MOOC��Python���Գ�����ơ�(��15��)
�����������(������)21.8.5
��ϰ��
ʵ��9:����ͳ��ֵ����
def getNum(): #��ȡ�û��������ȵ�����
s = input()
ls = list(eval(s))
return ls
def mean(numbers): #����ƽ��ֵ
s = 0.0
for num in numbers:
s = s + num
return s / len(numbers)
def dev(numbers, mean): #�������
sdev = 0.0
for num in numbers:
sdev = sdev + (num - mean)**2
return pow(sdev / (len(numbers)-1), 0.5)
def median(numbers): #�������
numbers.sort()
size = len(numbers)
if size % 2 == 0:
med = (numbers[size//2-1] + numbers[size//2])/2
else:
med = numbers[size//2]
return med
n = getNum() #���庯��
m = mean(n)
print("ƽ��ֵ:{:.2f},����:{:.2f},��λ��:{}".format(m, dev(n,m),median(n)))
ʵ��10:�ı���Ƶͳ�� �C Hamlet
def getText():
txt = open("hamlet.txt", "r").read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_��{|}~':
txt = txt.replace(ch, " ") #���ı��������ַ��滻Ϊ�ո�
return txt
hamletTxt = getText()
words = hamletTxt.split()
counts = {}
for word in words:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
# print ("{0:<10}{1:>5}".format(word, count)) �����������10�����ʺ�����ִ���
print (word) #�����������10������
����������ͳ��
s = '''˫�� ���߹� ���� ���� ��ң�� ���� ������ ���ַ��� �Ƿ� ��� ���߹� ����
���� ���� ������ ���� ���� Ľ�ݸ� ���� Ľ�ݸ� ��ܽ �Ƿ� ����� ��ܽ
���ַ��� С��Ů ��� Ľ�ݸ� ÷���� ��Ī�� ���߹� ���� ÷���� ����
���� ����Ⱥ ��ҩʦ ���� ���� ���ַ��� ������ ������ ������ �Ƿ� �Ƿ�
���� �Ƿ� ���ַ��� Ԭ���� ���� ���� ���� ��Ī�� ���� ���� ��ܽ ������
�Ƿ� ���� ÷���� ˫�� ���� �¼��� Ԭ���� ��ܽ ��ܽ ���� ���� ���ַ���
������ Ľ�ݸ� ������ ���� ����� ��ҩʦ Ԭ���� ���� ���պ��� ������
��Ī�� ���� ��ң�� �Ƿ� ��ң�� ���պ��� ��ܽ ���� ���� ��� Ľ�ݸ�
��ң�� ���� ˫�� �Ƿ� ��ܽ ���� ��Ī�� �¼��� ��� ������ ���� ������
���߹� ΤС�� ���� ÷���� ���� ����ɺ ���պ��� �Ƿ� ���� ��� ��� Ľ�ݸ�
���� ��� ���� ���� ������ ������ ���� ������ ���� ���� ���ַ��� ����
������ ����� ��ܽ ΤС�� ��ҩʦ ���� ΤС�� ���ַ��� ���� ����� ����
���߹� Ԭ���� ˫�� ���� ���� лѷ ���� ���� ÷���� ���� ���� ������
���պ��� ˫�� ��ң�� лѷ ���պ��� ������ ���ַ��� ������ ˫�� ���� ����
���� ˫�� ��Ī�� ���� ������ ���ַ��� ���� ���� ������ ���� �����
лѷ ÷���� ������ ���� Ԭ���� ������ ������ ���� лѷ ��� ���� ����
˫�� ���ʦ̫ ���� ���� �¼��� ���� ���� ��ҩʦ ��ң�� ������ ����
��ң�� ���պ��� ���ַ��� ˫�� ���� ���߹� ��ܽ ����'''
print(len(set(s.split())))
�ֵ䷭ת���
# ����һ:
din = eval(input())
try:
dout={value : key for key,value in din.items()}
print(dout)
except:
print('�������')
# ������:
s = input()
try:
d = eval(s)
e = {}
for k in d:
e[d[k]] = k
print(e)
except:
print("�������")
����Ĭ�ĸ���֮����
# ����һ
import jieba
txt = open("��Ĭ�ĸ���.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1: # 1���ֵ�ֱ������
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items()) # ��ȡ����ֵ,ת��Ϊ�б�����
items.sort(key=lambda x:x[1], reverse=True)
print(items[0][0])
# ������
import jieba
f = open("��Ĭ�ĸ���.txt", encoding='utf-8')
ls = jieba.lcut(f.read())
d = {}
for w in ls:
if len(w) >= 2:
d[w] = d.get(w, 0) + 1
maxc = 0
maxw = ""
for k in d:
if d[k] > maxc :
maxc = d[k]
maxw = k
elif d[k] == maxc and k > maxw:
maxw = k
print(maxw)
f.close()
����ѡ����
1������Python��Ԫ������,����ѡ��������:????????????????????????????????????????????????????????????????????????????????????????????????
A��Ԫ����ö��ź�Բ����(��ѡ)����ʾ
B��һ��Ԫ�������Ϊ��һ��Ԫ���Ԫ��,���Բ��ö༶������ȡ��Ϣ
C��Ԫ��һ�������Ͳ��ܱ���
D��Ԫ����Ԫ�ر�������ͬ����
��ȷ�� D
��������(Ԫ�顢�б�)��Ԫ�ض������Dz�ͬ���͡�
2���ĸ�ѡ������������������?????????????????????????????????????????????????????????????????????????????????????????????????
d={'a':1,'b':2,'b':3}
print(d['b'])
A��1
B����b��= 2
C��2
D��3
��ȷ�� D
�����ֵ�ʱ,�����ͬ����Ӧ��ֵͬ,�ֵ�������(����)һ��"��ֵ��"��
3������Python�����������,���������������:????????????????????????????????????????????????????????????????????????????????????????????????
A������������Ϳ��Է�Ϊ3��:�������͡��������ͺ�ӳ������
B��������������ܹ��������ͬ���ͻ�ͬ���͵�������֯����,ͨ����һ�ı�ʾʹ���ݲ�������������
C�����������Ƕ�άԪ������,Ԫ��֮������Ⱥ��ϵ,ͨ����ŷ���
D��Python���ַ�����Ԫ����б����Ͷ�������������
��ȷ�� C
�������������Ͽ��Կ���һά����,�����Ԫ�ض�������,��ɱ�������ά������
4���б�ls,�ĸ�ѡ���ls.append(x)����������ȷ��?????????????????????????????????????????????????????????????????????????????????????????????????
A��ֻ�����б�ls�������һ��Ԫ��x
B�����б�ls��ǰ������һ��Ԫ��x
C����ls������Ԫ��,���x��һ���б�,�����ͬʱ���Ӷ��Ԫ��
D���滻�б�ls���һ��Ԫ��Ϊx
��ȷ�� A
ls.append(x),���x��һ���б�,����б���Ϊһ��Ԫ�����ӵ�ls�С�
5�������ֵ�d,�ĸ�ѡ���x in d����������ȷ��?????????????????????????????????????????????????????????????????????????????????????????????????
A��x��һ����ԪԪ��,�ж�x�Ƿ����ֵ�d�еļ�ֵ��
B���ж�x�Ƿ����ֵ�d�е�ֵ
C���ж�x�Ƿ������ֵ�d���Լ���ֵ��ʽ����
D���ж�x�Ƿ����ֵ�d�еļ�
��ȷ�� D
����ֵ�����,Ҳ���ֵ���ֵ��������ʽ��
���,x in d �е�x������d�е���Ž����жϡ�
6������s,�ĸ�ѡ���s.index(x)����������ȷ��?????????????????????????????????????????????????????????????????????????????????????????????????
A����������s��x�ij���
B����������s��Ԫ��x��һ�γ��ֵ����
C����������s��Ԫ��x���г���λ�õ����
D����������s�����Ϊx��Ԫ��
��ȷ�� B
ע��:s.index(x)���ص�һ�γ���x�����,��������ȫ����š�
7�����²���Python�������͵���:????????????????????????????????????????????????????????????????????????????????????????????????
A��Ԫ������
B�������
C���ַ�������
D����������
��ȷ�� D
Python��������������û���������͡�
8�����ڴ�����{},����������ȷ����:????????????????????????????????????????????????????????????????????????????????????????????????
A��ֱ��ʹ��{}������һ���ֵ�����
B��ֱ��ʹ��{}������һ���б�����
C��ֱ��ʹ��{}������һ����������
D��ֱ��ʹ��{}������һ��Ԫ������
��ȷ�� A
�������ͺ��ֵ�����������{}��ʾ,��ͬ����,��������Ԫ������ͨԪ��,�ֵ�����Ԫ���Ǽ�ֵ�ԡ�
�ֵ��ڳ�������зdz�����,���,ֱ�Ӳ���{}Ĭ������һ�����ֵ䡣
9�������ֵ�d,�ĸ�ѡ���d.values()����������ȷ��?????????????????????????????????????????????????????????????????????????????????????????????????
A������һ����������,�����ֵ�d������ֵ
B������һ��Ԫ������,�����ֵ�d������ֵ
C������һ���б�����,�����ֵ�d������ֵ
D������һ��dict_values����,�����ֵ�d������ֵ
��ȷ�� D
�������´���:(����d��һ��Ԥ������ֵ�)
python d={"a":1, "b":2}
type(d.values())��������:<class ��dict_values��>
d.values()���ص���dict_values����,�������ͨ����for��in���ʹ�á�
10��S��T����������,�ĸ�ѡ���S^T����������ȷ��?????????????????????????????????????????????????????????????????????????????????????????????????
A��S��T�IJ�����,�����ڼ���S������T�е�Ԫ��
B��S��T�IJ�����,��������S��T�еķ���ͬԪ��
C��S��T�Ľ�����,����ͬʱ�ڼ���S��T�е�Ԫ��
D��S��T�IJ�����,�����ڼ���S��T�е�����Ԫ��
��ȷ�� B
����"�����"��������ֱ��Ӧ���������:& | - ^
���������
���ֲ�ͬ��֮��
'''
����:
����û������һ������N,���N�������ֲ�ͬ���ֵĺ͡�????????????????????????????????????????????????????????????????????????????????????????????????
����:�û����� 123123123,���������ֵIJ�ͬ����Ϊ:1��2��3,�⼸�����ֺ�Ϊ6��
'''
ls = set(input())
sum=0
for i in ls:
sum = sum + eval(i)
print(sum)
���������ͳ��
'''
����:
���ģ���и�����һ���ַ���,���а����˺����ظ�������,��ֱ�������������������
'''
s = '''˫�� ���߹� ���� ���� ��ң�� ���� ������ ���ַ��� �Ƿ� ��� ���߹� ����
���� ���� ������ ���� ���� Ľ�ݸ� ���� Ľ�ݸ� ��ܽ �Ƿ� ����� ��ܽ
���ַ��� С��Ů ��� Ľ�ݸ� ÷���� ��Ī�� ���߹� ���� ÷���� ����
���� ����Ⱥ ��ҩʦ ���� ���� ���ַ��� ������ ������ ������ �Ƿ� �Ƿ�
���� �Ƿ� ���ַ��� Ԭ���� ���� ���� ���� ��Ī�� ���� ���� ��ܽ ������
�Ƿ� ���� ÷���� ˫�� ���� �¼��� Ԭ���� ��ܽ ��ܽ ���� ���� ���ַ���
������ Ľ�ݸ� ������ ���� ���� ����� ��ҩʦ Ԭ���� ���� ���պ��� ������
��Ī�� ���� ��ң�� �Ƿ� ��ң�� ���պ��� ��ܽ ���� ���� ��� Ľ�ݸ�
��ң�� ���� ˫�� �Ƿ� ��ܽ ���� ��Ī�� �¼��� ��� ������ ���� ������
���߹� ΤС�� ���� ÷���� ���� ����ɺ ���պ��� �Ƿ� ���� ��� ��� Ľ�ݸ�
���� ��� ���� ���� ������ ������ ���� ������ ���� ���� ���ַ��� ����
������ ����� ���� ��ܽ ΤС�� ��ҩʦ ���� ΤС�� ���ַ��� ���� ����� ����
���߹� Ԭ���� ˫�� ���� ���� лѷ ���� ���� ÷���� ���� ���� ������
���պ��� ˫�� ��ң�� лѷ ���պ��� ������ ���ַ��� ������ ˫�� ���� ����
���� ˫�� ��Ī�� ���� ������ ���ַ��� ���� ���� ������ ���� �����
лѷ ÷���� ������ ���� Ԭ���� ������ ������ ���� лѷ ��� ���� ����
˫�� ���ʦ̫ ���� ���� �¼��� ���� ���� ��ҩʦ ��ң�� ������ ����
��ң�� ���պ��� ���ַ��� ˫�� ���� ���߹� ��ܽ ���� ����'''
ls = s.split()
counts = {}
for name in ls:
counts[name] = counts.get(name, 0) + 1
counts = list(counts.items())
counts.sort(key=lambda x:x[1], reverse=True)
print(counts[0][0])
ѧϰ�ʼ�
1���������ͼ�����
1.1 �������Ͷ���
�����Ƕ��Ԫ�ص�������ϡ�
- �����ô�����{}��ʾ,Ԫ�ؼ��ö��ŷָ�
- ��������������{}��set,�����ռ��ϱ���ʹ��set
- ÿ��Ԫ��Ψһ,��������ͬԪ��
- ����Ԫ�ز��ɸ���,�����ǿɱ���������
1.2 ���ϲ�����
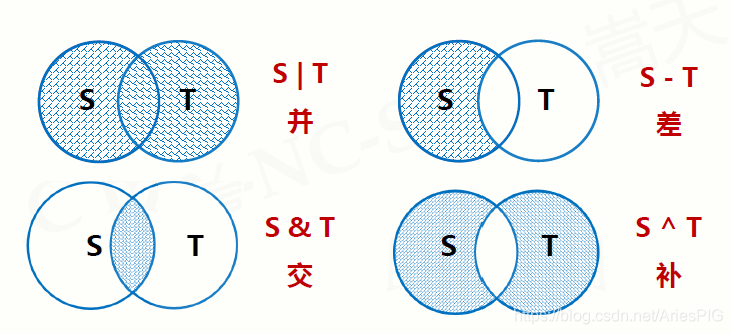
| ��������Ӧ�� | ���� |
|---|---|
| S | T | ��,����һ���¼���,�����ڼ���S��T�е�����Ԫ�� |
| S - T | ��,����һ���¼���,�����ڼ���S������T�е�Ԫ�� |
| S & T | ��,����һ���¼���,����ͬʱ�ڼ���S��T�е�Ԫ�� |
| S ^ T | ��,����һ���¼���,�����ڼ���S��T�еķ���ͬԪ�� |
| S <= T �� S < T | ����True/Flase,�ж�S��T���Ӽ���ϵ |
| S >= T �� S > T | ����True/False,�ж�S��T�İ�����ϵ |
1.3 ���ϴ�������
| ���������� | ���� |
|---|---|
| S.add(x) | ���x���ڼ���S��,��x���ӵ�S |
| S.discard(x) | �Ƴ�S��Ԫ��x,���x���ڼ���S��,������ |
| S.remove(x) | �Ƴ�S��Ԫ��x,���x���ڼ���S��,����KeyError�쳣 |
| S.clear() | �Ƴ�S������Ԫ�� |
| S.pop() | �������S��һ��Ԫ��,����S,��SΪ�ղ���KeyError�쳣 |
| S.copy() | ���ؼ���S��һ������ |
| len(S) | ���ؼ���S��Ԫ�ظ��� |
| x in S | �ж�S��Ԫ��x,x�ڼ���S��,����True,����False |
| x not in S | �ж�S��Ԫ��x,x���ڼ���S��,����True,����False |
| set(x) | ���������ͱ���ת��Ϊ�������� |
1.4 ��������Ӧ�ó���
- ������ϵ�Ƚ�
- ����ȥ��:������������Ԫ�����ظ�
2���������ͼ�����
2.1 ����
���еĶ���
�����Ǿ����Ⱥ��ϵ��һ��Ԫ��
python���������Ͱ���Ԫ��,�б�,�ַ���
- ��������ΪԪ������,Ԫ�����Ϳ��Բ�ͬ
- ������ѧԪ������:s0,s1,s2,��,s(n-1)
- Ԫ�ؼ����������,ͨ���±�������е��ض�Ԫ��
���������������
| ��������Ӧ�� | ���� |
|---|---|
| x in s | ���x������s��Ԫ��,����Ture,����Flase |
| x not in s | ���x������s��Ԫ��,����Flase,����Ture |
| s + t | ������������s��t |
| s*n �� n *s | ������s����n�� |
| s[i] | ����,����s�еĵ�i��Ԫ��,i�����е���� |
| s[i:j] �� s[i: j: k] | ��Ƭ,��������s�е�i��j��kΪ������Ԫ�������� |
���е�ͨ�ú����ͷ���
| �����ͷ��� | ���� |
|---|---|
| len(s) | ��������s�ij���,��Ԫ�ظ��� |
| min(s) | ��������s����СԪ��,s��Ԫ����Ҫ�ɱȽ� |
| max(s) | ��������s�����Ԫ��,s��Ԫ����Ҫ�ɱȽ� |
| s.index(x)�� s.index(x,i,j) | ��������s��i��ʼ��jλ���е�һ�γ���Ԫ��x��λ�� |
| s.count(x) | ��������s�г���x���ܴ��� |
2.2 Ԫ��
Ԫ��Ķ���
Ԫ�����������͵�һ����չ
- Ԫ����һ����������,һ�������Ͳ��ܱ���
- ʹ��С����()��tuple()����,Ԫ�ؼ��ö��ŷָ�
- ����ʹ�û�����С����
Ԫ��IJ���
- Ԫ��̳����������͵�ȫ��ͨ�ò���
- Ԫ����Ϊ����������,û���������
- ����ʹ�û�ʹ��С����
2.3 �б�
�б��Ķ���
- �б����������͵�һ����չ,ʮ�ֳ���
- ʹ�÷�����[]��list()����,Ԫ�ؼ��ö��ŷָ�
- �б��и�Ԫ�����Ϳ��Բ�ͬ,��������
��IJ���
| ���� | ���� |
|---|---|
| ls[i] = x | �滻�б�ls��iԪ��Ϊx |
| ls[i: j: k] = lt | ���б�lt�滻ls��Ƭ���ӦԪ�����б� |
| del ls[i] | ɾ���б�ls�е�iԪ�� |
| del ls[i: j: k] | ɾ���б�ls�е�i����j��kΪ������Ԫ�� |
| ls += lt | �����б�ls,���б�ltԪ�����ӵ��б�ls�� |
| ls *= n | �����б�ls,��Ԫ���ظ�n�� |
| ���� | |
| ls.append(x) | ���б�ls�������һ��Ԫ��x |
| ls.clear() | ɾ���б�ls������Ԫ�� |
| ls.copy() | ����һ�����б�,��ֵls������Ԫ�� |
| ls.insert(i,x) | ���б�ls�ĵ�iλ������Ԫ��x |
| ls.pop(i) | ���б�ls�е�iλ��Ԫ��ȡ����ɾ����Ԫ�� |
| ls.remove(x) | ���б�ls�г��ֵĵ�һ��Ԫ��xɾ�� |
| ls.reverse() | ���б�ls�е�Ԫ�ط�ת |
�б�����ʵ��
lt = [] # ������б�lt,[]
lt += [1,2,3,4,5] # ��lt����5��Ԫ��,[1,2,3,4,5]
lt[2] = 6 # ��le�е�2��Ԫ��,[1,2,6,4,5]
lt.insert(2,7) # ��lt�е�2��λ������һ��Ԫ��,[1,2,7,6,4,5]
del lt[1] # ��lt�е�һ��λ��ɾ��һ��Ԫ��,[1, 7, 6, 4, 5]
del lt[1:4] # ɾ��lt�е�1-3λ��Ԫ��(����3),[1, 5]
print(0 in lt) # �ж�lt���Ƿ��������0,False
lt.append(0) # ��lt��������0,[1, 5, 0]
lt.index(0) # ��������0����lt�����,2
len(lt) # lt�ij���,3
max(lt) # lt�����Ԫ��,5
lt.clear() # ���lt,[]
2.4 ��������Ӧ�ó���
Ԫ������Ԫ�ز��ı��Ӧ�ó���,�������ڹ̶����䳡��
�����ϣ�����ݱ��������ı�,ת����Ԫ������
�б��������,����õ���������
����Ҫ����:��ʾһ����������,������������
3��ʵ��9:����ͳ��ֵ����
def getNum(): # ��ȡ����������
nums = []
inNumStr = input("����������(�س��˳�):")
while inNumStr != '':
nums.append(eval(inNumStr))
inNumStr = input("����������(�س��˳�):")
return nums
def mean(numbers): # ����ƽ��ֵ
s = 0.0
for num in numbers:
s = s + num
return s / len(numbers)
def dev(numbers,mean): # ���㷽��
sdev = 0.0
for num in numbers:
sdev = sdev + (num - mean) ** 2
return pow(sdev / (len(numbers)-1),0.5)
def median(numbers): # �������
numbers.sort() # ����
size = len(numbers)
if size % 2 == 0:
med = (numbers[size//2-1]+numbers[size//2])/2
else:
med = numbers[size//2]
return med
n = getNum()
m = mean(n)
print("ƽ��ֵ:{},����:{:.2f},��λ��:{}��".format(m,dev(n,m),median(n)))
4���ֵ����ͼ�����
4.1 �ֵ����Ͷ���
ӳ����һ�ּ�(����)��ֵ(����)�Ķ�Ӧ
�ֵ������ǡ�ӳ�䡱������
- ��ֵ��:����������������չ
- �ֵ��Ǽ�ֵ�Եļ���,��ֵ��֮������
- ���ô�����{ }��dict()����,��ֵ����ð��:��ʾ
4.2 �ֵ䴦������������
| ������ | ���� |
|---|---|
| del d[k] | ɾ���ֵ�d�м�k��Ӧ������ֵ |
| k in d | �жϼ�k�Ƿ����ֵ�d��,����ڷ���True,����False |
| d.keys() | �����ֵ�d�����еļ���Ϣ |
| d.values() | �����ֵ�d�����е�ֵ��Ϣ |
| d.items() | �����ֵ�d�����еļ�ֵ����Ϣ |
| ���� | |
| d.get(k, ) | ��k����,����Ӧֵ,������ֵ |
| d.pop(k, ) | ��k����,��ȡ����Ӧֵ,������ֵ |
| d.popitem() | ������ֵ���dȡ��һ����ֵ��,��Ԫ����ʽ���� |
| d.clear() | ɾ�����еļ�ֵ�� |
| len(d) | �����ֵ�d��Ԫ�صĸ��� |
�ֵ书��ʵ��
d = {} # ������ֵ� d,{}
d['one'] = 1 # �� d ������2����ֵ��Ԫ��,{'one': 1, 'two': 2}
d['two'] = 2
d['two'] = 'number 2' # �ĵ�2��Ԫ��,{'one': 1, 'two': 'number 2'}
print('c' in d) # �жϡ�c���Ƿ���d�ļ�,False
print(len(d)) # ���� d �ij���,2
d.clear() # ��� d,{}
4.3 �ֵ�����Ӧ�ó���
ӳ��ı���
- ӳ��������,��ֵ��������,����:ͳ�����ݳ��ֵĴ���,�����Ǽ�,������ֵ��
- ����Ҫ������:�����ֵ������,������������
Ԫ�ر���
for k in d:
? <����>
5��jieba���ʹ��
5.1 jieba���������
jieba����������ķִʵ�������
- �����ı���Ҫͨ���ִʻ�õ����Ĵ���
- jieba����������ķִʵ�������,��Ҫ���ⰲװ
- jieba���ṩ���ִַ�ģʽ,���ֻ������һ������
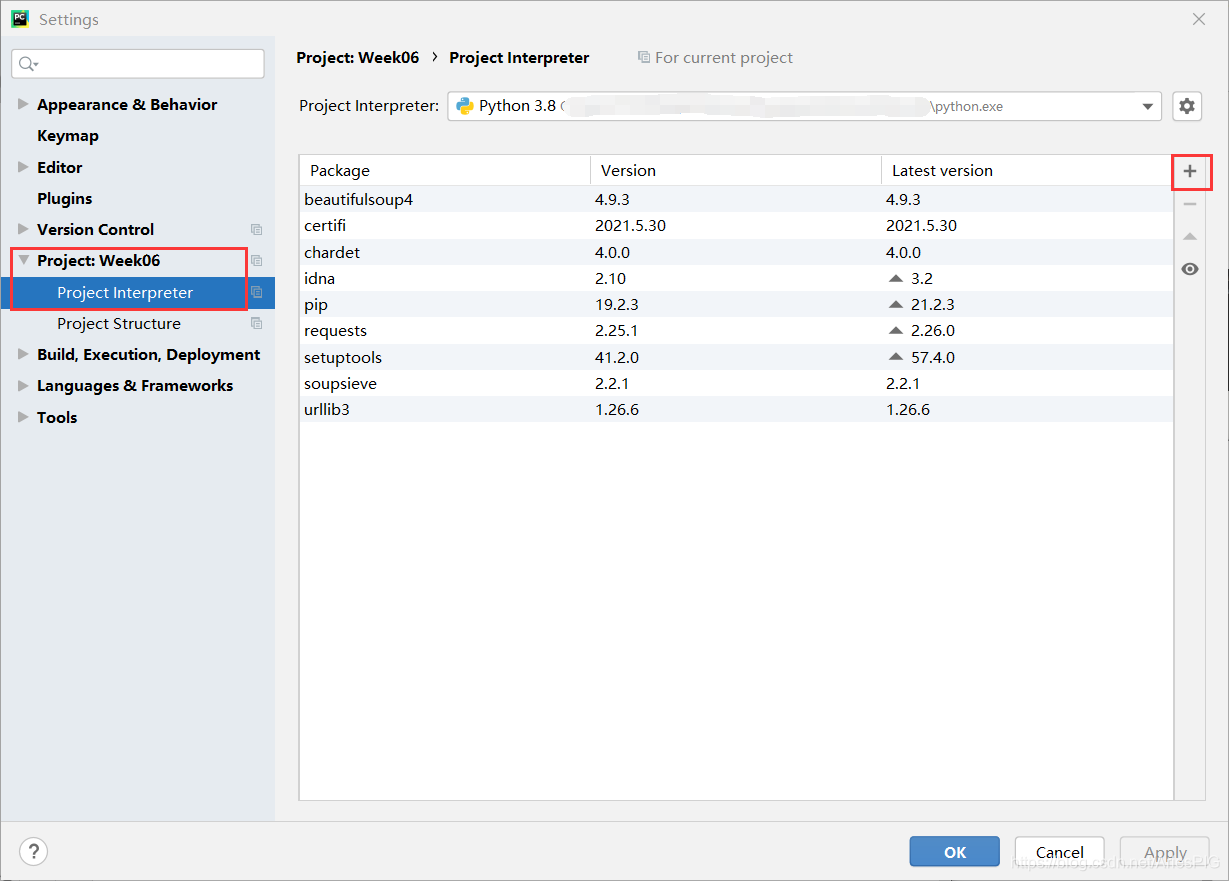
5.2 jieba��İ�װ(pycharm����)
��File -> Settings -> Project Interpreter�Ŀ�����е���Ҳ�Ӻ�
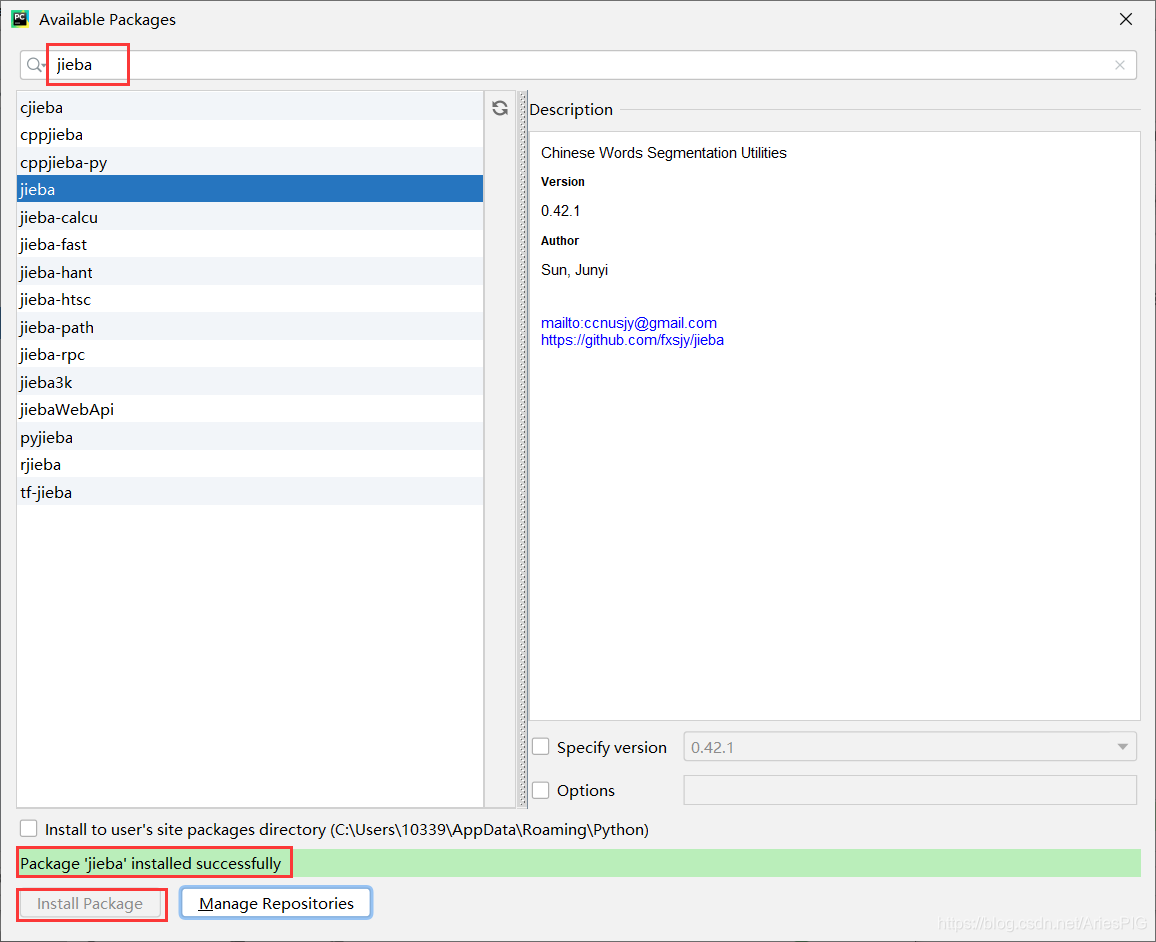
��������������jieba,������½�install,�ȴ�,��ɺ����ʾ��װ�ɹ���
5.3 jieba��ʹ��˵��
jieba�ִʾ�������ģʽ
��ȷģʽ:���ı���ȷ���зֿ�,�����������
ȫģʽ:���ı������п��ܵĴ��ﶼɨ�����,������
��������ģʽ:�ھ�ȷģʽ������,�Գ����ٴ��з�
| ���� | ���� |
|---|---|
| jieba.lcut(s) | ��ȷģʽ,����һ���б��ķִʽ�� >>> jieba.lcut(���й���һ��ΰ��Ĺ��ҡ�) [���й���, ���ǡ�, ��һ����, ��ΰ��, ���ġ�, �����ҡ�] |
| jieba.lcut(s,cut_all = True) | ȫģʽ,����һ���б����͵ķִʽ��,�������� >>> jieba.lcut(���й���һ��ΰ��Ĺ��ҡ�,cut_all=True) [���й���, �����ǡ�, ��һ����, ��ΰ��, ���ġ�, �����ҡ�] |
| jieba.lcut_for_search(s) | ��������ģʽ,����һ���б����͵ķִʽ��,�������� >>> jieba.lcut_for_search(���й�������ΰ��ġ�) [���й���, �����͡�, ��������, ���ǡ�, ��ΰ��, ���ġ�] |
| jieba.add_word(w) | ��ִʴʵ������´�w jieba.add_word(���������ԡ�) |
6���ı���Ƶͳ��
Hamlet��Ƶͳ��
# Hamlet��Ƶͳ��
def getText():
txt = open("hamlet.txt", "r").read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_��{|}~':
txt = txt.replace(ch, " ") #���ı��������ַ��滻Ϊ�ո�
return txt
hamletTxt = getText()
words = hamletTxt.split()
counts = {}
for word in words:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
���������塷�������ͳ��(ǰʮ)
# ���������塷�������ͳ��(ǰʮ)
import jieba
excludes = {"����","ȴ˵","����","����","����","����","���","����","���","����",
"��ʿ","����","����","����","����","��ϲ","����","����","����","����",
"����","κ��","����","һ��","����","����","��֪"}
txt = open("threekingdoms.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "�����" or word == "����Ի":
rword = "����"
elif word == "�ع�" or word == "�Ƴ�":
rword = "����"
elif word == "����" or word == "����Ի":
rword = "����"
elif word == "�ϵ�" or word == "ة��":
rword = "�ܲ�"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
������Դ:
Python���Գ������_����������ѧ_�й���ѧMOOC(Ľ��) https://www.icourse163.org/course/BIT-268001