官方文档
第三方库
pip install bs4
pip install reaqusts
pip install lxml
审源码

脚本
import json
import requests
from bs4 import BeautifulSoup
# 1.定义请求的url和请求头
url = 'https://old.lmonkey.com/t'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'}
# 2. 发送请求
res=requests.get(url,headers=headers)
# 3.判断请求是否成功,并获取请求的源代码
if res.status_code==200:
print(res.text)
# 4.解析数据
soup = BeautifulSoup(res.text,'lxml')
# 获取页面中的所有文章
divs = soup.find_all('div',class_="list-group-item list-group-item-action p-06")
varlist = []
for i in divs:
r = i.find('div',class_="topic_title")
if r:
# print(i.span)
vardict = {'title': r.text.split('\n')[0],
'url':i.a['href'],
"author": i.strong.a.text,
'pudate': i.span['title']}
varlist.append(vardict)
print(varlist)
#5. 写入数据
with open('./bs4test.json','w') as fp:
json.dump(varlist,fp)
结果


封装优化脚本
import json
import requests
from bs4 import BeautifulSoup
# BS4()
class BS4():
# 定义属性
url = 'https://old.lmonkey.com/t'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'}
# 响应代码存放的位置
res_html = None
# 存储解析后的数据
varlist = []
#初始化方法
def __init__(self):
#发起请求
res = requests.get(self.url,headers=self.headers)
if res.status_code==200:
self.res_html=res.text
if self.ParseData():
self.WriteJson()
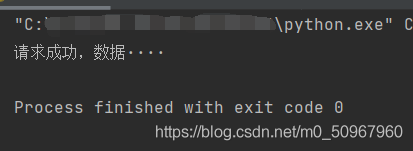
print("请求成功,数据・・・・")
else:
print("请求失败")
#解析html数据
def ParseData(self):
soup=BeautifulSoup(self.res_html,'lxml')
try:
#获取页面中所有文章
divs = soup.find_all('div', class_="list-group-item list-group-item-action p-06")
for i in divs:
r = i.find('div' , class_="topic_title")
if r:
vardict = {'title': r.text.split('\n')[0],
'url': i.a['href'],
"author": i.strong.a.text,
'pudate': i.span['title']}
self.varlist.append(vardict)
return True
except:
return False
#写入json数据
def WriteJson(self):
if self.varlist !=[]:
try:
with open('./bs4test2.json', 'w') as fp:
json.dump(self.varlist, fp)
return True
except:
return False
else:
print('无法获取当前解析的数据')
return False
BS4()
优化后结果