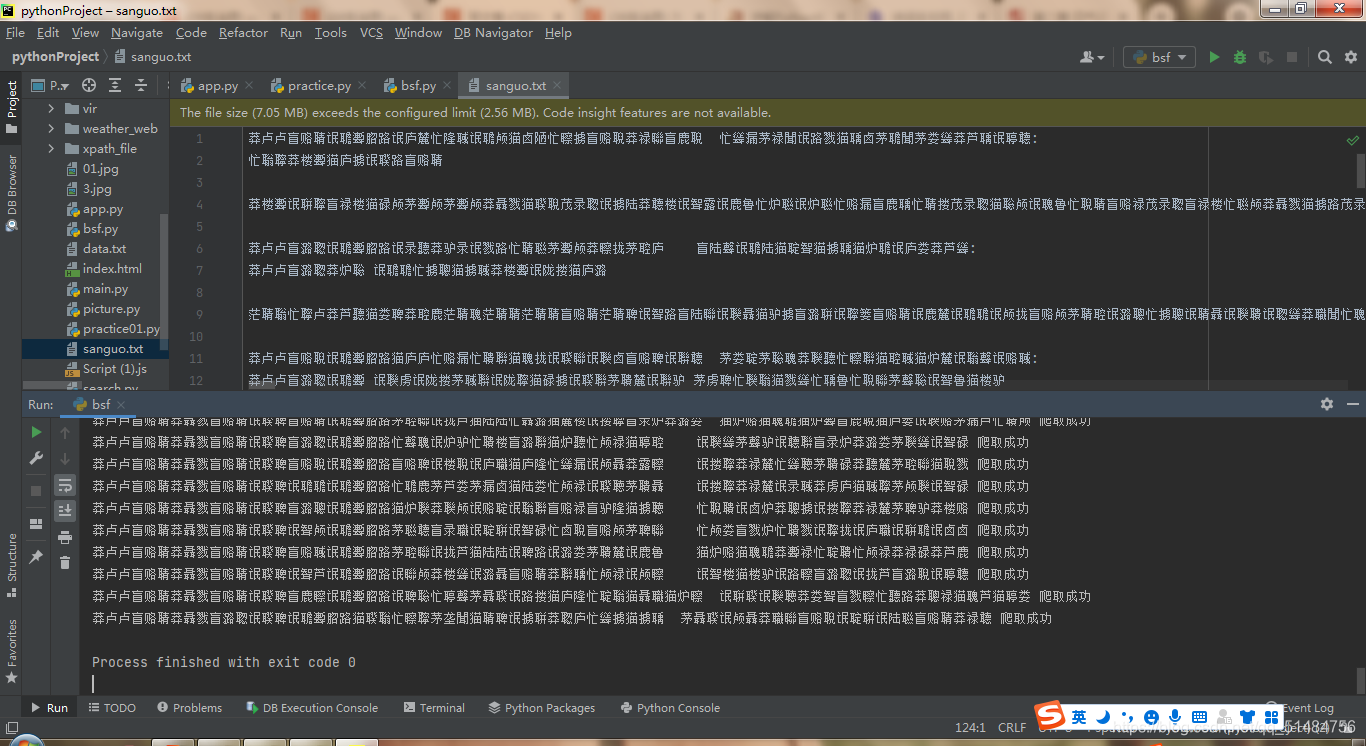
代码,之前一直乱码,经过多番尝试
使用了.encode(‘ISO-8859-1’).decode(‘utf-8’)这个方法
from bs4 import BeautifulSoup
import requests
if __name__ == '__main__':
url='https://m.shicimingju.com/book/sanguoyanyi.html'
headers={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
page_text=requests.get(url=url,headers=headers)
#page_text.encoding = 'utf-8'
soup=BeautifulSoup(page_text.text.encode('ISO-8859-1').decode('utf-8'),'lxml')
li=soup.select('.book-mulu > ul > li')
f=open('sanguo.txt','w',encoding='utf-8')
for list in li:
title=list.a.string
#t=title.encode('utf-8').decode('gbk')
href='https://m.shicimingju.com'+list.a['href']
detail_text=requests.get(href,headers=headers)
#detail_text.encoding='utf-8'
content=BeautifulSoup(detail_text.text.encode('ISO-8859-1').decode('utf-8'),'lxml')
con=content.find('div',class_='card')
p=con.text
#p=p.encode('utf-8').decode('gbk')
f.write(title+':'+p+'\n')
print(title,'爬取成功')
图片
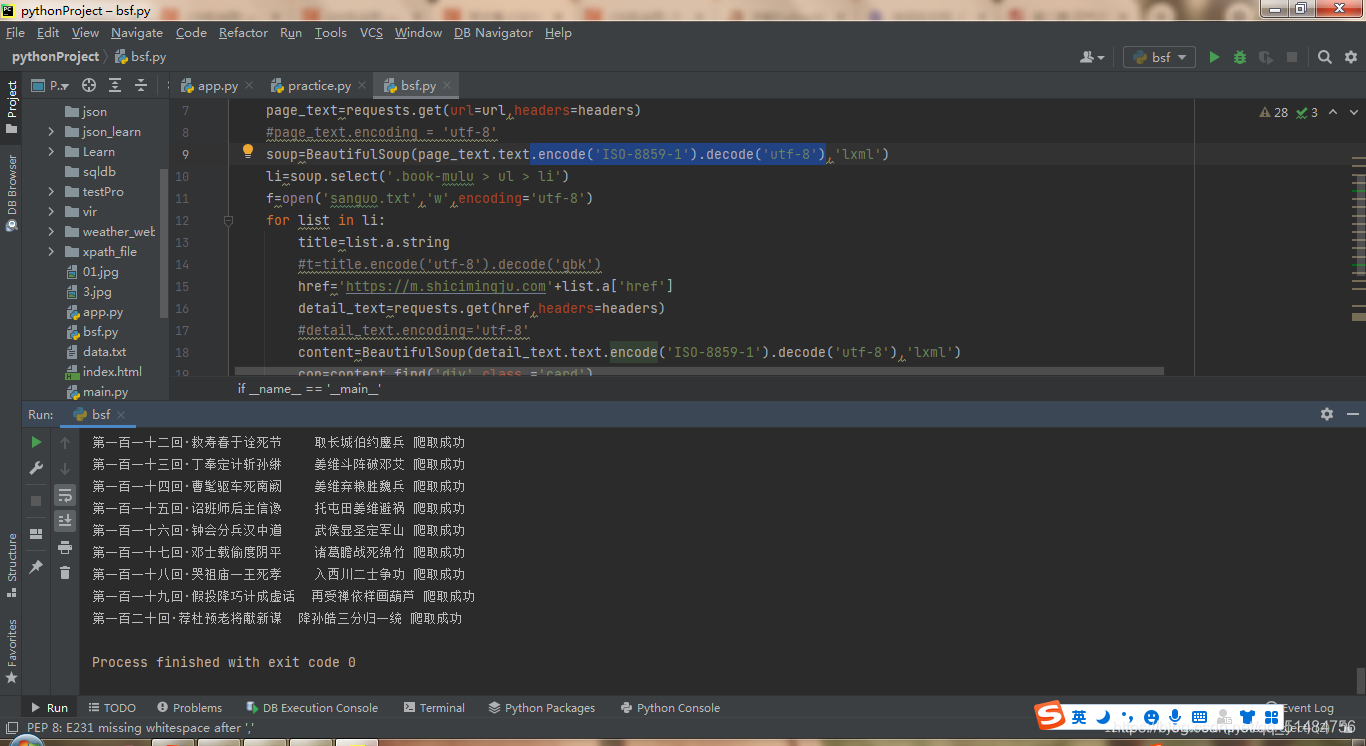
但是这个爬出来的txt含有NSBP
根据此方法:
\xa0 是不间断空白符
str.replace(u’\xa0’, u’ ‘)
\u3000 是全角的空白符
str.replace(u’\u3000’,u’ ‘)
title.strip(‘\r\n’).replace(u’\u3000’, u’ ‘).replace(u’\xa0’, u’ ‘)
content.strip(“”).strip(‘\r\n’).replace(u’\u3000’, u’ ‘).replace(u’\xa0’, u’ ‘)
进行修改:
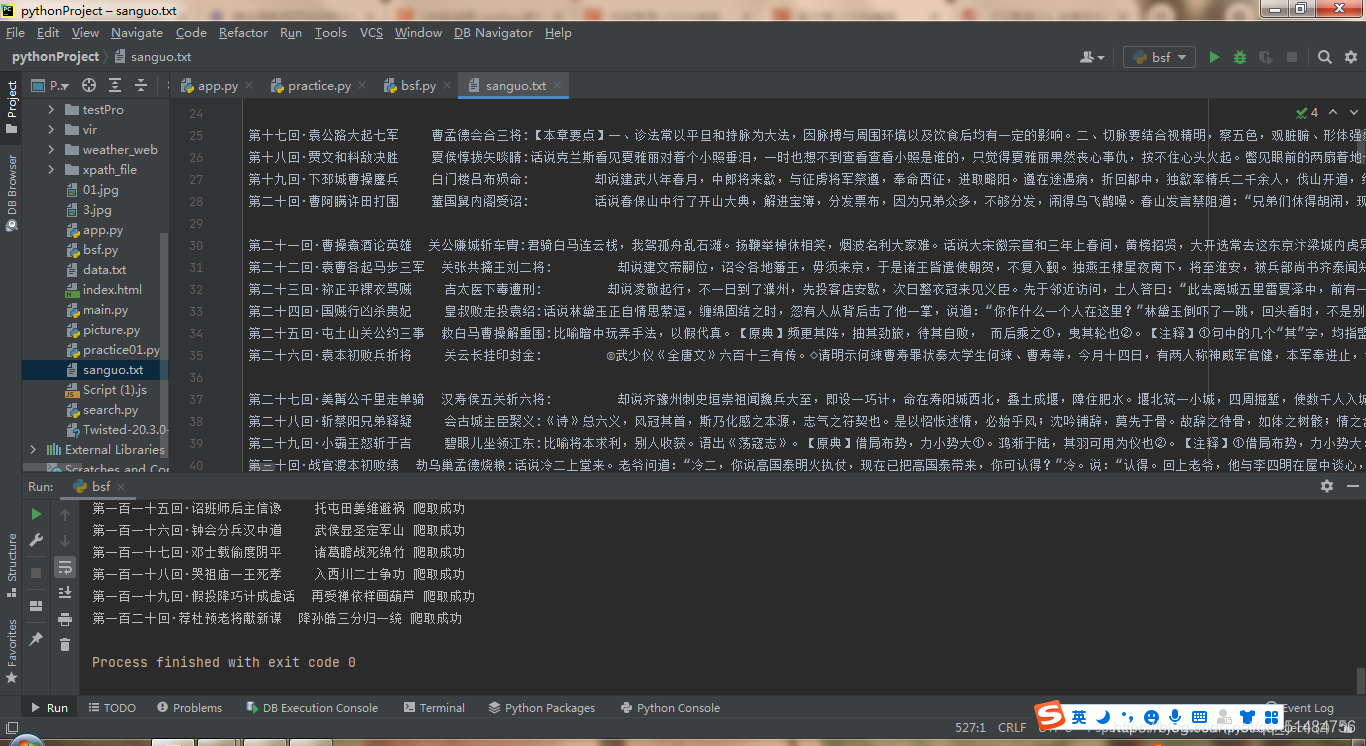
这个txt文件就没有NSBP了,而且格式也规范许多。
最终代码:
from bs4 import BeautifulSoup
import requests
if __name__ == '__main__':
url='https://m.shicimingju.com/book/sanguoyanyi.html'
headers={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
page_text=requests.get(url=url,headers=headers)
#page_text.encoding = 'utf-8'
soup=BeautifulSoup(page_text.text.encode('ISO-8859-1').decode('utf-8'),'lxml')
li=soup.select('.book-mulu > ul > li')
f=open('sanguo.txt','w',encoding='utf-8')
for list in li:
title=list.a.string
t=title.strip('\r\n').replace(u'\u3000', u'').replace(u'\xa0', u'')
href='https://m.shicimingju.com'+list.a['href']
detail_text=requests.get(href,headers=headers)
#detail_text.encoding='utf-8'
content=BeautifulSoup(detail_text.text.encode('ISO-8859-1').decode('utf-8'),'lxml')
con=content.find('div',class_='chapter_content')
p=con.text
p=p.strip('\r\n').replace(u'\u3000', u'').replace(u'\xa0', u'')
f.write(t+':'+p+'\n')
print(t,'爬取成功')
之前错误的代码示范
from bs4 import BeautifulSoup
import requests
if __name__ == '__main__':
url='https://m.shicimingju.com/book/sanguoyanyi.html'
headers={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
page_text=requests.get(url=url,headers=headers).text
soup=BeautifulSoup(page_text,'lxml')
li=soup.select('.book-mulu > ul > li')
f=open('sanguo.txt','w',encoding='utf-8')
for list in li:
title=list.a.string
t=title.encode('utf-8').decode('gbk')
href='https://m.shicimingju.com'+list.a['href']
detail_text=requests.get(href,headers=headers).text
#detail_text.encoding='utf-8'
content=BeautifulSoup(detail_text,'lxml')
con=content.find('div',class_='card')
p=con.text
p=p.encode('utf-8').decode('gbk')
f.write(t+':'+p+'\n')
print(t,'爬取成功')
图片,虽然是中文但是内容完全错误,不知道爬的啥。