希望各位大佬指出不足,第一次记录,存在问题比较多,各位见谅
从未跑过爬虫代码的菜蛋从百度图片上批量爬取图片详细步骤亲测可用
这份代码目前用不到,但是以后肯定是要用,记录下,以后拿过来直接用
需求:爬虫从百度图片中批量爬取图片到本地
首先感谢大佬的博客,地址我放在这了:
https://blog.csdn.net/qq_52907353/article/details/112391518
详细的一步步来哦
打开百度输入某某,例如zta(不黑不吹),按F12,打开网页源码
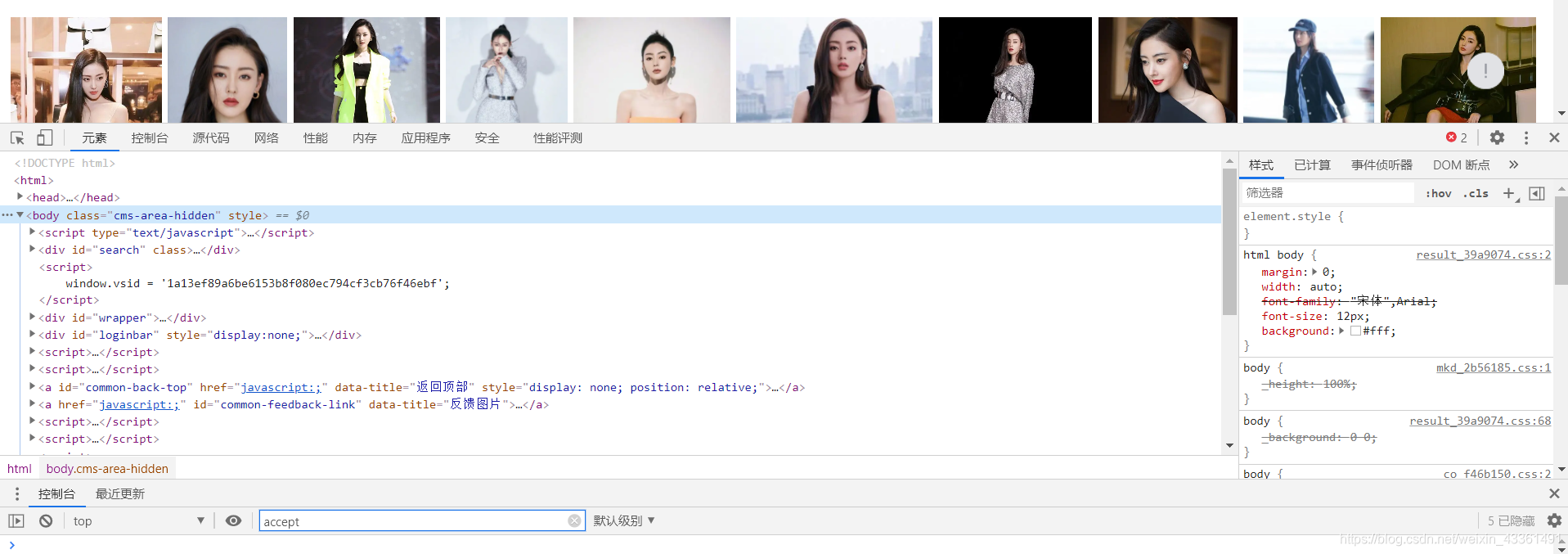
点开网络,刷新一下网页,记录下数据,依次点开下面图片中框框所示:

代码中需要标头的几部分信息分别是:
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36```
# 这就是网址信息
请求 URL: https://image.baidu.com/search/acjson?tn=resultjson_com&logid=9347931664272835957&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%BC%A0%E5%A4%A9%E7%88%B1&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=%E5%BC%A0%E5%A4%A9%E7%88%B1&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&nojc=&pn=120&rn=30&gsm=78&1628608999095=
查询字符串中的所有信息,(你可以一会在代码中ctrl+C ctrlV复制粘贴,改改格式,有点多,不急,爬出图片就行)
接下来就是全部代码了我做了详细的解释
```python
import requests
import re
import os
# 设置保存本地文件夹
save_folder = "./zhangtianai/"
if os.path.exists(save_folder):
print("文件夹存在")
else:
os.mkdir(save_folder)
page = input('请输入要爬取多少页:')
page = int(page) + 1
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
# 这个是记录总的爬取次数,如果多次添加,可以每次修改这个值,继续上次爬取图片数量的代码不知道怎么添加,以后慢慢学着添加
n = 0
pn = 1 # 默认最少爬一张
for m in range(1,page): # 总共下载多少页
header = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
url = "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=81708\
84394692947667&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%BC%A0%E\
5%A4%A9%E7%88%B1&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&l\
atest=©right=&word=%E5%BC%A0%E5%A4%A9%E7%88%B1&s=&se=&tab=&width=&height=&f\
ace=&istype=&qc=&nc=1&fr=&expermode=&nojc=&pn=60&rn=30&gsm=3c&1628595832275="
# 这部分参考CSDN大佬,做了一句解析的修改,但是填这个信息很麻烦但是目
# 前我python基础不好,也没有跑过爬虫的任何代码,在爬取百度图片是直接使
# 用requests.get解析url时,提示百度安全验证的error,也没解决,希望有
# 懂的大佬给我指示下这个问题我该怎么解决,各位大佬别嘲笑我能力差,我会慢
# 慢熟悉起来的。
param = {
"tn": "resultjson_com",
"logid": "8170884394692947667",
"ipn": "rj",
"ct": "201326592",
"is":"",
"fp": "result",
"queryWord": "张天爱",
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid":"",
"st":"",
"z":"",
"ic":"",
"hd":"",
"latest":"",
"copyright":"",
"word": "张天爱",
"s":"",
"se":"",
"tab":"",
"width":"",
"height":"",
"face":"",
"istype":"",
"qc":"",
"nc": "1",
"fr":"",
"expermode":"",
"nojc":"",
"pn": pn, # 这个参数记得要改哦,这是每次爬取的数量
"rn": "30",
"gsm": "3c",
}
page_text = requests.get(url=url, headers=header, params=param)
page_text.encoding = 'utf-8'
# 用json解析报/的error,使用正则拿到所有图片信息
info_list = re.findall('"thumbURL":"(.*?)"', page_text.text)
# page_text = page_text.json()
# info_list = page_text['data']
img_path_list = []
name = "zta" # 方便图片命名 (可以修改)
# 记录一个所有图片的ls,遍历进行下载
for i in info_list:
img_path_list.append(i)
for img_path in img_path_list:
img_data = requests.get(url=img_path, headers=header).content # 根据url下载图片
img_path = name + "_"+ str(n) + '.jpg' # 当前目录重命名进行保存
print(img_path)
with open(save_folder+img_path, 'wb') as fp: #
fp.write(img_data) # 这个部分读取的图片不知道是否损坏,过几天添加一个判断图片损坏的函数,
# 我现在工作中试试,好了分享给大家
n = n + 1
pn += 19 # 每次爬取图片的数量
```python
```python
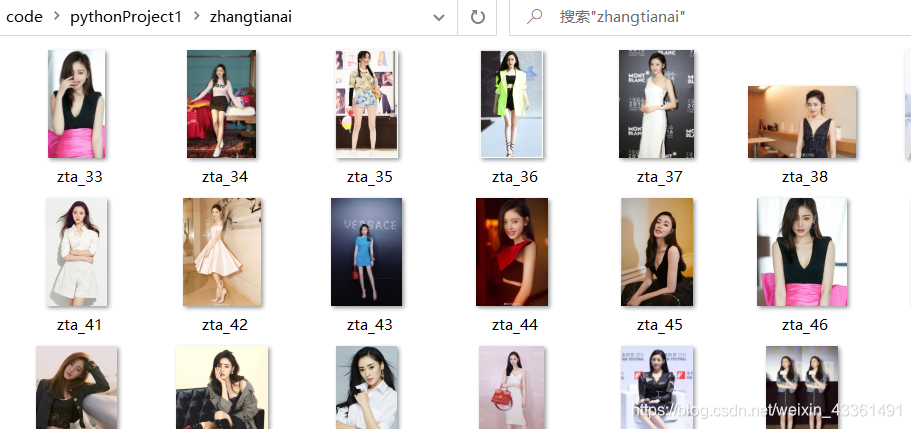
结果如下图:
过程及结果如下图:

爬取的图片
第一次写,写的很烂,排版什么的也都没注意,不求点赞,只希望能读到它
的人是有一点点帮助的,如果其中哪里有什么问题,希望大佬指点,还有我在代码中列举出来的直接requsets.get(url)解析百度的地址,报错百度安全验证Error,这个问题我还没解决,说的accept 添加到headers中,在哪里找到accept?。慢慢积累,路很长,也很远,希望能一直坚持下去~~~~~