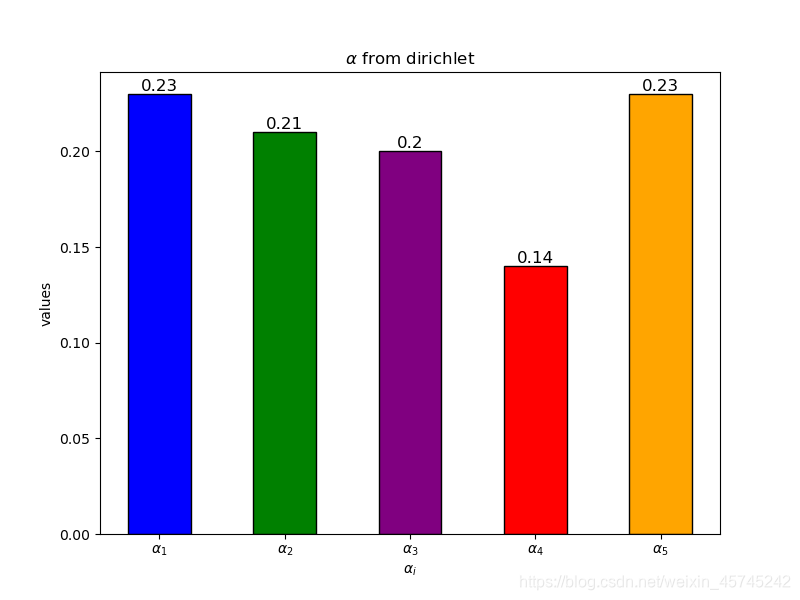
ІВk?ІСk?=1?,?ІСk?>0?,??ІСk?,бЁдёДгЕвРћПЫРзЗжВМnp.random.dirichletЩњГЩ
ІС
\alpha
ІС,ТњзуЯожЦЬѕМўЁЃГігкМђЕЅЪЕбщЕФФПЕФ,жБНгжИЖЈСЫ
ІЬ
?
,
?
c
o
v
\mu\ ,\ cov
ІЬ?,?cov,ЪЕМЪЩЯвВПЩвдЫцЛњжИЖЈ,ТњзуИїЗжСПаЗНВюОиеѓе§ЖЈМДПЩЁЃ
МьбщФЃаЭ
НЋФЃаЭЩњГЩЕФЪ§ОнгыНтЮіЪ§ОнЗХдквЛЦ№ПЩЪгЛЏЁЃ
ДњТы
import math
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import mixture
from matplotlib.colors import LogNorm
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
%matplotlib
#бљБОЪ§СП
n_samples = 20000
#ЗжСПЪ§СП
K=5
#ОљжЕОиеѓ
mu = np.array([[0, 0],[10, 0],[5, 5],[0, 10],[10, 10]])
#аЗНВюОиеѓ
cc = np.array([1,0.2,0.2,1,1,0.4,0.4,1,1,0,0,1,1,-0.6,-0.6,1,1,-0.8,-0.8,1])
cov = cc.reshape((5,2,2))
cov_inverse = np.linalg.inv(cov)#гУгкКѓајЩњГЩНтЮіЪ§Он
#ШЈжиОиеѓ
alpha = np.random.dirichlet(np.array([3,4,5,6,7]))
#ЫцЛњЪ§ОнзАди
gmm_0 = np.random.multivariate_normal(mu[0],cov[0],n_samples)
gmm_1 = np.random.multivariate_normal(mu[1],cov[1],n_samples)
gmm_2 = np.random.multivariate_normal(mu[2],cov[2],n_samples)
gmm_3 = np.random.multivariate_normal(mu[3],cov[3],n_samples)
gmm_4 = np.random.multivariate_normal(mu[4],cov[4],n_samples)
GMM = np.vstack([gmm_0,gmm_1,gmm_2,gmm_3,gmm_4])
#ВщПДдЪМЪ§Он
#figure 1: ШЈжиЯђСП alpha
alpha_d = np.around(alpha,decimals=2)
fig = plt.figure(1,figsize=(8,6))
ax = fig.add_subplot(111,title=r"$\alpha$ from dirichlet")
name = [r"$\alpha_1$",r"$\alpha_2$",r"$\alpha_3$",r"$\alpha_4$",r"$\alpha_5$"]
df = pd.DataFrame({"index":name,"value":alpha_d})
ax.bar(data=df,x="index",height="value",width=0.5,color=["blue","green","purple","red","orange"],edgecolor='black')
ax.set_xlabel(r"$\alpha_i$")
ax.set_ylabel("values")
for idx, text in zip(name, alpha_d):
ax.text(idx, text, text, ha='center', va='bottom',fontsize=12)
#figure 2: gmmИїЗжСПЁЂgmmКЯВЂЕЋЮДФтКЯЕФЦНУцжБЗНЭМ
fig = plt.figure(2,figsize=(15,12))
grid_size=int(n_samples/400)
ax = fig.add_subplot(231,aspect='equal',title=r"$gmm_1$")
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.hexbin(x=gmm_0[:,0],y=gmm_0[:,1],gridsize=grid_size,cmap='viridis')
ax = fig.add_subplot(232,aspect='equal',title=r"$gmm_2$")
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.hexbin(x=gmm_1[:,0],y=gmm_1[:,1],gridsize=grid_size,cmap='viridis')
ax = fig.add_subplot(233,aspect='equal',title=r"$gmm_3$")
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.hexbin(x=gmm_2[:,0],y=gmm_2[:,1],gridsize=grid_size,cmap='viridis')
ax = fig.add_subplot(234,aspect='equal',title=r"$gmm_4$")
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.hexbin(x=gmm_3[:,0],y=gmm_3[:,1],gridsize=grid_size,cmap='viridis')
ax = fig.add_subplot(235,aspect='equal',title=r"$gmm_5$")
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.hexbin(x=gmm_4[:,0],y=gmm_4[:,1],gridsize=grid_size,cmap='viridis')
ax = fig.add_subplot(236,aspect='equal',title="Gaussians before mixing")
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.hexbin(x=GMM[:,0],y=GMM[:,1],gridsize=grid_size,cmap='viridis')
#МгдиФЃаЭ,ФтКЯ
#KИіЗжСП
#covariance_type = full УПИіЗжСПОпгаздМКЕФаЗНВюОиеѓ
#init_paramas ='kmeans' ЪЙгУ kmeansЗНЗЈФтКЯ
#weights_init = alpha жИЖЈШЈжиОиеѓ
#means_init = mu жИЖЈИїЗжСПжааФ
"""
ЮЊsklearn.mixture.GaussianMixtureжИЖЈжкЖрВЮЪ§ЪЧЮЊСЫИќОЋзМЕФФтКЯ,
ВЂЗЧЮЊСЫМьВтИУЗжРрЦїадФм,
ЖјЪЧдкжЎКѓЪЙгУИУФЃаЭЩњГЩЪ§ОнЗўЮёгкЦфЫћБДвЖЫЙШЮЮё,
ГЩЮЊЦфЫћЭЦРэЗНЗЈЕФВЮееЁЃ
"""
model = mixture.GaussianMixture(n_components=K, covariance_type='full',init_params='kmeans',weights_init=alpha,means_init=mu)
model.fit(GMM)
#ВщПДGMMдЄВтЕФИКЖдЪ§ЫЦШЛКЏЪ§жЕ model.score_samples
x = np.linspace(-100,100,1000)
y = np.linspace(-100,100,1000)
X, Y = np.meshgrid(x, y)
XX = np.array([X.ravel(), Y.ravel()]).T
Z = -model.score_samples(XX)
Z = Z.reshape(X.shape)
#ЛцжЦЕШИпЭМВщПДИК log-liklihood дЄВтжЕ
fig = plt.figure(3,figsize=(8,6))
ax = fig.add_subplot(111,aspect='equal',title='Negative log-likelihood predicted by a GMM')
ax.set_xlabel('x')
ax.set_ylabel('y')
CS = ax.contourf(X, Y, Z,cmap='YlGnBu', levels=25)
plt.colorbar(CS, shrink=0.8, aspect=10)
sample_test, index = model.sample(10000)
fig = plt.figure(4,figsize=(20,6))
#GMMФЃаЭжаИїЗжСПЕФОљжЕ
ax = fig.add_subplot(131,title='model means',aspect='equal')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.scatter(x=model.means_[:,0],y=model.means_[:,1],c='r')
#ВщПДДгGMMФЃаЭЩњГЩЕФЪ§Он model.samples
ax = fig.add_subplot(132,title="model sample")
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.hexbin(x=sample_test[:,0],y=sample_test[:,1],gridsize=grid_size,cmap='jet')
#зМБИНтЮіЪ§Он
#ЩшжУБпНч:е§ИК 3Ів
bound = list((
mu[0,0]-3*cov[0,0,0], mu[0,0]+3*cov[0,0,0], mu[0,1]-3*cov[0,1,1], mu[0,1]+3*cov[0,1,1],
mu[1,0]-3*cov[1,0,0], mu[1,0]+3*cov[1,0,0], mu[1,1]-3*cov[1,1,1], mu[1,1]+3*cov[1,1,1],
mu[2,0]-3*cov[2,0,0], mu[2,0]+3*cov[2,0,0], mu[2,1]-3*cov[2,1,1], mu[2,1]+3*cov[2,1,1],
mu[3,0]-3*cov[3,0,0], mu[3,0]+3*cov[3,0,0], mu[3,1]-3*cov[3,1,1], mu[3,1]+3*cov[3,1,1],
mu[4,0]-3*cov[4,0,0], mu[4,0]+3*cov[4,0,0], mu[4,1]-3*cov[4,1,1], mu[4,1]+3*cov[4,1,1],
))
#ВНГЄ
step=0.1
#Ыїв§
x= np.arange(min(bound),max(bound),step)
y= np.arange(min(bound),max(bound),step)
X, Y = np.meshgrid(x,y)
#ЩњГЩЪ§Он
#1. K ИіЖРСЂЕФ 2 ЮЌИпЫЙ
Z_1 = 1/np.sqrt(2*math.pi*np.linalg.det(cov[0])) * np.exp(-1/2*((
X-mu[0,0])**2*cov_inverse[0,0,0]
+(X-mu[0,0])*(Y-mu[0,1])*cov_inverse[0,1,0]
+(Y-mu[0,1])*(X-mu[0,0])*cov_inverse[0,0,1]
+(Y-mu[0,1])**2*cov_inverse[0,1,1]
))
Z_2 = 1/np.sqrt(2*math.pi*np.linalg.det(cov[1])) * np.exp(-1/2*((
X-mu[1,0])**2*cov_inverse[1,0,0]
+(X-mu[1,0])*(Y-mu[1,1])*cov_inverse[1,1,0]
+(Y-mu[1,1])*(X-mu[1,0])*cov_inverse[1,0,1]
+(Y-mu[1,1])**2*cov_inverse[1,1,1]
))
Z_3 = 1/np.sqrt(2*math.pi*np.linalg.det(cov[2])) * np.exp(-1/2*((
X-mu[2,0])**2*cov_inverse[2,0,0]
+(X-mu[2,0])*(Y-mu[2,1])*cov_inverse[2,1,0]
+(Y-mu[2,1])*(X-mu[2,0])*cov_inverse[2,0,1]
+(Y-mu[2,1])**2*cov_inverse[2,1,1]
))
Z_4 = 1/np.sqrt(2*math.pi*np.linalg.det(cov[3])) * np.exp(-1/2*((
X-mu[3,0])**2*cov_inverse[3,0,0]
+(X-mu[3,0])*(Y-mu[3,1])*cov_inverse[3,1,0]
+(Y-mu[3,1])*(X-mu[3,0])*cov_inverse[3,0,1]
+(Y-mu[3,1])**2*cov_inverse[3,1,1]
))
Z_5 = 1/np.sqrt(2*math.pi*np.linalg.det(cov[4])) * np.exp(-1/2*((
X-mu[4,0])**2*cov_inverse[4,0,0]
+(X-mu[4,0])*(Y-mu[4,1])*cov_inverse[4,1,0]
+(Y-mu[4,1])*(X-mu[4,0])*cov_inverse[4,0,1]
+(Y-mu[4,1])**2*cov_inverse[4,1,1]
))
#2. ИљОн alpha зіЯпадзщКЯ(ЛьКЯ)
GMM_SUM = Z_1*alpha[0] + Z_2*alpha[1] + Z_3*alpha[2] + Z_4*alpha[3] + Z_5*alpha[4]
#3. ЛцЭМ:3dБэУцЭМ,зјБъУцЩЯгаЕШИпЯпЭЖгА
ax = fig.add_subplot(133,projection='3d',title='GMM analytical 3d surface')
ax.plot_surface(X, Y, GMM_SUM, lw=2,rstride=1, cstride=1, cmap='jet', alpha=0.8)
cset = ax.contour(X,Y,GMM_SUM,zdir='x',offset=-Y.min() if Y.min()>0 else Y.min(),cmap='coolwarm')
cset = ax.contour(X,Y,GMM_SUM,zdir='y',offset=X.max() if X.max()>0 else -X.max(),cmap='coolwarm')
cset = ax.contour(X,Y,GMM_SUM,zdir='z',offset=-abs(GMM_SUM).max(),cmap='coolwarm')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.set_xlim(X.min(),X.max())
ax.set_ylim(Y.min(),Y.max())
ax.set_zlim(-abs(GMM_SUM).max(),abs(GMM_SUM).max())
plt.show()
дЫааНсЙћЮЊШєИЩеХЭМ:


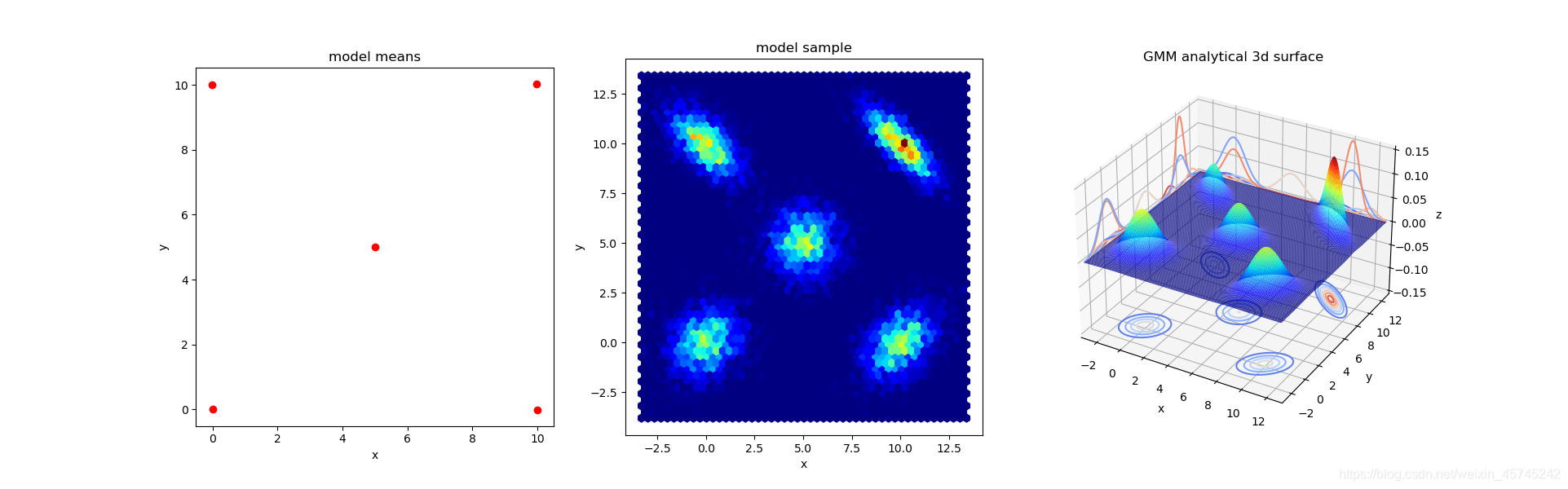
зюКѓвЛеХЭМЕФ3dФЃаЭПЩЭЈЙ§ЪѓБъЭЯЖЏа§зЊВщПДЁЃ
зюКѓ,ГЂЪдвЛЯТФЃаЭЖдаТЪ§ОнЕФдЄВт,ДгЭМЯёРДПД,ИїДиИННќЕФЕуЛсБЛБШНЯзМШЗЕидЄВтЕНИУДиЁЃ
test = model.predict([[2,2],[10,10]])
print(test)
дЫааНсЙћЮЊ:
[0 4]
ЭЈЙ§model.means_ВщПДФЃаЭЕФОљжЕШЗЖЈ0гы4ДњБэЕФДи,ЯрЗћЁЃ