����Ŀ¼
ǰ��
��� Task01,���ݵİٶ����̵�����������,��������ļ�����ĩβ����
1 RFMģ�ͽ���
???????RFMģ���Ǻ����ͻ���ֵ�Ϳͻ�������������Ҫ���ߺ��ֶΡ����ڶ�Ŀͻ���ϵ����(CRM)�ķ���ģʽ��,RFMģ���DZ��㷺�ᵽ�ġ��û�еģ��ͨ��һ���ͻ��Ľ��ڹ�����Ϊ�����������Ƶ���Լ����˶���Ǯ3��ָ���������ÿͻ��ļ�ֵ״����<�ٶȰٿ�>
���һ������ (Recency)
����Ƶ�� (Frequency)
���ѽ�� (Monetary)
2 ����ʵ��
(1) �����
import numpy as np
import pandas as pd
import time
# �������ѧϰ��sklearn
from sklearn.ensemble import RandomForestClassifier
�����õ�4����:time��numpy��pandas��sklearn
- time:������¼�������ݿ�ʱ�ĵ�ǰ����
- numpy:�������������ݴ�����
- pandas:�й�����ת�������ݸ�ʽ����������ҪRFM������̵�
- sklearn:ʹ�����е����ɭ�ֿ�
(2) ��ȡ����
# ����sheet-names�б�,������������Ӧ
sheet_names = ['2015','2016','2017','2018','��Ա�ȼ�']
# ����pandas���е�read_excel()����,����ÿһ�е�sheet_names,��һ�е����һ�����ζ�ȡÿһ�е���
sheet_datas = [pd.read_excel('./data/sales.xlsx',sheet_name=i) for i in sheet_names]
�ȶ���һ���б�sheet_names,Ŀ���Ƿ�������ƶ�sheet����;Ȼ����ͨ���б��Ƶ�ʽ���pandas��read_excel������ȡsales.xlsx�����е����ݵ��б���,�γ�sheet_datas���ù��̻�ȽϺ�ʱ��
(3) �������
- ǰN��������Ҫ�鿴��ͬ�����е����ݸ�ʽ,���������ض�ת������֮���Ƿ����Դ�����ļ��ĸ�ʽ��õ�Ŀ��ת��Ҫ��,�Լ����ݵij��ȡ���ɹ��ɡ����͵��Ƿ�����ʵ����һ�¡�
- ������������Ϣ��Ҫ�������ݷֲ�����,������¼������ֵ�������λ�������,���������ݼ���ʹ��ģ�͡���ֵ�Ĵ����Ⱥ�������ĸ����ж����ݡ�
- ȱʧֵ��Ϣ���������ж������Լ�����Ӧ�Բ��ԡ�
- �������������ж�Ŀ�����͵�ǰ״̬,�Լ������Ƿ���Ҫ���������
# �Ա�����������ʾ,�����һ�����ǵ������Ƿ�����
for each_name,each_data in zip(sheet_names,sheet_datas): # �������ڽ��ɵ����Ķ�����Ϊ����
print('[data summary for {0:=^50}]'.format(each_name)) #��ʾ�����֮��ķָ���
print('Overview:','\n',each_data.head(4)) #չʾ����ǰ4��
print('DESC:','\n',each_data.describe()) # ������������Ϣ
print('NA records',each_data.isnull().any(axis=1).sum())#ȱʧֵ��¼��
print('Dtypes',each_data.dtypes) #��������
print('�����������С:',each_data.info())
[data summary for =======================2015=======================]
Overview:
��ԱID ������ �ύ���� �������
0 15278002468 3000304681 2015-01-01 499.0
1 39236378972 3000305791 2015-01-01 2588.0
2 38722039578 3000641787 2015-01-01 498.0
3 11049640063 3000798913 2015-01-01 1572.0
DESC:
��ԱID ������ �������
count 3.077400e+04 3.077400e+04 30774.000000
mean 2.918779e+10 4.020414e+09 960.991161
std 1.385333e+10 2.630510e+08 2068.107231
min 2.670000e+02 3.000305e+09 0.500000
25% 1.944122e+10 3.885510e+09 59.000000
50% 3.746545e+10 4.117491e+09 139.000000
75% 3.923593e+10 4.234882e+09 899.000000
max 3.954613e+10 4.282025e+09 111750.000000
NA records 0
Dtypes ��ԱID int64
������ int64
�ύ���� datetime64[ns]
������� float64
dtype: object
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 30774 entries, 0 to 30773
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ��ԱID 30774 non-null int64
1 ������ 30774 non-null int64
2 �ύ���� 30774 non-null datetime64[ns]
3 ������� 30774 non-null float64
dtypes: datetime64[ns](1), float64(1), int64(2)
memory usage: 961.8 KB
�����������С: None
[data summary for
����
ʹ��forѭ��,���zip��������ȡsheet_names��sheet_datas�е�ÿ��ֵ,Ȼ��ֱ������������:
- ����չʾ:ʹ�����ݿ��head����,��ʾǰ4������
- ��������Ϣ:ʹ�����ݿ��describe����,��ʾ���е�������ͳ�ƽ��
- ȱʧֵ��¼:ʹ�����ݿ��isnull().any(axis=1)���жϺ���ȱʧֵ�ļ�¼,Ȼ����sum��ȡ�ܼ�¼��
- ��������:ʹ�����ݿ��dtypes������ȡ�����ֶ�����������Ϣ��
���������������cell��ʾ��
ͨ������������ǿ��Եõ����½���:
- ÿ��sheet�е����ݶ���������ȡ��ʶ��,���κδ���
- ������(�ύ����)�Ѿ����Զ�ʶ��Ϊ���ڸ�ʽ,��ʡȥ�˺�����ת���Ĺ��̡�
- �������ķֲ��Dz����ȵ�,���������Եļ���ֵ,����2016���������,���ֵΪ174900,��Сֵ��Ϊ0.1�������ķֲ�״̬,���ݻ��ܵ���ֵӰ�졣
- �����е���Сֵ��Ȼ����0��0.1�����Ľ��,��Ȼ��������������������ҵ��ͨ��ȷ��,���ֵ�Ķ��������Ч,ͨ���ǿͻ�һ���Թ�������ҵ���Ʒ;���������Ϊ0.1������ʹ���Ż�ȯ֧���Ķ���,��û��ʵ�����塣����֮��,���е���1Ԫ�Ķ��������������,�����Ҫ�ں���������ȥ����
- �еı��д���ȱʧֵ��¼,����������,���ѡ��������䶼���ԡ�
(4) ����Ԥ����,ȥ��ȱʧֵ���쳣ֵ
ͨ��forѭ�����enumerate����,���ÿ���ɵ���Ԫ�ص������;���ֵ�����ڴ���ȱʧֵ���쳣ֵֻ��Զ�������,���sheet_datasͨ������ʵ�ֲ��������һ������(����Ա�ȼ���)��
- ֱ�ӽ�each_dataʹ��dropna����ȱʧֵ������ݿ����ԭ��sheet_datas�е����ݿ�
- ʹ��each_data[each_data[��������]>1]�����˳������������>1�ļ�¼��,Ȼ���滻ԭ��sheet_datas�е����ݿ�
- ���һ�д����Ŀ������ÿ����ݵ�����������һ��max_year_date,ͨ��each_data[���ύ���ڡ�].max()��ȡһ�������ڵ����ֵ,��������������ÿ������ݷֱ���RFM����,���������4�������ͳһ��RFM���㡣
# ȥ���쳣ֵ��ȱʧֵ
for ind,each_data in enumerate(sheet_datas[:-1]):
print(ind)
print(each_data)
sheet_datas[ind] = each_data.dropna() # ����ȱʧֵ��¼ axis: Ĭ��axis=0��0Ϊ����ɾ��,1Ϊ����ɾ��
sheet_datas[ind] = each_data[each_data['�������'] > 1]
sheet_datas[ind]['max_year_date'] = each_data['�ύ����'].max() # ����һ���������ֵ
0
��ԱID ������ �ύ���� �������
0 15278002468 3000304681 2015-01-01 499.0
1 39236378972 3000305791 2015-01-01 2588.0
2 38722039578 3000641787 2015-01-01 498.0
3 11049640063 3000798913 2015-01-01 1572.0
4 35038752292 3000821546 2015-01-01 10.1
... ... ... ... ...
30769 39368100847 4281994827 2015-12-31 828.0
30770 409757 4282010457 2015-12-31 199.0
30771 38380526114 4282017675 2015-12-31 208.0
30772 28074988 4282019440 2015-12-31 89.0
30773 39460363230 4282025309 2015-12-31 719.0
[30774 rows x 4 columns]
1
��ԱID ������ �ύ���� �������
0 39288120141 4282025766 2016-01-01 76.00
1 39293812118 4282037929 2016-01-01 7599.00
2 27596340905 4282038740 2016-01-01 802.00
3 15111475509 4282043819 2016-01-01 65.00
4 38896594001 4282051044 2016-01-01 95.00
... ... ... ... ...
41273 35336052906 4324910145 2016-12-31 99.00
41274 39305835721 4324910148 2016-12-31 238.89
41275 39296945352 4324910770 2016-12-31 765.00
41276 14791026234 4324911025 2016-12-31 45.80
41277 16779755770 4324911048 2016-12-31 119.00
[41278 rows x 4 columns]
2
��ԱID ������ �ύ���� �������
0 38765290840 4324911135 2017-01-01 1799.0
1 39305832102 4324911213 2017-01-01 369.0
2 34190994969 4324911251 2017-01-01 189.0
3 38986333210 4324911283 2017-01-01 169.0
4 4271359 4324911355 2017-01-01 78.0
... ... ... ... ...
50834 39155833075 4338762307 2017-12-31 96.0
50835 29523124076 4338762514 2017-12-31 99.0
50836 7807573 4338762906 2017-12-31 258.0
50837 36642530033 4338762958 2017-12-31 286.0
50838 39155901156 4338763879 2017-12-31 249.0
[50839 rows x 4 columns]
3
��ԱID ������ �ύ���� �������
0 39229691808 4338764262 2018-01-01 3646.0
1 39293668916 4338764363 2018-01-01 3999.0
2 35059646224 4338764376 2018-01-01 10.1
3 1084397 4338770013 2018-01-01 828.0
4 3349915 4338770121 2018-01-01 3758.0
... ... ... ... ...
81344 39229485704 4354225182 2018-12-31 249.0
81345 39229021075 4354225188 2018-12-31 89.0
81346 39288976750 4354230034 2018-12-31 48.5
81347 26772630 4354230163 2018-12-31 3196.0
81348 39455580335 4354235084 2018-12-31 2999.0
[81349 rows x 4 columns]
������������
data_merge = pd.concat(sheet_datas[:-1],axis=0)
data_merge['date_interval'] = data_merge['max_year_date'] - data_merge['�ύ����'] #�����������ύ���ڵļ��
data_merge['year'] = data_merge['�ύ����'].dt.year # ����һ���µ��ֶ�,Ϊÿ����¼��Ϊ���������
# �����ڼ��ת��������
data_merge['date_interval'] = data_merge['date_interval'].apply(lambda x:x.days)
rfm_gb = data_merge.groupby(['year','��ԱID'],as_index=False).agg({'date_interval':'min', # �������һ�ζ���ʱ��
'�ύ����':'count', # ���㶩����Ƶ��
'�������':'sum'}) # ���㶩�����ܽ��
rfm_gb
| year | ��ԱID | date_interval | �ύ���� | ������� | |
|---|---|---|---|---|---|
| 0 | 2015 | 267 | 197 | 2 | 105.0 |
| 1 | 2015 | 282 | 251 | 1 | 29.7 |
| 2 | 2015 | 283 | 340 | 1 | 5398.0 |
| 3 | 2015 | 343 | 300 | 1 | 118.0 |
| 4 | 2015 | 525 | 37 | 3 | 213.0 |
| ... | ... | ... | ... | ... | ... |
| 148586 | 2018 | 39538034299 | 272 | 1 | 49.0 |
| 148587 | 2018 | 39538034662 | 189 | 1 | 3558.0 |
| 148588 | 2018 | 39538035729 | 179 | 1 | 3699.0 |
| 148589 | 2018 | 39545237824 | 275 | 1 | 49.0 |
| 148590 | 2018 | 39546136285 | 163 | 1 | 19.9 |
148591 rows �� 5 columns
# ����������
rfm_gb.columns = ['year','��ԱID','r','f','m']
rfm_gb.head() # Ԥ������ӡ
| year | ��ԱID | r | f | m | |
|---|---|---|---|---|---|
| 0 | 2015 | 267 | 197 | 2 | 105.0 |
| 1 | 2015 | 282 | 251 | 1 | 29.7 |
| 2 | 2015 | 283 | 340 | 1 | 5398.0 |
| 3 | 2015 | 343 | 300 | 1 | 118.0 |
| 4 | 2015 | 525 | 37 | 3 | 213.0 |
(5) ȷ��RFM��������
����RFM����ʱ,�������Ƿֱ��R��F��M�����������ɢ������,Ȼ����ܵõ��÷���ɢ����Ľ��������ɢ�������ж��ַ�����ѡ,��������Ҫ��������RFM��ɢ��,�����Ҫ�ȿ������ݵĻ����ֲ�״̬��
�鿴���ݷֲ�:
# �鿴���ݷֲ�
desc_pd = rfm_gb.iloc[:,2:].describe().T
desc_pd
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| r | 148591.0 | 165.524043 | 101.988472 | 0.0 | 79.0 | 156.0 | 255.0 | 365.0 |
| f | 148591.0 | 1.365002 | 2.626953 | 1.0 | 1.0 | 1.0 | 1.0 | 130.0 |
| m | 148591.0 | 1323.741329 | 3753.906883 | 1.5 | 69.0 | 189.0 | 1199.0 | 206251.8 |
??????��һ����������,r��m�����ܽϺ������û�����,��f��������(�������û�ֻ��1������) ��Ը�����������ҵ���Ž����˹�ͨ,������������ҵ����(��ҵ�)��ԭ��,�û�������ȷʵ����,1�깺��1���DZȽ��ձ�(���а����¿ͻ��Լ��Ͽͻ��ڵ���ĵ�1�ι���),��˻����ǿ�����2��5��Ϊ�߽�,ѡ��2����Ϊһ���ҵ������Ϊ���깺��2�μ�2�����ϾͿ��Զ���Ϊ�����û�(�����ۼƵ��������㸴���û�).ѡ��5����Ϊҵ������Ϊ����5���Ѿ��Ƿdz��ߵĴ���,�����ô��������ڷdz���ֵ���û�Ⱥ��,���ֵ�ǻ���ҵ�������ճ����ݱ�������õ�
��������߽�
r_bins = [-1,79,255,365] # ע����ʼ�߽�С����Сֵ
f_bins = [0,2,5,130]
m_bins = [0,69,1199,206252]
- �ڱ߽��ϵ����ݹ�����һ������ԭ��,Ҫô�����������,Ҫô���������Ҳ�
- ʹ��pd.cut������,�����Զ���߽�,ʵ�е������ұյ�ԭ��,�����������Ҳ�����,��������Ļ��ֲ�����,��f_bins��Сֵ��1,Ҫ��[0,2]����,����1,2����,������[1,2,5,130],��Ϊ�����Ͳ���ȡ��1��,�������ұյ�
(6)����RFM����Ȩ��
����ѧϰ�����ھ��ǽ��
�ڼ���RFM��ϵ÷�ʱ,���ǿ���ֱ�ӽ�������Ϊһ���µķ���,����322/132�����ڼ�Ȩ��͵õ�һ���µ�RFM�÷�ָ��ʱ,�����Ҫȷ��һ��Ȩ��ֵ�����ȷ��RFM����ά�ȵ�Ȩ����?
�������ṩһ��˼·����ʵ��ÿ����˾��,�漰����Ա����ʱ,һ�㶼���л�Ա��ϵ,����Ա��ϵ����һ��ά��,�Ǻ�����Ա��ֵ�ȸߵ͵�,���ά���ǡ�����Ա�ȼ�����ָ����Ա�ȼ�ʱ,������˾���Ѿ��ۺϿ��ǵ��˶����빫˾����������ص�����,���ø��ֻ�ԱȨ�涼���Ա�ȼ��йء�����,���˷��ż����Ż�ȯʹ�á�������Ʒ�Żݼ۸�Ա���Ӫ���ȡ�������ǿ��Ի��ڻ�Ա�ȼ���ȷ��RFM���ߵ�Ȩ��,����˼·��,����һ��rfm����ά�����Ա�ȼ��ķ���ģ��,Ȼ��ͨ��ģ�����ά�ȵ�Ȩ�ء�
ƥ���Ա�ȼ���RFM�÷�:
rfm_merge = pd.merge(rfm_gb,sheet_datas[-1],on='��ԱID',how='inner')
����Ա�Ķ���������ȼ�����ƥ��,ʹ��merge�����ϲ��������ݿ�,���������ǻ�ԱID,ƥ�䷽ʽ���ڲ�ƥ�䡣
# rf ���rfm���ӵ÷�
clf = RandomForestClassifier() #�������ɭ�ַ�����ģ��
clf = clf.fit(rfm_merge[['r','f','m']],rfm_merge['��Ա�ȼ�'])
weights = clf.feature_importances_ # ����'r','f','m' ������Ȩ��
print('feature importance:',weights)
feature importance: [0.4080503 0.00656342 0.58538628]
�������̷dz���,�Ƚ���rfģ�Ͷ���,Ȼ��rfm������Ϊ����,����Ա�ȼ���ΪĿ������ģ���н���ѵ��,���ͨ��ģ�͵�feature_importances_���Ȩ����Ϣ��������ϡ�
�����������֪,����3��ά����,�û��ĵȼ����Ȳ����ڻ�Ա�ļ�ֵ����(ʵ�ʶ����Ĺ���),������½��̶�,�����Ƶ�Ρ���������ܶ˾�������Ա�ȼ�һ�¡�����ij���ڵ��̵Ļ�Ա�ȼ�,�ǻ�����ʷ�ۼƶ�������������,������һ��ʱ��(����1����)û�й���,��ή�ͻ�Ա�ȼ���
(7)RFM�������
RFM����÷�:
rfm_gb['r_score'] = pd.cut(rfm_gb['r'],r_bins,labels=[i for i in range(len(r_bins)-1,0,-1)])
rfm_gb['f_score'] = pd.cut(rfm_gb['f'],f_bins,labels=[i+1 for i in range(len(f_bins)-1)])
rfm_gb['m_score'] = pd.cut(rfm_gb['m'],m_bins,labels=[i+1 for i in range(len(m_bins)-1)])
ÿ��rfm�Ĺ���ʹ����pd.cut����,�����Զ���ı߽�������л���,labels������ʾÿ����ɢ����ľ���ֵ��F��M�Ĺ�����ֵԽ��,�ȼ�Խ��;��R�Ĺ�����ֵԽС,�ȼ�Խ�ߡ���˹���R��labels�Ĺ�����F��M�෴����labelsָ��ʱ��Ҫע��,4������Ľ���ǻ���Ϊ3��,���labels��������ͨ����1ʵ�ֱ߽�����������������ƽ��,��i+1��ʵ���������1��ʼ,������0��
�����ܵ÷�
����1 ��Ȩ�÷�
rfm_gb = rfm_gb.apply(np.int32) # caseת��ֵ
rfm_gb['rfm_score'] = rfm_gb['r_score'] * weights[0] +rfm_gb['f_score'] * weights[1] +rfm_gb['m_score'] *weights[2]
����2 RFM���
rfm_gb['r_score'] = rfm_gb['r_score'].astype(np.str)
rfm_gb['f_score'] = rfm_gb['f_score'].astype(np.str)
rfm_gb['m_score'] = rfm_gb['m_score'].astype(np.str)
rfm_gb['rfm_group'] = rfm_gb['r_score'].str.cat(rfm_gb['f_score']).str.cat(rfm_gb['m_score'])
rfm_gb['rfm_group']
0 212
1 211
2 113
3 112
4 322
...
148586 111
148587 213
148588 213
148589 111
148590 211
Name: rfm_group, Length: 148591, dtype: object
���ַ�ʽ�Ǵ�ͳ������Ա����ķ�ʽ��Ŀ���ǽ�3����Ϊ�ַ������Ϊ�µķ��顣
������,�����3��ʹ��astype��������ֵ��ת��Ϊ�ַ�������,Ȼ��ʹ��pandas���ַ�����������str��cat�������ַ����ϲ�,�÷������Խ��Ҳ�����ݺϲ������,������ʹ������str.cat�����õ��ܵ�R��F��M�ַ�����ϡ�
��
��
p
a
n
d
a
s
��
s
t
r
��
��
����pandas��str����
����pandas��str����
����str����cat����,�����ַ�������ϲ�,�����:
��������:
others:Ҫ�ϲ�������һ������(�Ҳ����),���Ϊ��,�������������ϡ�
sep:�ϲ��ķָ���,Ĭ��Ϊ��,���Զ���,���硰,������;���ȡ�
na_rep:�������NA(ȱʧֵ)ʱ��δ���,Ĭ��Ϊ���ԡ�
��Ҫע�����:�÷������ڶ�series�����,�����������ݿ�,������һά���ݻ����ַ�����
����:��������������
����������¡�

(8) ��������excel
rfm_gb.to_excel('sales_rfm_scorel.xlsx')
�ܽ�
????????��������!!! ������ʮ������,�������������ȥ��,���̳�û��˵��ô����������,Ȼ��һֱ��Ϲ����,��˼���Լ��Ƕ�ô��,������ô�����������ҵľžŰ�ʮһ����?�������̸�ԭһ����
- �ӱ��һ�,������,Ȼ��

զ��һ����ô�������,Ϊɶrfm_group �������,����ɢ����?
����:������year����ԭ��������,�����Ը�Ϊ�ı�˵�����ͺ���

���˿��û�б仯,������ô������,Ȼ��һֱ�ٶ��ӱ�Ū�������,δ��
2 �����˿���Ū������Ū���
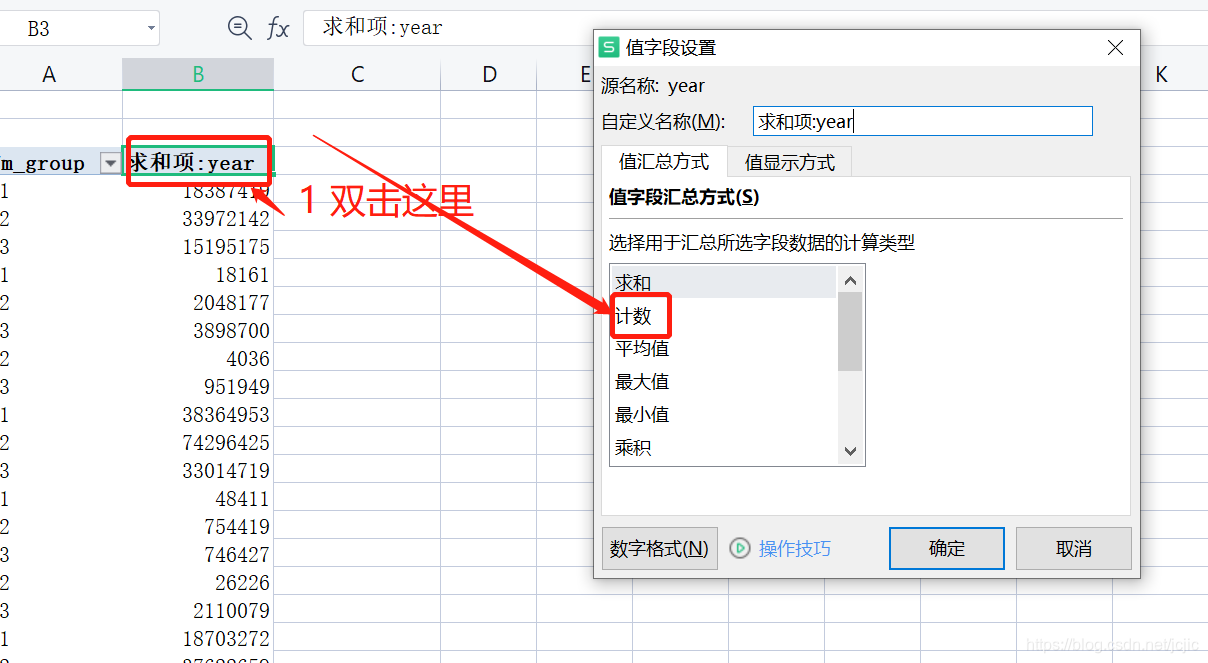
���Ƿ��ֻ��Dz�������Ҫ��!
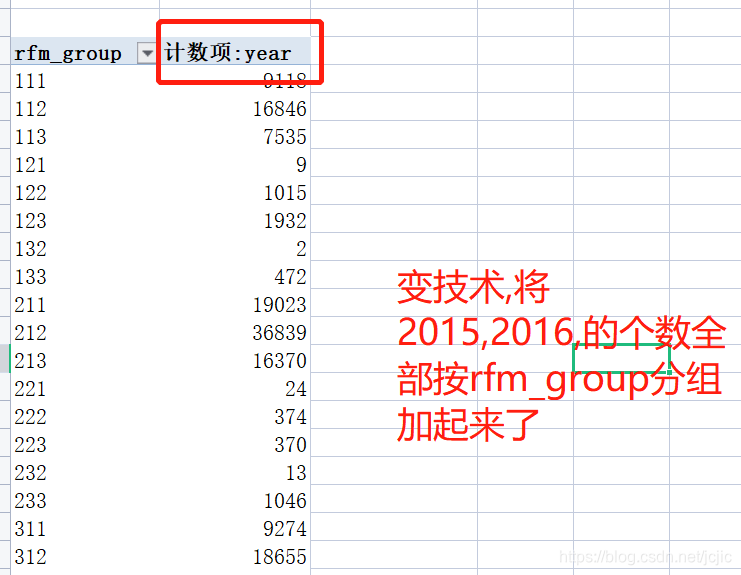
3 �ٶ���ô��ֱ��ͼ��,�������Dz�������python����groupby ���,Ȼ���Ǹ�ͼ,�뵽��������
import pandas as pd
data = pd.read_excel('sales_rfm_scorel.xlsx',sheet_name='Sheet1')
new_data = data.groupby(['year','rfm_group'],as_index=False).agg({'��ԱID':'count'})
new_data = new_data.rename(columns={'��ԱID':'����'})
new_data.to_excel('year_rfm_group_����.xlsx')
���,��ô���Ӧ�ÿ�������

��������һ���������һ���һ�

���

4 �����ٶ���,����̽��,�����������Ź�ע��excelһЩ���ںſ�����ô����
���:����û�н��
5 ������ӱ���������,���Ͽ��˽̳̺���һЩͼ�Ļ�,����Ϥ��һ���ӱ�,������ҵ�Ŭ����Ū����
��1�� ���̳���Ȼ���������岽������ô����,����֪������python����ֱ���������ӾͿ�����
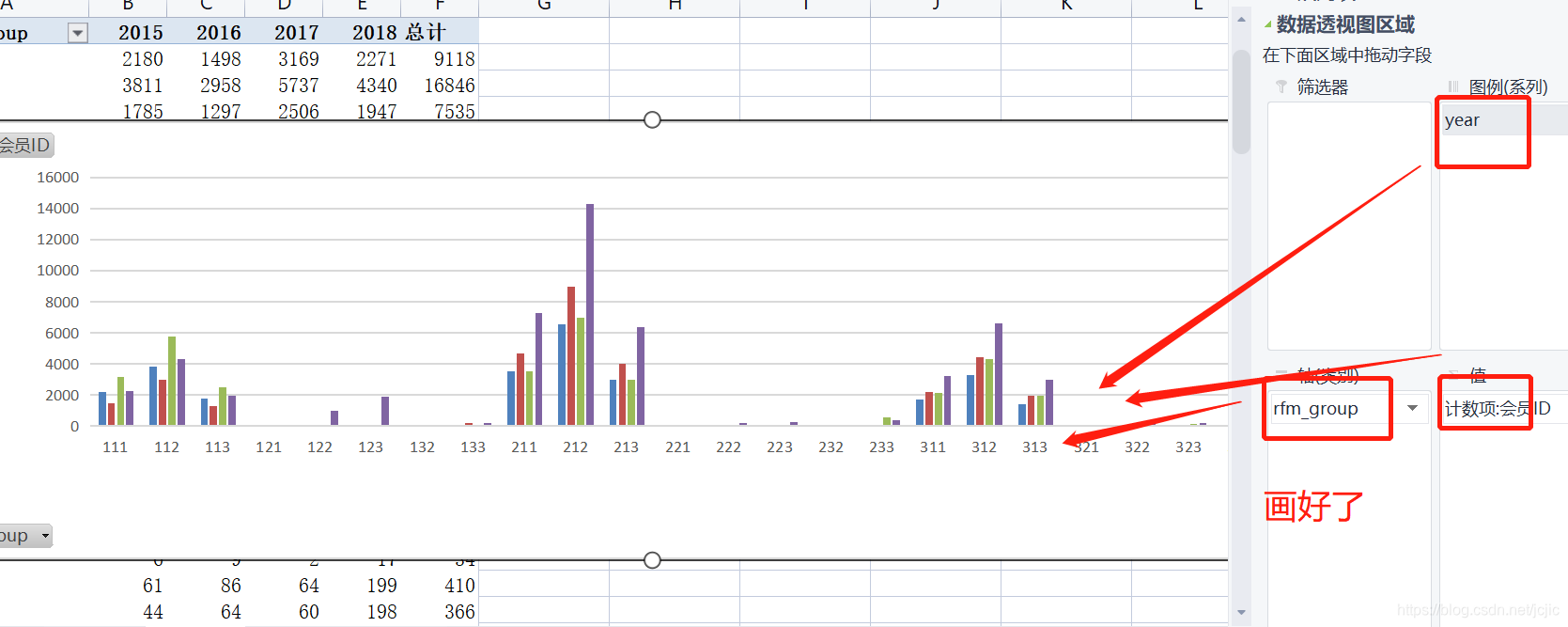
Ȼ���������������ͼ����

��yearһ����������,���ϲ�����ֵ������,����������,���ϸо�����Ϸ,���ǿ���������ͼ���Dz���
6 ����ȡ��������óɹ���
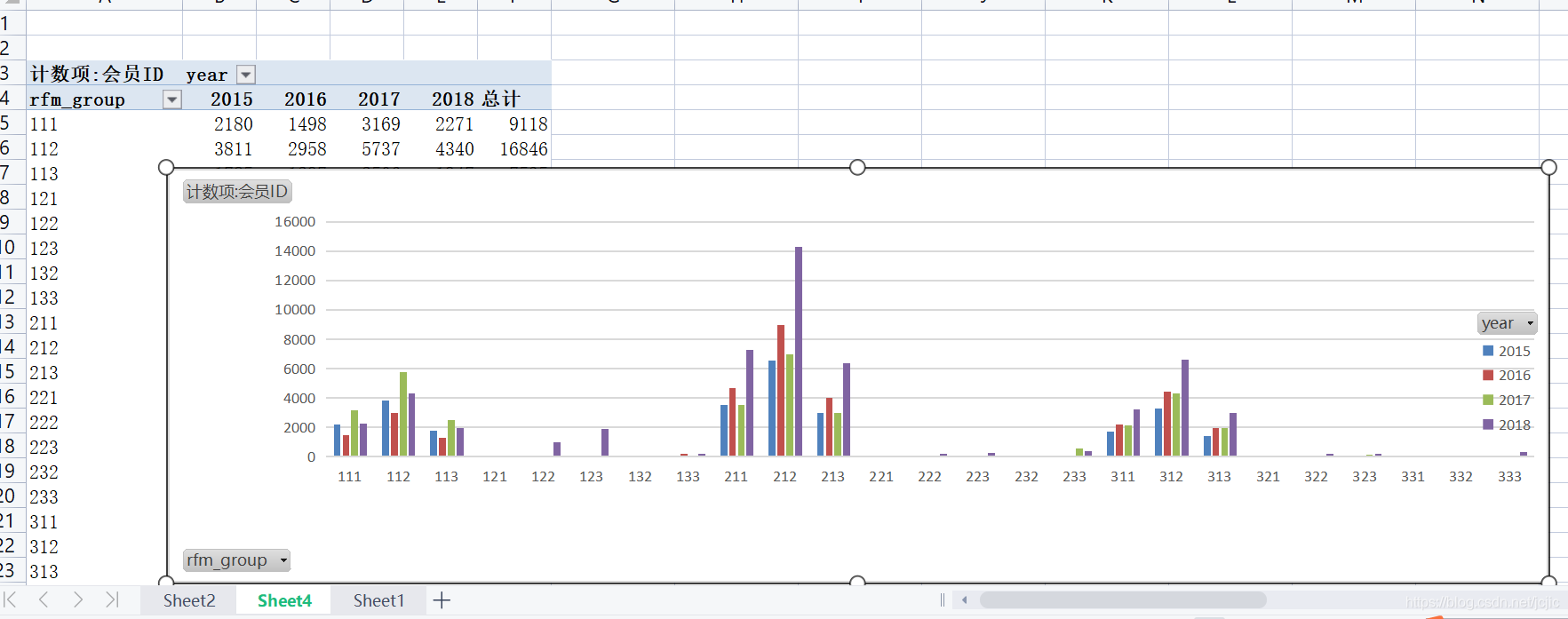
��year������ͼ��(ϵ������)
СС��:
- ��Ļ�Ȼ�����,֮ǰҲһֱ����excel��ǿ,�������������ھ�,Ҳ��ע��һ��excel��صĹ��ں�,Ҳ��֪��ˢ����ص�,���������ղ��˽̳�,���ǻ��Ǵ�����ϵѧ��
- ���˹����ϵ�һЩЩСС�ջ�,�������ݻ���Ӫ�̵�һЩ����,��ǰ�ܾ���pythonֱ��pd.read() ����dataframe�Ϳ��������д�����,��excel���������ֲ�����������Ȧ�ĸо�,������һ�����Ե�excel��ǿ��,Ҳ֪��python,tableau��ǿ,���ǹ��߶�����,ҵ��������,�ܵ�����,python������ϴ����,����RFMģ��,��excel��ͼ�����ó�һЩ����,����python���ݷ��������ݻ���Ӫ����,��һ���Ǹ�������ʽ��Ӫ,ҲӦ�������ݷ���ʦ�е�һЩ�ճ�
--------------------------δ��,�������� 2021��8��21�� 0:04�� ��˯��
3 �������ݽ���
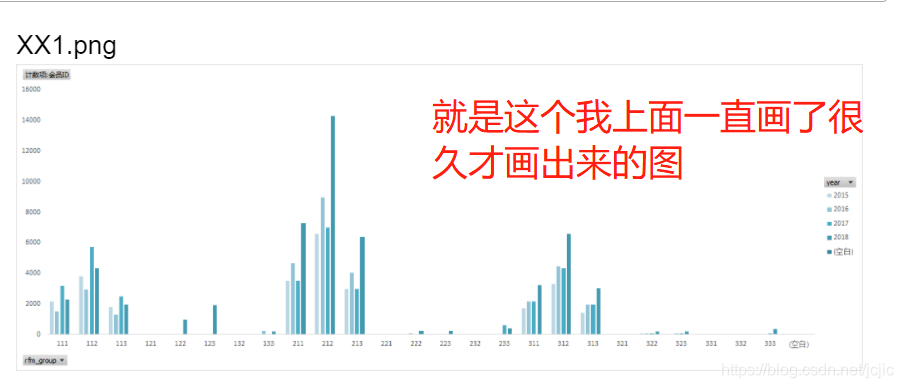
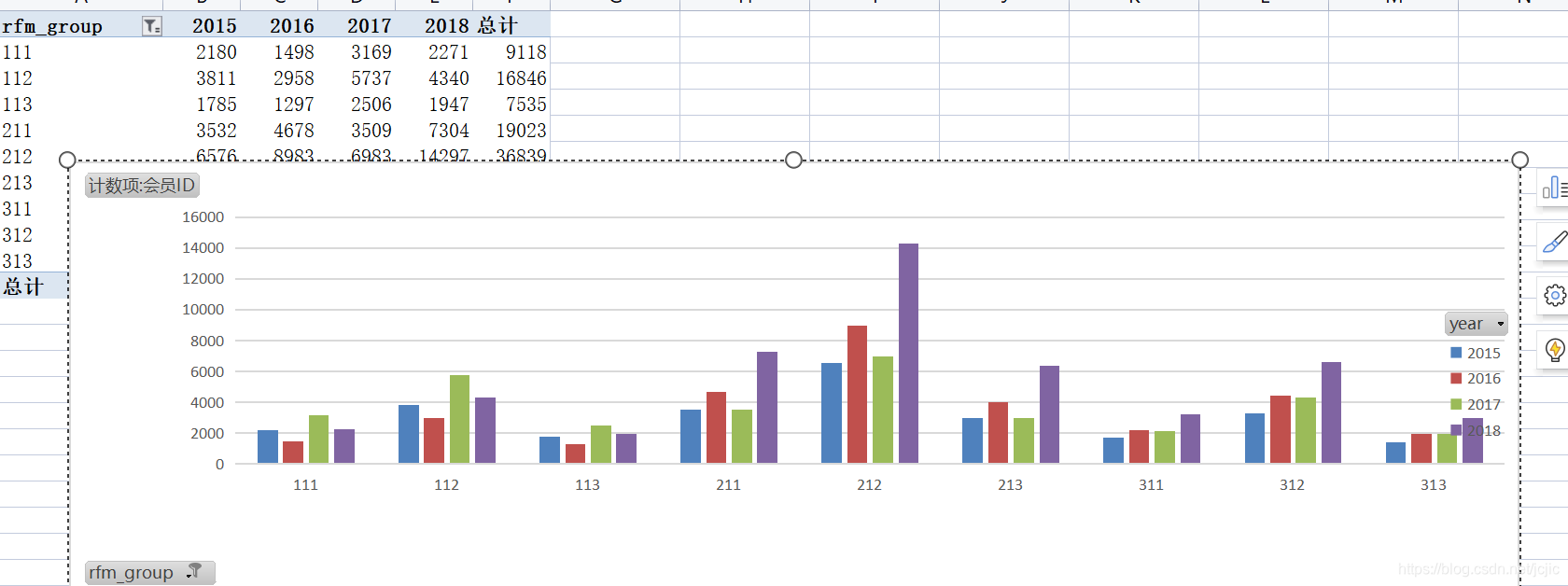
(1)����ͼ�εĽ���ʽ���� �ص���Ⱥ�ֲ�:��ͨ��Excel����ͼ������,������������,212Ⱥ����û�����Լ����ұ仯���ġ�
ͨ��ͼXX1���Է���,��2016�굽2017���û�Ⱥ�������仯����,����2018�������˽�һ�������,�ⲿ����Ⱥ����Ϊ�ص������Ⱥ��
�ص����ֲ�:����212��Ⱥ��,ͼXX1����ʾ��312��213��211��112��Ⱥ���ڸ������ռ�ݺܴ�����,��Ȼ���Թ�ģ����,�������������������212���������,����ҲҪ�ص�������������ֵ����Ϊ2000����,��ͼXX2����ʾ,�ܶ����dz��ٵ���Ⱥ�����˺ܶ�,˵����Ⱥ�����Ƚ��ٵ����dz��ࡣ
???????���Կ��ó���������������python���ݴ���+excel�ӱ��ó�һЩ����,��Щ��������������ɭ�ֵ�����,������ƫ����������ѧϰ�ó�������,����ƫ�������߲�����Ӫ,��Ȼ���,���Ǿ�����ƫ���������ݷ���,��Ϊ�漰��python��,�ҿ���һЩ����ȺһЩ�Ĵ������ݷ���ҵ��,���������漰python��,����ҵ�����ݷ�����������ô�漰��̵�,��Щ����ĿǰһЩ�����뷨,Ҳ�����������Ҿ���ȫ����Ūͨ��
ɸѡ����2000��
������һЩexcel��ϸ�IJ����IJ���,ȫ�������òο����ӵ�,��ʵ��,ȫ������
(2)����RFM�������ķ���
ͨ��RFM�����Excel�������,���ǽ�����һ��ȷ��Ҫ��������ҪĿ��Ⱥ�塣
���Ǵ�����sales_rfm_score.xlsx�ļ�,Ȼ���������ӱ���
����Ϊ:
����Excel�����˵����ġ�����C�����ӱ���,�ڵ����Ĵ����е�����ȷ������ť,��ͼ��ʾ

���½���sheet��ͼ��,������������:
- ��rfm_group���������ӱ��ֶ������еġ��С�����
- ����ԱID���������ӱ��ֶ������еġ�ֵ������
- ������ԱID��
- �ڵ����Ĵ�����ѡ��ֵ�ֶ����á�
- �ڵ�����ѡ�������͡�Ϊ��������
- ������ȷ������ť
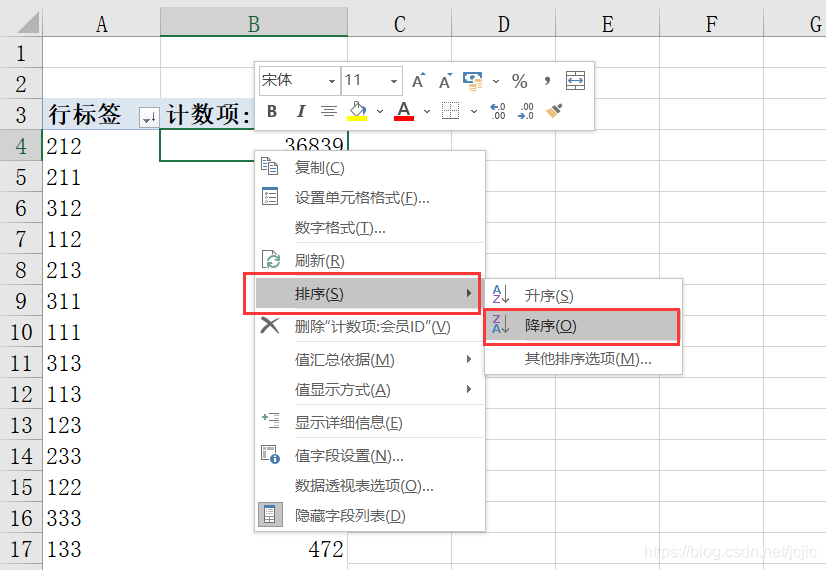
����,���ݾ���RFM����Ϊ����,���û�������Ϊ���������,��ͼ��ʾ
 ������������������:��ԱID���е�������ֵ,����������������,���Ӵ�С������ͼ��ʾ��
������������������:��ԱID���е�������ֵ,����������������,���Ӵ�С������ͼ��ʾ��
�������,��Ա�����з���ķֲ��Dz����ȵ�,������Ҫ���ٷ������л�����ʾ,��������֪��ÿ�������ռ�ȡ����ӱ��еġ�������:��ԱID���е���������ֵ,Ȼ���Ҽ�,�ڵ����IJ˵���ѡ��ֵ��ʾ��ʽ��,���Ҳ�˵���ѡ���л��ܵİٷֱȡ�,��ͼ��ʾ��
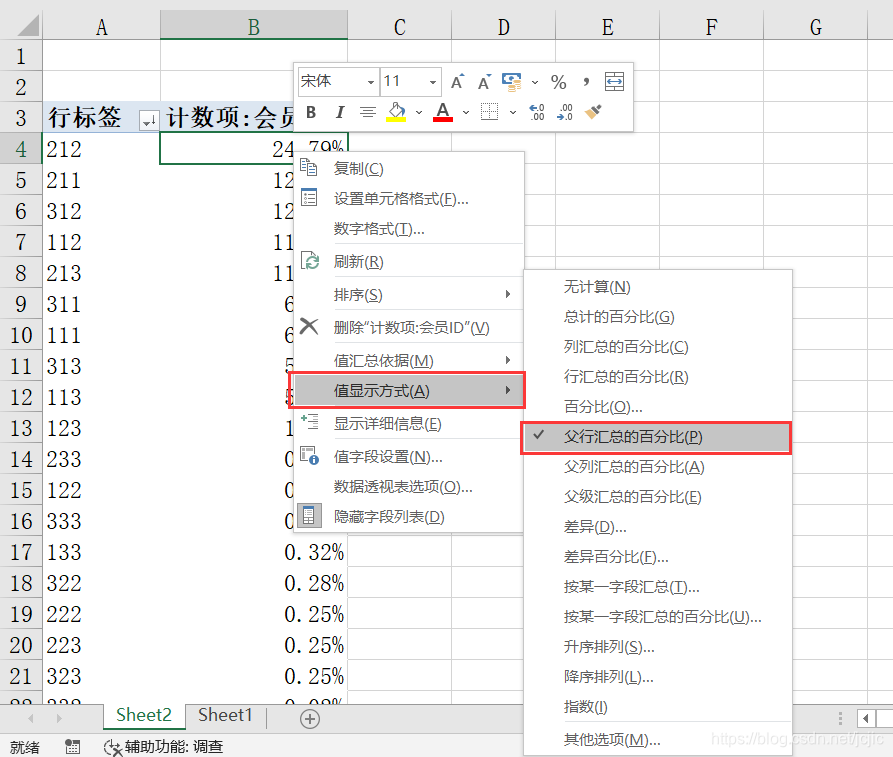
������ɺ�,���ǶԷ����û��������ۼ����,�����ǰ9��������û�����ռ�Ƚӽ�96%,��ͼ��ʾ
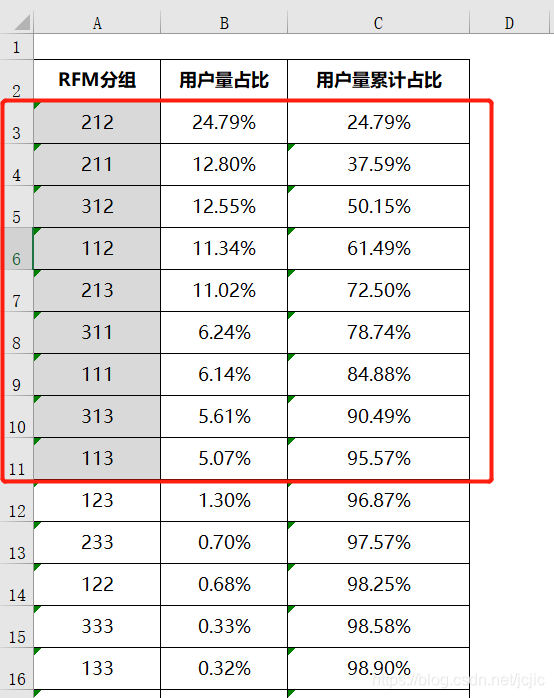
������Ϊ���ص�����
�ó�����,Ӧ���������������ݷ��������ĵط���
���,������Ҫ�ѷ����ص�,������9����Ⱥ�ϡ�
(3)RFM�û��������� ��������ķ���,���ǵõ���Ҫ�������ص�ͻ�Ⱥ�塣�ɸ����û���������Ϊ����: ��1�����û�Ⱥ��ռ�ȳ���10%��Ⱥ��;
��2����ռ���ڸ�λ����Ⱥ�塣 ������������������ͬ,�����Ҫ�ֱ�������ԵIJ��Գ�����
��������,���ǻ������ӵ�3����Ⱥ,��Ȼ���û�������ƫС,���ǵ����˵ļ�ֵ�ȷdz��ߡ���1����Ⱥ:ռ�ȳ���10%��Ⱥ�塣 ����������Ⱥ������,�����ȡ������������Ӫ�ķ�ʽ�����Ӫ����,һ����Ҫͨ��ϵͳ���Ʒʵ��,��������Ҫ�������˹���
212:�ɷ�չ��һ����Ⱥ�塣����Ⱥ�幺���½��ȺͶ������һ��,�ҹ���Ƶ�ʵ�,���ǵ�������Ⱥ�����,�Լ����½��ȺͶ�������϶�������,��˿ɲ�ȡ�����Ե���Ʒ�һ����������������ǩ�������˷ѵ��ֶ�,ά�ֲ�����������״̬��
211:�ɷ�չ�ĵͼ�ֵȺ�塣����Ⱥ�������212Ⱥ��,�ڶ�������ϱ����Բ�,�����211Ⱥ����ԵĻ�����,���������붩����صĴ̼���ʩ,���������Ʒ�Ż�ȯ,���ͻ��ֹ�����Ʒ�ȡ�
312:��DZ����һ����Ⱥ�塣����Ⱥ�幺���½��ȸ�,˵�����һ�ι������ںܶ�ʱ��֮ǰ,Ⱥ����ڹ�˾���бȽ���Ϥ�ĽӴ���������֪״̬,����Ƶ�ʵ�,˵������վ���ҳ϶�һ��,���������еȲ㼶,˵���仹���п������Ŀռ�,��˿��Խ���������������Ʒ,Ϊ�䶨��һЩ���ϴι�����ص���Ʒ,ͨ���������۵Ȳ�����������Ƶ�κͶ�����
112:����ص�һ����Ⱥ�塣����Ⱥ�幺���½��Ƚϵ�,˵�������ϴι���ʱ��ϳ�,�ܿ����û��Ѿ����ڳ�Ĭ��Ԥ��ʧ��ʧ��;����Ƶ�ʵ�,˵������վ���ҳ϶�һ��,���������еȲ㼶,˵���仹���ܾ��п������Ŀռ�,��˶��ⲿ��Ⱥ��IJ���,������ͨ�����ַ�ʽ(�����ʼ����ŵ�)����ͻ������,Ȼ��ͨ�������ʧ�ͻ���ר���Ż�(������ʧ�û�ר���Ż�ȯ)��ʩ�ٽ�������,�ڴ˹����п����ӽӴ�Ƶ�κʹ̼����ȵķ�ʽ,�����û��Ļطá������Լ�������ֵ�ر���
213:�ɷ�չ�ĸ�ֵȺ�塣������Ⱥ��չ���ص�����������Ƶ��,��˿�ָ����ͬ�Ļ���¼��������û�,�ٽ���طú���,���粻ͬ�Ľ��ջ,ÿ����Ʒ����,��ֵ�ͻ�ר����Ʒ�ȡ���2����Ⱥ:ռ��Ϊ1%~10%��Ⱥ��,�ⲿ����Ⱥ��������,�����ʱ�����Dz�Ʒ�����˹����ɽ��롣 311:��DZ���ĵͼ�ֵȺ�塣�ⲿ���û���211Ⱥ������,���ڹ����½����ϸ���,��˶���ɲ�ȡ��ͬ�IJ��ԡ���������,������Ⱥ�������Ӵ�������,��������Ӫ��������ԴͶ��,ͨ����Щ�����ٴν��ͻ�������վ������ѡ�
111:����һ���ڸ���ά���϶��Ƚϲ�Ŀͻ�Ⱥ��,һ������»�����������Ⱥ����Ժ�������غ�ſ������ǡ���Ҫ��������ͨ�����ֲ�����ؿͻ�,Ȼ��Ϊ�ͻ������������Ƶ�����Ⱥ��,���ߵ�ǰ��������Ʒ���ۿ۷dz������Ʒ���ڴ̼�����ʱ,�ɸ���������ˮƽ��Ʒ������,������Ե�������Ʒ��¶����,�����Ż�ȯ���Ż���Ʒ���ۺϴ̼���,ʹ��ʵ������,�ٿ�������Ƶ���Լ���������������
313:��DZ���ĸ�ֵȺ�塣����Ⱥ��������½��ȸ��Ҷ�������,������Ƶ�ʵ�,���ֻҪ�����乺��Ƶ��,�û�Ⱥ��Ĺ���ֵ�ͻᱶ������������Ƶ����,�����������һ�εĽӴ������������ع���,�����һ��������ص�����������������ҲҪ��������Ӫ����Դ,����213�еIJ���ҲҪ���Ӧ�����С�
113:����صĸ�ֵȺ��,����Ⱥ����112Ⱥ������,������������,��˳���Ӧ��112�еIJ�����,�����Ӳ����˹��IJ����������Щ��ֵ�ͻ�,�������·�̸,�ͻ��绰��ͨ�ȡ���3��Ⱥ��:ռ�ȷdz���,��ȴ�Ƿdz���Ҫ��Ⱥ�塣 333:�����ҳϵĸ�ֵȺ�塣��Ȼ�û���������ֻ��355,���������������ַdz�ͻ��,��˿�����б�������Դ,�������VIP����ר��������ɫͨ���ȡ���������ⲿ����Ⱥ�ĸ�ֵ���ӷ�����Ƽ�,Ҳ���������ֵ���ص���ԡ�
233��223��133:һ���Եĸ�ֵȺ�塣����Ⱥ�����Ҫ���ֵ��������½������,���ٽ���ʵ�����һ�εĹ���,��ͨ���绰���ͻ��ݷá����·�̸���š������ʼ��ȷ�ʽ,ֱ�ӽ����û����ͨ��,������ⲿ�ָ�ֵ�û���
322��323��332:��DZ������ͨȺ�塣����Ⱥ���������ɹ���,��Ҫ�������ǹ���Ƶ�μ��������˿�ͨ���������ۡ����Ի��Ƽ����������ۡ�����Ż�ȯ�������Ʒ���۵Ȳ���,�����䵥�ι���Ķ������,���ٽ����ظ�����
4 ����Ӧ�úͲ���
��������õ��ķ�������,��Ա���Ų�ȡ��һ�´�ʩ:
�ֱ����3��Ⱥ��,���չ�˾ʵ����Ӫ����͵�ǰĿ��,�ƶ��˲�ͬ��Ⱥ����ص����ڡ�
¼�����ݿ��RFM�÷������Ѿ�Ӧ�õ���������ģ����,��Ϊ��ģ����Ĺؼ�ά������֮һ��
5 ����ע���
����������һ�¼�����Ҫ�ر��ע��:
��ͬƷ�ࡢ��ҵ����RFM�����������в����,��ʹ��һ����˾,�ڲ�ͬ�ķ�չ�κ�������,3��ά�ȵ����ȼ���Ҳ�е�������һ���Եľ������,��ҵ���������ڽϳ�����ҵ,R��M�����ҪһЩ;����Ʒ���������ڶ��ҿ����ҵ,������R��F�����廹��Ҫ���ݵ�ǰ��Ӫ������ҵ���Ź�ͨ��
��R��F��M����Ļ�����һ����ɢ���Ĺ���,������Ҫ����Ϊ��������,��Ҫ��ҵ��ȷ�ϡ��������ǻ���Ϊ3������,�����Ľ������ҵ���������,���е�ࡣ����ζ��ҵ����Ҫ�ƶ�ʮ������������IJ��ԡ����ҵ��Ҫ�����,Ҳ���Ի���Ϊ2������,�����ֳ�������������8��,�����ƶ�����Ӽ�����,�����ǻ���Ϊ2������3��,ȡ���ڵ�ǰҵ���ж�����Դ����Ͷ�뵽�������������
R��F��M��Ȩ�ش��,���˰������ᵽ�Ľ�ģ������,���ҵ�����ר�Ҵ�ַ�Ҳ�dz��õ�˼·������,���AHP��η��������д��,����������Ȩ�ؽ������ӿ�ѧ���Ͻ���
��Ȼ�������ݿ��е�����������Խϸ�,�������������ݲɼ������ݿ�ͬ����ETL����ѯ�������������,���ǻᵼ��NAֵ�ij���,��NAֵ�Ĵ����dz���Ҫ��
R��F��M����ά�ȵĴ���(�������㡢��ɢ������ϡ�ת��)֮ǰ����Ҫע�����������ͺ�ʽ,�������й�ʱ�����ת������Ӧ��ǰ��ɡ�
5 ��������˼��
����RFMģ�ͻ����û�Ⱥ�岢����ֵ�ȷ���,��ͳ�Ʒ����dz���������Ч�ķ�������ģ�ͼ����ò����κ�רҵ��ͳ�Ʒ������ھ�ֻ��,ֻ��Ҫ���л�����������ϴ��������ת�����ܼ������,��˼����Ǹ�����ҵ�����õ���ģ�͡�����Ҫ����,��ģ��ԭ����,ҵ�������Ӧ�������dz���������,�ɴ����߲�����صĿ����ԡ�
��ϱ��ڰ���,��һ�¼���ֵ��˼��������:
(1)����R��F��M����ά�Ƚ����,Ӧ����333=27�п�����,����Ϊʲô���ֻ��26��?
(2)��ͬ������,R��F��MȨ�ػᷢ���ı�,��ô��Ӫ����Ƿ��пɱ��Ժ�������?
(3)RFMģ�Ϳ�����Ϊģ�ͷ�������,Ҳ������Ϊ����Ԥ��������,���ڲ�ͬ��ά��,ͨ��������ϵ÷ֻ��Ȩ�÷ֵķ�ʽ����µ�����,����һ�����ݽ�ά����Ч������ʹ����ϵ÷ַ����ͼ�Ȩ�÷ַ����õ������ֽ�ά����,�ں���Ӧ����,��ʲô��ͬ��
---------------���������������� ----���� 2021��8��21��11:32
�ο�
Datawhale-team-learning
���ݲ��ֲο���������ʦ�ġ�Python���ݷ��������ݻ���Ӫ��