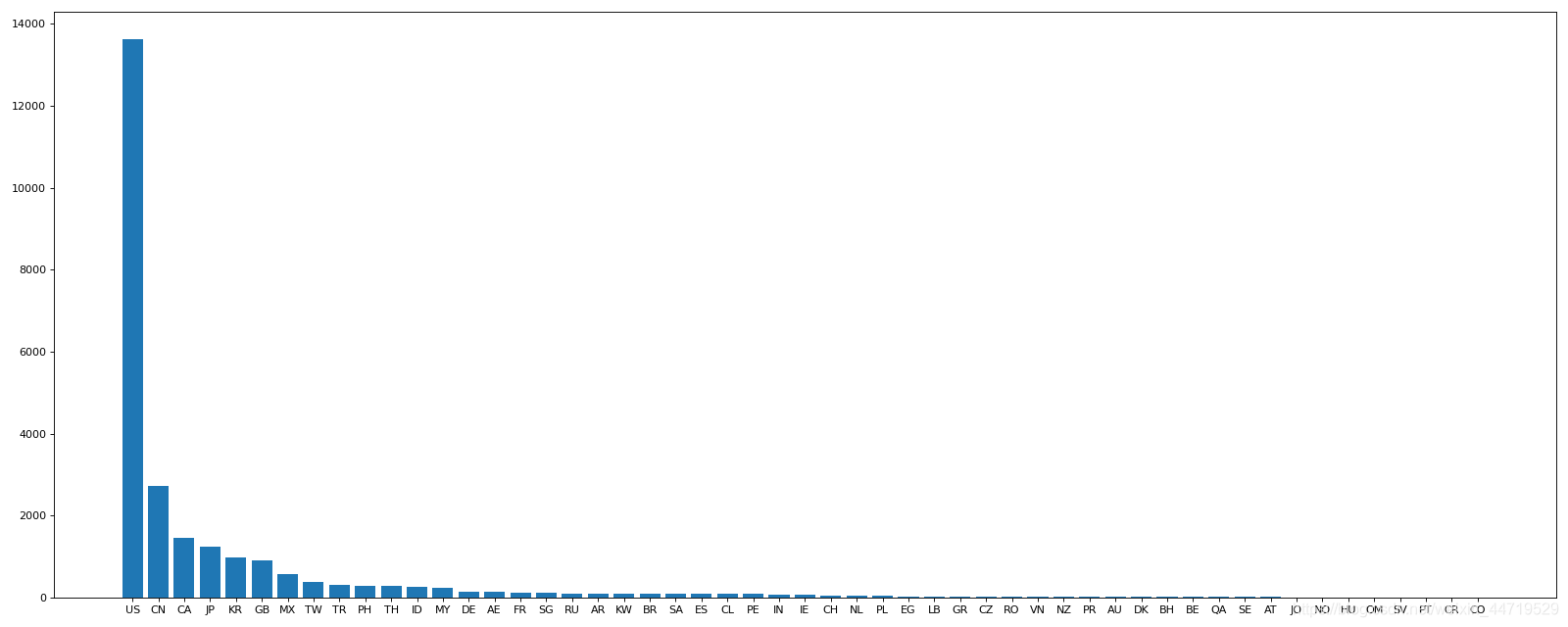
一、grouby 的练习
grouby 将df进行分组,选择某一列形成Series,之后进行画图
x轴:range (Series.index)
y轴:Series(或Series.value)
"""
@desc: 店铺排名前十的绘图
"""
import pandas as pd
from matplotlib import pyplot as plt
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
df=pd.read_csv("starbucks_store_worldwide.csv")
grouped=df.groupby(by="Country")["Country"].count()
grouped=grouped[grouped>10]
grouped=grouped.sort_values(ascending=False)
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(grouped)),grouped)
plt.xticks(range(len(grouped)),grouped.index)
plt.show()
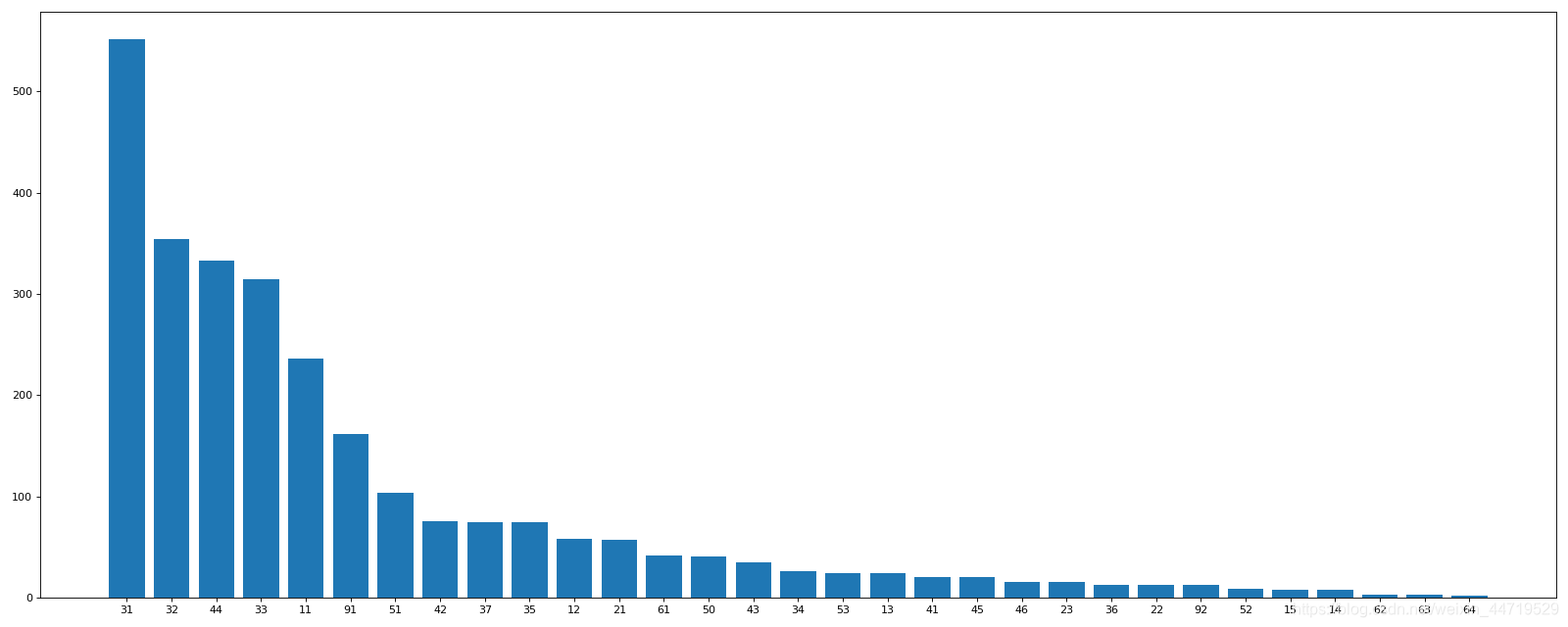
@file: 21_中国每个城市店铺的数量.py
@time: 2021/08/21
@desc:
"""
import pandas as pd
from matplotlib import pyplot as plt
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
df=pd.read_csv("starbucks_store_worldwide.csv")
df_cn=df[df["Country"]=="CN"]
grouped=df_cn.groupby(by="State/Province")["State/Province"].count()
grouped=grouped.sort_values(ascending=False)
print(grouped)
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(grouped)),grouped)
#
plt.xticks(range(len(grouped)),grouped.index)#其中中国各个城市名字以数字代替
plt.show()
在这里插入图片描述
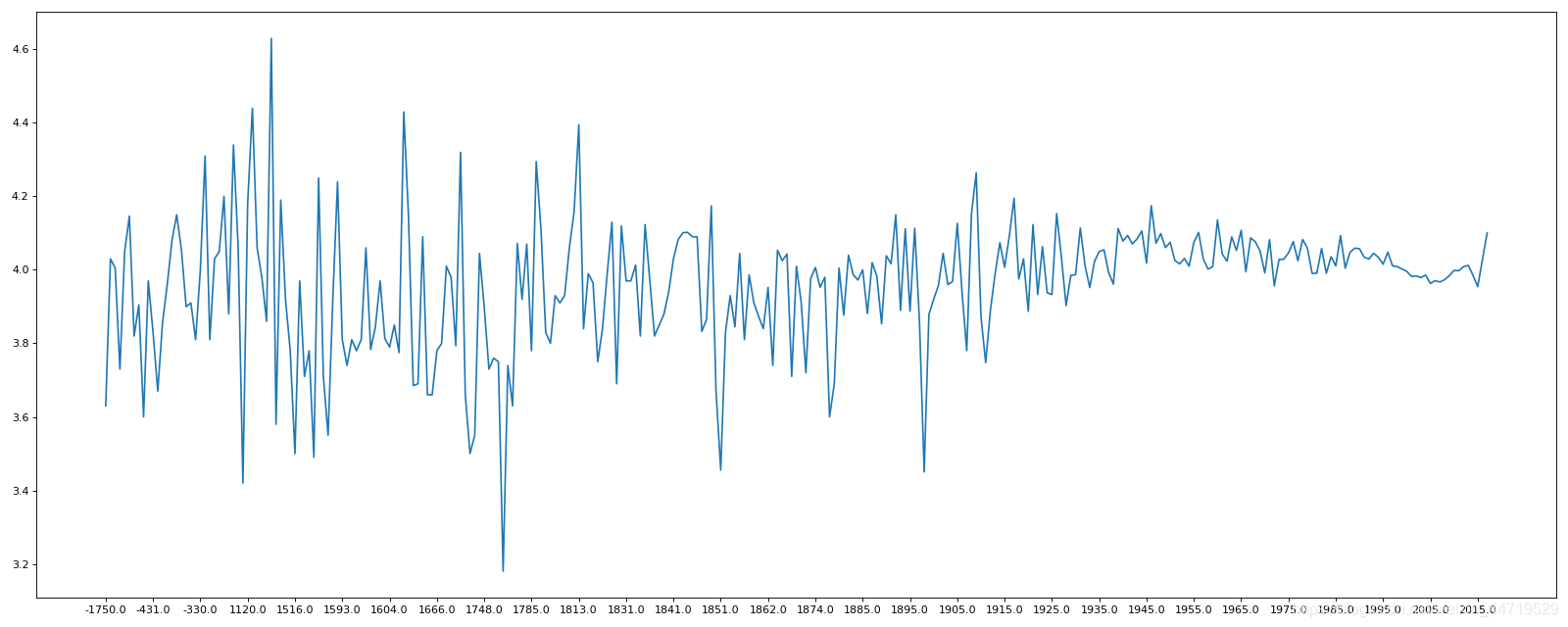
二、不同年份书的评分情况
import pandas as pd
from matplotlib import pyplot as plt
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
df=pd.read_csv("books.csv")
df=df[pd.notnull(df["original_publication_year"])]#选择original_publication_year非NAN的值
grouped=df["average_rating"].groupby(by=df["original_publication_year"]).mean()
print(grouped)
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(grouped)),grouped)
plt.xticks(list(range(len(grouped)))[::10],list(grouped.index)[::10])
plt.show()