1.论文出处
1.MTCNN:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
论文原文🔗:https://pan.baidu.com/s/1ZmEzKqvXkyqRWNVROsceYA
2.FaceNet: A Unified Embedding for Face Recognition and Clustering
论文原文🔗:上面的码:8x7o
3.FaceNet项目🔗:https://github.com/davidsandberg/facenet
2.简介
2.1 MTCNN
MTCNN(Multi-task convolutional neural network) 是一种用于人脸检测的多任务卷积神经网络模型,于 2016 年由中国科学院深圳研究院乔宇等提出。该模型借鉴了经典的AdaBoost 方法,采用级联结构。同时,还能够实现人脸检测与对齐,是一种结合人脸检测和面部关键检测的多任务方法。该模型的级联结构主要由三个网络构成,分别是 Proposal Network(P-Net)、Refine Network(R-Net)、Output Network(O-Net),分别如下图所示。
2.1.1 P-Net
P-Net 用于快速生成候选窗口。实现流程为:将输入的特征进行三层卷积后,用人脸分类器、边框回归和面部关键点定位来进行人脸区域的初选。接着 P-Net 初选所得人脸区域被送入 R-Net 进行下一步处理。
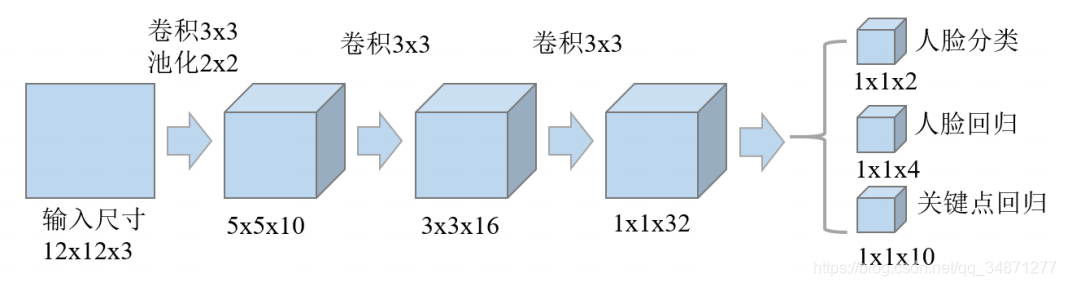
2.1.2 R-Net
R-Net 的功能是对上一步得到的人脸区域进行更严格的选择。实现流程为:将 P-Net中得到的候选窗口全部输入 R-Net,淘汰效果较差的候选窗口后进行边框回归与非极大值抑制得到进一步的预测窗口。
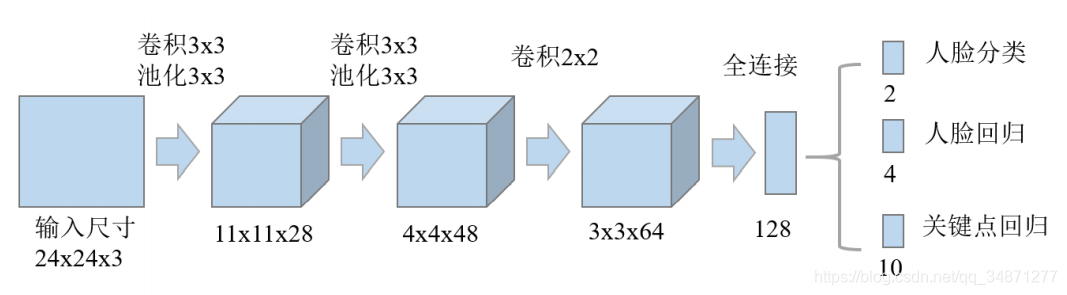
2.1.3 O-Net
O-Net 的功能是生成最终的边界框和人脸关键点。实现流程为:与 R-Net 类似,但增加了对人的面部特征点位置的回归预测。最后输出 5 个人脸面部特征点。
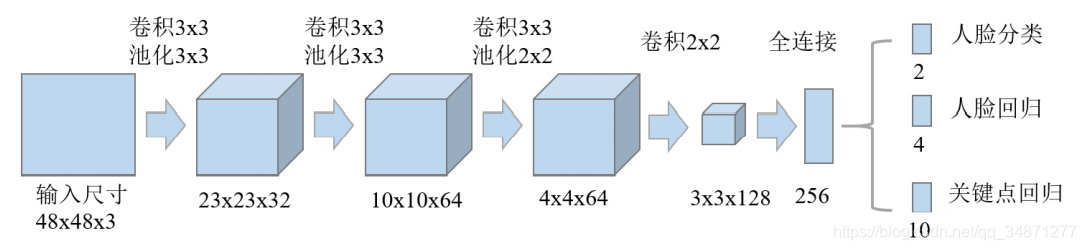
2.2 FaceNet
2015年谷歌工程师Schroff, F等提出了FaceNet模型。此模型没有使用经典的softmax来进行分类学习,而是通过提取其中一个层作为特征,学习从图像到欧几里得空间的编码方法。
该算法的主要思想是利用已有的 CNN 模型(如 GoogleNet 等),在此之上更改损失函数,从而将人脸图像映射到高维空间。利用损失函数来优化人脸间的欧几里得距离,使得同一个人的人脸图像间的距离尽量小,不同人的人脸图像间的距离尽量大。根据所得特征向量,计算欧几里得距离,从而来进行人脸识别。其网络结构如下。

该算法的核心是 Triplet Loss 损失函数。经过学习过程后样本间的距离发生了改变。形象的来描述,就是经过学习,尽量使正样本的距离变小,负样本的距离变大。

3.环境配置
用Python最麻烦的就是依赖项的安装。依赖安装好了,后面的步骤就简单多了。
下面是官方给的requirements。直接pip就可以了。
tensorflow==1.7
scipy
scikit-learn
opencv-python
h5py
matplotlib
Pillow
requests
psutil
其中,比较麻烦的是tensorflow的版本。因为facenet已经是好几年前的了,所以用的tensorflow的版本比较低,用官方代码大概率会出现各种报错。我给出的建议是另外创建一个环境,比如我使用的是Anaconda(当然你也可以使用Pycharm)。
下面是我用的虚拟环境的依赖版本,可以参考,报错的话请自行调整版本。
python == 3.6.13
tensorflow == 1.7.0
scipy == 1.2.1
scikit-learn == 0.24.2
opencv-python == 4.5.2.52
h5py == 3.1.0
matplotlib == 3.3.4
Pillow == 8.2.0
requests == 2.25.1
psutil == 5.8.0
请注意:
1.python版本过高的话会安装不上tensorflow的老版本。比如你用3.8的python的话就安不上1.7.0的tensorflow。所以我建议使用3.6的python。
2.我在笔记本上用cpu训练的话直接用1.7.0的tensorflow是没问题的。但是速度特别慢。用一个比较小的5000多人的训练集都需要大概1000个小时。更不用说用CASIA-WebFace和VGGFace2这种大数据集了。因此我租了一个GPU服务器来训练。想用GPU训练的话就必须安装相应的tensorflow-gpu版本,以及配置相应的CUDA版本。于是问题又来了,我没有在英伟达官网找到符合Tensorflow-gpu==1.7.0的cuda,我把相邻版本的CUDA都试了遍,没有一个符合。可能我cai,当然你可以自己试一下。
最后的解决方案是我直接用1.8.0的tensorflow-gpu,以及相应的CUDA。
所以,我的建议是你如果要用GPU训练的话直接安装1.8.0的tensorflow-gpu,因为1.7.0的GPU版本会很难配置。
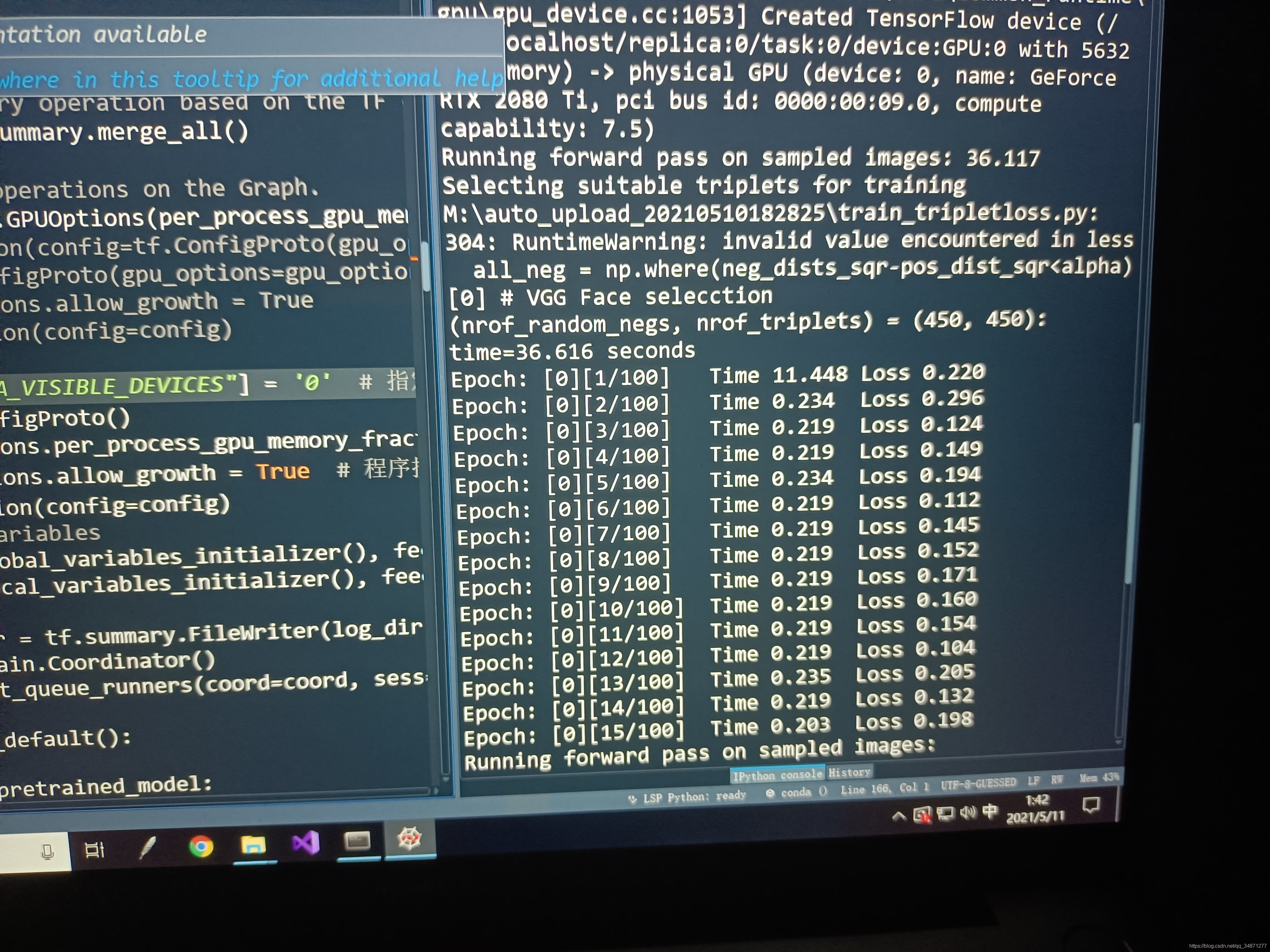
4.训练
下面介绍模型训练过程。
首先,下载Facenet代码:🔗https://github.com/davidsandberg/facenet
4.1 训练集
我选择的是择中科院自动化所 CASIA-FaceV5 公开数据集。500 个人的 2500 张彩色人脸图像组成了该数据库,并且拥有眼镜、表情、照明、姿势、成像距离等典型的类内变化,每一张人脸图像的分辨率都为 640480。同时,该 500 位志愿者的人脸图像全为亚洲人脸,其身份包括研究生、工人、服务生等。

实 验 中 FaceNet 模 型 使用的 深 度 卷 积 神 经 网 络 结 构 是 Google 公司的inception_resnet_v1 模型,该模型的图像输入分辨率为 160160,而 CASIA-FaceV5 数据集的人脸图像分辨率为 640*480。因此需要对训练的人脸图像进行预处理。FaceNet 中图像预处理的思路是利用 MTCNN 进行人脸对齐和图像裁剪,具体实现是输入相关参数并运行 FaceNet 开源代码里的 align_dataset_mtcnn.py 文件,即生成预处理后的人脸数据集。我用的spyder在下面红色框位置输入。
python src/align/align_dataset_mtcnn.py 数据集存储位置 --image_size 160 --margin 32 --random_order

图像预处理后的效果如下:

4.2 训练
打开train_tripletloss.py文件,其中的下面这个函数主要负责模型训练中的参数,也是我们自己训练的时候需要修改的地方。
其中,重要的几个点有:
1.存放event的目录。你如果需要用tensorboard来绘制图像的话,就需要训练生成的event文件。如果你是在租的GPU上进行训练,记得保存该文件。
2.存放models的目录。即存放训练后的模型的目录。
3.数据集的目录。我们用来训练的数据集在电脑里的存储位置。
def parse_arguments(argv):
parser = argparse.ArgumentParser()
#存放训练事件的目录
parser.add_argument('--logs_base_dir', type=str,
help='Directory where to write event logs.', default='~/logs/facenet')
#存放训练模型的目录
parser.add_argument('--models_base_dir', type=str,
help='Directory where to write trained models and checkpoints.', default='~/models/facenet')
#GPU显存占比
parser.add_argument('--gpu_memory_fraction', type=float,
help='Upper bound on the amount of GPU memory that will be used by the process.', default=1.0)
#预训练模型
parser.add_argument('--pretrained_model', type=str,
help='Load a pretrained model before training starts.')
#数据集目录,要求对齐人脸
parser.add_argument('--data_dir', type=str,
help='Path to the data directory containing aligned face patches.',
default='D:/facenet/align/data/test_160')
#使用的卷积神经网络结构
parser.add_argument('--model_def', type=str,
help='Model definition. Points to a module containing the definition of the inference graph.', default='models.inception_resnet_v1')
#设定运行的代数
parser.add_argument('--max_nrof_epochs', type=int,
help='Number of epochs to run.', default=100)
#批尺寸:批量处理的图象数
parser.add_argument('--batch_size', type=int,
help='Number of images to process in a batch.', default=90)
#图片像素
parser.add_argument('--image_size', type=int,
help='Image size (height, width) in pixels.', default=160)
#每一批的人数
parser.add_argument('--people_per_batch', type=int,
help='Number of people per batch.', default=45)
#每个人的图片数量
parser.add_argument('--images_per_person', type=int,
help='Number of images per person.', default=40)
#每一代的batch数量
parser.add_argument('--epoch_size', type=int,
help='Number of batches per epoch.', default=100)
#正三元距到负三元距
parser.add_argument('--alpha', type=float,
help='Positive to negative triplet distance margin.', default=0.2)
#特征值尺寸:特征向量维度
parser.add_argument('--embedding_size', type=int,
help='Dimensionality of the embedding.', default=128)
#随机裁剪
parser.add_argument('--random_crop',
help='Performs random cropping of training images. If false, the center image_size pixels from the training images are used. ' +
'If the size of the images in the data directory is equal to image_size no cropping is performed', action='store_true')
#随机翻转
parser.add_argument('--random_flip',
help='Performs random horizontal flipping of training images.', action='store_true')
#保留概率
parser.add_argument('--keep_probability', type=float,
help='Keep probability of dropout for the fully connected layer(s).', default=1.0)
#权重衰减
parser.add_argument('--weight_decay', type=float,
help='L2 weight regularization.', default=0.0)
#优化器
parser.add_argument('--optimizer', type=str, choices=['ADAGRAD', 'ADADELTA', 'ADAM', 'RMSPROP', 'MOM'],
help='The optimization algorithm to use', default='ADAGRAD')
#学习率:时间表可以在文件"learning_rate_schedule.txt"中指定
#默认为0.1
#设置为-1,就使用时间表
parser.add_argument('--learning_rate', type=float,
help='Initial learning rate. If set to a negative value a learning rate ' +
'schedule can be specified in the file "learning_rate_schedule.txt"', default=0.1)
#开始学习率衰减的epoch数
parser.add_argument('--learning_rate_decay_epochs', type=int,
help='Number of epochs between learning rate decay.', default=100)
#学习率衰减因子
parser.add_argument('--learning_rate_decay_factor', type=float,
help='Learning rate decay factor.', default=1.0)
#指数衰减来追踪训练参数
parser.add_argument('--moving_average_decay', type=float,
help='Exponential decay for tracking of training parameters.', default=0.9999)
#随机数种子
parser.add_argument('--seed', type=int,
help='Random seed.', default=666)
#学习率设置为-1,就使用时间表
parser.add_argument('--learning_rate_schedule_file', type=str,
help='File containing the learning rate schedule that is used when learning_rate is set to to -1.', default='data/learning_rate_schedule.txt')
# Parameters for validation on LFW
#validation验证
parser.add_argument('--lfw_pairs', type=str,
help='The file containing the pairs to use for validation.', default='data/pairs.txt')
parser.add_argument('--lfw_dir', type=str,
help='Path to the data directory containing aligned face patches.', default='')
parser.add_argument('--lfw_nrof_folds', type=int,
help='Number of folds to use for cross validation. Mainly used for testing.', default=10)
return parser.parse_args(argv)
最后,用GPU跑起来的效果大概如下: