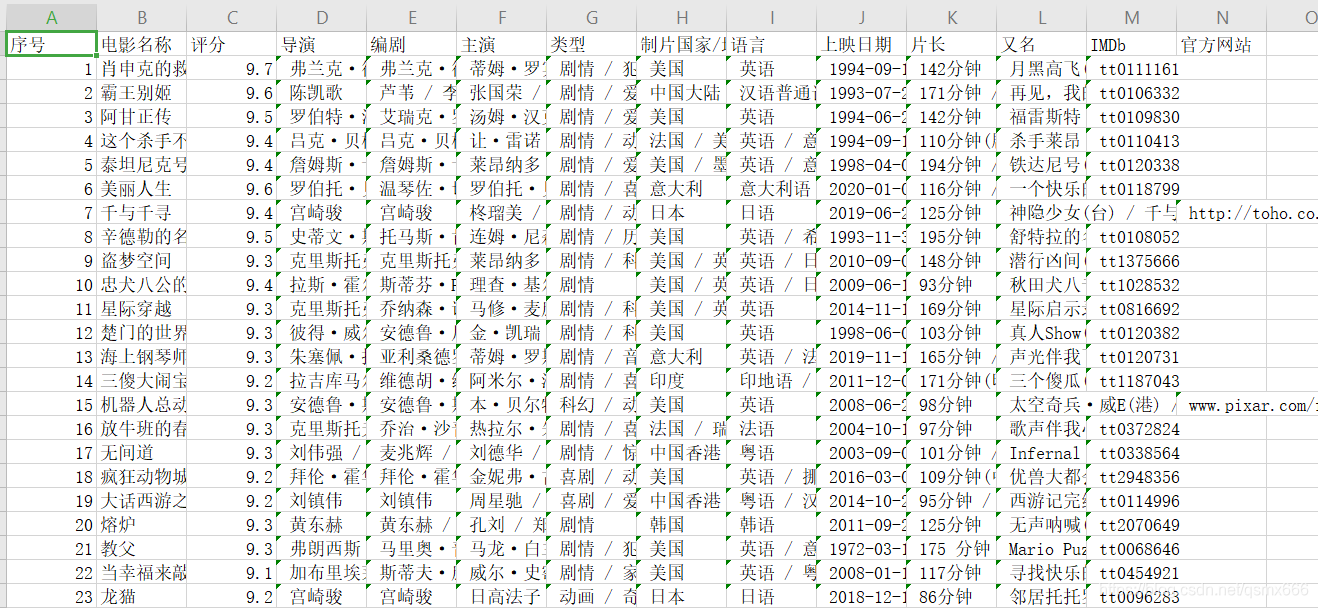
豆瓣电影Top250链接:https://movie.douban.com/top250
这是一个静态网页,没有任何反爬措施,直接爬就好了。
如下图,需要爬取的内容包括电影序号、名称、导演、编剧、主演等。
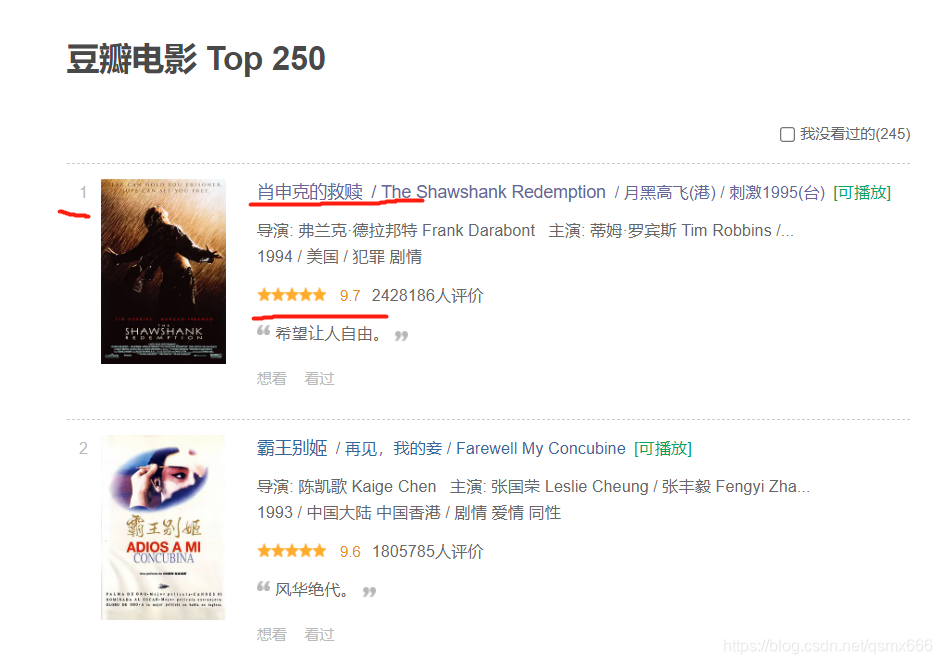
首先分析一下网页,每页一共有25部电影,一共有10页。每一页的url是有规律的。
第一页的url:https://movie.douban.com/top250?start=0&filter=
第二页的url:https://movie.douban.com/top250?start=25&filter=
第三页的url:https://movie.douban.com/top250?start=50&filter=
可以发现url的start参数是25的倍数,我们可以按照这个规律构造url,再对其进行解析。
代码如下:
from bs4 import BeautifulSoup
import requests
import pandas as pd
#解析列表页
def scrape_index(url):
content = requests.get(url, headers=headers)
soup = BeautifulSoup(content.text, "html.parser")
for tag in soup.find_all(attrs={"class":"item"}):
#爬取序号
detail_data={}
num = tag.find('em').get_text()
detail_data['序号']=num
#电影名称
name = tag.find_all(attrs={"class":"title"})
zwname = name[0].get_text()
detail_data['电影名称']=zwname
#电影评分
score = tag.find(attrs={"class":"rating_num"}).get_text()
detail_data['评分']=score
#网页链接
url_movie = tag.find(attrs={"class":"hd"}).a
href = url_movie.attrs['href']
scrape_detail(href,detail_data)
# 解析详情页
def scrape_detail(url, detail_data):
content = requests.get(url, headers=headers, stream=True)
soup = BeautifulSoup(content.text, "html.parser")
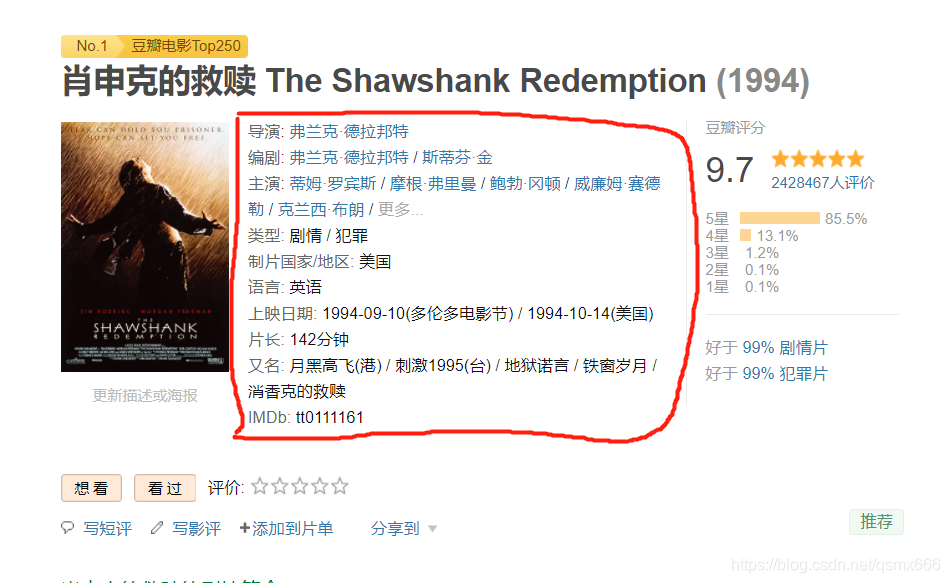
info = soup.find(attrs={"id": "info"})
details = info.get_text().strip().split('\n')
for detail in details[:10]:
item, info = detail.split(':', 1)
detail_data[item] = info
movie_data.append(detail_data)
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
INDEX_URL = 'https://movie.douban.com/top250?start={start}&filter='
movie_data = []
for start in range(0, 226, 25):
url = INDEX_URL.format(start=start)
scrape_index(url)
df = pd.DataFrame(movie_data)
df.to_csv('movie.csv', index=None)
我们用一个字典保存电影数据,先解析列表页,获取序号、名称、评分和详情页链接,再解析详情页,获取详情页数据。详情页的数据是一整段的,可以直接通过BeautifulSoup获取整段文本,再对这个长字符串进行处理。
结果如下: