1.什么是框架
一个集成了很多功能且具有很强通用性的一个项目模拟。
2.如何学习框架
专门学习框架封装的各种功能的详细用法。
3.什么是Scrapy
爬虫中封装好的一个明星框架。
功能:高性能的持久化存储,异步的数据下载,高性能的数据分析,分布式
3.1环境安装
1.pip install scrapy
3.2scrapy基本使用
scrapy创建工程是根据终端指令进行创建
创建工程步骤:
1.进入终端:(Terminal[Alt+F12])
2.进入指定目录【cd 第十章】cd 目录
3.创建工程【scrapy startproject xxxPro】
如:scrapy startproject firstBlood
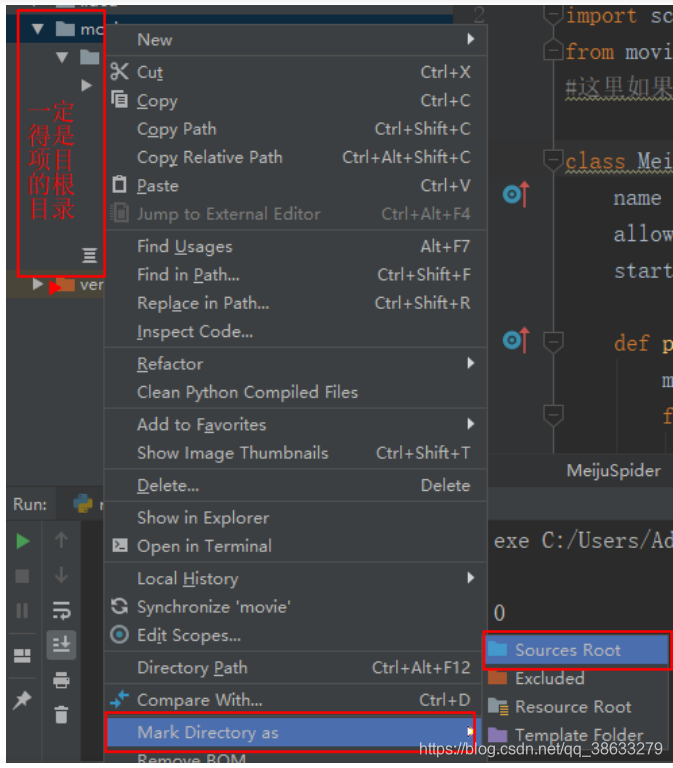
查看:1个和工程同名的文件夹和1个scrapy.cfg配置文件
spyder文件夹:爬虫文件夹,又称爬虫目录:在该文件夹中需要创建一个爬虫源文件
__init__.py:
items.py:
middlewares.py:
pipelines.py:
settings.py:放置项目对应配置文件(应该经常使用)
4.进入工程目录中【cd xxxPro/】
如:cd firstBlood/
5.在spiders子目录中创建一个爬虫文件【scrapy genspider spiderName www.xxx.com】
如:scrapy genspider first www.xxx.com #srcapy genspider 爬虫文件名称 起始的URL
6.执行工程【scrapy crawl spiderName】
如:scrapy crawl first #first为自己在spider文件夹中创建的爬虫文件名称
终端调试技巧:
1.清除屏幕:cls【Ctrl+L】
2.不看日志:scrapy crawl first --nolog #scray crawl 爬取文件名 --nolog
3.仅输出错误日志:在settings.py中添加【LOG_LEVEL = ‘ERROR’】
4.退回上一级目录 【cd …】
3.2 案例1:简单实用Scrapy
import scrapy
class First1Spider(scrapy.Spider):
name = 'first1'
start_urls = ['https://www.qiushibaike.com/text/']
#解析网页
def parse(self, response):
div_list = response.xpath('//*[@id="content"]/div/div[2]//div')
for div in div_list:
author = div.xpath('./div[1]/a/img/@alt')[0].extract()
content = div.xpath('./a/div[@class="content"]/span//text()')[0].extract()
# content = ''.join(content)
print(author,content)
break
步骤1. 进入目录:cd 第十章
步骤2. 创建工程 scrapy startproject qiushi
步骤3. 进入工程中的爬虫文件夹中 cd spider/
步骤4. 创建爬虫文件 scrapy genspider first1 www.xxx.com
步骤5. 修改setting.py配置中的USER-AGENT、ROBOTTXT、LOG_LEVEL
步骤6. 爬虫文件编辑
4.Scrapy持久化存储
4.1基于终端指令存储
要求:只可以将parse方法的返回值存储到本地的文本文件中
注意:持久化存储对应的文本文件的类型只能是:(‘json’, ‘jsonlines’, ‘jl’, ‘csv’, ‘xml’, ‘marshal’, ‘pickle’)
指令:scrapy crawl 爬虫文件 -o 保存文件名称 如:scrapy crawl first1 -o ./qiushi.csv
缺点 :局限性比较强(数据只可以存储到指定后缀的文本文件中)
案例:
import scrapy
class First1Spider(scrapy.Spider):
name = 'first1'
start_urls = ['https://www.qiushibaike.com/text/']
#解析网页
def parse(self, response):
#网页解析 该xpath同etree中的xpath不同,但解析方式是相同的
div_list = response.xpath('//*[@id="content"]/div/div[2]/div')
all_data = []
for div in div_list:
#获取作者名称
author = div.xpath('./div[1]/a[1]/img/@alt')[0].extract()
#获取文本内容
content = div.xpath('./a[1]/div[1]/span//text()')[0].extract()
dic = {
'author':author,
'content':content
}
all_data.append(dic)
print(author,content)
return all_data
备注:1.终端持久化存储,必须在parse()方法中有return返回值,才能保存在终端。
2.终端Tessertial中输入scrapy crawl first1 -o ./qiushi.csv
4.2基于管道进行持久化存储
步骤如下:
1.数据解析【first2.py】
2.在item类中定义相关的属性【items.py中添加:author = scrapy.Field()和 content = scrapy.Field()】
3.将解析的数据封装存储到item类型的对象
4.将item类型的对象提交给管道进行持久化存储
5.在pipelines管道类的process_item要将其接受到的item对象中存储的数据进行持久化存储操作
6.在配置文件中开启管道
邮电:通用性强
案例:
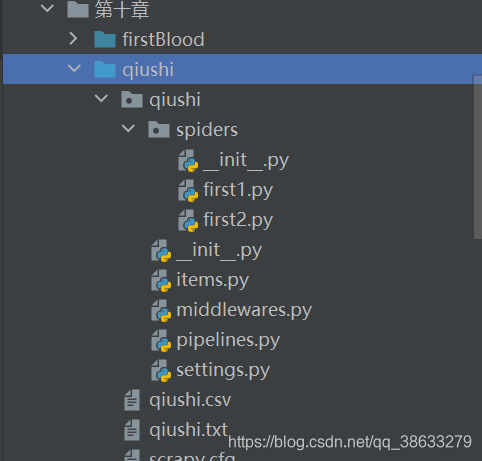
1.first2.py
import scrapy
from qiushi.items import QiushiItem
class First2Spider(scrapy.Spider):
name = 'first2'
start_urls = ['https://www.qiushibaike.com/text/']
#1.解析网页
def parse(self, response):
# 网页解析 该xpath同etree中的xpath不同,但解析方式是相同的
div_list = response.xpath('//*[@id="content"]/div/div[2]/div')
all_data = []
for div in div_list:
# 获取作者名称
author = div.xpath('./div[1]/a[1]/img/@alt')[0].extract()
# 获取文本内容
content = div.xpath('./a[1]/div[1]/span//text()')[0].extract()
#3.实例化item对象
item = QiushiItem()
#将解析的数据封装到该类型对象当中,其中该类型指item类型
item['author'] = author
item['content'] = content
#4.将item类型的对象提交给管道
yield item
2.items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class QiushiItem(scrapy.Item):
# define the fields for your item here like:
author = scrapy.Field()
content = scrapy.Field()
3.pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class QiushiPipeline(object):
fp = None
#重写父类的get_spider方法:该方法只在开始爬虫的时候被调用一次,不会被反复调用
def open_spider(self,spider):
print('开始爬虫!!!')
self.fp = open('./qiushi.txt','w',encoding='utf-8')
#专门迎来处理item类型对象,该方法可以接收爬虫文件提交过来的item对象
#该方法每接收到一个item,就会调用一次
def process_item(self, item, spider):
author = item['author']
content = item['content']
self.fp.write(author+':'+content+'\n')
return item
#关闭get_spider方法
def close_spider(self,spider):
print('结束爬虫!!!')
self.fp.close()
4.settings.py
ITEM_PIPELINES = {
'qiushi.pipelines.QiushiPipeline': 300, #300表示优先级
}
步骤1.首先在first2.py中完成数据的解析
def parse(self, response):
# 网页解析 该xpath同etree中的xpath不同,但解析方式是相同的
div_list = response.xpath('//*[@id="content"]/div/div[2]/div')
all_data = []
for div in div_list:
# 获取作者名称
author = div.xpath('./div[1]/a[1]/img/@alt')[0].extract()
# 获取文本内容
content = div.xpath('./a[1]/div[1]/span//text()')[0].extract()
步骤2.在items.py中定义相关的属性
author = scrapy.Field()
content = scrapy.Field()
步骤3.在first2.py中实例化item对象,引入from qiushi.items import QiushiItem
#3.实例化item对象
item = QiushiItem()
#将解析的数据封装到该类型对象当中,其中该类型指item类型
item['author'] = author
item['content'] = content
步骤4.将item类型的对象提交给管道
1.首先在first.py中输入:
#4.将item类型的对象提交给管道
yield item
步骤5…使用pipelines.py类的process_item将接受到的item对象中存储的数据进行持久化存储操作
#.在pipelines.py中完成管道处理:
fp = None
#重写父类的get_spider方法:该方法只在开始爬虫的时候被调用一次,不会被反复调用
def open_spider(self,spider):
print('开始爬虫!!!')
self.fp = open('./qiushi.txt','w',encoding='utf-8')
#专门迎来处理item类型对象,该方法可以接收爬虫文件提交过来的item对象
#该方法每接收到一个item,就会调用一次
def process_item(self, item, spider):
author = item['author']
content = item['content']
self.fp.write(author+':'+content+'\n')
return item
#关闭open_spider方法
def close_spider(self,spider):
print('结束爬虫!!!')
self.fp.close()
步骤6.在settings.py中开启管道
ITEM_PIPELINES = {
'qiushi.pipelines.QiushiPipeline': 300,
}
问题:在步骤3中导入Item包后变红
解决: