反爬
ajax使用js代码设置网页样式,而不直接使用html。
如下js代码将id为show-text的标签设为hello world
document.getElementById("show-text").innerHTML = "hello world"
等价与:
<p id="show-text">hello world</p>
使用script标签做一个html页面:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>js-ajax</title>
</head>
<body>
<p id="show-text">我不是“hello world”!</p>
<script>
document.getElementById("show-text").innerHTML = "hello world"
</script>
</body>
</html>
用flask写一个服务器
import flask
app = flask.Flask(__name__)
@app.route('/')
def index():
return flask.render_template('index.html')
if __name__ == '__main__':
app.run(port=8888)
爬虫
打开http://127.0.0.1:8888/
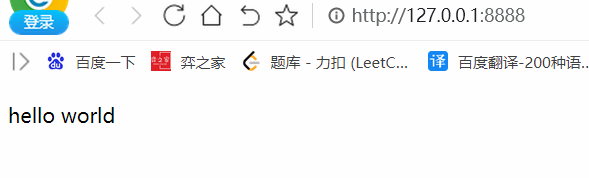
开F12,找到p标签:

写个py脚本:
import requests
url = 'http://127.0.0.1:8888/'
headers = {
'User-Agent': (
'Mozilla/5.0 (Windows NT 6.2; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/30.0.1599.17 Safari/537.36'
)
}
response = requests.get(url, headers=headers)
ps:不管网站有没有做请求头验证,建议都伪装一下请求头。
直接正则:
import requests
import re
url = 'http://127.0.0.1:8888/'
headers = {
'User-Agent': (
'Mozilla/5.0 (Windows NT 6.2; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/30.0.1599.17 Safari/537.36'
)
}
response = requests.get(url, headers=headers)
hello_world = re.search('<p id="show-text">(.*)</p>', response.text, re.S)
print(hello_world.group())
ps:用lxml或beautiful-soup都一样

却得到了我们意料之外的结果。
方案
1.解析js
我们把js爬下来:
import re
url = 'http://127.0.0.1:8888/'
headers = {
'User-Agent': (
'Mozilla/5.0 (Windows NT 6.2; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/30.0.1599.17 Safari/537.36'
)
}
response = requests.get(url, headers=headers)
hello_world = re.search('<script>(.*)</script>', response.text, re.S)
js = hello_world.groups(0)[0]
print(js)

使用re解析:
import requests
import re
url = 'http://127.0.0.1:8888/'
headers = {
'User-Agent': (
'Mozilla/5.0 (Windows NT 6.2; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/30.0.1599.17 Safari/537.36'
)
}
response = requests.get(url, headers=headers)
js = re.search('<script>(.*)</script>', response.text, re.S)
js = js.groups(0)[0]
hello_world = re.search('.innerHTML = "(.*)"', js, re.S)
hello_world = hello_world.groups(0)[0]
print(hello_world)
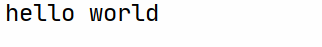
此方法需要js基础,并可能遇到如下情况:
1.找不到js代码
2.ob混淆,例如:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>js-ajax</title>
</head>
<body>
<p id="123456789">我不是“hello world”!</p>
<script>
document.getElementById("123456789").innerHTML = "hello world";
while (true)
{
debugger;
} // 常见的无限debug,也是一种反爬方案
</script>
</body>
</html>
3.js代码请求错误
2.selenium
selenium的配置有些复杂,可以看下面:
下载selenium
pip install Selenium
下载Chrome驱动
- 进入https://chromedriver.storage.googleapis.com/index.html?path=2.35/,根据你的系统下载
chrome-driver,我的是chromedriver_win32.zip - 找到下载路径,解压:

添加到环境变量
由于我的系统使用Windows10,因此仅以Win10系统为例。
- 右键单击此电脑,选择属性:
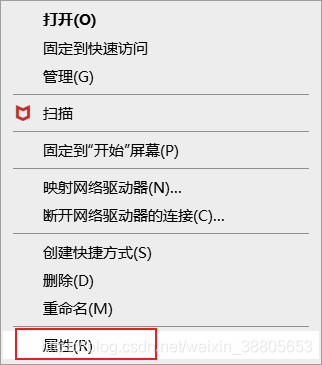
- 点击高级系统设置

- 点击环境变量
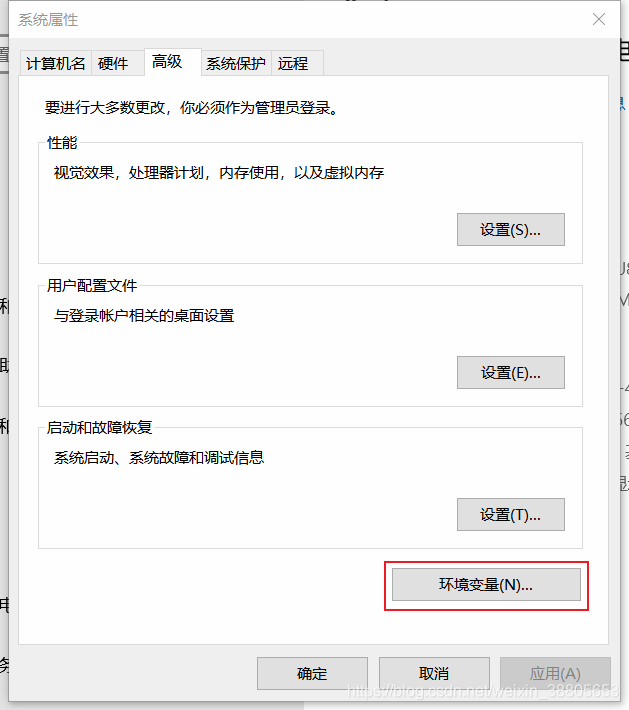
- 找到系统变量中的Path,点击编辑(I)
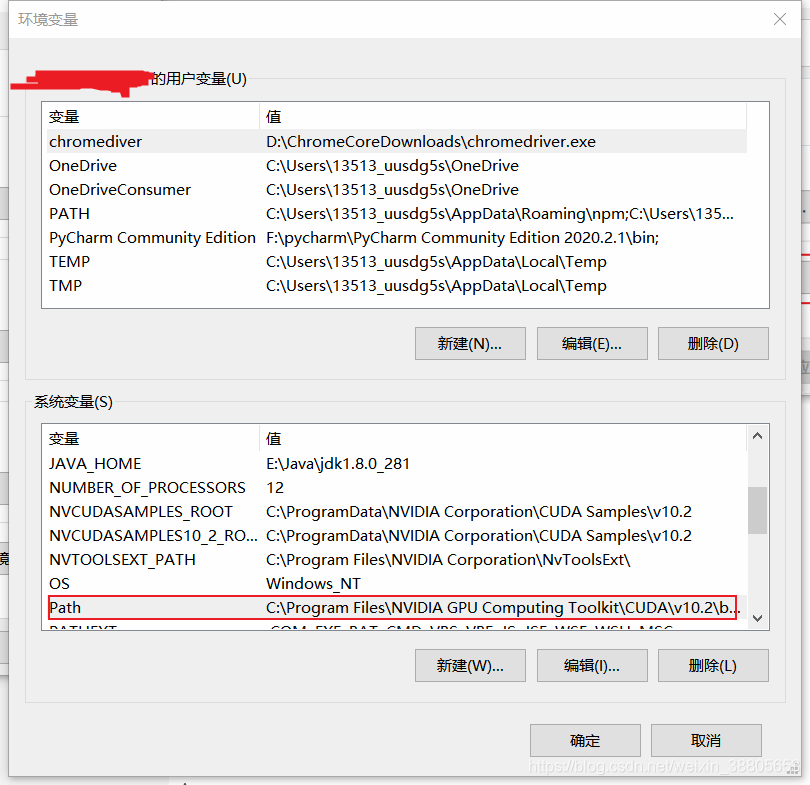
- 点击新建
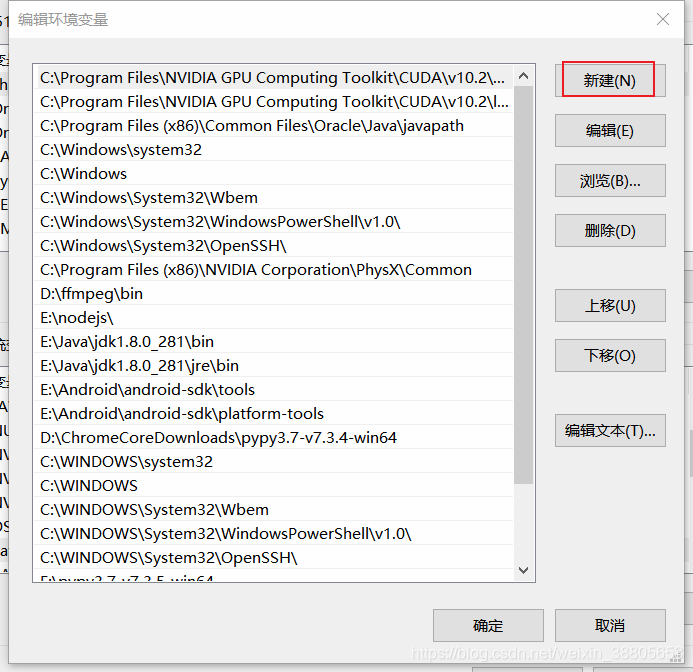
- 选择浏览,选择存放
chromedriver.exe的文件夹:
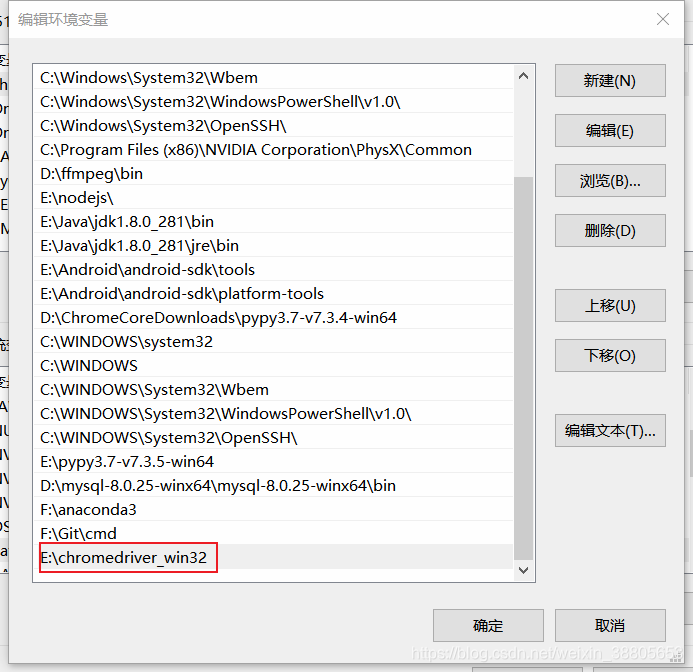
- 最后一路确定下去
编写代码
from selenium import webdriver
url = 'http://127.0.0.1:8888/'
# 还支持Firefox、IE、Edge、Safari、PhantomJS等
# 注意将你的chrome.exe添加到环境变量
options = webdriver.ChromeOptions()
options.binary_location = 'chrome'
chrome = webdriver.Chrome()
chrome.get(url)
p = chrome.find_element_by_id('show-text')
print(p.text)
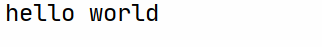
搞定!