文章目录
1 Series
结构: 索引 + 一维数组数值
1.1 创建Series
通过三种方式创建:pd.Series ( list /array / dict)
- 列表list

- 数组array

- 字典dict(键――索引,值――值)

1.2 指定Series索引
pd.Series (list , index=[ ])
#Series默认索引为0 1 2 3…
#指定index ,索引长度要与值长度一致

1.3 获取Series数据
获取索引 .index

获取值 .values

1.4 Series运算
-
加减乘除
直接对Series进行操作

-
筛选
#筛选出大于3的数值

- Series之间的操作
**两个series进行操作,相同索引的值进行运算;若无相同索引,最终相加结果赋值为NaN。


2 DataFrame
表格型数据结构,含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等);
既有行索引也有列索引,可以被看作由series组成的字典(共用同一个索引)。
2.1 创建Dataframe
pd. DataFrame (array / dict)
- 通过 array
未指定行索引和列索引,默认0 1 2…

指定行列索引:pd. DataFrame (arr , columns =[ ] , index=[ ])

- 通过dict

2.2 dataframe常见操作
- 查看数据
-
head()查看头数据 tail()查看尾数据

-
info() 查看数据结构及储存信息

describe() 查看数据按列的统计信息

#std代表标准差
- mean()均值 median()中位数

-
index 行索引 columns 列索引

-
T转置

- 排序
sort_index(axis=0/1,ascending=True/False)
axis=0按行索引进行排序 axis=1按列索引进行排序
ascending=True(索引按从小到大排序)/False(索引按从大到小排序)

3 对比Series与Dataframe
DataFrame是由多个共用相同索引的Series组成,
Series没有列索引,DataFrame有列索引
可拆分、合并互相转化
3.1 Dataframe可拆分成多个Sereis
#通过相应列名

3.2 多个Sereis可组成Dataframe

#其中name,age,sex列为不同的Series.
3.3 其他:逐行读取数据
for index.value in df.iterrows():

读出具体数值

4 Pandas IO 操作(input/output文件的读与写)
url: ‘https://pandas.pydata.org/pandas- docs/ version/1.0.1 /users_guide /io.html’
4.1 读取数据
**查看当前目录下文件
!dir #Windows操作系统

!ls #Linux
- read_csv 读取csv、txt数据

- read_excel 读取excel数据

4.2 输出数据
- to_excel
输出一个excel文件

df.to_excel(‘ ’,header=T/F,index=T/F)
#header=True/False 输出/不输出标题
index=True/False 输出/不输出索引


- to_dict
输出一个字典

- to_csv
输出一个csv文件
- to_html
输出一个网页文件


5 loc与iloc数据选择
选择指定行列 loc/iloc
5.1 loc
- 选择列/行
loc [row,column]
#df.loc[ : , : ] 返回所有数据
#row 选择指定行数索引
df.loc[ : 3, : ] 返回前4行(0,1,2,3)
#column 选择指定的列名
df.loc[ : ,’列名’] 返回Series (1列)
df.loc[ : , [’列名’,’列名’]] 返回DataFrame (可多列)
#加中括号可返回多列DataFrame

- 筛选特定条件的DataFrame
选择出所有stockcode为71053的数据

选择出所有索引为偶数的数据 df .index%2==0

5.2 iloc
loc前面输入数字后面需要输入列名
iloc前后返回行列都需要输入数字,不能输入相应列名
#df.iloc[ :3 , : 3] 返回前3行前3列 (0,1,2) 与loc不同

6 pivot_table 数据透视表
 #传入两个值要加中括号
#传入两个值要加中括号
df.pivot_table( ) 内部参数默认

aggfunc 默认计算均值 ,可进行修改用于求和等
#aggfunc=[np.sum,len,np.mean]
可传入字典,指定列进行相关计算

fill_value 空值填充
margins 统计,求和由aggfunc决定
7 merge连接
内部参数

how:
‘inner’内连接(默认内连接) 根据on条件,列出左右两表共有数据
‘left’ 左连接 表1的完全集,而表2中匹配的则有值,没有匹配的则以null值取代
‘right’右连接 表2从完全集,而表1中匹配的则有值,没有匹配的则以null值取代
‘outer’全连接 所有值
on =两个dataframe相同的列名
left_on=第一个dataframe列名
right_on=第二个dataframe列名
Suffixes=(‘_x’,’_y’) 可传入指定后缀名 ,如果两个dataframe有相同列名,则第一个dataframe列名默认后缀+‘_x’,第二个列名默认后缀+‘_y’

-
内连接

-
左连接

-
右连接

-
全连接

8 groupby分组
g=data.groupby(‘分组字段’)
过程是将一个DataFrame按照groupby字段,化分成若干个分组DataFrame,分组会返回一个DataFrameGroupby对象

-
list() 查看DataFrameGroupby对象内部情况

-
get_group() 查看一个组的数据情况 g.get_group()

-
agg函数聚合 data.groupby( ).agg( )
相关函数:
min 、max、 sum、 mean、 median、
count 计数,不包含NaN值、
size 计数,包含NaN值、
nunique 计算去重后的个数。

groupby分组后直接.agg()进行聚合操作

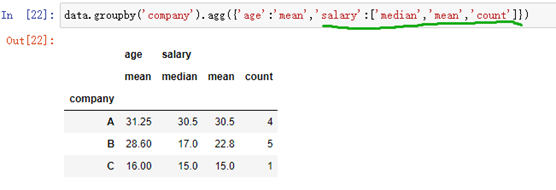
**可通过传入字典的形式不同列进行不同操作,也可对一个列进行多个操作
9 map、replace操作
9.1 map
内部参数

- arg
字典键值对替换,若字典中没有找到series中对应的值,则赋值为NaN


- na_action
如果传入‘ignore’,则跳过对空值的操作

9.2 Replace
字典键值对替换,其他值保持不变
- 指定列替换


- 不指定列替换

10 分箱操作
pd.cut 常用来把一组数据分割成离散的区间
内部参数

x:被切分的类数组数据,一维,arrary/series
bins:被切割后的区间个数
- int:当bins为一个ins型标量时,如bins=3,代表将x分为三个区间


- sequence:指定区间如[0,59,70,80,100],控制区间范围

right:bool型参数,默认为True。right=True,区间左开右闭;right=False,区间左闭右开
labels:给分割后的bins区间设置标签,labels的长度和划分后的区间长度相同,例如分割后有2个区间,则labels长度必须为2.

可将其转化为dataframe形式

 用groupby查看数据统计
用groupby查看数据统计

11 apply自定义函数
可直接用于Series和DataFrame对象,进行数据聚合运算
apply( np.sqrt ) 开根号


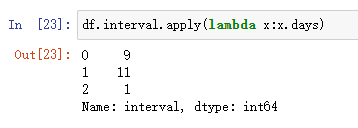
apply ( pd.to_datetime ) 计算时间间隔

对多列进行操作 采用自定义函数,axis=1
例:score>=600且interval<=15,打个标签 1,否则为0

#x为操作接收参数
lambda

12 其他常用函数
-
rename 修改列名/索引


令inplce=True,才会将其真正改变,否则只是改变了副本 -
set_index 将DataFrame中的某一(多)个字段设置为索引

若将多个字段同时设置为索引需加中括号

-
reset_index 重置索引
参数:drop
drop=False 保留原索引 ,并作为DataFrame新字段 默认
drop=True 删除原索引



- drop_duplicates 去重
参数:
subset 指定列作为主键,即在去重过程只针对指定列进行去重,保留指定列不同的字段;不指定列时去重完全重复的数据。
keep first/last 即在去重过程中保留第一行还是最后一行,默认first.


- drop 删除DataFrame指定列与索引

- isin 常用于构建布尔索引,对DataFrame的数据条件筛选

- value_counts 统计分类变量中每个类的数量
参数:normalize=True返回各类的占比,否则返回具体数量

- isna 判断DataFrame/Series是否为缺失值,是的话返回True。

返回出有缺失值的一行

any df.isna( ).any( ) 可判断某一列是否有缺失值,方便

- dropna 删除含有缺失值的数据

- fillna 填充缺失值
参数:
value
method
=pad/ffill 用上一个值填充;
=backfill/bfill 用下一个值填充。

- sort_values
按照某列(通过参数by实现)进行排序,对Series按数据列进行排序

#默认ascending=True,即由小到大排序;令ascending=False由大到小排序