确认数据
import pandas as pd # 读取数据到DataFrame
import urllib # 获取网络数据
import tempfile # 创建临时文件系统
import shutil # 文件操作
import zipfile # 压缩解压
temp_dir = tempfile.mkdtemp() # 建立临时目录
data_source = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00275/Bike-Sharing-Dataset.zip' # 网络数据地址
zipname = temp_dir + '/Bike-Sharing-Dataset.zip' # 拼接文件和路径
try:
urllib.urlretrieve(data_source, zipname) # 获得数据 python2.x
except:
urllib.request.urlretrieve(data_source, zipname) # 获得数据 python3.x
zip_ref = zipfile.ZipFile(zipname, 'r') # 创建一个ZipFile对象处理压缩文件
zip_ref.extractall(temp_dir) # 解压
zip_ref.close()
daily_path = temp_dir + '/day.csv'
daily_data = pd.read_csv(daily_path) # 读取csv文件
daily_data['dteday'] = pd.to_datetime(daily_data['dteday']) # 把字符串数据传换成日期数据
drop_list = ['instant', 'season', 'yr', 'mnth', 'holiday', 'workingday', 'weathersit', 'atemp', 'hum'] # 不关注的列
daily_data.drop(drop_list, inplace = True, axis = 1) # inplace=true在对象上直接操作
shutil.rmtree(temp_dir) # 删除临时文件目录
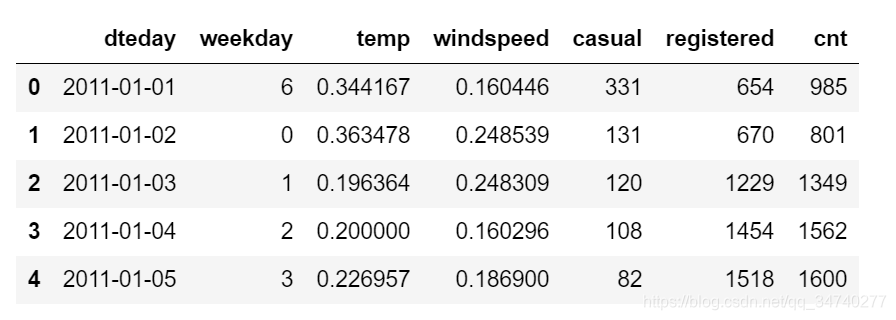
daily_data.head() # 看一看数据哈~
配置参数
# 引入3.x版本的除法和打印
from __future__ import division, print_function
from matplotlib import pyplot as plt
import pandas as pd
import numpy as np
# 在notebook中显示绘图结果
%matplotlib inline
# 设置一些全局的资源参数,可以进行个性化修改
import matplotlib
# 设置图片尺寸 14" x 7"
# rc: resource configuration
matplotlib.rc('figure', figsize = (14, 7))
# 设置字体 14
matplotlib.rc('font', size = 14)
# 不显示网格
matplotlib.rc('axes', grid = False)
# 设置背景颜色是白色
matplotlib.rc('axes', facecolor = 'white')
关联分析
关联分析是所有分析中的第一步!考虑的两组数据之间是否存在关系~
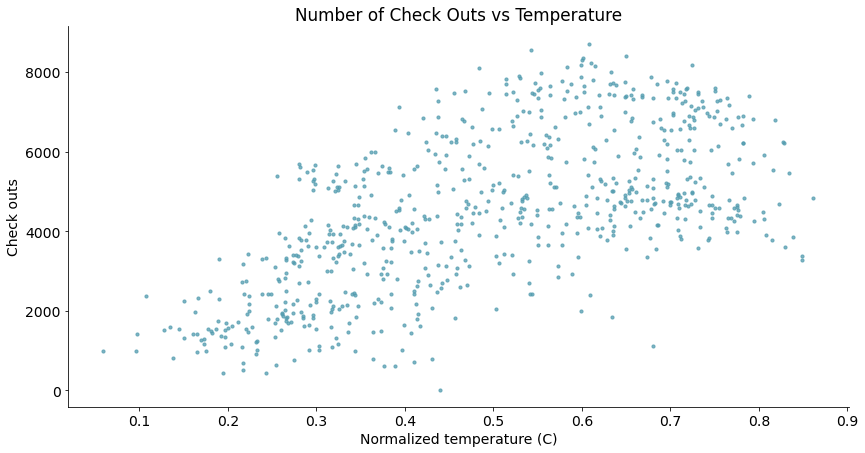
散点图
- 分析变量关系
判断:“正相关”?“负相关”?还是“不相关”?
# 包装一个散点图的函数便于复用
def scatterplot(x_data, y_data, x_label, y_label, title, ax = None):
# 创建一个绘图对象
if ax:
pass
else:
fig, ax = plt.subplots()
# 调用plt句柄画一个图,返回两个变量fig,ax,分别是figure和 axes的缩写。函数返回一个figure图像和一个子图ax的array列表。
# 一个fig图里边会套好几个ax,而每个ax会负责当前坐标上的图。所以任何绘制的图形都是在ax上完成的;
# 而设置整个画布,将是在fig上完成。
# 不显示顶部和右侧的坐标线
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 设置数据x_data和y_data、点的大小s、点的颜色color和透明度alpha
ax.scatter(x_data, y_data, s = 10, color = '#539caf', alpha = 0.75)
# 添加标题和坐标说明
ax.set_title(title)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
# 绘制散点图
scatterplot(x_data = daily_data['temp']
, y_data = daily_data['cnt']
, x_label = 'Normalized temperature (C)'
, y_label = 'Check outs'
, title = 'Number of Check Outs vs Temperature')
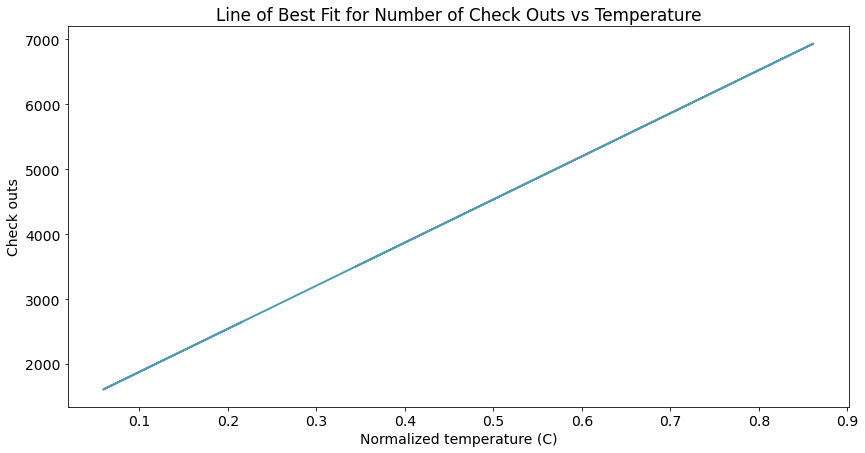
曲线图
拟合变量关系(绘制拟合关联曲线)
# 线性回归
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import summary_table
x = sm.add_constant(daily_data['temp']) # 线性回归增加常数项
y = daily_data['cnt']
regr = sm.OLS(y, x) # 普通最小二乘模型,ordinary least square model
res = regr.fit()
# 从模型获得拟合数据
st, data, ss2 = summary_table(res, alpha=0.05) # 置信水平alpha=5%,st数据汇总,data数据详情,ss2数据列名
fitted_values = data[:,2]
# x.head()
# type(regr) # 普通最小二乘模型
# st # 数据汇总
# 包装曲线绘制函数
def lineplot(x_data, y_data, x_label, y_label, title):
# 创建绘图对象
_, ax = plt.subplots()
# 绘制拟合曲线,lw=linewidth,alpha=transparancy
ax.plot(x_data, y_data, lw = 2, color = '#539caf', alpha = 1)
# 添加标题和坐标说明
ax.set_title(title)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
# 调用绘图函数
lineplot(x_data = daily_data['temp']
, y_data = fitted_values
, x_label = 'Normalized temperature (C)'
, y_label = 'Check outs'
, title = 'Line of Best Fit for Number of Check Outs vs Temperature')
带置信区间的曲线图
评估曲线拟合结果(对曲线图的进一步分析~)
# 获得5%置信区间的上下界
predict_mean_ci_low, predict_mean_ci_upp = data[:,4:6].T
# 创建置信区间DataFrame,上下界
CI_df = pd.DataFrame(columns = ['x_data', 'low_CI', 'upper_CI'])
CI_df['x_data'] = daily_data['temp']
CI_df['low_CI'] = predict_mean_ci_low
CI_df['upper_CI'] = predict_mean_ci_upp
CI_df.sort_values('x_data', inplace = True) # 根据x_data进行排序
# 绘制置信区间
def lineplotCI(x_data, y_data, sorted_x, low_CI, upper_CI, x_label, y_label, title):
# 创建绘图对象
_, ax = plt.subplots()
# 绘制预测曲线
ax.plot(x_data, y_data, lw = 1, color = '#539caf', alpha = 1, label = 'Fit')
# 绘制置信区间,顺序填充
ax.fill_between(sorted_x, low_CI, upper_CI, color = '#539caf', alpha = 0.4, label = '95% CI')
# 添加标题和坐标说明
ax.set_title(title)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
# 显示图例,配合label参数,loc=“best”自适应方式
ax.legend(loc = 'best')
return ax
# Call the function to create plot
ax = lineplotCI(x_data = daily_data['temp']
, y_data = fitted_values
, sorted_x = CI_df['x_data']
, low_CI = CI_df['low_CI']
, upper_CI = CI_df['upper_CI']
, x_label = 'Normalized temperature (C)'
, y_label = 'Check outs'
, title = 'Line of Best Fit for Number of Check Outs vs Temperature')
# 叠加上绘制散点图
scatterplot(x_data = daily_data['temp']
, y_data = daily_data['cnt']
, x_label = 'Normalized temperature (C)'
, y_label = 'Check outs'
, title = 'Number of Check Outs vs Temperature'
, ax=ax)
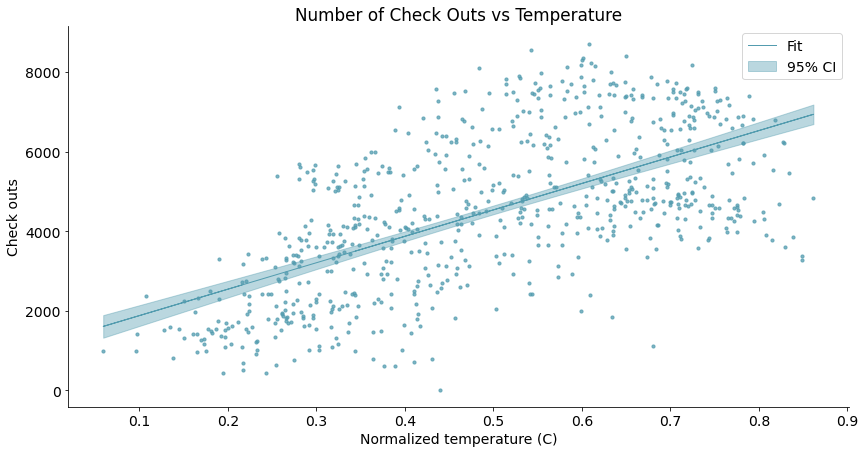
有95%的数据都集中在上图阴影区域中,可见我们画出的曲线置信度其实是很大的,并没有像之前的散点图那样让人觉得相关性还很模糊,其实散点图中很多点在绘制中重合了。图中的带状区域越宽,曲线的置信度越低。异常值少,对应的带状区域自然也就会窄。图中带状区域两头宽,中间窄,是由于中间数据量丰富,置信度很大,再加上置信度的计算方式是σ方式,对于σ来说,数据越多,方差σ越小,由此带状区域两头数据量没有那么丰富和足够充分,从而影响了方差和置信度。
双坐标曲线图
- 曲线拟合不满足置信阈值时,考虑增加独立变量
- 分析不同尺度多变量的关系
# 双纵坐标绘图函数
def lineplot2y(x_data, x_label,
y1_data, y1_color, y1_label,
y2_data, y2_color, y2_label, title):
_, ax1 = plt.subplots()
ax1.plot(x_data, y1_data, color = y1_color)
# 添加标题和坐标说明
ax1.set_ylabel(y1_label, color = y1_color)
ax1.set_xlabel(x_label)
ax1.set_title(title)
ax2 = ax1.twinx() # 两个绘图对象共享横坐标轴(关键!)
ax2.plot(x_data, y2_data, color = y2_color)
ax2.set_ylabel(y2_label, color = y2_color)
# 右侧坐标轴可见
ax2.spines['right'].set_visible(True)
# 调用绘图函数
lineplot2y(x_data = daily_data['dteday']
, x_label = 'Day'
, y1_data = daily_data['cnt']
, y1_color = '#539caf'
, y1_label = 'Check outs'
, y2_data = daily_data['windspeed']
, y2_color = '#7663b0'
, y2_label = 'Normalized windspeed'
, title = 'Check Outs and Windspeed Over Time')
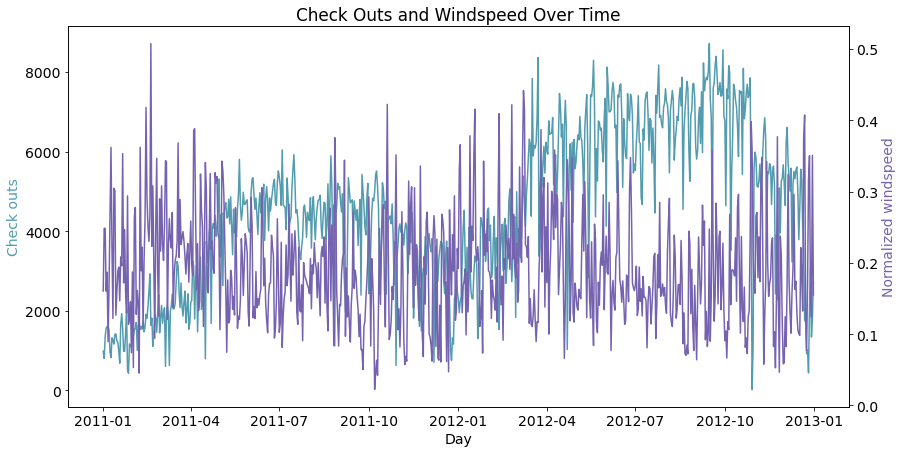
从图中可以察觉到总租车量与风速的大小存在负相关性。
分布分析
上一步是知道了变量之间的关系,接下来需要进一步知晓变量服从什么样的分布。因为分布情况会决定我们后续的处理方式。
灰度图(粗略)
- 粗略区间计数
# 绘制灰度图的函数
def histogram(data, x_label, y_label, title):
_, ax = plt.subplots()
res = ax.hist(data, color = '#539caf', bins=10) # 设置bin的数量
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
return res
# 绘图函数调用
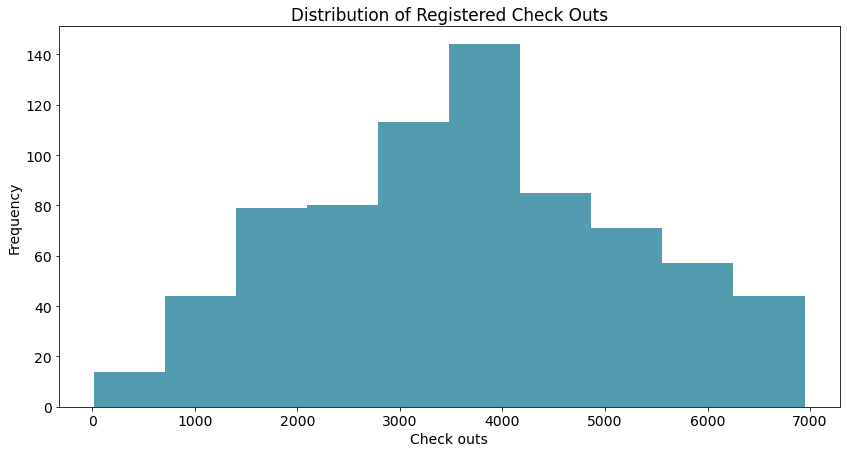
res = histogram(data = daily_data['registered']
, x_label = 'Check outs'
, y_label = 'Frequency'
, title = 'Distribution of Registered Check Outs')
res[0] # value of bins

res[1] # boundary of bins
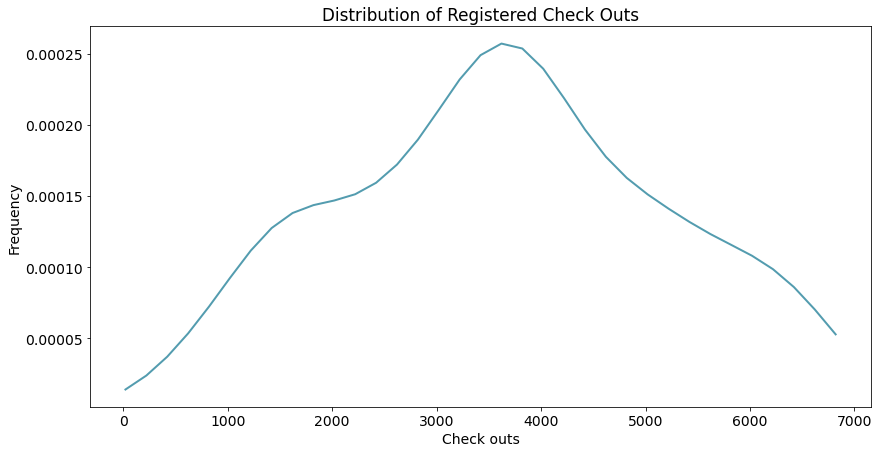
可以猜一下大概的分布,比如上面的图可能是正态分布。
堆叠直方图(粗略)
- 比较两个分布
# 绘制堆叠的直方图
def overlaid_histogram(data1, data1_name, data1_color, data2, data2_name, data2_color, x_label, y_label, title):
# 归一化数据区间,对齐两个直方图的bins
max_nbins = 10
data_range = [min(min(data1), min(data2)), max(max(data1), max(data2))]
binwidth = (data_range[1] - data_range[0]) / max_nbins
bins = np.arange(data_range[0], data_range[1] + binwidth, binwidth) # 生成直方图bins区间
# Create the plot
_, ax = plt.subplots()
ax.hist(data1, bins = bins, color = data1_color, alpha = 1, label = data1_name)
ax.hist(data2, bins = bins, color = data2_color, alpha = 0.75, label = data2_name)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = 'best')
# Call the function to create plot
overlaid_histogram(data1 = daily_data['registered']
, data1_name = 'Registered'
, data1_color = '#539caf'
, data2 = daily_data['casual']
, data2_name = 'Casual'
, data2_color = '#7663b0'
, x_label = 'Check outs'
, y_label = 'Frequency'
, title = 'Distribution of Check Outs By Type')
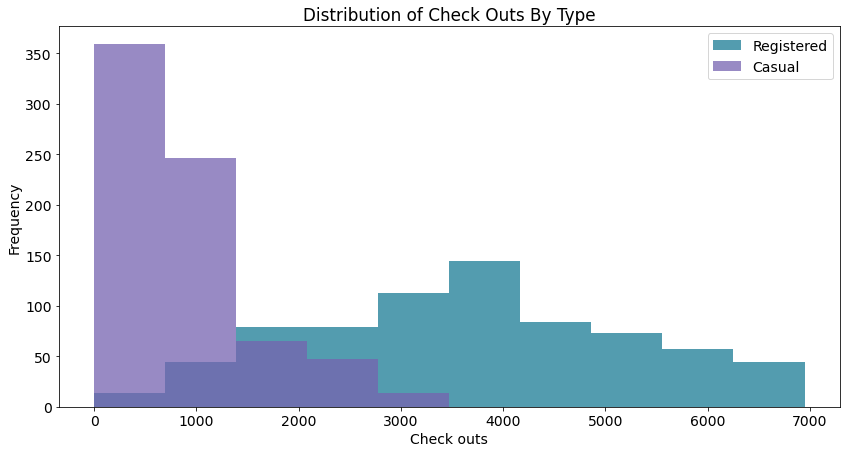
- 关于上图:
- registered:注册预约过的人的分布(绿色),正态分布,why
- 预约租车的人都是有计划性的,一般都是正态分布,呈现出大部分人在某区间内选择的现象。
- casual:偶然来租车的人的分布(紫色),疑似指数分布,why
- 偶然来租车的人是有随机性的~(我个人觉得可以看作是半个正态分布,表示大部分偶然租车的人,是倾向于选择少租 )
- registered:注册预约过的人的分布(绿色),正态分布,why
不过总感觉灰度图太糙了,有没有,肿么破
密度图(精细)
- 精细刻画概率分布
KDE: kernal density estimate 核密度估计
f ^ h ( x ) = 1 n ∑ i = 1 n K h ( x ? x i ) = 1 n h ∑ i = 1 n K ( x ? x i h ) \hat{f}_h(x)=\frac{1}{n}\sum^n_{i=1}K_h(x?x_i)=\frac{1}{nh}\sum^n_{i=1}K(\frac{x?x_i}{h}) f^?h?(x)=n1?i=1∑n?Kh?(x?xi?)=nh1?i=1∑n?K(hx?xi??)
用核函数去顾及每个采样点,最终把他们做一个平均(REF)。
# 计算概率密度
from scipy.stats import gaussian_kde
data = daily_data['registered']
density_est = gaussian_kde(data) # kernal density estimate: https://en.wikipedia.org/wiki/Kernel_density_estimation
# 控制平滑程度,数值越大,越平滑哈
density_est.covariance_factor = lambda : .3
# 这个数字越大,平滑度越好,但细节不足;数字越小,细节很突兀,
# 看不清分布趋势了。
# 该算法其实就是用正态分布去拟合的,用多个正态分布线性叠加,
# 叠加后也会是正态分布,但是叠加前被拟合的分布未必正态分布。
density_est._compute_covariance()
x_data = np.arange(min(data), max(data), 200)
# 绘制密度估计曲线
def densityplot(x_data, density_est, x_label, y_label, title):
_, ax = plt.subplots()
ax.plot(x_data, density_est(x_data), color = '#539caf', lw = 2)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
# 调用绘图函数
densityplot(x_data = x_data
, density_est = density_est
, x_label = 'Check outs'
, y_label = 'Frequency'
, title = 'Distribution of Registered Check Outs')
type(density_est)
或许我们可以堆叠多个直方图来分析分布~
组间分析
- 组间定量比较
- 分组粒度
- 组间聚类
柱状图 - 一级类间均值方差比较
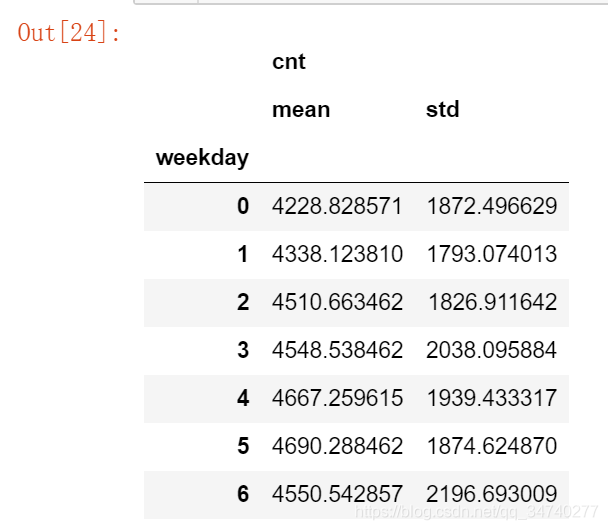
daily_data[['weekday', 'cnt']].groupby('weekday').agg([np.mean,np.std])
# 分天分析统计特征
mean_total_co_day = daily_data[['weekday', 'cnt']].groupby('weekday').agg([np.mean, np.std])
mean_total_co_day.columns = mean_total_co_day.columns.droplevel() # ['mean', 'std']
# 定义绘制柱状图的函数
def barplot(x_data, y_data, error_data, x_label, y_label, title):
_, ax = plt.subplots()
# 柱状图(注:x_data是不能接受str或者float的)
ax.bar(x_data, y_data, color = '#539caf', align = 'center')
# 绘制方差
# ls='none'去掉bar之间的连线
ax.errorbar(x_data, y_data, yerr = error_data, color = '#297083', ls = 'none', lw = 5) # lw线宽
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
# 绘图函数调用
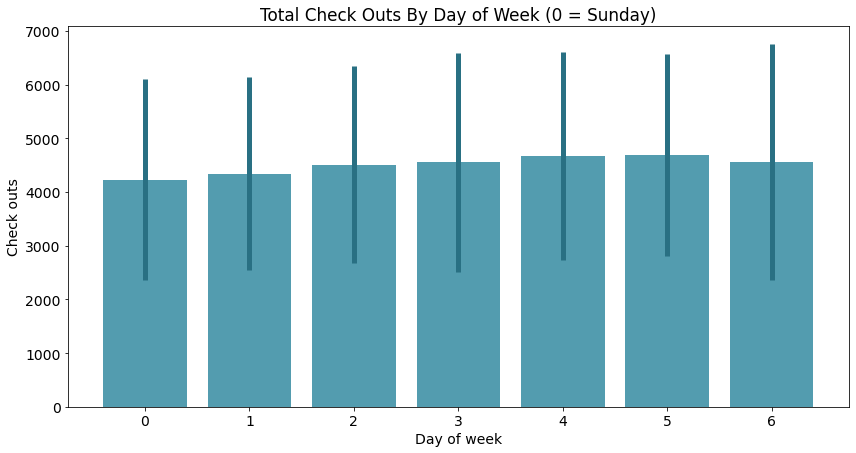
barplot(x_data = mean_total_co_day.index.values
, y_data = mean_total_co_day['mean'] # 取每天租车量的均值
, error_data = mean_total_co_day['std']
, x_label = 'Day of week'
, y_label = 'Check outs'
, title = 'Total Check Outs By Day of Week (0 = Sunday)')
堆积柱状图
- 多级类间相对占比比较
mean_by_reg_co_day = daily_data[['weekday', 'registered', 'casual']].groupby('weekday').mean()
mean_by_reg_co_day
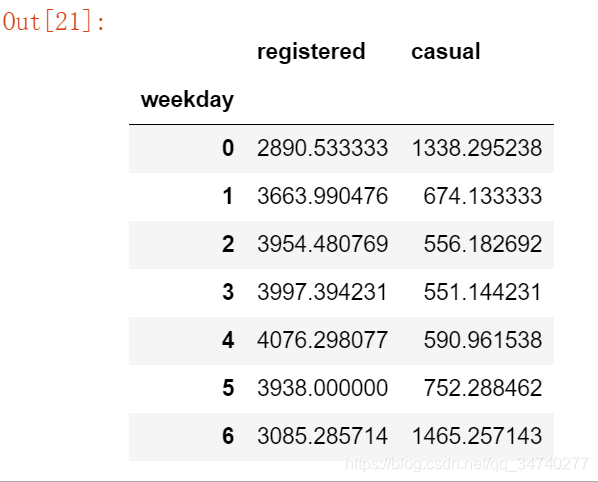
# 分天统计注册和偶然使用的情况
mean_by_reg_co_day = daily_data[['weekday', 'registered', 'casual']].groupby('weekday').mean()
# 分天统计注册和偶然使用的占比
mean_by_reg_co_day['total'] = mean_by_reg_co_day['registered'] + mean_by_reg_co_day['casual']
mean_by_reg_co_day['reg_prop'] = mean_by_reg_co_day['registered'] / mean_by_reg_co_day['total']
mean_by_reg_co_day['casual_prop'] = mean_by_reg_co_day['casual'] / mean_by_reg_co_day['total']
# 绘制堆积柱状图
def stackedbarplot(x_data, y_data_list, y_data_names, colors, x_label, y_label, title):
_, ax = plt.subplots()
# 循环绘制堆积柱状图
for i in range(0, len(y_data_list)):
if i == 0:
ax.bar(x_data, y_data_list[i], color = colors[i], align = 'center', label = y_data_names[i])
else:
# 采用堆积的方式,除了第一个分类,后面的分类都从前一个分类的柱状图接着画
# 用归一化保证最终累积结果为1,下面bottom参数表示纵向从哪里开始画
ax.bar(x_data, y_data_list[i], color = colors[i], bottom = y_data_list[i - 1], align = 'center', label = y_data_names[i])
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = 'upper right') # 设定图例位置
# 调用绘图函数
stackedbarplot(x_data = mean_by_reg_co_day.index.values
, y_data_list = [mean_by_reg_co_day['reg_prop'], mean_by_reg_co_day['casual_prop']]
, y_data_names = ['Registered', 'Casual']
, colors = ['#539caf', '#7663b0']
, x_label = 'Day of week'
, y_label = 'Proportion of check outs'
, title = 'Check Outs By Registration Status and Day of Week (0 = Sunday)')
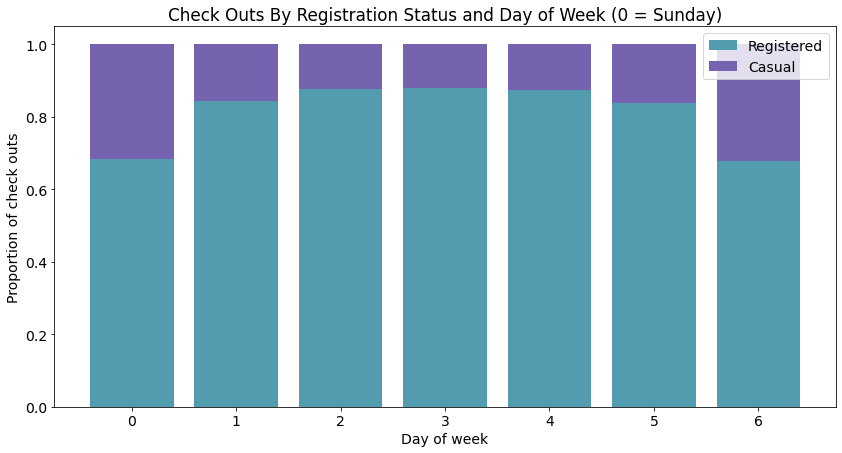
- 从这幅图你看出了什么?工作日 VS 节假日(每天预约和偶然租车的相对量)
- 为什么会有这样的差别?周末的随机性更大。
分组柱状图
- 多级类间绝对数值比较
# 绘制分组柱状图的函数
def groupedbarplot(x_data, y_data_list, y_data_names, colors, x_label, y_label, title):
_, ax = plt.subplots()
# 设置每一组柱状图的宽度
total_width = 0.8
# 设置每一个柱状图的宽度
ind_width = total_width / len(y_data_list)
# 计算每一个柱状图的中心偏移
alteration = np.arange(-total_width/2+ind_width/2, total_width/2+ind_width/2, ind_width)
# 分别绘制每一个柱状图
for i in range(0, len(y_data_list)):
# 横向散开绘制
ax.bar(x_data + alteration[i], y_data_list[i], color = colors[i], label = y_data_names[i], width = ind_width)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = 'upper right')
# 调用绘图函数
groupedbarplot(x_data = mean_by_reg_co_day.index.values
, y_data_list = [mean_by_reg_co_day['registered'], mean_by_reg_co_day['casual']]
, y_data_names = ['Registered', 'Casual']
, colors = ['#539caf', '#7663b0']
, x_label = 'Day of week'
, y_label = 'Check outs'
, title = 'Check Outs By Registration Status and Day of Week (0 = Sunday)')
- 偏移前:ind_width/2
- 偏移后:total_width/2
- 偏移量:total_width/2-ind_width/2
箱式图
- 多级类间数据分布比较
- 柱状图 + 堆叠灰度图
# 只需要指定分类的依据,就能自动绘制箱式图
days = np.unique(daily_data['weekday']) # [0, 1, 2, 3, 4, 5, 6]
bp_data = []
for day in days:
bp_data.append(daily_data[daily_data['weekday'] == day]['cnt'].values)
# 定义绘图函数
def boxplot(x_data, y_data, base_color, median_color, x_label, y_label, title):
_, ax = plt.subplots()
# 设置样式
ax.boxplot(y_data
# 箱子是否颜色填充
, patch_artist = True
# 中位数线颜色
, medianprops = {'color': base_color}
# 箱子颜色设置,color:边框颜色,facecolor:填充颜色
, boxprops = {'color': base_color, 'facecolor': median_color}
# 猫须颜色whisker
, whiskerprops = {'color': median_color}
# 猫须界限颜色whisker cap
, capprops = {'color': base_color})
# 箱图与x_data保持一致
ax.set_xticklabels(x_data)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
# 调用绘图函数
boxplot(x_data = days
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Day of week'
, y_label = 'Check outs'
, title = 'Total Check Outs By Day of Week (0 = Sunday)')
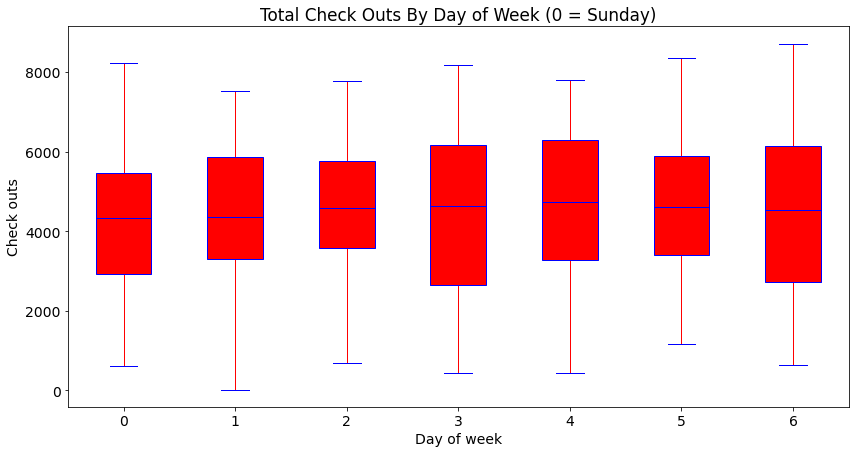
简单总结
- 关联分析、定量数值比较:散点图、曲线图
- 分布分析(定量数据:粗处度/细处度):灰度图、密度图
- 涉及分类的分析(关于定序/定类数据):柱状图、箱式图
源码获取:关注微信公众号“AI阅读知识图谱”,回复“Python数据可视化”获取已更新内容全部代码。