1.背景
我最近准备把1985年-2019年的全国30m分辨率土地利用数据按照地级市进行裁剪与归纳,这需要用到Geopandas对shp数据进行批量操作。在安装Geopandas的python包时,遇到一系列模块包版本在加利福尼亚大学尔湾分校python库中下架的情况(这个网站几乎囊括了python所有whl文件,网址为:https://www.lfd.uci.edu/~gohlke/pythonlibs/ ) 。

加利福尼亚大学尔湾分校python库示意图
由此,我便产生了一个想法,下载所有的模块包并做一个备份。
2.下载方法
2.1 找到模块包的下载链接
首先这个网站不需要注册,也不需要fq,因此不用考虑反爬机制和网络连接设置。
当你要在这个网站下载python包时,只需要点击就可以下载。我猜想每个模块包的下载链接藏在html文档中的"li"标签中,F12检查要素。


可以看到li标签中没有下载链接,那下载链接应该是通过点击动作,服务器才会返回下载链接进行下载。理论上使用爬虫模拟点击获取链接,也是可行的。
但,不采用爬虫,还有更简单的。
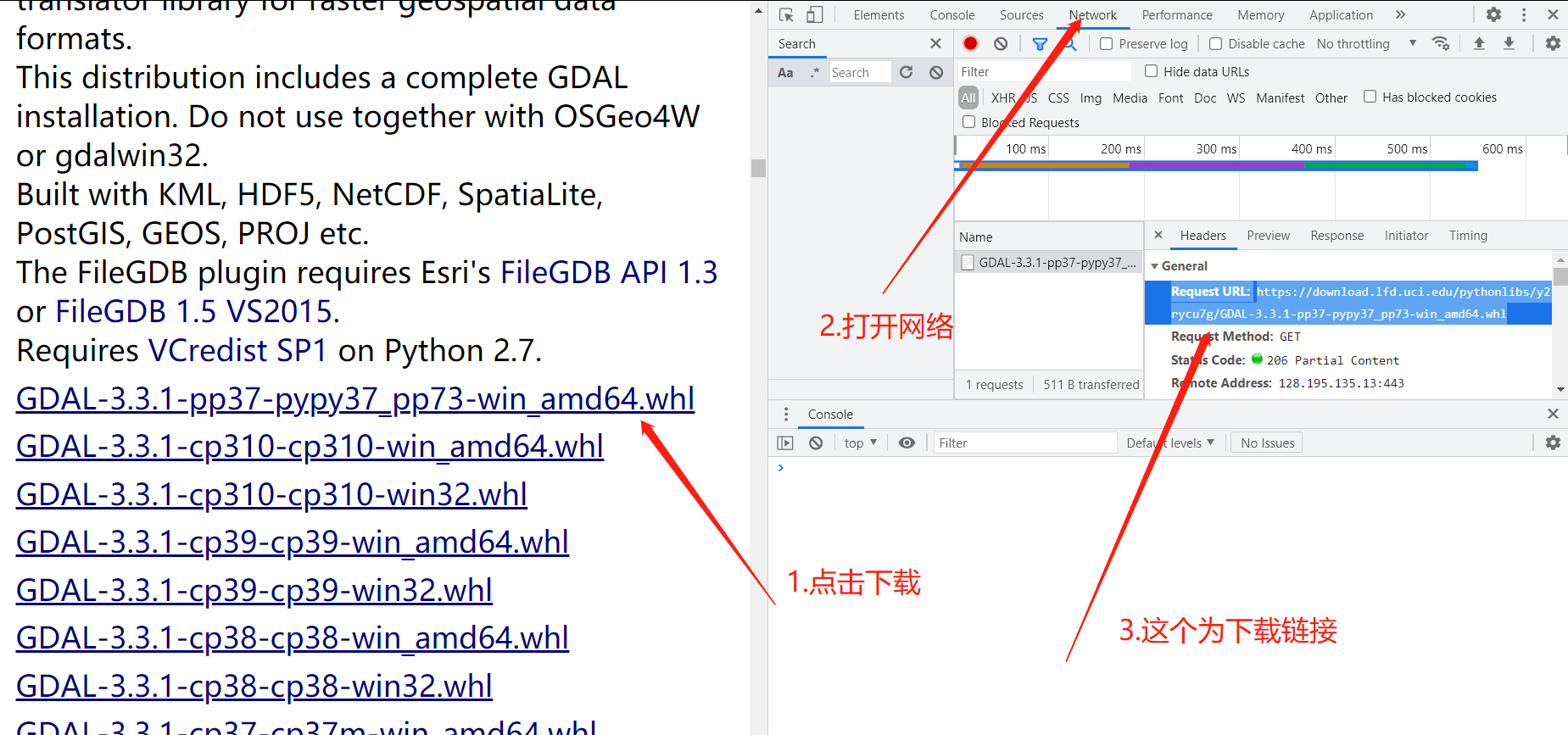
由此,我们获取了一个下载链接,链接为:
https://download.lfd.uci.edu/pythonlibs/y2rycu7g/GDAL-3.3.1-pp37-pypy37_pp73-win_amd64.whl, 将此链接放入浏览器访问,可以下载模块包。
2.2 确定下载思路
观察到下载链接在最后一个斜杠后的为模块包的名字,比如:GDAL-3.3.1-pp37-pypy37_pp73-win_amd64.whl。
那我们是不是可以用模块包的名字,直接复制到“https://download.lfd.uci.edu/pythonlibs/y2rycu7g/”之后。于是我又试了几个包,该方案是可行的。
因此,所有python包的下载链接为:固定的格式+模块名。
2.2 实操
(1)ctrl+A、ctrl+V、ctrl+C,复制网页,粘贴到notepad++:

(2)数据清洗,只保存python包的名字。这里面数据清洗,可以使用notepad++自带的正则表达式筛选、标记行、删除行,最后文档只包含python包名字:

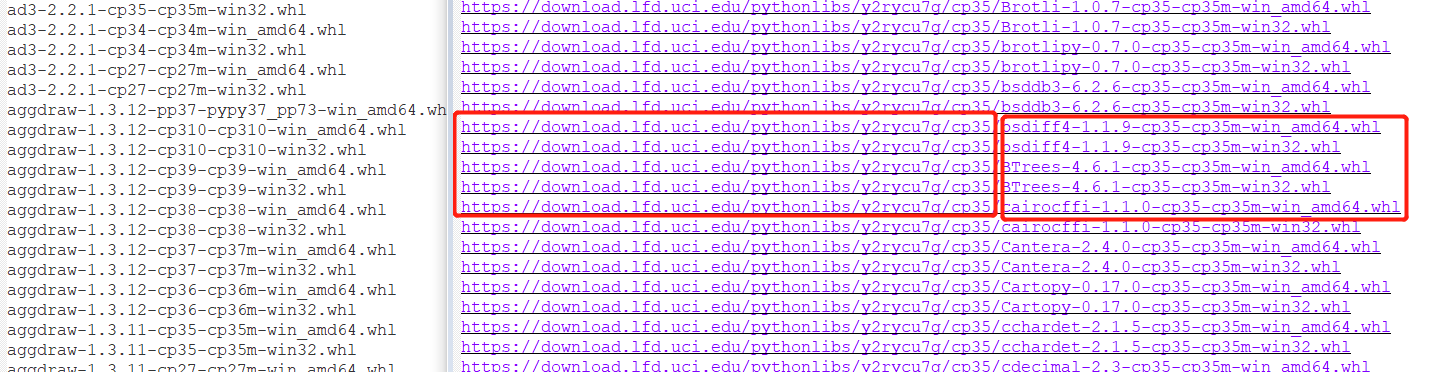
(3)添加链接,就完成了。其中python27、python33、python34、python35、python36需要额外添加一个斜杆内容,代表python版本:
2.2 下载
我刚开始打算用python,开多线程下载。后面一想,有下载链接了,用迅雷不好吗?数据链接通过迅雷下。
3.下载结果
以下是结果,共计8000个模块包,24G内存大小。

并且按照python版本进行了归类:

4.总结
1.全文思路:通过下载链接,获取链接生成方式;然后利用notepad++进行数据清洗,制作链接;最后通过迅雷下载。
2.对python包进行了备份,以后需要老版本的包,可以在百度云中下载。需要资源的,请找下面的二维码。
