��������е�ǿ��,�뿴Ƭ�ˡ��Ȳ������ó��ҵ�Python��
�������
- ��ȡ�����Ӱ�������а�
- ����������
������
��װ requests �� pyquery ��:
��ݼ� Windows+r �����п��ƿ�,���� cmd,����������,����:
pip install requests
pip install pyquery
����:
import requests
from pyquery import PyQuery as pq
��ҳ����������
����ַ:https://movie.douban.com/chart
��һ��:��ȡ����ؼ���
��������Ҫ��ȡ��Ӱ�����������Ϣ:

��������Ҫ���� get ������ html Դ�벢����,��ȡ������Ϣ��
�Ҽ�,������Ԫ��,����������ģʽ,�����ȵ��Network��,¼�����ǵ�������ˢ��һ����ҳ,���Կ���������һ������,�������������ҳ����ַ:

�������ҵ���ַ������ͷ,��Ȼ,����ͷ��������Dz���Ҫ�IJ���,����ֻ��Ҫ Cookie��Referer��User-Agent �Ϳ����ˡ���������:
url1 = 'https://movie.douban.com/chart'
headers1 = {
'Cookie': '...',
'Referer': 'https://movie.douban.com/',
'User-Agent': '...'
}
response1 = requests.get(url1, headers=headers1) # ��������
��ȡ����ҳԴ���,���Elements,Ȼ�������Ͻǵļ�ͷ,ѡ�з����ǩ,Ѱ�Ҹò��ֵ�htmlԴ��:

�ҵ������ǩ��λ�ú�,�� pyquery ����һ��:
typelabels = pq(response1.text).find('.types span a') # ���ҽڵ�
typeslist = list(typelabels.items()) # תΪ�б�,����֮�������
Ȼ������ѭ�������б�,��ӡ����źؼ���,���ȴ��û�����:
for i, n in enumerate(typeslist):
print(str(i) + ':', n.text())
choose = int(input('��ѡ��:'))
�ڶ���:��ȡ�����
�����ǵ��Network��,¼�����ǵ�������������ǵ��һ������,���������档���Կ���������һ������,�������ǽ����������ַ,Preview ����������Ҫ�İ�ע����������������Ƶ���ַ,ע������:


��������IJ�����������ȡ:
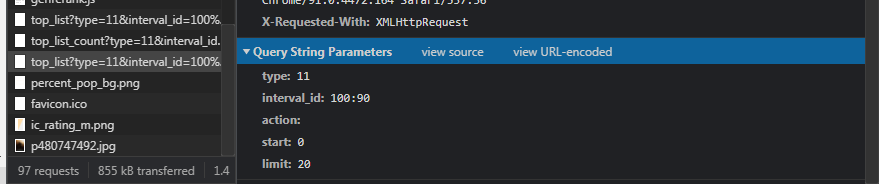
��ʱ��Ҫ˵һ��,�����ڷ�������ʱ,һ���ַ���ʺź���Ŀ���ʡ��,����Ϊ�ʺź���ļ����������,���Ƿ��� params ��Ϣ�Ͳ���Ҫ����IJ����ˡ�params ���÷�������ʱ�����IJ���,�ֵ���ֽ�����ʽ,��Ϊ����������ӵ�url��(�ʺź�IJ���)����Ȼ����,��ô����Ҳ���Է�����,�ڵ�ַ�з������,���ܹ�ʡ�Ե� params �ˡ�
���ǿ��Է���,����ҳԴ����ķ����ǩ��,href �������������Ӻ�:

��ʱ������ֻ�轫�������ַ'https://movie.douban.com/j/chart/top_list'�ͺ���/typerank�IJ�����������,���ܹ��õ���Ҫ�ĵ�ַ:
add = typeslist[choose].attr('href')
url2 = 'https://movie.douban.com/j/chart/top_list' + add.lstrip('/typerank')
#'https://movie.douban.com/j/chart/top_list?type_name=����&type=11&interval_id=100:90&action='
����� get ����,��ȡ����Ϣ,������Ҫparams�������:
headers2 = {
'Cookie': '...',
'Referer': 'https://movie.douban.com/typerank',
'User-Agent': '...'
}
response2 = requests.get(url=url2, headers=headers2)
Ȼ����ɸѡ����Ҫ����Ϣ,��ӡ����:
for i, n in enumerate(response2.json()):
print(i+1, n['title'] + ' ' + n['rating'][0] + '��' + ','.join(n['types']) + '��', sep=' ')
#��ӡ���������ơ����ּ�ӰƬ����
��:

��������
from pyquery import PyQuery as pq
import requests
url1 = 'https://movie.douban.com/chart'
headers1 = {
'Cookie': '...',
'Referer': 'https://movie.douban.com/',
'User-Agent': '...'
}
response1 = requests.get(url1, headers=headers1) # ��һ������,��ȡ�ؼ���
typelabels = pq(response1.text).find('.types span a') # ���ҽڵ�
typeslist = list(typelabels.items()) # תΪ�б�,����֮�������
for i, n in enumerate(typeslist):
print(str(i) + ':', n.text()) # ��ӡ�ؼ���
choose = int(input('��ѡ��:'))
add = typeslist[choose].attr('href')
url2 = 'https://movie.douban.com/j/chart/top_list' + add.lstrip('/typerank') # �ϲ�����url
headers2 = {
'Cookie': '...',
'Referer': 'https://movie.douban.com/typerank',
'User-Agent': '...'
}
response2 = requests.get(url=url2, headers=headers2) # �ڶ�������,��ȡ��
for i, n in enumerate(response2.json()): # ��ӡ��/
print(i, n['title'] + ' ' + n['rating'][0] + '��' + ','.join(n['types']) + '��', sep=' ')
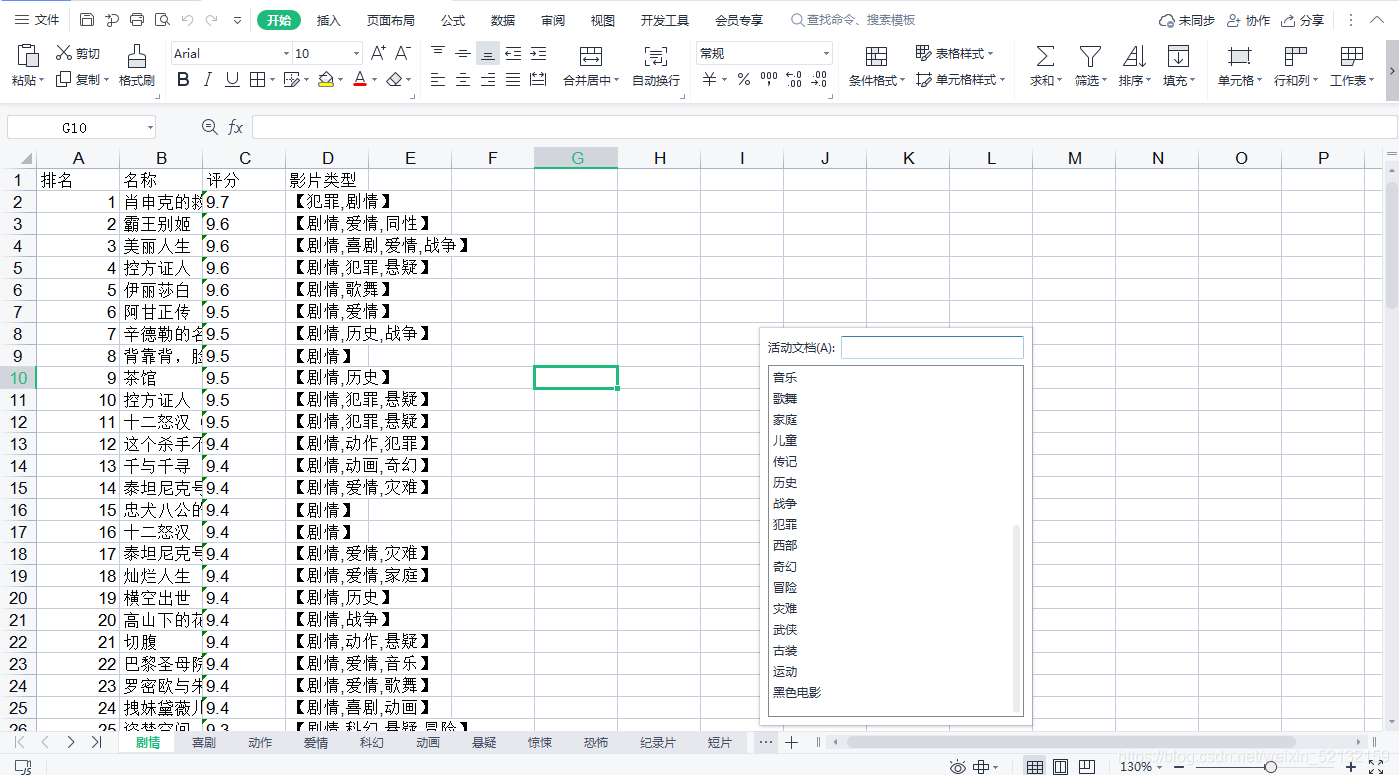
ѡ:���浽����
һ����˵,���ϵĹ��ܾ����������ѯ����Ҫ,����ʱ������Ҳ��Ҫ������������,��������ȡ���������������:
import requests
from pyquery import PyQuery as pq
import xlwt
# �½�������
wb = xlwt.Workbook(encoding='utf-8')
url1 = 'https://movie.douban.com/chart'
headers1 = {
'Cookie': '...',
'Referer': 'https://movie.douban.com/',
'User-Agent': '...'
}
response1 = requests.get(url1, headers=headers1).text
typelabels = pq(response1.text).find('.types span a') # ���ҽڵ�
typeslist = list(typelabels.items()) # תΪ�б�,����֮�������
headers2 = {
'Cookie': '...',
'Referer': 'https://movie.douban.com/typerank',
'User-Agent': '...'
}
for j in typeslist:
# �½�������
ws = wb.add_sheet(i.text, cell_overwrite_ok=True)
#��������
add = i.attr('href')
url2 = 'https://movie.douban.com/j/chart/top_list' + add.lstrip('/typerank')
response2 = requests.get(url=url2, headers=headers2)
#��ȡ������Ϣ
datas = [[i+1, n['title'], n['rating'][0], '��' + ','.join(n['types']) + '��'] for i, n in enumerate(response2.json())]
# ����ͷ�����ݺϲ�
table += [j for i in datas for j in i]
# ��������
for i, n in enumerate(table):
ws.write(i // 4, i % 4, n)
# ���湤����
wb.save('�����Ӱ�������а�.xls')
��:
��ܰ��ʾ:��ȡ������ȫ��,���ķѵ�ʱ�����,�����ĵȴ�����
�C the End �C
���Ͼ����ҷ�����ȫ������,��л�Ķ�!
������¼��ר��:Python����
��ע����,�����Ķ����ߵ�����,ѧϰ����Python֪ʶ!
https://blog.csdn.net/weixin_52132159
2021/8/8
�Ƽ��Ķ�
- Python���� | ��ȡbվ�������˻ῪĻʽ��Ļ,�ж����˴Ӷ������˻��ܹ�����?
- ����!Python���������ˢ�ֻ����˱����ԭ��!��ƪ���²��û����
- Pythonÿ��һ����:���深ֳ����?�Ұ�����������׳�ͳɳ�㶨��
- û�뵽�������꼶����Ŀ���ⲻ����?�ɲ��ܱ���С��,�����ܵ�Python�dz�
- Python:����Գ��ôŮ��?����̶̼��д������,����������!
- ��ѧPython��֪�Ӻ�����?ѧϰPython�ر��ؼ�,����ַ,����!
- Python����:datetime ʱ�������ģ�� ���� ʱ��Ļ�ȡ�Ͳ������
- ѧϰ�ʼ� | PyInstaller ʹ�ý̡̳�����pyinstaller���exeӦ�ó������ղ�!��
- ��Python���桿�������� requests ��С��(�����ղ�!)