实用模块及网页知识拓展
一、模拟网站登录
我们已经学会了如何在Network中提取xhr类请求内的数据,接下来要处理更多复杂的问题。首先,在之前的学习中,我们始终没有涉及到登录行为,而登录实际上,很多网站需要登录才能访问到我们所需要的信息。这一节,我们来解决如何登录的问题。
准备好练习网站,我们开始这次的学习。我们先手动登录网站,看看登陆之后的样子,账号为kaikeba,密码为kaikeba888。
点击登录并滑动至网页底部:

这里有评价页面。那么这节我们就以在练习网站发表评论为例,讲述如何用python完成登录以及发表评论。
首先,要用爬虫工程师的思维思考问题,打开登录网站之后就要右击检查:

这里记得要勾选preserve log(持续显示请求记录,防止请求记录被刷新)。然后我们进行登录,并记录新增的请求。登陆之后看到请求的变化:

相信大家已经发现了wp-login.php请求1,因为我们可以看到它的状态码是302(目标暂时性转移),而之前我们爬取请求内容的状态码都是200。
ps:可以试试双击这个请求,看有什么事情发生。
接下来我们查看一下这个请求的headers:

这里的url很短,并没有出现“#”或“?”来连接附带参数,并且请求方式也不是之前我们学到的“GET”,而是“POST”。
实际上,POST和GET一样,都可以带参数,但是POST不会在url里面显示出来。这也正是使用POST请求方式的原因,毕竟直接将账号和密码暴露在url里很不安全。当然,这两者的区别更在于get请求会应用于获取网页数据,比如我们之前学的 requests.get();而post 请求则应用于向网页提交数据,比如提交表单类型数据(如账号密码)。
get 和 post 是两种最常用的请求方式,除此之外,还有其他类型的请求方式,如 head, options 等,但由于这些都不是很常用,这里就不做介绍了。
get 和 post 这两种请求方式解释清楚了,就让我们继续往下看:

之前我们已经介绍过了headers里的许多参数,只有 response headers还没有详细介绍。正如requests headers存储的是浏览器的请求信息,response headers存储的是服务器的响应信息。下面就到了第一个重点内容:cookie。
1.cookie及其用法
cookie其实随处可见。当我们需要经常性登录一个网站又不想每次都输入账号密码时,通常会选择“记住密码”标识的选项:

勾选之后,就可以很长时间不用再次输入密码或者会直接自动登录了。这就是cookie在起作用。
如果我们登录kaikeba账号并勾选“记住我”,服务器就会生成一个cookie和这个账号绑定,接着会告诉浏览器,让浏览器把这个cookie存储到本地电脑,下一次浏览器带着cookie访问时,服务器可以直接识别,不需要再次输入账号和密码。
当然,cookie也有时效性,如果长时间未使用或本地存储的cookie丢失,亦或账号信息有所变动,网页还是需要重新登录,这就是原来的cookie失效了。
下面我们继续查看Form Data:
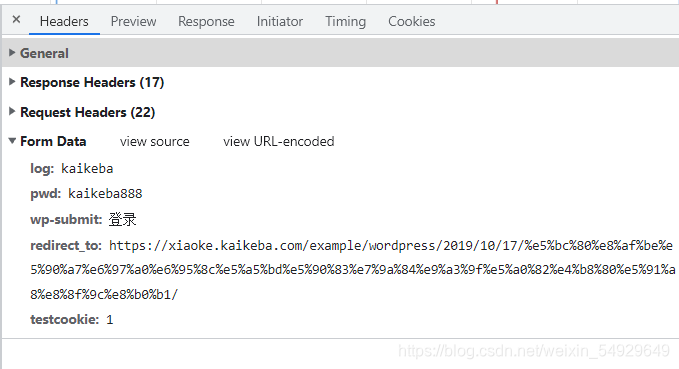
log和pwd 显然是我们的账号和密码,wp-submit是登录的按钮,redirect_to 后面带的链接是我们登录后会跳转到的页面网址,但是testcookie暂时还看不出是什么。
既然关于登录的
参数已经都找到了,我们就先尝试一下向服务器发起登录请求:
import requests
url='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
data={
'log': 'kaikeba',
'pwd': 'kaikeba888',
'wp-submit': '登录',
'redirect_to': 'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
log_in=requests.post(url,headers=headers,data=data)
# .post()和.get()方法的用法很类似,参考get()的用法写代码即可
print(log_in.status_code)
# 结果为:200
看到这个状态码,意味着服务器接收到并响应了登录请求,我们已经登录成功,接下来我们就开始研究怎么进行评论。
我们要利用程序来发表评论,就要先来发表一次评论,观察请求栏会有什么变化。首先清空请求栏,然后发表一条评论观察:
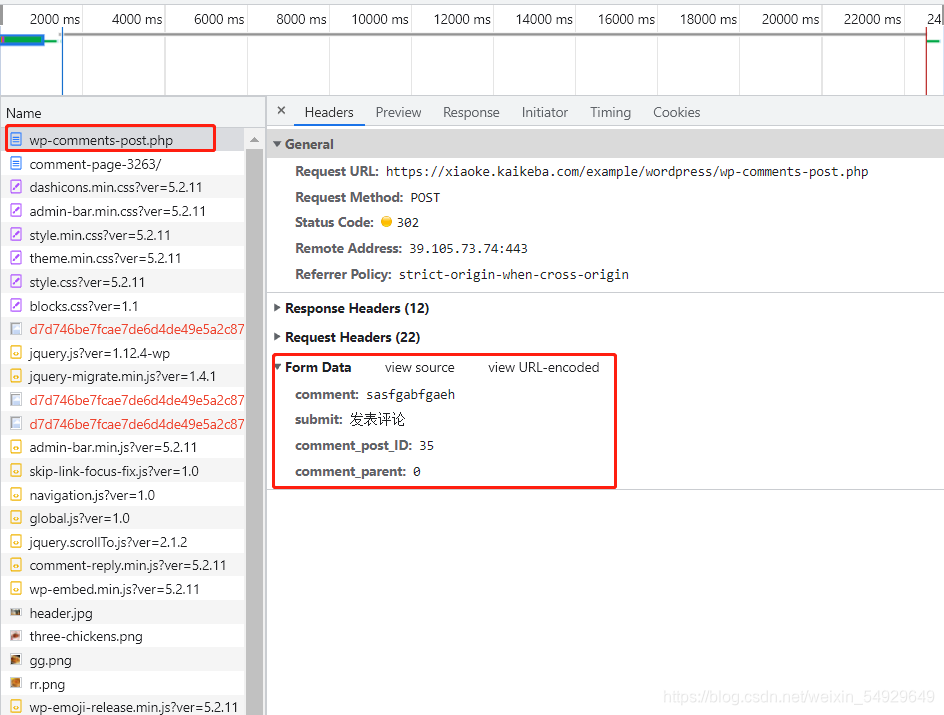
重新加载出来的请求里,wp-comments-post.php的Form Data的内容已经更新出我们刚刚发表评论的内容了。comment的内容对应我们刚刚发表的评论内容,submit对应发表评论按钮,另外两个参数看不太懂,不过也没关系,它们都是和评论有关的参数,所以直接照抄就好。
细看之下还会发现,wp-comments-post.php的数据并没有藏在 XHR 中,而是放在了Other 里。但常规情况下,大部分网站都会把这样的数据存储在 XHR 里,比如知乎的回答。
现在我们回忆一下发表评论的过程:首先得登录,其次得提取和调用登录的 cookie,然后还需要评论的参数,才能发起评论的请求。
现在,我们就只差提取和调用登录的 cookie了。而cookie是每个requests对象的属性,可以使用requests对象.cookie的方式查到:
import requests
url='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
data={
'log': 'kaikeba',
'pwd': 'kaikeba888',
'wp-submit': '登录',
'redirect_to': 'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
log_in=requests.post(url,headers=headers,data=data)
# 以下是新增代码
cookie = log_in.cookies
# 提取 cookie 的方法:调用 requests 对象(log_in)的cookie属性获得登录的cookie并保存
url_comment = 'https://xiaoke.kaikeba.com/example/wordpress/wp-comments-post.php'
# 我们想要评论的文章网址
data_comment = {
'comment': input('请输入你想要发表的评论:'),
'submit': '发表评论',
'comment_post_ID': '35',
'comment_parent': '0'
}
# 把有关评论的参数封装成字典
comment = requests.post(url_comment,headers=headers,data=data_comment,cookies=cookie)
# 用 requests.post 发起发表评论的请求,放入参数:文章网址、headers、评论参数、cookie 参数,赋值给 comment
# 调用 cookie 的方法就是在post请求中传入cookies = cookie的参数
print(comment.status_code)
# 打印出 comment 的状态码,若状态码等于 200,则证明我们评论成功
运行这段代码,我们可以输入“下面我们尝试发表评论”,观察运行结果:
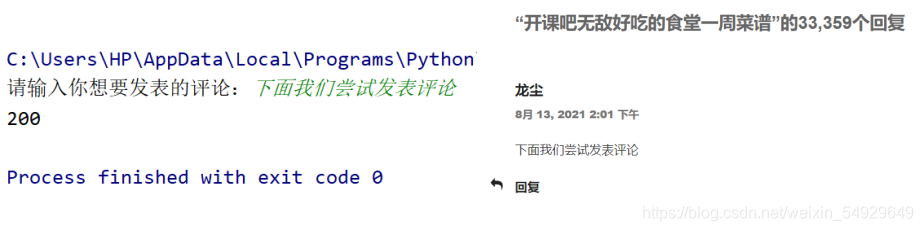
到这里我们已经成功发表了评论。但是项目并没有结束,这个代码还有优化空间。
注:这个网站不能发送重复的评论,大家练习的时候记得换评论内容
2.session及其用法
session,中文意会话。所谓会话,可以理解为我们用浏览器上网,到关闭浏览器的这一过程。
我们这里要学习的session,实际作用是帮助我们记录会话过程中,服务器用来记录特定用户会话的信息。举个例子,如果没有 session,可能会出现这样搞笑的情况:淘宝购物车添加了很多商品,但在想要结算时,却发现购物车空无一物,因为服务器根本没有帮你记录你想买的商品。
session和cookie的关系十分密切,因为cookie中存储着session的编码信息,session中又存储了cookie的信息。
以访问购物网页为例,当浏览器第一次访问时,服务器会返回set cookie的字段给浏览器,浏览器会把cookie保存到本地;等浏览器第二次访问这个购物网页时,就会带着 cookie 去请求,而cookie里带有session的编码信息,服务器立马就能辨认出这个用户,同时返回和这个用户相关的特定编码的 session。尽管存放在本地的cookie会有很多种可能失效,但是服务器里存储的cookie会一直保存session的编码信息,无论是更改密码,还是长时间未登陆等情况,都几乎不会丢失。
正因如此,我们每次重新登录购物网站后,即使cookie存储的内容(如密码)有所变化,只要session的编码信息没变,都还是可以找到保存在购物车中的商品。
session介绍完了,下面就来说如何优化代码。由于cookie和session的关系密切,我们来查查可不可以通过创建一个 session 来处理 cookie:

在 requests 的高级用法里,真有这样的方法~那么下面我们就实战一下:
import requests
session = requests.session()
# 用 requests.session()创建session 对象,它可以帮帮我们自动保持了cookie
url_login='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
# 登陆页面网址
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
data_login = {
# 用input函数实现输入账号,可以登录不同账号
'log': input('请输入账号:'),
'pwd': input('请输入密码:'),
'wp-submit': '登录',
'redirect_to':'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
# Form Data信息
session.post(url_login, headers=headers, data=data_login)
# 在创建的session下用post发起登录请求,放入参数:请求登录的网址、请求头和登录参数。
# session.post和requests.post用法一样,只是不再需要手动传参cookie
url_comment='https://xiaoke.kaikeba.com/example/wordpress/wp-comments-post.php'
# 把我们想要评论的文章网址赋值给 url_comment
data_comment = {
# 把有关评论的参数封装成字典
'comment': input('请输入你想要发表的评论:'),
'submit': '发表评论',
'comment_post_ID': '35',
'comment_parent': '0'
}
# 在创建的 session 下用 post 发起评论请求,放入参数:文章网址,请求头和评论参数,并赋值给 comment
comment=session.post(url_comment, headers=headers, data=data_comment)
# 打印 comment
print(comment)
请大家自己运行,可以看到程序会打印出我们评论的内容的,这也说明调用.post()方法会返回我们评论的内容。
这段代码可以自己提取cookie,也就意味着不需要先登录获取cookies再登录进行评论,可以只登录一次就完成评论。是不是简单了一些?但还不够理想。我们能不能将cookie存在指定位置,然后每次直接自动登录,发表评论呢?
3.cookies的存取及调用
①cookies的存储
下面我们就来探讨如何把cookie保存到指定位置,完成第一次登录后,每一次都进行自动登录。
我们先来看看cookie的内容和类型:
import requests
url='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
data={
'log': 'kaikeba',
'pwd': 'kaikeba888',
'wp-submit': '登录',
'redirect_to': 'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
log_in=requests.post(url,headers=headers,data=data)
cookie=log_in.cookies
print(cookie)
print(type(cookie))
cookie的内容我们看不懂,只是觉得有点像字典。这没有什么影响,但是这个类型有点令人头疼。我们可以将str类型的数据写入.txt文档,但这里的数据类型却是 ‘requests.cookies.RequestsCookieJar’。
如何保存这种类型的数据,相信大家已经回想起之前我们学过的json模块了。或许我们可以先把 cookie 转成字典,然后再通过 json 模块转成字符串。
当然我们想要使用数据的时候还需要先把字符串转化成字典,然后再转化为’RequestsCookieJar’类型。有json模块,字典和str类型的相互转化好说,但是怎么完成’RequestsCookieJar’类型与字典类型的双向转化呢?

这个方法引发了博主的一些思考。我们看代码:
import requests
import json
session=requests.session()
url='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
data = {
'log': 'kaikeba',
'pwd':'kaikeba888',
'wp-submit': '登录',
'redirect_to':
'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
session.post(url, headers=headers, data=data)
cookie_dict=requests.utils.dict_from_cookiejar(session.cookies)
# 把 cookie 转化成字典
print(type(cookie_dict))
# 查看cookie_dict类型
cookie_str = json.dumps(cookie_dict)
# 调用 json 模块的 dumps 函数,把 cookie 从字典再转成字符串
print(type(cookie_str))
# 查看cookie_str是否转化成了str类型
with open('cookie.txt', 'w+') as f:
f.write(cookie_str)
# 把已经转成字符串的cookie写入文件
f.seek(0)
# 移动文件指针,查看内容
print(f.read())
运行一下,和刚才的结果对比,cookie的文字内容没有变化但是类型已经成功地由’RequestsCookieJar’转化为字典,进而转化为str并被保存起来了。
②cookies的读取
接下来我们研究这个过程的逆过程。刚刚将cookies转化为字典类型的方法是:
dict_=requests.utils.dict_from_cookiejar()
# 从cookiejar转化为dict
那么将字典转化成cookies原有格式的方法也比较类似:
cookies=requests.utils.cookiejar_from_dict()
# 从dict转化为cookiejar
接下来,我们将刚保存的txt文档打开并将数据还原成RequestsCookieJar类型:
import requests
import json
with open('cookie.txt','r') as f:
con=f.read()
cookies_dict=json.loads(con)
# 将con内容由字符串转化为字典类型
print(type(cookies_dict))
# 查看转换是否成功
cookies_jar=requests.utils.cookiejar_from_dict(cookies_dict)
print(cookies_jar,'\n',type(cookies_jar))
# 输出为:<class 'dict'>
# <RequestsCookieJar[<Cookie ... for />, <Cookie .. for />, <Cookie.. for />]>
# <class 'requests.cookies.RequestsCookieJar'>
经过检查,输出的内容和其类型和我们最初直接从网页上获取的一致,我们成功完成了cookies的存取。
③cookies的调用
之前我们已经可以存储和读取cookies了,下面我们学着使用存储的cookies登录网页发表评论。编写代码之前,我们先梳理一下代码执行的过程:
(i)尝试读取cookies并登录网站,成功则执行(iii),读取到的cookies过期或没有读取到cookies执行(ii)
(ii)进入登录页面进行登录并存储cookies
(iii)发表评论
下面编写代码:
import requests,json
session=requests.session()
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
def cookies_read():
# 封装函数用以读取cookies
with open('cookie.txt', 'r') as f:
con=f.read()
cookies_dict=json.loads(con)
return(requests.utils.cookiejar_from_dict(cookies_dict))
def sign_in():
# 没有读取到cookies或cookies已过期
url='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
data_login = {
'log': input('请输入你的账号:'),
'pwd': input('请输入你的密码:'),
# 设置成可以手动输入登录信息
'wp-submit': '登录',
'redirect_to':
'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
session.post(url, headers=headers, data=data_login)
# 尝试登录并评论
# cookie存储
cookie_dict=requests.utils.dict_from_cookiejar(session.cookies)
# 转化为字典
cookie_str = json.dumps(cookie_dict)
# 转化为json字符串
with open('cookie.txt', 'w') as f:
f.write(cookie_str)
# 已经登录成功,进行评论的发表
def write_message():
url_comment = 'https://xiaoke.kaikeba.com/example/wordpress/wp-comments-post.php'
# 记录评论所需要的网址
data_comment = {
'comment': input('请输入你要发表的评论:'),
'submit': '发表评论',
'comment_post_ID': '35',
'comment_parent': '0'
}
return (session.post(url_comment, headers=headers, data=data_comment))
# 进行评论并返回评论内容
# 主函数
try: # 获取cookies
session.cookies = cookies_read()
except :
sign_in()
session.cookies = cookies_read()
comment=write_message()
if comment.status_code == 200:
print('成功啦!')
else: # 防止之前存储的cookies过期
print('存储的cookies过期,需要重新登录!')
sign_in()
session.cookies = cookies_read()
comment = write_message()
这段代码需要进行三次测试,首先直接运行,看能否发表评论;然后更改cookie.txt文档内容(注意要保证字典的完整性,不能只删除某一个键或值等,否则会报错)再运行,运行之后观察cookie.txt文档内容是否和修改之前一样;然后删除这个文档再运行一次。三次都成功运行则代码没有问题。当然,想要清楚地看到代码运行过程的小伙伴可以使用debug进行单步运行:

这个样子说明我们已经运行成功了。这才是我们优化代码的最终版。
我们已经发过的评论就不能再发了,小伙伴们练习的时候记得换评论内容。
二、用程序指挥浏览器
上一节我们已经介绍了网页登录,但是有些网站的登录验证码很难破解,还有的网站对URL的加密逻辑很复杂,像之前爬过的五月天歌曲列表,URL的参数变量比较难找。通常这样的情况下,想要攻破反爬技术会有些难度。下面我们就来介绍一款新的武器:
1.初识selenium
selenium是一个强大的 Python 库,使用selenium后可以看到浏览器自动打开、输入、点击等操作,很像我们在操作浏览器。
我们编写的程序遇到验证码很复杂的网站时,selenium 可以使用延时函数暂停运行,进而让人工介入,手动输入验证码,然后把剩下的操作交给程序去完成。
同时,对于那些交互复杂、加密复杂的网站,requests.get()函数爬取不到全部的网页代码,只能在Network里寻找对应请求。归根结底,这是因为没有真正打开网站的时候,很多请求是不会由浏览器向服务器发起。但selenium可以真正的打开一个网站,向服务器发出并完成所有请求后,将它们一起组成开发者工具的Elements中所展示的样子。也因此使用selenium爬取网站的内容时不必寻找请求源,而是可以直接在Elements中爬取内容,爬动态网页如爬静态网页2一样简单。
当然,selenium也有自己的缺点。由于要真实地运行本地浏览器,打开浏览器以及等待网渲染完成需要一些时间,selenium的工作不可避免地牺牲了爬取速度和更多资源。不过,肯定还是要比手动的操作快很多。
2.selenium的使用
以上说了很多文字内容,多少有些难以理解,因此我们接下来一起学习selenium的使用。那么,和其它所有Python库一样,需要安装selenium。当然只有标准库还不够,我们想要让代码操作浏览器还需要安装驱动。
安装完成之后,先运行一下下面的代码,体会一下selenium的神奇之处:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
time.sleep(2)
teacher = driver.find_element_by_id('teacher')
teacher.send_keys('1')
assistant = driver.find_element_by_name('assist')
assistant.send_keys('2')
time.sleep(2)
button = driver.find_element_by_tag_name('button')
time.sleep(1)
button.click()
time.sleep(5)
driver.close()
首先我们看到的是【你好,X战警】几个大字,一秒之后,它会自动跳转到一个新的页面,请你输入最喜欢的老师和助教,点击提交之后,就能看到一个关于爬虫的课程表。仔细看会发现,在这个过程中,网页URL一直没有变化。可见这是个动态网页。
代码运行完之后,我们手动登录刚刚的网站,执行一下同样的操作试试看。
下面我们开始代码的讲解:
from selenium import webdriver
# 从 selenium 库中调用 webdriver 模块
driver = webdriver.Chrome()
# 设置引擎为 Chrome,真实地打开一个 Chrome 浏览器
driver 是实例化的浏览器,后面也会经常出现,因为我们要控制这个实例化的浏览器为我们做一些事情。
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
# 打开网页
time.sleep(3)
# 延时,让计算机加载全部请求。这个时间可以依据计算机性能的不同而自行设置
driver.close()
# 关闭浏览器
driver.get(URL) 是 webdriver 的一个方法可以打开指定的网页,使用的浏览器,就是刚刚实例化的浏览器。这个网页被打开后,网页的全部数据就会加载到浏览器中,也就都可以被我们获取到了。driver.close() 是关闭浏览器驱动,每次打开浏览器后都需要关闭,否则会占用系统内存。当然,打开的浏览器也可以手动关闭,不过浏览器关闭之后代码就不能获取网页的信息了。因此想要手动关闭的小伙伴一定要记得在代码运行完后进行关闭。
3.解析网站,提取数据
与BeautifulSoup库类似,selenium 库同样也具备解析数据、提取数据的能力。他们的底层原理一致,只是一些细节和语法上有所出入。首先明显的一个不同就是selenium所解析提取的,是Elements中的所有数据,而BeautifulSoup所解析的则只是Network中第 0 个请求的响应。
下面就让我们通过使用 selenium 来提取【你好,X战警】网页中,
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
time.sleep(3)
label=driver.find_element_by_tag_name('label')
# 调用wbdriver的专有查找方法
print(label.text)
print(type(label))
driver.close()
# 运行结果:提示:(小K老师)
# <class 'selenium.webdriver.remote.webelement.WebElement'>
从这个结果中可以看出想要提取到的label标签名对应的第一个元素的文字内容。其实不难发现,解析代码是由driver实例打开网页时自动完成的,提取数据则是driver实例的一个方法:.find_element_by_tag_name()。
当然,webdriver自带的查找方法有很多,并不只局限于依据标签提取内容,还有非常直截了当的方法:
| 方法 | 作用 |
|---|---|
| found_element_by_id() | 通过元素id查找 |
| found_element_by_class_name() | 通过元素class查找 |
| found_element_by_tag_name() | 通过元素标签名查找 |
| found_element_by_name() | 通过元素内容查找 |
| found_element_by_partial_link_text() | 通过文本的内容查找标签中含有的超链接 |
| found_element_by_link_text() | 通过文本的部分内容查找标签中含有的超链接 |
下面我们进行举例说明:
# driver为实例化的浏览器,已经使用.get()方法打开需要提取内容的网站
# find_element_by_tag_name:通过元素的名称选择
# 如: <h1>你好,X战警</h1>
driver.find_element_by_tag_name('h1')
# find_element_by_class_name:通过元素的 class 属性选择
# 如: <h1 class="title">你好,X战警</h1>
driver.find_element_by_class_name('title')
# find_element_by_id:通过元素的 id 选择
# 如 :<h1 id="title">你好,X战警</h1>
driver.find_element_by_id('title')
# find_element_by_name:通过元素的 name 属性选择
# 如 <h1 name="hello">你好,X战警</h1>
driver.find_element_by_name('hello')
# find_element_by_link_text:通过链接文本获取超链接
# 如 <a href="spidermen.html">你好,X战警</a>
driver.find_element_by_link_text('你好,X战警')
# find_element_by_partial_link_text:通过链接的部分文本获取超链接
# 如 <a href="https://xiaoke.kaikeba.com/example/X-Man/">你好,X战警</a>
driver.find_element_by_partial_link_text('你好')
以上方法均只能提取第一个元素,需要提取全部元素时,将“element”改为“elements”即可。提取出的元素类型为:WebElement,这个类型与Tag类似,也有一个属性为.text,用于把提取出的元素用字符串格式显示;并且它也有一个方法.get_attribute(),可以通过属性名提取属性的值。
| WebElement | Tag | 作用 |
|---|---|---|
| .text | .text | 获取文字内容 |
| .get_attribute() | [’’] | 依据属性名获取属性值 |
举个例子介绍这个属性:

假如我们想找到type对应的值:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
time.sleep(2)
label = driver.find_element_by_class_name('form-teacher')
print(type(label))
print(label.get_attribute('type'))
# 获取type属性的值
driver.close()
# 结果为:<class 'selenium.webdriver.remote.webelement.WebElement'>
# text
那么,有的小伙伴可能会说,我已经习惯使用.find()和.find_all()来提取内容了,selenium提取的内容可以用BeautifulSoup解析吗?
当然可以了,下面我们就介绍一下selenium如何与BeautifulSoup愉快合作。webdriver有一个方法page_source,可以获取到渲染完整的网页代码,我们只需要使用该方法将获取到的网页源代码交给BeautifulSoup来解析就好了,上代码:
from selenium import webdriver
import time
from bs4 import BeautifulSoup as bs
driver = webdriver.Chrome()
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
time.sleep(2)
p=driver.page_source
# 获取到渲染完整的网页源代码,这种方式获取到的内容已经是
# str类型,可以直接给BeautifulSoup解析。
page_source=bs(p,'html.parser')
want = page_source.find_all('span')[1].find('input')
print(type(want))
print(want)
print(want['type'])
# 获取type属性的值
driver.close()
# 输出为:<class 'bs4.element.Tag'>
# <input class="form-teacher" id="teacher" name="teacher" type="text"/>
# text
很好,我们已经学会了selenium与BeautifulSoup合作了,那么接下来给大家重点解释一下这句代码:
want = page_source.find_all('span')[1].find('input')
首先,使用.find_all()找到的内容为一个列表,里面每个元素的类型均为Tag。

从这张图中不难发现,我们想找的标签在第二个span标签下,因此我们需要使用.find_all()找到所有的span标签,并锁定这个列表中第二个(下标为1的)元素,然后再寻找input标签。当然,这里有很多更简单的方法找到我们想要的内容,故意选择这种方法只是和大家分享一下这种用法。
4.文本输入与模拟点击
上面我们已经把提取内容讲解的十分清楚了,接下来继续讲解如何利用代码向网页输入内容并进行模拟点击。
现给大家介绍我们会用到的方法:
| 方法 | 作用 |
|---|---|
| .clear() | 清除元素的所有内容 |
| .send_keys() | 模拟键盘输入,参数为需要输入的内容 |
| .click() | 模拟点击元素 |
我们可以通过之前介绍的方法找到需要填写内容的位置:

找到后我们就开始实践:
from selenium import webdriver
import time
driver = webdriver.Chrome()
# 设置引擎为 Chrome,真实地打开一个 Chrome 浏览器
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
# 访问页面
# 暂停两秒,等待浏览器缓冲
time.sleep(2)
# 暂停两秒,等待浏览器缓冲
teacher = driver.find_element_by_id('teacher')
# 找到【请输入你喜欢的老师】下面的输入框位置
teacher.send_keys('1')
# 输入文字
time.sleep(1)
# 等待一秒,小伙伴们要盯住【请输入你喜欢的助教】下面的输入框
teacher.clear()
# 清除之前输入的内容
# .clear()多用于输入框有字但不是我们想输入的内容时
time.sleep(1)
teacher.send_keys('k老师')
# 重新输入内容
time.sleep(1)
assistant = driver.find_element_by_name('assist')
# 找到【请输入你喜欢的助教】下面的输入框位置
assistant.send_keys('学姐')
# 输入文字
time.sleep(1)
button = driver.find_element_by_tag_name('button')
# 找到【提交】按钮
button.click()
# 点击【提交】按钮
time.sleep(2)
driver.close()
这样一来,这节理要讲的最后的一部分内容已经包含在代码里了,要重点看注释。在学习输入、清除内容和模拟点击的同时,也顺带复习一下之前学的东西吧,然后我们进行下一节的学习。
三、让爬虫学会定时汇报
有时候,我们编写爬虫的目的不是一次性爬取内容,而是需要爬虫定期汇报,比如每天早晨上班之前为我们发送天气预告。关于定时功能,python自带的标准库――time和datetime都可以完成。但是,这两个基本库只有最原始基础的功能,实现起来的操作逻辑比较复杂,因此选择使用第三方库schedule是实现,其代码也比较简单。
1.schedule的使用方法
首先,先给大家提供schedule的官方文档介绍。看不懂也没有关系,下面我们一起学习这个库的一些基本用法:
import schedule
import time
def job():
print("Working in progress...")
# 定义job函数,执行函数会'I'm working...',用以监视代码是否正常工作
# 部署情况
schedule.every(5).seconds.do(job)
# 每 5s 执行一次 job() 函数
schedule.every(10).minutes.do(job)
# 部署每 10 分钟执行一次 job() 函数的任务
schedule.every().hour.do(job)
# 部署每 x 小时执行一次 job() 函数的任务
schedule.every().day.at("10:30").do(job)
# 部署在每天的 10:30 执行 job() 函数的任务
schedule.every().monday.do(job)
# 部署每个星期一执行 job() 函数的任务
schedule.every().wednesday.at("13:15").do(job)
# 部署每周三的 13:15 执行函数的任务
while True:
schedule.run_pending()
# 检查部署的情况,如果任务准备就绪,就开始执行任务
time.sleep(1)
# 程序每秒进行一次检查部署,防止检查频率过高占用计算机资源
实战中,我们需要自己写好job()函数,然后确定部署时间,需要注意的是,如果部署情况为1秒执行一次job()函数,而检查部署为3秒检查一次,那么运行结果是3秒执行一次job()函数,也就是取这两者的最小公倍数。
下面举个例子:
import schedule
import time
def job():
print("Working in progress...")
# 定义job函数,执行函数会'I'm working...',用以监视代码是否正常工作
# 部署情况
schedule.every(1).seconds.do(job)
while True:
# 检查部署的情况,如果任务准备就绪,就开始执行任务
schedule.run_pending()
time.sleep(1)
运行的结果是每隔一秒,计算机输出一次“Working in progress…”。
2.schedule的实战应用
上面我们已经学会了schedule的基本使用方法,下面我们就来做一个实战,让我们的的爬虫每天以邮件方式向我们汇报明天天气。
i.爬取明天的天气信息
首先先找到中国天气网,选择自己所在的城市。这里以北京为例,选择七天的天气预报:

还是用老方法找到源代码中气温的位置(这个网页的HTML源代码就包含了全部的网页的全部信息。要养成动手实践之前要注意先查看一下的习惯。)找到位置以后,我们确定要爬取的内容,这里仅选取气温和天气。
下面先编写这部分代码:
我们先看看全部代码,验证一下有没有问题:
import requests
from bs4 import BeautifulSoup as bs
url='http://www.weather.com.cn/weather/101010100.shtml'
headers= {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'}
res=requests.get(url, headers=headers, verify=False)
print(res.text)
运行这段代码,可以很明显看出,提取到的内容是满足我们的需求的,但是却出现了很多乱码:

出现这种问题一定是编码解码的过程出现了问题,运用之前介绍的知识可以解决这个问题,但是这里给大家介绍一种新的方法,首先我们看到网页源代码的最开始部分:

这里是这个网站所用到的编码方式。那么我们只需要在给res赋值之后,设置res的编码方式为utf-8即可。代码改进如下:
res=requests.get(url, headers=headers, verify=False)
res.encoding = 'utf-8'
下面我们就正式爬取天气内容:
import requests
from bs4 import BeautifulSoup as bs
url='http://www.weather.com.cn/weather/101010100.shtml'
headers= {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'}
res=requests.get(url, headers=headers, verify=False)
# 定义 Response 对象的编码
res.encoding = 'utf-8'
analysis=page_source=bs(res.text,'html.parser')
tem=analysis.find_all(class_='tem')[1]
print('明天气温为:'+tem.text.replace('\n',''),end=',')
weather=analysis.find_all('p',class_="wea")
print('天气为:'+weather[1]['title'].replace('\n','')+'。')
# 输出为:明天气温为:29℃/21℃,天气为:多云。
ii.使用QQ邮箱发送邮件
如何使用python发送邮件在之前的文章中有过具体介绍,这里不做赘述,直接给出代码,忘记的小伙伴可以去复习。
import smtplib
from email.mime.text import MIMEText
from email.header import Header
# 采集信息
from_addr = input('请输入发件人的邮箱: ')
password = input('请输入发件人的 QQ 邮箱授权码: ')
to_addrs=input('请输入收件人邮箱:')
text = '将天气信息写入邮件正文内容'
msg = MIMEText(text, 'plain', 'utf-8')
# 设置邮件头信息
msg['From'] = Header(from_addr)
msg['To'] = Header(to_addrs)
# 这句是群发格式,单发也可以这样写
msg['Subject'] = Header('明日天气预报')
try:
server = smtplib.SMTP_SSL()
server.connect('smtp.qq.com', 465)
server.login(from_addr, password)
server.sendmail(from_addr, to_addrs, msg.as_string())
print('发送成功')
server.quit()
except :
print('发送失败')
iii.设置定时信息
应用之前讲的知识设置发送时间,当然,测试运行时可以把发送时间设置成几秒:
import schedule
import time
def send():# 这里之后会换成具有实际意义的函数
return 0
# 部署情况
schedule.every().day.at("22:30").do(send)
while True:
schedule.run_pending()
time.sleep(1)
iv.代码整合
各部分的功能都实现之后,我们将代码整合:
import requests
from bs4 import BeautifulSoup as bs
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import schedule
import time
url='http://www.weather.com.cn/weather/101010100.shtml'
headers= {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'}
from_addr = input('请输入发件人的邮箱: ')
password = input('请输入发件人的 QQ 邮箱授权码: ')
to_addrs = input('请输入收件人邮箱:')
def find_weather():# 查找函数,用于查看明天天气
res = requests.get(url, headers=headers, verify=False)
# 定义 Response 对象的编码
res.encoding = 'utf-8'
analysis = page_source = bs(res.text, 'html.parser')
tem = analysis.find_all(class_='tem')[1]
weather = analysis.find_all('p', class_="wea")
return '明天气温为:' + tem.text.replace('\n', '')+','+'天气为:' + weather[1]['title'].replace('\n', '') + '。'
def send_email():
weather=find_weather()
text = weather
msg = MIMEText(text, 'plain', 'utf-8')
# 设置邮件头信息
msg['From'] = Header(from_addr)
msg['To'] = Header(to_addrs)
# 这句是群发格式,单发也可以这样写
msg['Subject'] = Header('明日天气预报')
try:
server = smtplib.SMTP_SSL()
server.connect('smtp.qq.com', 465)
server.login(from_addr, password)
server.sendmail(from_addr, to_addrs, msg.as_string())
print('发送成功')
server.quit()
except:
print('发送失败')
schedule.every().day.at("22:30").do(send_email)
while True:
schedule.run_pending()
time.sleep(1)
到此为止,我们的目的已经完成了。感兴趣的小伙伴可以自己运行试试。这节的内容就到这里了,我们下篇文章见~