1.主要目的
- 对数据进行分类统计
- 将统计后结果进行可视化
2.项目说明
2.1数据说明
已有某网店销售数据,数据中分别存储了用户名称、购买日期两列数据,部分数据如下: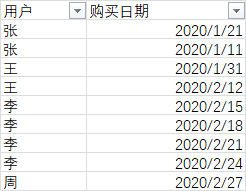
2.2要求说明
(1)统计每月客户人数有多少
统计的是每月客户数量。例如王先生在1月份有三次购买记录,统计客户数量时只能统计为一次。
(2)统计每月新客户人数有多少
每月的新客户是指在统计周期内当月新出现的,例如李先生在1月份有购买记录,则其算1月份的新客户,1月以后的各月均不能再统计李先生。
3.项目代码
import pandas as pd
import matplotlib.pyplot as plt
# 设置字体样式,用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
#********************************************************************
#(1)计算每月新增客户和总客户
#读取文件数据,选取用到的4列
data=pd.read_excel('./新增客户-精简01.xlsx')
df=data.copy()
#按月对数据进行分组
grouper=pd.Grouper(key='购买日期',freq='M')
df1_list=list(df.groupby(grouper))
#用两个列表,分别存储月份及每月客户数
date1,customer1=[],[]
for i in df1_list:
date1.append(i[0].strftime('%Y-%m'))
customer1.append(i[1].drop_duplicates(subset=['用户'])['用户'].count())
#用列表生成dataframe,并重置索引
df1_result=pd.DataFrame(data=customer1,index=date1).reset_index()
df1_result.columns=['购买日期','每月客户总数']
#按购买日期对数据进行从小到大排序
df2=df.sort_values(by='购买日期')
#去重,只保留最早时间的买家,以便统计每月新增用户
df2.drop_duplicates(subset='用户',inplace=True)
df2_list=list(df2.groupby(grouper))
#用列表分别统计每月新增客户
date2,customer2=[],[]
for j in df2_list:
date2.append(j[0].strftime('%Y-%m'))
customer2.append(j[1]['用户'].count())
#用列表创建dataframe
df2_result=pd.DataFrame(data=customer2,index=date2).reset_index()
df2_result.columns=['购买日期','每月新客户总数']
#合并两个dataframe,合并类型很关键,如果两个df大小不一样,选错内、外连接会丢失数据
df3=pd.merge(df1_result,df2_result,on='购买日期')
#****************************************************************
#(2)将(1)的结果绘图
fig,axs=plt.subplots(figsize=(20,10))
df4=df3.set_index('购买日期')
#运用pandas的plot绘图
df4.plot(kind='bar',ax=axs)
df4.plot(kind='line',ax=axs)
#给图加标签
for x1,y1 in zip(range(len(df3['购买日期'])),df4['每月客户总数']):
axs.text(x1,y1+1,str(y1),ha='right',va='bottom',fontsize=14, rotation=45)
for x2,y2 in zip(range(len(df3['购买日期'])),df4['每月新客户总数']):
axs.text(x2,y2+0.5,str(y2),ha='left',va='bottom',fontsize=14, rotation=45)
plt.xlabel('日期',fontsize=16)
plt.ylabel('客户人数',fontsize=16)
plt.title('新增客户与总客户趋势图',fontsize=36)4.代码说明
4.1 统计部分
(1)引用模块,设置标签,读取数据,此部分较为常规,不再详述。
(2)数据分组
由于数据需要按月分组,因此使用了Grouper函数
#按月对数据进行分组
grouper=pd.Grouper(key='购买日期',freq='M')
df1_list=list(df.groupby(grouper))- class pandas.Grouper ( key = None,level = None,freq = None,axis = 0,sort = False ) [source]
| 参数: | key:string,默认为None groupby键,用于选择目标的分组列 level:名称/数字,默认为无 目标索引的级别 freq:string / frequency对象,默认为None 如果目标选择(通过key或level)是类似日期时间的对象, 则将按指定的频率进行分组。 有关可用频率的完整说明,请参见此处。 axis?:?轴的编号/名称,默认为0 sort:布尔值,默认为False 是否对生成的标签进行排序 额外的kwargs来控制类似时间的groupers(当``freq``通过时) closed??:?区间的封闭结束; 'left' 还是 'right' label?:?用于标记的区间边界;?'left'还是'right' convention:{'start','end','e','s'} 如果groupers是PeriodIndex base, loffset |
| 返回: | groupby指令的规范 |
| 链接: | ?https://www.cjavapy.com/article/161/ |
要区分grouper与groupby的区别,grouper返回的是分组规范,groupby返回的是groupby对象。
- DataFrame.groupby(self, by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)? ?
| 参数: | by??:?映射,功能,标签或标签列表 用于确定分组依据的分组。如果by是函数, 则在对象索引的每个值上调用它。 如果通过了 则将使用Series或dict VALUES来确定组 (将Series的值首先对齐;请参见 如果传递了 标签或标签列表可以按中的列传递给分组self。 注意,元组被解释为(单个)key。 axis?:?{ 沿 level?:?int,level名称或此类的序列,默认为 如果axis是MultiIndex(分层), 则按一个或多个特定级别分组。 as_index?:?bool,默认为 对于聚合输出,返回带有组标签的对象作为索引。 仅与DataFrame输入有关。
sort?:?布尔值,默认为True 排序组键。关闭此功能可获得更好的性能。请注意, 这不会影响每个组中观察的顺序。 Groupby保留每个组中行的顺序。 group_keys?:?布尔值,默认为 调用apply时,将组键添加到索引以识别片段。 squeeze?:?布尔值,默认为 如果可能,请减小返回类型的维数, 否则返回一致的类型。 observed?:?布尔值,默认为 仅当任何groupers为分类者时才适用。如果为 仅显示分类groupers的观测值。 如果为 0.23.0版中的新功能。 **kwargs 可选,仅接受关键字参数"mutated"并传递给groupby。 |
| 返回值: |
依赖于调用对象, 并返回包含有关组信息的groupby对象。 |
| 链接 | https://www.cjavapy.com/article/495/ |
- groupby分组依据是标签,即行标签或列标签,grouper能够在此基础上对标签内容进行分组。此项目中涉及到按月分组,是groupby函数单独无法实现的。
(3)分组后的统计
分组完成后,需要将groupby对象列表化,便于进行统计每月用户数,在此过程中,要对每月的数据用户进行去重。
(4)绘图
- 绘图结合了pandas.plot函数和matplotlib的plot函数,pandas的plot函数便于直接对dataframe进行画图,但文本标记较麻烦,且无法同时将两种类型图画到一个画布上(此点还存疑),而matplotlib的plot函数结合后,可实现该功能。两个plot函数略有不同,区分如下
- Pandas.DataFrame.plot()函数
- 详见:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.html
该函数主要直接用于pd中Series和DataFrame作图,较为方便,可直接作图。但涉及到布局/子图等,需要matplotlib的调用才行。
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False,
sharex=None, sharey=False, layout=None, figsize=None,
use_index=True, title=None, grid=None, legend=True,
style=None, logx=False, logy=False, loglog=False,
xticks=None, yticks=None, xlim=None, ylim=None, rot=None,
fontsize=None, colormap=None, position=0.5, table=False, yerr=None,
xerr=None, stacked=True/False, sort_columns=False,
secondary_y=False, mark_right=True, **kwds)
例1如下,df.plot()是一个<class 'matplotlib.axes._subplots.AxesSubplot'>类,还需要matplotlib才能显示图像
import pandas as pd
import numpy as np
df = pd.DataFrame([[1,2,3],[4,2,6],[5,4,7],[1,6,9],[5,8,8],],columns=['A','B','C'],index = np.arange(1,6))
df.plot.line()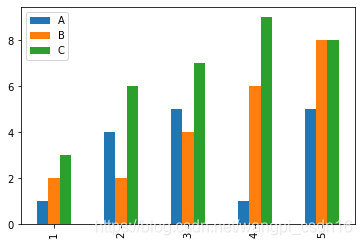
?
- ?matplotlib.pyplot.plot函数
matplotlib.pyplot.plot(*args, scalex=True, scaley=True, data=None, **kwargs)- 链接:https:
- //matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.plot.html#matplotlib.pyplot.plot
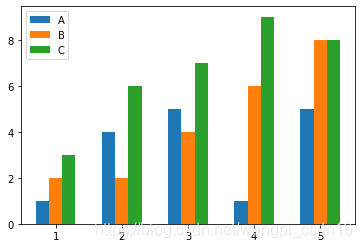
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.DataFrame([[1,2,3],[4,2,6],[5,4,7],[1,6,9],[5,8,8],],columns=['A','B','C'],index = np.arange(1,6))
#将要绘制的各列数据序列化
a=np.array(df['A'])
b=np.array(df['B'])
c=np.array(df['C'])
x=np.arange(1,6)
#定义柱形宽度
width = 0.2 # the width of the bars
fig, ax = plt.subplots()
#分别设置三个柱相关信息
rects1 = ax.bar(x - width, a, width, label='A')
rects2 = ax.bar(x, b, width, label='B')
rects3 = ax.bar(x + width,c,width,label='C')
#显示图例
plt.legend()
plt.show()从以上代码可看出,matplotlib的plot函数与dataframe的plot函数相比,在处理数据框数据时,要麻烦一些,但也更具灵活性。结果如下
?